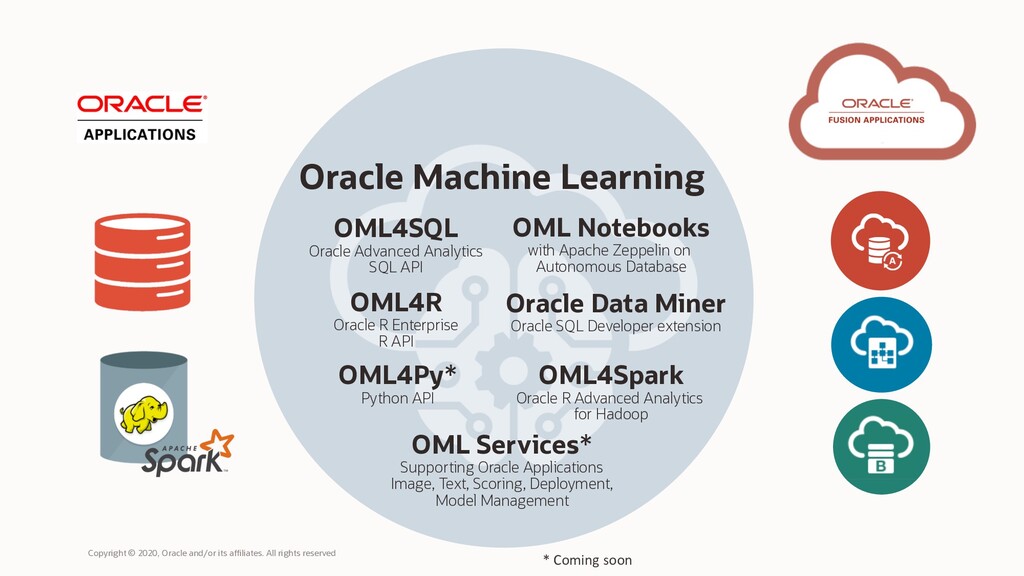
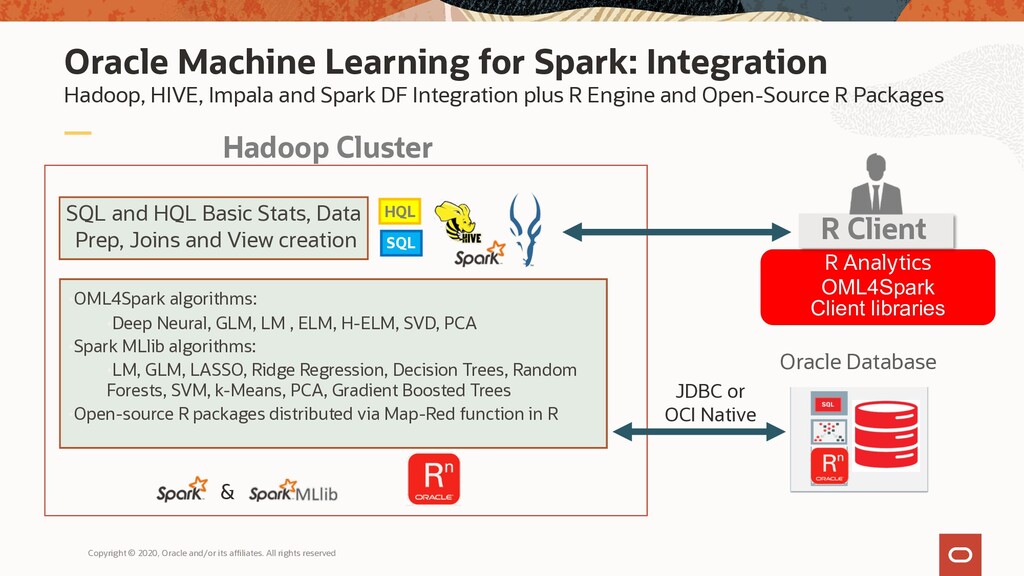
Oracle Machine Learning for Spark offers interfaces to run Machine Learning algorithms on top of Data Lakes, using Spark to distribute computation across Nodes, and brings integration with the Big Data ecosystem that allows for manipulation tables in HIVE and Impala, as well as integration with HDFS and the Oracle Database, using the R language as front-end.
It makes the open source R scripting language and environment ready for the enterprise and big data. Designed for problems involving both large and small volumes of data, Oracle Machine Learning for Spark integrates R with Data Lakes, allowing users to execute R commands and scripts for data processing, statistical and machine learning analytics on HIVE, IMPALA, Spark DataFrame tables and views using R and Spark SQL syntax. Many familiar R functions are overloaded and translate R functions into SQL for in-Data Lake execution.
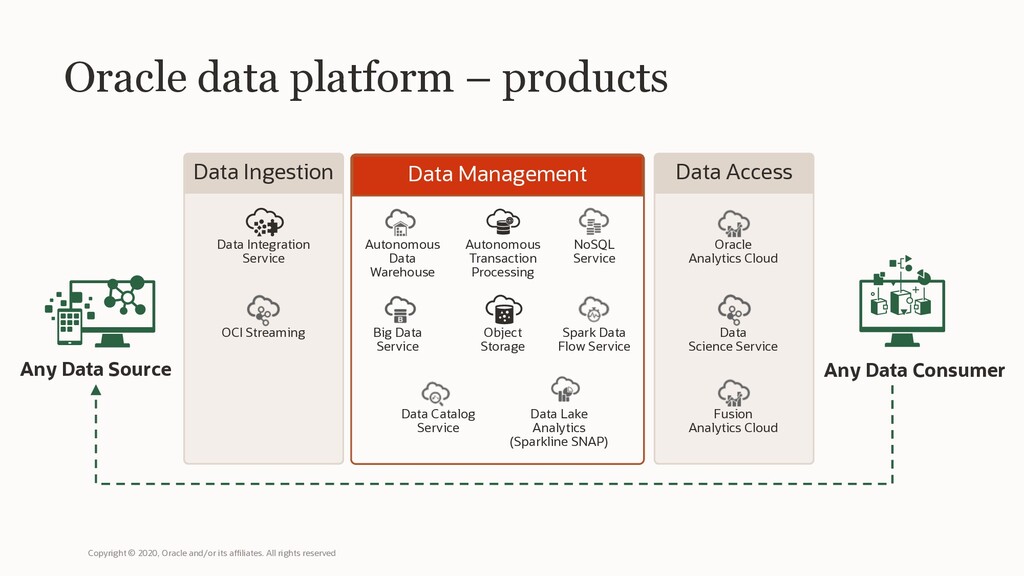
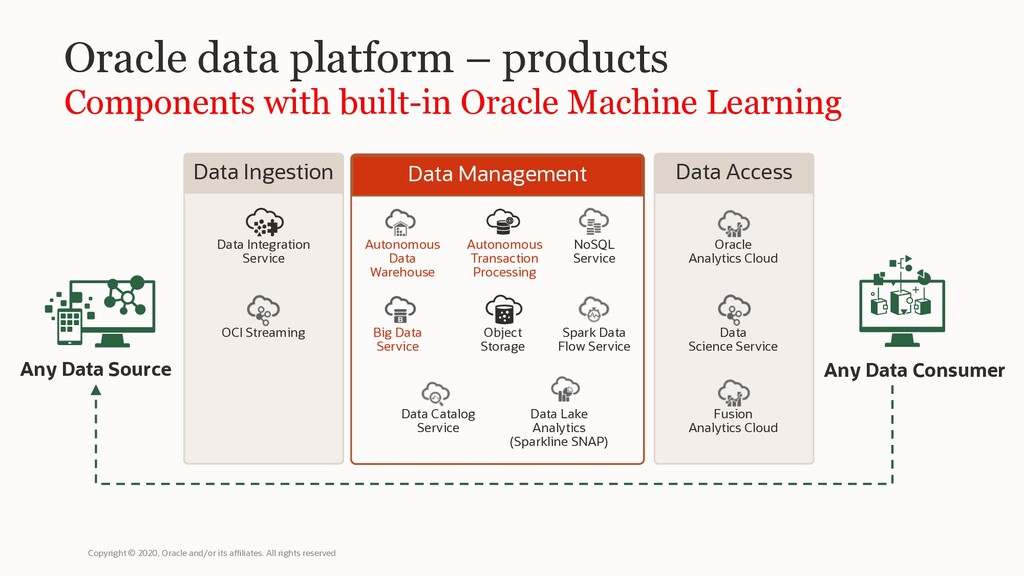
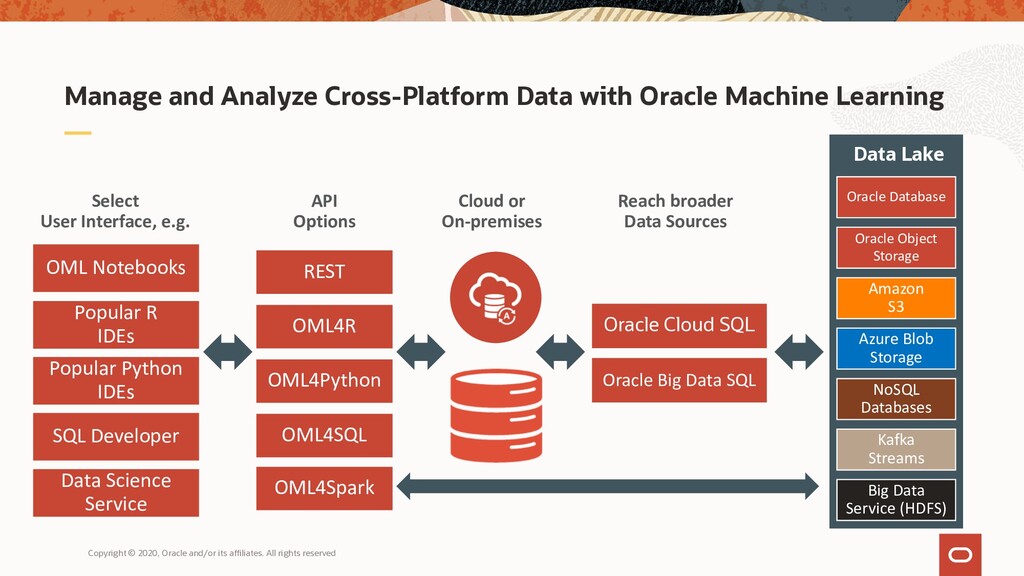
Oracle Machine Learning consists of complementary components supporting scalable machine learning algorithms for in-database and big data environments (including Cloud and on-premises), notebook technology, SQL, Python and R APIs, and Hadoop/Spark environments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
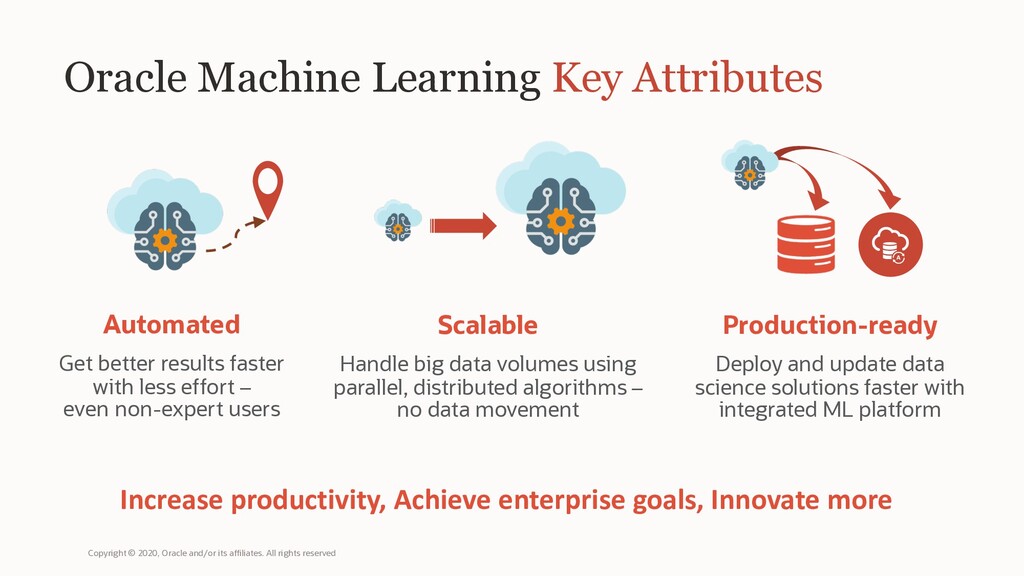{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}