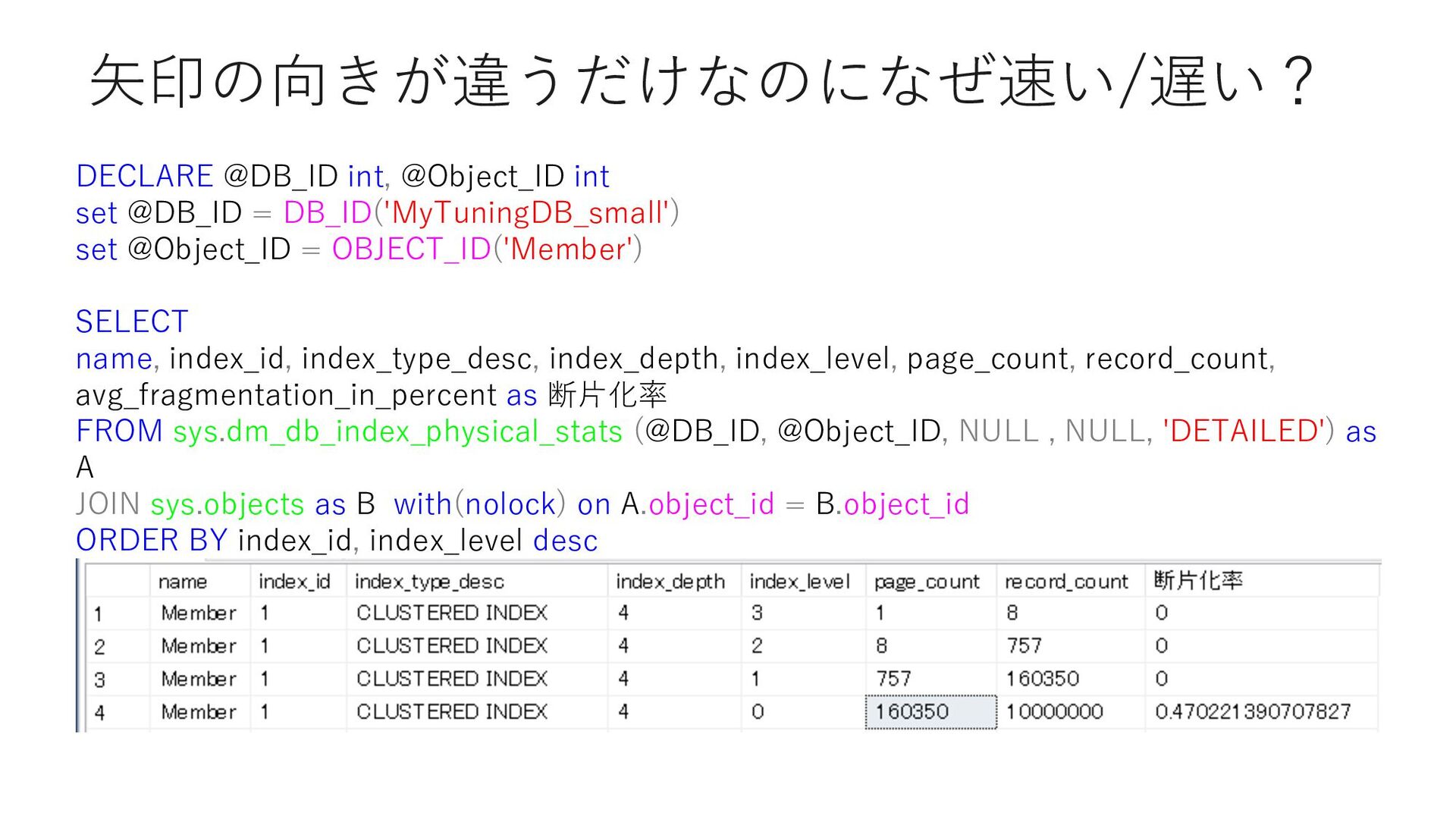
set @Object_ID = OBJECT_ID('Member') SELECT name, index_id, index_type_desc, index_depth, index_level, page_count, record_count, avg_fragmentation_in_percent as 断⽚化率 FROM sys.dm_db_index_physical_stats (@DB_ID, @Object_ID, NULL , NULL, 'DETAILED') as A JOIN sys.objects as B with(nolock) on A.object_id = B.object_id ORDER BY index_id, index_level desc
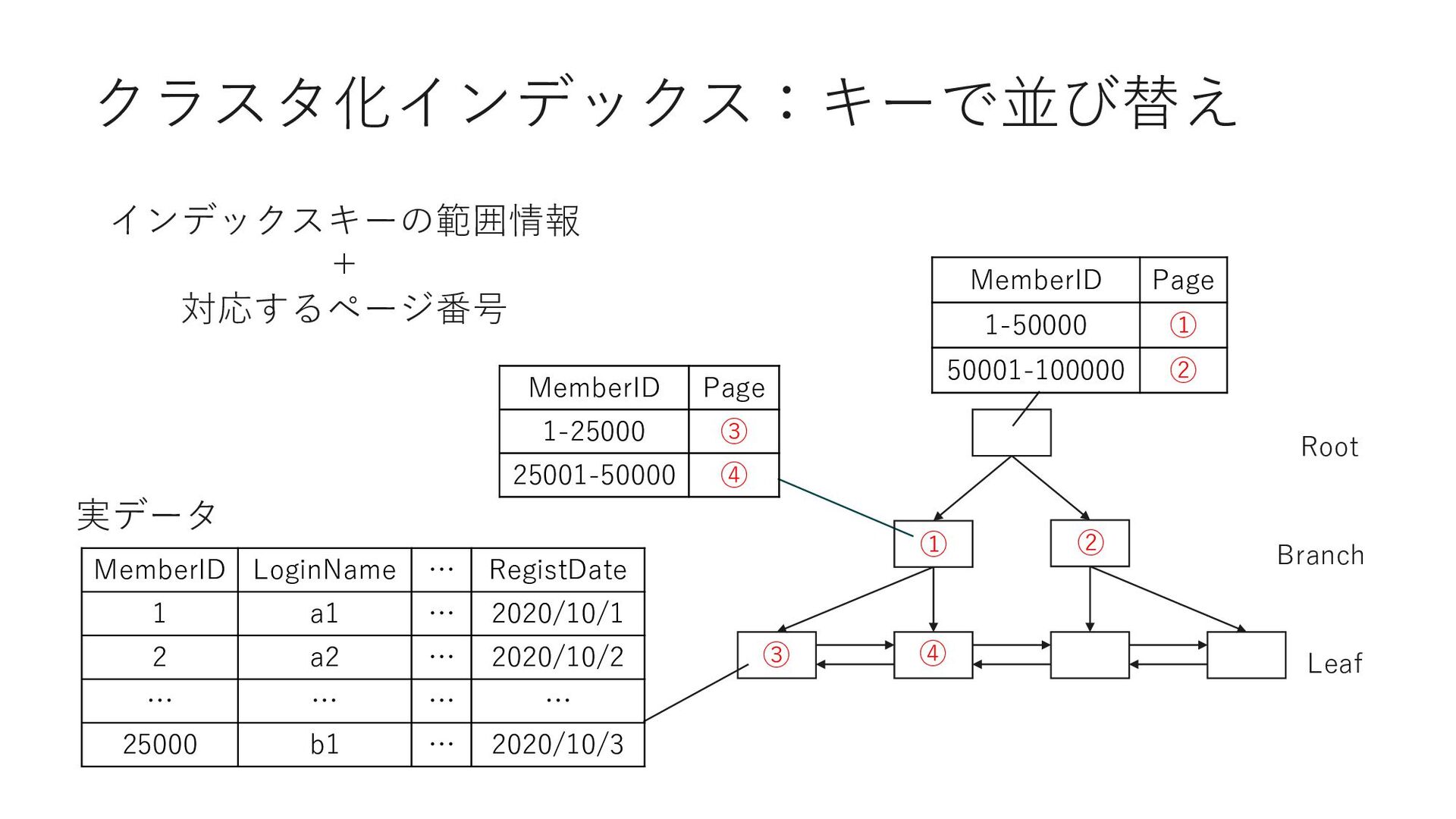
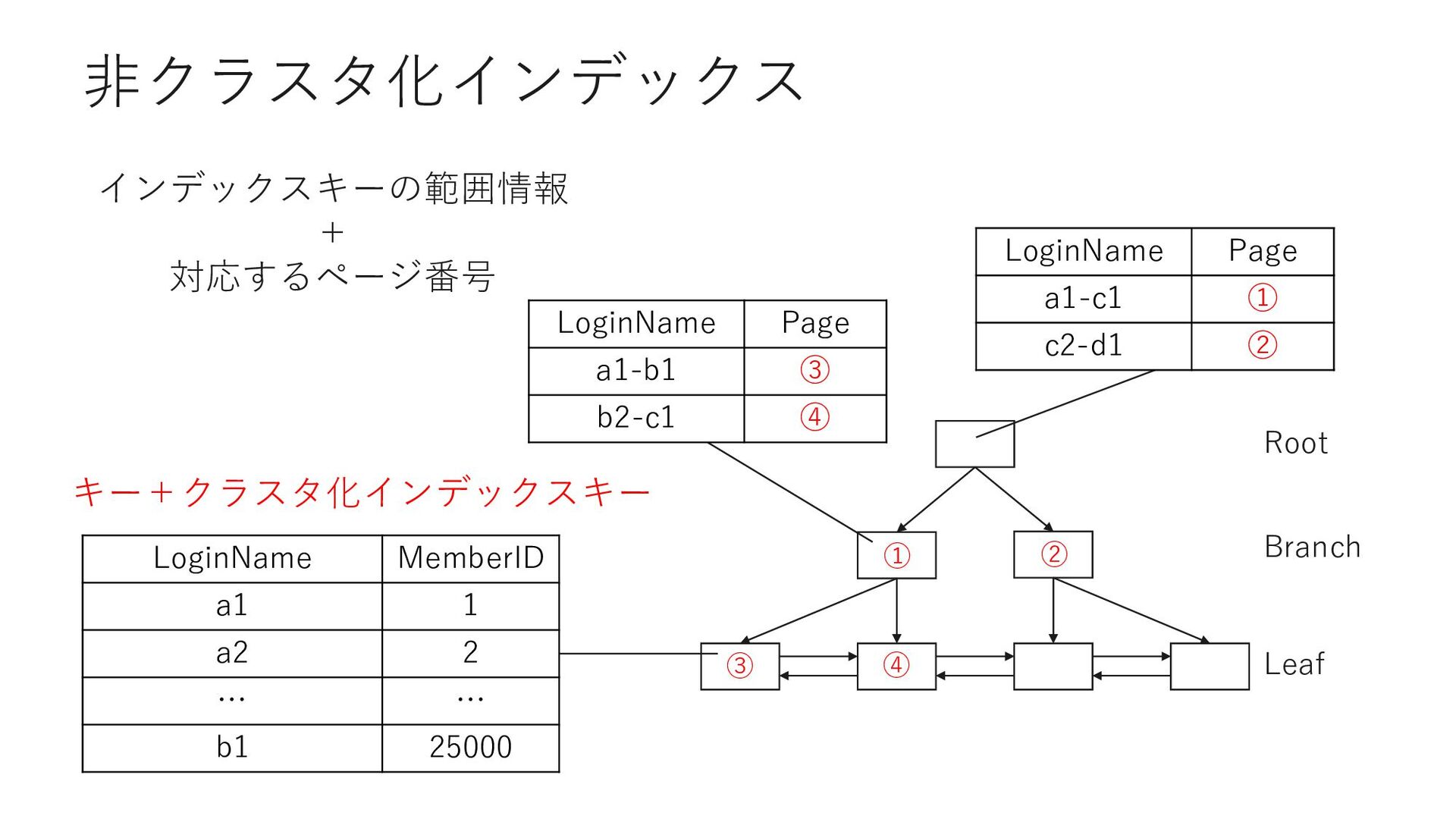
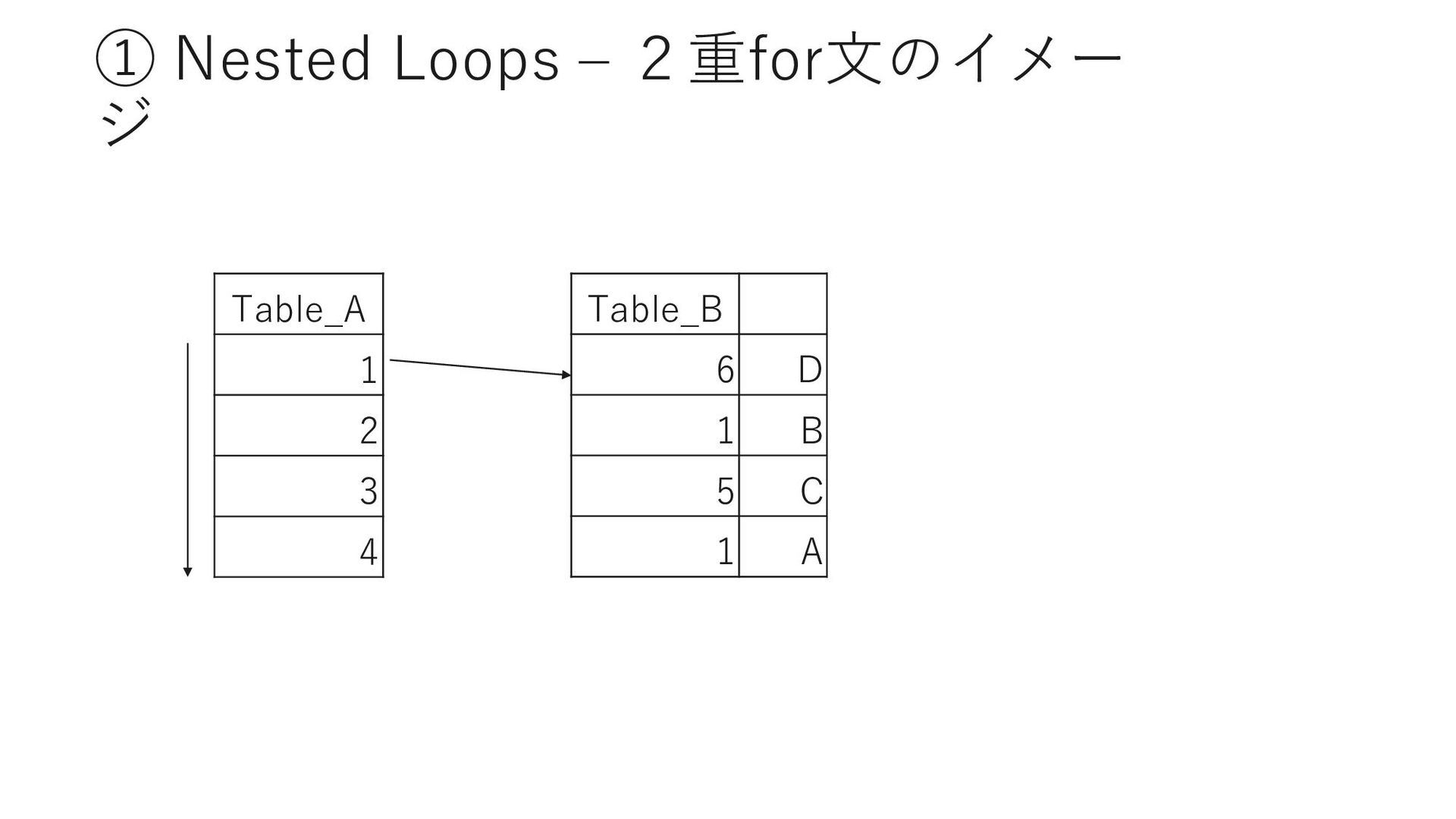
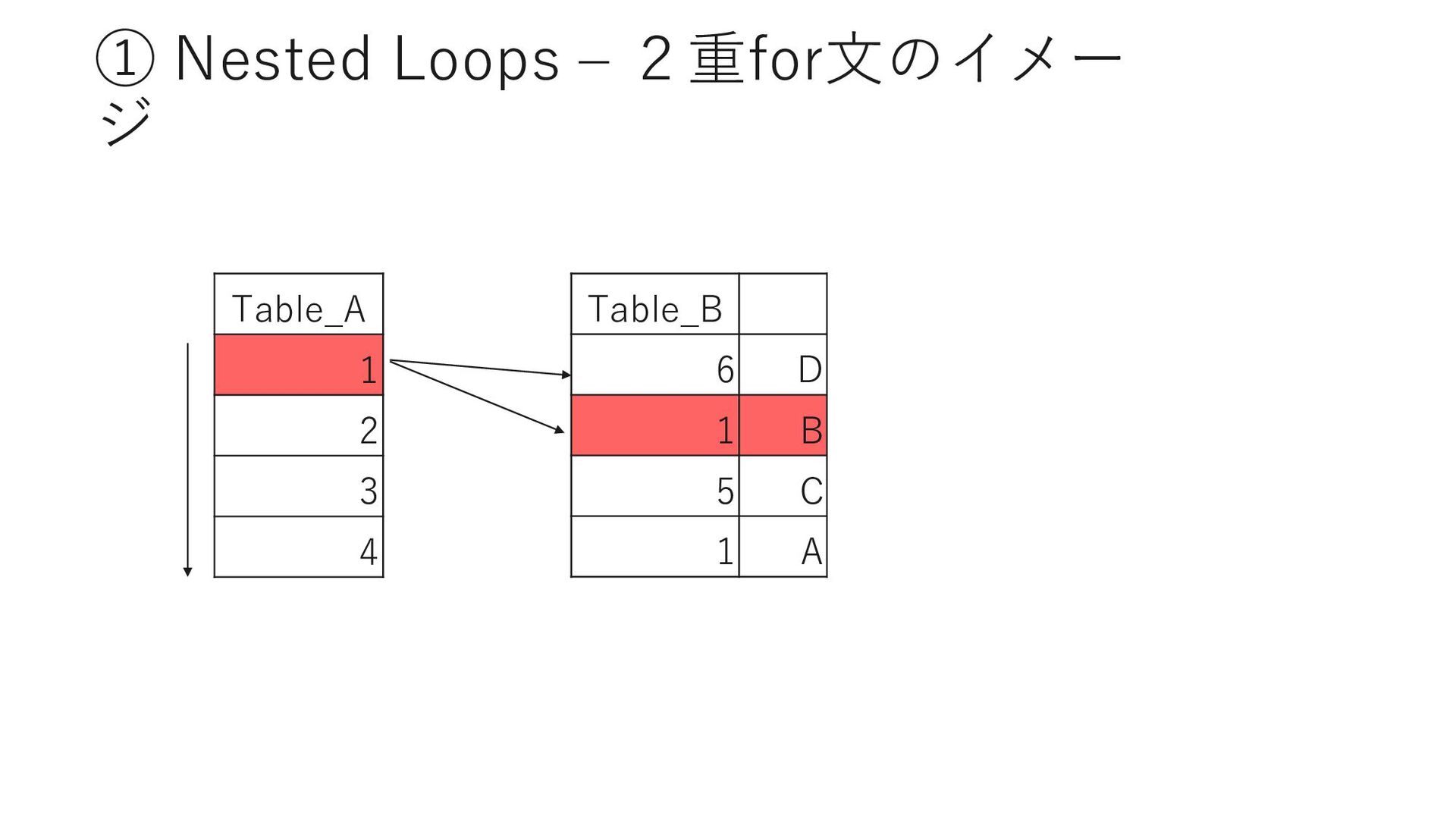
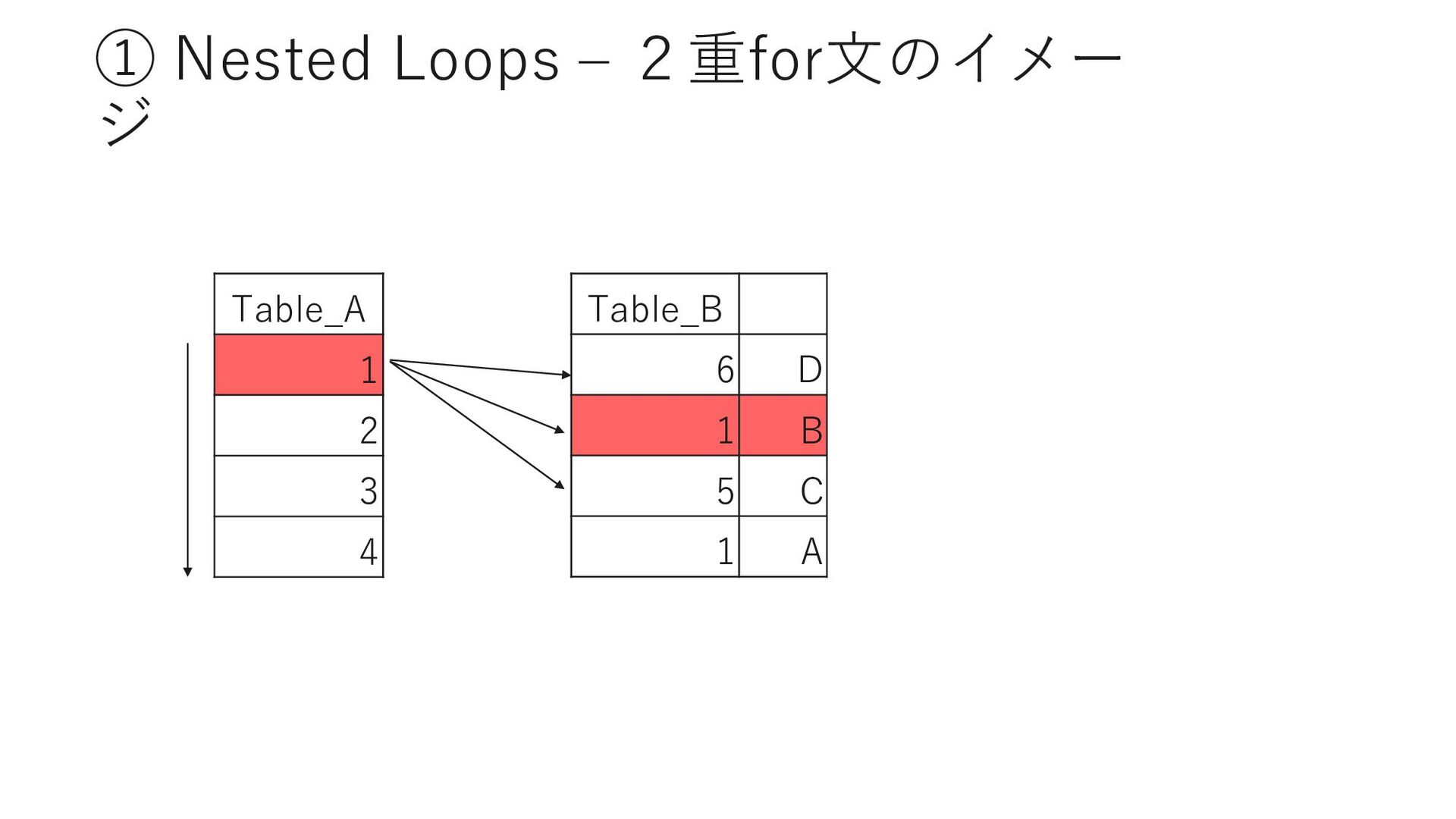
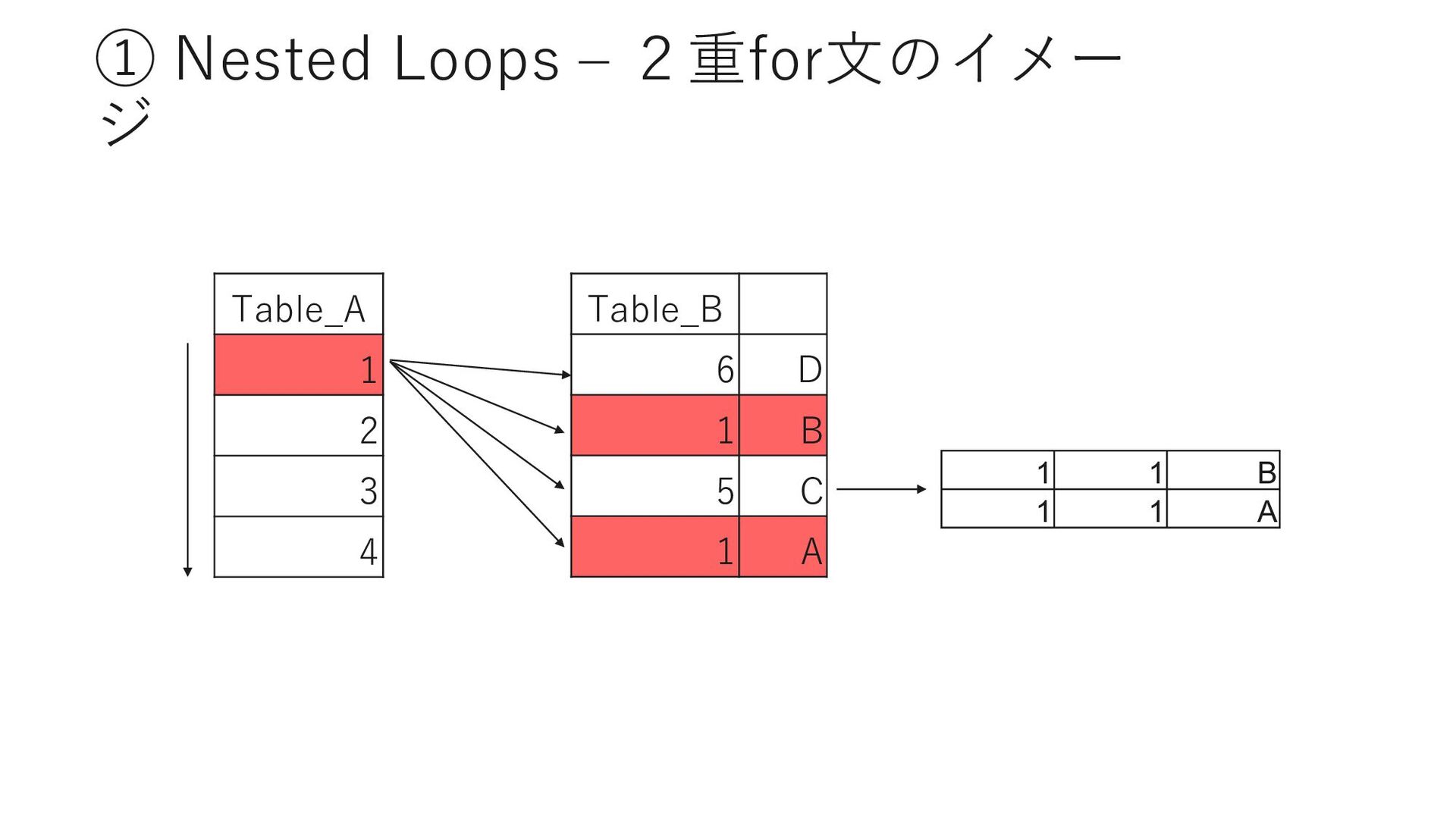
D Page Adena 40 ① Barrett 25 ② Sei PrefectureID Page Adena 40 ③ Adrian 3 ④ Sei PrefectureID MemberID Adena 40 523 Adena 42 613 作成時に指定したカラムの順序で インデックスキーが作成される
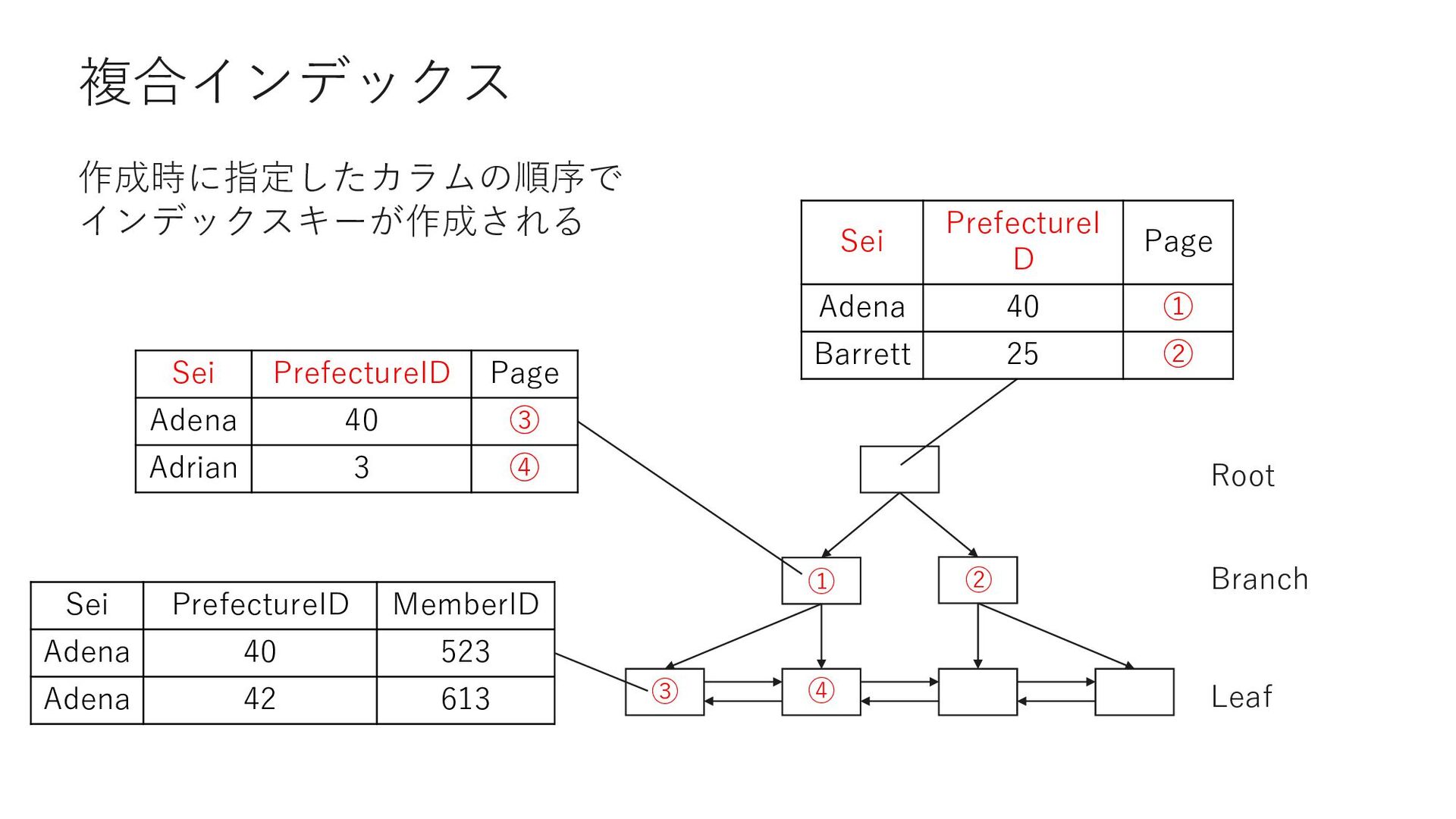
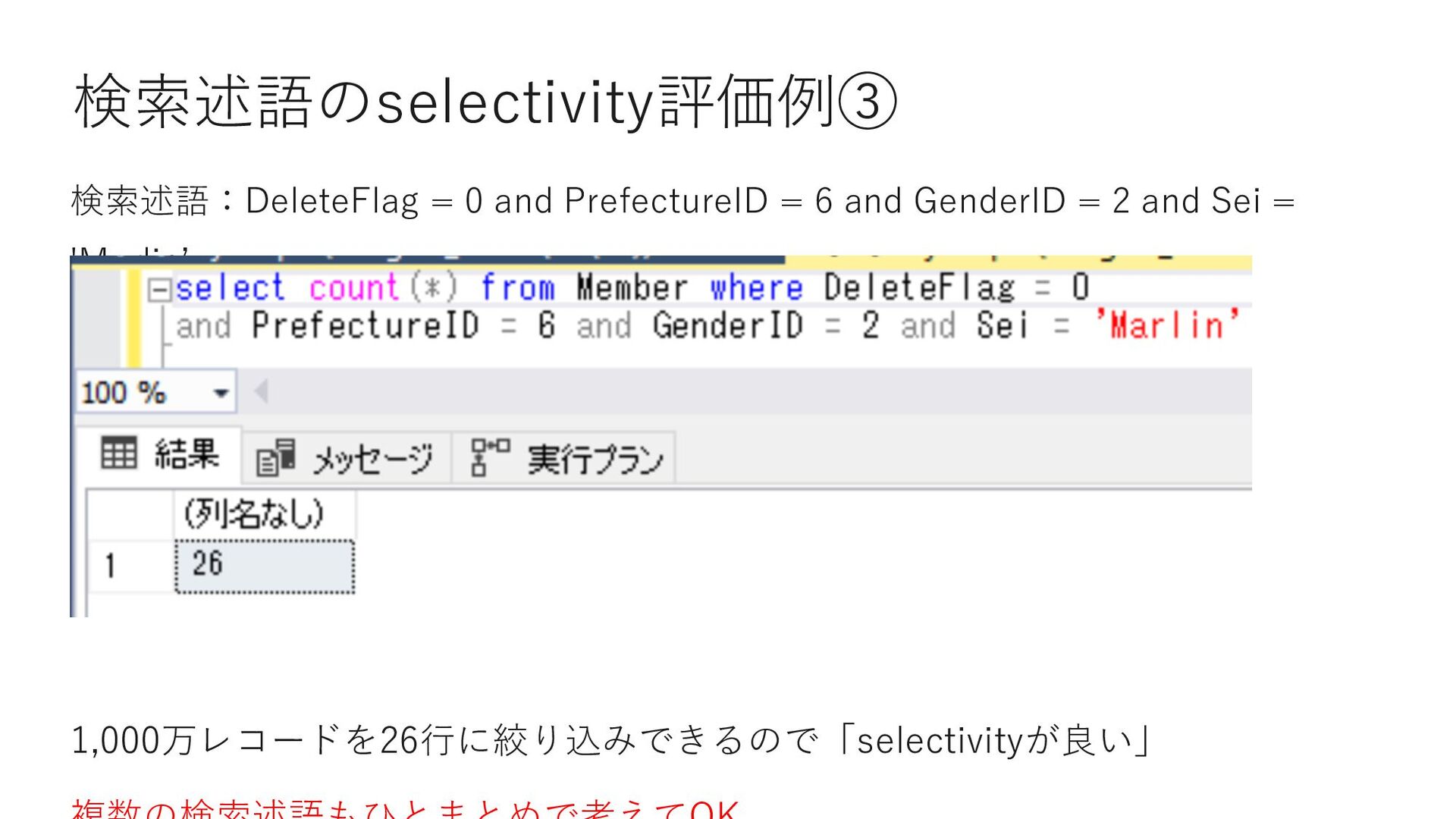
AND PrefectureID = 1 → インデックス作成時に指定したカラムの両⽅が検索条件に含まれる SELECT COUNT(*) FROM Member WHERE Sei = 'Adenaʻ → インデックス作成時に指定した「先頭のカラム」が検索条件に含まれる SELECT COUNT(*) FROM Member WHERE PrefectureID = 1 → インデックス作成時に指定したカラムは含むが、「先頭のカラム」が検索条件に 含まれていない • Index Seekで検索されるケース • Index Seekで検索が⾏われないケース ⇒ インデックスの先頭には検索に使われる頻度の多い項⽬を指定する
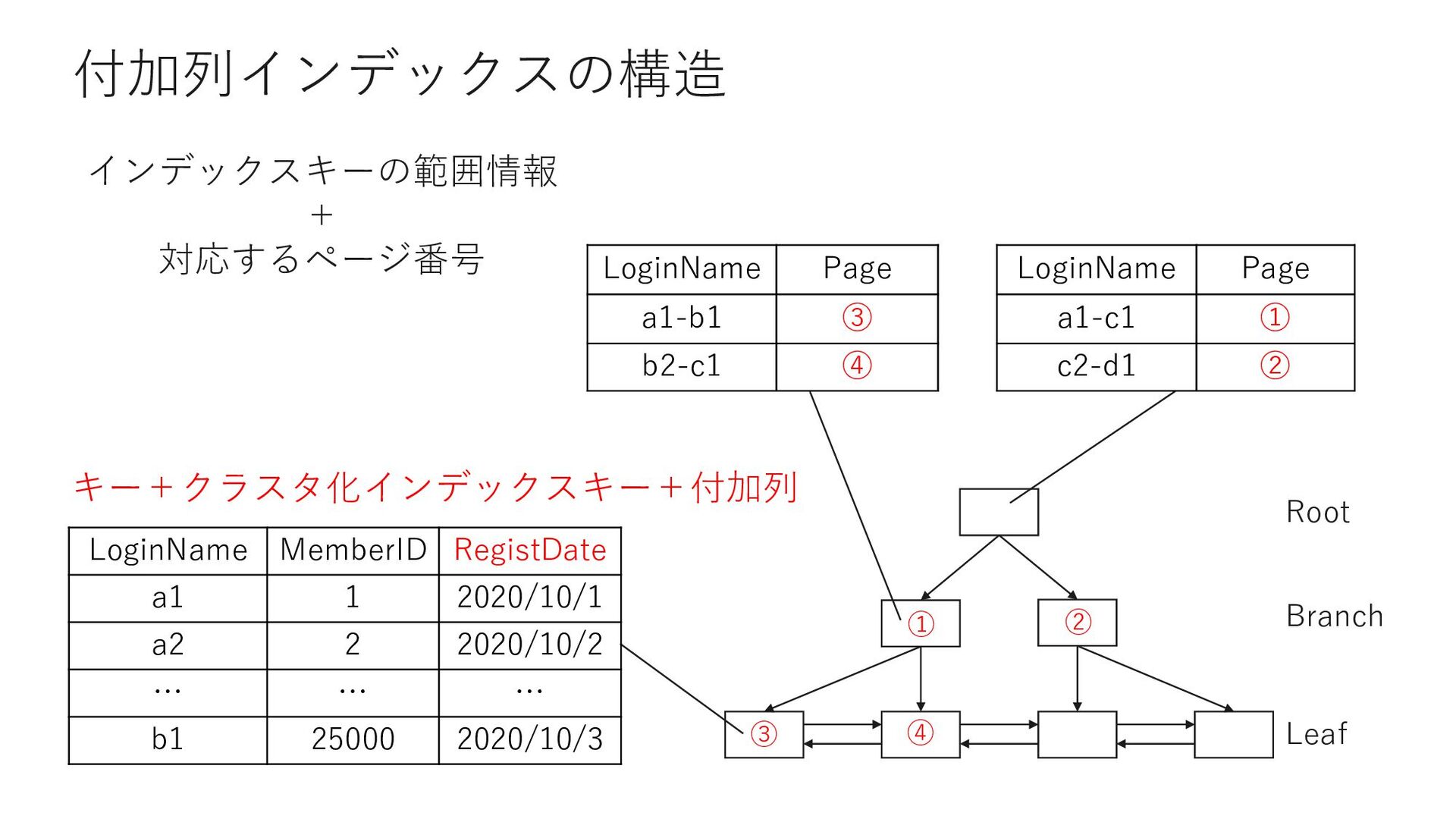
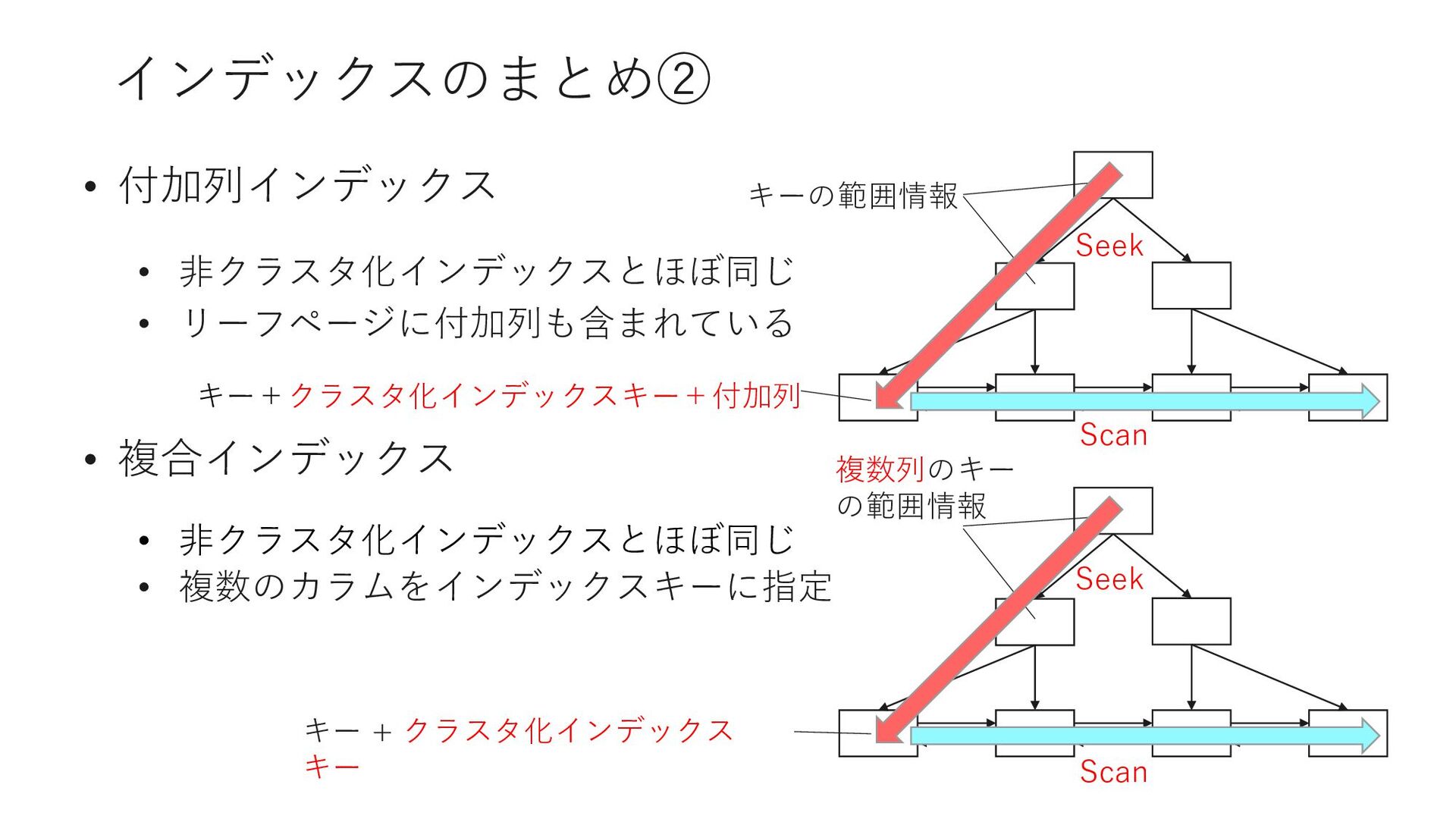
ASC) INCLUDE (RegistDate) キー参照が発⽣しないインデックスを「カバリングインデックス」 SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167' インデックスキー インデックスキー INCLUDE カラム クエリに必要なカラムをカバーするインデックスになっている =カバリングインデックス
INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName] ASC) INCLUDE (RegistDate) SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167' SELECT LoginName, RegistDate, Sei FROM Member WHERE LoginName = 'Tawny265167'
,index_type_desc ,index_depth ,index_level ,page_count ,record_count FROM sys.dm_db_index_physical_stats (DB_ID(), @OBJECT_ID, NULL , NULL, 'DETAILED') as A JOIN sys.objects as B on A.object_id = B.object_id ORDER BY index_id, index_level
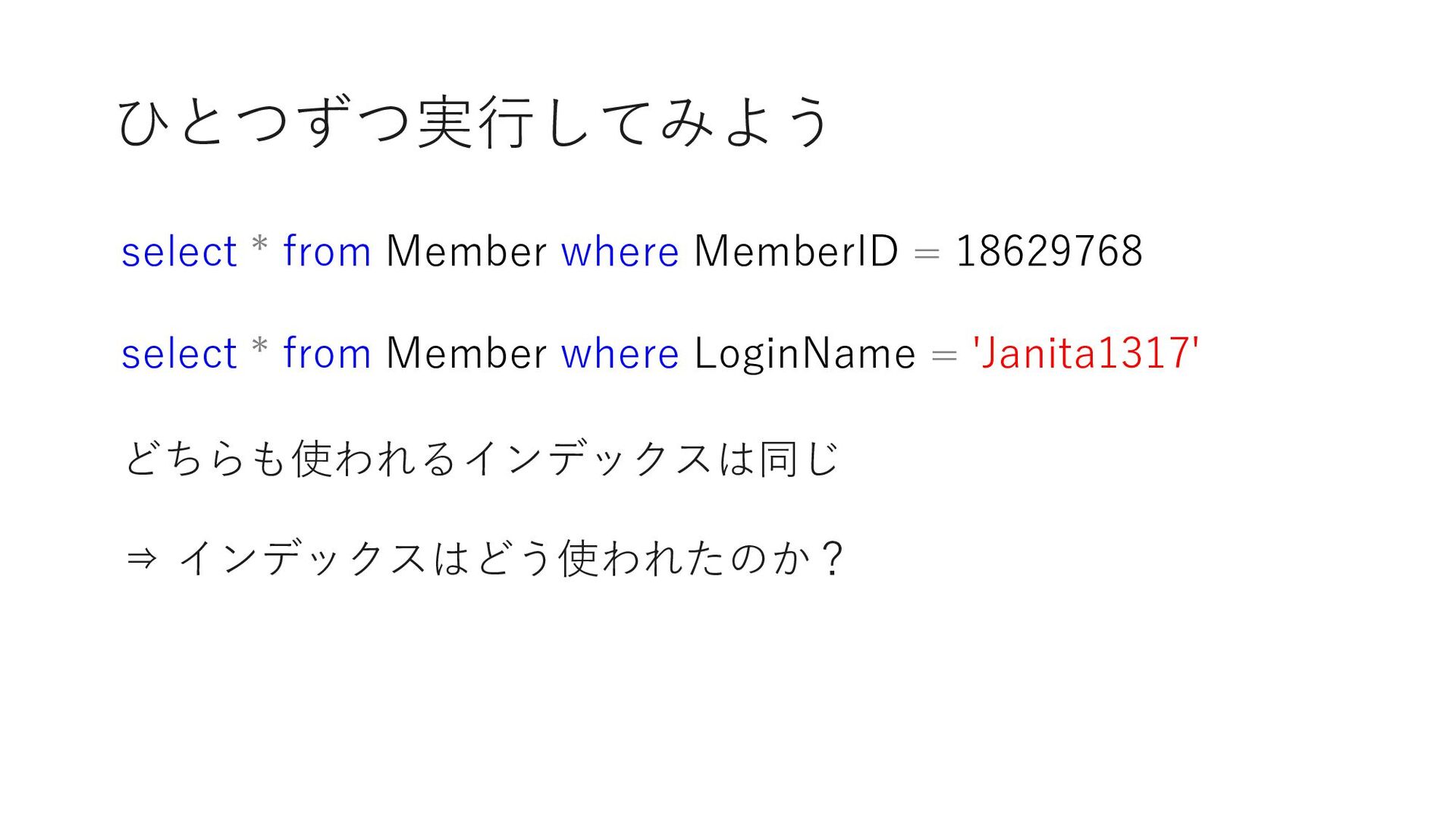
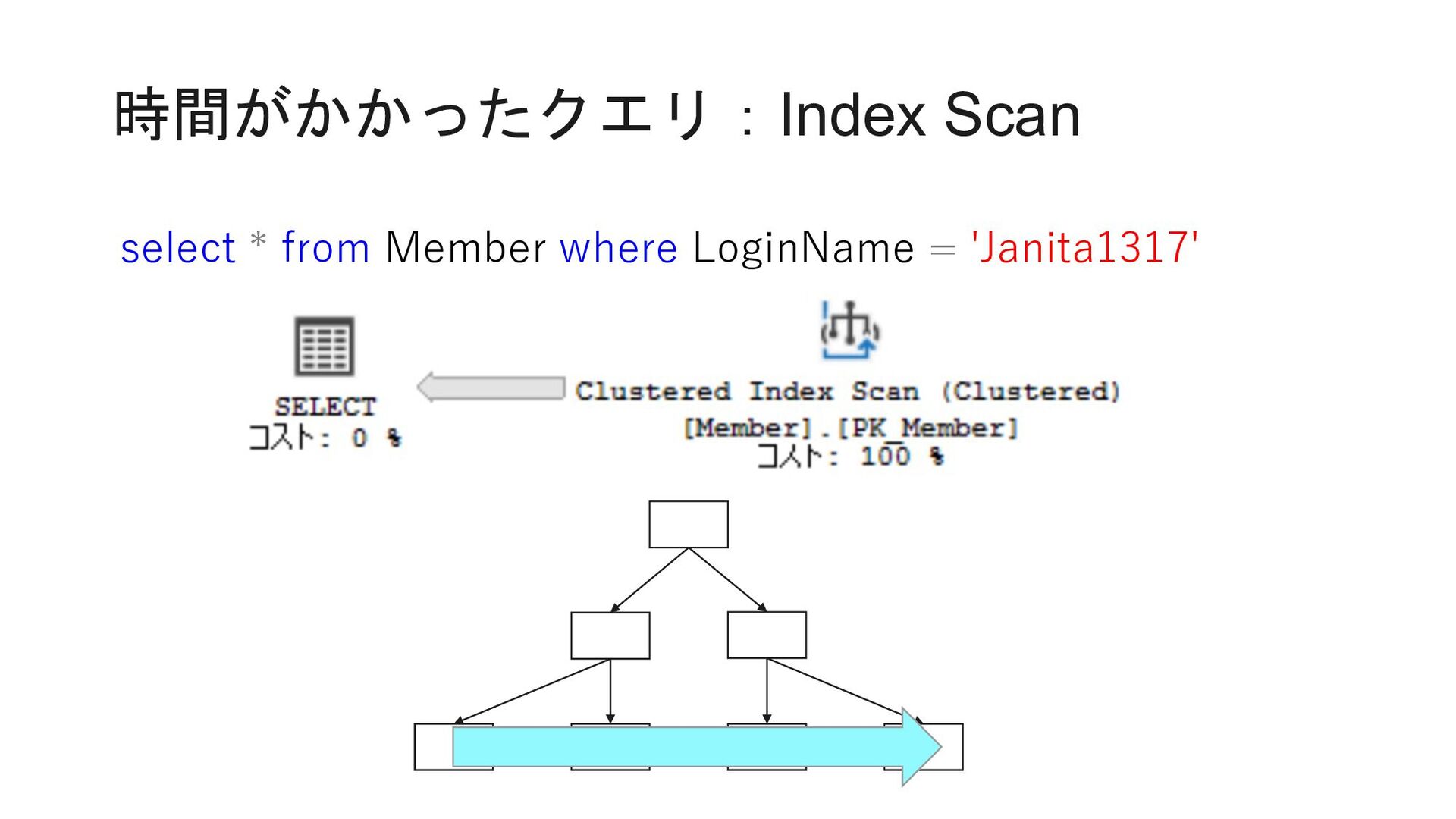
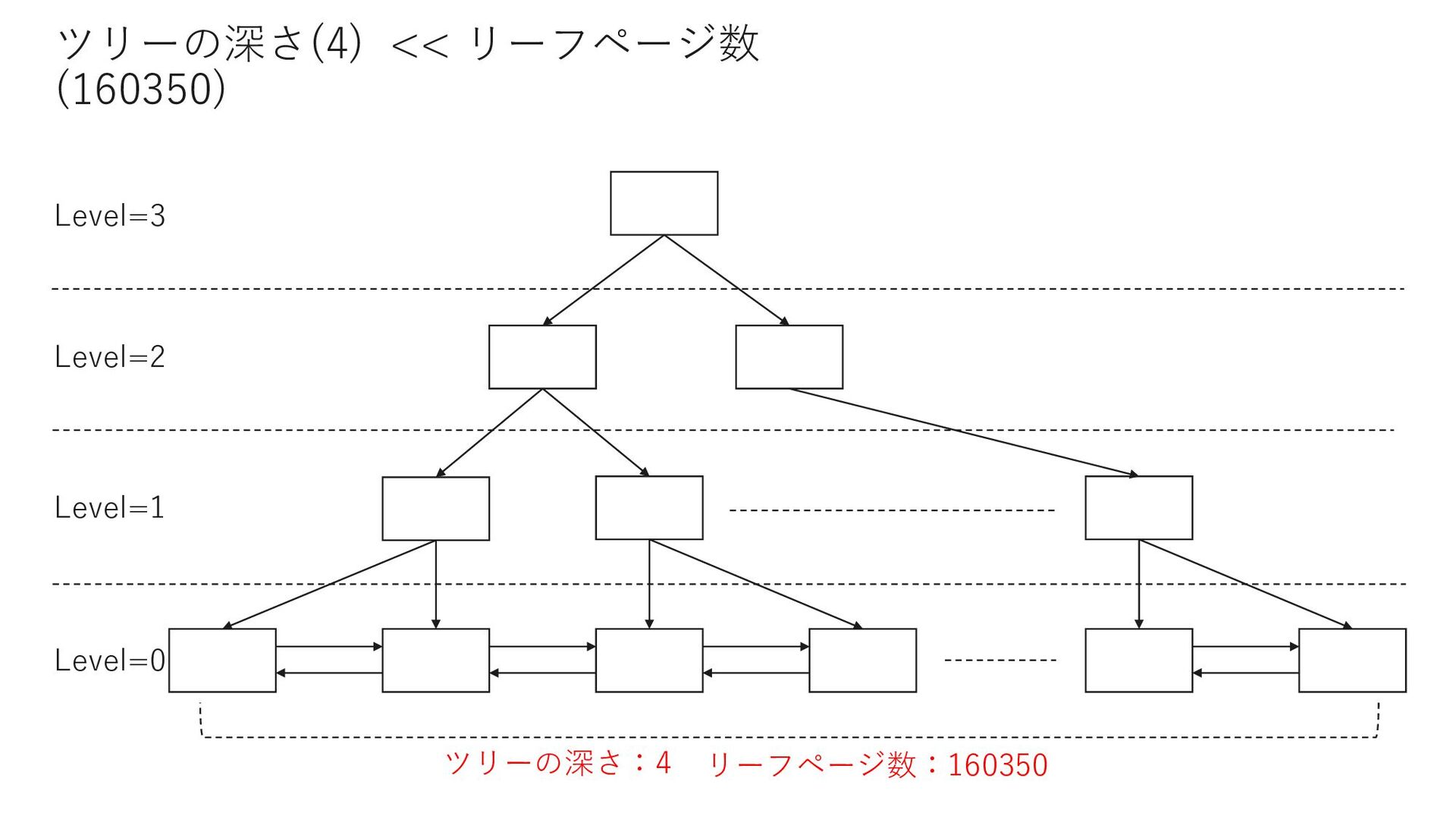
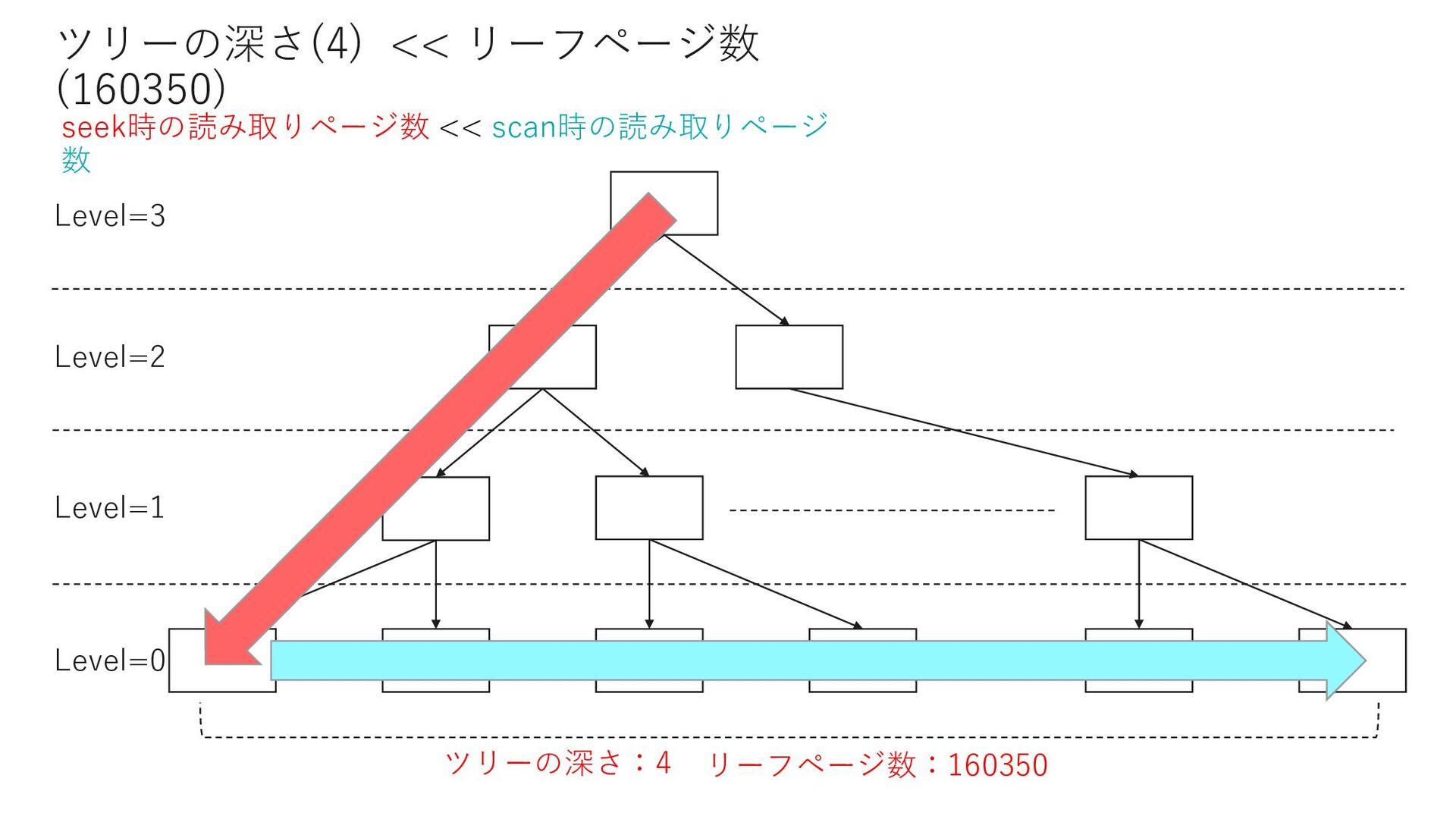
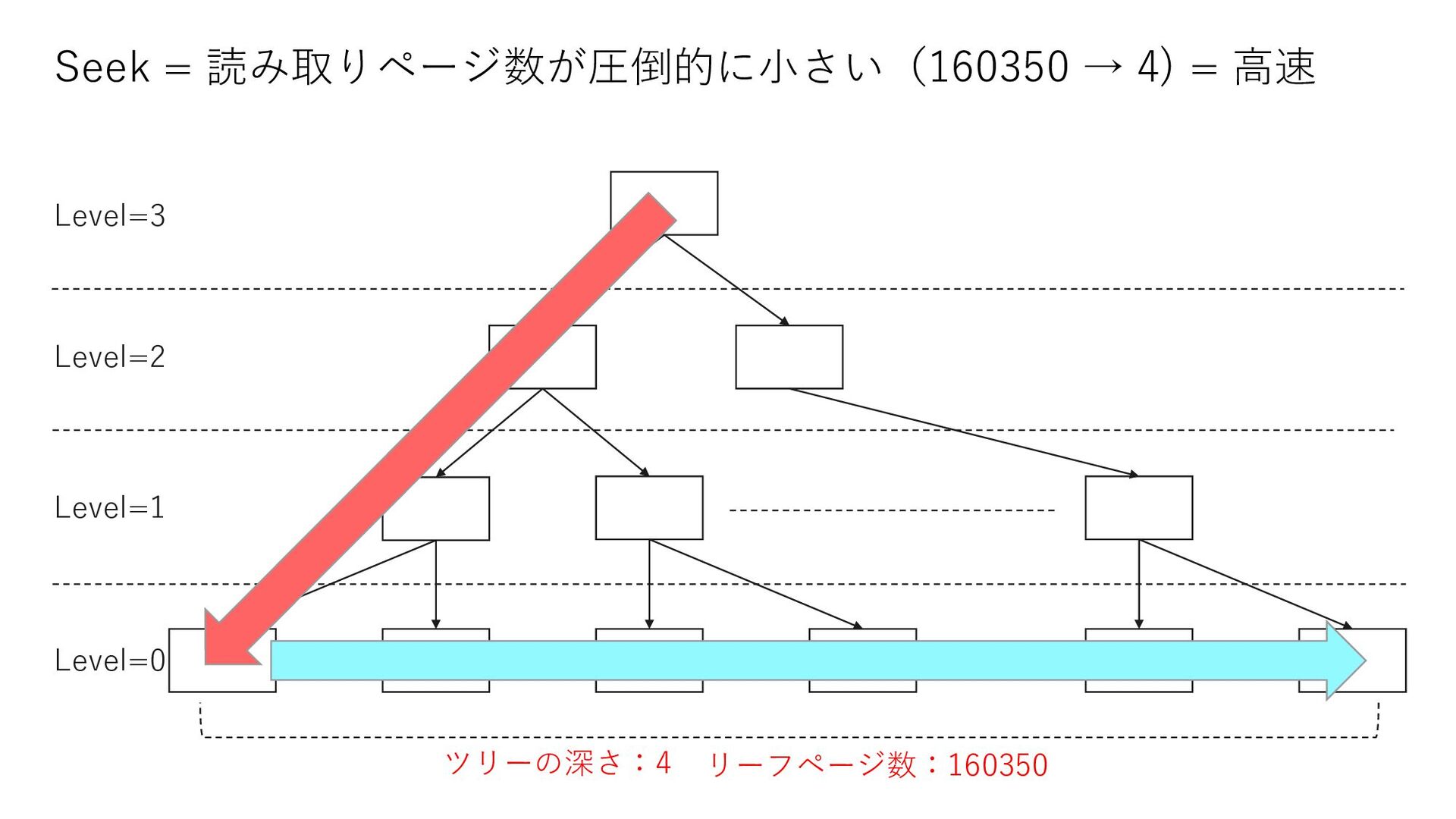
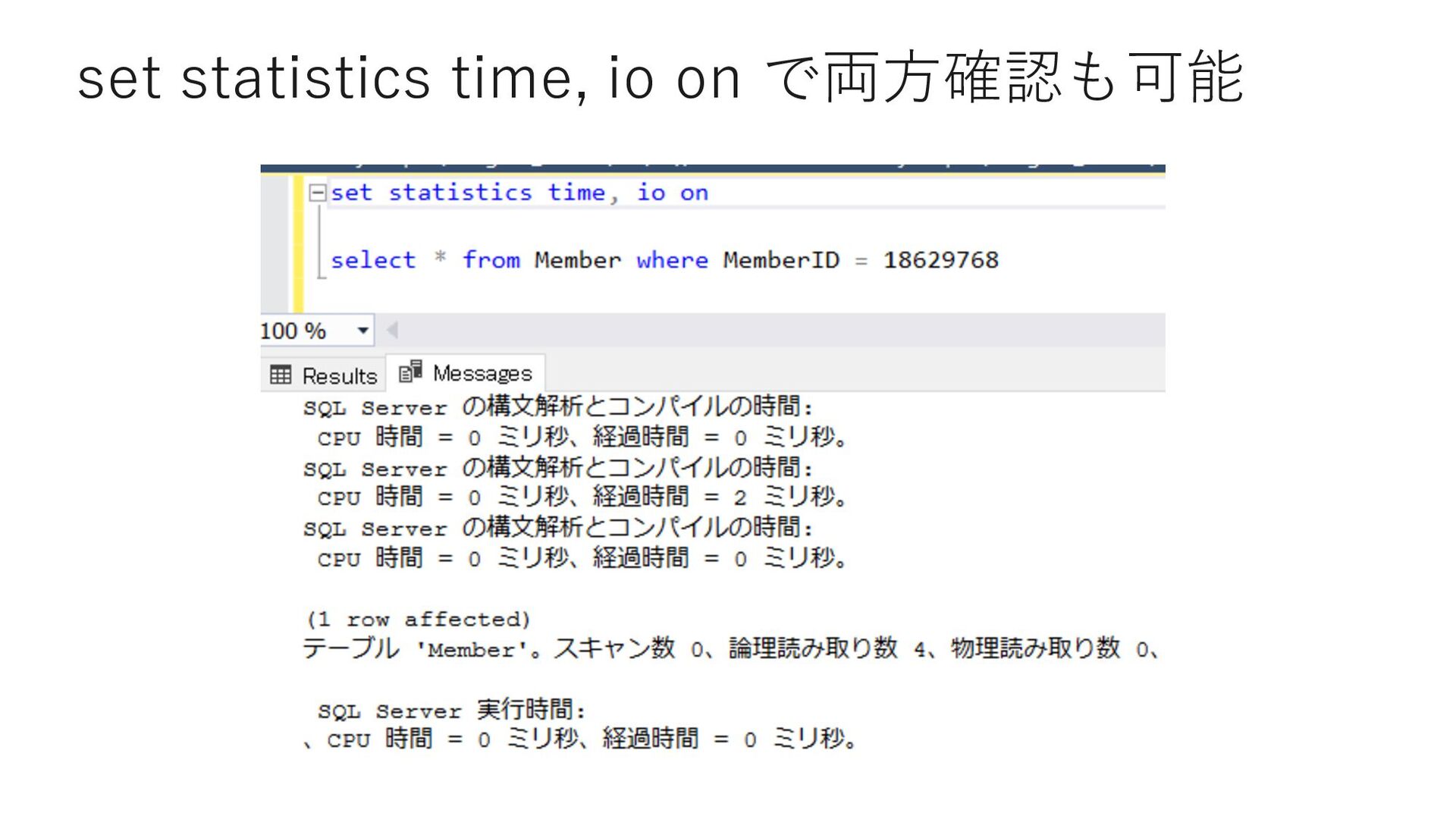
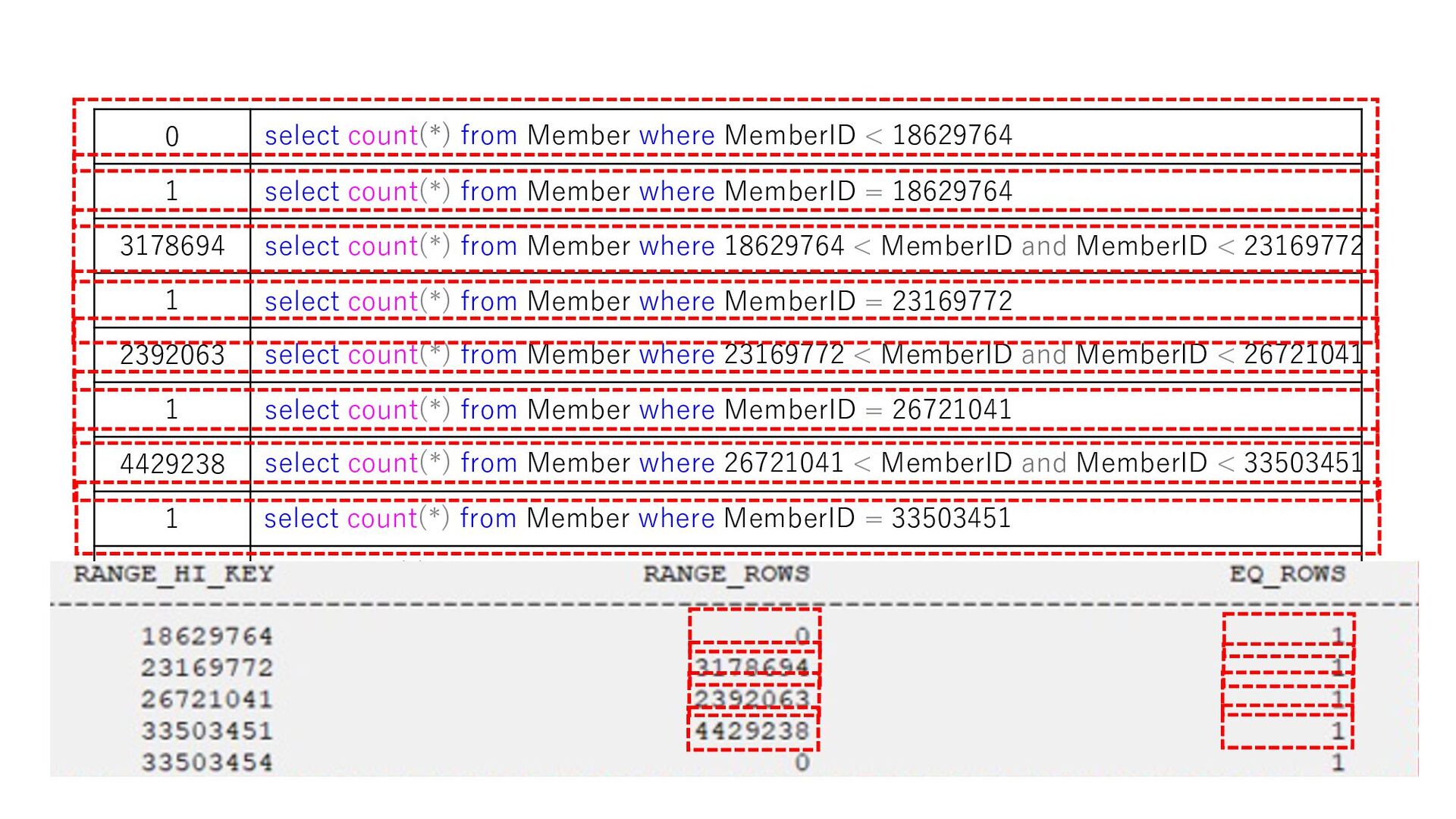
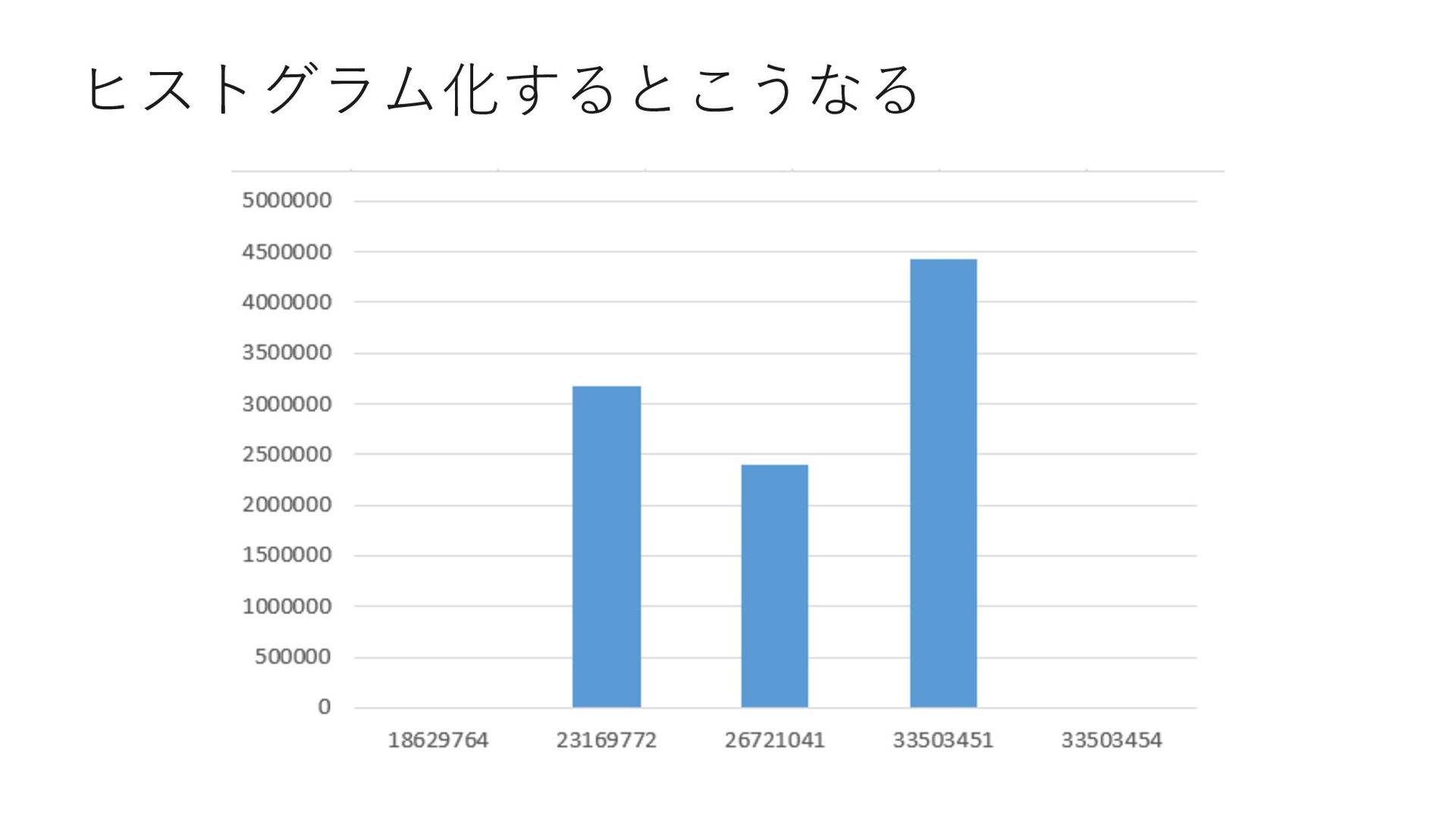
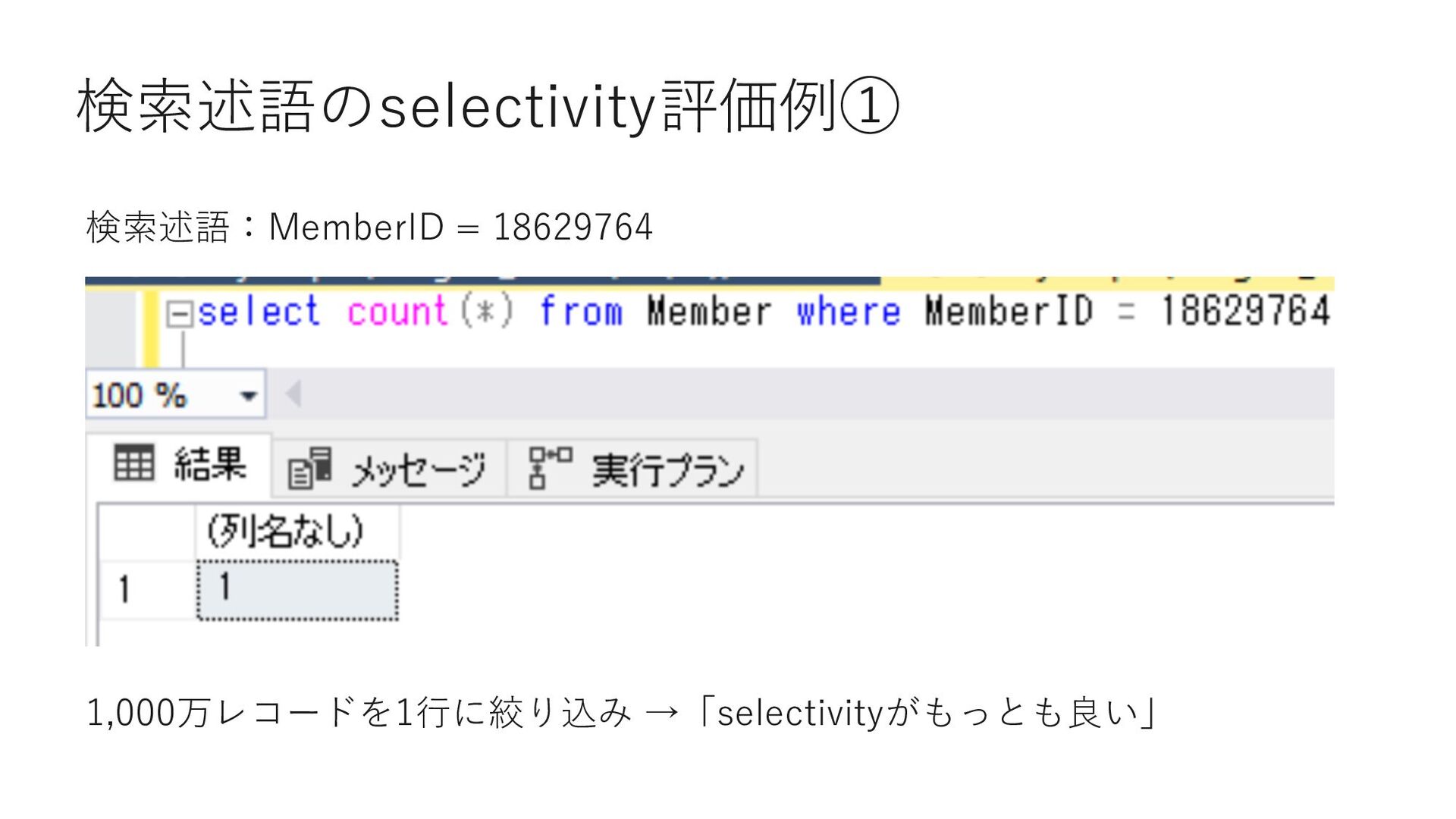
0 select count(*) from Member where MemberID < 18629764 select count(*) from Member where MemberID = 18629764 select count(*) from Member where 18629764 < MemberID and MemberID < 23169772 select count(*) from Member where MemberID = 23169772 select count(*) from Member where 23169772 < MemberID and MemberID < 26721041 select count(*) from Member where MemberID = 26721041 select count(*) from Member where 26721041 < MemberID and MemberID < 33503451 select count(*) from Member where MemberID = 33503451 select count(*) from Member where 33503451 < MemberID and MemberID < 33503454 select count(*) from Member where 33503454 = MemberID select count(*) from Member where 33503454 < MemberID
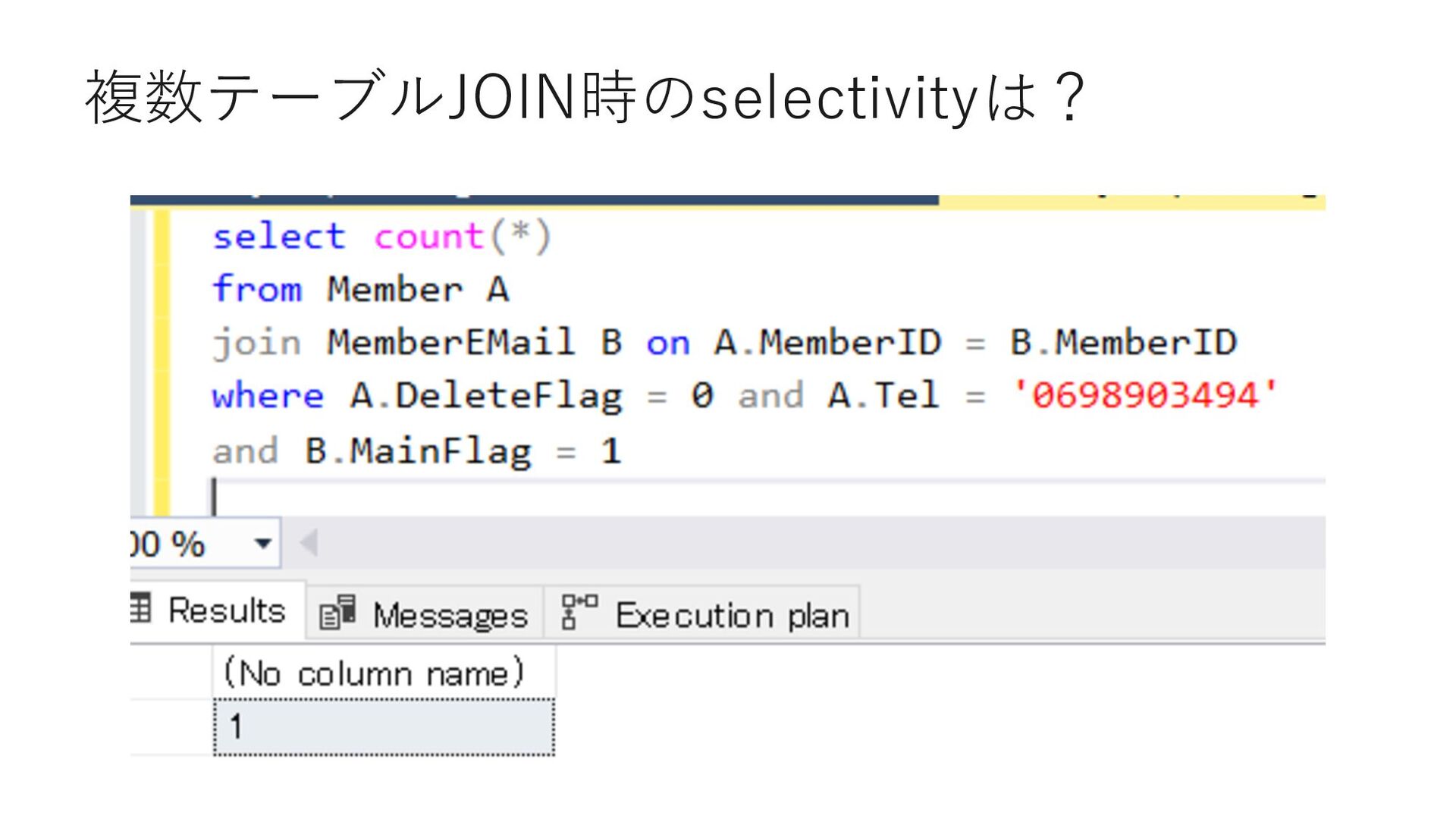
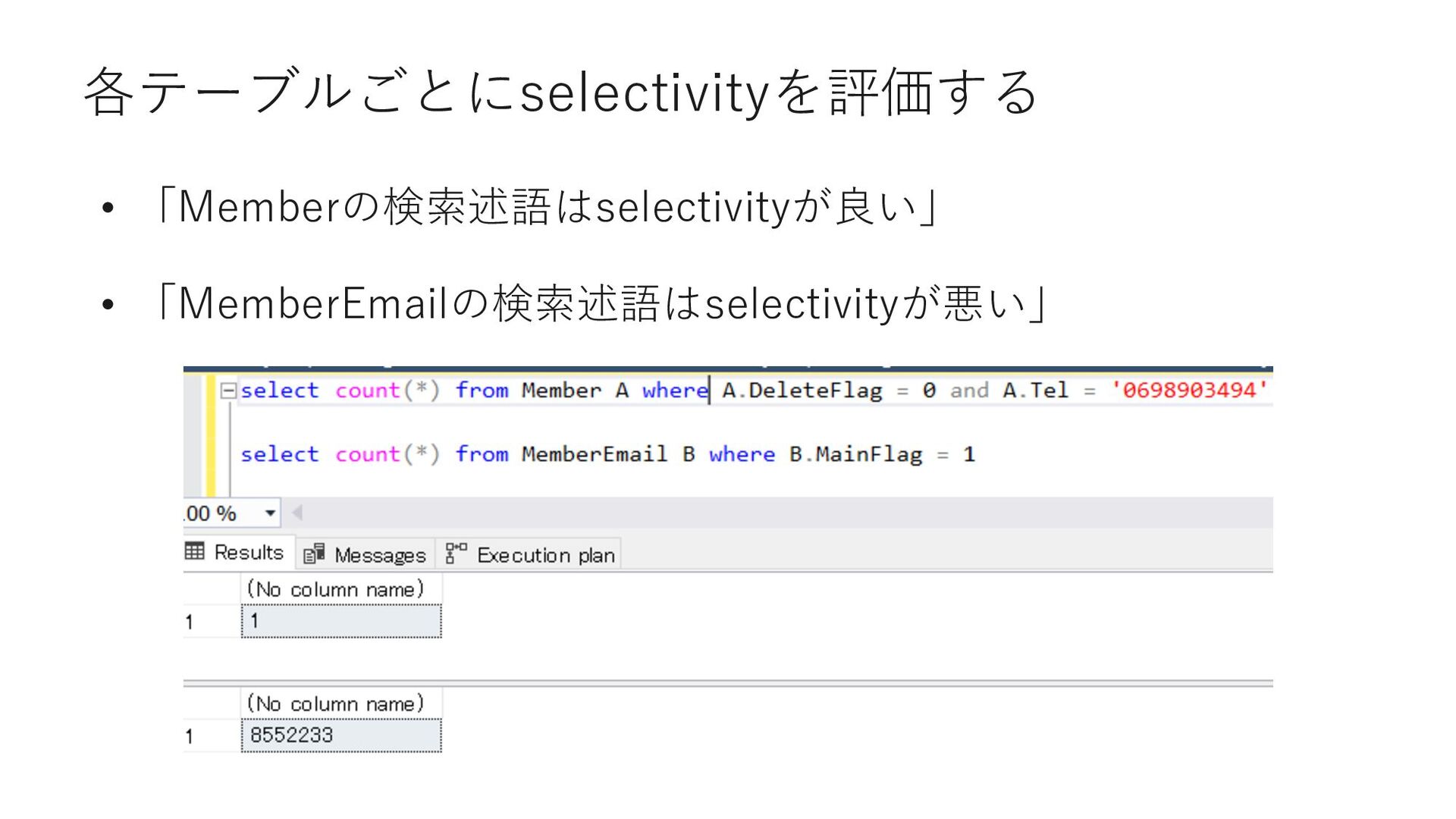
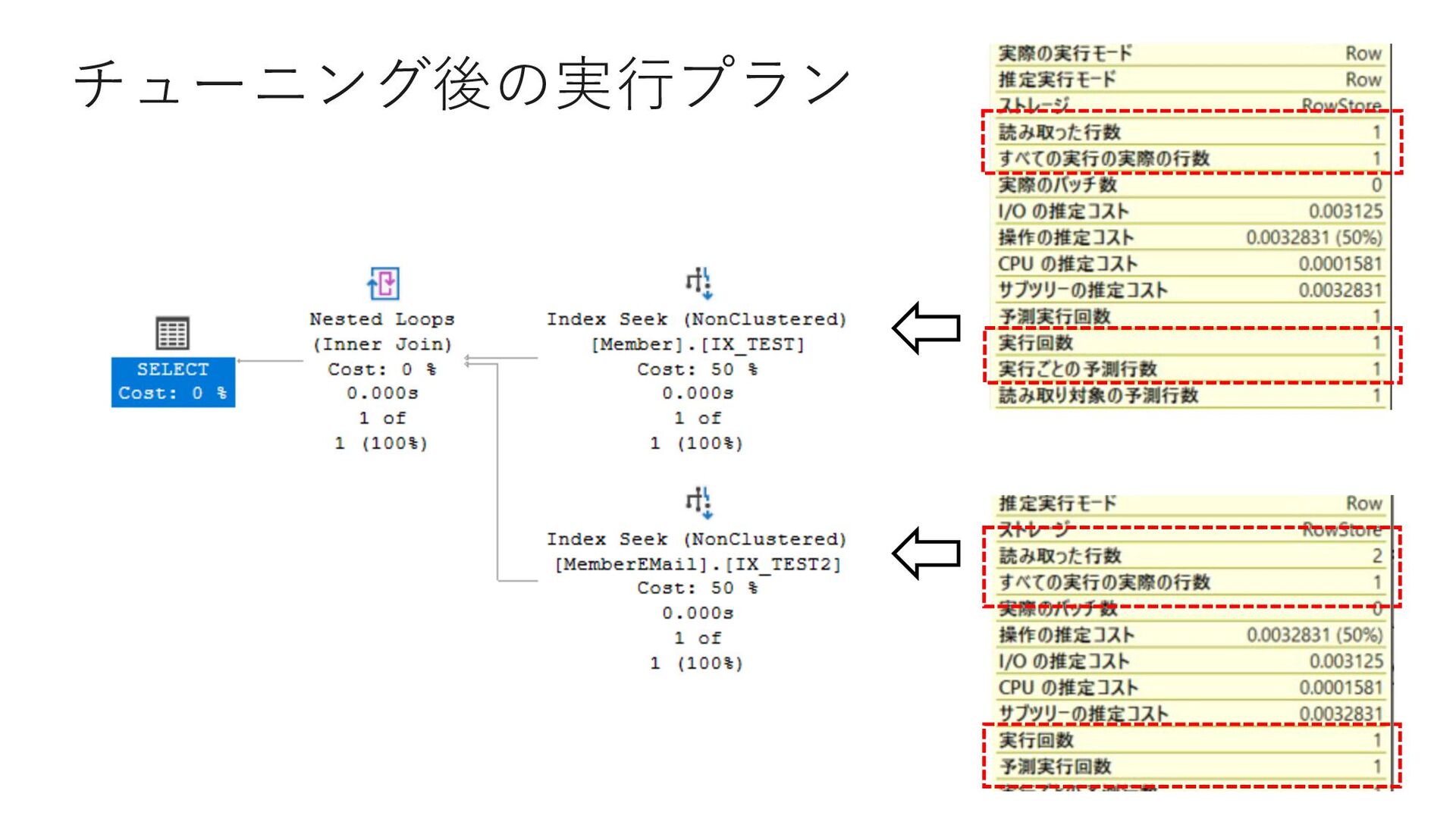
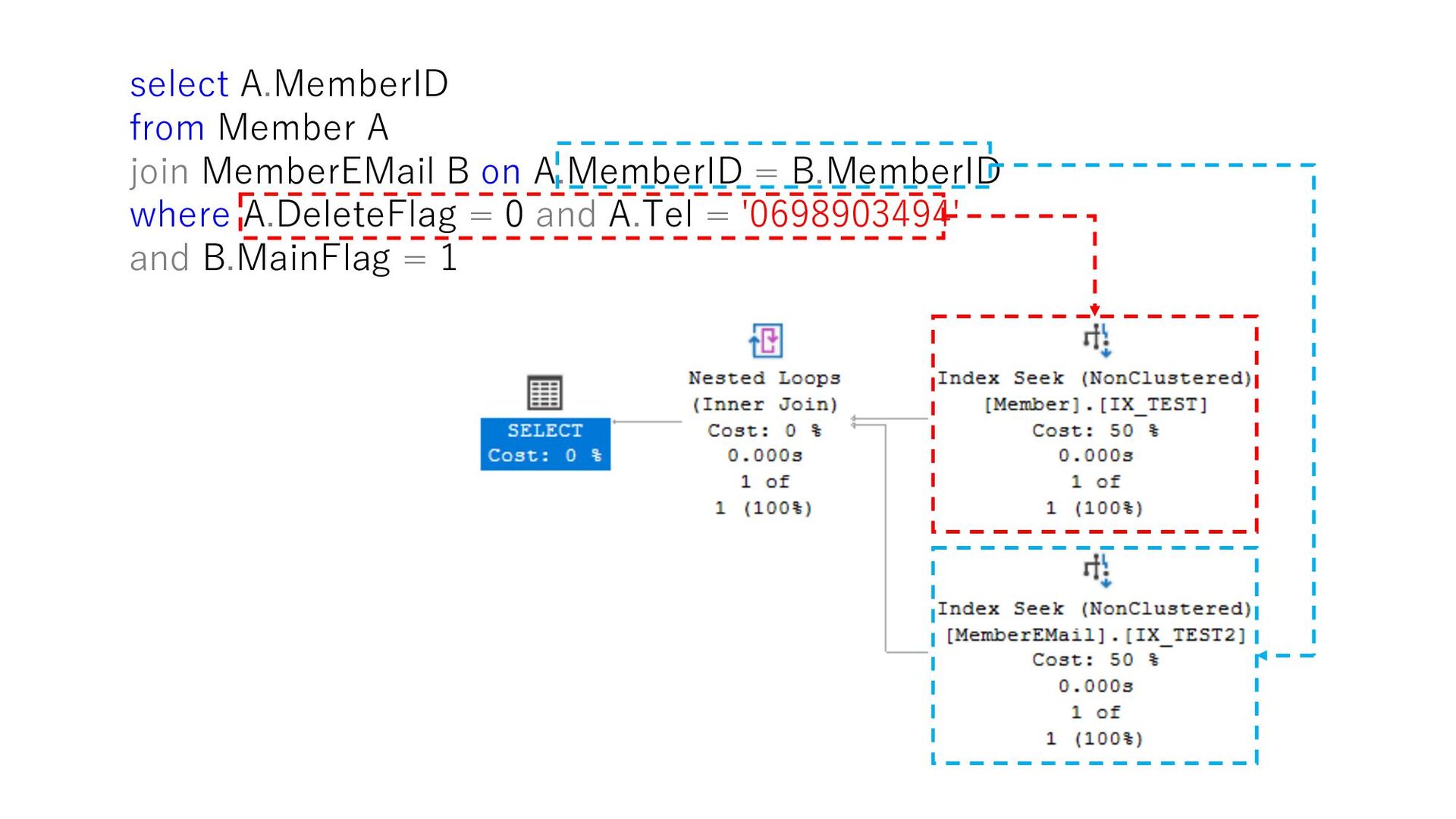
join MemberEMail B on A.MemberID = B.MemberID where A.DeleteFlag = 0 and A.Tel = '0698903494' and B.MainFlag = 1 select MemberID from Member where DeleteFlag = 0 and Tel = '0698903494' select MemberID from MemberEMail where MemberID = 18629764 and MainFlag = 1 ①まずMemberから MemberIDを取得 ②取得したMemberIDを検索 述語に追加
Sei, Mei, Tel FROM Member a WHERE EXISTS ( SELECT * FROM MemberEMail b WHERE a.MemberID = b.MemberID AND MainFlag = 1 AND b.DeleteFlag = 0 ) AND Tel = @Tel
( [LoginName] ASC ) INCLUDE (RegistDate) CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName3] ON [dbo].[Member] ( [LoginName] ASC, [RegistDate] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName4] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (DeleteFlag)
INCLUDE (RegistDate) CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName3] ON [dbo].[Member] ( [LoginName] ASC, [RegistDate] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName4] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (DeleteFlag) CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC , [RegistDate] ASC ) INCLUDE (RegistDate, Sei, Mei, DeleteFlag)
,i.name as index_name ,ps.row_count as row_count ,ps.reserved_page_count * 8.0 / 1024 as size_mb ,type_desc ,us.* from sys.dm_db_partition_stats ps left join sys.indexes i on ps.object_id = i.object_id and ps.index_id = i.index_id left join sys.dm_db_index_usage_stats us on ps.object_id = us.object_id and ps.index_id = us.index_id where OBJECT_NAME(i.object_id) = @TableName order by index_id
'Test' 〇 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([Sei], [Mei]) × CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei], [Mei])
([Sei], [Mei]) CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [DeleteFlag]) INCLUDE ([Sei], [Mei]) ・ひとつのインデックスで2種類のクエリに対応可能
[Sei], [Mei]) select * from Member where LoginName = 'Test' and Sei = 'aaa' and Mei = 'bbb' • この既存インデックスだけみると、下記のようなクエリが すでに実⾏されていると考えるのが妥当 ・よってインデックスを増やすしかなくなる
having count(*) > 1 select Sei, Mei from Member where LoginName = 'Test' and DeleteFlag = 1 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([Sei], [Mei], [DeleteFlag]) ・したがって、上記のクエリのインデックスは下記でOK
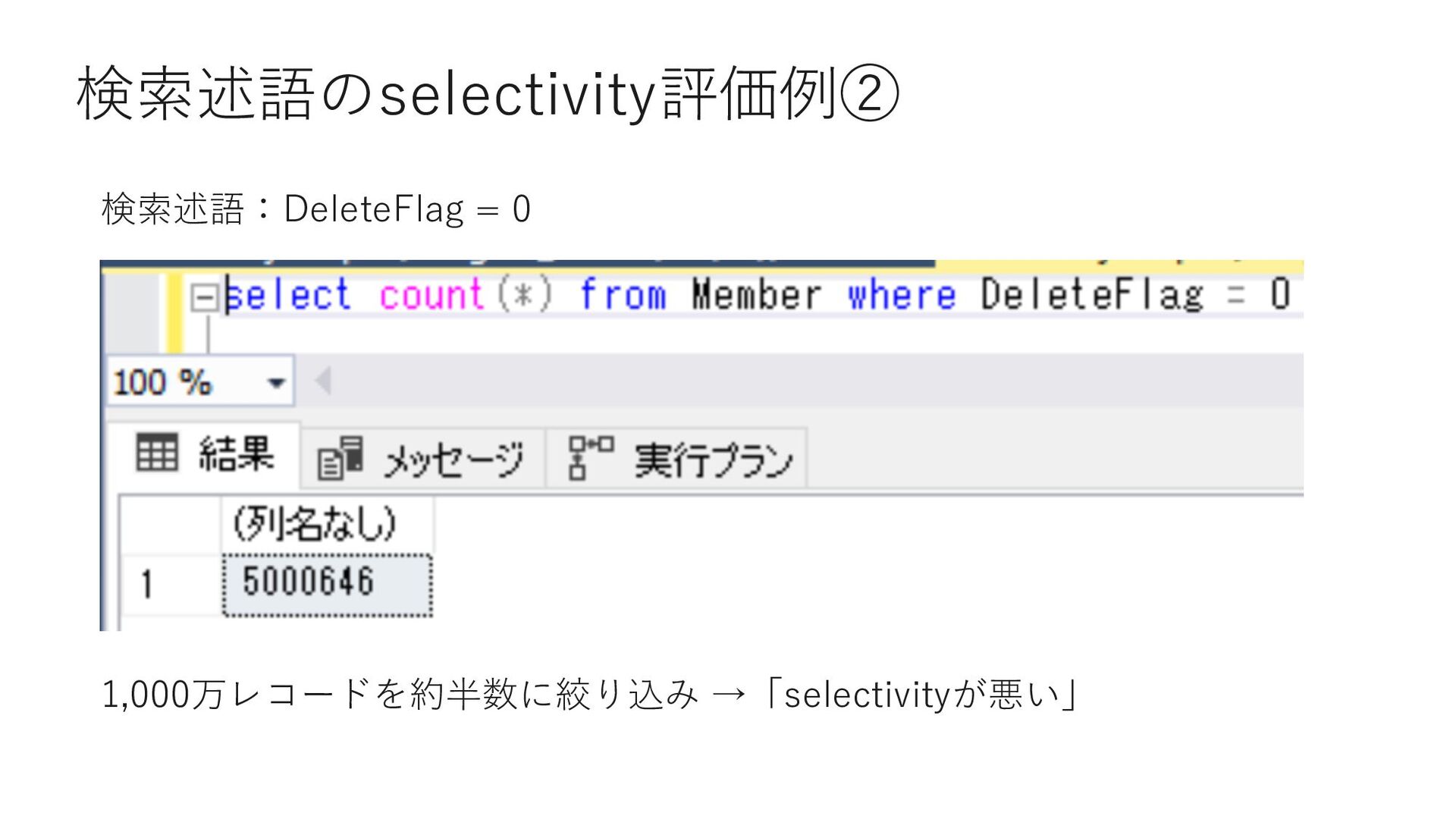
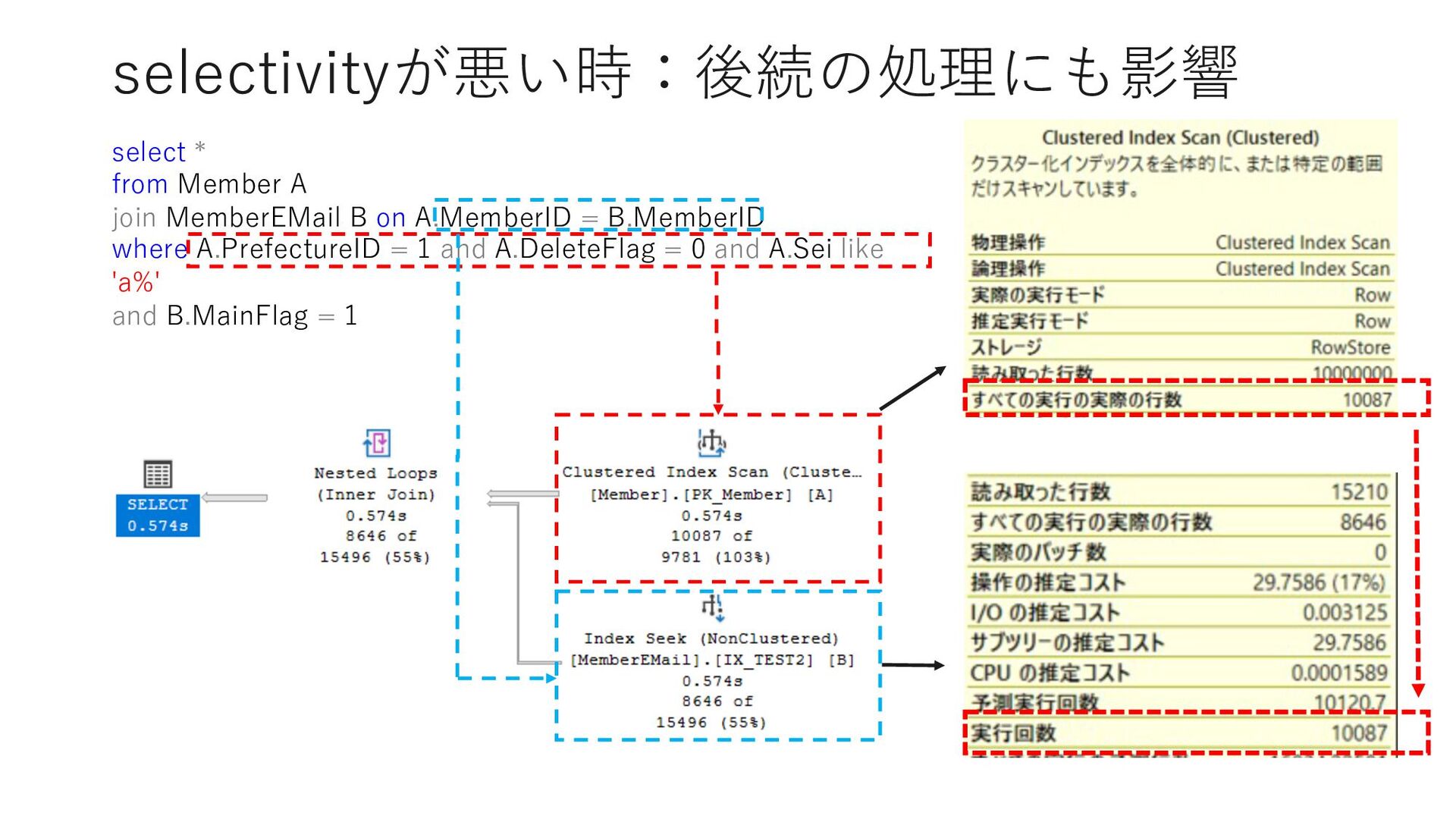
1 → 9,999,995レコード • select * from Member where PrefectureID = 2 → 1レコード • select * from Member where PrefectureID = 3 → 1レコード • select * from Member where PrefectureID = 4 → 1レコード • select * from Member where PrefectureID = 5 → 1レコード • select * from Member where PrefectureID = 6 → 1レコード 「PrefectureID = 1」だけ selectivityが⼤きく異なる
10 * from Member where PrefectureID = @PrefID IndexScanの実⾏プランがキャッシュされ、@PrefIDで別の値が指定されても IndexScanでクエリ実⾏される @PrefID=1の場合はテーブルの99%以上のレコードが取得されるためIndexScan
([RegistDate]) ② CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei]) ③ CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName]) INCLUDE ([GenderID], [PrefectureID]) ④ CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate]) ⑤ CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([DeleteFlag]) ⑥
[DeleteFlag]) INCLUDE ([RegistDate]) ① CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE ([RegistDate]) ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON[Member] ([tel], [DeleteFlag])
[Member] ([LoginName], [HashedPassword]) INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag]) ② CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei]) ③ CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName]) INCLUDE ([GenderID], [PrefectureID]) ⑤ CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([DeleteFlag])
[DeleteFlag]) INCLUDE ([RegistDate]) ② + ③ + ⑤ CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag]) ④ CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate])
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![durationの差と実⾏プランの違い • インデックス効いてる • select * from [Member] where LoginName](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![クラスタ化インデックスの定義 [MemberID]で並び替えられたツリー構造になっている ALTER TABLE [dbo].[Member] ADD CONSTRAINT [PK_Member] PRIMARY KEY](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![インデックスが効く(=seek)条 件 例:「インデックスの並び順」=「where句で指定した条件」 ALTER TABLE [dbo].[Member] ADD CONSTRAINT [PK_Member] PRIMARY](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![そのための新しいインデックス CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
![付加列インデックス CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_65.jpg){kind=link}
{kind=link}
![複合インデックス CREATE NONCLUSTERED INDEX [IX_Member_Sei_PrefectureID] ON [dbo].[Member] ( [Sei] ASC,](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![カバリングインデックス • 上記ようなインデックスが作成されている場合 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![回答 ※MemberIDは主キーなので⾃動的にインデックスに含まれる CREATE NONCLUSTERED INDEX [IX_Member_Tel] ON [dbo].[Member] ([Tel])](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_85.jpg){kind=link}
{kind=link}
![回答① CREATE NONCLUSTERED INDEX [IX_Memer_LoginName] ON [dbo].[Member] ([LoginName])](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_87.jpg){kind=link}
![回答②:付加列を追加 CREATE NONCLUSTERED INDEX [IX_Memer_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([GenderID],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
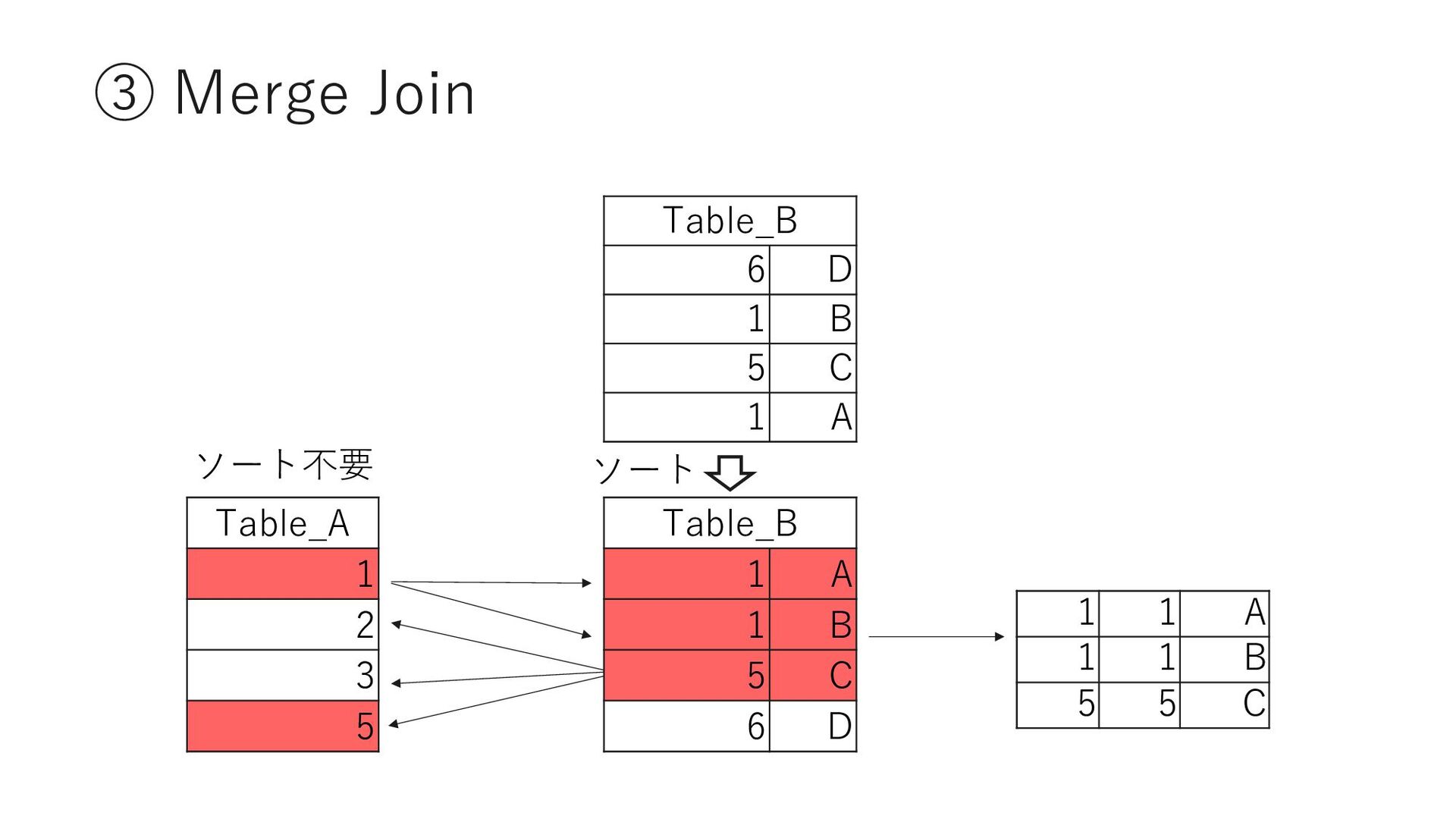{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![回答:ソートをカットするインデックス create index [IX_MemberEMail_Email] on [MemberEmail] ([Email] asc)](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_144.jpg){kind=link}
{kind=link}
![回答:order byとキーの並び順を同じにする create index [IX_MemberEMail_DeleteFlag_Email] on [MemberEmail] ([DeleteFlag] asc, [EMail]](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_146.jpg){kind=link}
{kind=link}
![回答:クエリ実⾏順序とキーの順番を同じにする create index [IX_MemberEMail_DeleteFlag_Email] on [MemberEmail]([DeleteFlag], [EMail])](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_148.jpg){kind=link}
{kind=link}
{kind=link}
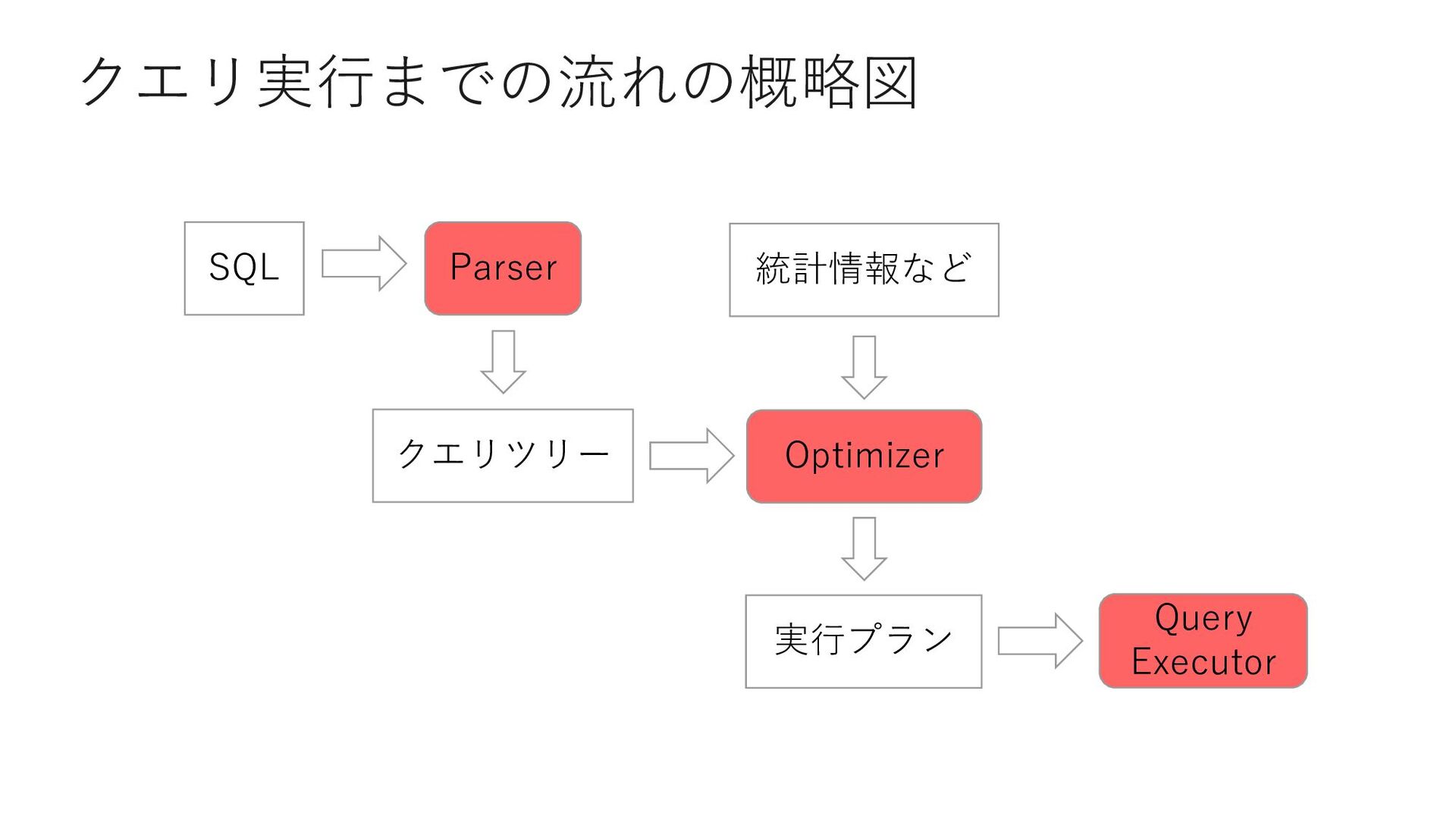{kind=link}
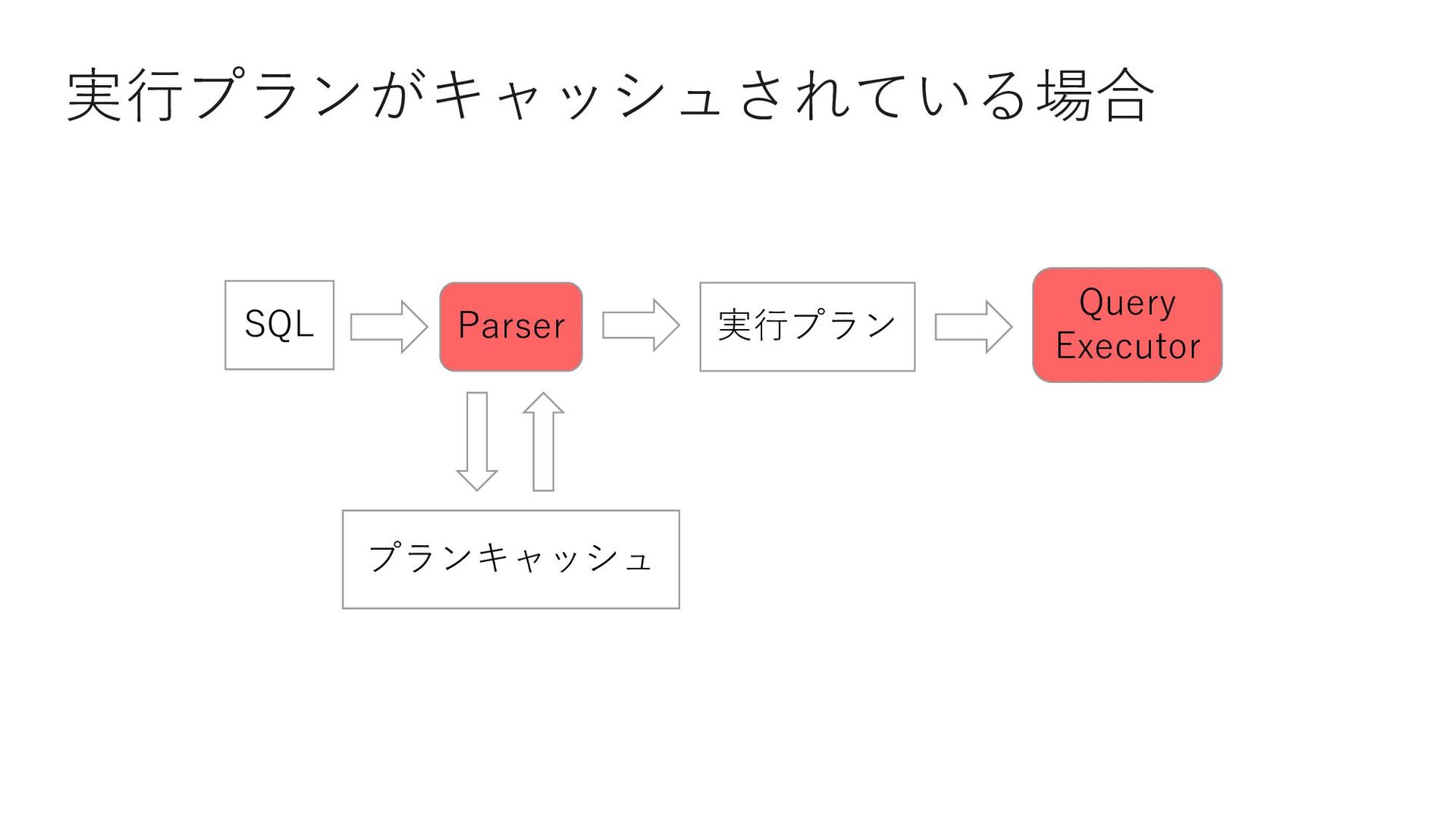{kind=link}
{kind=link}
{kind=link}
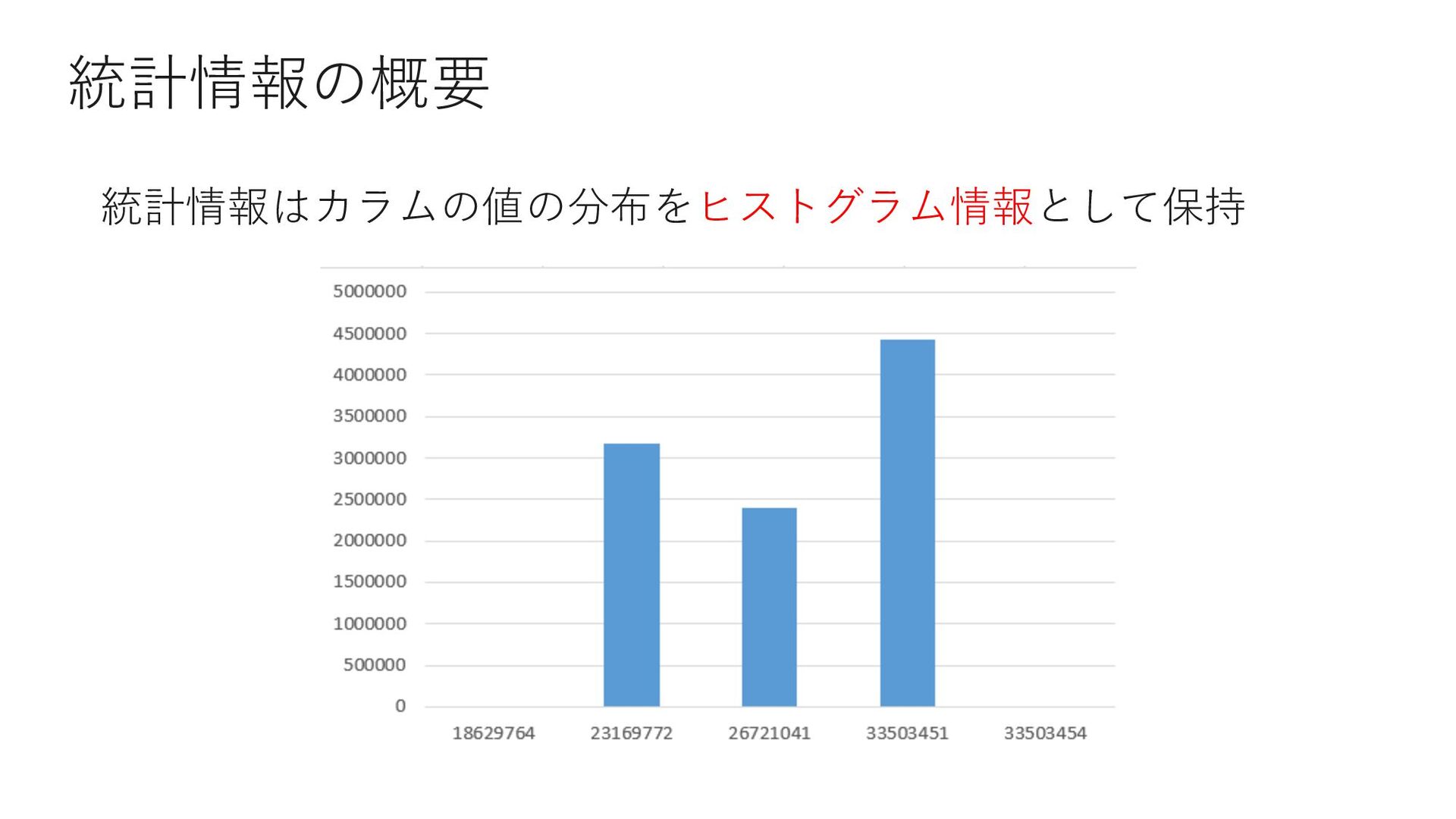{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![回答:MemberEMailのScanをSeekにしたい CREATE NONCLUSTERED INDEX [IX_MemberEmail_MemberID] ON [dbo].[MemberEMail] ([MemberID])](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_193.jpg){kind=link}
{kind=link}
{kind=link}
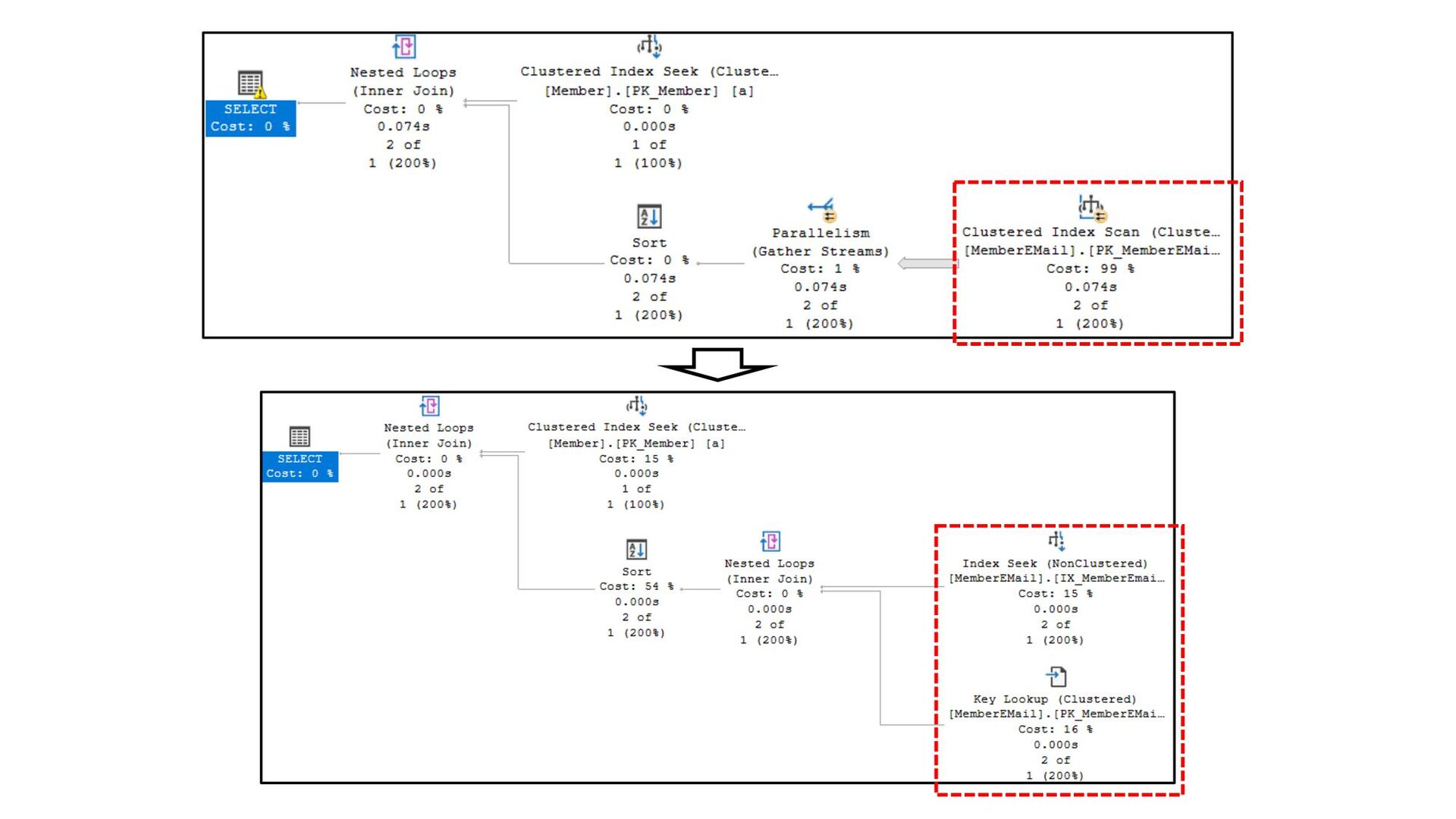
![回答:まずMemberのScanをSeekにする CREATE NONCLUSTERED INDEX [IX_Member_Tel] ON [dbo].[Member] ([Tel])](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_196.jpg){kind=link}
{kind=link}
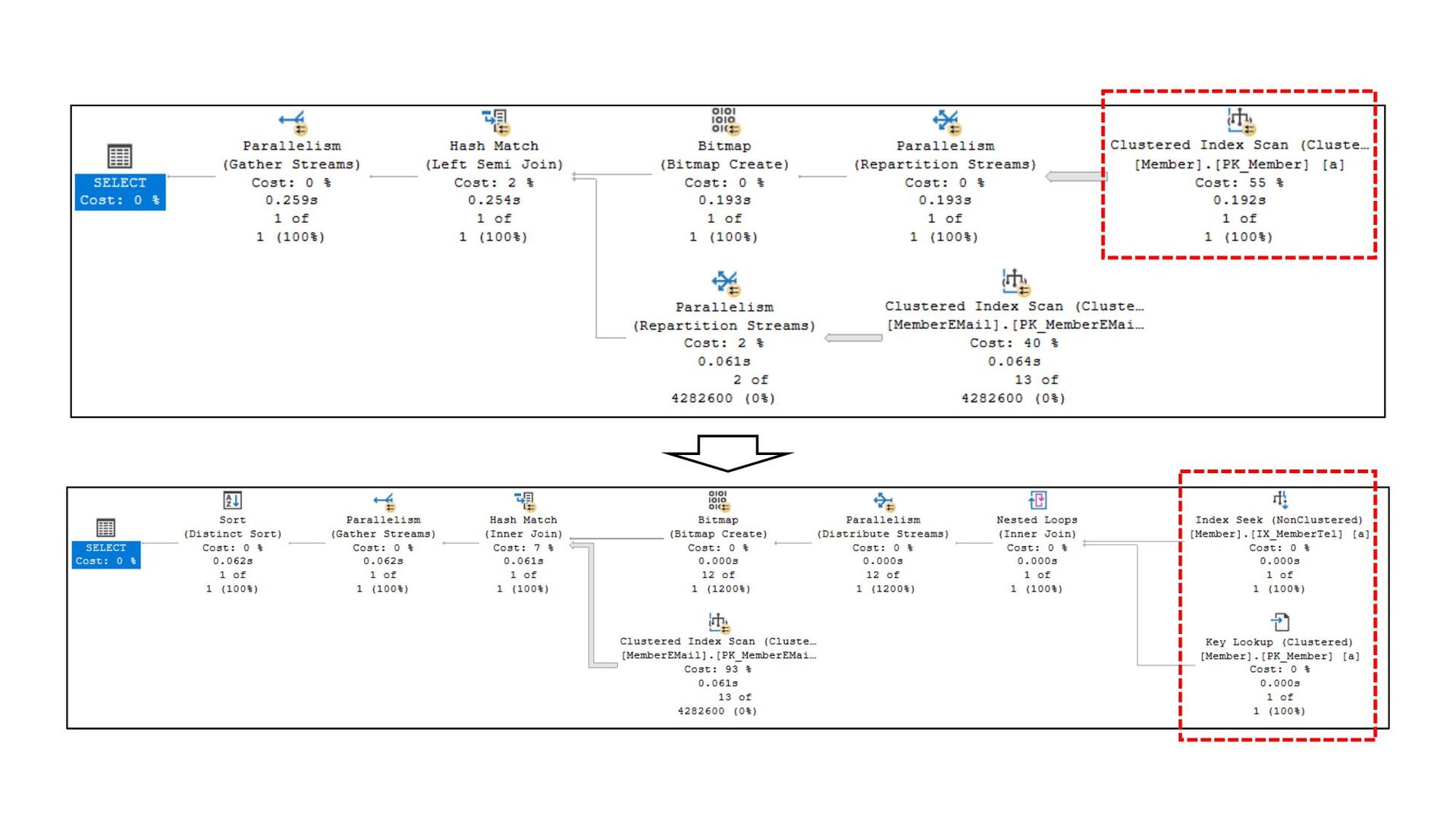
![次にMemberEMailのScanをSeekにする CREATE NONCLUSTERED INDEX [IX_MemberEMail_MemberID] ON [dbo].[MemberEMail] ([MemberID]) INCLUDE ([MainFlag],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_198.jpg){kind=link}
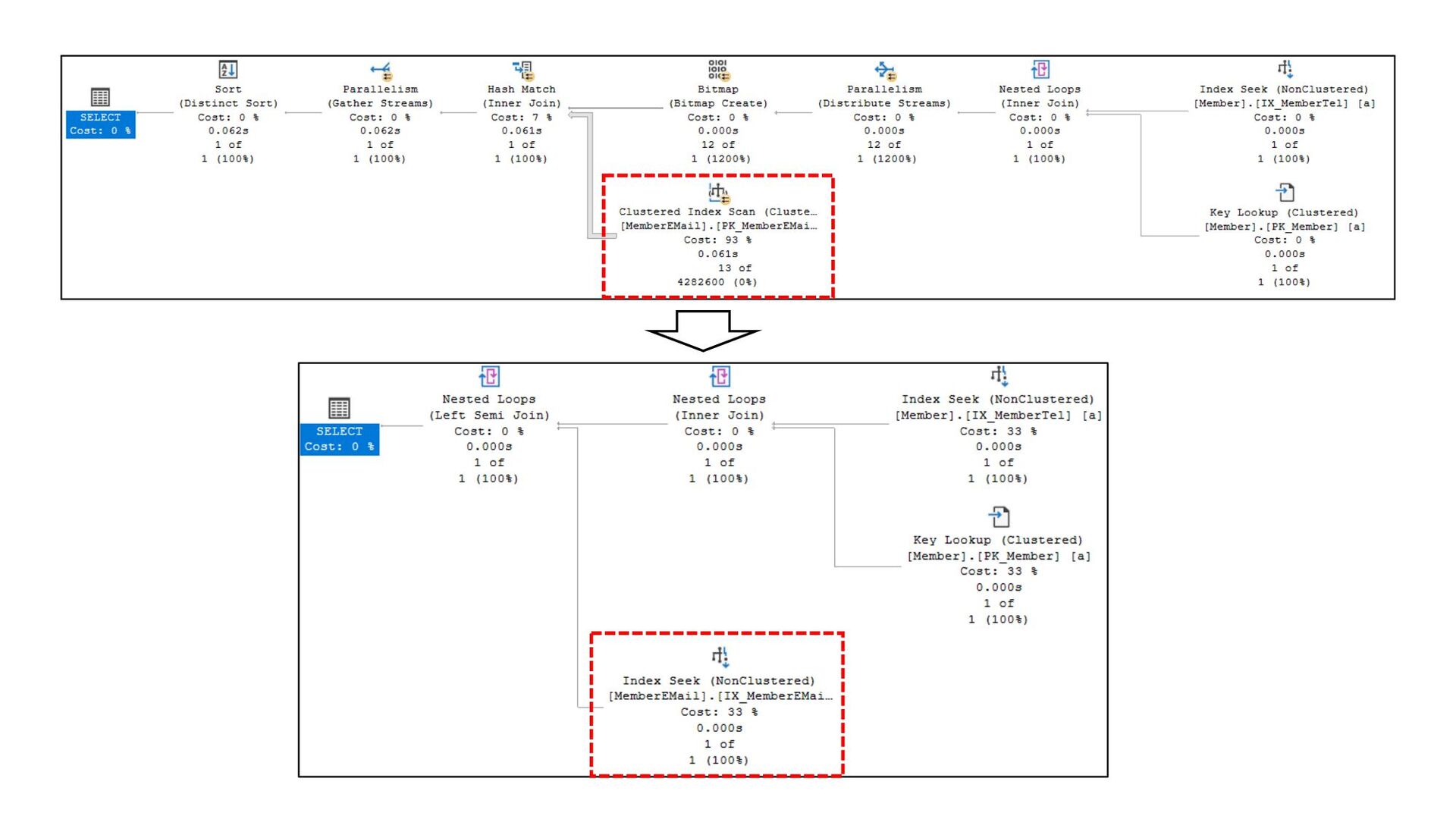{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
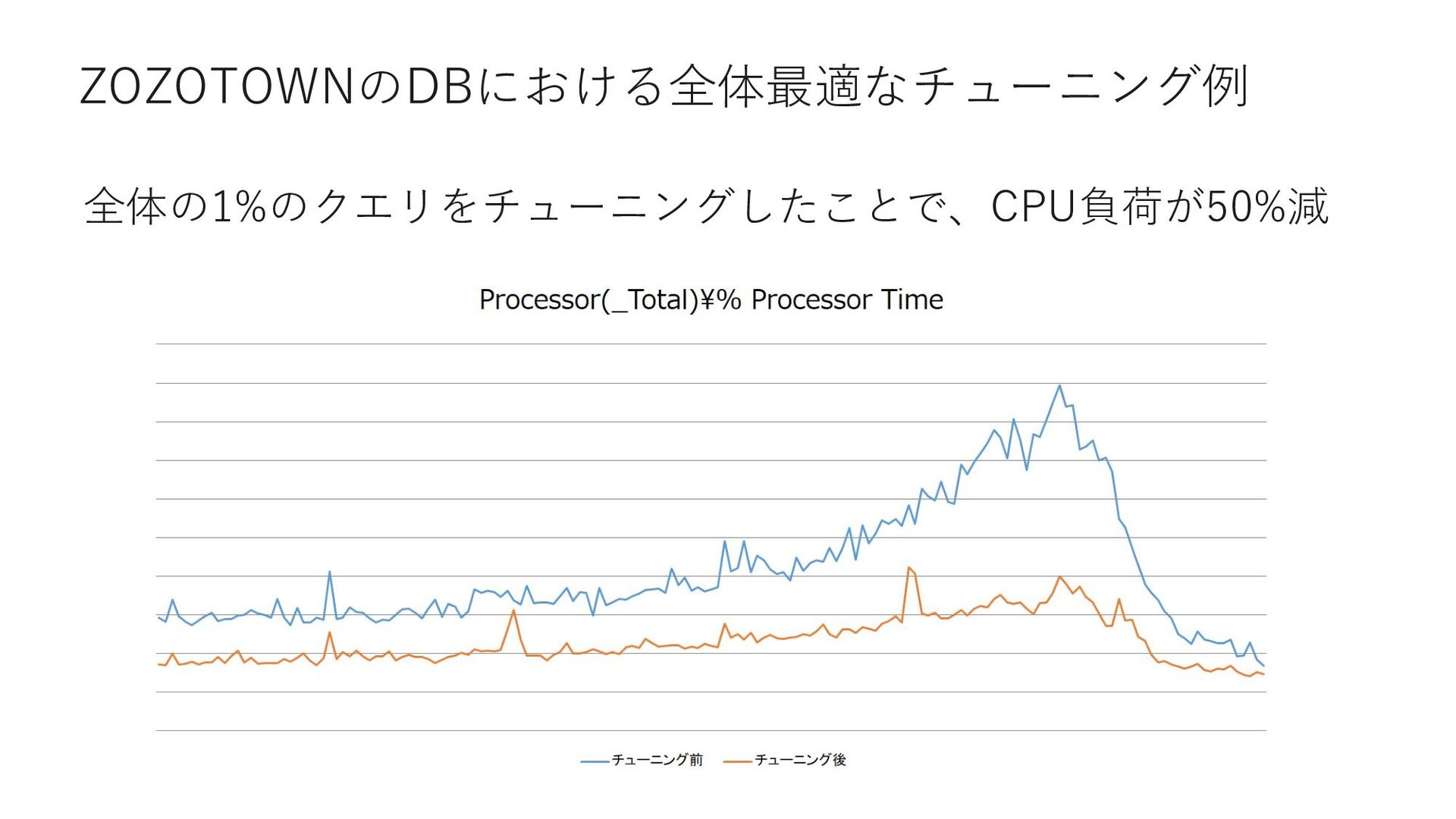{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
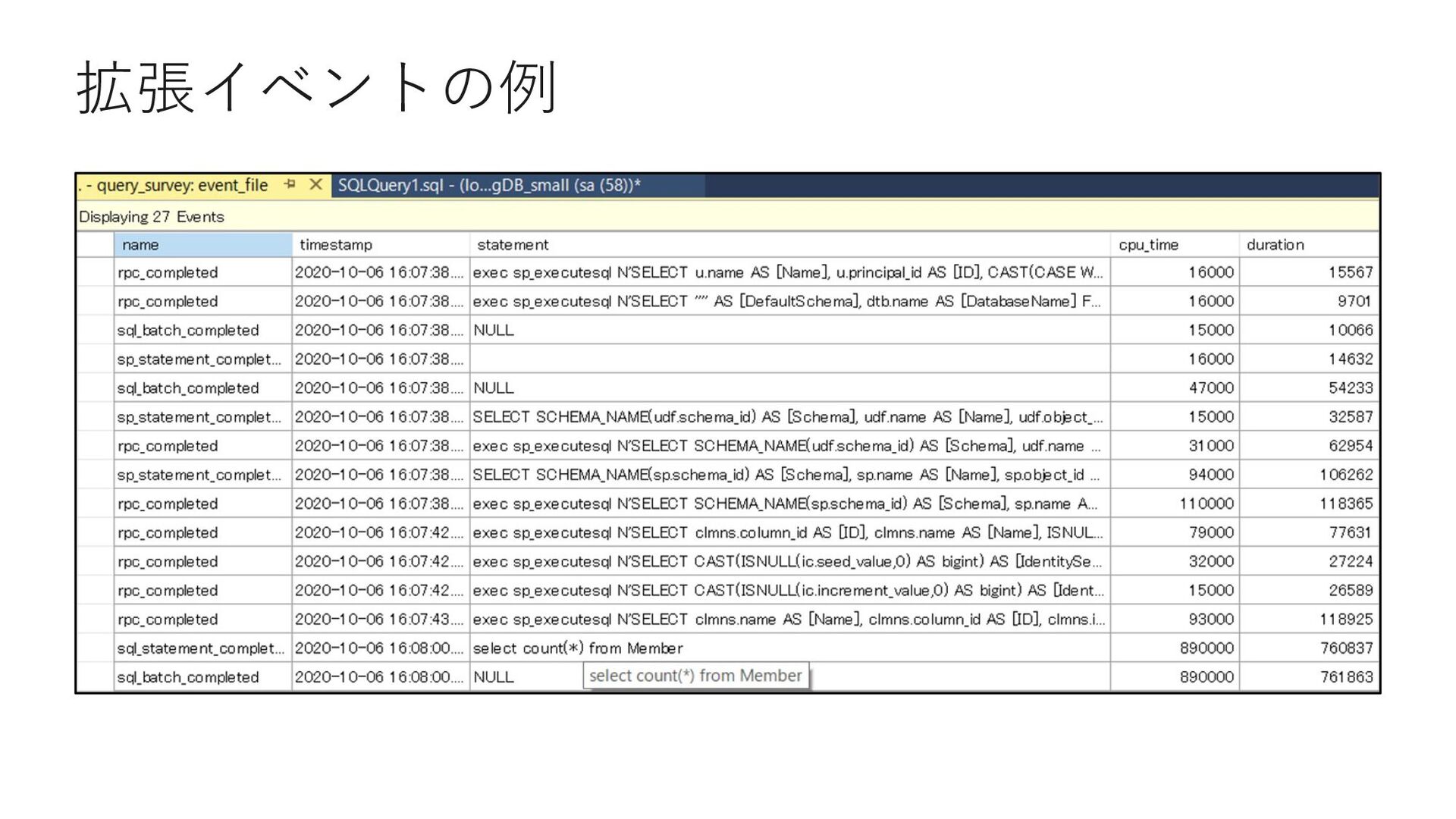{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![インデックス作成のアンチパターン 各クエリごとに最適なインデックスを作成する ⇒ 似たインデックスが⼤量に作成される CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member]](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_222.jpg){kind=link}
![CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC )](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_223.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![付加列にしたインデックスの場合 ・既存のインデックスを⼀度DROPして作り直せばOK CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_228.jpg){kind=link}
![CREATE NONCLUSTERED INDEX [IX_Memaber_LoginName] ON [dbo].[Member] ([LoginName], [DeleteFlag]) INCLUDE ([Sei],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_229.jpg){kind=link}
![付加列にしないインデックスの場合 • 追加で別のインデックスを作るしかなくなる CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_230.jpg){kind=link}
![• インデックスを修正する時点でプロダクション環境で 実⾏されている全クエリを把握するのは難しい CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_231.jpg){kind=link}
![• 結果的に以下のふたつのインデックスを作成する必要が出てくる CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_232.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![問題:全体最適な観点でインデックスを再設計 してください ① CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_248.jpg){kind=link}
{kind=link}
![解説① ① + ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_250.jpg){kind=link}
![解説② ② + ③ + ⑤ CREATE INDEX [IX_Member_LoginName] ON](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_251.jpg){kind=link}
![最終的な回答 ① + ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel],](https://files.speakerdeck.com/presentations/84cb0f6ac65140ca8e86148d1a750354/slide_252.jpg){kind=link}