Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2021前期_Bilingual Dictionary Based Neural Ma...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
maskcott
July 01, 2021
Research
54
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
July 01, 2021
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
poster.NAACL-SRW_Two Sentence Concatenation Approach to Data Augmentation for Neural Machine Translation
maskcott
0
120
Other Decks in Research
See All in Research
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
0
100
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
420
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
6
3.5k
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
210
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
390
Cross-Media Information Spaces and Architectures
signer
PRO
0
300
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
160
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
590
Harness Engineering and Al Agent
kzinmr
3
1.7k
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
820
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
160
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
400
Building Applications with DynamoDB
mza
96
7.1k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Navigating Weather and Climate Data
rabernat
0
240
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Ethics towards AI in product and experience design
skipperchong
2
320
Documentation Writing (for coders)
carmenintech
77
5.4k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Writing Fast Ruby
sferik
630
63k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.4k
Transcript
発表者: 小町研 M1 今藤誠一郎 2021/07/01 @論文紹介2021 1
概要 • 機械翻訳における新しいタスクの提案 → 対訳コーパスを用いず、対訳辞書と単言語コーパスが利用可能な条件における機械翻訳 • このタスクに取り組むために anchored training (AT)
を提案 → 対訳辞書を用いてsrc言語とtgt言語の埋め込み表現の差を小さくする • 辞書ベースの単語間翻訳や辞書教師ありの言語間単語埋め込み変換、教師なし MTなどのベースライン よりも優位に優れていることを示した • 教師なしMTではうまくいかない遠い言語対でも優れた性能を発揮し、 400万以上の並列文で楽手された 教師ありSMTに匹敵する性能も示した 2
背景 • 人が辞書を引いて翻訳能力を獲得することからこのタスクを提案 • 教師なしMTは辞書を含む対訳リソースの使用不可 • 半教師あり / 教師ありMTでは並列文を用いる •
これまでのnlpにおける対訳辞書の使用用途 → 対訳辞書構築(BLI)においてシードとして( Mikolov et al., 2013) → 教師ありMTの低頻出語の翻訳( Arthur et al., 2016; Zhang and Zong, 2016) ↓ この研究は対訳辞書と大量の単言語コーパスのみを用いて、 MTが対訳文なしでどこまで能力を発揮できるの かを調べる初めての試み 3 過去のどのタスクとも異なる
提案手法 • 大規模な単言語コーパスにアンカリングポイントを置くことによって対訳辞書を MTの学習に導入 → 両言語の意味空間を近づけて翻訳を容易にする • Anchored Traning (AT)
と Bi-view AT の二つの手法を提案 4
Anchored Training (AT) ソース文: → ATのプロセスではこのアンカーを用いて埋め込み空間の一貫性を強化 学習プロセス 1. から
src-to-tgt で を生成 2. と を文対として tgt-to-src のモデルを学習 3. tgt-to-src で から を生成 4. と を文対として src-to-tgt のモデルを学習 モデルの学習はMTモデルの出力文を入力とし、元の文またはアンカーに置き換えられた 文を出力として行われる 教師なしMT(Lample et al., 2018)におけるノイズ除去も行われている (デリーションや語順の入れ替え) 5 対訳辞書に基づく置き換え アンカー デコード 学習
Anchored Training (AT) テスト時 1. 対訳辞書を調べてsrc文をアンカーを含む文に変換 2. src-to-tgt モデルを用いてアンカーを含む文をデコード 4層からなるエンコーダー、デコーダーを持つ
Transformerを採用 エンコーダーの最終 3層とデコーダーの最初の 3層を両言語で共有 → 2つの言語の共通の特性と固有の特性を一つのモデルに取り込んで学習できる ↓ この手法はターゲット言語視点で両言語の文をモデル化しようとしている 6 デコード 学習
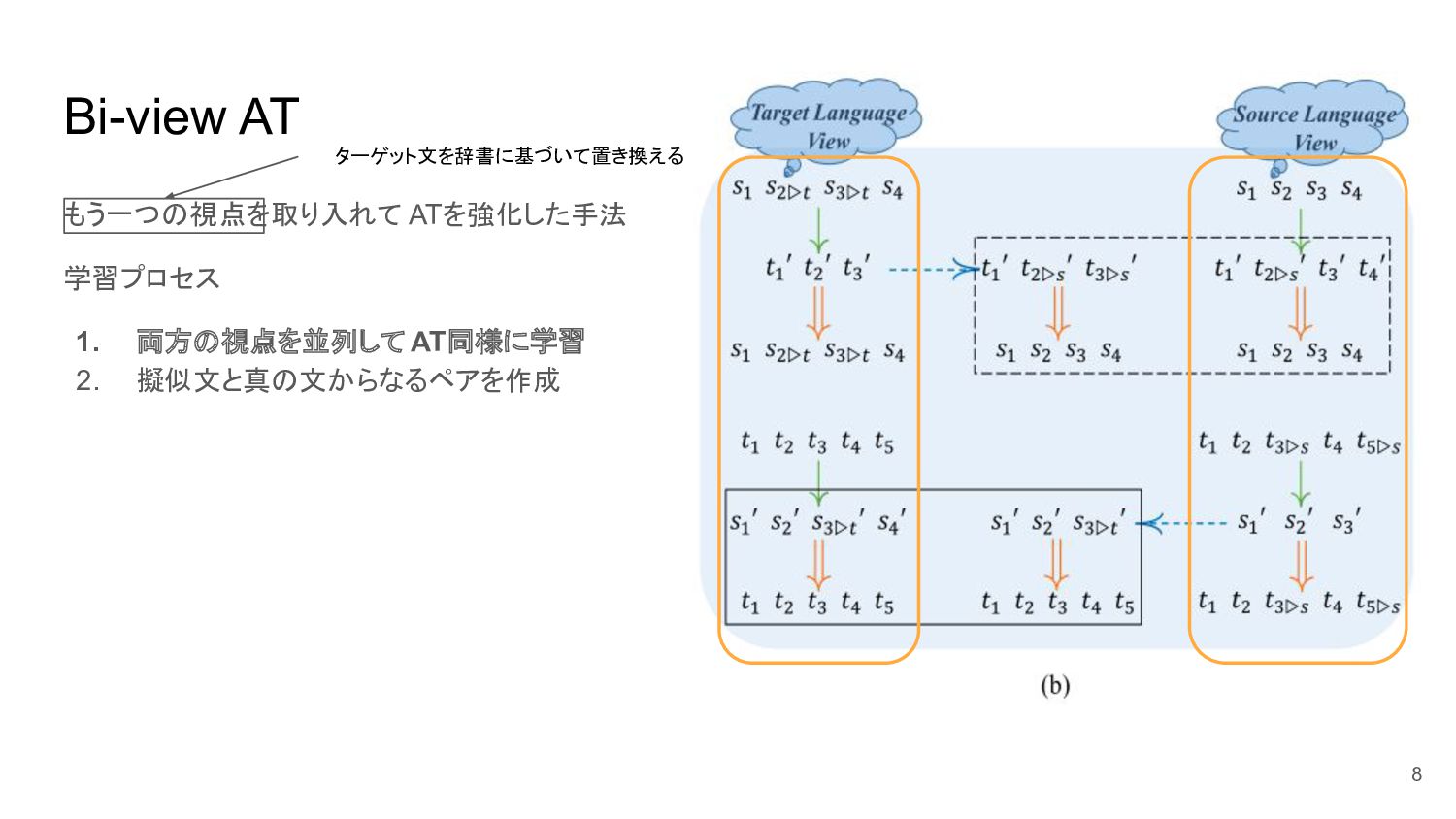
Bi-view AT もう一つの視点を取り入れて ATを強化した手法 学習プロセス 1. 両方の視点を並列して AT同様に学習 2. 擬似文と真の文からなるペアを作成
7 ターゲット文を辞書に基づいて置き換える
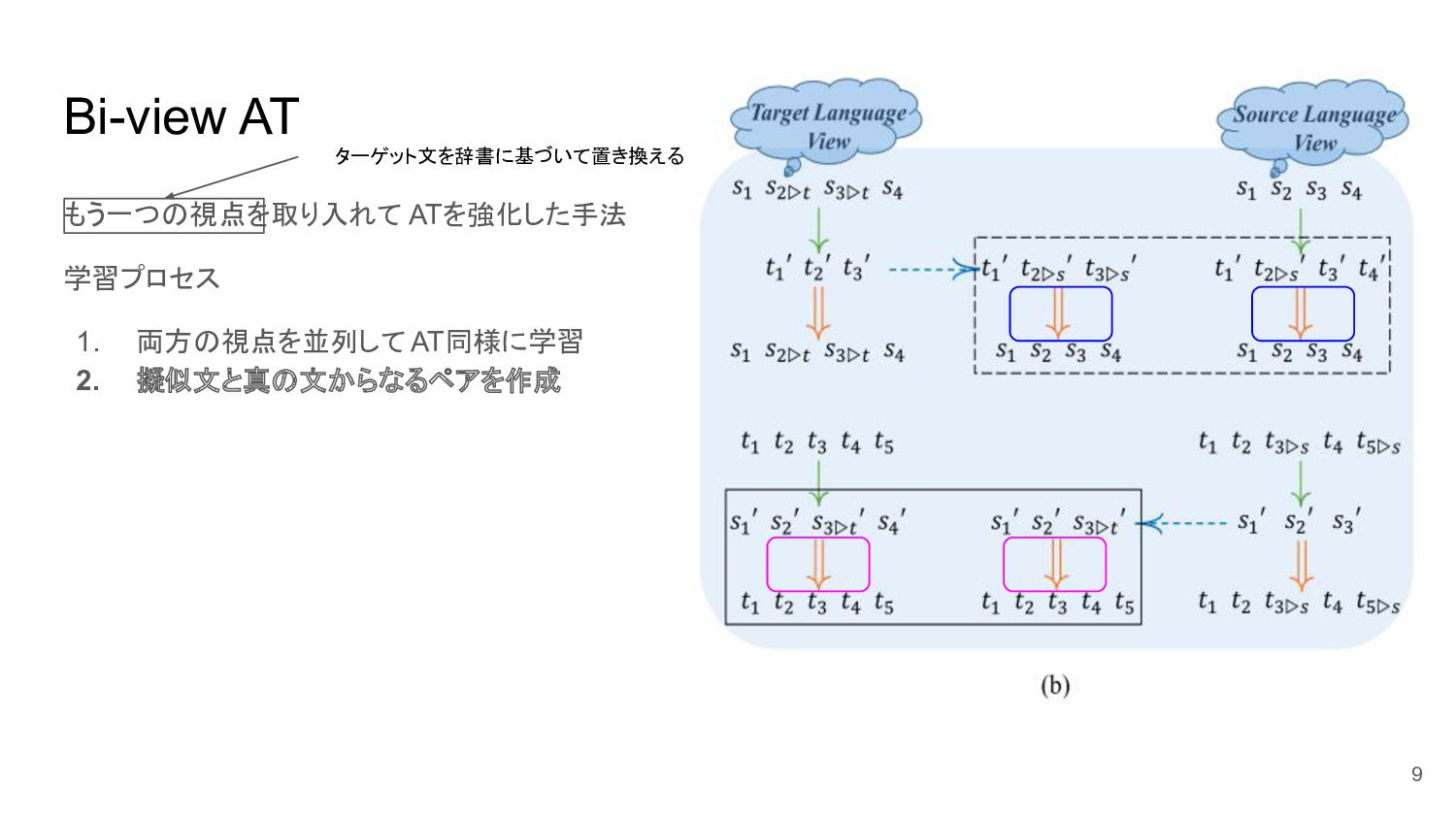
Bi-view AT もう一つの視点を取り入れて ATを強化した手法 学習プロセス 1. 両方の視点を並列して AT同様に学習 2. 擬似文と真の文からなるペアを作成
8 ターゲット文を辞書に基づいて置き換える
Bi-view AT もう一つの視点を取り入れて ATを強化した手法 学習プロセス 1. 両方の視点を並列して AT同様に学習 2. 擬似文と真の文からなるペアを作成
9 ターゲット文を辞書に基づいて置き換える
Anchored Cross-lingual Pretraining (ACP) • 教師なしMTで効果を出している Cross-lingual Pretraining を応用 →
単言語コーパスの単語をランダムにマスクして穴埋めタスクを行う • ACPではアンカーを使った文から元の文に変換するようなタスクを行う → 先の方法よりもsrc言語空間とtgt言語空間のギャップを小さくすることができる(後述) • 対応するATのエンコーダーをACPで事前学習したもので初期化する。 • (Lample and Conneau, 2019) のXLMに従って行い、アンカーされた文ともう一方の言語の元の文を連 結したもので事前学習する。 (具体的な二文の選び方は明示されていないがおそらくランダム) (Lample and Conneau, 2019) の4.5、Lample et al. (2018a) 4.2から 10
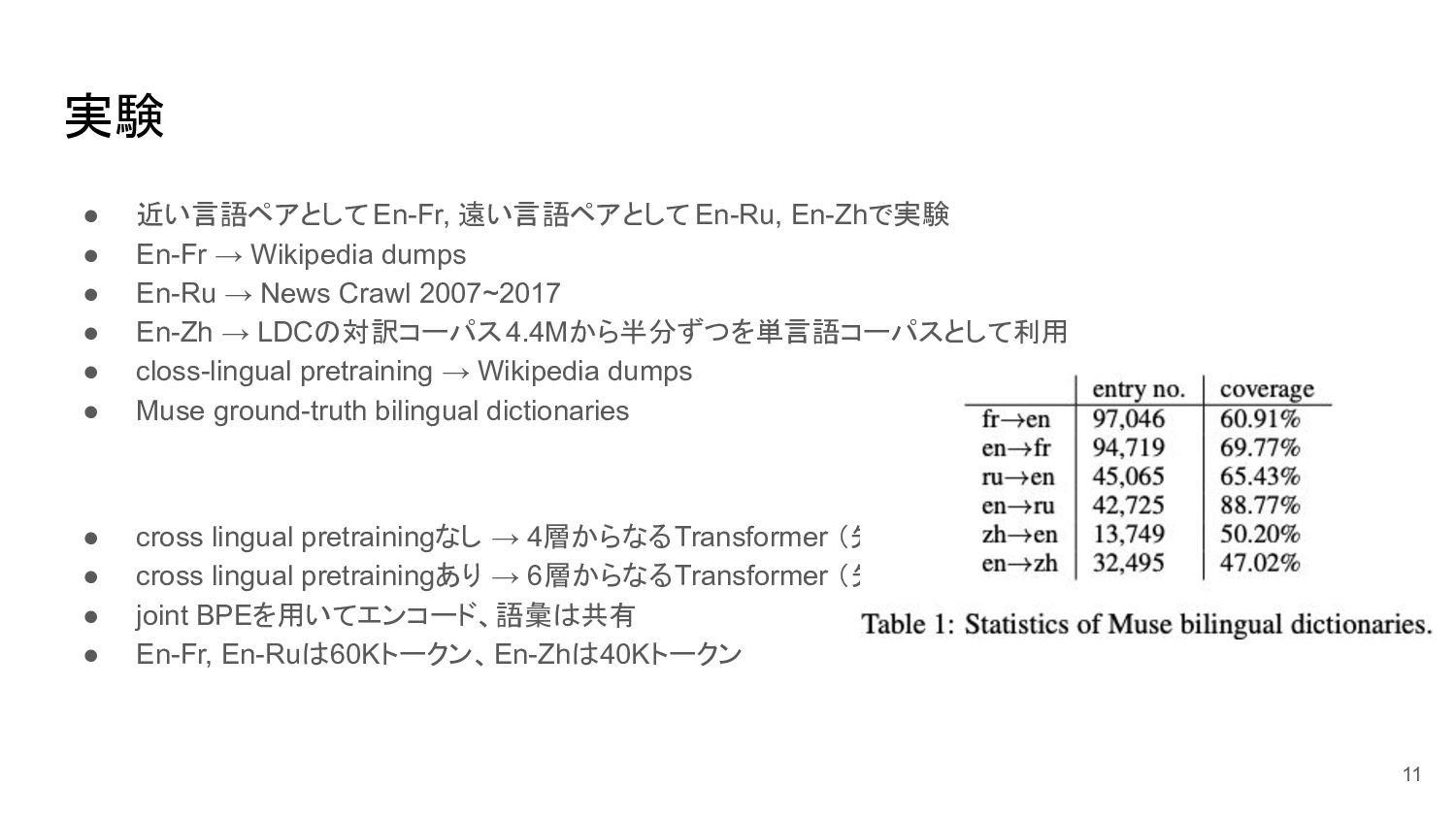
実験 • 近い言語ペアとしてEn-Fr, 遠い言語ペアとしてEn-Ru, En-Zhで実験 • En-Fr → Wikipedia dumps
• En-Ru → News Crawl 2007~2017 • En-Zh → LDCの対訳コーパス4.4Mから半分ずつを単言語コーパスとして利用 • closs-lingual pretraining → Wikipedia dumps • Muse ground-truth bilingual dictionaries • cross lingual pretrainingなし → 4層からなるTransformer (先行研究のUNMT) • cross lingual pretrainingあり → 6層からなるTransformer (先行研究のXLM) • joint BPEを用いてエンコード、語彙は共有 • En-Fr, En-Ruは60Kトークン、En-Zhは40Kトークン 11
ベースライン • Word-by-word translation • Unsupervised translation(UNMT) • UNMT initialized
by Unsupervised Word Embedding Transformation (UNMT+UWET) → 対訳辞書なし • UNMT system initialized by Supervised Word Embedding Transformation (UNMT+SWET) → 対訳辞書で src word を tgt word に変換することで初期化 12
結果 13
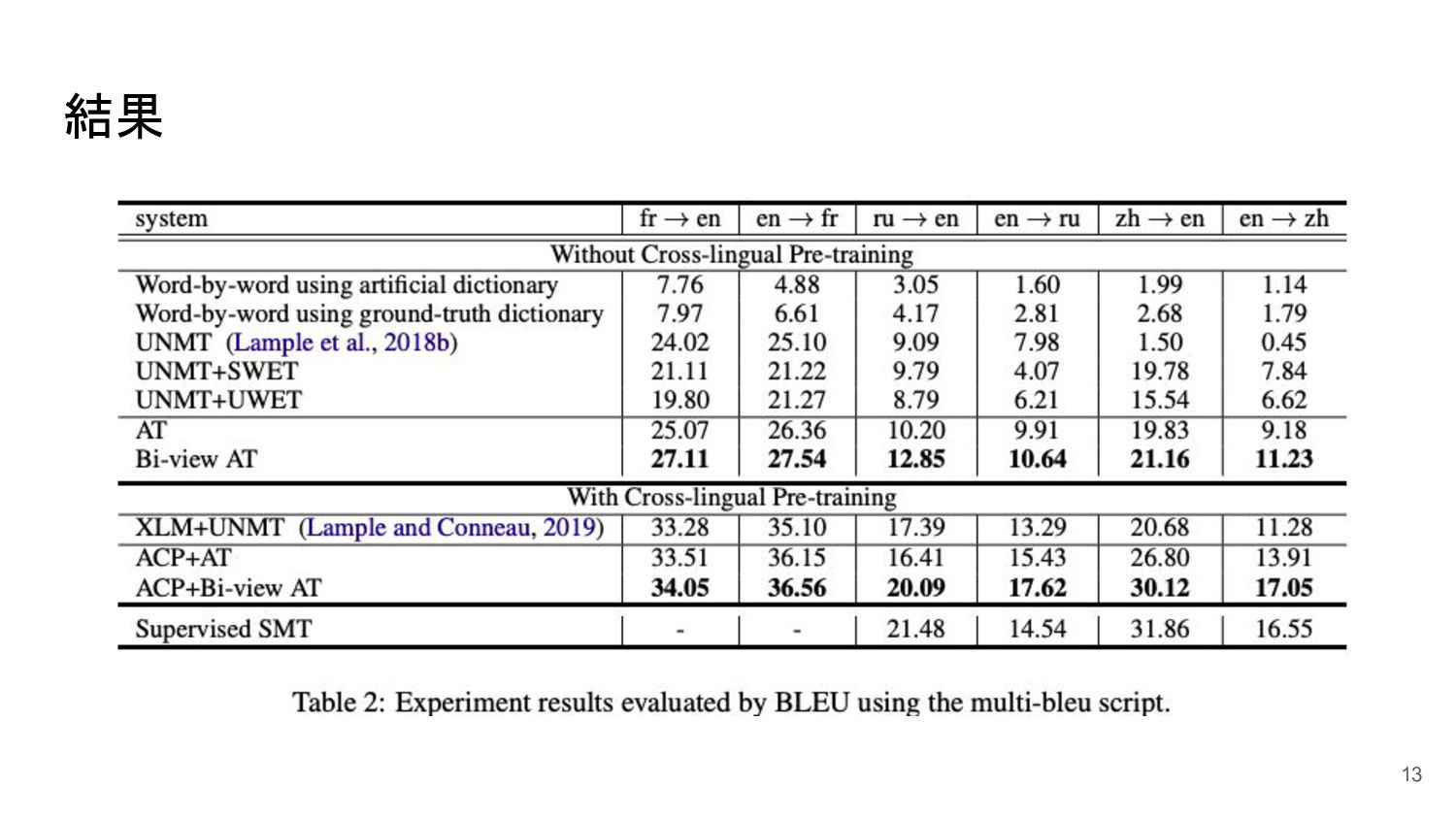
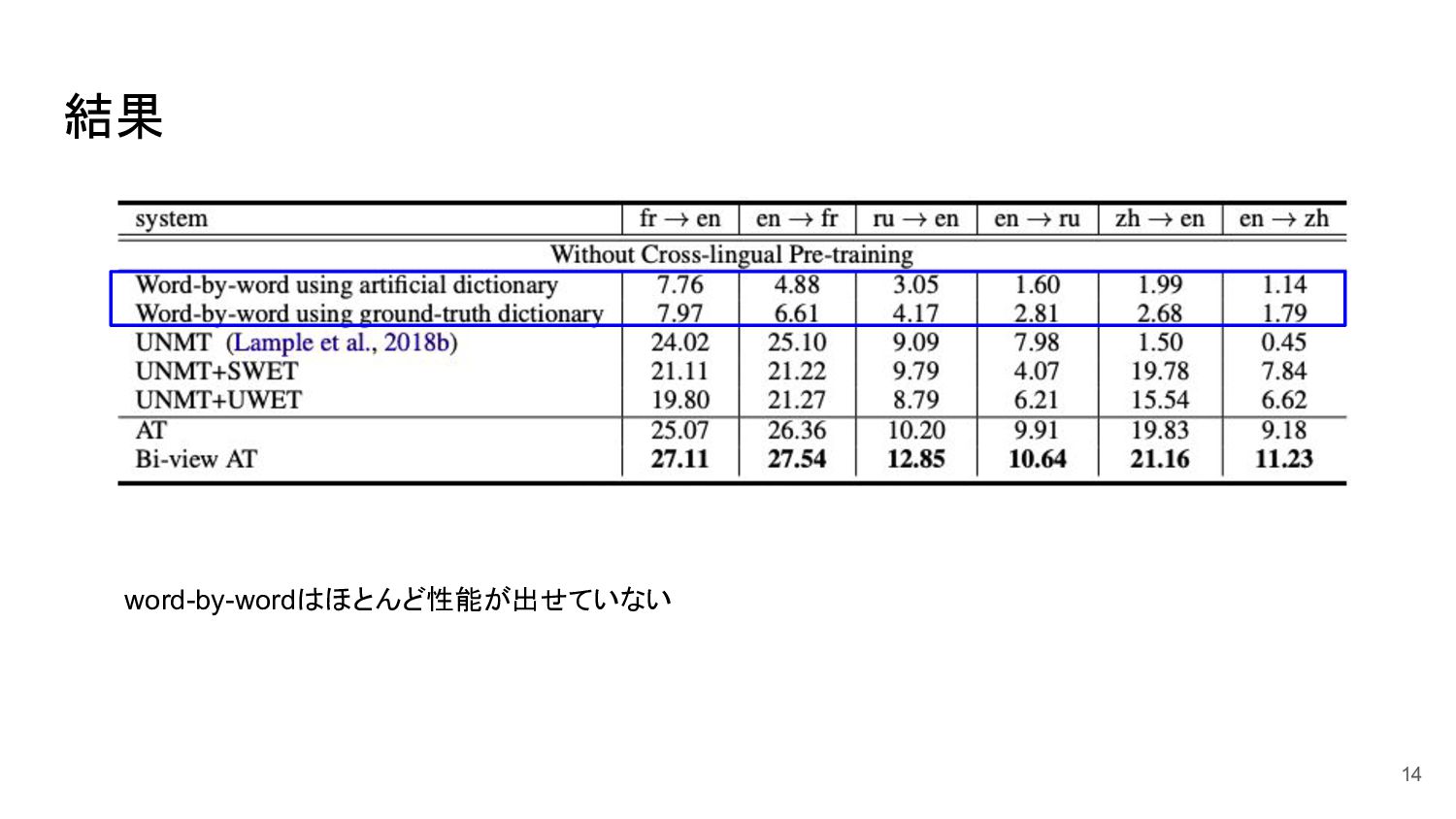
結果 14 word-by-wordはほとんど性能が出せていない
結果 15 言語距離が遠い時には WETの効果が見られる
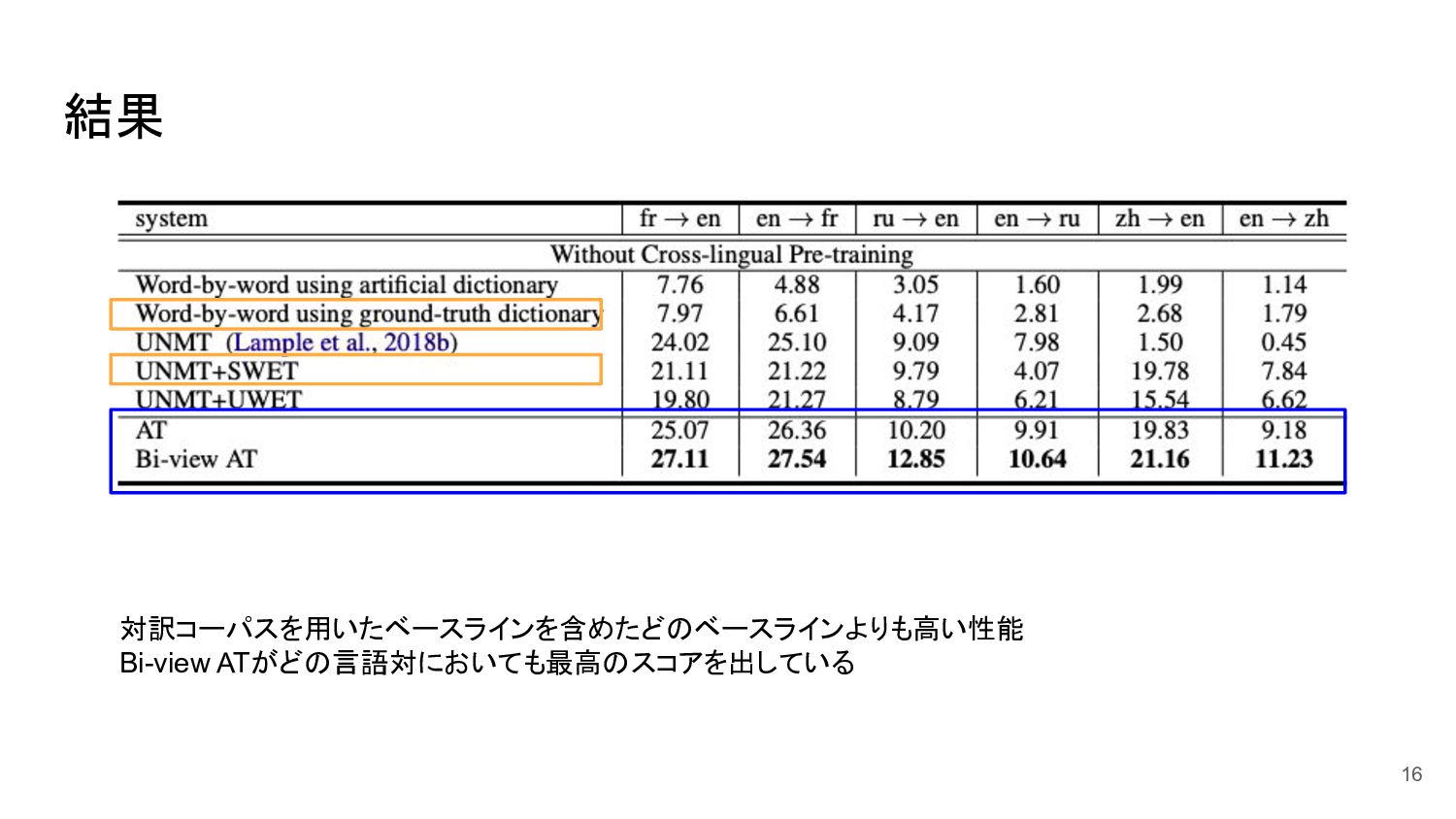
結果 16 対訳コーパスを用いたベースラインを含めたどのベースラインよりも高い性能 Bi-view ATがどの言語対においても最高のスコアを出している
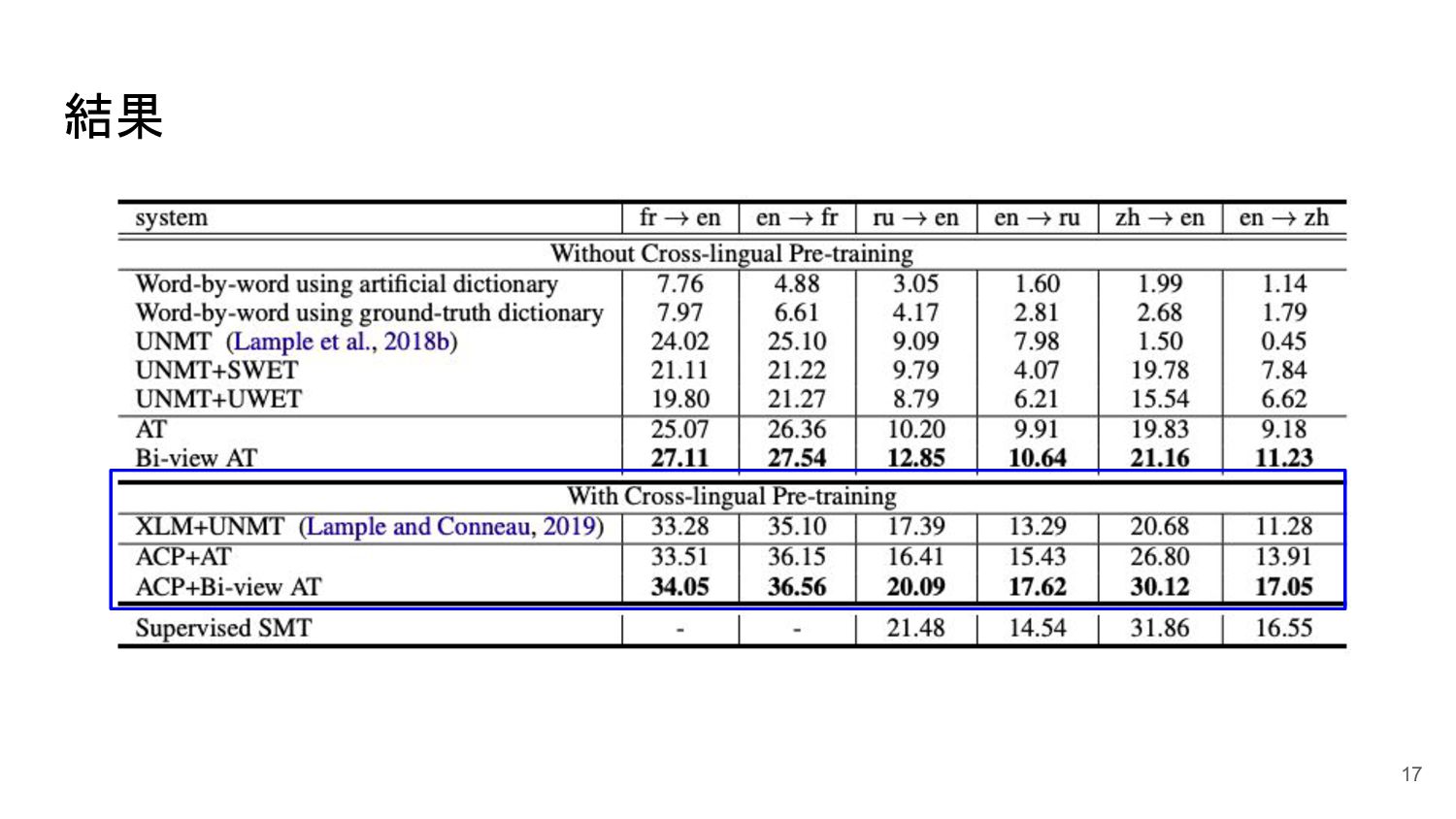
結果 17
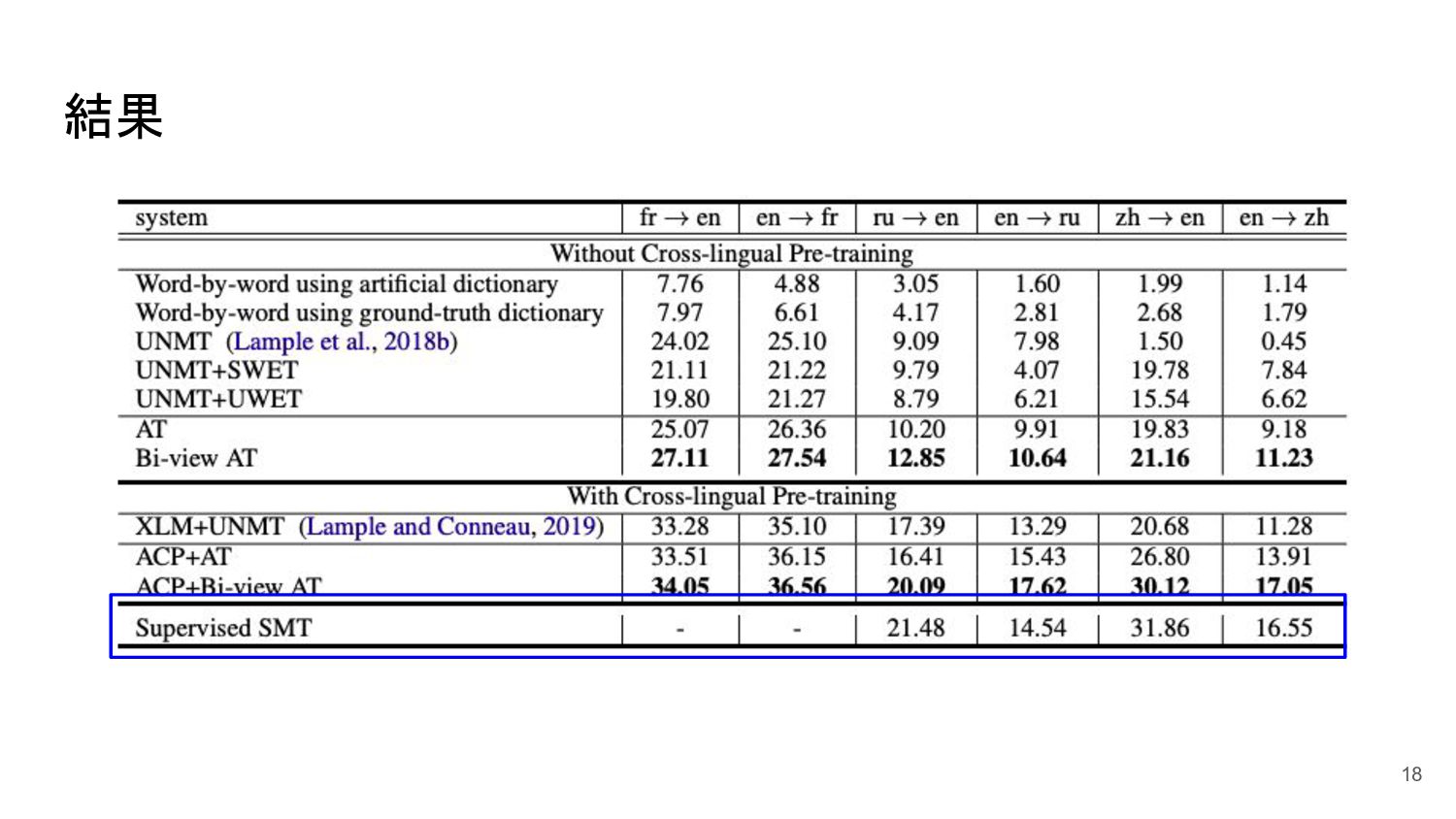
結果 18
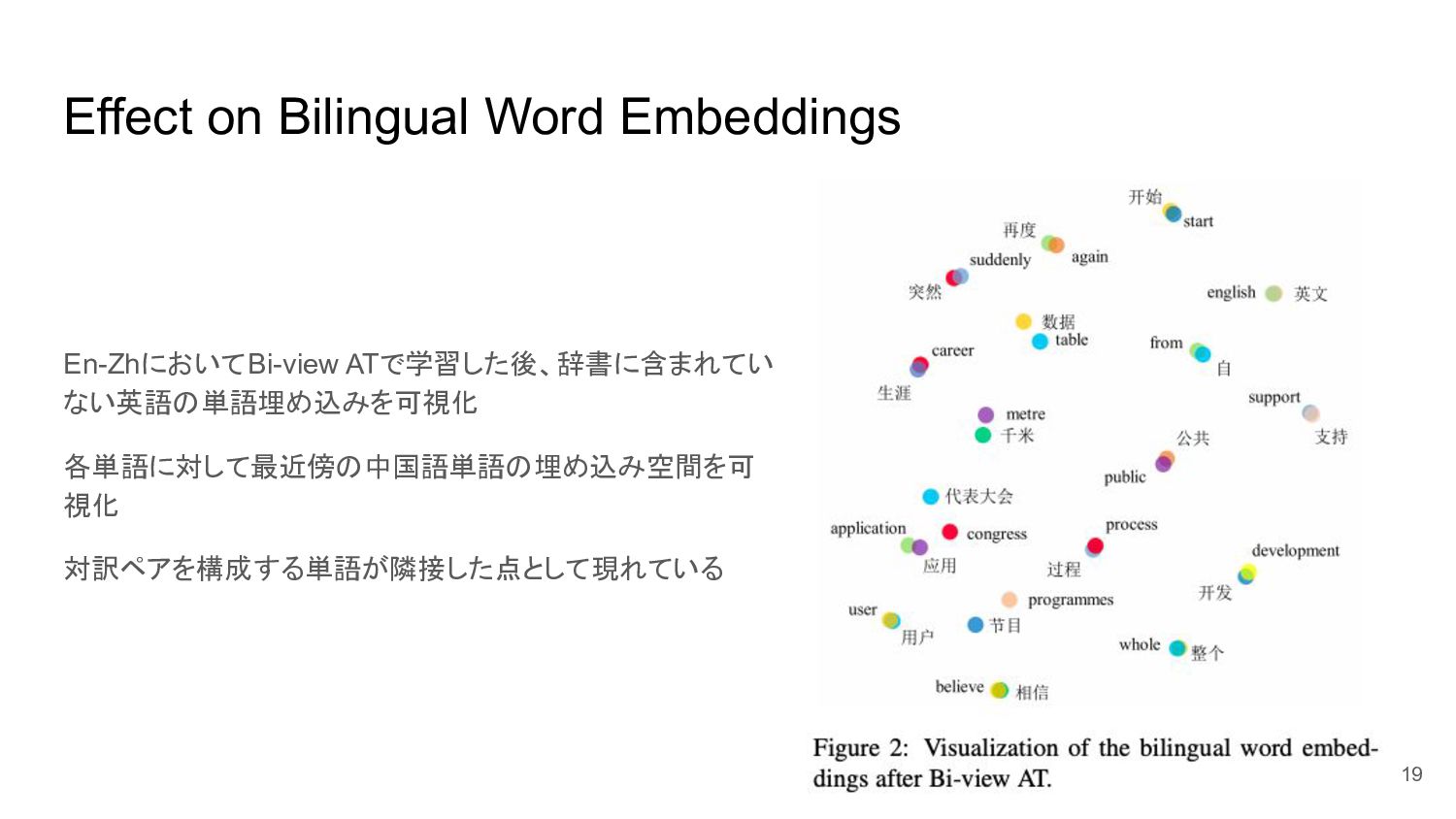
Effect on Bilingual Word Embeddings En-ZhにおいてBi-view ATで学習した後、辞書に含まれてい ない英語の単語埋め込みを可視化 各単語に対して最近傍の中国語単語の埋め込み空間を可 視化
対訳ペアを構成する単語が隣接した点として現れている 19
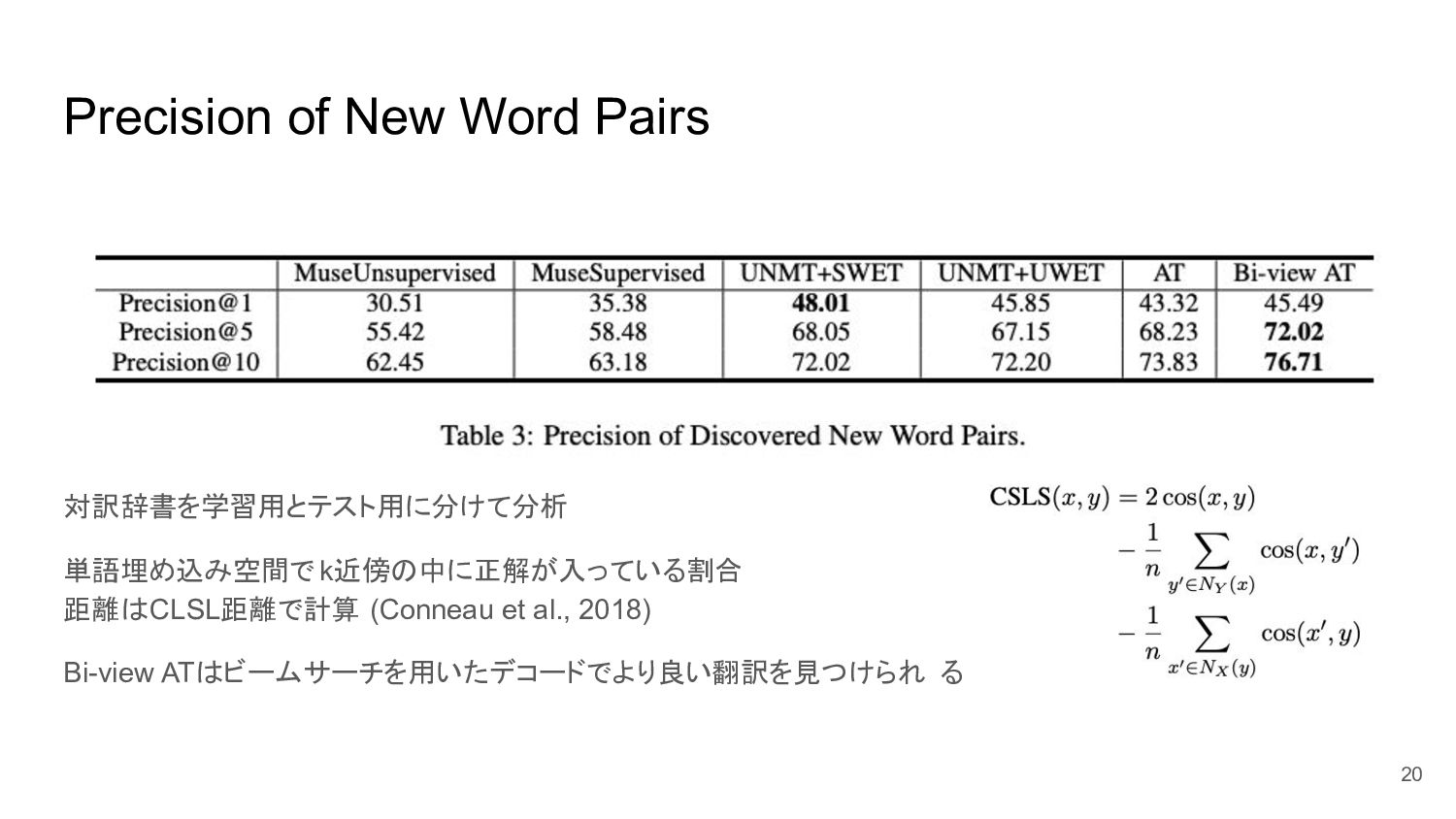
Precision of New Word Pairs 対訳辞書を学習用とテスト用に分けて分析 単語埋め込み空間で k近傍の中に正解が入っている割合 距離はCLSL距離で計算 (Conneau
et al., 2018) Bi-view ATはビームサーチを用いたデコードでより良い翻訳を見つけられ る 20
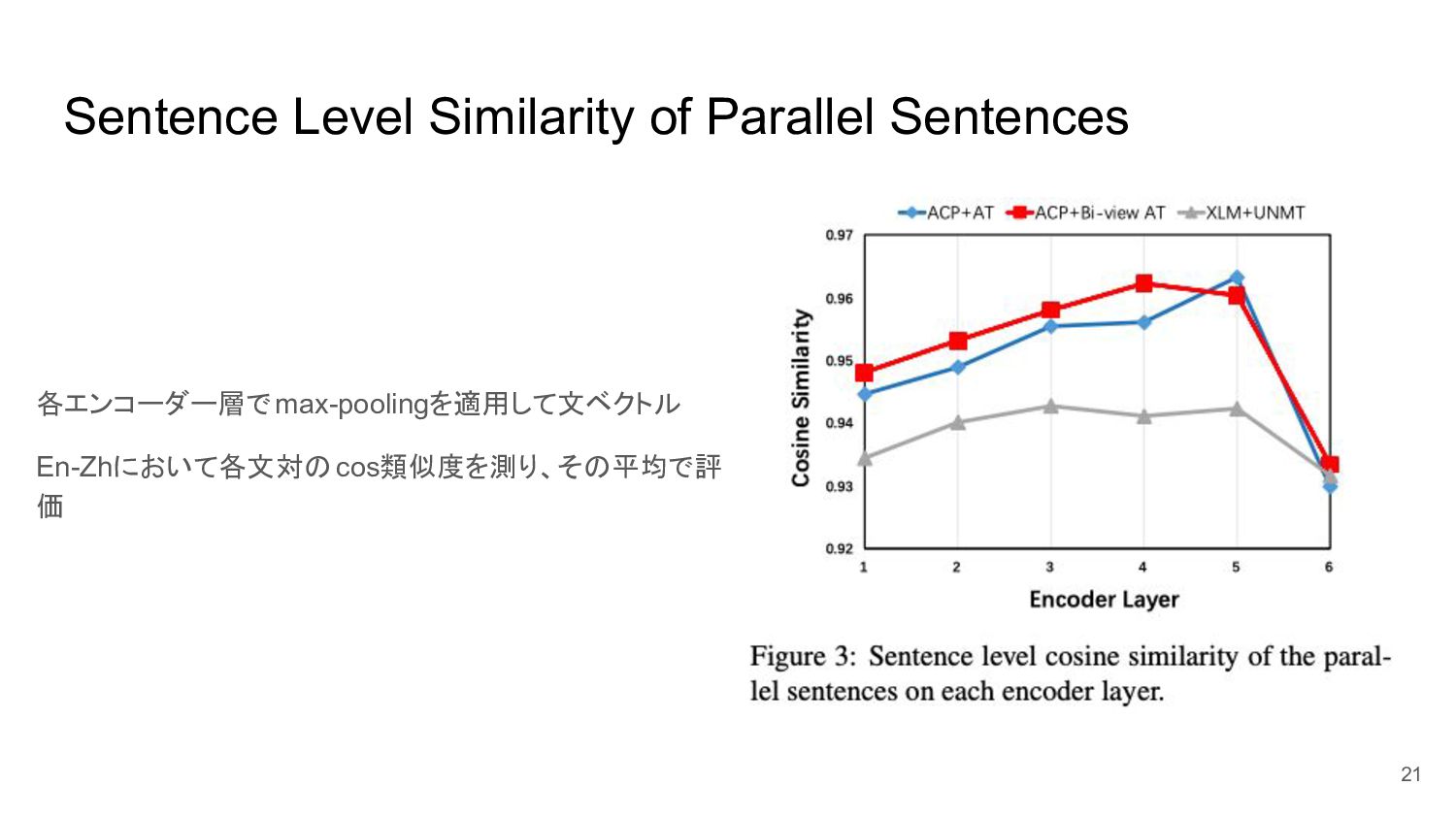
Sentence Level Similarity of Parallel Sentences 各エンコーダー層で max-poolingを適用して文ベクトル En-Zhにおいて各文対のcos類似度を測り、その平均で評 価
21
Ground-Truth Dictionary Vs Artificial Dictionary 22 The Effect of The
Dictionary Size
まとめ • 対訳辞書と大規模な単言語コーパス飲みを用いた場合に MTがどの程度の能力を発揮できるのか探った • この実験設定において、対訳辞書をアンカー付きの学習によって MTに導入することを提案 • 近い言語ペア、遠い言語ペアの両方で提案手法が両言語空間の差を効果的に小さくした •
辞書を用いないMT手法や、辞書でクロスリンガルな単語埋め込み変換を用いる手法に比べて翻訳精度 を大幅に向上させることを確認した 23
貢献 • 対訳文を用いないで対訳辞書と単言語コーパスのみを用いるという新しい MTタスクの提案 • このタスクにATを使って取り組んだ 対訳辞書を用いてsrcとtgtの言語空間を近づけることで翻訳を容易にできるようにした • 24
関連研究 • これまでの対訳辞書の主な使用用途 → 対訳辞書構築(BLI)... 単言語コーパスを用いて各言語の埋め込み表現を学習して、辞書に含まれる すべて単語ペアのユークリッド距離を最小化することで埋め込み空間から別の空間への変換を学習 • 教師なしNMTは対訳コーパスを用いないという点で同じ 教師なしBLIで生成される擬似対訳コーパスを用いて初期化するか、
joint BPEを用いる • 本研究は正確な対訳辞書を用いて新学習プロセスを適用 → 遠い言語ペアにおいて翻訳精度が著しく落ちるという UNMTの問題を低減(対訳辞書の必要性) • 対訳辞書はMT以外だと多言語構文解析や教師なし多言語会話タギングなどで利用 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}