Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Locality Sensitive Hashing at Lyst
Search
Maciej Kula
July 24, 2015
Programming
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Locality Sensitive Hashing at Lyst
Description of the intuition behind locality sensitive hashing and its application at Lyst.
Maciej Kula
July 24, 2015
More Decks by Maciej Kula
See All by Maciej Kula
Implicit and Explicit Recommender Systems
maciejkula
0
3k
Binary Embeddings For Efficient Ranking
maciejkula
0
720
Rust for Python Native Extensions
maciejkula
0
490
Hybrid Recommender Systems at PyData Amsterdam 2016
maciejkula
5
2.9k
Recommendations under sparsity
maciejkula
1
390
Metadata Embeddings for User and Item Cold-start Recommendations
maciejkula
2
1k
Other Decks in Programming
See All in Programming
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
180
Creating Composable Callables in Contemporary C++
rollbear
0
200
ECSアプリログをFireLensでコスト削減しようとしたけど諦めた話 in Fargate×Node.js
akihisaikeda
2
4.2k
初めてのKubernetes 本番運用でハマった話
oku053
0
120
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.4k
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
100
スマートグラスで並列バイブコーディング
hyshu
0
280
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
180
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
210
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
770
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
250
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
Featured
See All Featured
It's Worth the Effort
3n
188
29k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
A Soul's Torment
seathinner
6
3k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
RailsConf 2023
tenderlove
30
1.5k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
560
The untapped power of vector embeddings
frankvandijk
2
1.8k
Transcript
Speeding up search with locality sensitive hashing. by Maciej Kula
Hi, I’m Maciej Kula. @maciej_kula
We collect the world of fashion into a customisable shopping
experience.
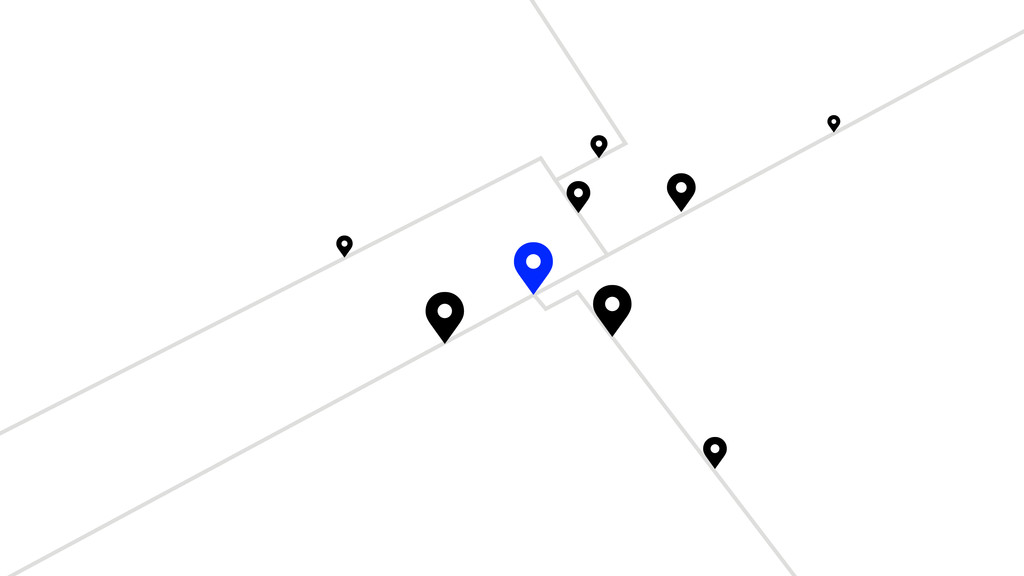
Given a point, find other points close to it. Nearest
neighbour search… 4
None
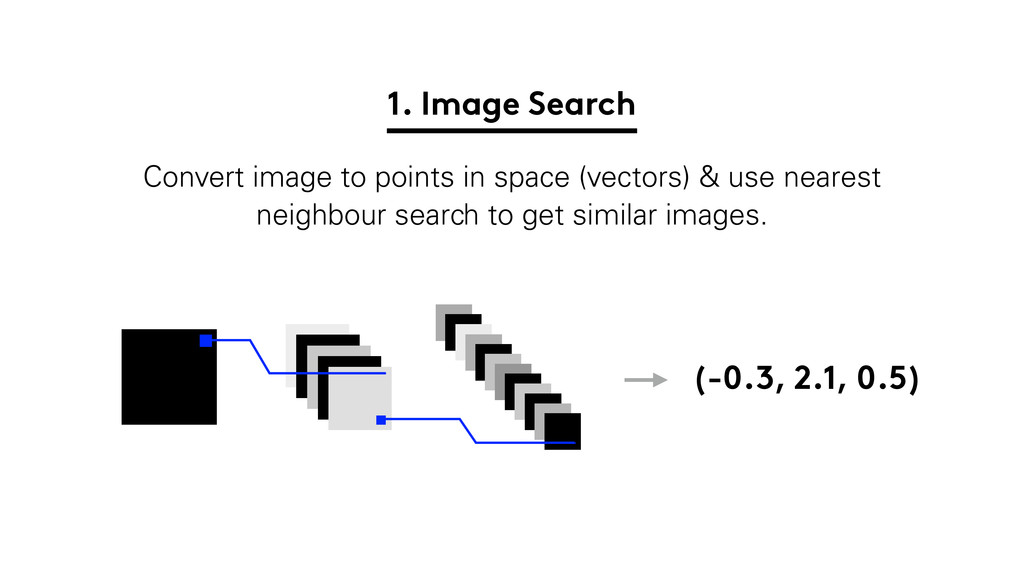
At Lyst we use it for… 1.) Image Search 2.)
Recommendations 6
Convert image to points in space (vectors) & use nearest
neighbour search to get similar images. 1. Image Search (-0.3, 2.1, 0.5)
Super useful for deduplication & search.
Convert products and users to points in space & use
nearest neighbour search to get related products for the user. 2. Recommendations user = (-0.3, 2.1, 0.5) product = (5.2, 0.3, -0.5)
Great, but…
11 80 million We have images
12 9 million We have products
Exhaustive nearest neighbour search is too slow.
Locality sensitive hashing to the rescue! Use a hash table.
Pick a hash function that puts similar points in the same bucket. Only search within the bucket.
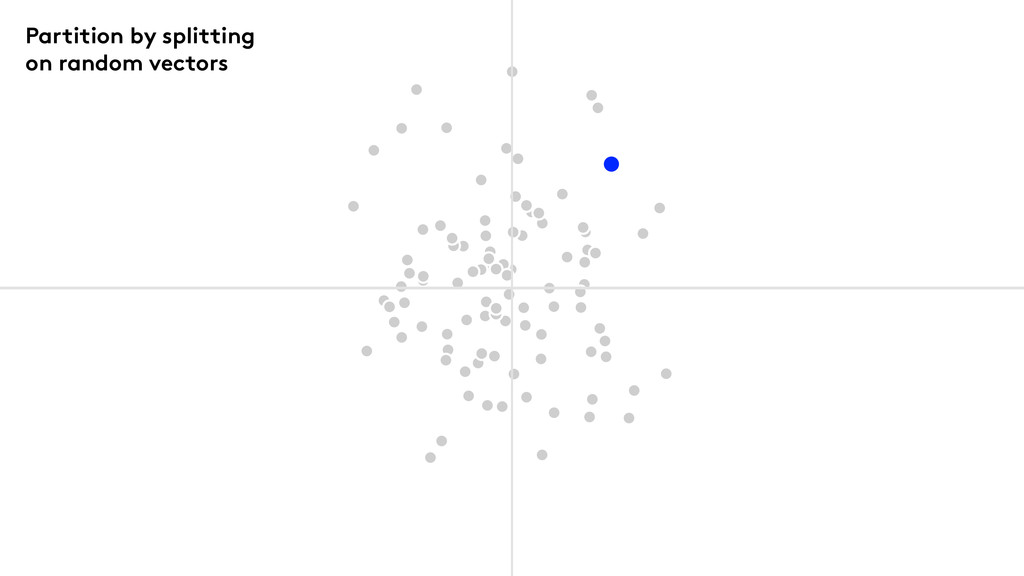
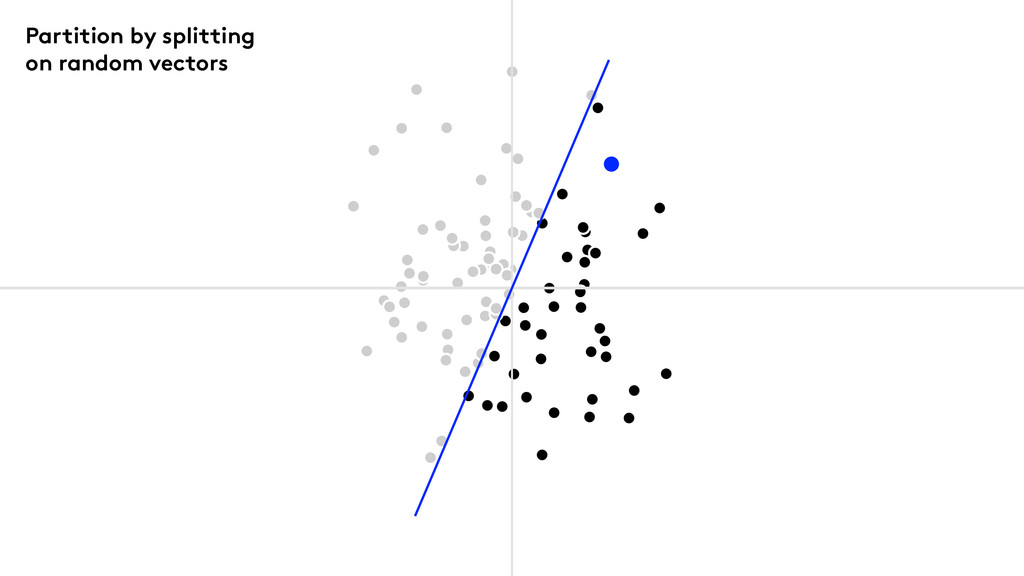
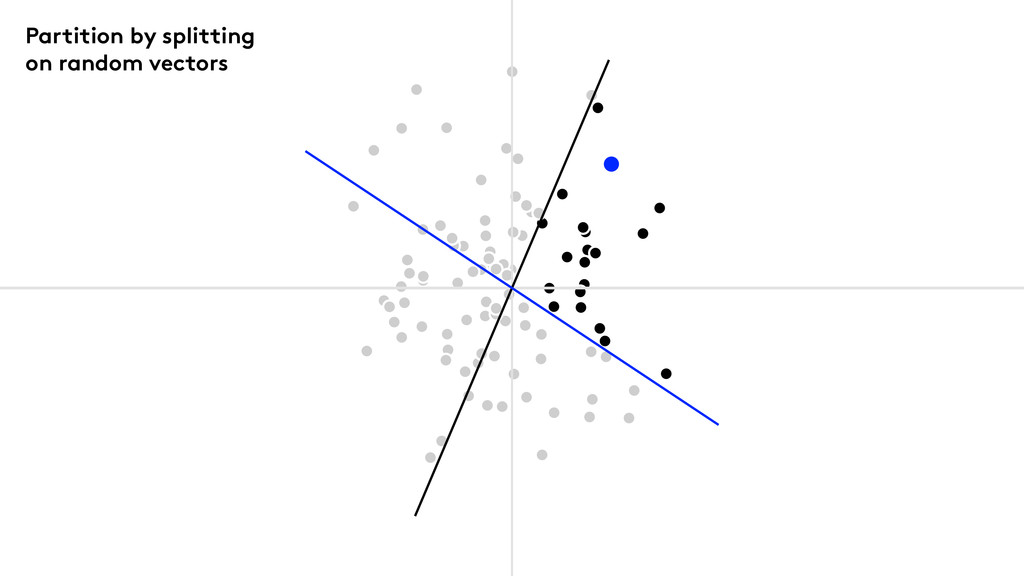
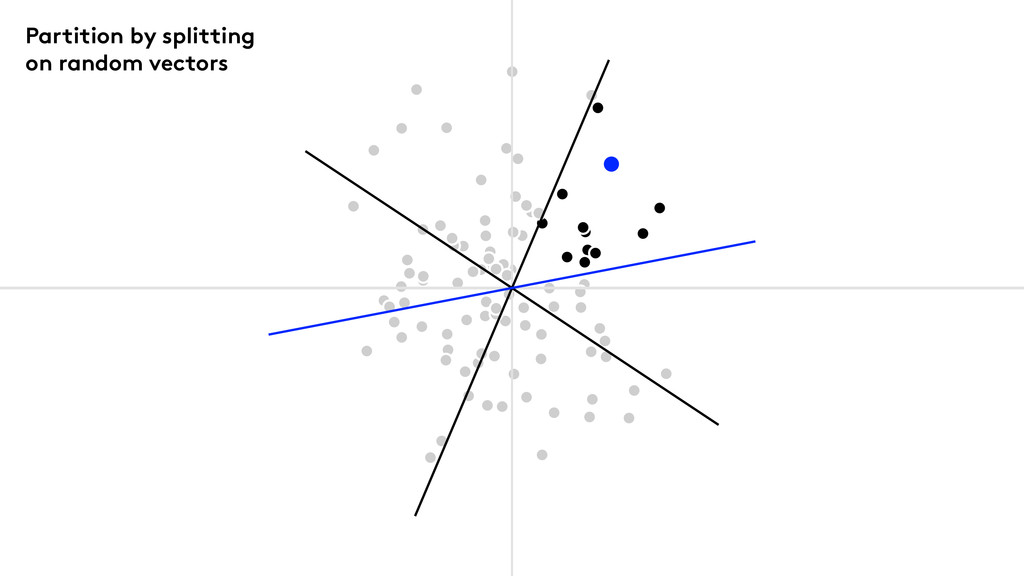
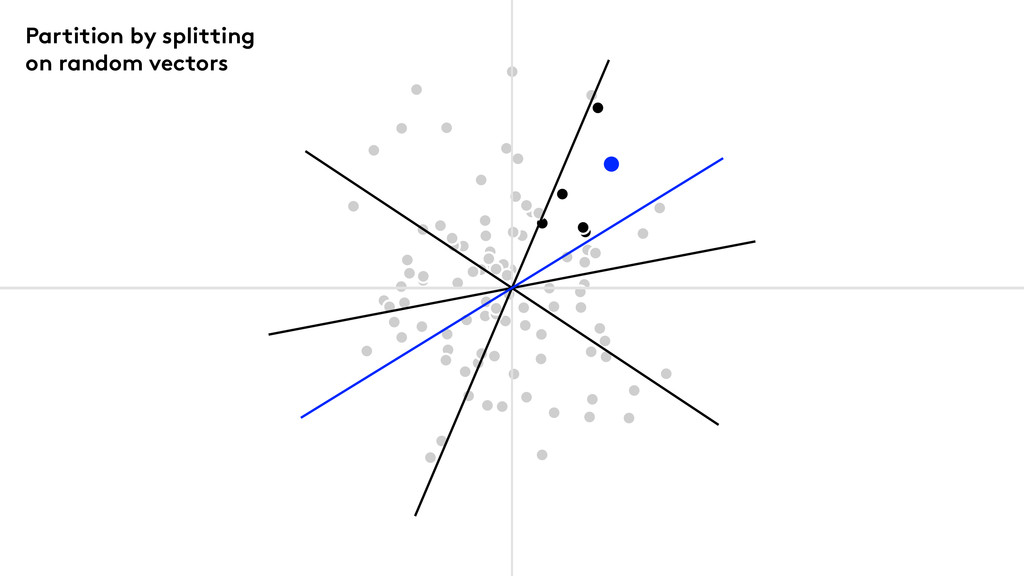
We use Random Projection Forests
Partition by splitting on random vectors
Partition by splitting on random vectors
Partition by splitting on random vectors
Partition by splitting on random vectors
Partition by splitting on random vectors
Points to note Keep splitting until the nodes are small
enough. Median splits give nicely balanced trees. Build a forest of trees.
Why do we need a forest? Some partitions split the
true neighbourhood of a point. Because partitions are random, other trees will not repeat the error. Build more trees to trade off query speed for precision.
LSH in Python annoy, Python wrapper for C++ code. LSHForest,
part of scikit-learn FLANN, an auto-tuning ANN index
But… LSHForest is slow. FLANN is a pain to deploy.
annoy is great, but can’t add points to an existing index.
So we wrote our own.
github.com/lyst/rpforest pip install rpforest
rpforest Quite fast. Allows adding new items to the index.
Does not require us to store points in memory.
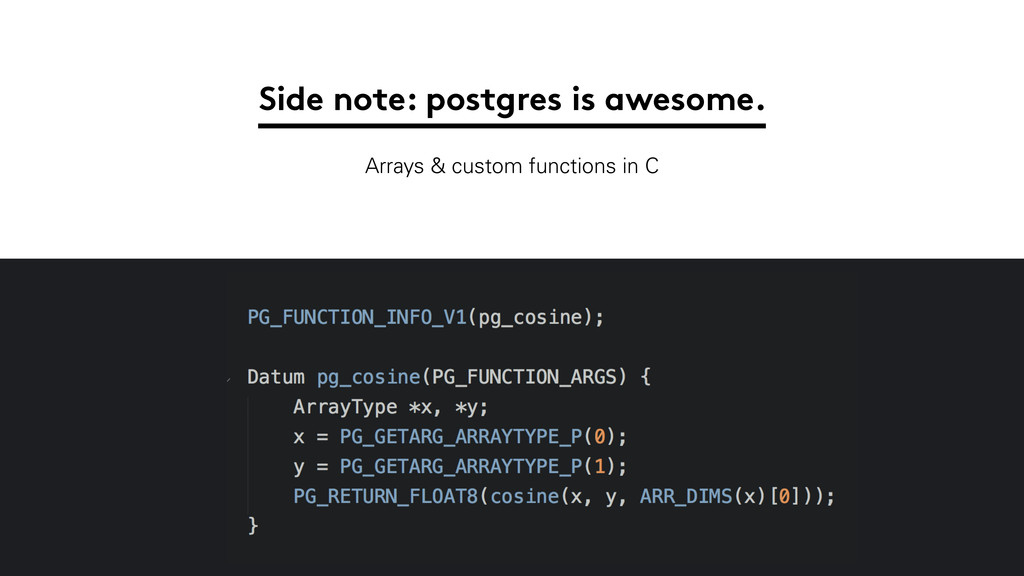
We use it in conjunction with PostgreSQL Send the query
point to the ANN index. Get ANN row ids back Plug them into postgres for filtering Final scoring done in postgres using C extensions.
Side note: postgres is awesome. Arrays & custom functions in
C
Gives us a fast and reliable ANN service 100x speed-up
with 0.6 10-NN precision Allows us to serve real-time results All on top of a real database.
thank you @maciej_kula
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}