representation for an item or a user is the elementwise sum of the representation of their features. • Predictions are given by the dot product of the user and item representations. 8 8
user features) user feature matrix 2. FI be the (no. items x no. item features) item feature matrix 3. EU be the (no. user features x latent dimensionality) user feature embedding matrix 4. EI be the (no. item features x latent dimensionality) item feature embedding matrix Then the user-item matrix can be expressed as FU EU (FI EI )T FU and FI are given and we estimate EU and EI .
(FU and FI are identity matrices), the model reduces to a traditional MF model. As we add metadata features,we gain the ability to make predictions for cold start items and users.
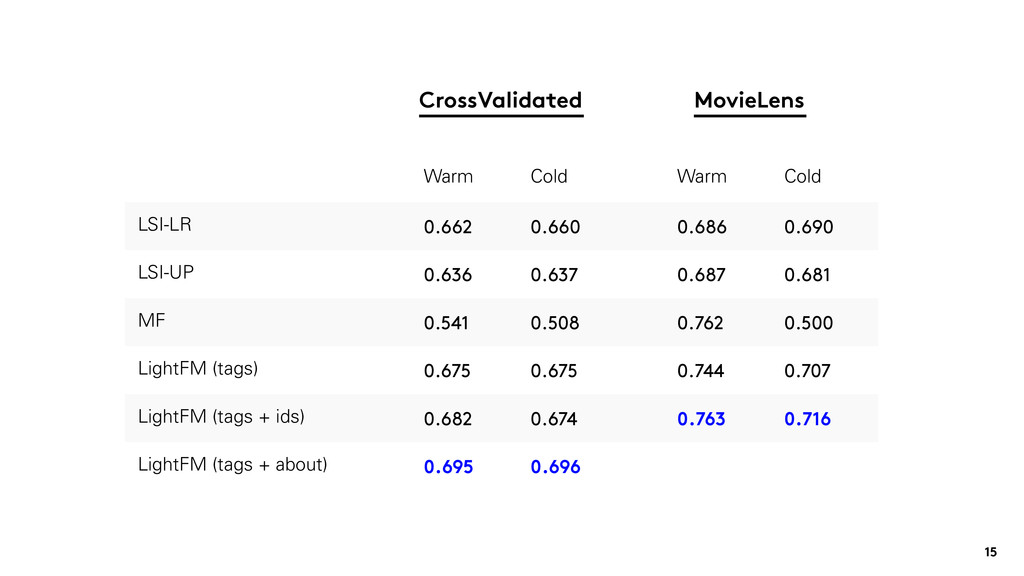
4 or higher are positives. • In the CrossValidated dataset, answered questions are positives and negatives are randomly sample unanswered questions. Two experiments: • warm-start: random 80%/20% split of all interactions. • cold-start: all interactions for 20% of items are moved to the test set. 12
model using per-user logistic regression models on top of principal components of the item metadata matrix. LSI-UP: a hybrid model that represents user profiles as linear combinations of items' content vectors, then applies LSI to the resulting matrix to obtain latent user and item representations. Baselines
standard MF in the warm-start setting. It outperforms the content-based baselines in the cold-start setting. We can have a single model that performs well across the data sparsity spectrum.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}