Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介 : More is not always better: balancing se...
Search
masaya82
February 14, 2019
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介 : More is not always better: balancing sense distributions for all-words
masaya82
February 14, 2019
More Decks by masaya82
See All by masaya82
文献紹介:Enhancing Modern Supervised Word Sense Disambiguation Models
masaya82
0
180
文献紹介:The Word Sense Disambiguation Test Suite at WMT18
masaya82
0
120
文献紹介:Preposition Sense Disambiguation and Representation
masaya82
0
150
文献紹介:Word Sense Disambiguation Based on Word Similarity Calculation Using Word Vector Representation from a Knowledge-based Graph
masaya82
0
170
Distributional Lesk: Effective Knowledge-Based Word Sense Disambiguation
masaya82
0
130
Japanese all-words WSD system using the Kyoto Text Analysis ToolKit
masaya82
0
150
Improving Word Sense Disambiguation in Neural Machine Translation with Sense Embeddings
masaya82
0
160
Learning_to_Identify_the_Best_Contexts_for_Knowledge-based_WSD
masaya82
0
150
Using Linked Disambiguated Distributional Networks for Word Sense Disambiguation
masaya82
0
110
Featured
See All Featured
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Speed Design
sergeychernyshev
33
1.9k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Six Lessons from altMBA
skipperchong
29
4.3k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Become a Pro
speakerdeck
PRO
31
6k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
370
A designer walks into a library…
pauljervisheath
211
24k
Transcript
More is not always better: balancing sense distributions for all-words
Marten Postma , Ruben Izquierdo Bevia , Piek Vossen 2019 2/14 文献紹介 長岡技術科学大学 自然言語処理研究室 福嶋 真也 Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 3496–3506, Osaka, Japan, December 11-17 2016.
2 Abstract • 現在のWSDシステムでは、出現頻度の低い語義であまり 良い性能が得られない。 →訓練データ、テストデータ内の語義の出現頻度の 偏りが原因。 • システムの性能に影響する特性を調査。 •
訓練データのバランスをとることでシステムが改善すること を確認した。
3 Introduction • WSDにおいて、教師ありの機械学習を用いたシステムは良い 性能を発揮している。 • トレーニングデータの量が問題であると考えられている。 →しかし、別問題として語義の出現頻度がある。 • WSDシステムの評価において、
– MFSのインスタンスでは精度が高い。(約80%) – LFSのインスタンスでは精度が低い。(約20%)
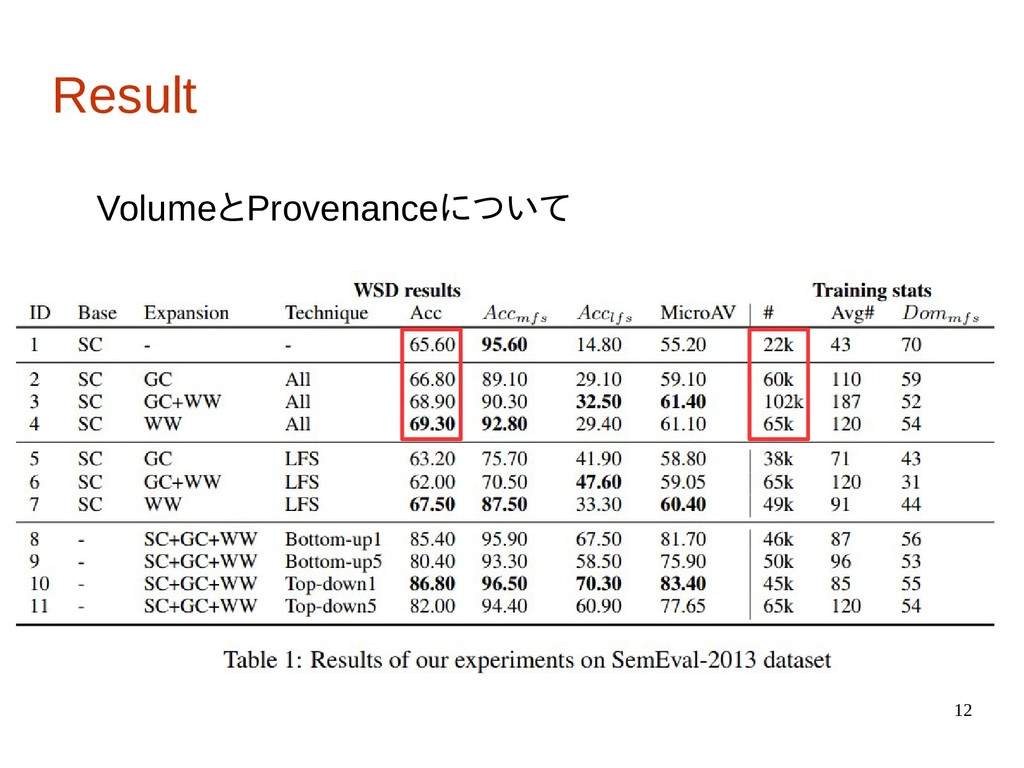
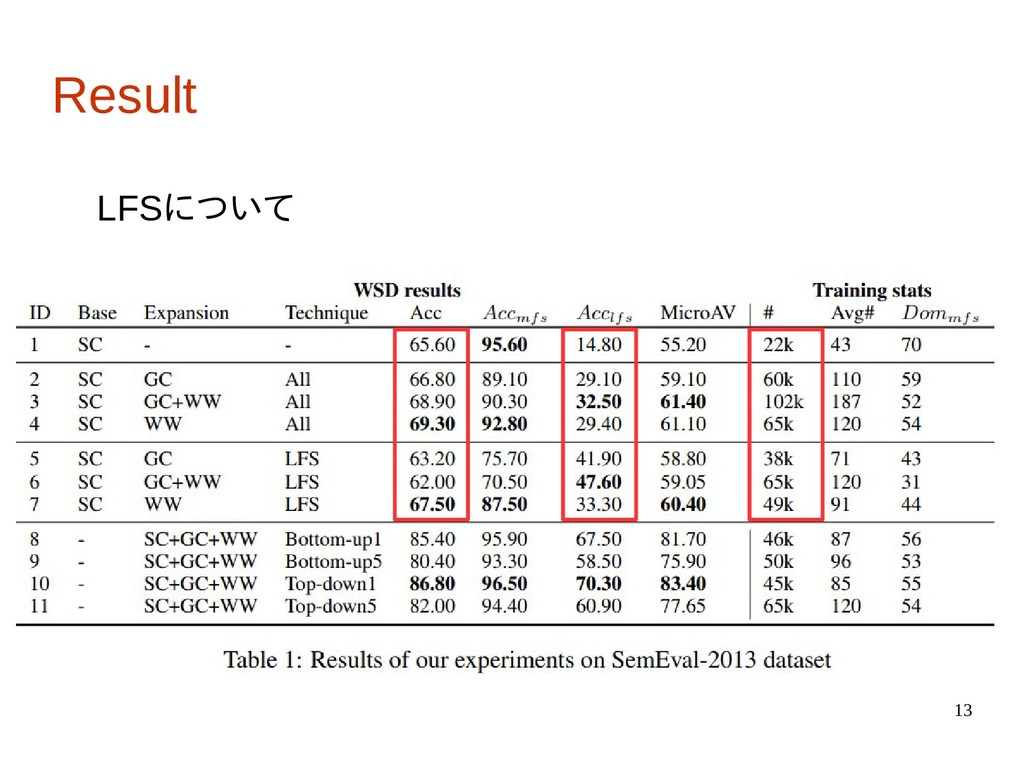
4 Introduction • 本研究では訓練データに関して4つの観点から精度への 影響を調査。 ・Volume: 単純に訓練データを増やした時の影響 ・LFS:LFSの事例を訓練データに追加した時の影響 ・Provenance:訓練データの注釈の付け方に関する影響 (手動と自動)
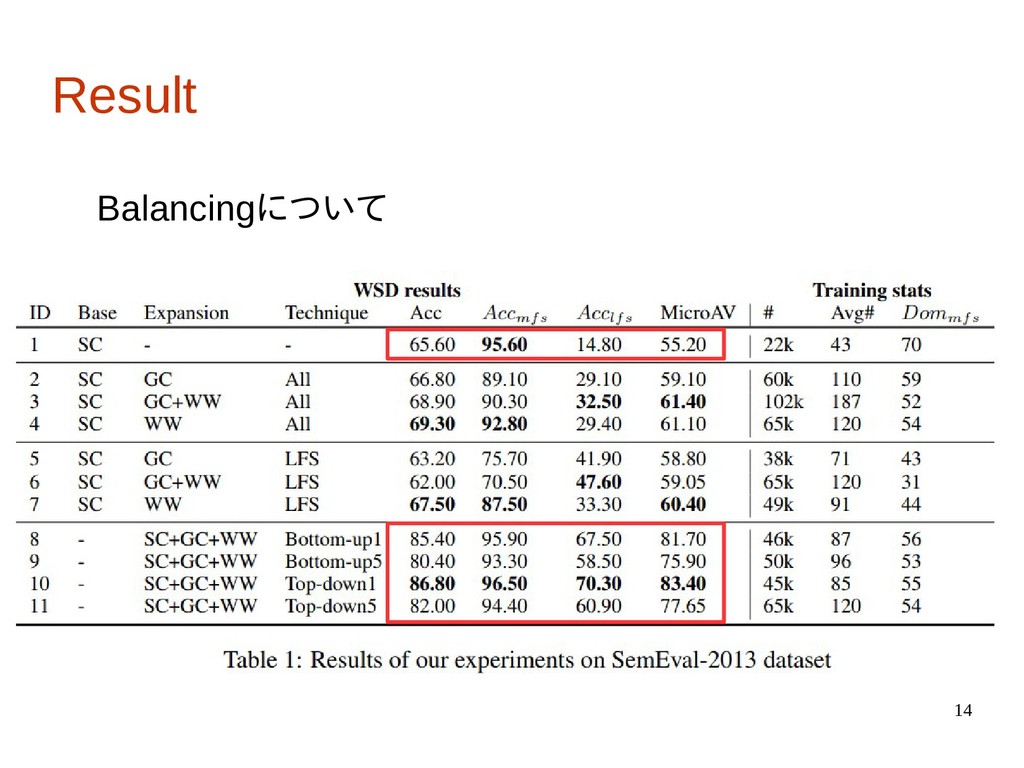
・Balancing:語義の出現分布をテストデータと訓練データ で合わせた時の影響
5 Methodology • 訓練データ ・SemCor(SC) ・Princeton WordNet Gloss Corpus (GC)
手動で注釈を付与 ・Wordnet2Wikipedia (WW) WordnetとWikipediaを使って、語義ごとに文を収集して 意味を付与したデータセット 自動で注釈を付与
6 Methodology • WSDシステム ・IMS(It Make Sense) WSDシステムのフレームワーク 素性として ・周辺単語
・品詞タグ ・コロケーション を使用
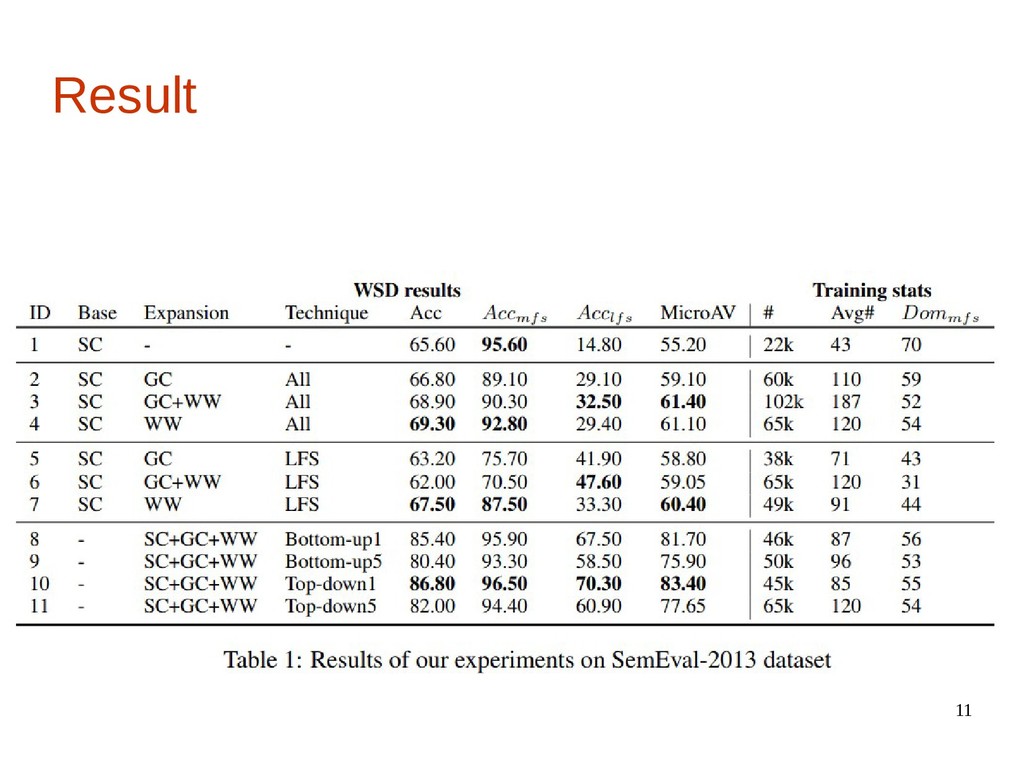
7 Methodology • 評価データ SemEval-2013 task12 のテストセット 1,644個のテストインスタンスが存在 データセットに出現する語義のうち、 MFS:1,035個
LFS:609個
8 Experiment • 実験設定 訓練データはSCをベースとして、GCとWWで拡張する。 訓練データの拡張方法として以下の手法を使用する。 ・All ・LFS ・Top-down ・Bottom-up
9 Experiment ・All MFSとLFSのインスタンスを両方加える。 ・LFS LFSのインスタンスのみ加える。
10 Experiment ・Top-down、Bottom-up テストセットの語義の出現分布から訓練データセットに入れ る例の事例を決定。 Top-downでは最も出現する語義の出現数、 Bottom-upでは最も出現しにくい語義の出現数を基準に 訓練データに入れる事例の数を決めていく。 テストデータに出現しない語義には、一定の事例の数を訓 練データに入れる(今回は1または5)。
11 Result
12 Result VolumeとProvenanceについて
13 Result LFSについて
14 Result Balancingについて
15 Conclusion • WSDにおけるLFSの語義の問題について、 トレーニングデータの影響を調査した。 • 訓練データの量、データの作り方によってWSDの性能を改 善できることが分かった。 • テストデータと訓練データで語義の出現分布が近いほど良
い性能を出せた。 →テストセットの特性に合わせたモデルを構築することで 良い性能を出せる可能性がある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}