Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Improving Word Sense Disambiguation in Neural M...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
masaya82
July 25, 2018
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Improving Word Sense Disambiguation in Neural Machine Translation with Sense Embeddings
masaya82
July 25, 2018
More Decks by masaya82
See All by masaya82
文献紹介 : More is not always better: balancing sense distributions for all-words
masaya82
0
170
文献紹介:Enhancing Modern Supervised Word Sense Disambiguation Models
masaya82
0
180
文献紹介:The Word Sense Disambiguation Test Suite at WMT18
masaya82
0
120
文献紹介:Preposition Sense Disambiguation and Representation
masaya82
0
150
文献紹介:Word Sense Disambiguation Based on Word Similarity Calculation Using Word Vector Representation from a Knowledge-based Graph
masaya82
0
170
Distributional Lesk: Effective Knowledge-Based Word Sense Disambiguation
masaya82
0
130
Japanese all-words WSD system using the Kyoto Text Analysis ToolKit
masaya82
0
150
Learning_to_Identify_the_Best_Contexts_for_Knowledge-based_WSD
masaya82
0
150
Using Linked Disambiguated Distributional Networks for Word Sense Disambiguation
masaya82
0
110
Featured
See All Featured
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The Spectacular Lies of Maps
axbom
PRO
1
870
Git: the NoSQL Database
bkeepers
PRO
432
67k
How to Talk to Developers About Accessibility
jct
2
430
BBQ
matthewcrist
89
10k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Building Applications with DynamoDB
mza
96
7.1k
Utilizing Notion as your number one productivity tool
mfonobong
4
450
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
First, design no harm
axbom
PRO
2
1.2k
Transcript
Improving Word Sense Disambiguation in Neural Machine Translation with Sense
Embeddings Annette Rios and Laura Mascarell and Rico Sennrich 2018 7/25 文献紹介 長岡技術科学大学 自然言語処理研究室 福嶋 真也 Proceedings of the Conference on Machine Translation (WMT), Volume 1: Research Papers, pages 11–19 Copenhagen, Denmark, September 711, 2017.
2 Abstract • NMTにおけるWSDの能力は定量化されていない。 • NMTにおけるWSDの能力を評価するための新しいcloss – lingual WSD task
をデザインした。 • German-English, German-Frenchでそれぞれテストデー タを作成し、評価を行った。
3 introduction • 機械翻訳において、正確な翻訳文を生成するためには与えら れた文脈から正確な意味を決定しなければならない。 • エラーは間違った翻訳や理解不能な翻訳を生み出すが、どの タイプのエラーが難しいかは定量化されていない。 →BLEUのような自動評価では詳細な解析が出来ないため •
機械翻訳のための語彙選択を評価する手法はいくつか提案されて いる。 しかし、同義語や言い換えなども罰されてしまう。
4 introduction • 提案するタスクではシステムに決められた翻訳セットから1つ の翻訳を選択するように制限。 • 大規模かつ再現可能な方法でWSDの評価を行いたい。 →NMTでは、文のペアに対して条件付き確率P(T|S)が割り 当てられることを利用する。 ※S:元の文、T:翻訳文
• 曖昧性によるエラーを含む文とリファレンスでNMTモデルの スコアを計算し、比較することでどのくらいうまく語義を区別で きているか評価する。
5 Test Set • 作成法 対訳コーパスのリファレンスから曖昧性のある語を別の意 味に置き換えて、別の翻訳結果を自動的に作る。 →作成には対訳コーパス、語義曖昧性を持つ名詞を 集めたものが必要。 例:
6 Test Set • テストデータとなる文の収集 ・語義曖昧性を持つ語: 既存のフレーズベースのMTシステムにある語彙の変換表から ドイツ語の語義曖昧性を持つ語を抽出。 ・対訳コーパス: 右図中の対訳コーパスを使用
(German-French, German-English,)
7 Approach • ベースラインと2つのWSDの手法を用いる。 ・ベースライン:最も頻出する意味を用いる。 ・Sense Embeddings: SenseGram(Pelevina et al.,
2016)を用いてSense Embeddingsを計算、学習して共起表現から語義を決定する手 法。 ・Lexical chain: SenseGramを用いて意味的に似ている語を集め、それぞれの embeddingを連結させたものを語のベクトル表現として用いる 手法。
8 Evaluation • 2つのNMTシステムを使用。 ・学習:210万文(EuroparlとNews Commentaryより) ・byte pair encoding(Sennrich et
al.,2016b)とNematus (Sennrich et al., 2017)を使用 ・Adam (Kingma and Ba, 2015)を使い、パラメータを更新 ・minibatch size : 80
9 Result • accuracyの比較 Human:N=100-150 (Random sampling)
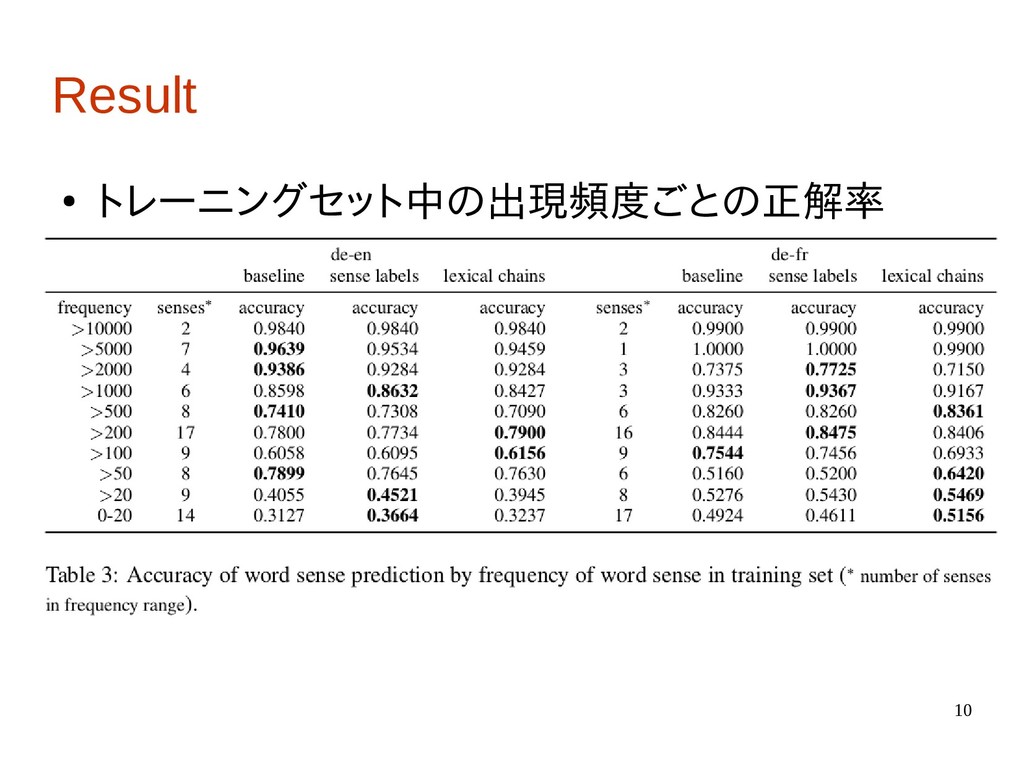
10 Result • トレーニングセット中の出現頻度ごとの正解率
11 Conclusion • NMTモデルを評価するための新たな語彙選択タスクを紹介 し、German-English、German-Frenchのテストセットを提示した。 • このタスクではNMTモデルにおける語彙の曖昧性解消についての能 力を自動的かつ定量的に解析できる。 • 実験では、ベースラインは学習データに頻出しない語義に弱いが、提
案した2つの手法ではそれに対して改善が見られた。 • 人間とNMTモデルの比較で、このタスクを解くためには文書の文脈 を広げる必要がある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}