encontradas na abordagem comumente empregada para SegInfo. • Auditar, ou seja, realizar análise crí.ca sobre a eficiência e eficácia das tecnologias e processos de SegInfo convencionais. • Compar.lhar conhecimento e experiência sobre como melhorar o processo de SegInfo como um todo, e não somente apontar os problemas. Metodologia • Explanações teóricas. • Demonstrações prá.cas (cenários e ferramentas).
l Mo.vação l Teorias e prá.cas convencionais de SegInfo l Analisando a SegInfo convencional l Auditando as falhas l Parte II – Encontrando soluções l Premissas para uma abordagem diferenciada de SegInfo l SegInfo baseada em Resposta a Incidentes
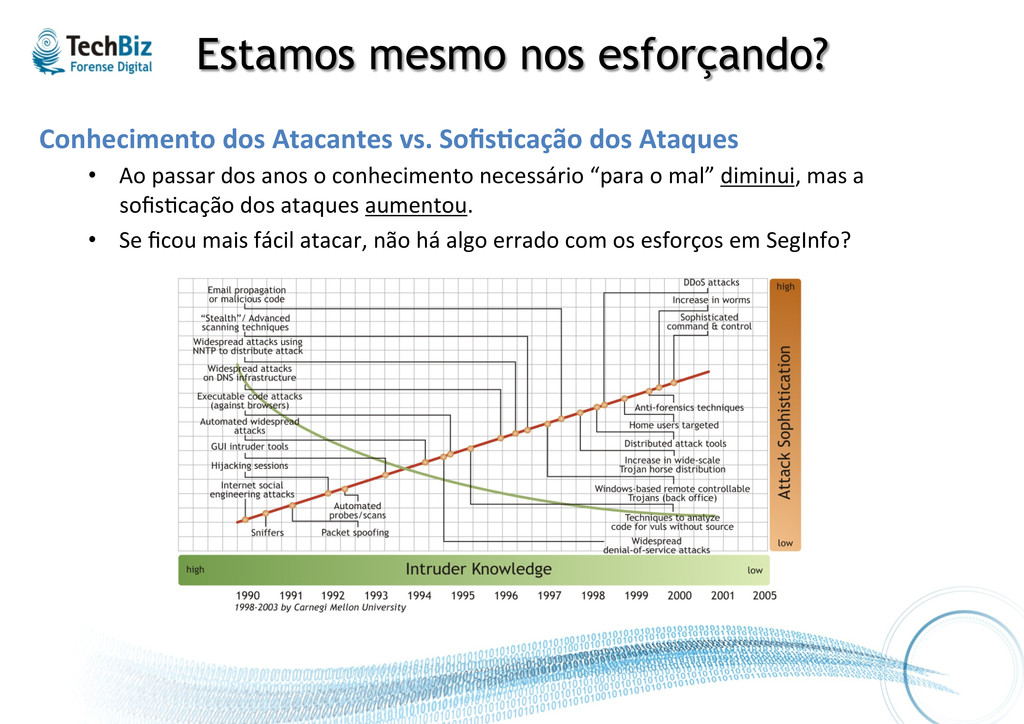
Ataques • Ao passar dos anos o conhecimento necessário “para o mal” diminui, mas a sofis.cação dos ataques aumentou. • Se ficou mais fácil atacar, não há algo errado com os esforços em SegInfo?
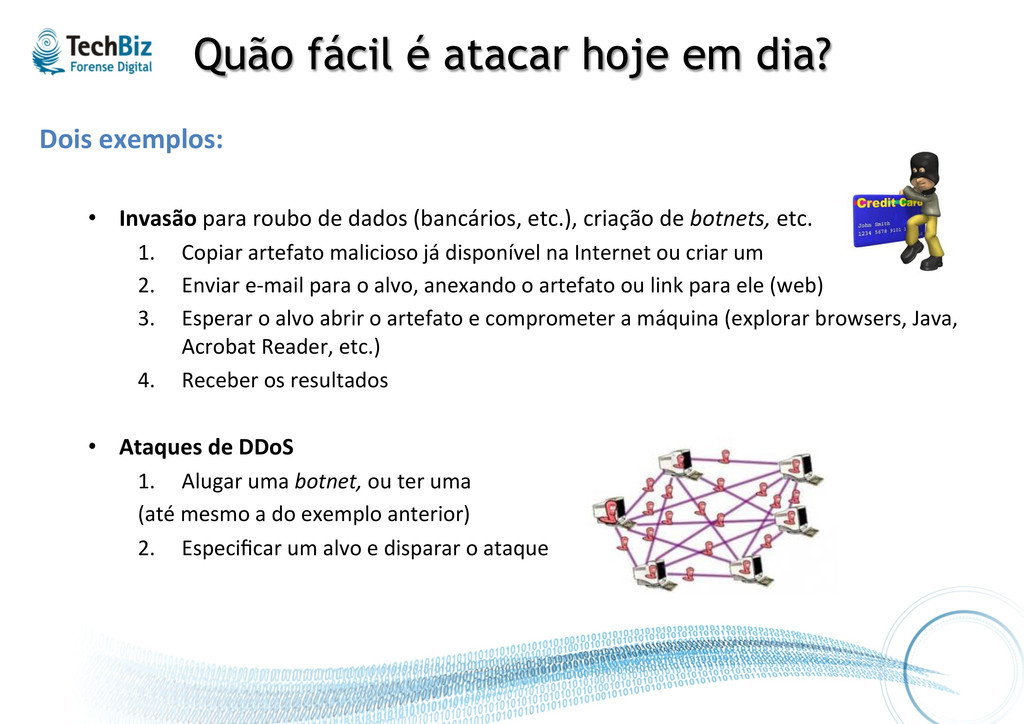
• Invasão para roubo de dados (bancários, etc.), criação de botnets, etc. 1. Copiar artefato malicioso já disponível na Internet ou criar um 2. Enviar e-‐mail para o alvo, anexando o artefato ou link para ele (web) 3. Esperar o alvo abrir o artefato e comprometer a máquina (explorar browsers, Java, Acrobat Reader, etc.) 4. Receber os resultados • Ataques de DDoS 1. Alugar uma botnet, ou ter uma (até mesmo a do exemplo anterior) 2. Especificar um alvo e disparar o ataque
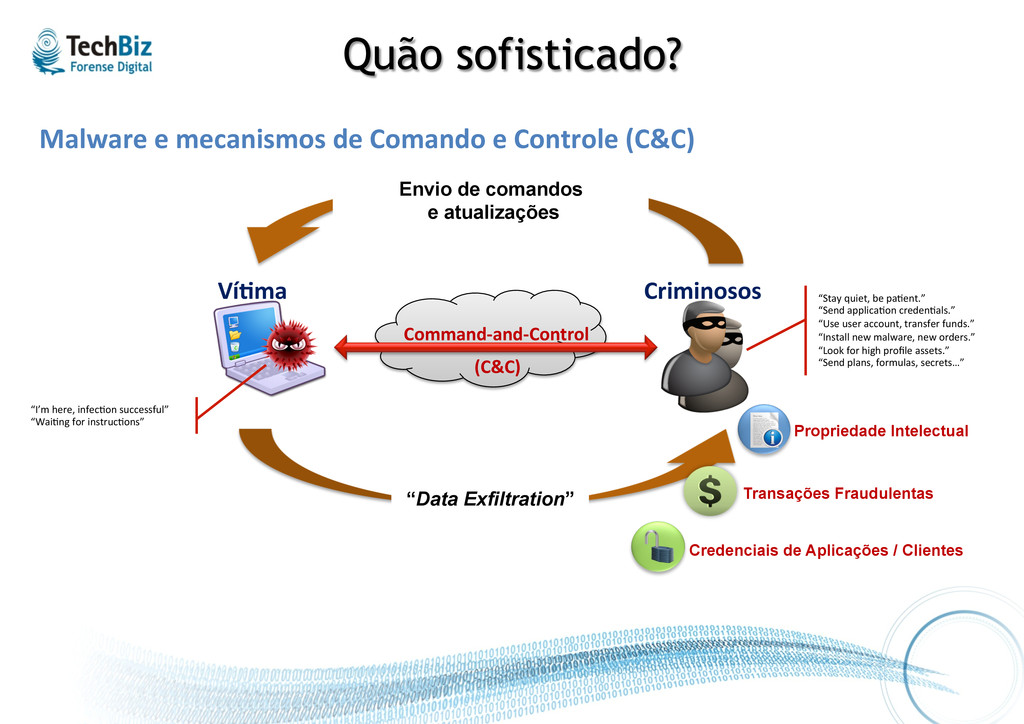
Ví%ma Criminosos Envio de comandos e atualizações “Data Exfiltration” “I’m here, infec.on successful” “Wai.ng for instruc.ons” “Stay quiet, be pa.ent.” “Send applica.on creden.als.” “Use user account, transfer funds.” “Install new malware, new orders.” “Look for high profile assets.” “Send plans, formulas, secrets…” Command-‐and-‐Control (C&C) Transações Fraudulentas Propriedade Intelectual Credenciais de Aplicações / Clientes
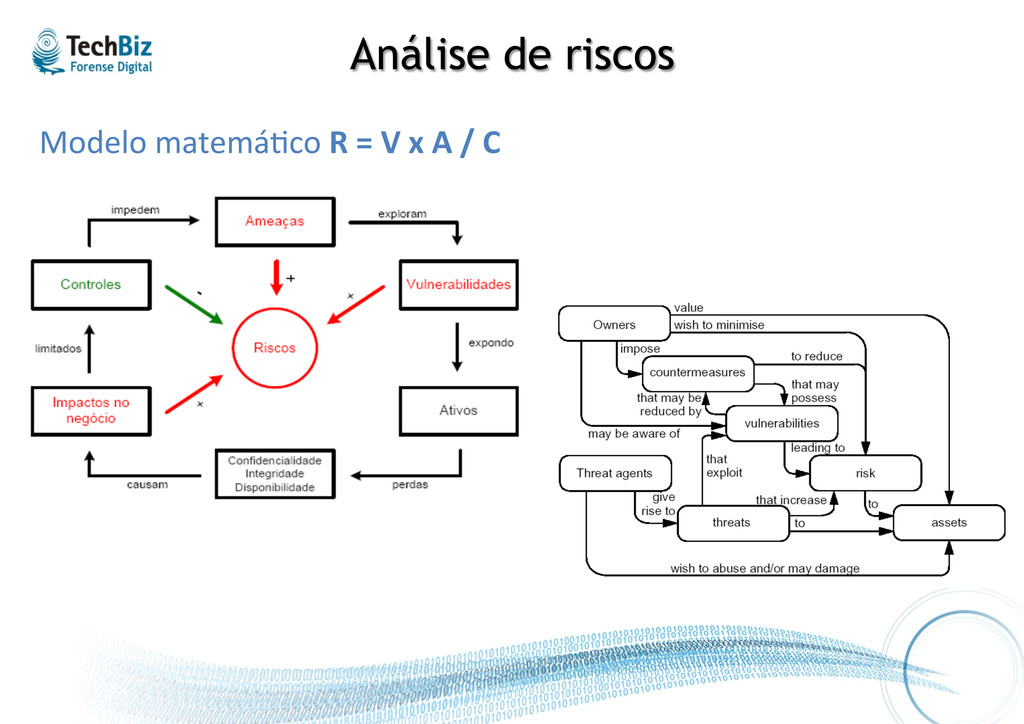
Proteger a%vos de informação contra ameaças que possam afetar a sua: • Confidencialidade: apenas usuários autorizados podem ter acesso à informação • Integridade: informação deve ser man.da no estado deixado pela úl.ma operação válida e autorizada • Disponibilidade: informação deve estar acessível aos usuários autorizadas no momento em que for necessária
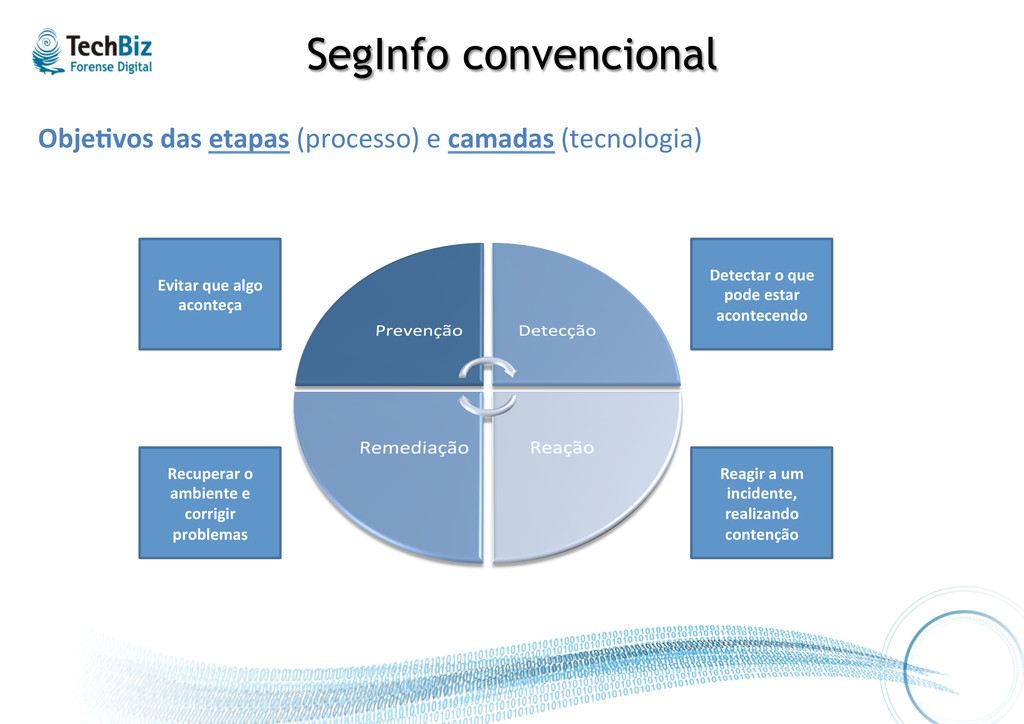
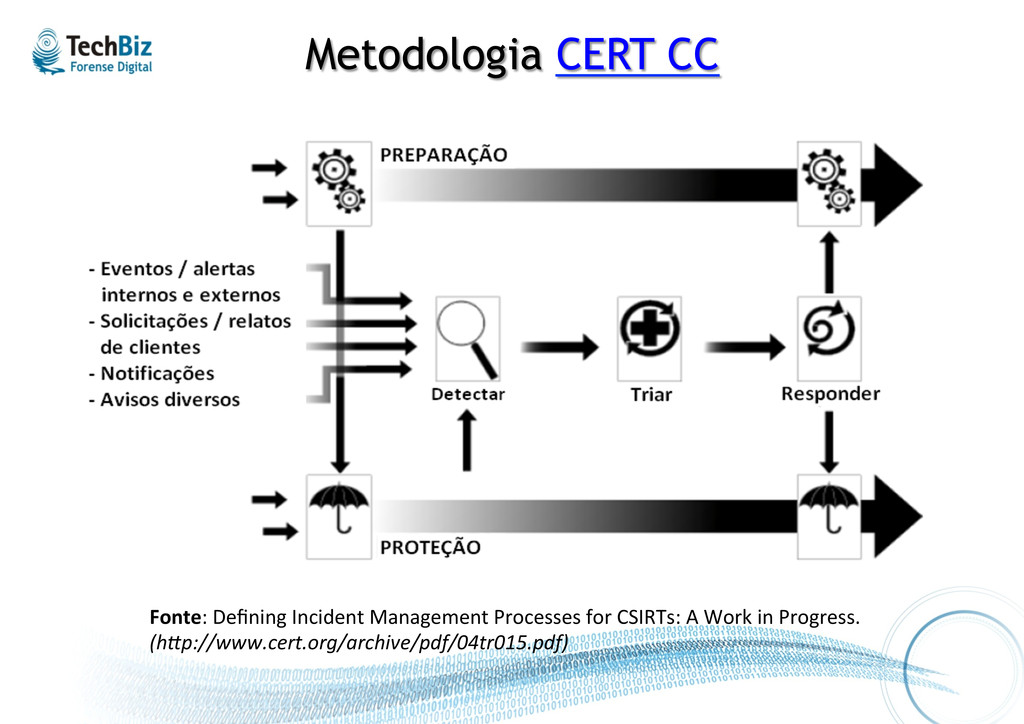
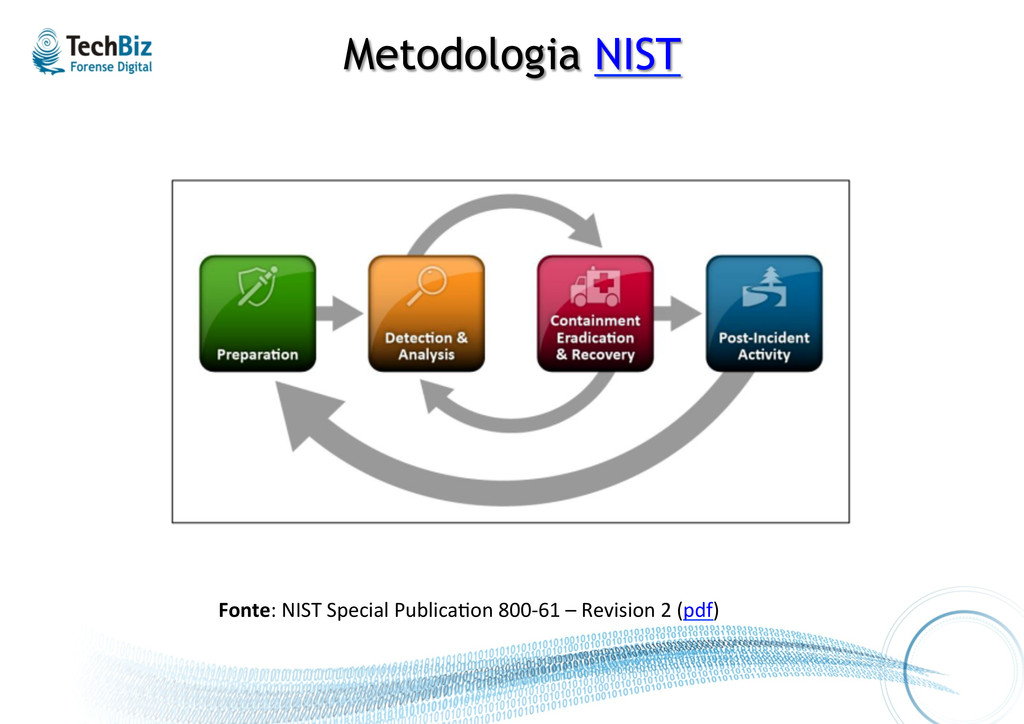
que pode estar acontecendo Reagir a um incidente, realizando contenção Recuperar o ambiente e corrigir problemas Obje%vos das etapas (processo) e camadas (tecnologia)
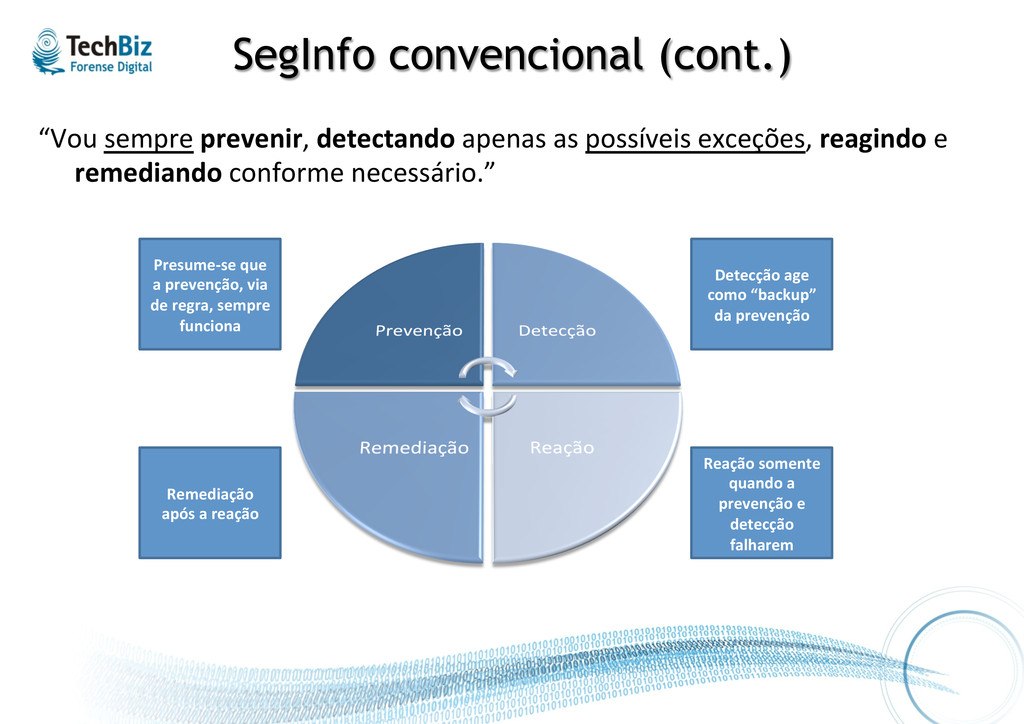
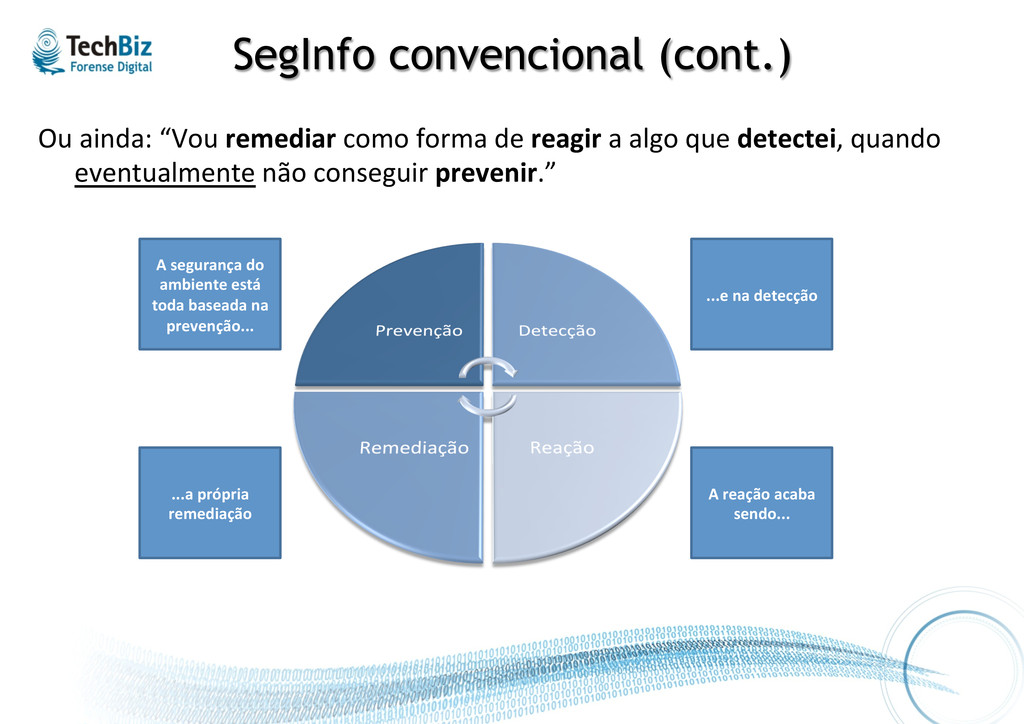
exceções, reagindo e remediando conforme necessário.” Presume-‐se que a prevenção, via de regra, sempre funciona Detecção age como “backup” da prevenção Reação somente quando a prevenção e detecção falharem Remediação após a reação
reagir a algo que detectei, quando eventualmente não conseguir prevenir.” A segurança do ambiente está toda baseada na prevenção... ...e na detecção A reação acaba sendo... ...a própria remediação
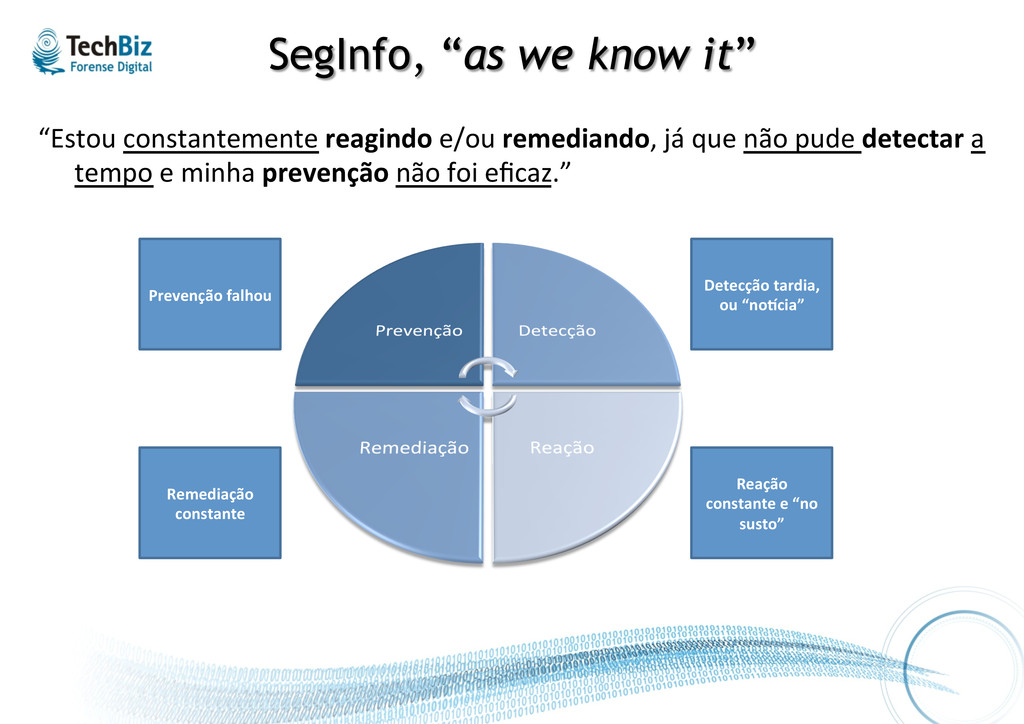
já que não pude detectar a tempo e minha prevenção não foi eficaz.” Prevenção falhou Detecção tardia, ou “noZcia” Reação constante e “no susto” Remediação constante
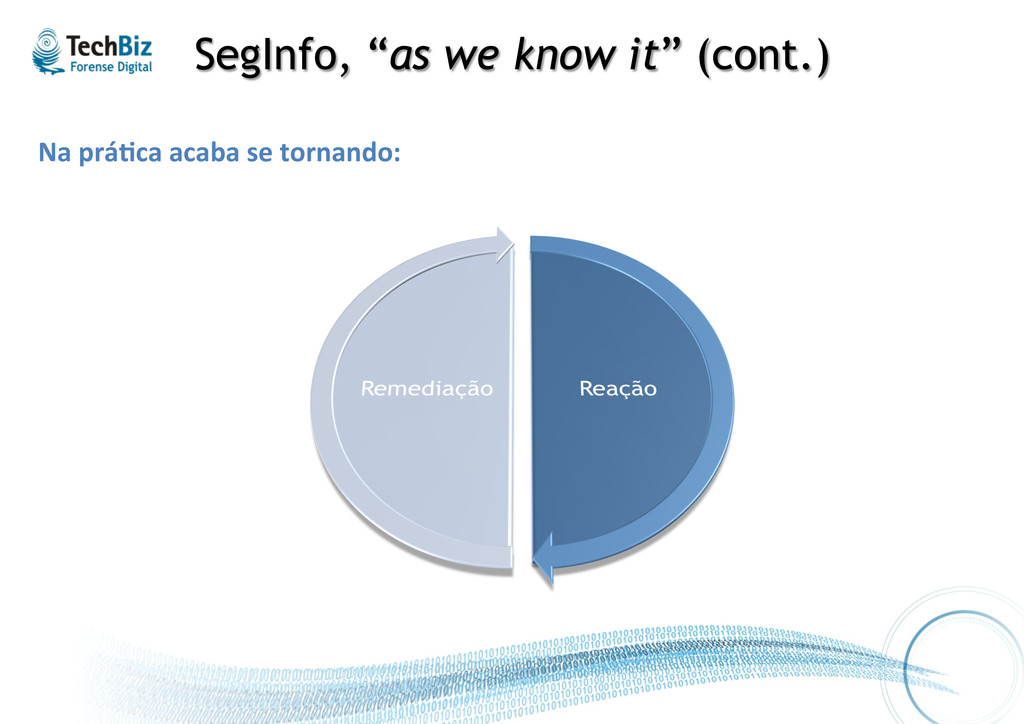
SegInfo: • Prevenção não é 100% efe.va, logo não funciona como deveria. • Basta uma “possível exceção” ter sucesso para toda abordagem falhar. • Reação muitas vezes desfavorecida, pois a organização prioriza a prevenção. • Remediação constante, também muitas vezes ineficaz. • Cria-‐se a “falsa sensação de segurança” ao confiar nessa abordagem.
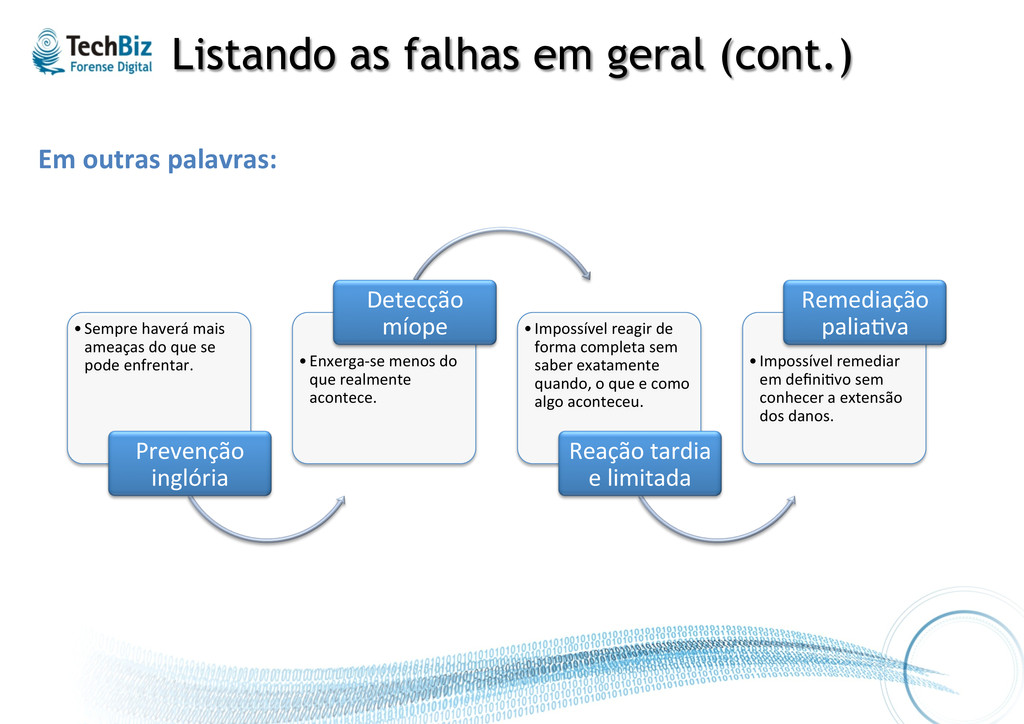
• Sempre haverá mais ameaças do que se pode enfrentar. Prevenção inglória • Enxerga-‐se menos do que realmente acontece. Detecção míope • Impossível reagir de forma completa sem saber exatamente quando, o que e como algo aconteceu. Reação tardia e limitada • Impossível remediar em defini.vo sem conhecer a extensão dos danos. Remediação palia.va
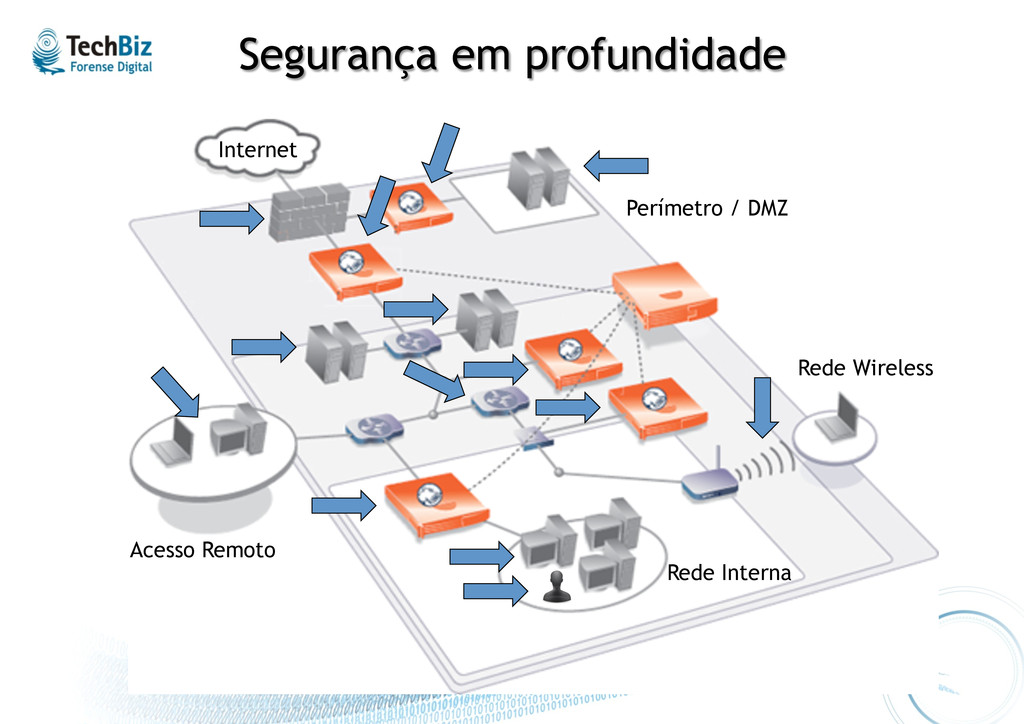
rede • Funcionamento: • Normalmente libera o tráfego que é explicitamente permi.do na organização, bloqueando todo o resto. • Falhas: • Muitas vezes possui configuração excessivamente permissiva. • Tráfego web e e-‐mail, obviamente liberado, concentra pra.camente a totalidade dos vetores de ataque. • Talvez não possa ser considerada uma solução de segurança “at all”, apesar de muitos discordarem.
Funcionamento: • Verifica se um arquivo possui padrão malicioso já conhecido. • É necessário que a base de assinaturas seja constantemente atualizada. • Para cada novo malware e suas variantes, o fabricante precisa lançar atualizações. • Falhas: • Padrões devem ser previamente conhecidos (modelo de segurança nega.vo – “blacklist”). • Proteção suscervel a anulação mesmo em pequenas modificações de malware. • Alto índice de falsos nega.vos. • Nenhuma proteção em casos de “zero day”.
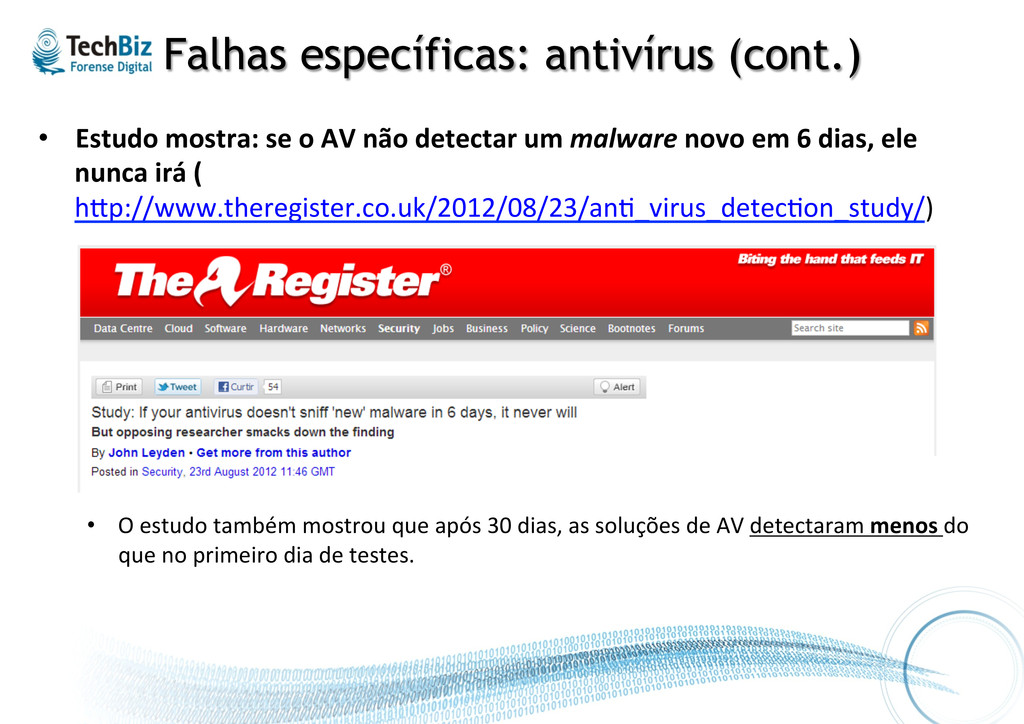
não detectar um malware novo em 6 dias, ele nunca irá ( hsp://www.theregister.co.uk/2012/08/23/an._virus_detec.on_study/) • O estudo também mostrou que após 30 dias, as soluções de AV detectaram menos do que no primeiro dia de testes.
malware simples 2. Vídeo do funcionamento do malware 3. Vídeo da verificação u.lizando VirusTotal (www.virustotal.com) 4. Relatório da verificação do malware u.lizando GFI Sandbox (www.threasrack.com)
• Funcionamento: • Capturam o tráfego e verificam a equivalência com conjunto de assinaturas pré-‐definido. • Falhas: • Padrões devem ser previamente conhecidos. • Detecção suscervel a anulação mesmo em pequenas modificações. • Nenhuma detecção em casos de “zero day”. • Detecção suscervel a falsos nega.vos. • Alto índice de falsos posi.vos, dificultando sua monitoração.
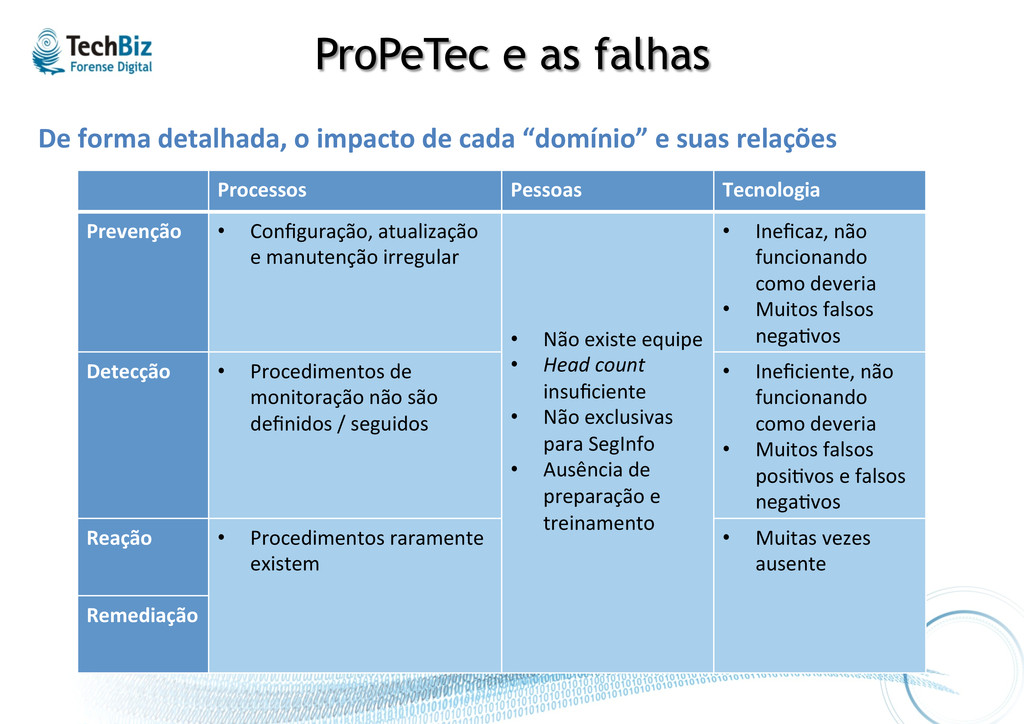
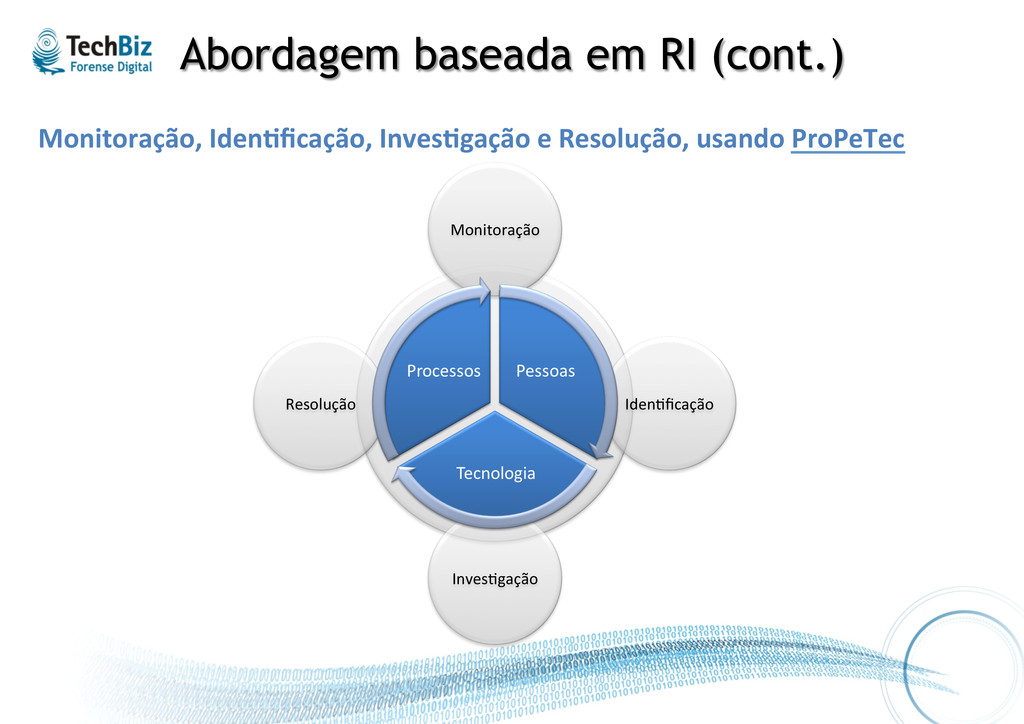
cada “domínio” e suas relações Processos Pessoas Tecnologia Prevenção • Configuração, atualização e manutenção irregular • Não existe equipe • Head count insuficiente • Não exclusivas para SegInfo • Ausência de preparação e treinamento • Ineficaz, não funcionando como deveria • Muitos falsos nega.vos Detecção • Procedimentos de monitoração não são definidos / seguidos • Ineficiente, não funcionando como deveria • Muitos falsos posi.vos e falsos nega.vos Reação • Procedimentos raramente existem • Muitas vezes ausente Remediação
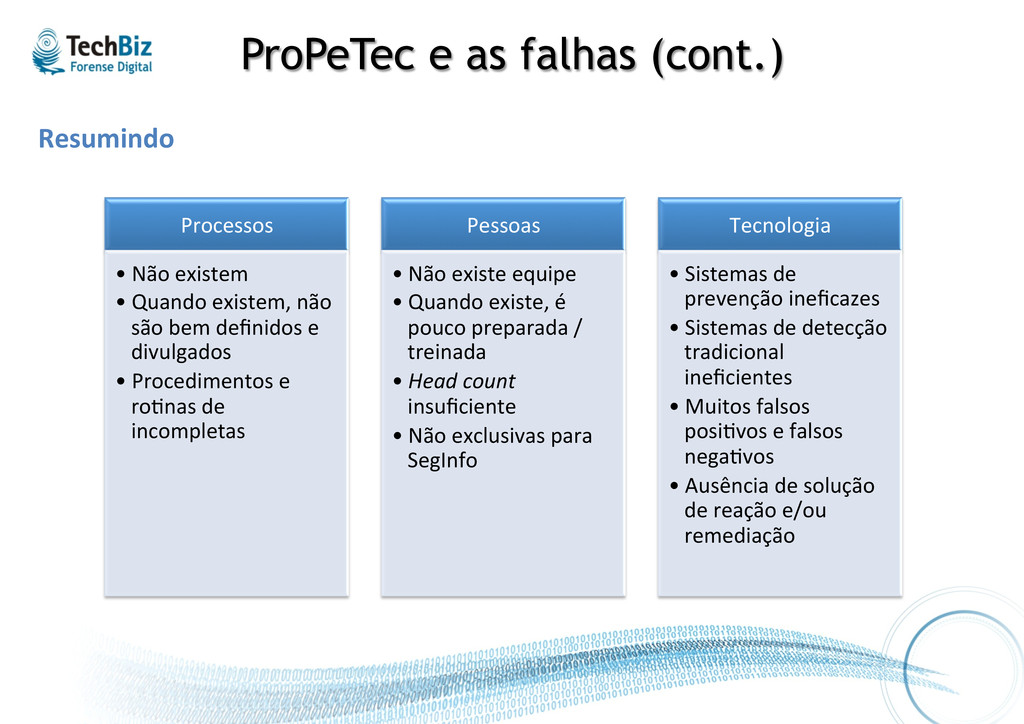
• Não existem • Quando existem, não são bem definidos e divulgados • Procedimentos e ro.nas de incompletas Pessoas • Não existe equipe • Quando existe, é pouco preparada / treinada • Head count insuficiente • Não exclusivas para SegInfo Tecnologia • Sistemas de prevenção ineficazes • Sistemas de detecção tradicional ineficientes • Muitos falsos posi.vos e falsos nega.vos • Ausência de solução de reação e/ou remediação
• Um sistema de proteção/prevenção (p) pode ser considerado seguro se funcionar por mais tempo que o tempo de detecção (d) somado ao tempo de reação (r) a um incidente: • Como vimos, a prevenção é falha. Logo, o tempo de proteção passa a ser na verdade tempo de exposição (e), que irá durar até a conclusão da reação Referência: Time Based Security (Winn Schwartau) Te = Td + Tr Tp > Td + Tr
ao infinito), então o sistema estará sempre exposto: • Conclusão: detecção e reação são importantes e úteis, porém somente se forem rápidas (eficientes) e produzirem resultados (eficazes). Te à ∞ Time Based Security é a chave
Foco em tecnologias de prevenção já se mostrou equivocado. à Não vale à pena concentrar esforços e depender apenas disso. • As soluções de detecção convencionais não são suficientes. à Porém ainda precisamos monitorar o que acontece no ambiente. • E quando algum incidente acontece? à Precisamos reagir. Para isso é necessário iden%ficar a ocorrência, inves%gar causas e resolver os issues, de modo que a resposta seja completa. • Então o foco passa a ser somente em responder aos incidentes? à O foco deve ser num conjunto de capacidades que permi.rão mi.gar riscos e impactos ao negócio.
ou não autorizada que envolva um sistema ou rede de computadores Resposta a incidente (RI) • Processo que visa a iden.ficação, inves.gação e resolução de um incidente Forense Digital • Disciplina focada na descoberta, extração e inves.gação de evidências a par.r de meios digitais (computadores, celures,…) DFIR • Digital Forensics and Incident Response, sigla muito u.lizada
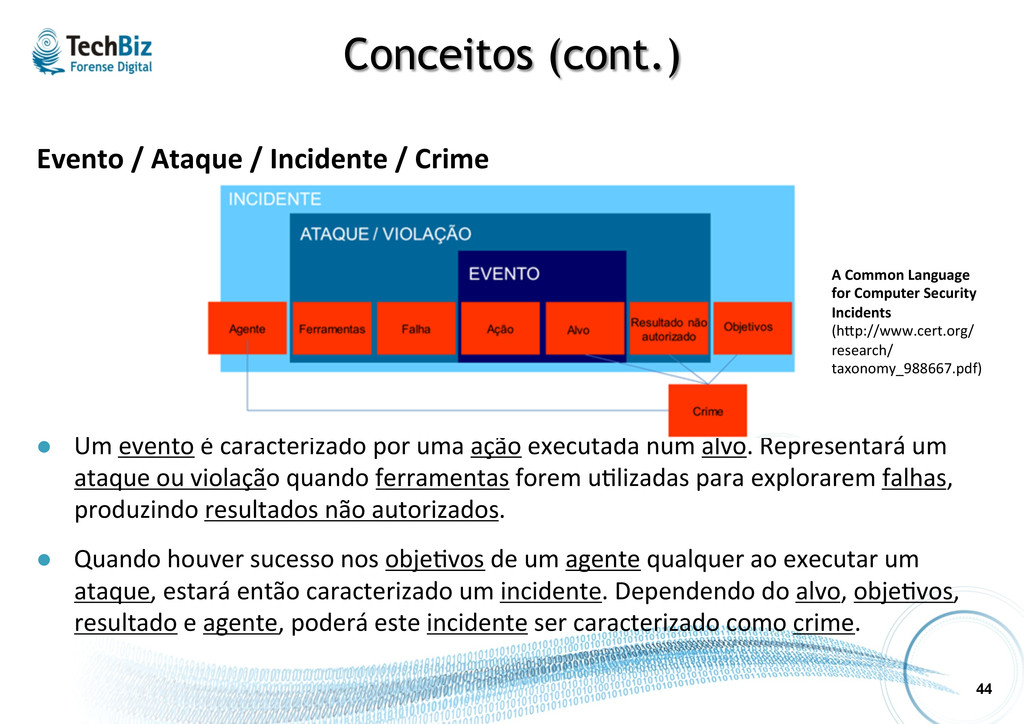
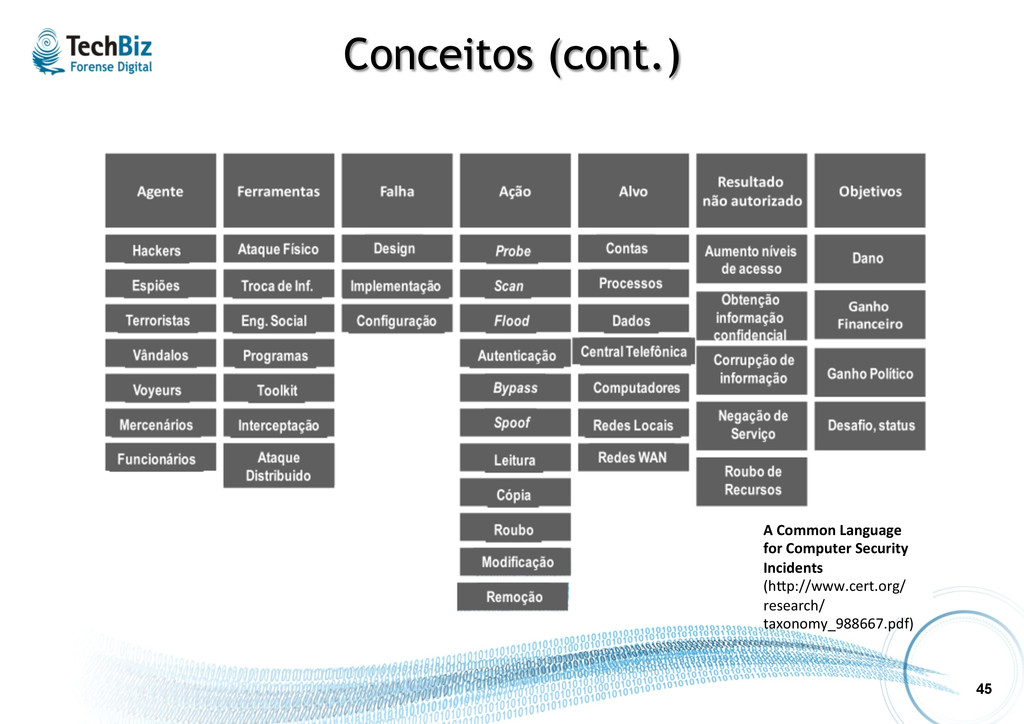
l Um evento é caracterizado por uma ação executada num alvo. Representará um ataque ou violação quando ferramentas forem u.lizadas para explorarem falhas, produzindo resultados não autorizados. l Quando houver sucesso nos obje.vos de um agente qualquer ao executar um ataque, estará então caracterizado um incidente. Dependendo do alvo, obje.vos, resultado e agente, poderá este incidente ser caracterizado como crime. A Common Language for Computer Security Incidents (hsp://www.cert.org/ research/ taxonomy_988667.pdf)
• PCI DSS, requisito 12.9 “Implement an incident response plan, be prepared to respond immediately to a system breach” • SOx Resposta a Incidentes pode ajudar a fornecer accountability.
CSIRT -‐ Computer Security Incident Response Team l FIRST -‐ Forum of Incident Response and Security Teams l CIRC -‐ Computer Incident Response Capability l CIRT -‐ Computer Incident Response Team l IRC -‐ Incident Response Center l IRT -‐ Incident Response Team l SERT -‐ Security Emergency Response Team l SIRT -‐ Security Incident Response Team
alguma ação em resposta. l Essa ação pode ter como obje.vos: l Determinar as consequências l Como prosseguir após essa ocorrência? Quais serão os próximos passos? l Quan.ficar prejuízos l Qual o impacto, seja ele financeiro, de imagem, moral, etc.? l Definir a.vidades de recuperação, correção, etc. l O que precisa ser feito para reestabelecer a normalidade? l Definir sanções, multas, penas, etc. l Quem precisa ser punido? O que exatamente jus.ficaria a punição?
obje.vos, certamente será necessário descobrir e comprovar: l A ocorrência do incidente e sua extensão l As causas (fatores que levaram ou permi.ram sua ocorrência) l Os causadores (acidentais ou propositais) l Sempre que se deseja descobrir e comprovar algo sobre um incidente, uma inves.gação se faz necessária. l Estas inves.gações são suportadas por a.vidades, ferramentas e profissionais de Forense Digital.
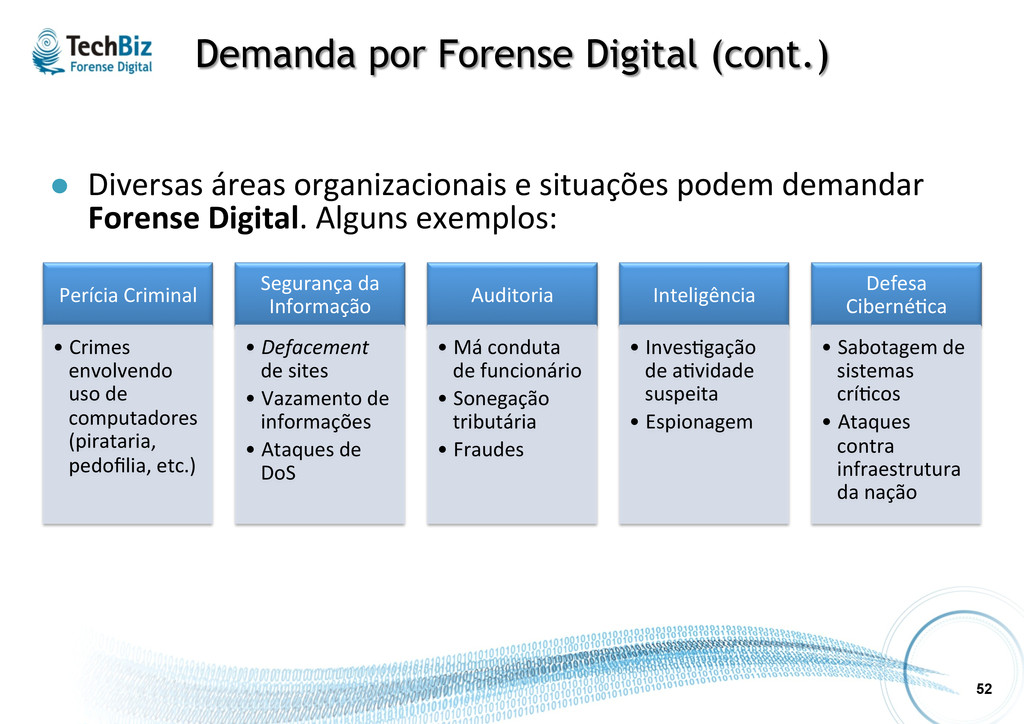
e situações podem demandar Forense Digital. Alguns exemplos: Perícia Criminal • Crimes envolvendo uso de computadores (pirataria, pedofilia, etc.) Segurança da Informação • Defacement de sites • Vazamento de informações • Ataques de DoS Auditoria • Má conduta de funcionário • Sonegação tributária • Fraudes Inteligência • Inves.gação de a.vidade suspeita • Espionagem Defesa Ciberné.ca • Sabotagem de sistemas crí.cos • Ataques contra infraestrutura da nação
formais provê benezcios: l Previne respostas precipitadas, incorretas ou incoerentes. l Confirma ou nega a ocorrência de um incidente e sua extensão. l Estabelece controles para a correta manipulação de provas. l Promove resolução e reparação mais rápidas. l Minimiza a exposição e o comprome.mento de informações. l Favorece a resposta a futuros incidentes com lições aprendidas.
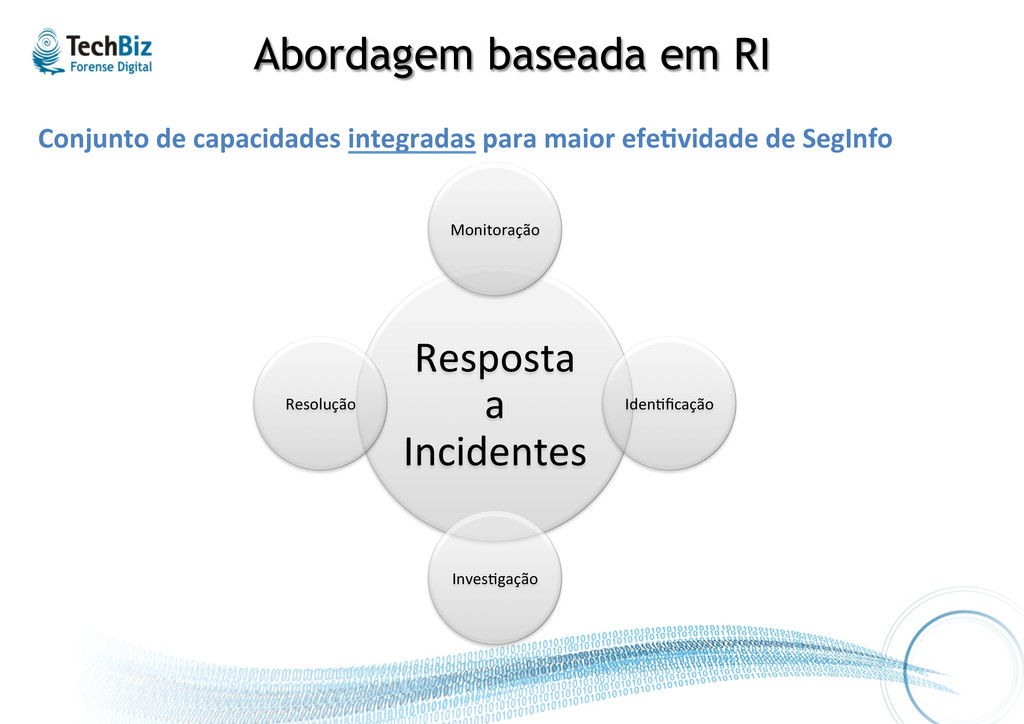
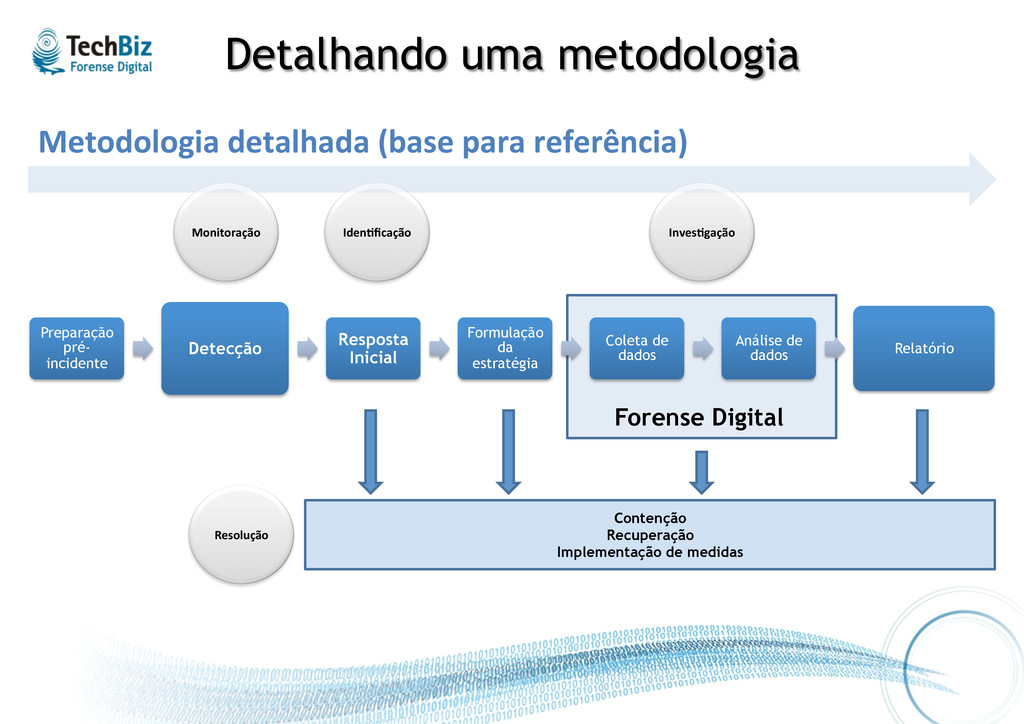
de dados Análise de dados Relatório Forense Digital Contenção Recuperação Implementação de medidas Detalhando uma metodologia Metodologia detalhada (base para referência) Monitoração Iden%ficação Inves%gação Resolução
• Deve-‐se preparar a organização para que RI possa acontecer • Polí.cas (AUP, etc), procedimentos, etc. • Modelos de documentação e formulários • Equipe (CSIRT) e treinamentos • So{ware e hardware para detecção, inves.gação e resposta • Ninguém quer se preparar após o pior acontecer...
eficaz, não existe resposta • Parte crucial do TBS • Pode acontecer de várias formas (vários canais) • O máximo de informações deve ser registrado. Ex.: data/hora, o quê foi reportado, natureza, a.vos envolvidos, pontos de contato.
todas informações possíveis • Determinar .po do incidente e seu impacto • Listar possíveis passos a seguir • Não envolve coleta direta no equipamento, e sim: • Entrevistas com usuários e administradores • Verificação de relatórios das ferramentas de monitoração • Revisão de logs de equipamentos de rede • O mínimo aqui é determinar se houve mesmo um incidente
Determinar como será a resposta, dadas as circunstâncias: • Polí.cas • Técnicas • Legais • Negócio • Estratégia final é definida pelo(s) líder(es) da equipe • Certamente o “vazamento de um projeto confidencial” terá resposta diferente de “usuário recebendo e-‐mail de phishing”
• Algumas questões importantes: • Qual a cri.cidade do sistema afetado? • Quão sensível é a informação comprome.da? • Quem são os perpetradores potenciais? • O incidente foi a público? • Qual é o nível de acesso ob.do pelo atacante? • Qual é a habilidade técnica aparente do atacante? • Quanto tempo de indisponibilidade está envolvido? • Quanto de perda financeira?
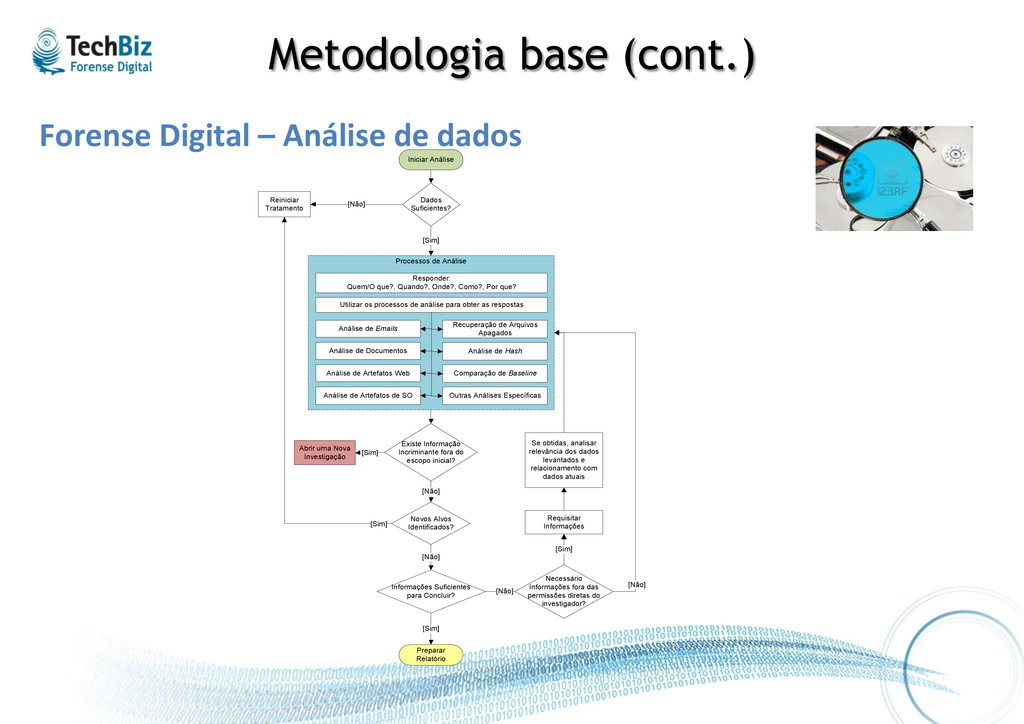
o quê, quando, onde, como e por quê § Conduzida com base nas evidências encontradas nos sistemas, entre outras § Duas etapas básicas: • Coleta de dados: • Análise de dados
• Acumular fatos e provas sobre o incidente • Quanto mais completa a coleta, maior a possibilidade de sucesso • Outros desafios únicos desta etapa: • Os dados devem ser coletados de forma forense • Normalmente são coletados mais dados do que se pode analisar • Os dados devem ser manipulados de modo que a integridade seja man.da
• Exemplos de evidências digitais: • Arquivos (imagens, vídeos, documentos, executáveis, etc.) • Histórico de conversas em IM (MSN, Skype, etc.) • Histórico de navegação na web (browsers), cookies e bookmarks • E-‐mails • Tráfego de rede capturado • Logs de servidores
Novos Alvos Identificados? [Não] [Sim] Iniciar Análise Dados Suficientes? Reiniciar Tratamento [Não] [Sim] Processos de Análise Responder: Quem/O que?, Quando?, Onde?, Como?, Por que? Utilizar os processos de análise para obter as respostas Análise de Emails Análise de Documentos Análise de Artefatos Web Análise de Artefatos de SO Recuperação de Arquivos Apagados Análise de Hash Comparação de Baseline Existe Informação Incriminante fora do escopo inicial? [Sim] Abrir uma Nova Investigação [Não] Requisitar Informações [Sim] Se obtidas, analisar relevância dos dados levantados e relacionamento com dados atuais Preparar Relatório Informações Suficientes para Concluir? [Sim] [Não] [Não] Outras Análises Específicas Necessário Informações fora das permissões diretas do investigador?
• As a.vidades de análise devem ter como obje.vo responder às seguintes questões (Heptâmetro de Quin%liano): • QUIS? Quem? • QUID? O quê? • UBI? Onde? • QUIBUS AUXILIIS? Com que auxílio? • CUR? Por quê? • QUODOMO? De que modo? • QUANDO? Quando?
descreva precisamente os detalhes do incidente • Recomendações: • Documente imediatamente • Escreva de forma concisa e clara • Siga um padrão e um modelo
E ESCRITA 4. DIPLOMACIA 6. INTEGRIDADE PESSOAL 7. CONHECER SEUS LIMITES 5. TRABALHO EM EQUIPE 9. SOLUÇÃO DE PROBLEMAS 10. GERENCIAMENTO DO TEMPO 2. APRESENTAÇÃO 3. POLÍTICAS E PROCEDIMENTOS 8. ADMINISTRAR O ESTRESSE
correta. 2. Ter boa apresentação pessoal (aparência e ves.mentas). 3. Saber a importância de seguir à risca polí.cas e procedimentos. 4. Munir-‐se de diplomacia. 5. Saber trabalhar em equipe. 6. Ser íntegro. 7. Conhecer seus limites. 8. Saber administrar o estresse e lidar com pressão. 9. Ter faro para a solução de problemas. 10. Saber gerenciar o tempo.
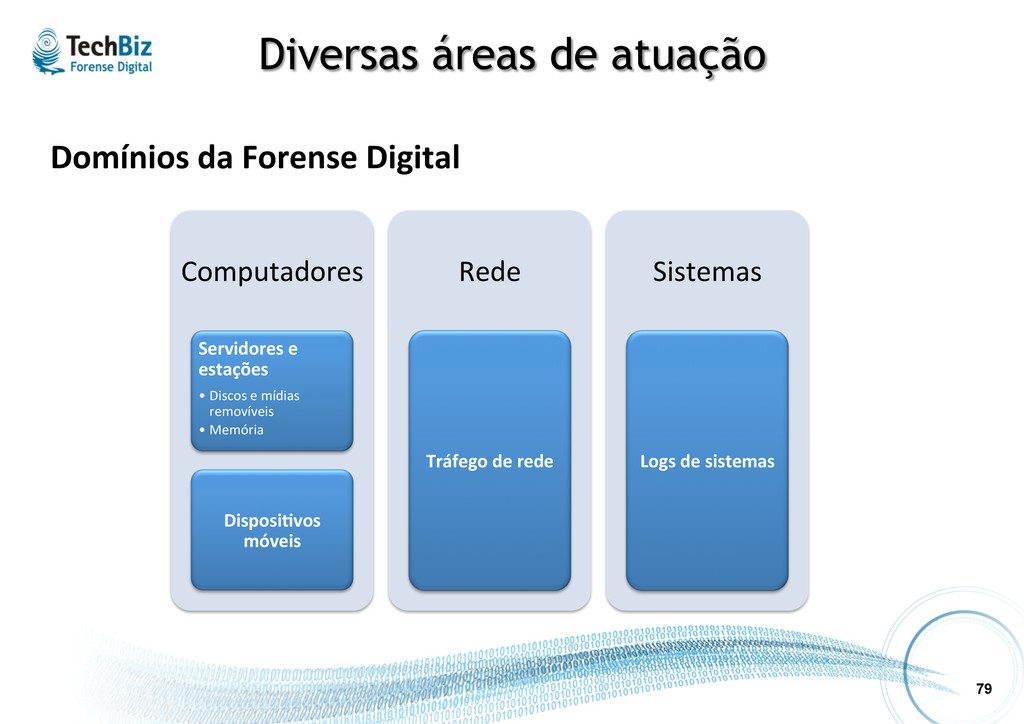
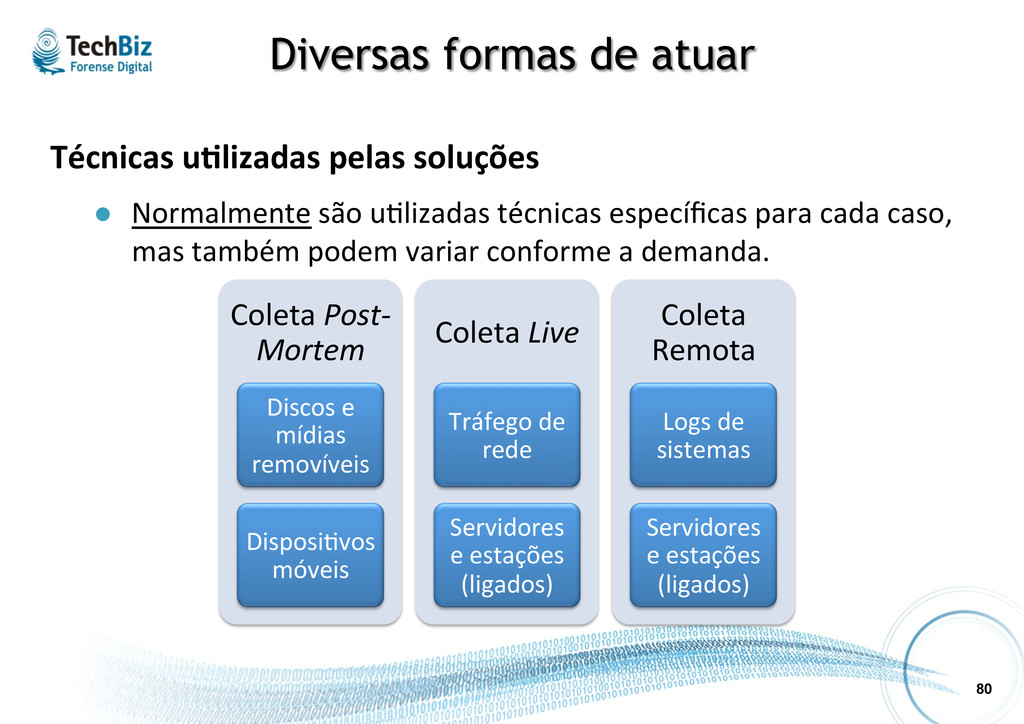
l Normalmente são u.lizadas técnicas específicas para cada caso, mas também podem variar conforme a demanda. Coleta Post-‐ Mortem Discos e mídias removíveis Disposi.vos móveis Coleta Live Tráfego de rede Servidores e estações (ligados) Coleta Remota Logs de sistemas Servidores e estações (ligados)
• Discos e mídias removíveis Definição: É o .po de forense “tradicional”, onde as evidências são os dados gravados em mídias e disposi.vos de armazenamento eletrônico em geral. Insumos para evidências: l Discos rígidos (internos) e mídias removíveis, usualmente com coleta post mortem (podendo ser também live e remota, através de agentes).
• Memória Definição: É o .po de forense onde as evidências são ob.das a par.r de dumping e análise dos dados armazenados em memória RAM (volá.l). Insumos para evidências: l Memória RAM, com coleta live (normalmente remota, através de agentes).
Definição: É o .po de forense realizada em telefones celulares, smartphones, tablets, GPSs, etc. Os dados gravados nestes disposi.vos, tais como fotos, mensagens SMS, registros de ligações, entre outros podem ser usados como evidências. Insumos para evidências: l Imagem lógica (arquivos, registros) ou zsica (bit-‐a-‐bit), coletados geralmente post mortem, com acesso zsico ao disposi.vo.
Definição: É a captura, armazenamento e análise de dados trafegados numa rede de computadores para detectar a origem de algum problema de segurança ou algum outro incidente. Insumos para evidências: l Tráfego de rede, usualmente com coleta live (podendo ser também post mortem).
É a captura, armazenamento e análise de eventos gerados pelos sistemas (SO, bancos de dados, aplicações, etc.) que podem ser usados como evidências. Insumos para evidências: l Logs (registros em trilhas de auditoria), com coleta local ou remota (ferramentas de SIEM e log management), live ou post mortem.
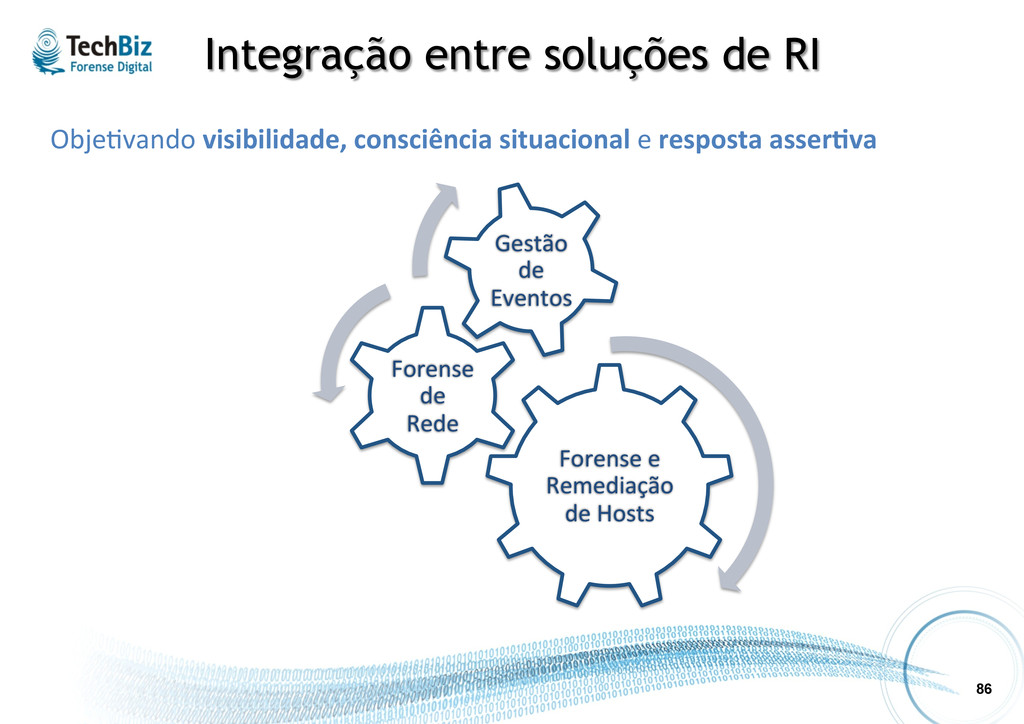
• Monitoração feita de maneira integrada traz visibilidade sobre os domínios (Rede, Hosts, Sistemas) e contextualização sobre os incidentes. • Iden%ficação focada em ameaças e impactos reais, conforme o contexto da organização (ambiente e negócio). • Inves%gação elucida.va que suporte ações (operacionais e legais) posteriores, visando melhorias. • Resolução que viabilize reação asser.va.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Marcelo de Souza Consultor Sênior [email protected] www.marcelosouza.com @marcelo_sz Fim](https://files.speakerdeck.com/presentations/8551b2601479013077d112313d1a82a3/slide_90.jpg){kind=link}