impossible to process texts of several million words in length. Twenty years ago it was considered marginally possible but lunatic. Ten years ago it was considered quite possible but still lunatic. Today it is very popular.” John Sinclair 1991
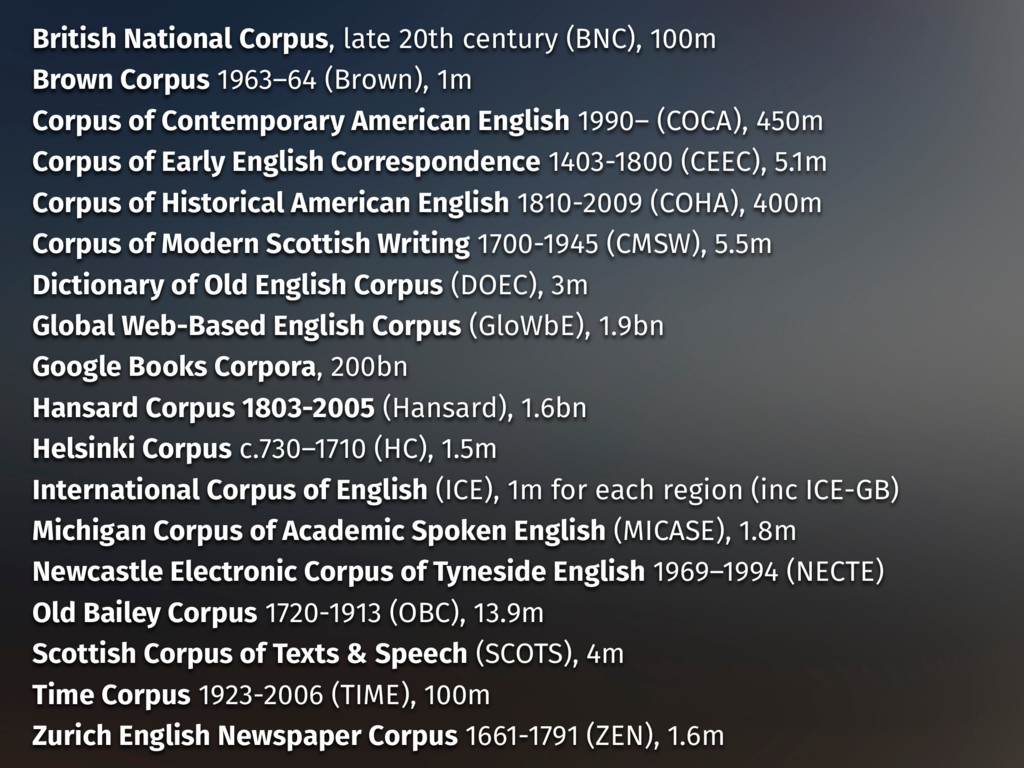
1963–64 (Brown), 1m Corpus of Contemporary American English 1990– (COCA), 450m Corpus of Early English Correspondence 1403-1800 (CEEC), 5.1m Corpus of Historical American English 1810-2009 (COHA), 400m Corpus of Modern Scottish Writing 1700-1945 (CMSW), 5.5m Dictionary of Old English Corpus (DOEC), 3m Global Web-Based English Corpus (GloWbE), 1.9bn Google Books Corpora, 200bn Hansard Corpus 1803-2005 (Hansard), 1.6bn Helsinki Corpus c.730–1710 (HC), 1.5m International Corpus of English (ICE), 1m for each region (inc ICE-GB) Michigan Corpus of Academic Spoken English (MICASE), 1.8m Newcastle Electronic Corpus of Tyneside English 1969–1994 (NECTE) Old Bailey Corpus 1720-1913 (OBC), 13.9m Scottish Corpus of Texts & Speech (SCOTS), 4m Time Corpus 1923-2006 (TIME), 100m Zurich English Newspaper Corpus 1661-1791 (ZEN), 1.6m
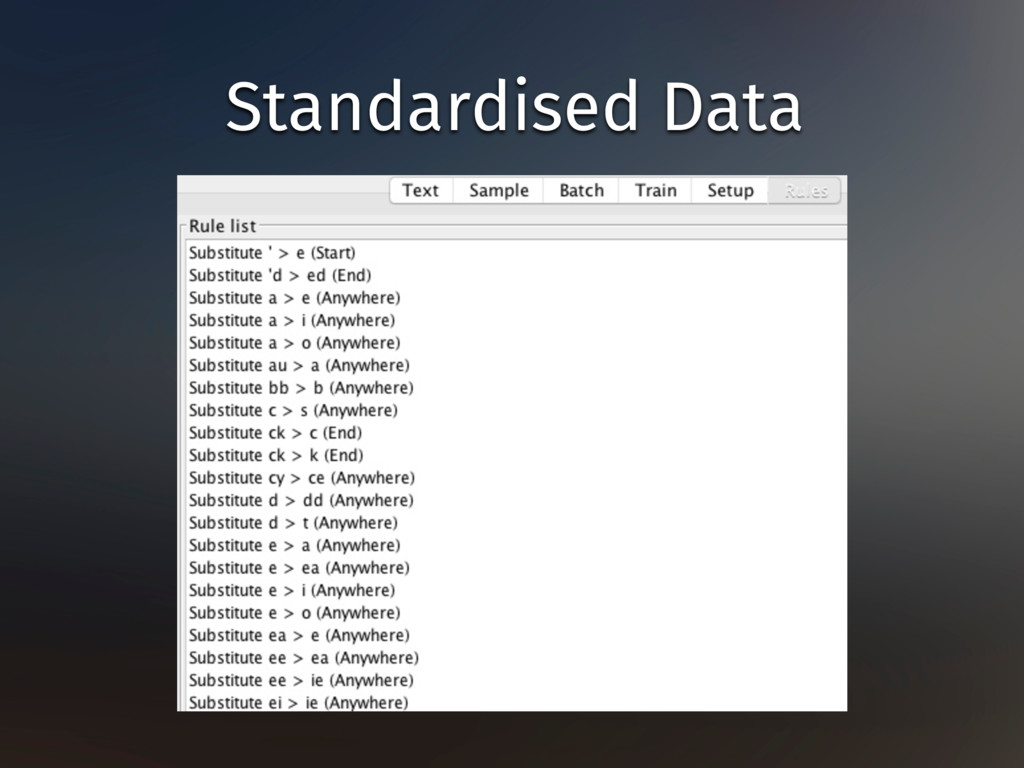
searching for it misses instances of misspelling or historical variation, or includes the wrong meaning of the word ‣ Improvement of automatic processing of language ‣ Can we find repeated grammatical structures in sentences / around certain words? ‣ Can we say how often a word was used and in what circumstances across a range of time? ‣ Can we spot when someone is talking about, say, having lunch when they don’t use the word lunch? ‣ Can we identify whether the appearance of a particular word in a sentence (say, cat) makes it very likely that another (say, kitten) will be used too? In what ways are these useful?
way but in tenements it seemed to be much easier for people to walk in and out of their house you know no no problem MJ: You got a bit of meat for soup and it would be passed round all the doors for to get everybody make a pot of soup out of one bit of meat that's what happened in our place it happened DJ: Oh aye these things happened aye that's right Airdrie, central belt
speak in Doric really, we speak half and half DB: s- we just speak KB: divnt we? we speak half and half, half Doric half English, half fittever INT: fa kens, fa kens DB: (clk) I ken I ken KB: if I k-- mhm I daa ken my quine, I w- I would say it they'll say fitte- fitna granny's that you had? DB: oh well, it doesna matter eh
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}