A session given at OpenStack Israel 2014 with some thoughts about what you should still look at if you are interested in deploying OpenStack as an Enterprise solution,
This is not an OpenStack Bashing session I really like OpenStack This is supposed to be an eye-opener And have I said I really like OpenStack? Disclaimer
• How do I keep my Management stack running smoothly? • How do I upgrade? • Rapid release cycles (every 6 months) • No Downtime during upgrades • Support
The bible (Introduction to OpenStack High Availability) The manual process is not simple Automation tools alleviate this (partially) HA is not the same for all components Active/Active Active/Passive There is no single best way to do it OpenStack HA
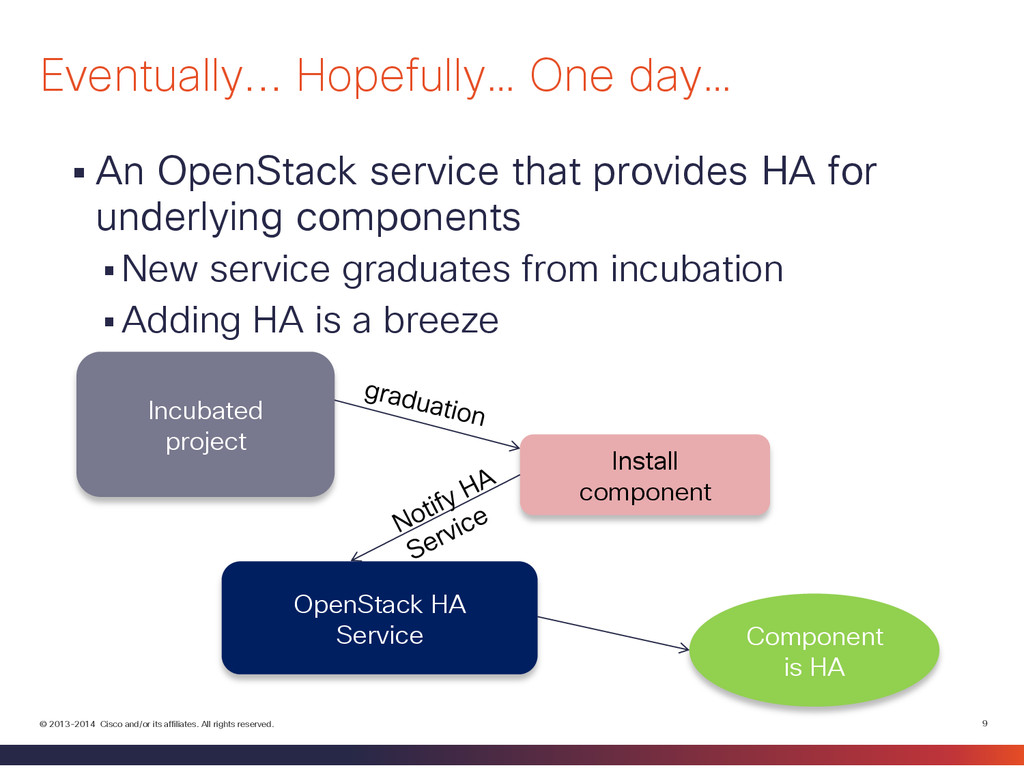
An OpenStack service that provides HA for underlying components New service graduates from incubation Adding HA is a breeze Eventually... Hopefully… One day… Incubated project Install component OpenStack HA Service Component is HA
Not a smooth process It is getting better (Nova improvements in Icehouse) Not always backward compatible Upgrade paths between older versions don’t always work It is not uncommon to see people running: Cactus, Diablo, Essex, Folsom, Grizzly, Icehouse All in one datacenter. Ready for an upgrade?
Patches are provided for 2 previous releases Perhaps an LTS version in the future? (Redhat are already going in that direction) Introduction of a new release Testing Deployment plan Implementation Stabilize Release Cycles and Why We Are Chasing Our Tails? And there is a new version every 6 months
Enterprises – want Enterprise support Not everyone can provide the support themselves If your environment crashed – you will want someone on the line Yesterday!! Who do I release my wrath upon?
Backup The management cluster should be relatively simple to rebuild – with automation Tenants and their workloads Is this an issue? Replication Not something that can be easily provided today (There are things in the works) DR Nothing today. Services provided by you today.
Monitoring Ceilometer How do I get the relevant information out of it. Not everything is being measured Volume metrics Cumulative uptime Services provided by you today.
General rules for loglevels: Critical: Shit's on fire, yo. Expected, known issue where things will break and bad. Error: Standard unexpected error trap - final, top-level error trap should dump the message to ERROR. Also, known error cases that someone should handle that aren't necessarily "the world is exploding" Warn: expected error conditions that might be an issue, but not huge problems. Example at session: Glance's error at startup that it can't find a storage device ID (which is currently error, should be warn) Info: Standard operational logging: VM request received, scheduled to launch on hypervisor X Debug: What's going on under the hood. So you can trace down origins of errors - shouldn't have to be on by default Trace: Super debug. Method-level logging, or some otherwise extra-detailed info like slightly sanitized api conversations Logging as an example
Auditing & Compliance Who did what And when “detecting the tenants who added "allow all" rules to essentially turn off security groups” Can this workload run in this cluster? If not – then what? Shut it down? Move to correct location? Notify the president????? Services provided by you today.
• There are several gaps that need to be addressed • Great work is being done - there is still more to accomplish • It is all a question of how much you are willing to be flexible? How much responsibility you are willing to take upon yourself? • Not everything should (or can) run in OpenStack
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}