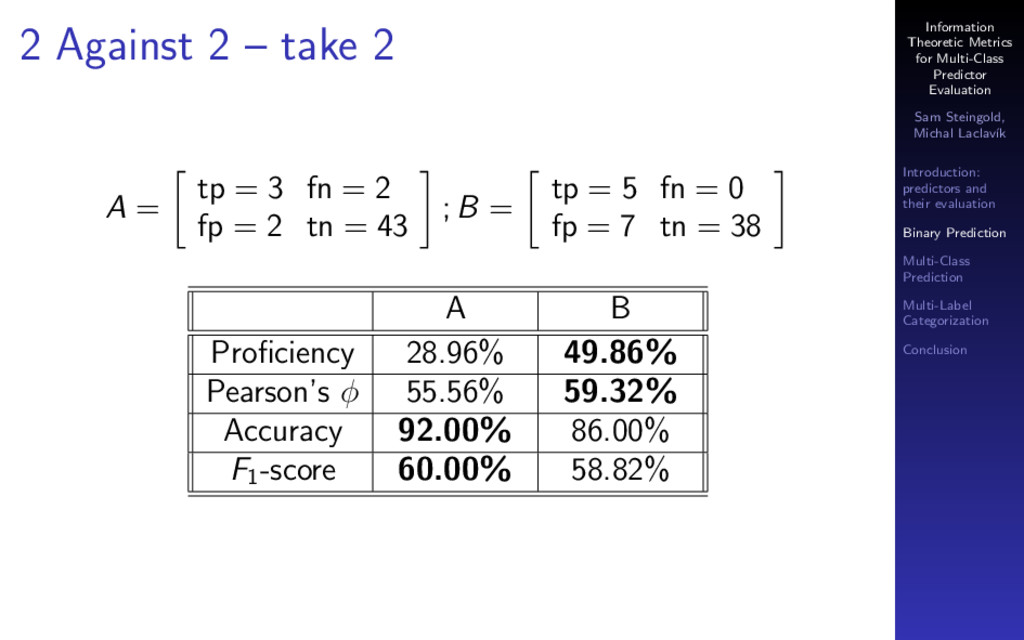
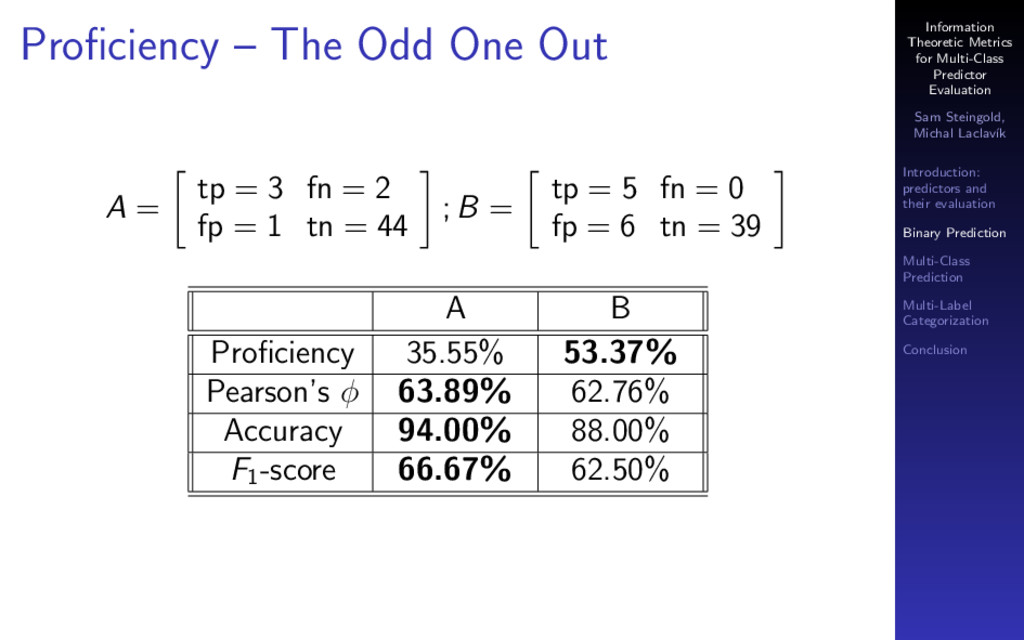
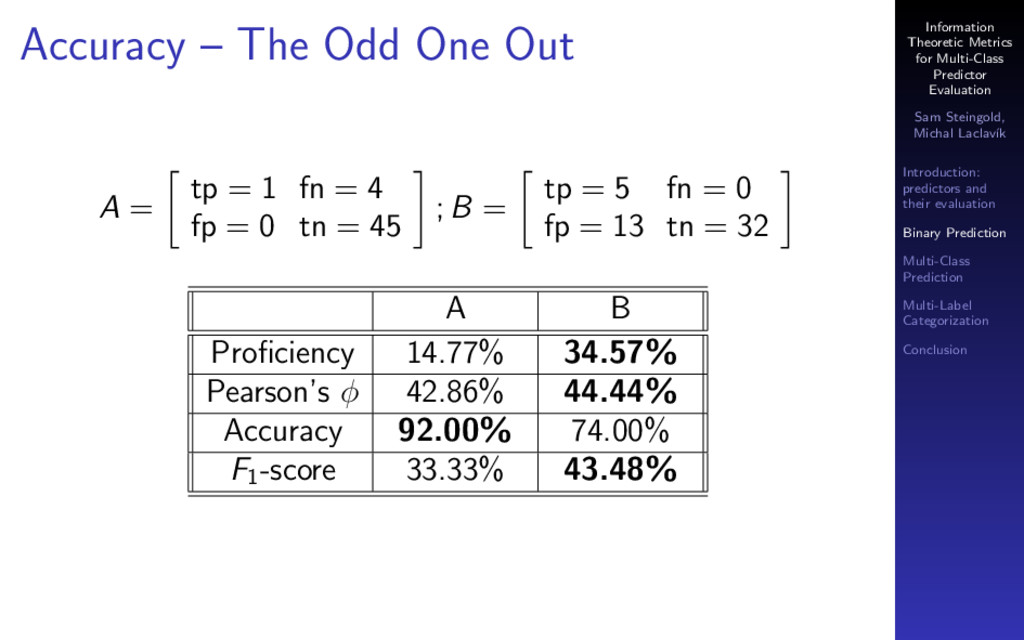
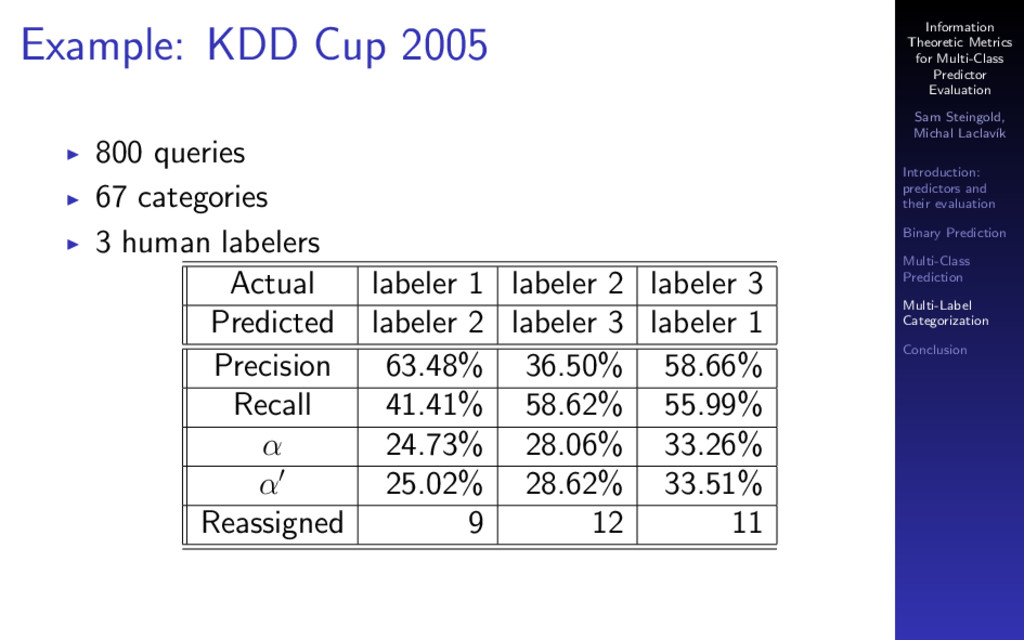
The most common metrics used to evaluate a classifier are accuracy, precision, recall and F1 score. These metrics are widely used in machine learning, information retrieval, and text analysis (e.g., text categorization). Each of these metrics is imperfect in some way (captures only one aspect of predictor performance and can be fooled by a weird data set). None of them can be used to compare predictors across different datasets.
by Sam Steingold
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
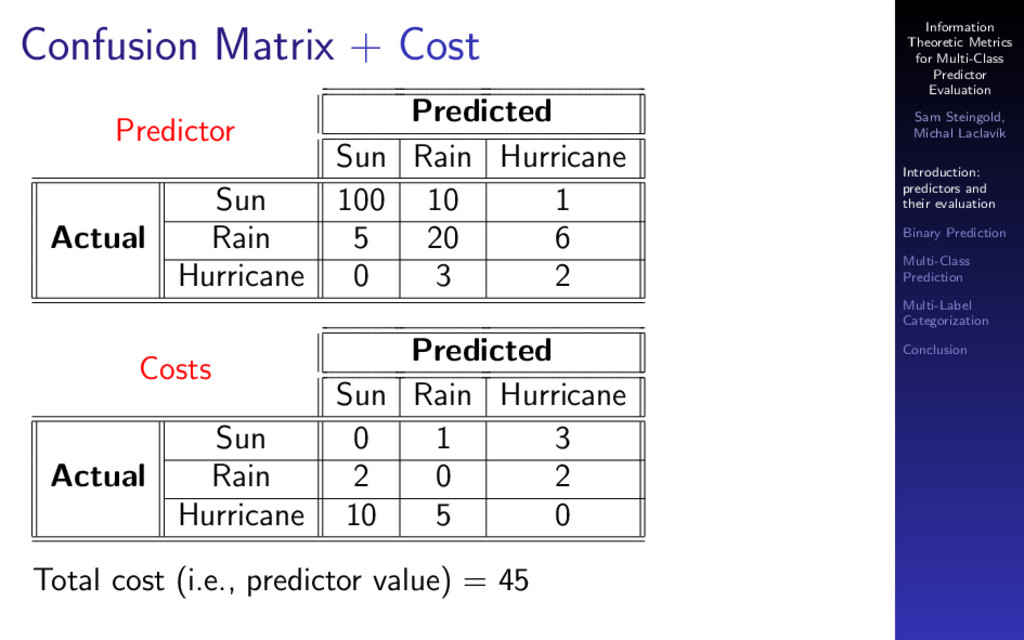{kind=link}
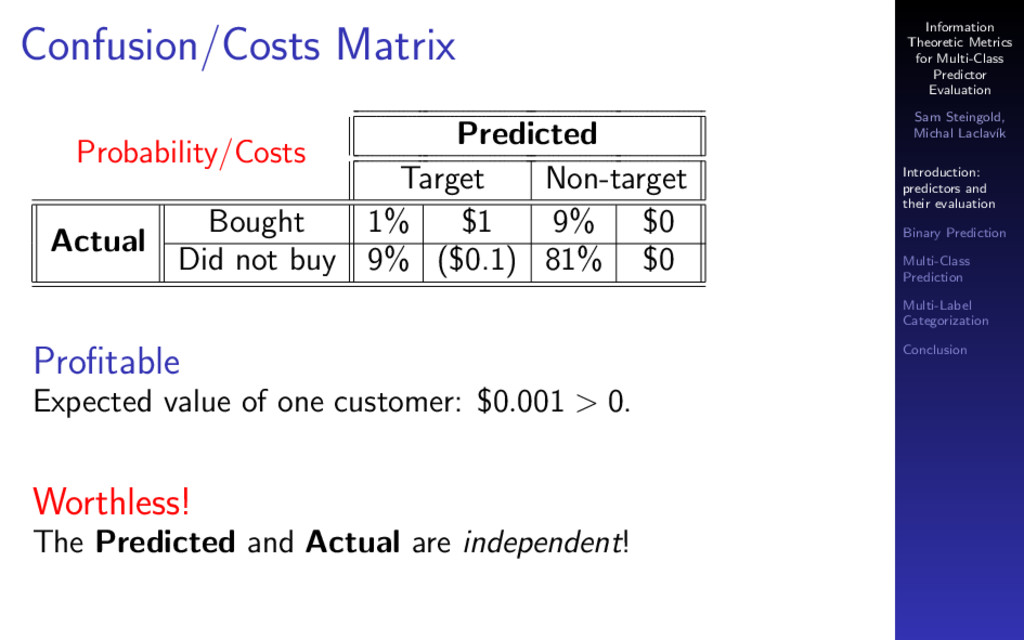{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
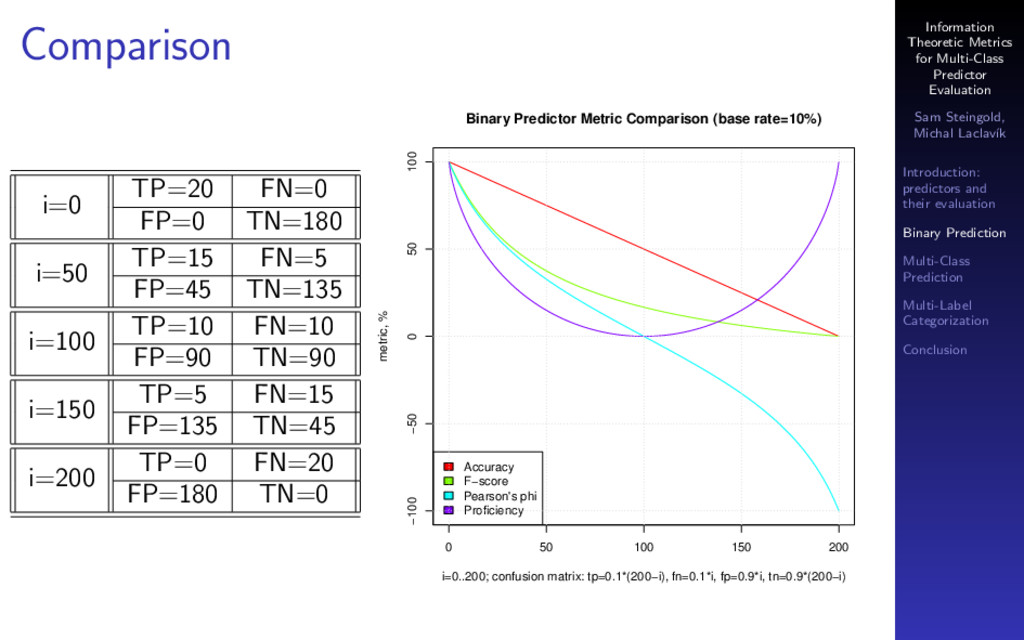{kind=link}
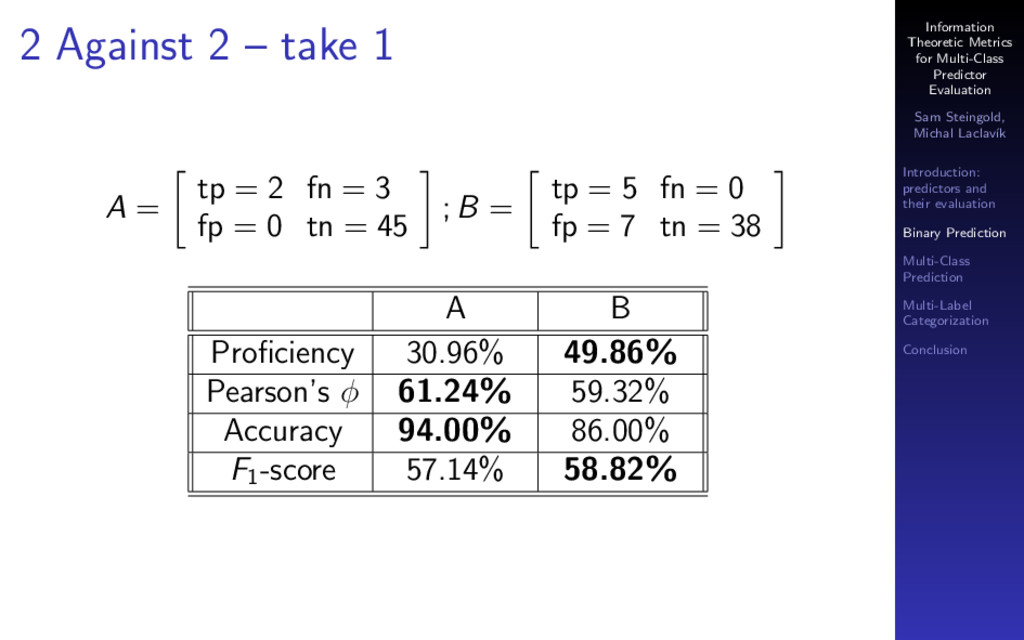{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}