Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2022後期(EMNLP2022)_Towards Opening the Black...
Search
maskcott
December 19, 2022
77
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
December 19, 2022
More Decks by maskcott
See All by maskcott
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
poster.NAACL-SRW_Two Sentence Concatenation Approach to Data Augmentation for Neural Machine Translation
maskcott
0
120
Featured
See All Featured
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
First, design no harm
axbom
PRO
2
1.2k
Mobile First: as difficult as doing things right
swwweet
225
10k
Crafting Experiences
bethany
1
190
How STYLIGHT went responsive
nonsquared
100
6.2k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
400
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
210
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Transcript
発表者: 小町研 M2 今藤誠一郎 2022/12/19 @論文紹介2022 後期(EMNLP 2022) 1
概要 2 • NMTモデルの解釈可能性について,全ての入力(src 文と prefix)がモデルの 予測に与える影響を追跡する手法(ALTI+)を提案. • ALTI+を用いて Transformer
ベースのモデル(bi-lingual, multi-lingual)に 適用して NMT モデルの挙動を分析した ◦ 入力文の <EOS> には src の情報を利用しないように促す効果がある ◦ hallucination を生成する時には src の貢献度が低い ◦ 英語→low-resource 言語 の翻訳時は src の貢献度が低い
関連研究 • Analyzing the Source and Target Contributions to Predictions
in Neural Machine Translation [Voita et al., ACL 2021] 🔗 ◦ Layer-wise Relevance Propagation (LRP) を用いた分析 ◦ 文長を揃えたコーパス単位でしか分析ができない → 本研究では文単位でも分析できる手法 • Measuring the Mixing of Contextual Information in the Transformer [Ferrando et al., EMNLP 2022] 🔗 ◦ ALTI (Aggregation of Layer-wise Tokens Attributions) を用いてBERT や RoBERTa を分析 ◦ 本研究はこの手法を Seq2Seq Transformer モデルに拡張(ALTI+) 3
ALTI • 各エンコーダ層で埋め込み表現が生成される際に,入力の各トークンがそれ ぞれどれだけ貢献しているのかを計算して集計. → エンコーダの入出力トークン間での貢献度 • 前準備 ◦ Multi-head
Attention を式変形 ◦ Layer normalization を式変形 4 各ヘッドの出力 : a の区分行列
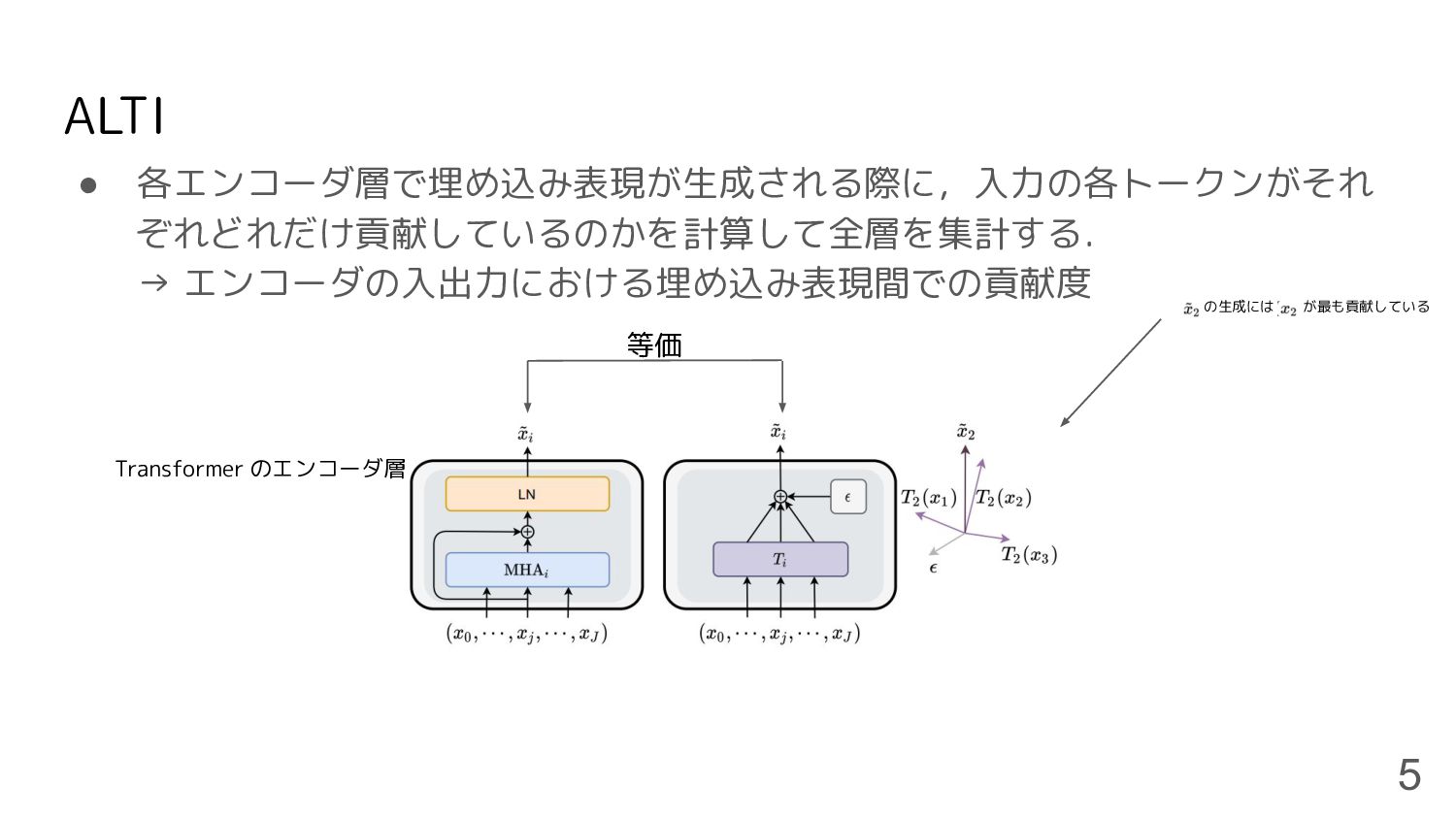
ALTI • 各エンコーダ層で埋め込み表現が生成される際に,入力の各トークンがそれ ぞれどれだけ貢献しているのかを計算して全層を集計する. → エンコーダの入出力における埋め込み表現間での貢献度 5 等価 Transformer のエンコーダ層
の生成には が最も貢献している
ALTI • 前準備 ◦ Transformerモデルのエンコーダ層における入出力関係を改めて式で表現 ◦ Multi-head Attention を式変形 ◦
Layer normalization の式に代入 6 各ヘッドの出力 : a の区分行列
ALTI • 出力ベクトルを入力トークンごとの成分に分解 ◦ Layer Normalization が に変換できることを利用 → • 入力
が 出力 に与える影響をマンハッタン距離で表現 → 貢献度を以下で定義 7 ( ) 残差接続 ※ ( ) :距離が大きいほど影響が小さくなる項
ALTI • 層ごとの貢献度を集計 ◦ Transformer の情報の流れを有向非巡回グラフに基づいてモデリングするアプローチを利用 ▪ ノード:トークン ▪ エッジ:入力が出力に与える影響( )
◦ 異なる層におけるノードからノードへの計算はパスの総和で計算 ◦ 層から層は積で計算 → 8 先行研究より CLSから への計算のイメージ
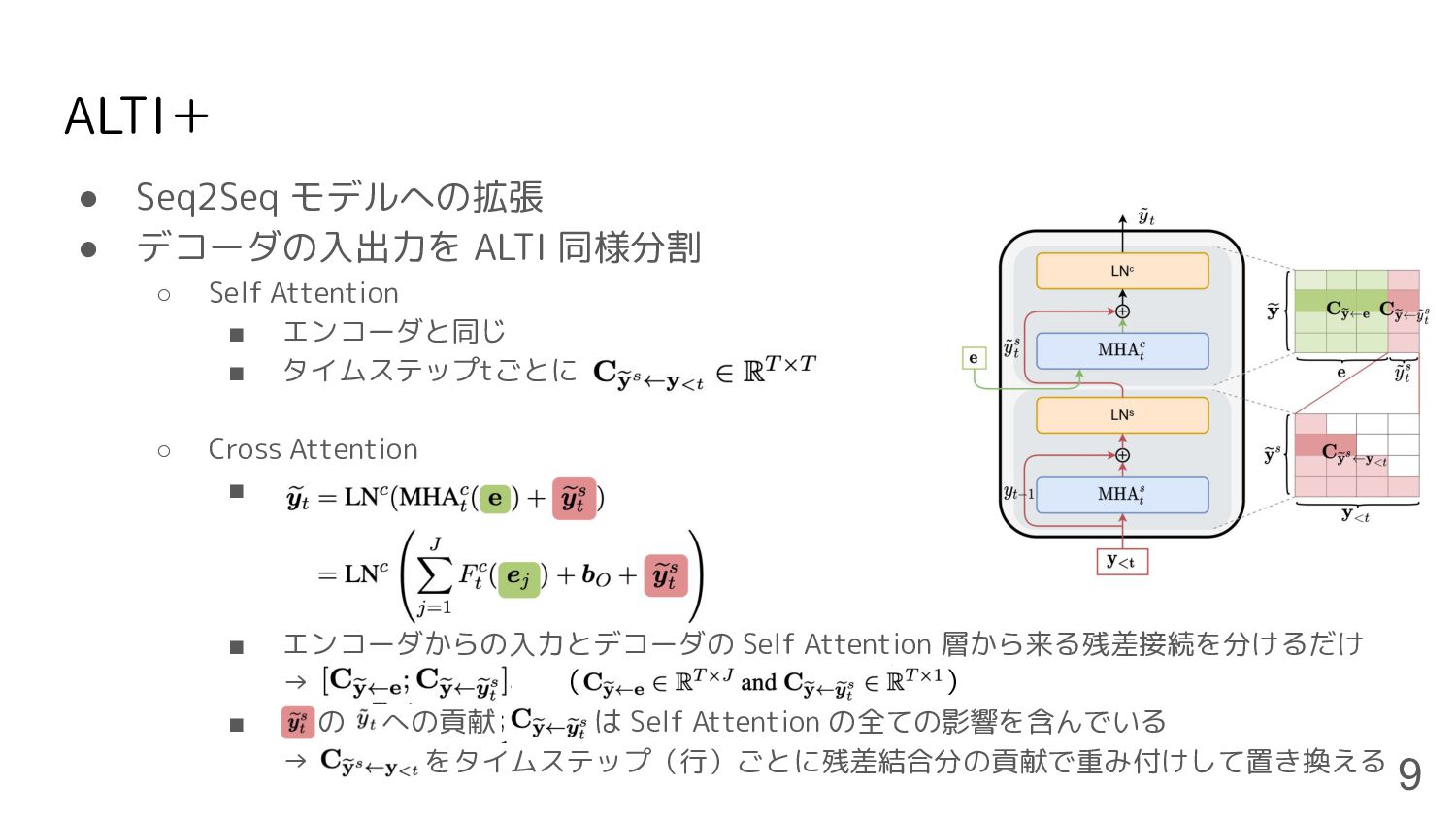
ALTI+ • Seq2Seq モデルへの拡張 • デコーダの入出力を ALTI 同様分割 ◦ Self
Attention ▪ エンコーダと同じ ▪ タイムステップtごとに ◦ Cross Attention ▪ ▪ エンコーダからの入力とデコーダの Self Attention 層から来る残差接続を分けるだけ → ▪ の への貢献 は Self Attention の全ての影響を含んでいる → をタイムステップ(行)ごとに残差結合分の貢献で重み付けして置き換える 9 ( )
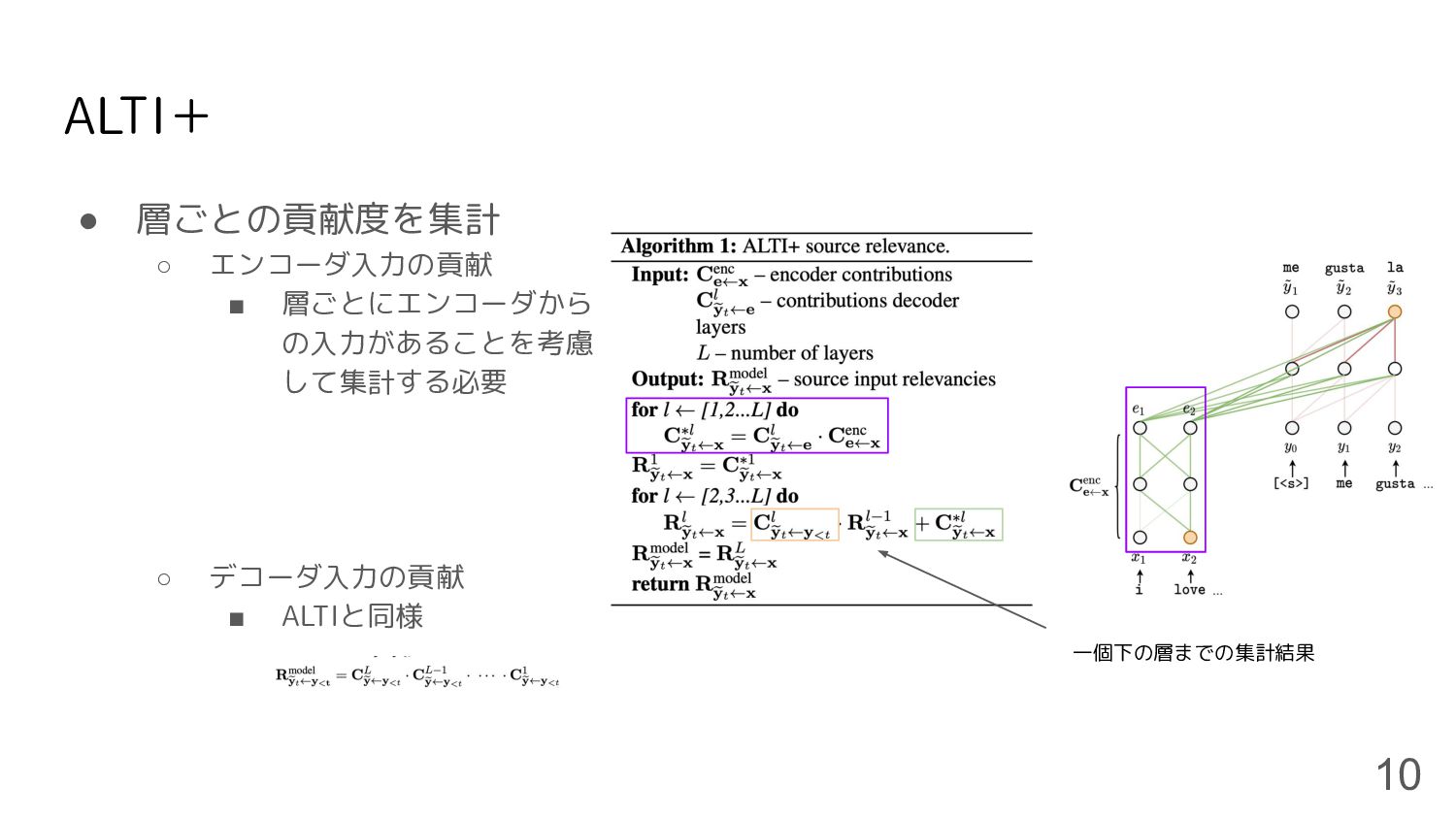
ALTI+ • 層ごとの貢献度を集計 ◦ エンコーダ入力の貢献 ▪ 層ごとにエンコーダから の入力があることを考慮 して集計する必要 ◦
デコーダ入力の貢献 ▪ ALTIと同様 10 一個下の層までの集計結果
実験 • Bi-lingual と Multi-lingual の設定で実験 ◦ Bi-lingual : 6層の
Transformer,De-En タスク ▪ Europarl v7 で学習 ◦ Multi-lingual: M2M Transformer(Fan et al., 2021) ▪ Fairseq で公開されているモデル • IWSLT’14 GermanEnglish dataset の 1,000 文を用いて定量分析 11
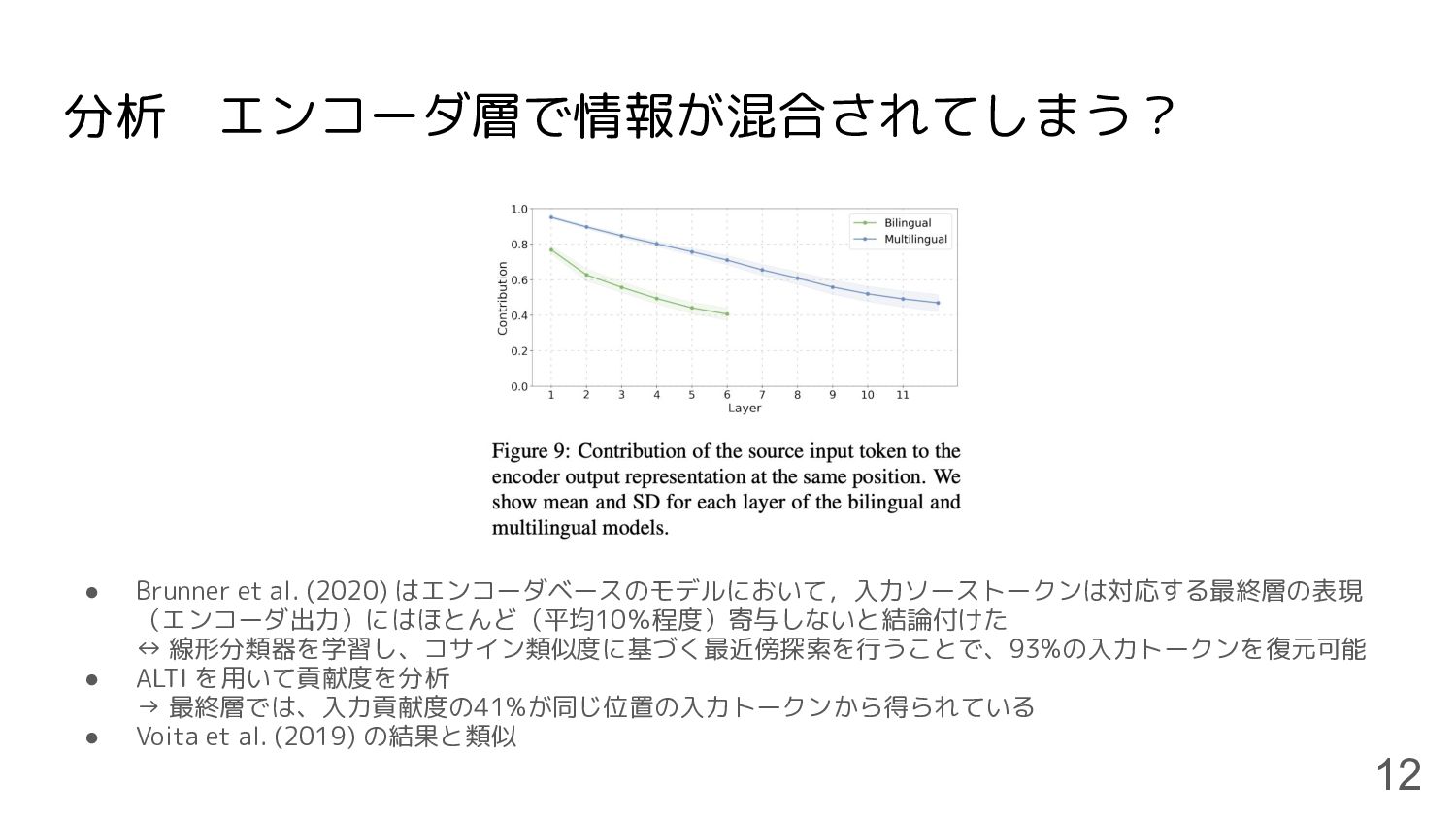
分析 エンコーダ層で情報が混合されてしまう? • Brunner et al. (2020) はエンコーダベースのモデルにおいて,入力ソーストークンは対応する最終層の表現 (エンコーダ出力)にはほとんど(平均10%程度)寄与しないと結論付けた ↔ 線形分類器を学習し、コサイン類似度に基づく最近傍探索を行うことで、93%の入力トークンを復元可能
• ALTI を用いて貢献度を分析 → 最終層では、入力貢献度の41%が同じ位置の入力トークンから得られている • Voita et al. (2019) の結果と類似 12
分析 Cross-Attention における貢献度の評価 • 人手アライメントに対する貢献度の Alignment Error Rate (AER) で評価 •
Garg et al. の主張に基づいて最後から2番目の層(Bi-lingual モデルの 第5層)を利用 13 先行研究の Attention の重みを利用する手法では </s>に集まってしまい,ノイズになっている 提案手法では</s>の貢献度はなくなっている
分析 End-of-Sentence トークンの役割について • Ferrando and Costa-jussà (2021) の先行研究 ◦ “</s>”
や “.” の Value ベクトルは 0 ノルムに近い ◦ “</s>” や “.” への Attention の重みは prefix に基づいて予測する時(接置詞,接辞 ,subword の末尾等)に大きくなる傾向 • 2つ目の主張を検証 ◦ “</s>” におけるAttention の重みと提案手法にの残差接続部分における貢献度でピアソンの 相関係数を測る(前ページ (a) と (b) の一番右の列) 14 • ほぼ全ての層で高い相関 • 文を終了させるトークン は src への Attention を スキップするのに利用
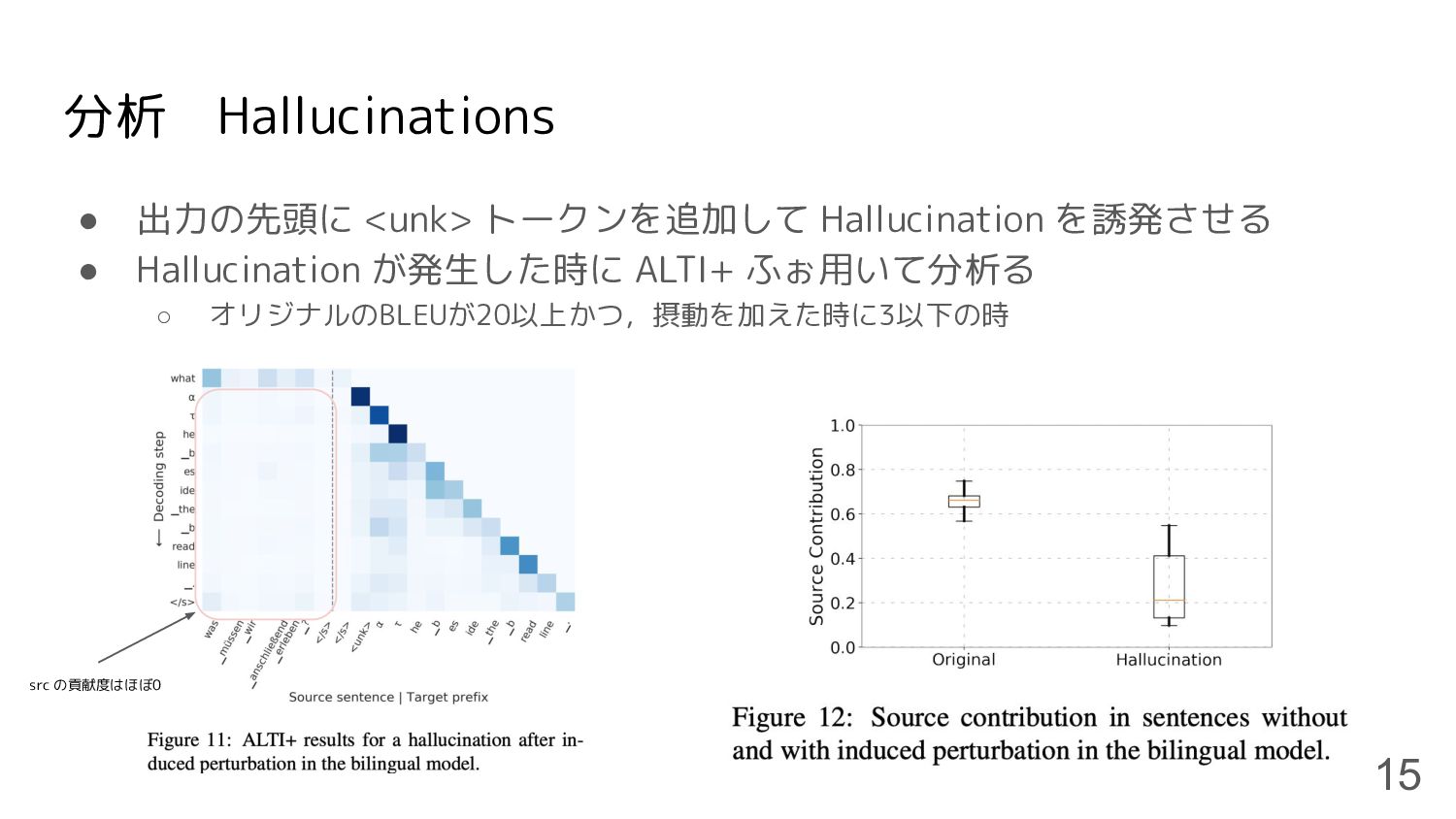
分析 Hallucinations • 出力の先頭に <unk> トークンを追加して Hallucination を誘発させる • Hallucination が発生した時に
ALTI+ ふぉ用いて分析る ◦ オリジナルのBLEUが20以上かつ,摂動を加えた時に3以下の時 15 src の貢献度はほぼ0
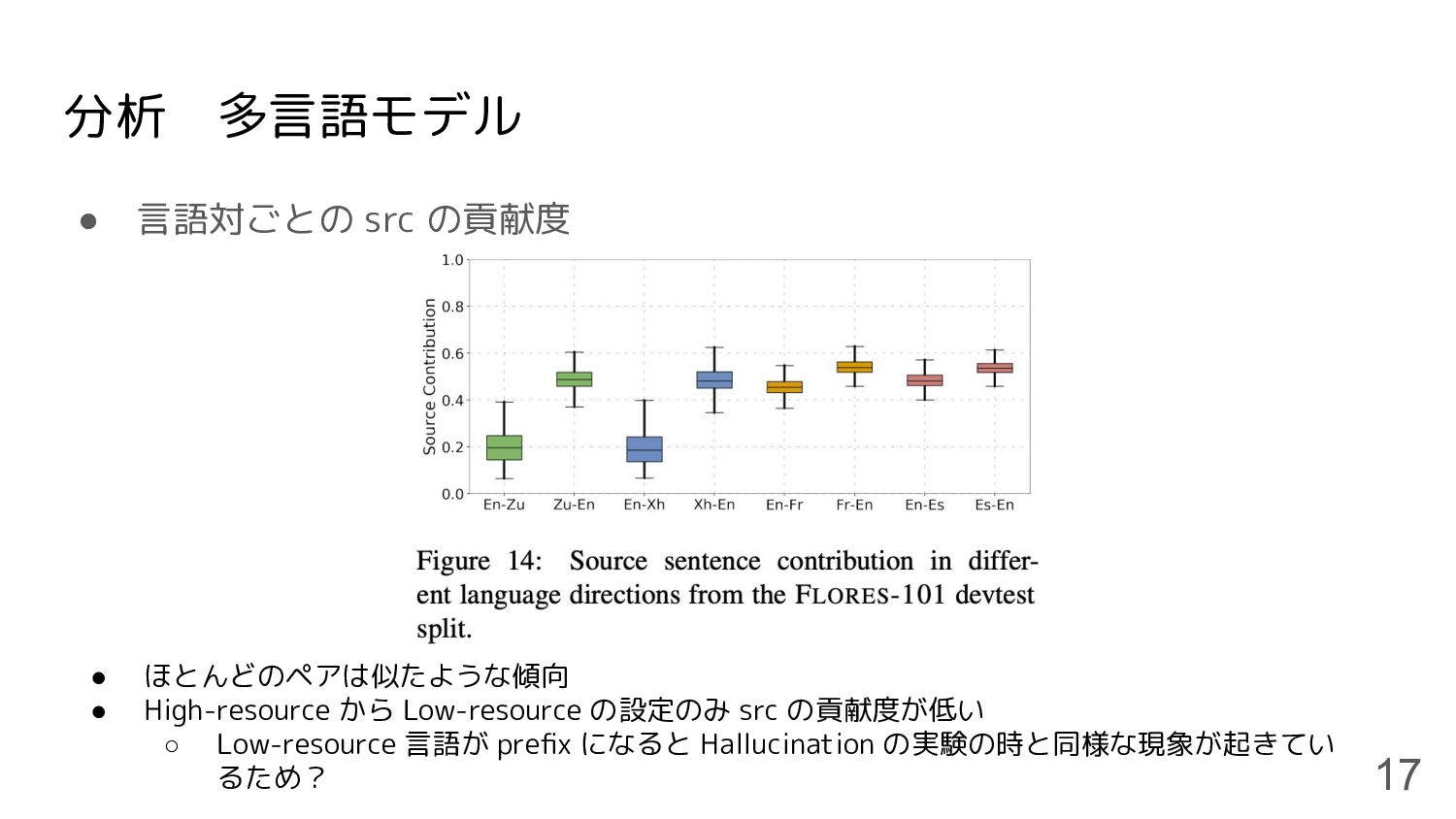
分析 多言語モデル • 複数の言語対で実験 ◦ High-resource: English (En), Spanish (Es), French
(Fr) ◦ Low-resource: Zulu (Zu) and Xhosa (Xh) • 言語タグの貢献度の分布 (prefix 2列目)はほぼ一様 ◦ 固有名詞の生成時は下がる傾向 → どの言語でも同じ表現だから 言語を気にする必要がないため? • 出力単語の依存関係も見える ◦ “for” 生成時の ”thanks” ◦ “Williams” 生成時の “Mr” ◦ “into” 生成時の “introducing” 16
分析 多言語モデル • 言語対ごとの src の貢献度 17 • ほとんどのペアは似たような傾向 • High-resource
から Low-resource の設定のみ src の貢献度が低い ◦ Low-resource 言語が prefix になると Hallucination の実験の時と同様な現象が起きてい るため?
まとめ • Transformer ベースの Seq2Seq モデルを分析する手法 ALTI+ を提案 • 入力文の貢献度を
src と prefix の両方の観点から分析 • Bi-lingual モデルと Multi-lingural モデルに適用し,モデルの挙動に関する 洞察を得ることができた 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}