Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-...
Search
maskcott
November 18, 2022
43
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
November 18, 2022
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
poster.NAACL-SRW_Two Sentence Concatenation Approach to Data Augmentation for Neural Machine Translation
maskcott
0
120
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Facilitating Awesome Meetings
lara
57
7k
The Limits of Empathy - UXLibs8
cassininazir
1
370
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
170
Mobile First: as difficult as doing things right
swwweet
225
10k
Unsuck your backbone
ammeep
672
58k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
220
Navigating Weather and Climate Data
rabernat
0
240
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Transcript
発表者: 小町研 M2 今藤誠一郎 2022/11/21 @論文紹介2022 後期(ACL2022) 1
Introduction 背景 • 機械翻訳は学習データにあまり出てこない固有表現を適切に翻訳するのが 難しい ◦ 新しい固有表現(人名、地名etc)は日々増え続けるため重要 ↓ 文中に出てくる固有表現を正確に翻訳できるようなモデルを作りたい! 2
Introduction 3 先行研究 • ルールベースの手法(Wan and Verspoor, 1998) • 統計的アライメントを用いた手法(
Huang et al., 2003, 2004) • Web マイニングを用いた手法 (Huang et al., 2005; Wu and Chang, 2007; Yang et al., 2009) ↓ • 文脈を無視した翻訳 ◦ 文脈から曖昧性を解消することが難しい • 多くが “固有表現抽出→翻訳” という2段階 ◦ 構造が複雑 ◦ カスケード故障となりやすい
Introduction 4 先行研究 • MASS(Song et al.) や mBART(Liu et
al.) などの事前学習を用いたNMT → (low, medium)-resourceな設定で翻訳精度を向上させる ↓ • この事前学習を固有表現に特化したい気持ち
概要 5 • 翻訳において固有表現の正解率を上げるための手法(DEEP: DEnoising Entity Pretraining)を提案 • ファインチューニング時にも翻訳タスクと事前学習タスクのマルチタスク学 習を行うことで、固有表現の翻訳精度向上を調査
• 英語と3言語の翻訳実験から提案手法が固有表現の翻訳を大きく改善すること を示した
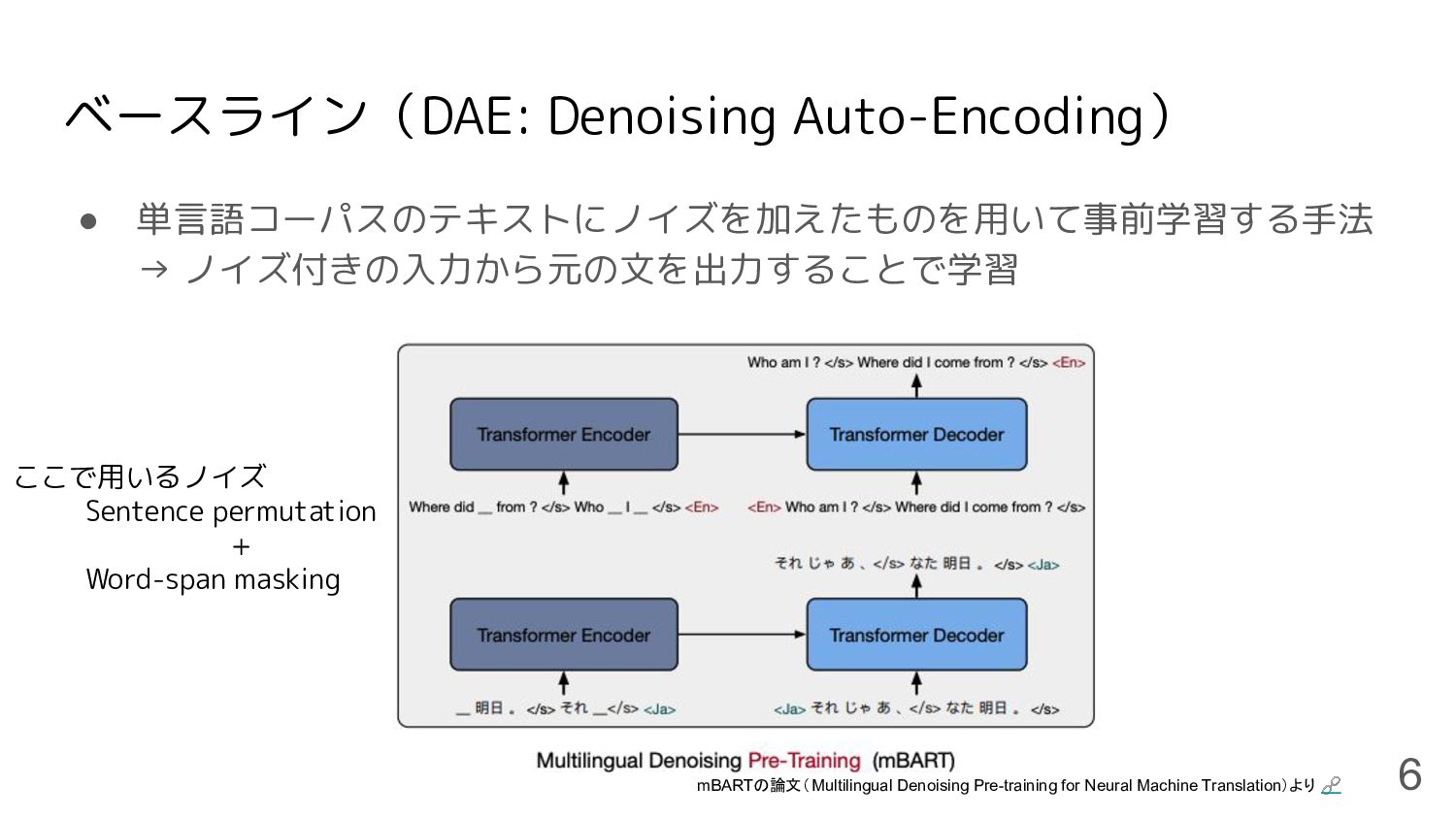
ベースライン(DAE: Denoising Auto-Encoding) • 単言語コーパスのテキストにノイズを加えたものを用いて事前学習する手法 → ノイズ付きの入力から元の文を出力することで学習 6 mBARTの論文(Multilingual Denoising
Pre-training for Neural Machine Translation)より 🔗 ここで用いるノイズ Sentence permutation + Word-span masking
提案手法(DEEP) • 先の DAE の拡張 • 目的言語側の単言語コーパスの固有表現を原言語に置き換えたものを利用 7 1. 固有表現認識&リンキング
2. 固有表現に基づいたデータ拡張 3. マルチタスクファインチューニング
提案手法 ①固有表現認識&リンキング • 利用するデータ:目的言語側の単言語コーパス(Wikipedia記事) • 知識ベース:Wikidata(Wikipedia記事の存在する様々な言語の表層形) • SLING(Ringgaard et al.,
2017)を用いて固有表現を認識 • 固有表現を知識ベースに基づいて原言語の表層形に置き換える 8 例: en-ru
提案手法 ②DEEP • ノイズを加えた(固有表現を原言語表現に置き換えた)テキストを入力して 元の目的言語文を出力するようにモデルを事前学習 • 固有表現が少ない系列は学習が容易になってしまう ◦ 置換されているスパンが単語単位で35%より少なかったら、35%になるまで mask
を行う • mBART同様文の並び替えも行う 9
提案手法 ③マルチタスクファインチューニング • 事前学習時の固有表現の情報を忘却しないため • 単言語コーパスは各エポック内でサンプリングして対訳コーパスとのデータ 数を揃える • 文頭の [BOS]
をタスクごとに置き換える([MT], [DAE], [DEEP]) 10
実験設定 • 事前学習データ:Wikipedia • ファインチューニング(テスト)データ: • モデル:Transformer • 比較手法 ◦
Random→MT:事前学習なし、ランダムに初期化、MTのファインチューニング ◦ DAE→MT:mBART(Liu et al.)同様の事前学習、MTのファインチューニング ◦ DEEP→MT:提案手法で事前学習、MTのファインチューニング ◦ DAE→DAE+MT:mBART(Liu et al.)同様の事前学習、マルチタスク学習 ◦ DEEP→DEEP+M:提案手法で事前学習、マルチタスク学習 • 事前学習 50Kstep, ファインチューニング 40Kstep 11 言語 En-Ru En-Uk En-Ne データ WMT18 TED FLORES
実験結果 コーパスレベルの評価 • 事前学習の手法はBLEU, chrFの観点から有効 • low-resourceな設定(En-Ne)でDEEPはDAEよりも有効 • En-Ru, En-Neではマルチタスク学習の効果がみられる
• ファインチューニング時、DEEPの学習は他よりも早い(付録1) ◦ 事前学習における固有表現の翻訳によってより良い初期化がなされているためでは 12
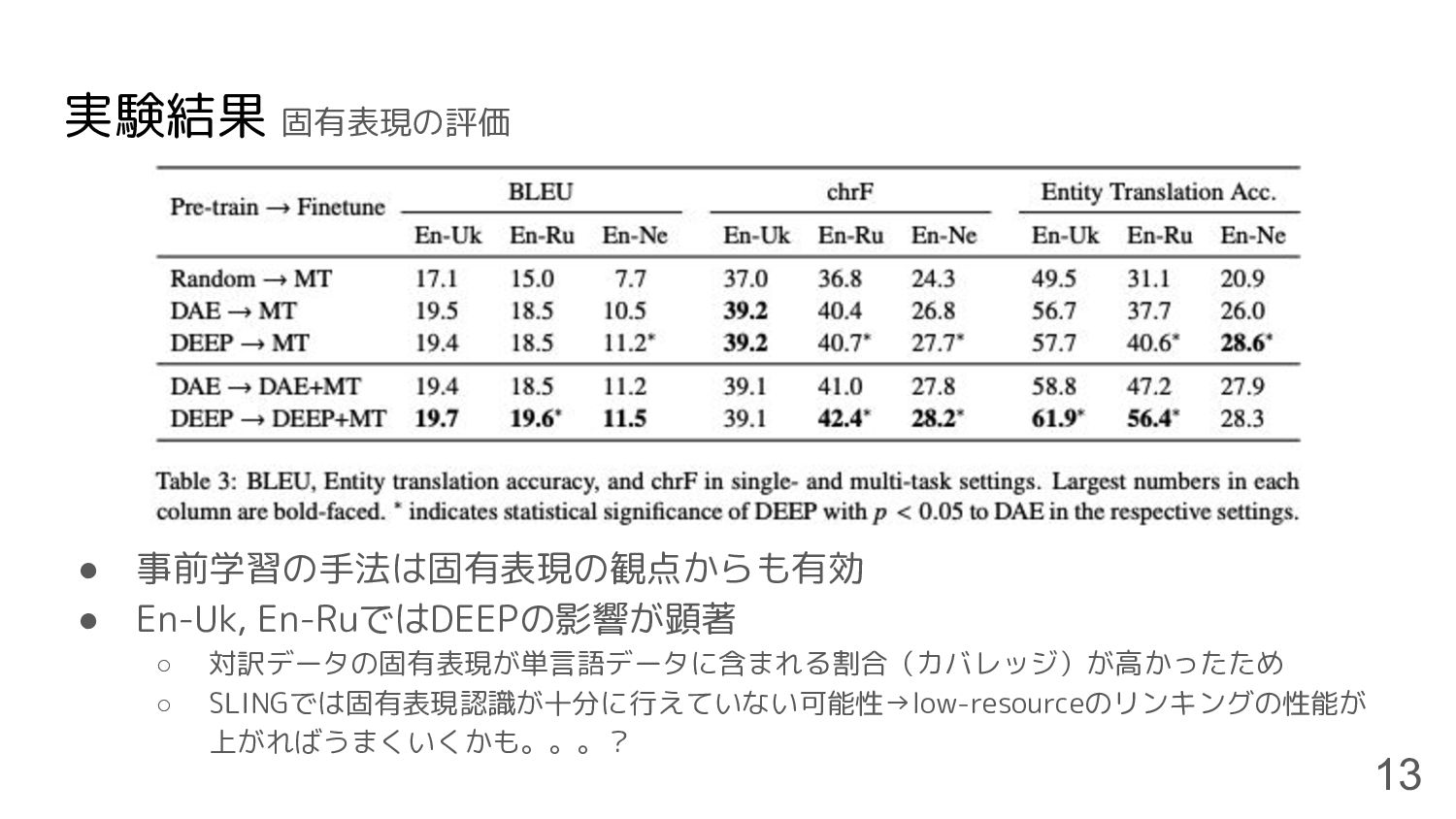
実験結果 固有表現の評価 • 事前学習の手法は固有表現の観点からも有効 • En-Uk, En-RuではDEEPの影響が顕著 ◦ 対訳データの固有表現が単言語データに含まれる割合(カバレッジ)が高かったため ◦
SLINGでは固有表現認識が十分に行えていない可能性→low-resourceのリンキングの性能が 上がればうまくいくかも。。。? 13
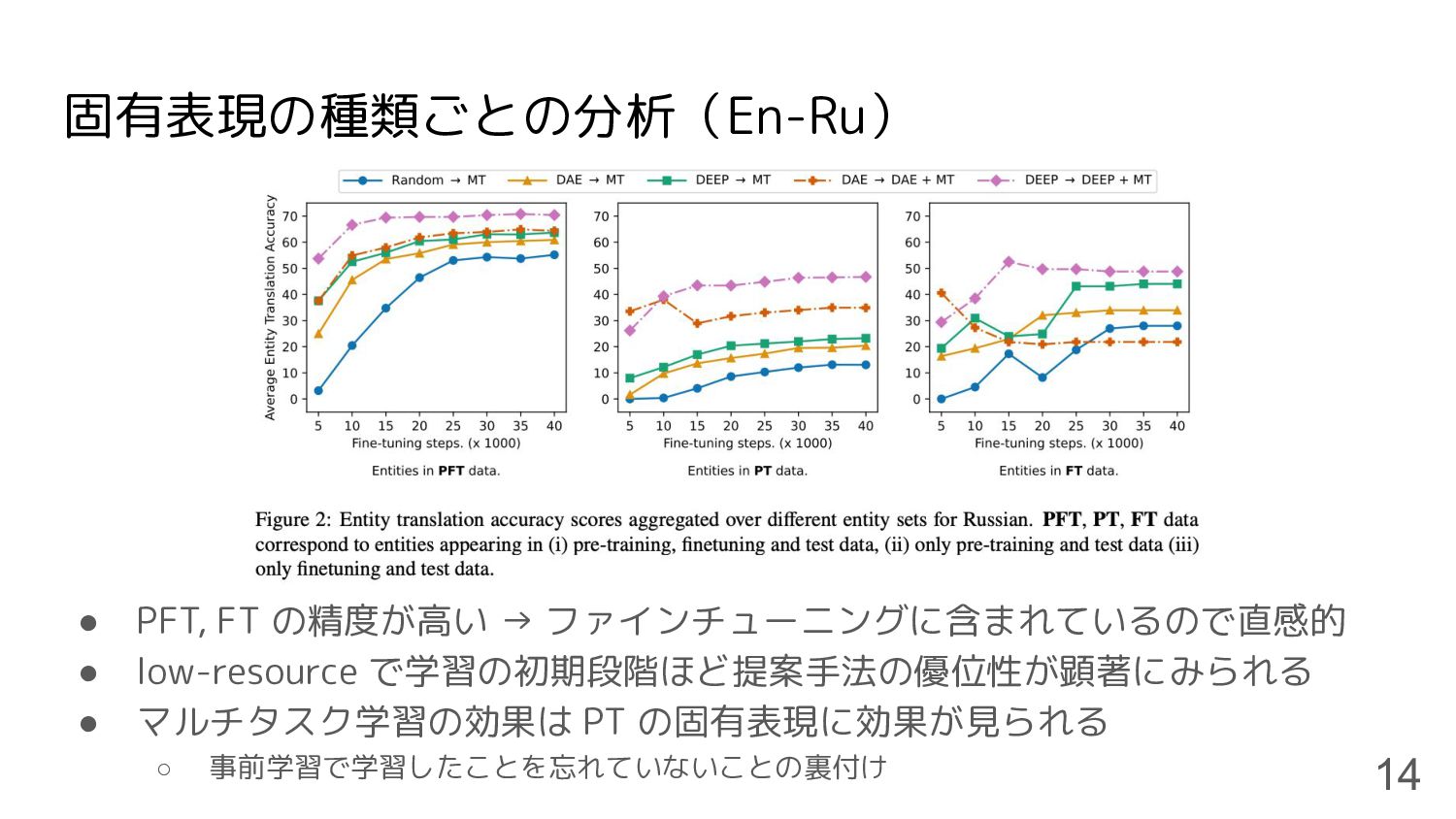
固有表現の種類ごとの分析(En-Ru) • PFT, FT の精度が高い → ファインチューニングに含まれているので直感的 • low-resource で学習の初期段階ほど提案手法の優位性が顕著にみられる
• マルチタスク学習の効果は PT の固有表現に効果が見られる ◦ 事前学習で学習したことを忘れていないことの裏付け 14
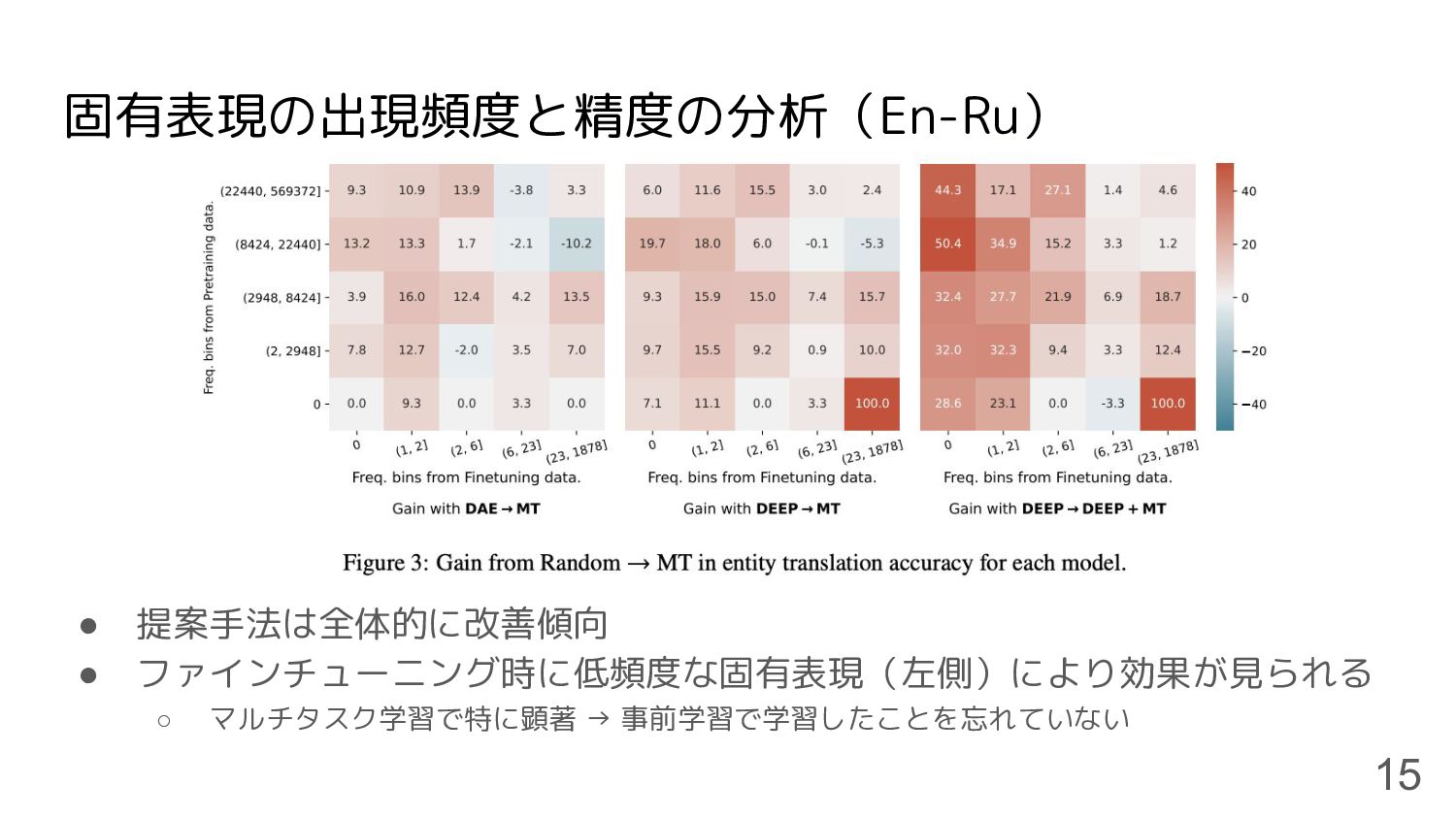
固有表現の出現頻度と精度の分析(En-Ru) • 提案手法は全体的に改善傾向 • ファインチューニング時に低頻度な固有表現(左側)により効果が見られる ◦ マルチタスク学習で特に顕著 → 事前学習で学習したことを忘れていない 15
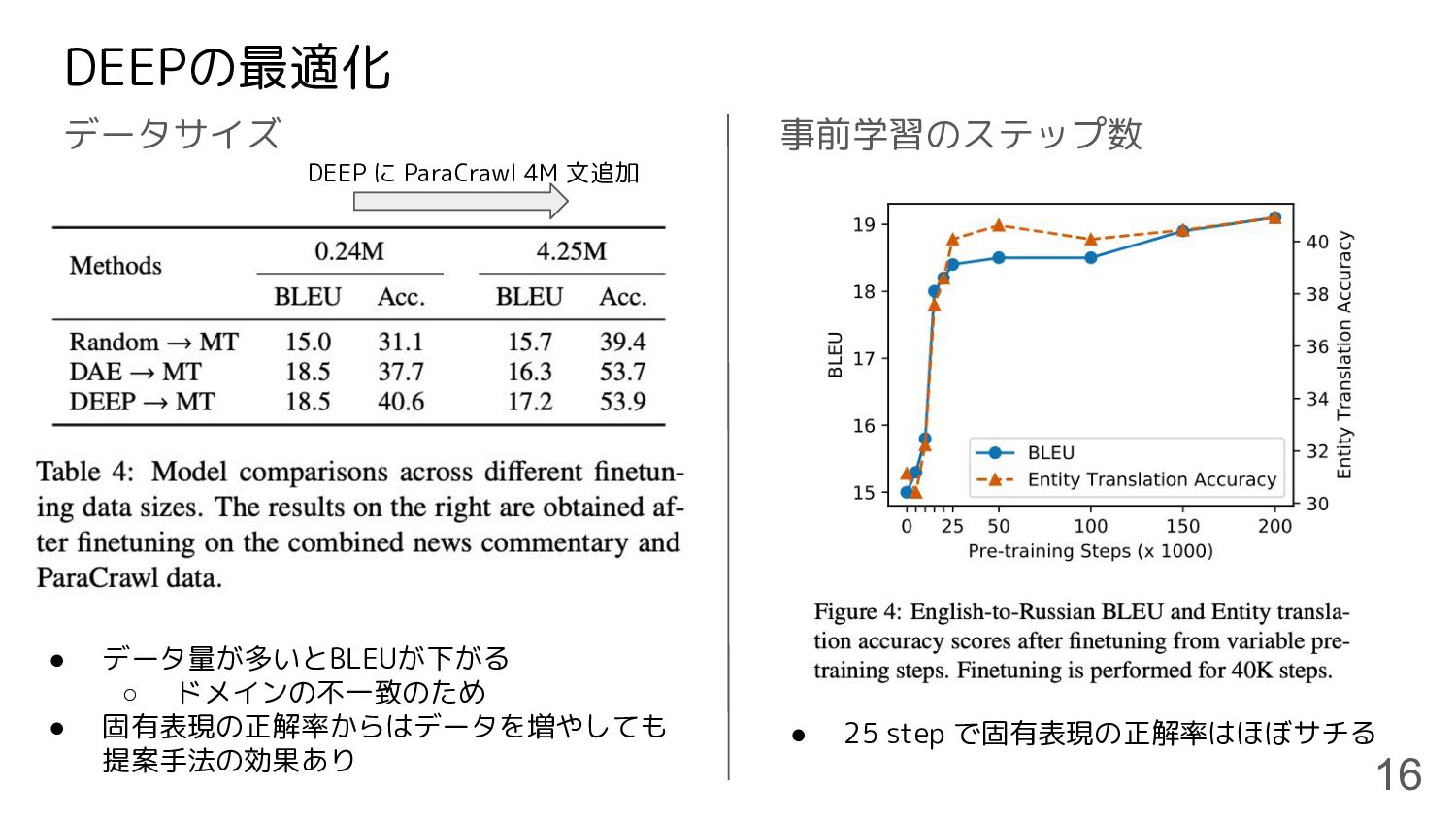
DEEPの最適化 データサイズ 16 事前学習のステップ数 • データ量が多いとBLEUが下がる ◦ ドメインの不一致のため • 固有表現の正解率からはデータを増やしても
提案手法の効果あり DEEP に ParaCrawl 4M 文追加 • 25 step で固有表現の正解率はほぼサチる
まとめ • NMTにおける固有表現に基づく事前学習手法を提案 • シングルタスクとマルチタスクの両方において、ベースラインのDAEより も、固有表現の翻訳精度とBLEUスコアを向上させることができた • 課題 ◦ 知識グラフの研究も盛んに行われているため、これらをうまく利用して固有表現の曖昧性を
どのように解決するのか ◦ ドメイン内の事前学習でより精度が向上する可能性がある(前スライド) 17
翻訳例(定性評価) 18
付録1 19
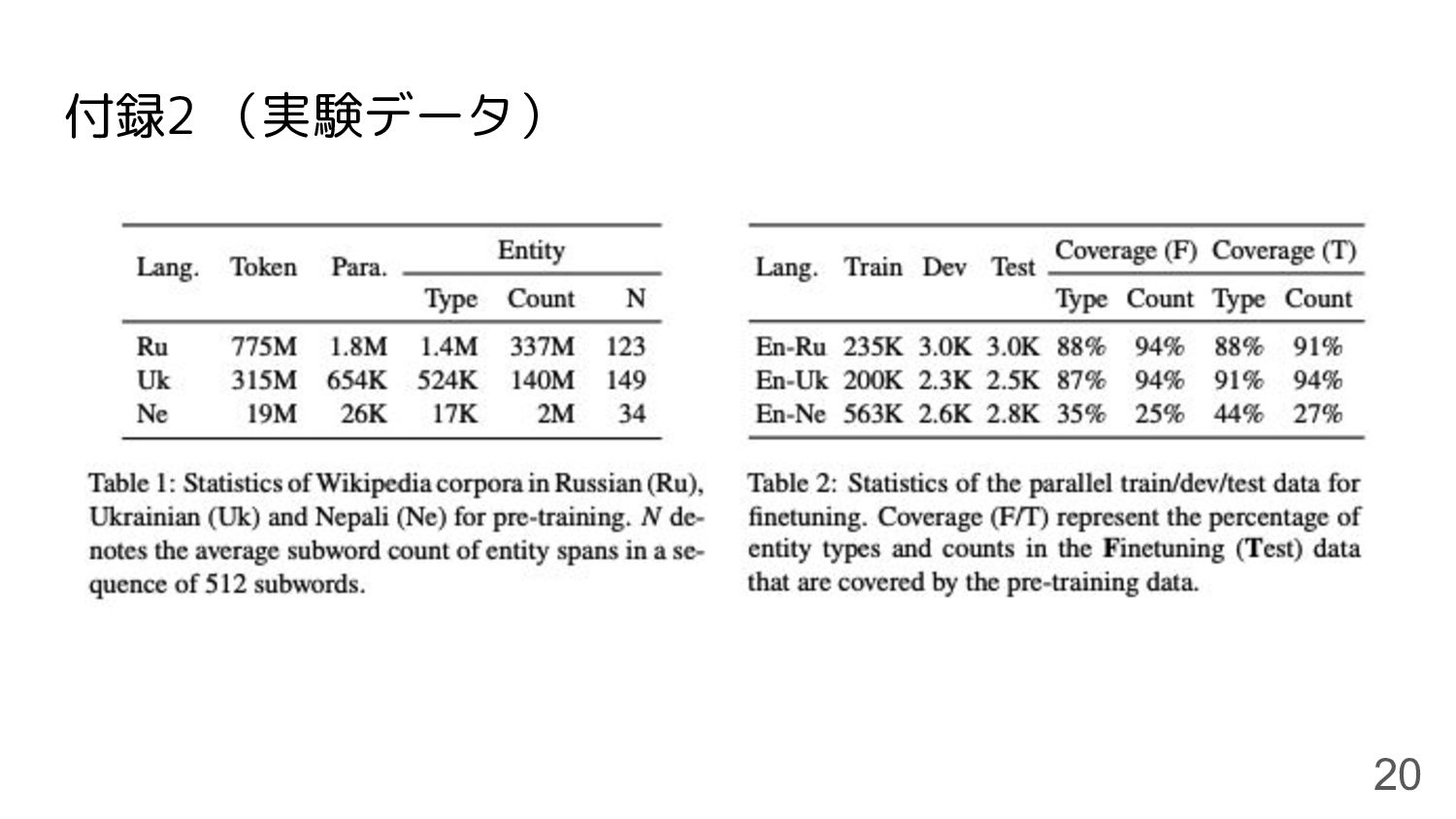
付録2 (実験データ) 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![提案手法 ③マルチタスクファインチューニング • 事前学習時の固有表現の情報を忘却しないため • 単言語コーパスは各エポック内でサンプリングして対訳コーパスとのデータ 数を揃える • 文頭の [BOS]](https://files.speakerdeck.com/presentations/09a4c110e69a4f9badd8a6e4567cacd1/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}