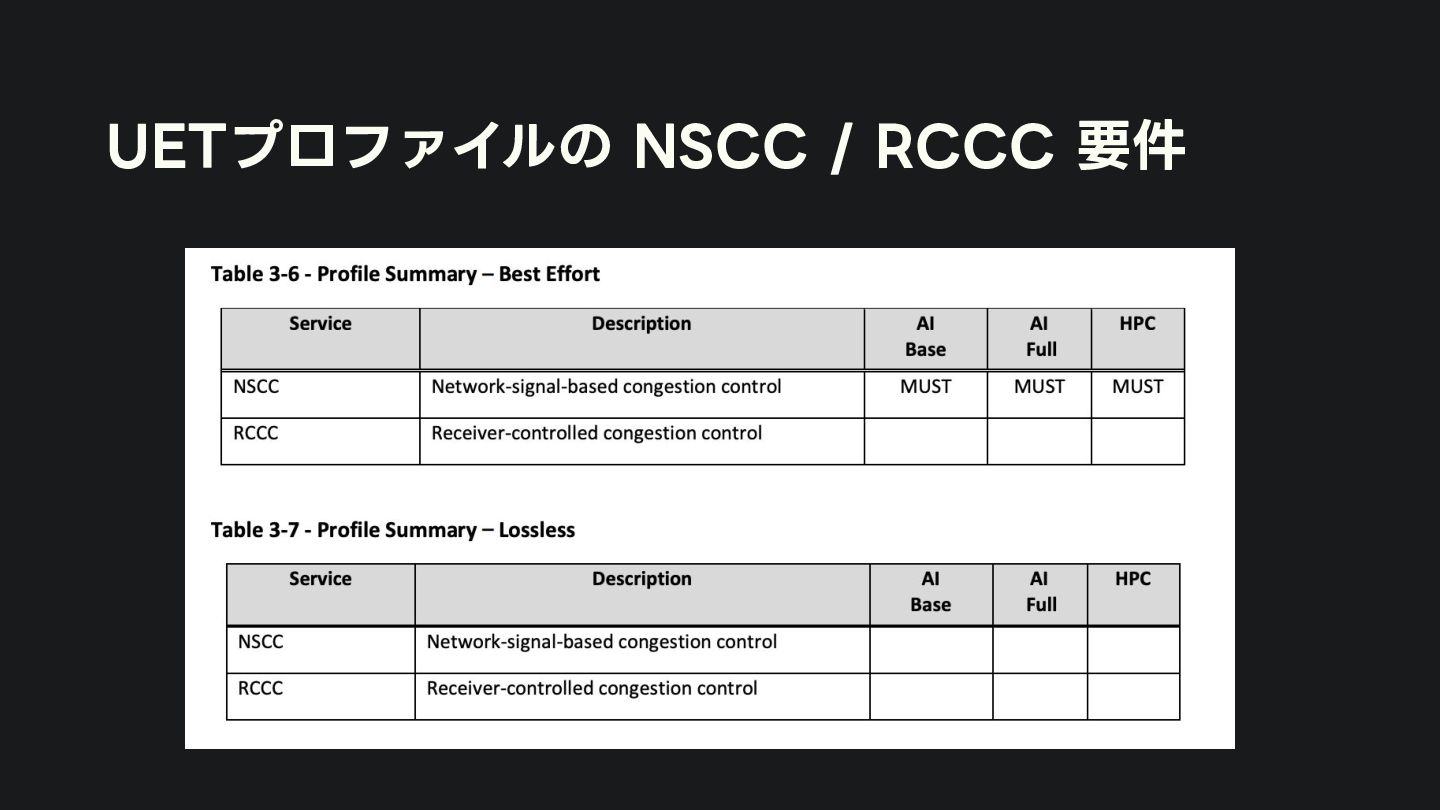
• AI Base:*CCL, UDのサポート • AI Full:学習と推論アプリケーション • HPC:広範なHPCアプリケーション OFA 2025 Webinar Series Webinar #1 - Libfabric: Getting Started with Ultra Ethernet https://www.youtube.com/watch?v=cgiGbny5vdo
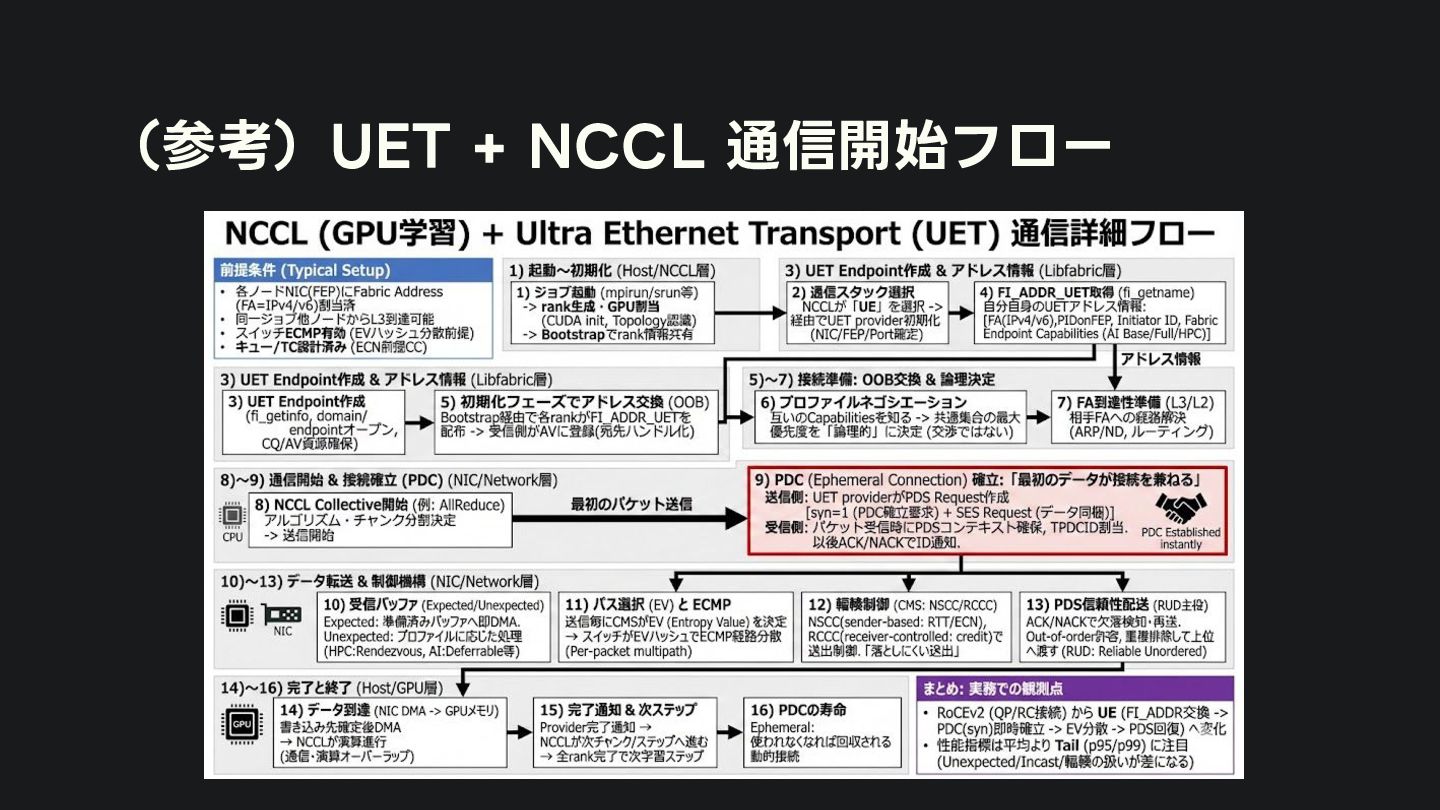
FEPアドレスには「そのFEPがサポートするプロファイル集合」が載り、 送受で共通集合がある場合は優先度最大( AI Base=0, AI Full=1, HPC=2) が選ばれる ◦ 例:片側AI Full、片側HPCのときは、制約付きで相互運用 (AI Fullの範囲に操作を制限、HPC側はdeferrable sendを通常send扱い) ◦ 両端が AI Base / AI Full / HPC を全部サポートしている場合、共通集合のうち優先度が一番高いHPCにな り、AI Baseにはならない → ベンダが独自にadvertiseするcapabilityを制限する実装を入れる?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
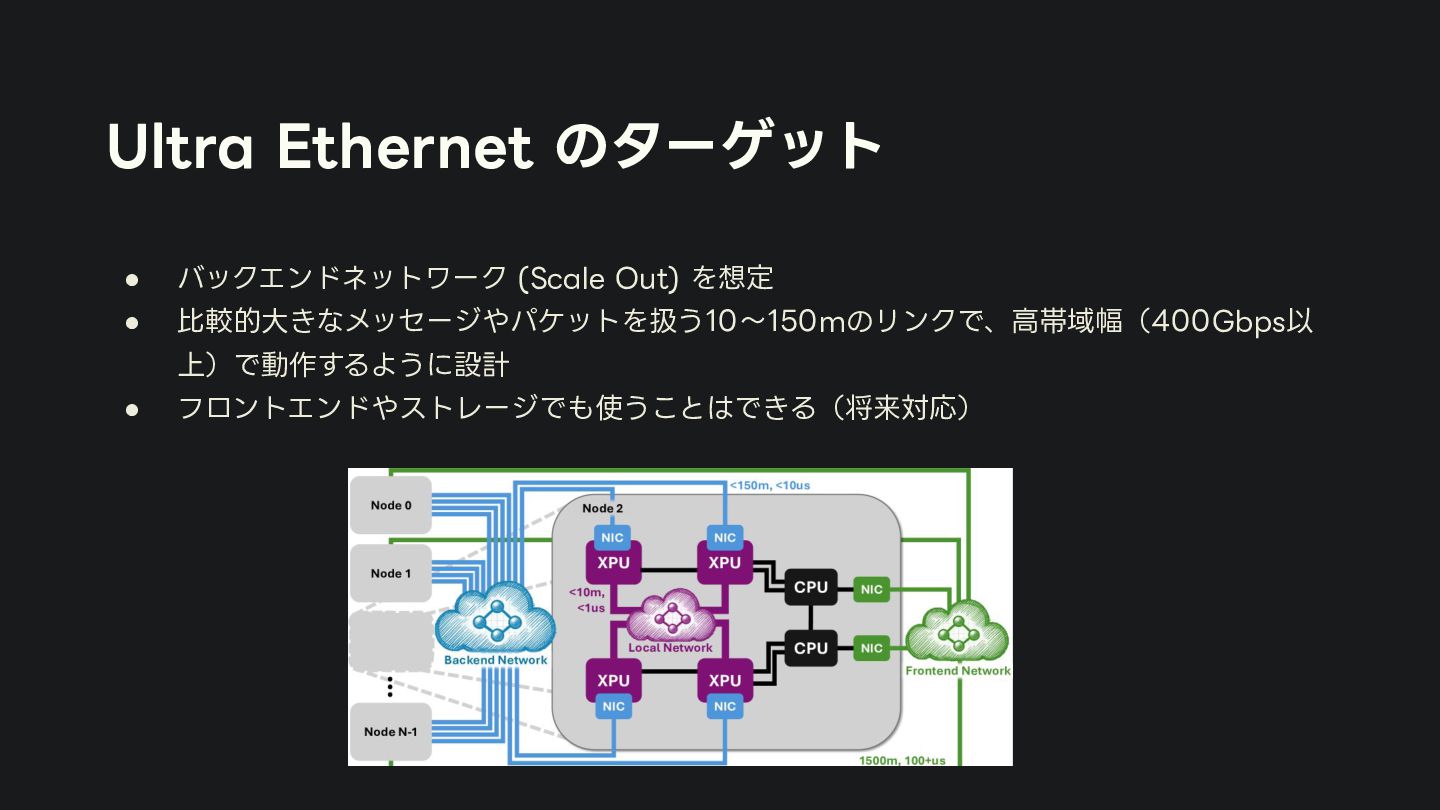{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
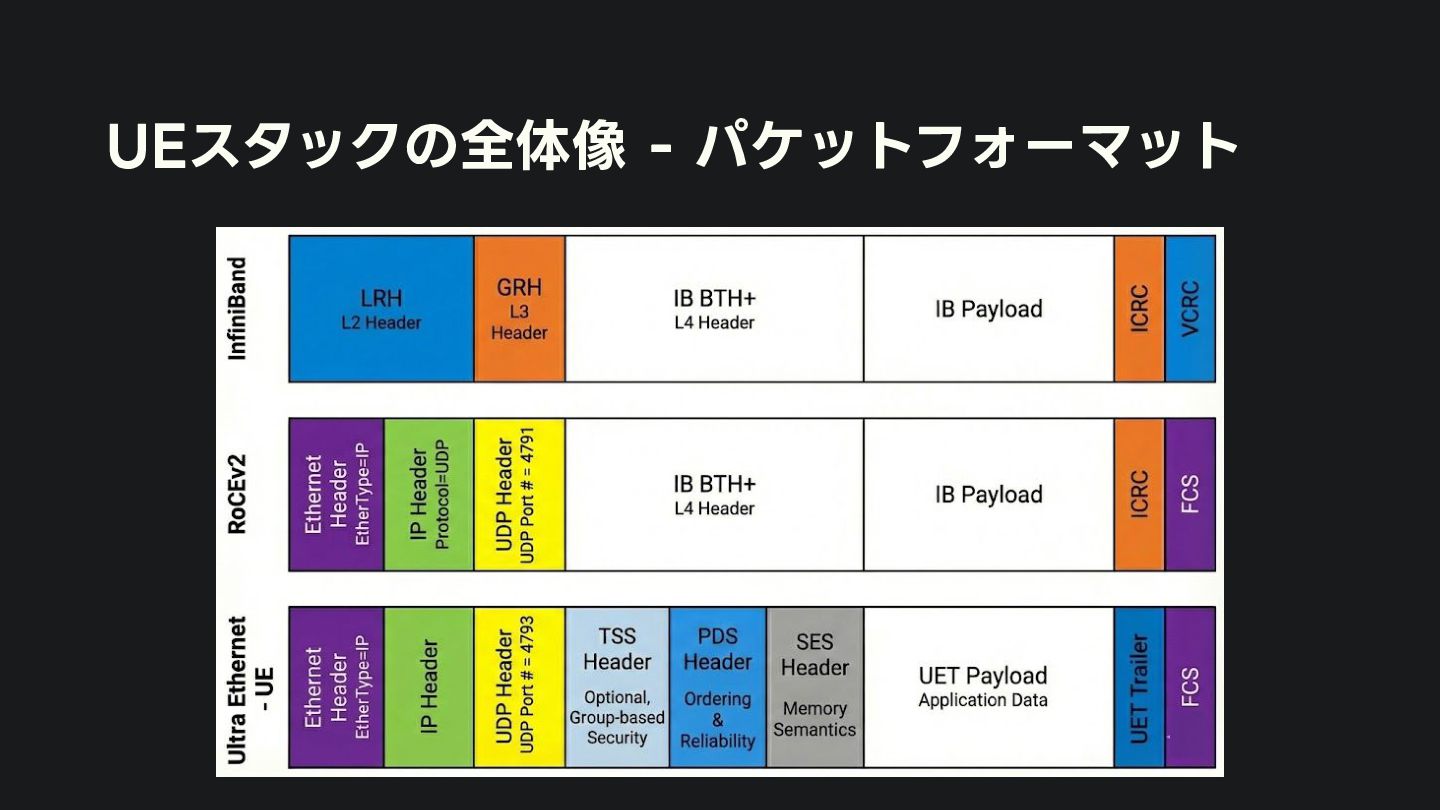{kind=link}
{kind=link}
{kind=link}
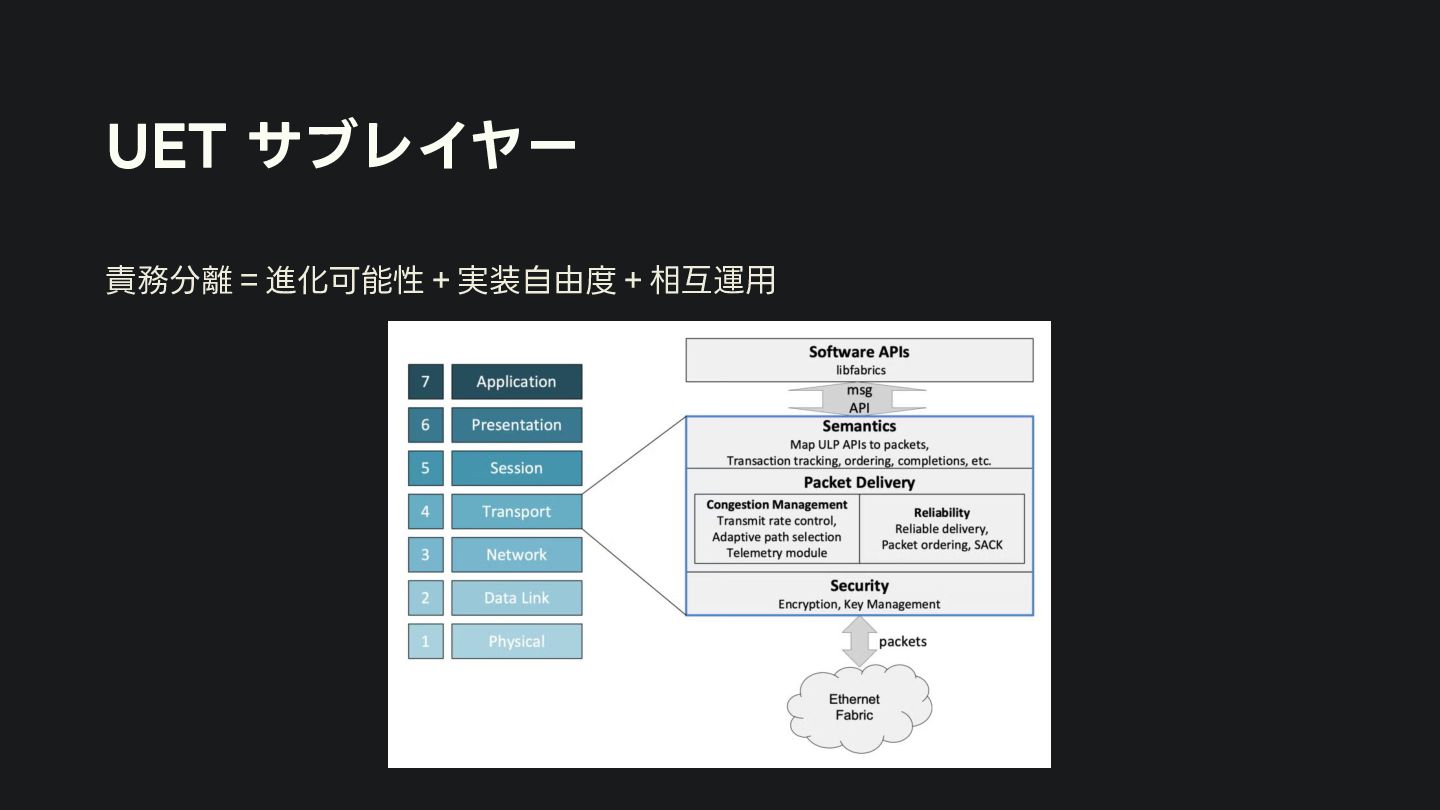{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
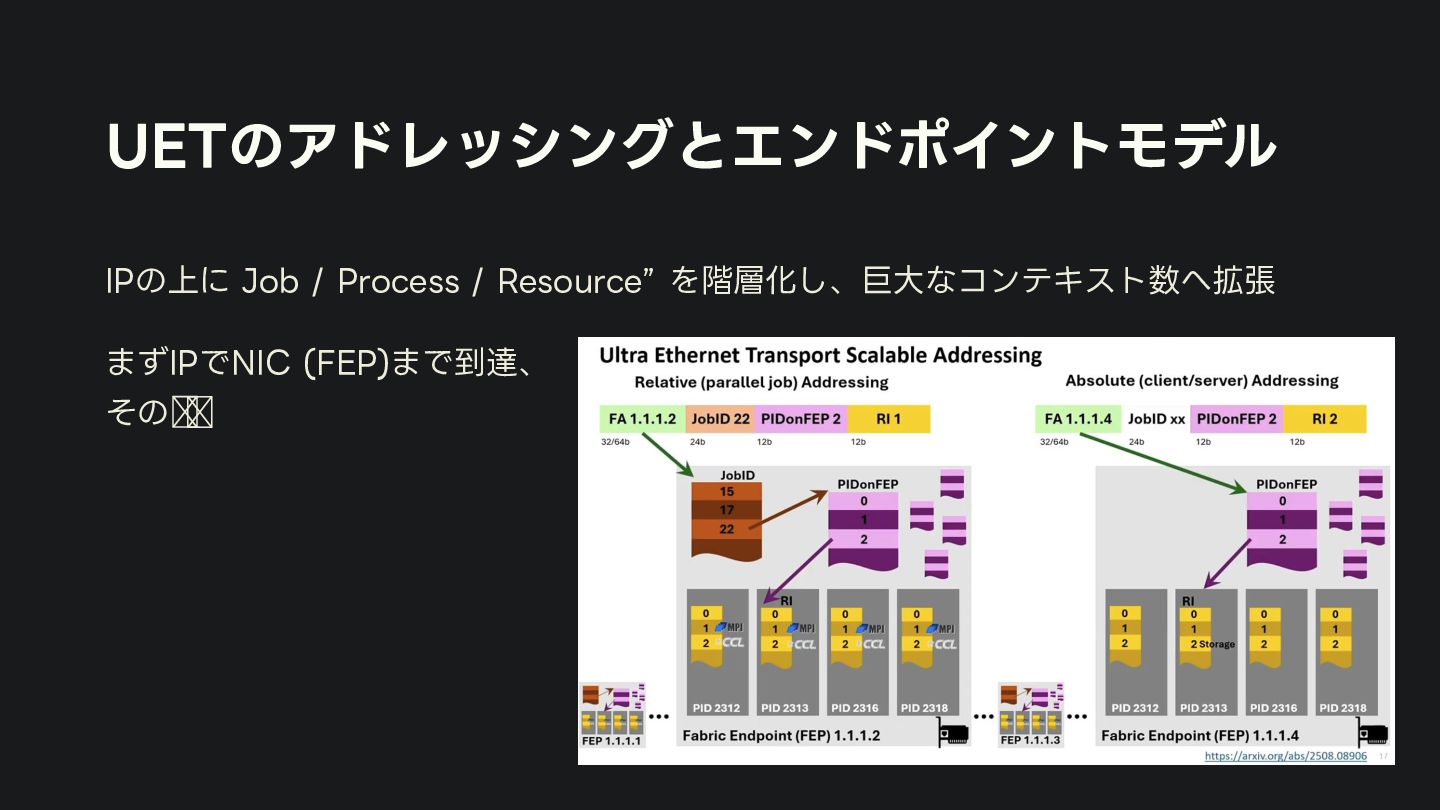{kind=link}
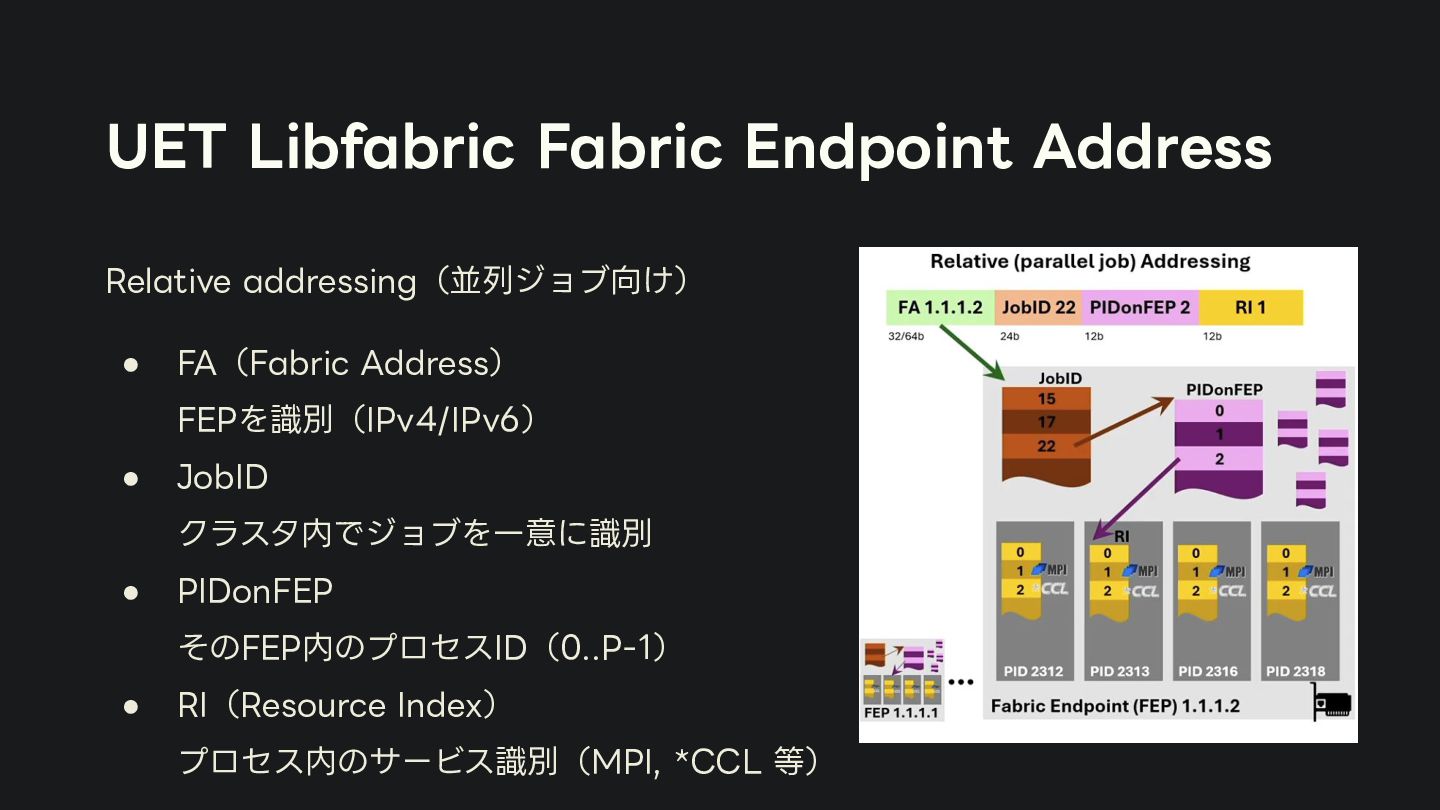{kind=link}
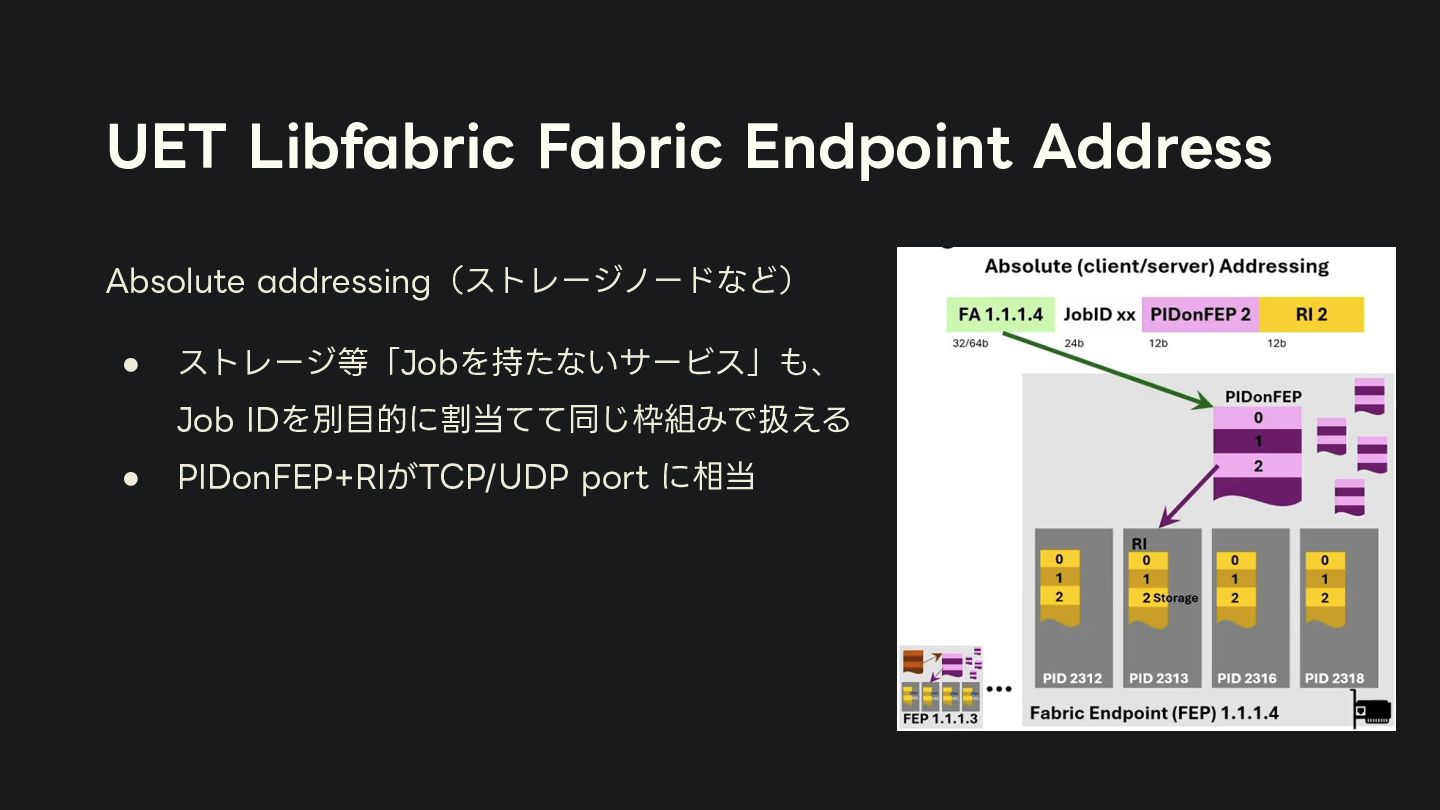{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
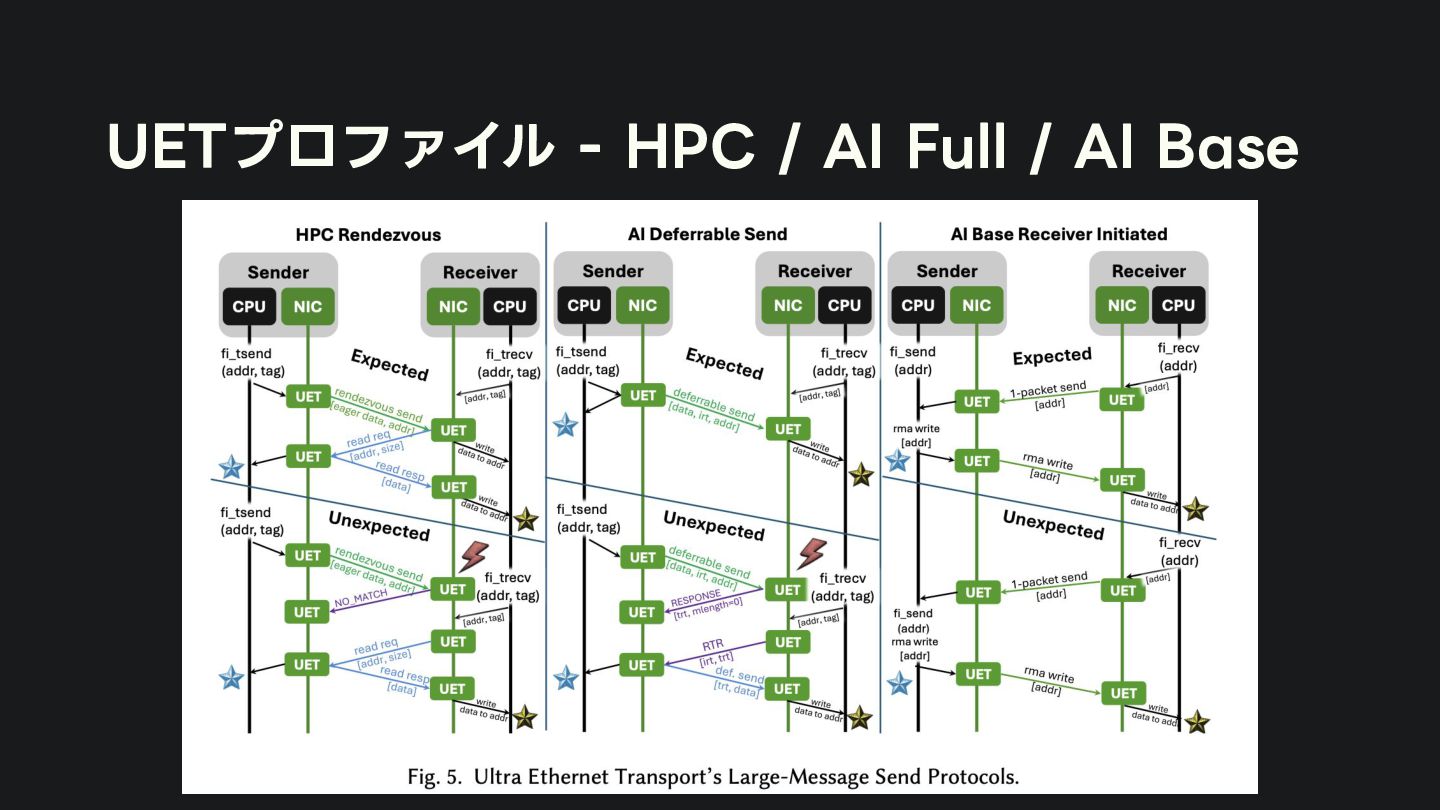{kind=link}
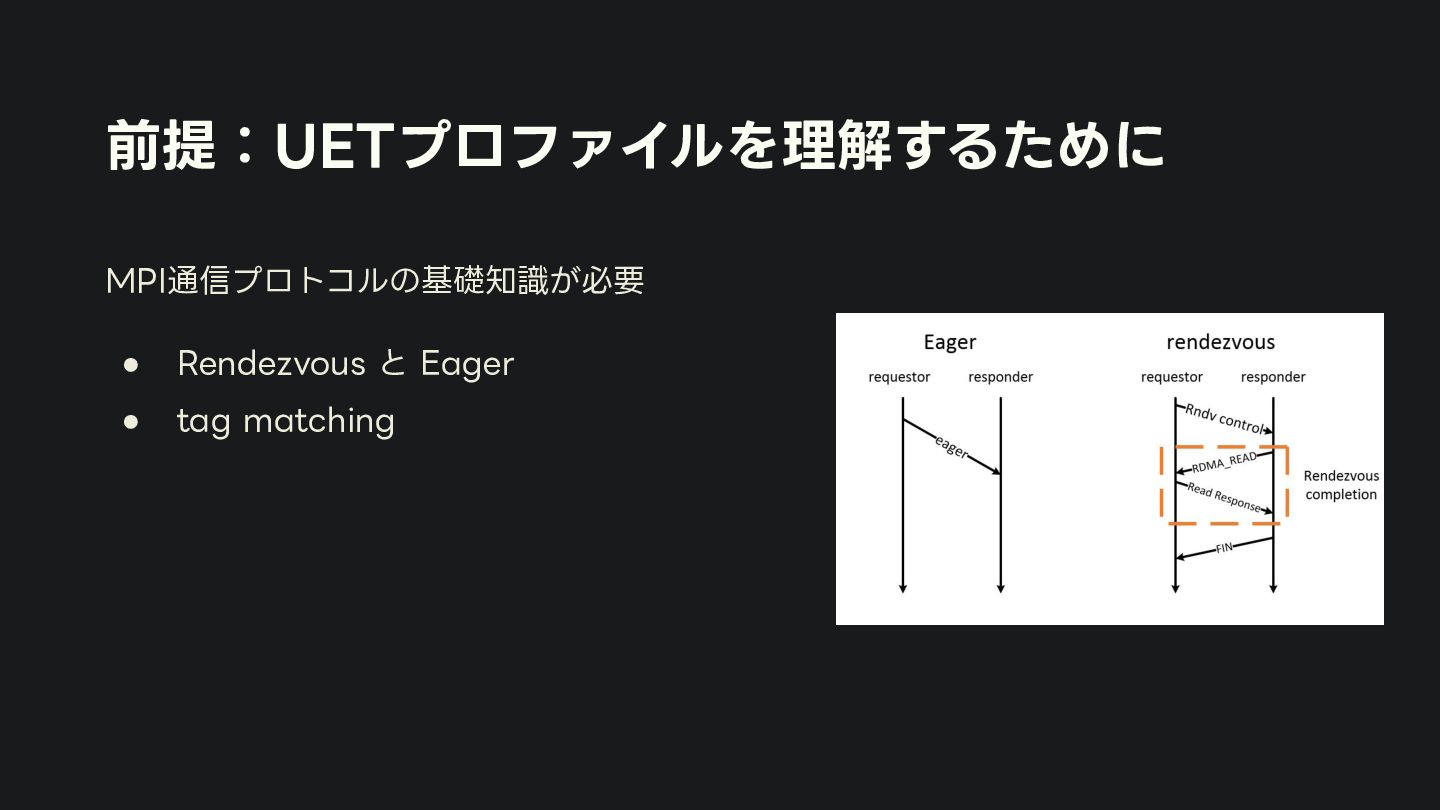{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
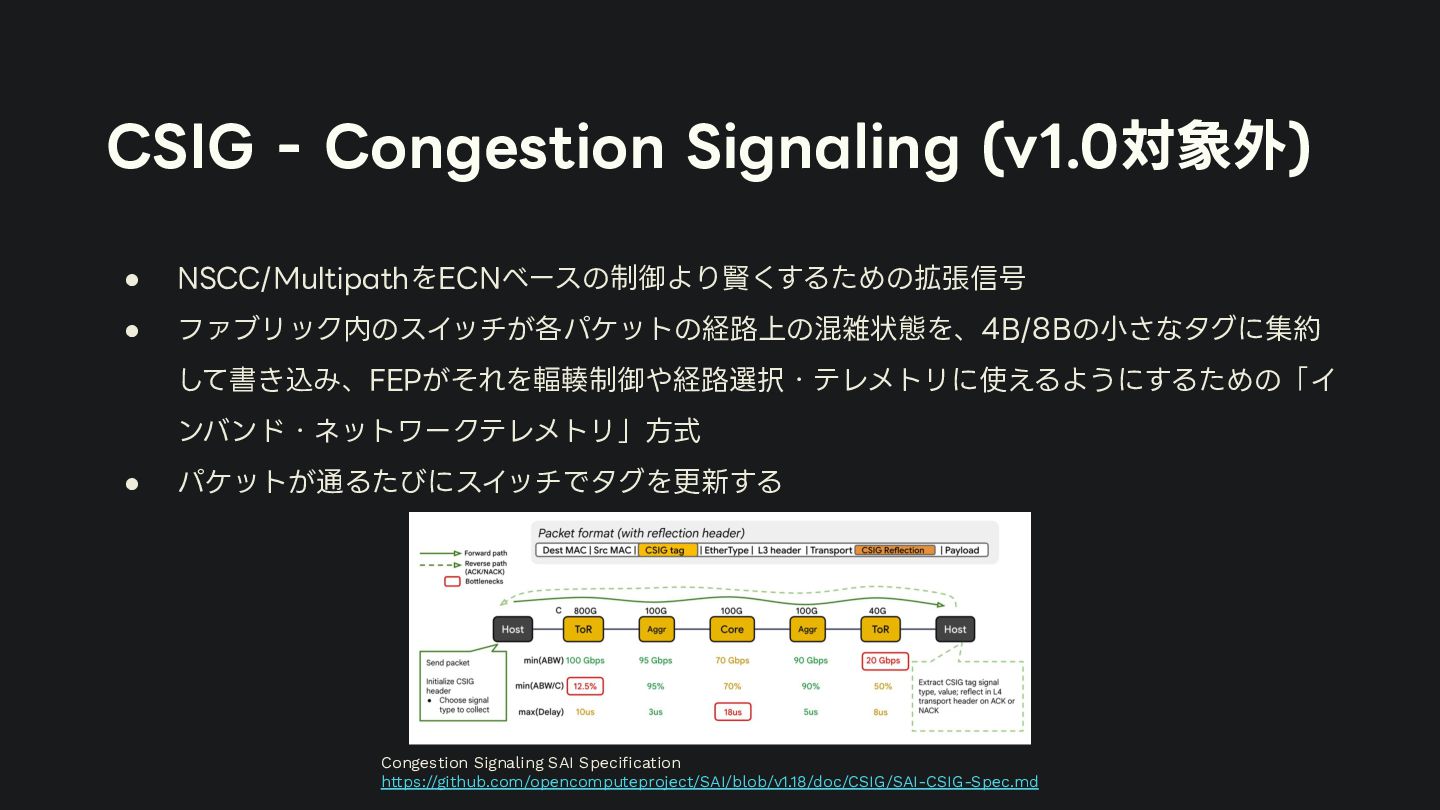{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
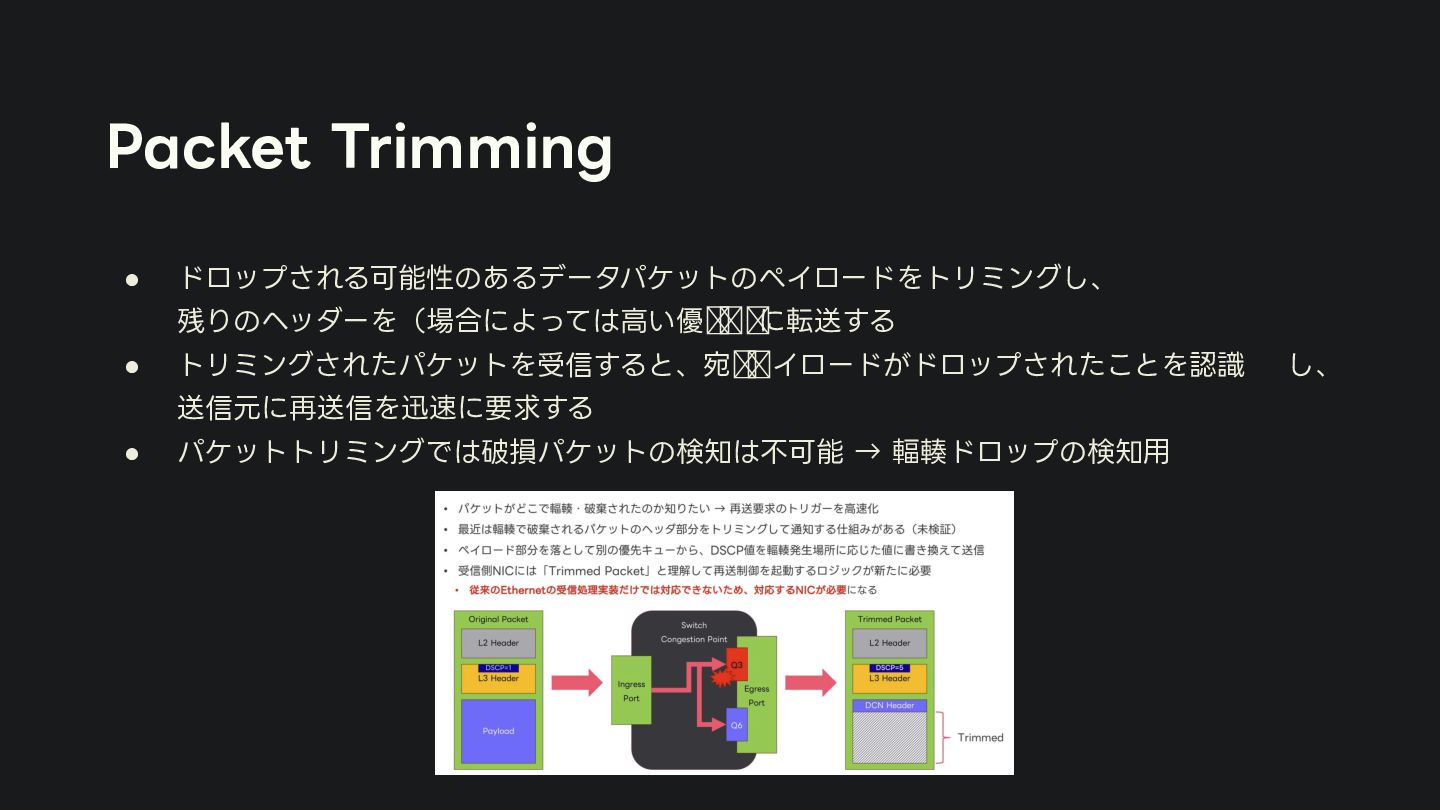{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
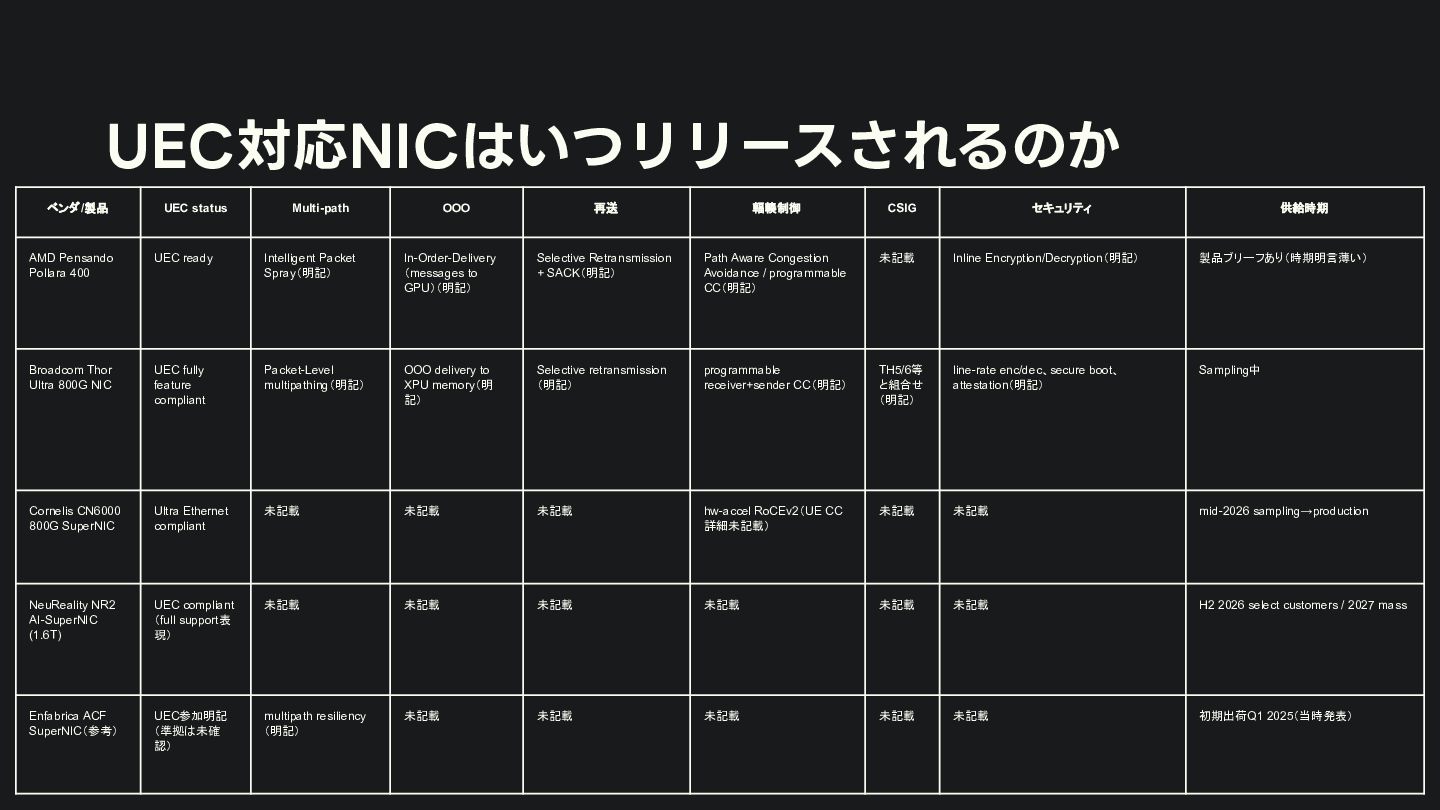{kind=link}
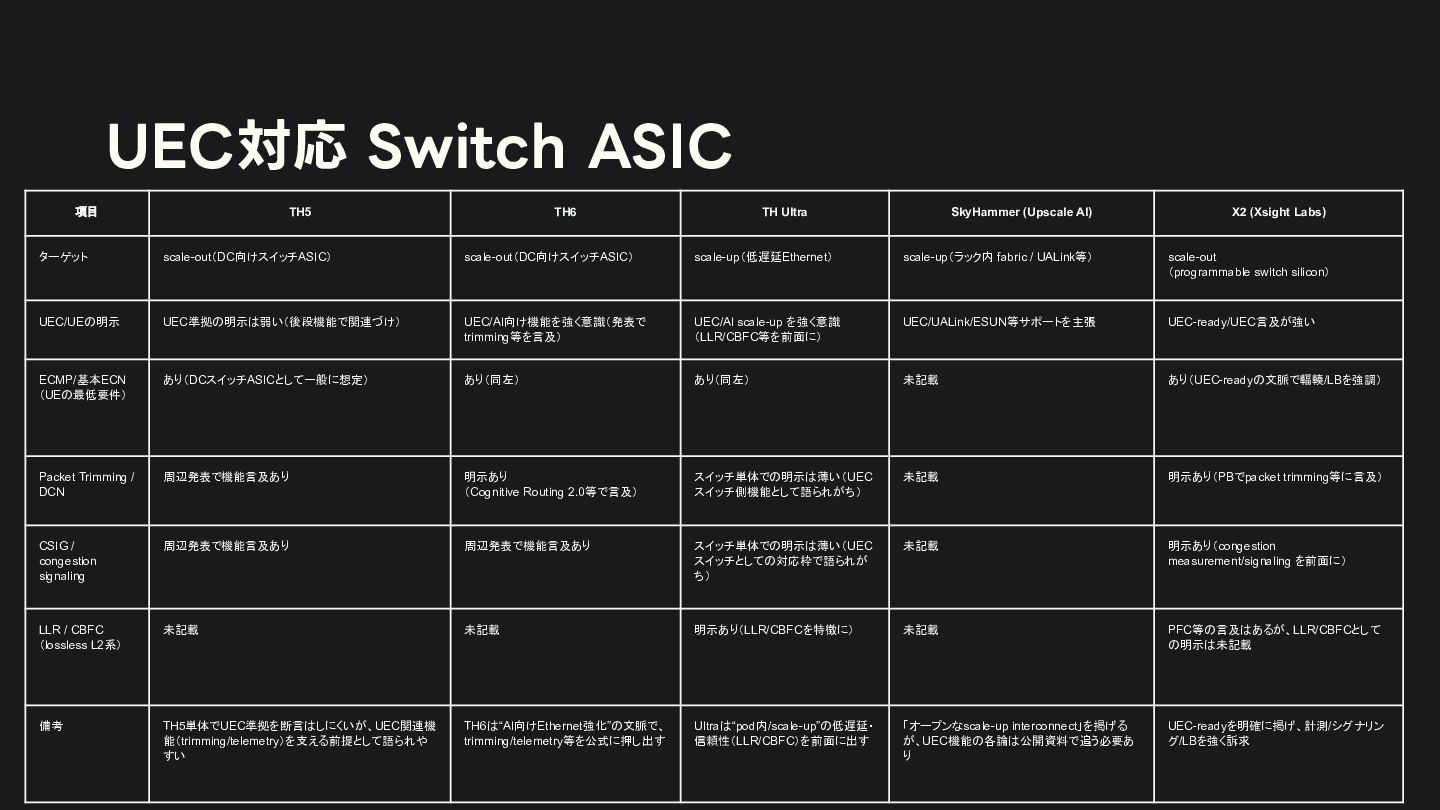{kind=link}
{kind=link}
{kind=link}
{kind=link}