leader at Rainforest Alliance More than 25 years of data experience Data engineer Data analyst Business analyst Accidental DBA Quality manager Data Quality Analyst Project manager Data architect Data modeler Tester Troubleshooter Security Officer
better farming, have better incomes, take better care of the environments. 2 group of products: • Certification of tropical products (Coffee, Cocoa, Tea, hazelnut, banana) • Landscale & Community projects And what is needed to support it
term I use most, but think analytics engineers, or data pipeline developers, ETL developers, data scientists I will discuss data pipelines in general, but many principles are also important for reporting, visualisation and complex models. Business data users are your data stewards, business analysts, data management team, data power users
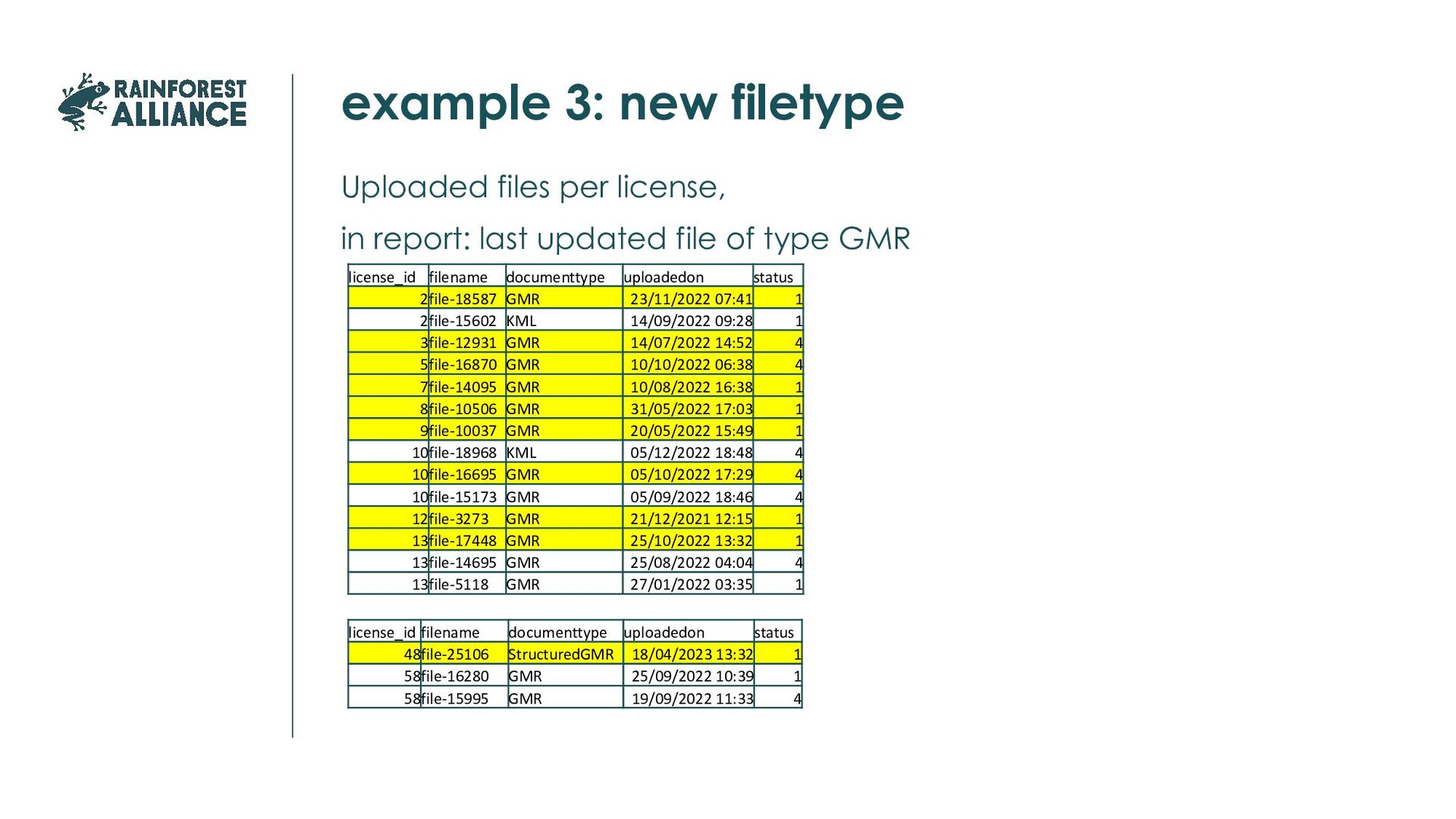
∙ New attributes ∙ Changed data formats ∙ Bugfixes ∙ New business rules ∙ Poor data quality ∙ New codes ∙ User creativity ∙ Incomplete data ∙ Reuse of existing codes and attributes Small changes often have more impact than the big ones.
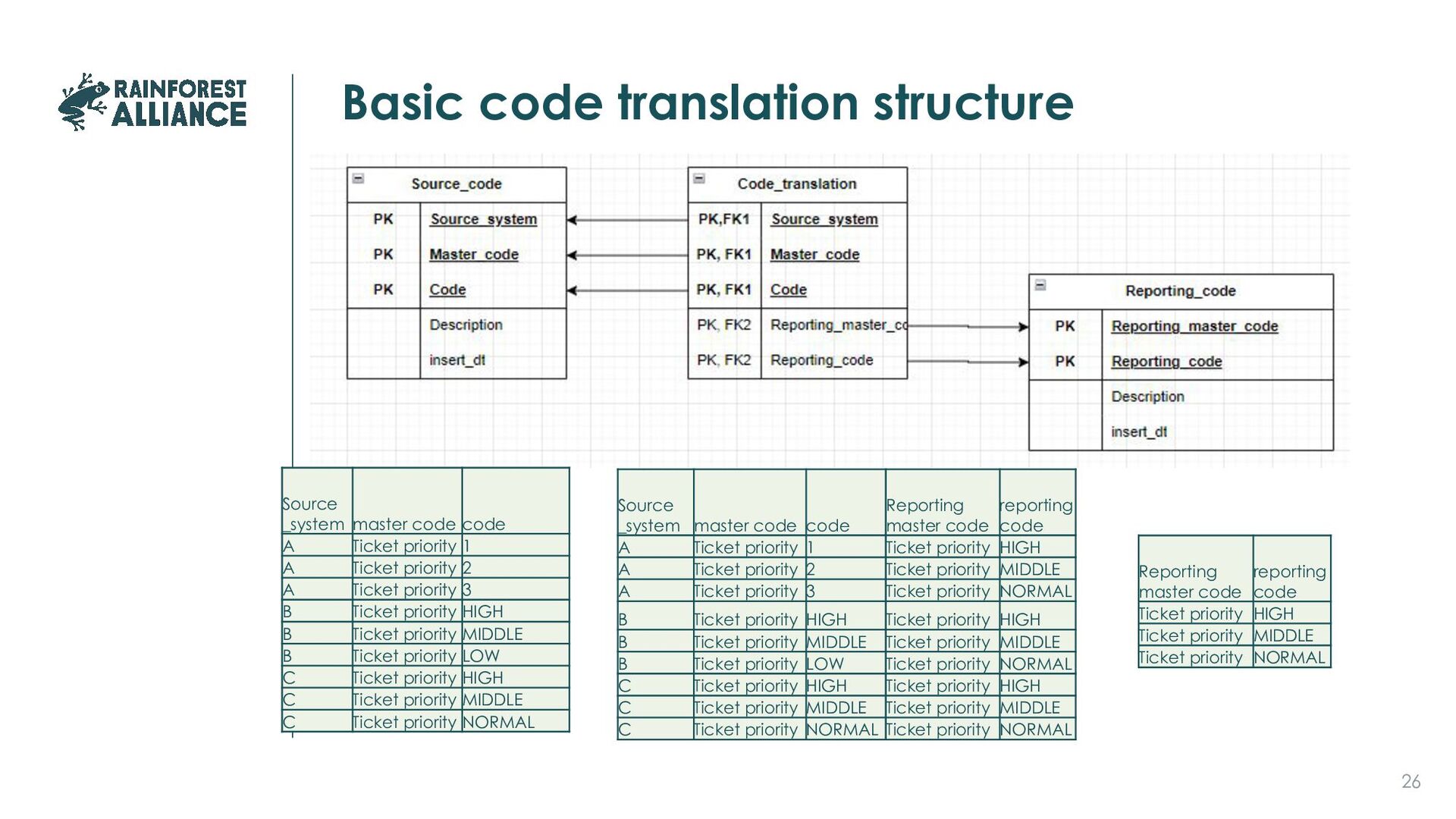
data Priority First Month Last Month 1 Sep-11 Feb-12 2 Sep-11 Feb-12 3 Sep-11 Feb-12 HIGH Feb-12 Jul-12 MIDDLE Feb-12 Jul-12 LOW Feb-12 Jul-12 HIGH Aug-12 now MIDDLE Aug-12 now NORMAL Aug-12 now reporting Priority HIGH MIDDLE NORMAL HIGH MIDDLE NORMAL HIGH MIDDLE NORMAL
end of a long data chain, inheriting all the issues Accept that your source data can change any time You need to build for resilience and flexibility You need to be able to quickly validate You are developing solutions for datasets, not for a number of specific cases You need to be able to quickly spot changes (errors) in your source data
will cover a significant variety of data and data issues 2. Production data have the relevant day-to-day changes in the data your data pipelines need to cover 3. You need realistic volumes of data 4. Trying to distinguish between real data issues and flawed test data will cost you lots of time and frustration
It is against our standards! • Developers should never work with production data Practical: • Confidentiality • Volume Most of the objections are coming from lack of appreciation of the differences with software engineering
Correctness Timeliness One or two of the there is reasonably achievable If you want to do all 3 perfectly the costs will go up exponentially And in most analytic use cases there is no need for it So challenge your business
Completeness Correctness Timeliness One or two of the there is reasonably achievable If you want to do all 3 perfectly the costs will go up exponentially And in most analytic use cases there is no need for it So challenge your business
to easily validate the correctness (without the need of engineering knowledge) (sql example) Intermediate results are very useful for that If you can only validate your pipeline or data product by changing the code to analyse part of it, or storing intermediate results in a table for analysis, it would be a good idea to store it as a standard part of your process.
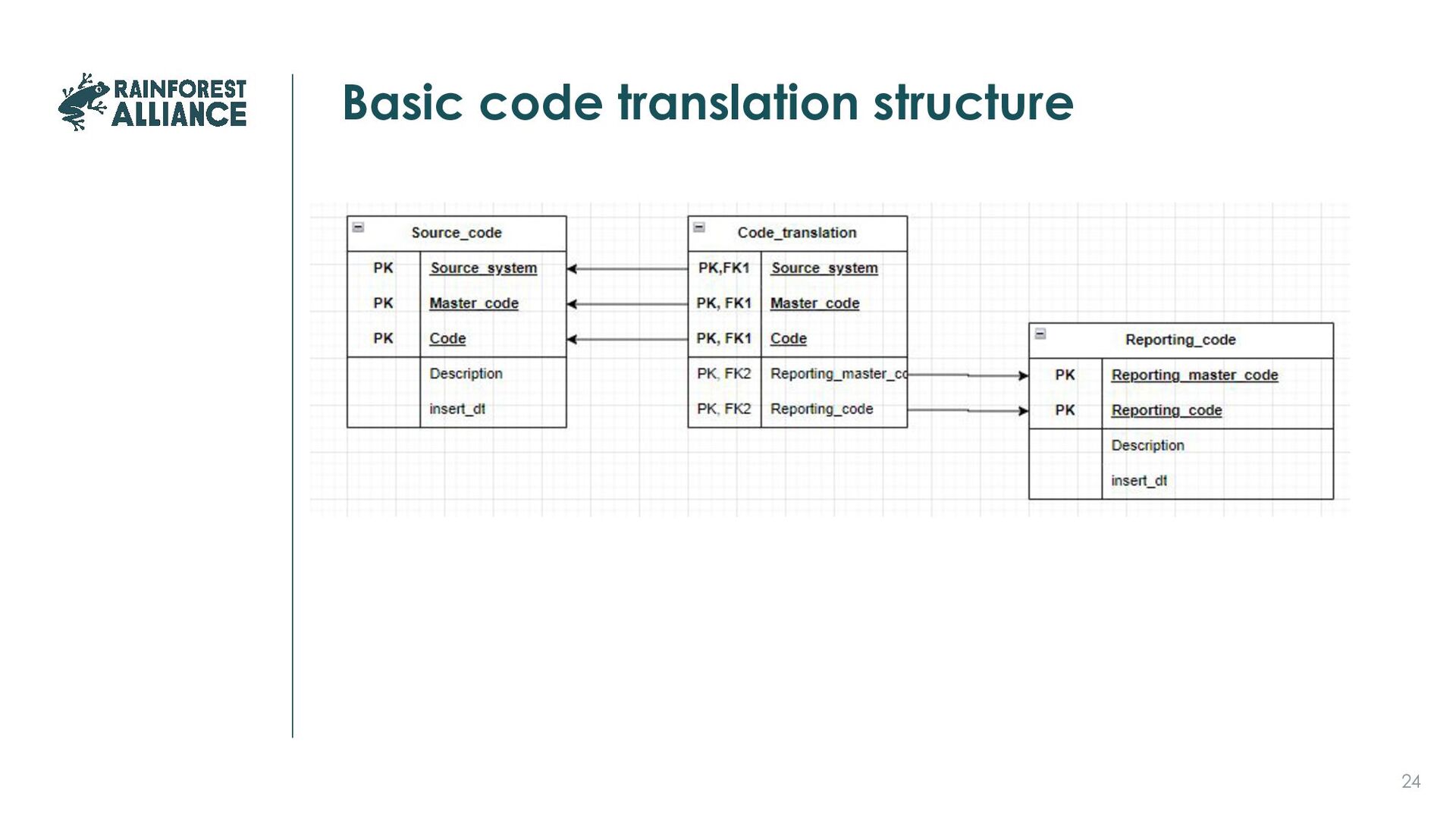
change over time, differ between systems, have changing interpretations, new ones added So make them part of your data management process, not of your code
data Priority First Month Last Month 1 Sep-11 Feb-12 2 Sep-11 Feb-12 3 Sep-11 Feb-12 HIGH Feb-12 Jul-12 MIDDLE Feb-12 Jul-12 LOW Feb-12 Jul-12 HIGH Aug-12 now MIDDLE Aug-12 now NORMAL Aug-12 now reporting Priority HIGH MIDDLE NORMAL HIGH MIDDLE NORMAL HIGH MIDDLE NORMAL
A Ticket priority 1 A Ticket priority 2 A Ticket priority 3 B Ticket priority HIGH B Ticket priority MIDDLE B Ticket priority LOW C Ticket priority HIGH C Ticket priority MIDDLE C Ticket priority NORMAL Reporting master code reporting code Ticket priority HIGH Ticket priority MIDDLE Ticket priority NORMAL Source _system master code code Reporting master code reporting code A Ticket priority 1 Ticket priority HIGH A Ticket priority 2 Ticket priority MIDDLE A Ticket priority 3 Ticket priority NORMAL B Ticket priority HIGH Ticket priority HIGH B Ticket priority MIDDLE Ticket priority MIDDLE B Ticket priority LOW Ticket priority NORMAL C Ticket priority HIGH Ticket priority HIGH C Ticket priority MIDDLE Ticket priority MIDDLE C Ticket priority NORMAL Ticket priority NORMAL
that the full dataset is correct We want to be able to spot changes and issues caused by your sources Not only now, but also in production, after every load The good thing: A good monitoring process works perfectly well for regressions and integration testing You need production data
the result is correct One way is using reconciliation reports, like finance uses. This is best designed by business data users. SALES per region Source Data warehouse Reporting Europe 1,700,000 1,700,000 1,700,000 Africa 940,000 942,000 942,000 Asia 365,000 363,000 363,000 US 9,993,000 9,993,000 9,993,000 Latin America 210,000 210,000 210,000
Number of empty values per column (including empty strings or default dates) • Number of unique values per column • Number of missing foreign key references • Number of new business keys (new customers, new shops, new products) Meaningful Business statistics: Average sales per order
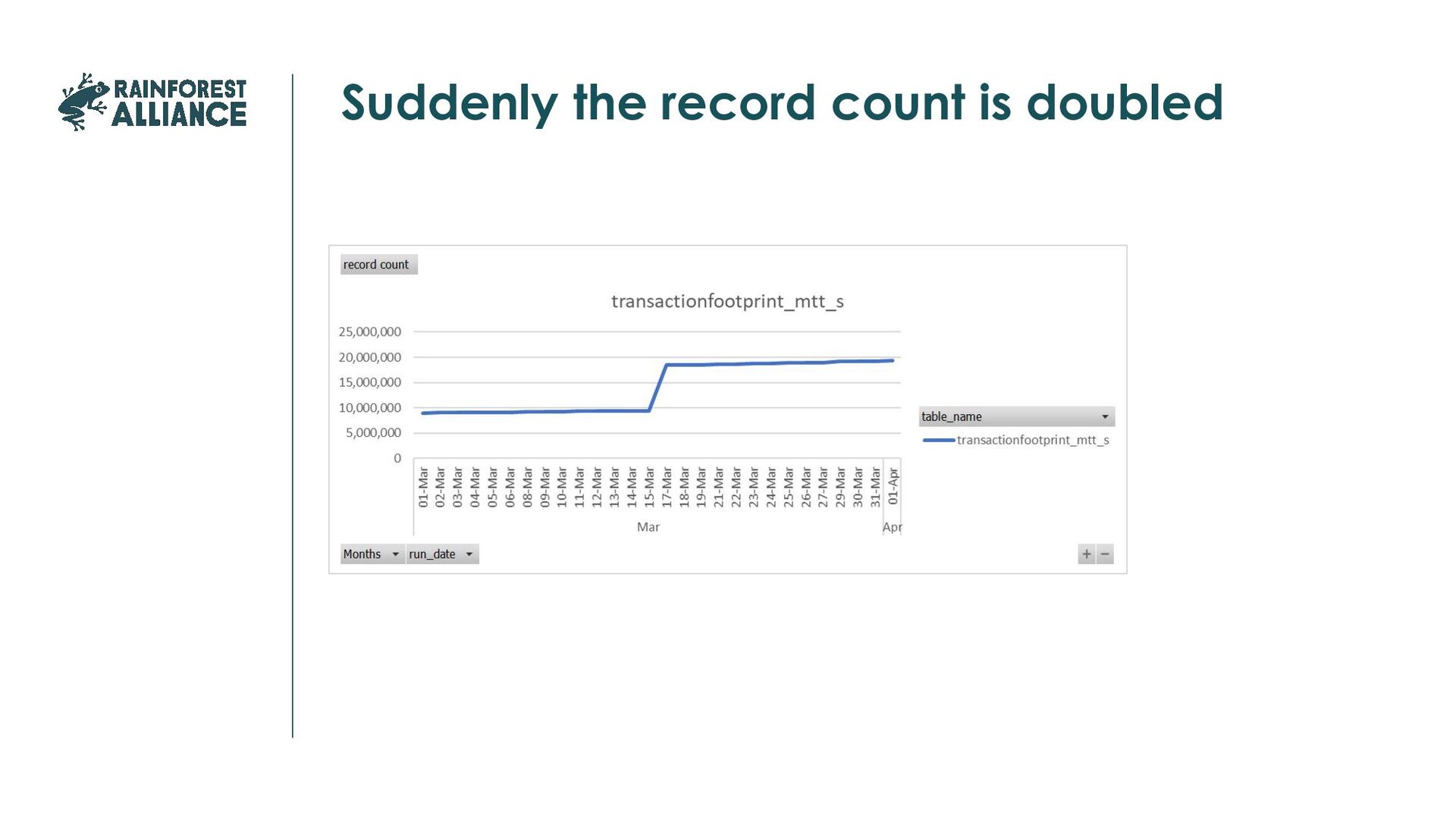
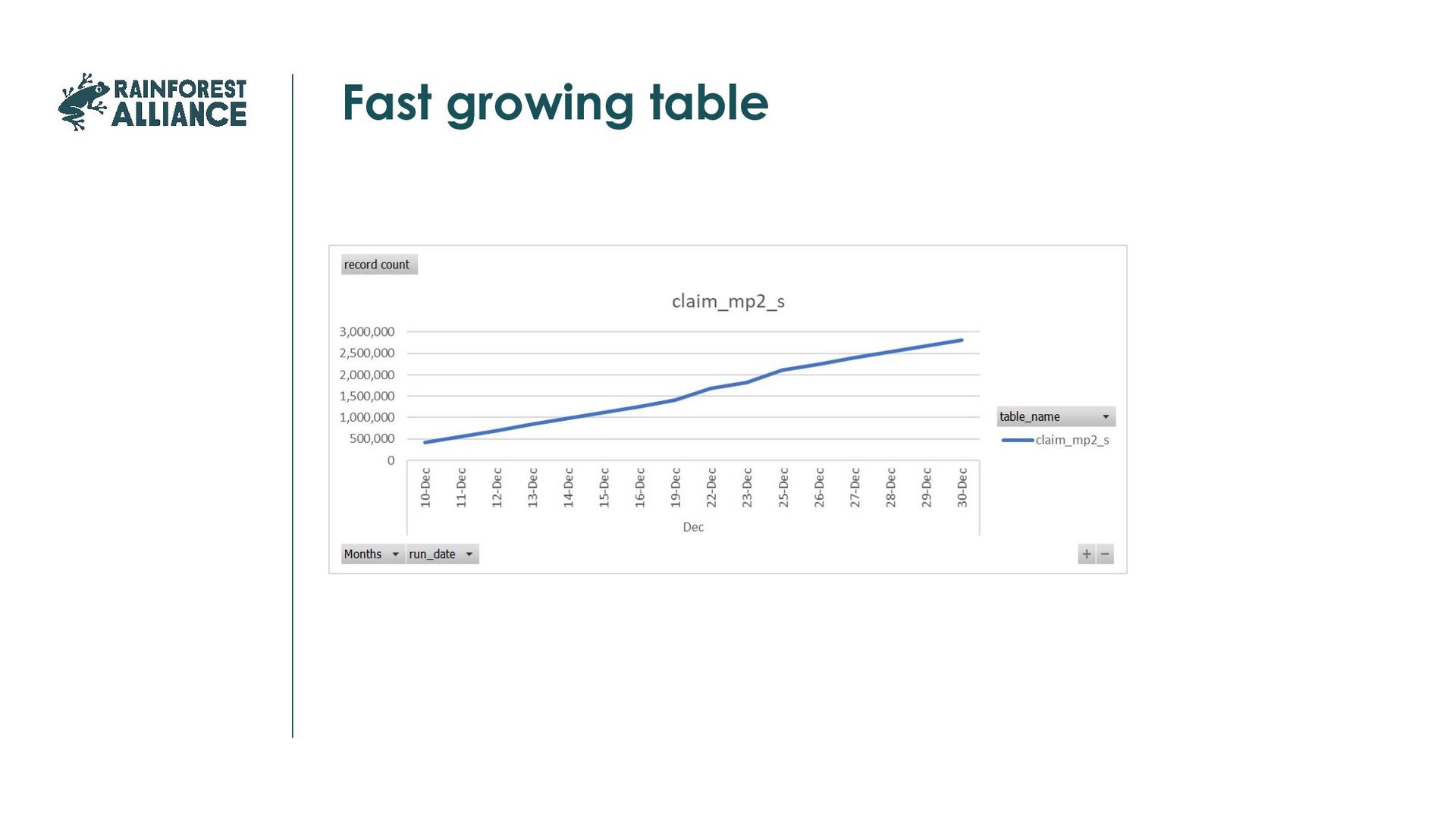
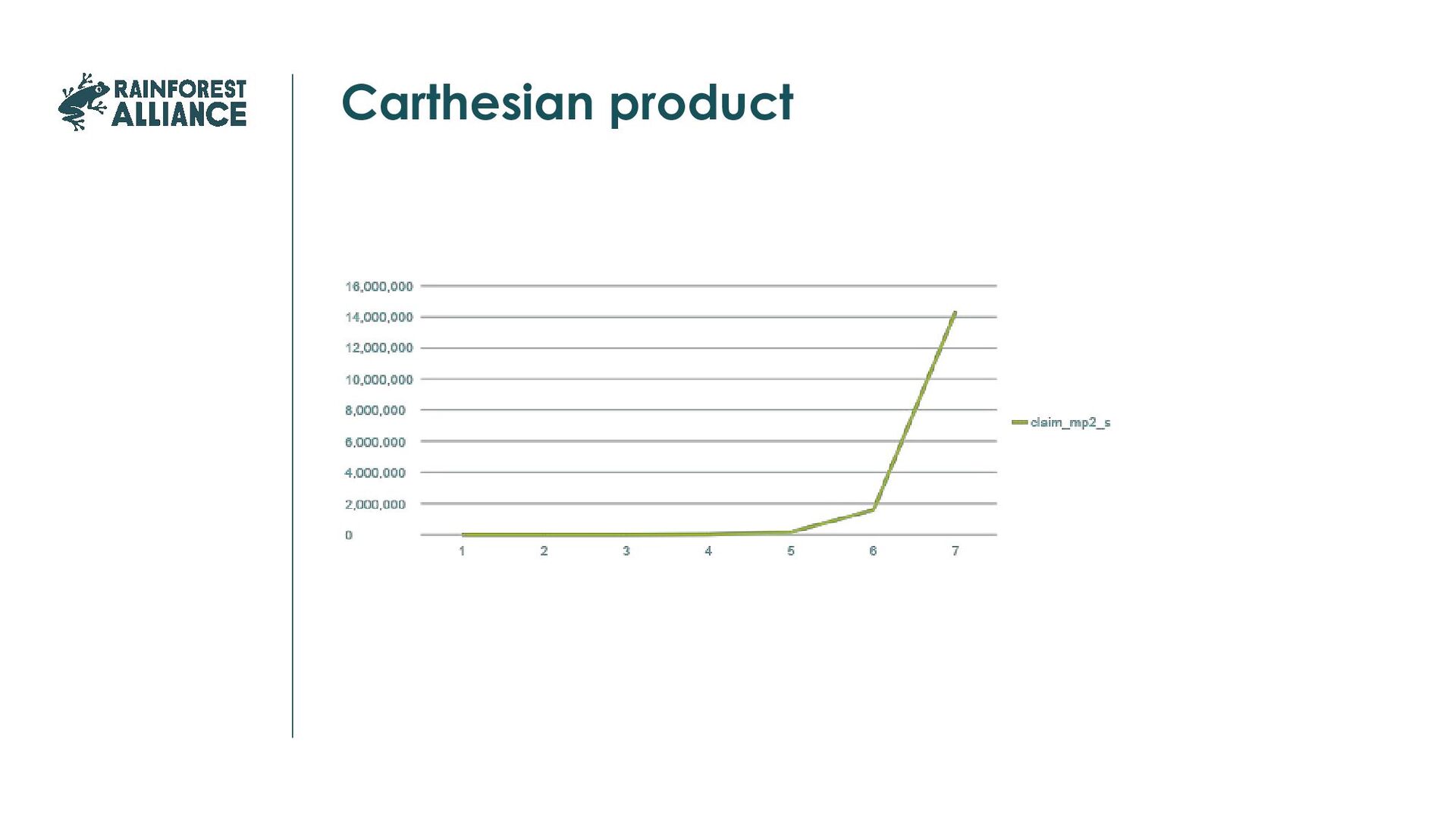
was correct, compare statistics with previous loads. Keep in mind that exception may only become visible after some time. How to do it, depends on your business and data. Examples of signals: Record counts: >2% growth, >0,5%, extra alert if the growth is more than twice last month average Negative growth for more than 1 day More than 3 days 0 growth for all tables except reference tables
Supermarket chain, shop number in the sales table. Usually no change, if there is a change the business should know. Code fields: Should be stable, if growth you need a sanity check Number of empty values: Either a fixed value (known errors), or a fixed percentage If there is a big change, investigation is needed. Sometimes it might be easier to look at non-empty values
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}