{ volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; int prio, static_prio, normal_prio; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; struct sched_dl_entity dl; pid_t pid; pid_t tgid; struct timespec start_time; /* monotonic time */ struct timespec real_start_time; /* boot based time */ struct css_set __rcu *cgroups; … int pdeath_signal; /* The signal sent when the parent dies */ unsigned int jobctl; /* JOBCTL_*, siglock protected */ /* ??? */ unsigned int personality; unsigned did_exec:1; unsigned in_execve:1; /* Tell the LSMs that the process is doing an * execve */
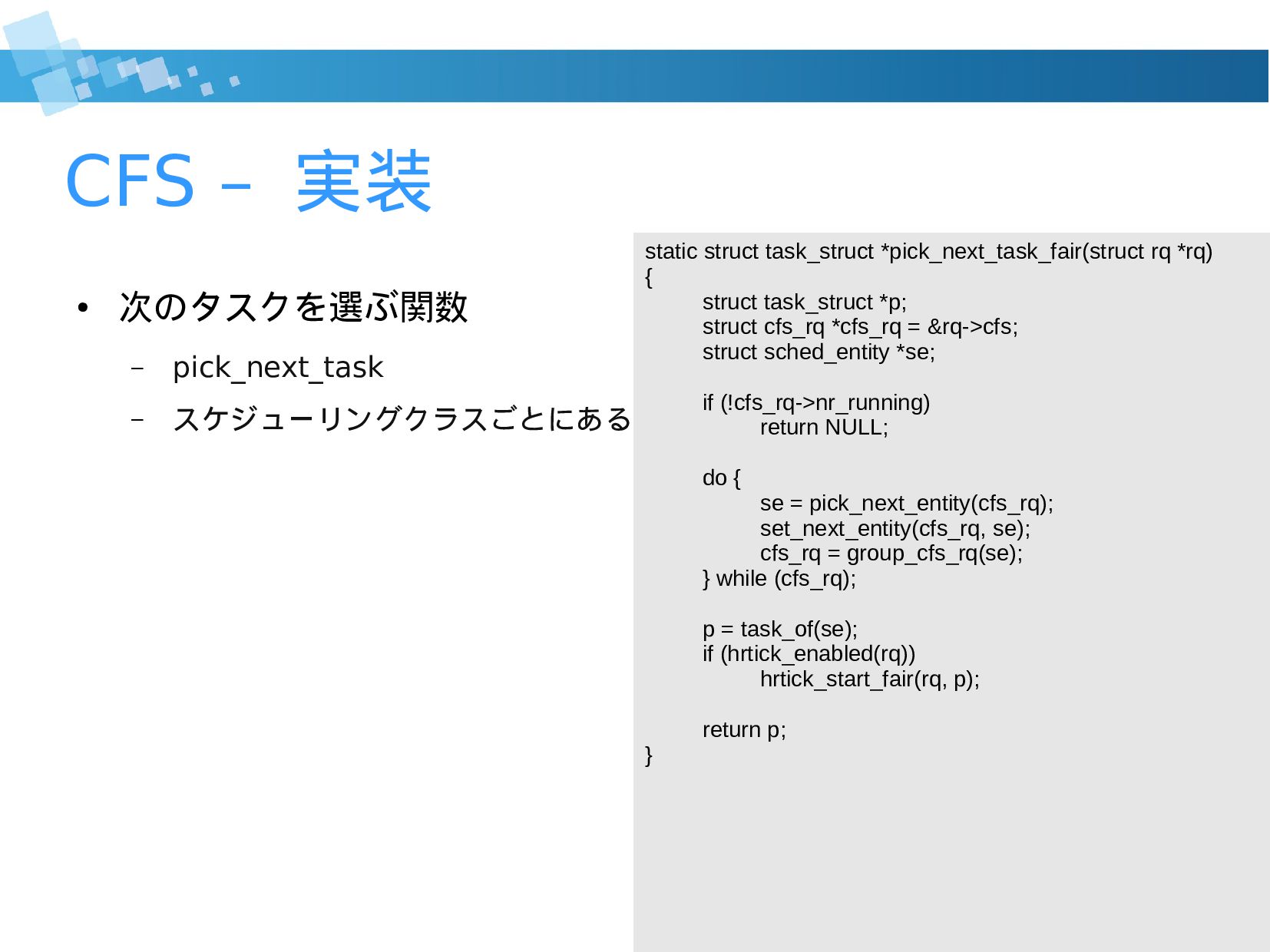
schedule() を呼ぶと次のタス クを選ぶ static inline struct task_struct * pick_next_task(struct rq *rq) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ if (likely(rq->nr_running == rq->cfs.h_nr_running)) { p = fair_sched_class.pick_next_task(rq); if (likely(p)) return p; } for_each_class(class) { p = class->pick_next_task(rq); if (p) return p; } BUG(); /* the idle class will always have a runnable task */ }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
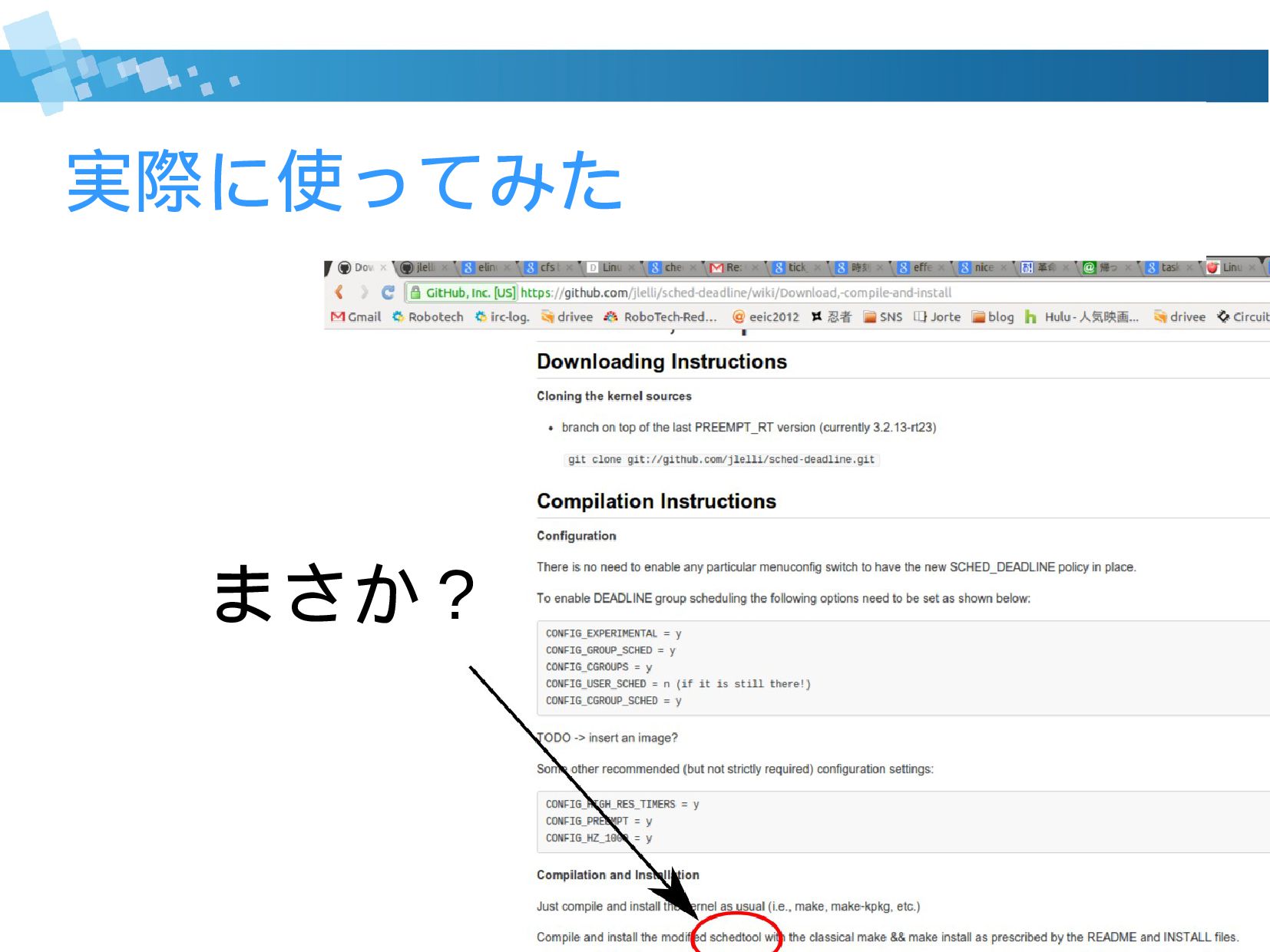{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
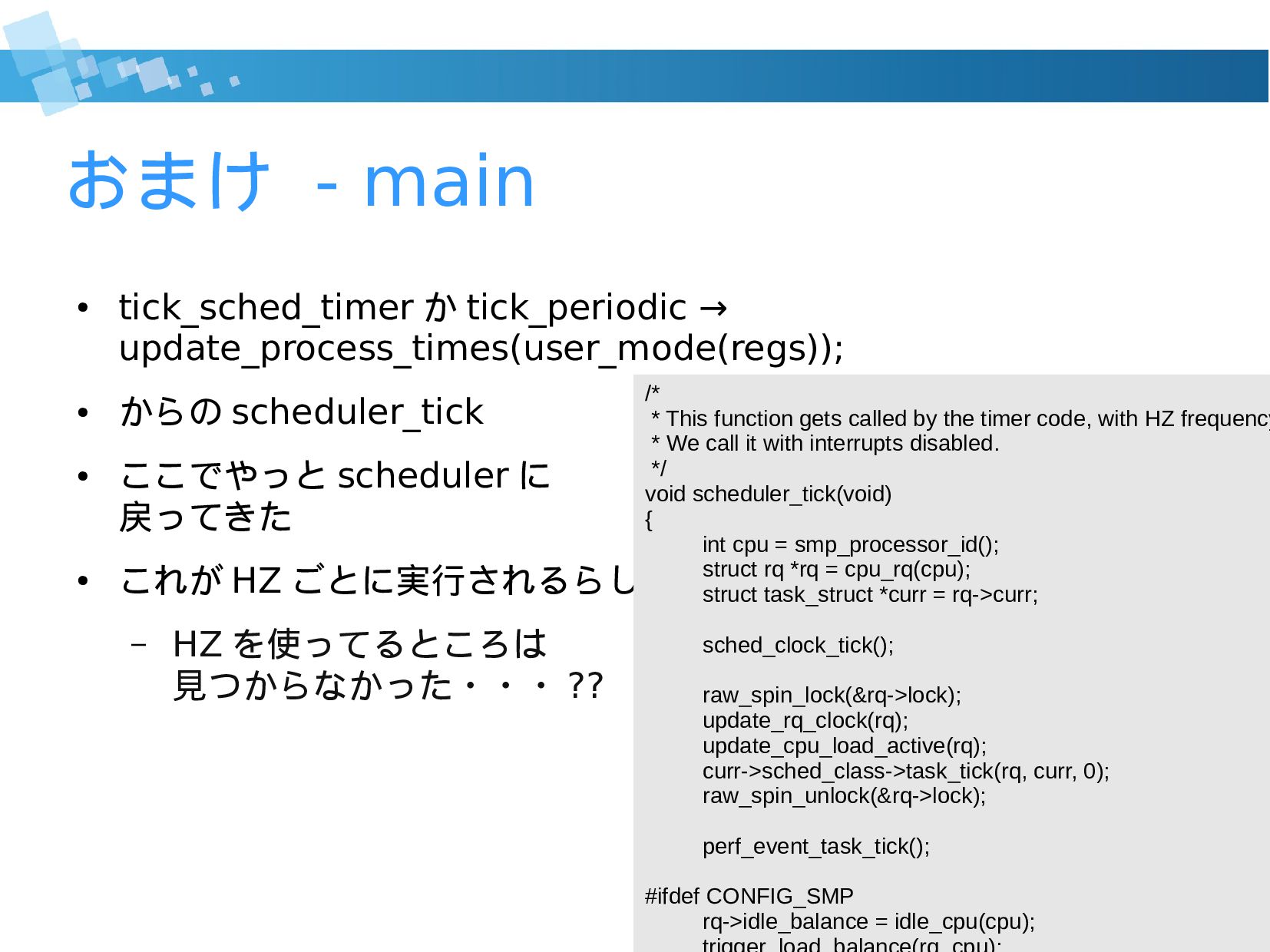{kind=link}
{kind=link}
{kind=link}