Vector Representation from a Knowledge-based Graph Dongsuk O, Sunjae Kwon, Kyungsun Kim and Youngjoong Ko 2018 10/19 文献紹介 長岡技術科学大学 自然言語処理研究室 福嶋 真也 Proceedings of the 27th International Conference on Computational Linguistics, pages 2704–2714 Santa Fe, New Mexico, USA, August 20-26, 2018.
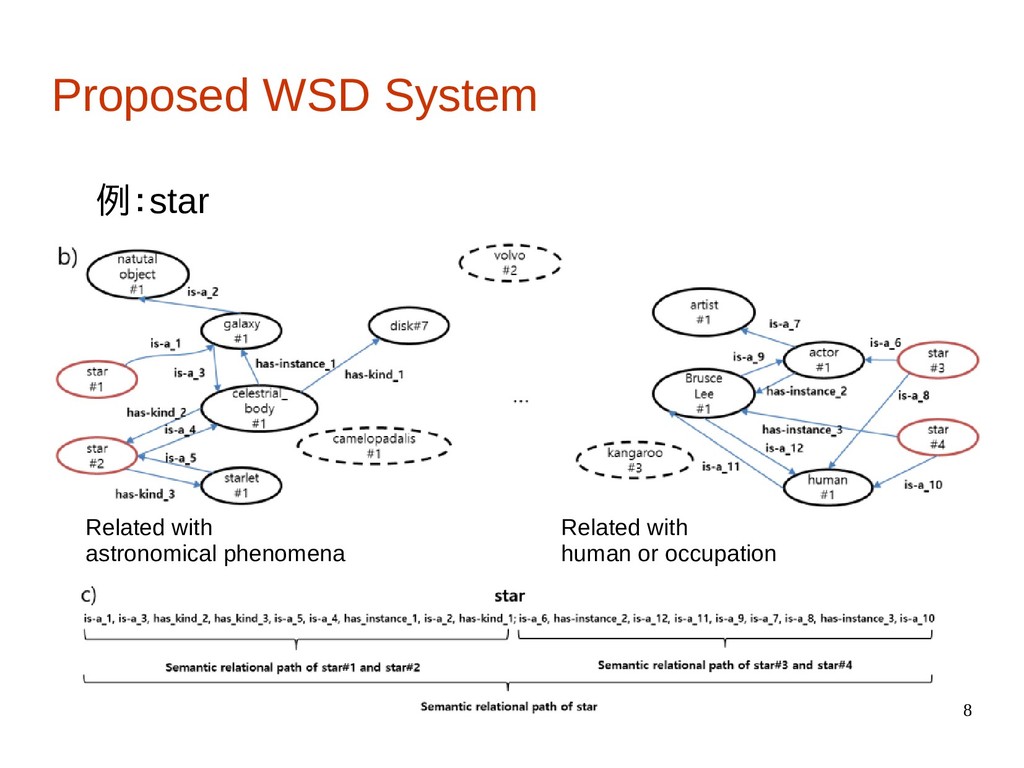
hot gases", star#2: “Any celestial body visible from the Earth at night.”, star#3: “An actor who plays a principal role” star#4: “A widely known person.”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}