sharing between HT and OED • On most occasions it should be safe to assume that an OED thesaurus category will have an HT counterpart • Categories should exist in same place in hierarchical structure • However, databases have been adjusted by HT and OED teams separately and have thus diverged
expressions ‣ Pertaining to -> relating to ‣ Inhabitant of -> inhabitant ‣ spec. -> specific ‣ -ize -> -ise ‣ January -> jan. ‣ Remove ‘a ’ and ‘to ’ at beginning of string
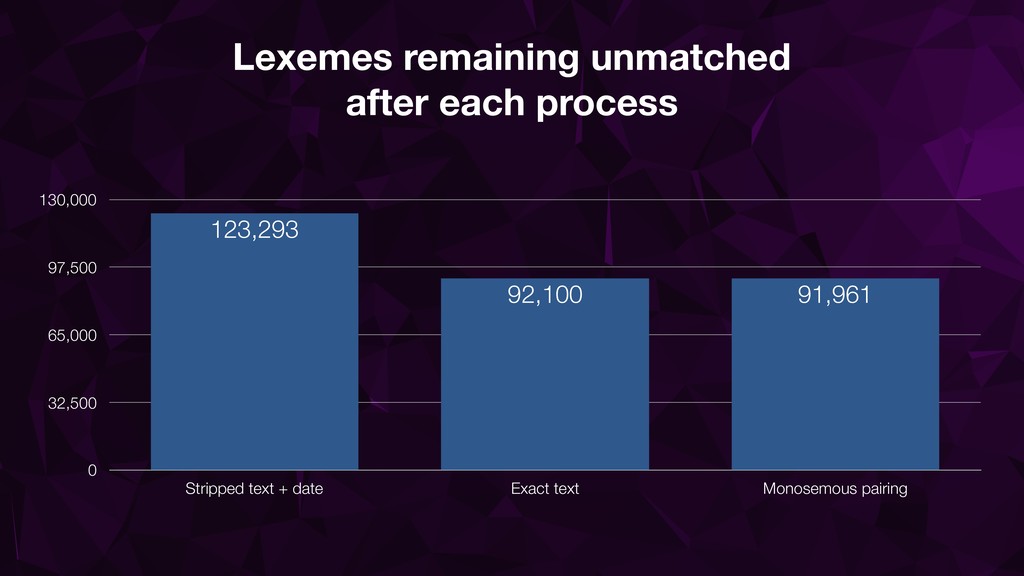
• Date information (even without lexeme text) very useful • Monosemous pairing helps but needs close monitoring • Iterative checking with distinct confidence levels essential
between resources are valuable for lexicographers, lexicologists, semanticists, the general interested public • Methods can be applied to/adapted for other lexical resources ‣ Thesaurus of the Scots Language pilot project (Carnegie Research Incentive Grant)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
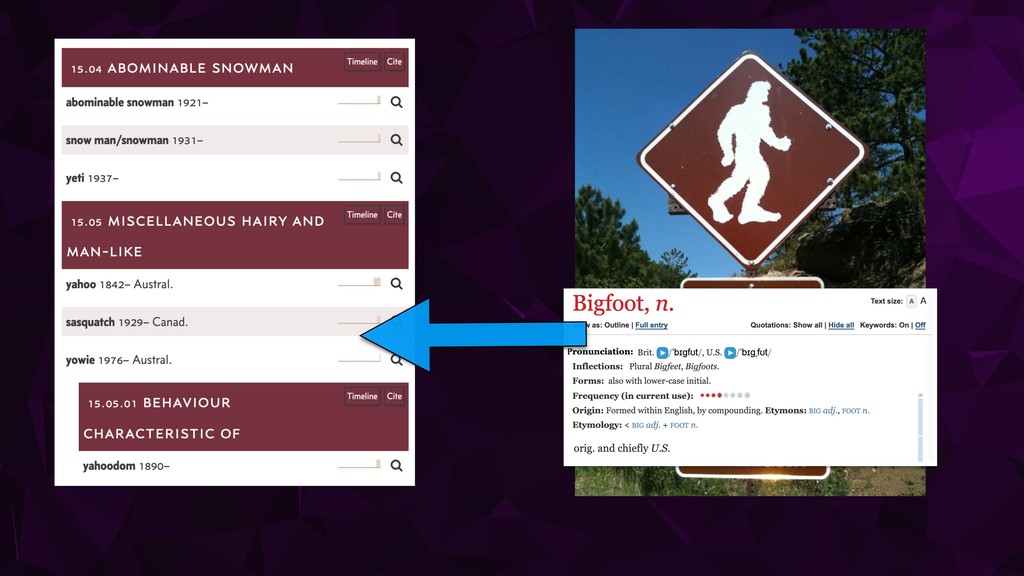{kind=link}
{kind=link}
{kind=link}
{kind=link}
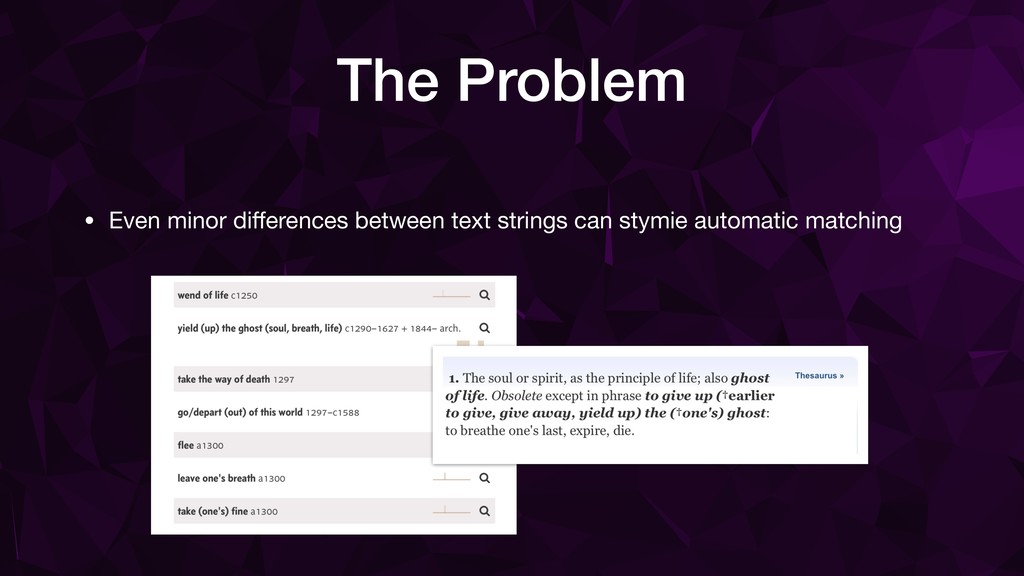{kind=link}
{kind=link}
{kind=link}
{kind=link}
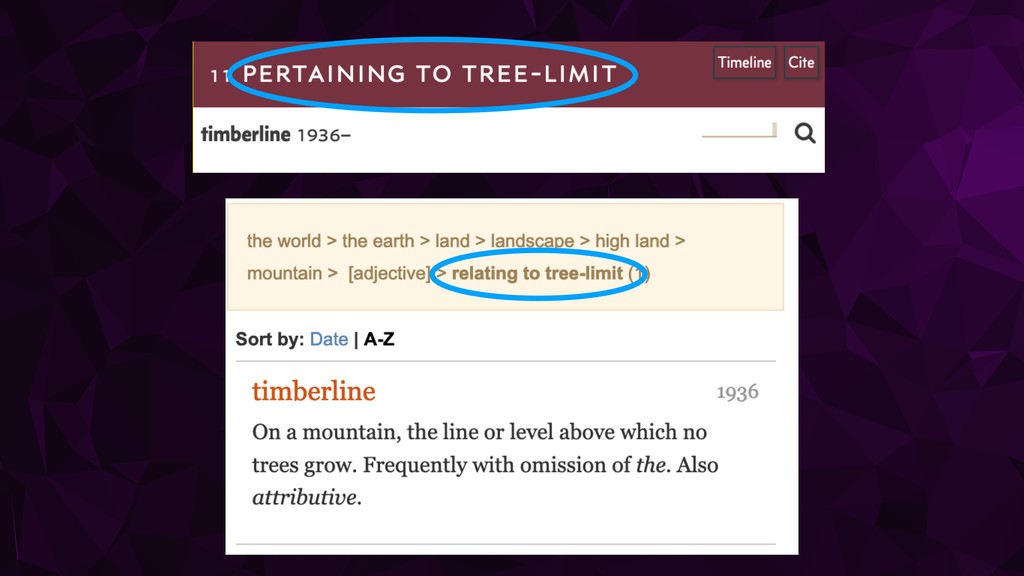{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
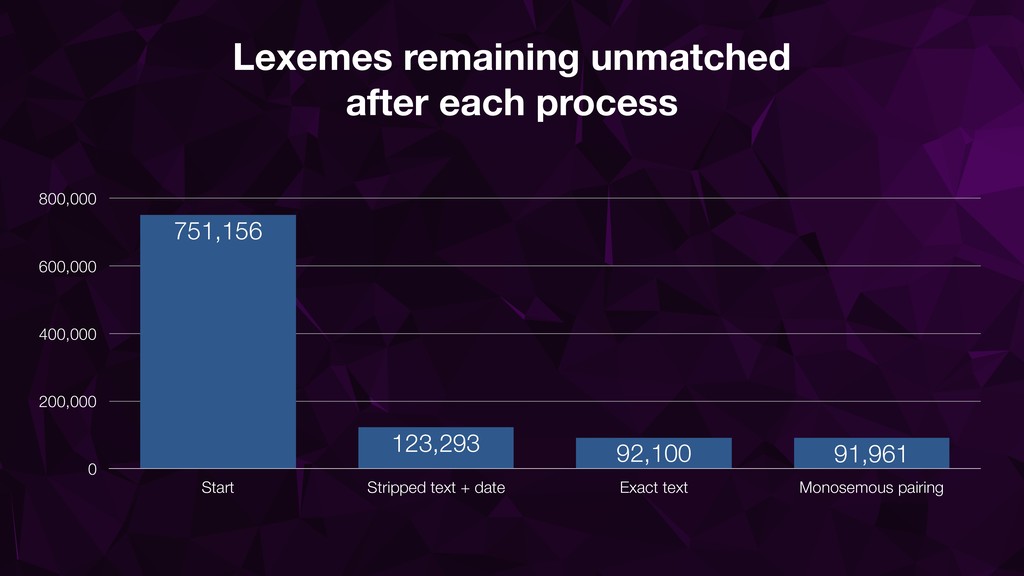{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}