Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Learning_to_Identify_the_Best_Contexts_for_Know...
Search
masaya82
June 20, 2018
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Learning_to_Identify_the_Best_Contexts_for_Knowledge-based_WSD
masaya82
June 20, 2018
More Decks by masaya82
See All by masaya82
文献紹介 : More is not always better: balancing sense distributions for all-words
masaya82
0
170
文献紹介:Enhancing Modern Supervised Word Sense Disambiguation Models
masaya82
0
180
文献紹介:The Word Sense Disambiguation Test Suite at WMT18
masaya82
0
120
文献紹介:Preposition Sense Disambiguation and Representation
masaya82
0
150
文献紹介:Word Sense Disambiguation Based on Word Similarity Calculation Using Word Vector Representation from a Knowledge-based Graph
masaya82
0
170
Distributional Lesk: Effective Knowledge-Based Word Sense Disambiguation
masaya82
0
130
Japanese all-words WSD system using the Kyoto Text Analysis ToolKit
masaya82
0
150
Improving Word Sense Disambiguation in Neural Machine Translation with Sense Embeddings
masaya82
0
160
Using Linked Disambiguated Distributional Networks for Word Sense Disambiguation
masaya82
0
110
Featured
See All Featured
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
The Invisible Side of Design
smashingmag
301
52k
Documentation Writing (for coders)
carmenintech
77
5.4k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
For a Future-Friendly Web
brad_frost
183
10k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Become a Pro
speakerdeck
PRO
31
6k
Raft: Consensus for Rubyists
vanstee
141
7.6k
How to Talk to Developers About Accessibility
jct
2
430
Ethics towards AI in product and experience design
skipperchong
2
330
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Transcript
Learning to Identify the Best Contexts for Knowledge-based WSD Evgenia
Wasserman-Pritsker , William W. Cohen , Einat Minkov 2018 6/20 文献紹介 長岡技術科学大学 自然言語処理研究室 福嶋 真也 Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing : page 1662–1667
2 Abstract • 知識ベースのWSDのための有用な文脈上の手がかりを 特定することを目的とした学習フレームワークの概説 • 実験では2つの異なる知識ベースの手法とベンチマーク データセットを使い、その結果従来のウィンドウベースの手 法を上回るようなcontext modelingによる大幅な改善が見
られた。
3 introduction • WSDにおいて、知識ベースの手法では、語義の推 論は知識ベースからの情報を使い、文脈に最も合 致する語義を見つけることが行われる。 • 推論のモデルは発展しているが、context modelingについてはあまり注意が払われていな い。
4 introduction • 文脈はBag-of-Wordsで表現され、通常文脈上の 語の重要度は等しい。 →しかし、中には関係ない語や情報を持たない語も 例:church(building) “An ancient stone
church stands amid the fields, the sound of bells cascading from its tower”
5 introduction • 本研究では語義を予測するための手がかりを識別 するための学習フレームワークを提案 • 文脈上の語の有用性は構文的情報、語彙統計的 情報、単純な語の距離によって評価される。 • WSDを実行する際は最も評価の高い語のみを考
慮
6 Learned context selection models (LCS) • 本研究では以下のように語義を推論する。 Sim()は文脈と候補の語義の類似度を最大化する関数
• Sim()は以下のように表される。 w:単語 s:語義 S(w):単語の全ての語義 Ctx:利用可能な文脈 cj:文脈上の語 ※weight()は普通1となる。 文脈上の語が使えない場合は重みが減る。
7 Learned context selection models (LCS) • 学習 distantly supervised
learning schemeを提案 語義のタグがつけられたインスタンスから、ターゲット の語と、その後が含まれる文脈のペアのデータセットを 作成。 Sim()で予測された語義が正しいなら信頼できる文脈 上の語だと考える。
8 Learned context selection models (LCS) • 特徴の種類 ・単純な単語の距離 ・構文的特徴
→ターゲットの単語と文脈上の語が依存関係に あるとき、文脈上の語の品詞を特徴とする。 ・語彙統計的特徴 →PMI、IDFを使用(頻度はulWac コーパスより 取得)。
9 Experiment • 2つの知識ベースの手法で実験。 ・Gloss Vectors(GV) →上位語、関連語義、共起語などでWordNetの用 語を豊かにする手法。 ・Personalized PageRank
(PPR) algorithm →最先端のWSDパフォーマンスを記録している アルゴリズム。
10 Experiment • データセット ・the lexical sample data set due
to Koeling et al. ・Semeval’07
11 Results • LCSについては、クロスデータ評価(CW)とクロス データ実験(CD)を実施。 ・PPRよりGVの方が改善率が高い。 ・SemEvalについては データセットの歪みで 過大評価されている。
12 Results • 特徴がパフォーマンスに与える影響の調査 ・語彙統計的特徴の与える影響が最も大きい。 →知識ベースのWSDでは局所的な文脈上の語が 有用。 ・単語の距離はあまり 影響しない
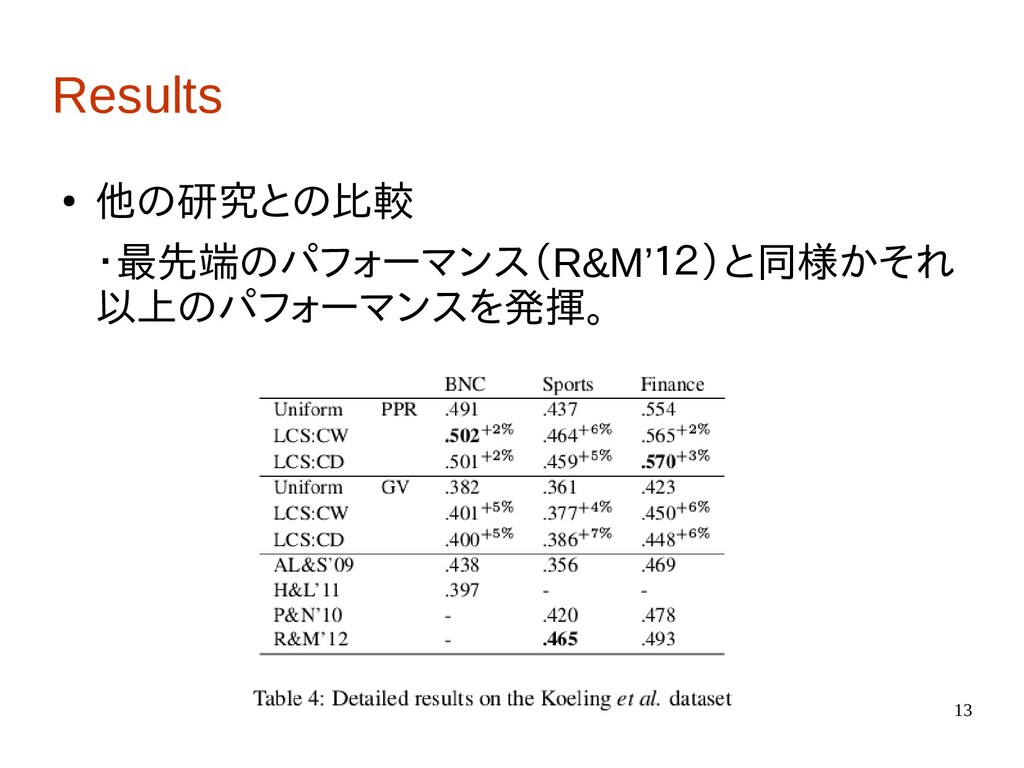
13 Results • 他の研究との比較 ・最先端のパフォーマンス(R&M’12)と同様かそれ 以上のパフォーマンスを発揮。
14 Conclusion & future work • 知識ベースのWSDにおいて有用な手がかりとなる文脈上 の語の識別を行う学習フレームワークを作成 • 提案手法は多様な種類の証拠を効果的に強化する。
• 将来的に単語関連性の尺度をフレームワークに追加する。 特別なモデルを作成することにも関心がある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}