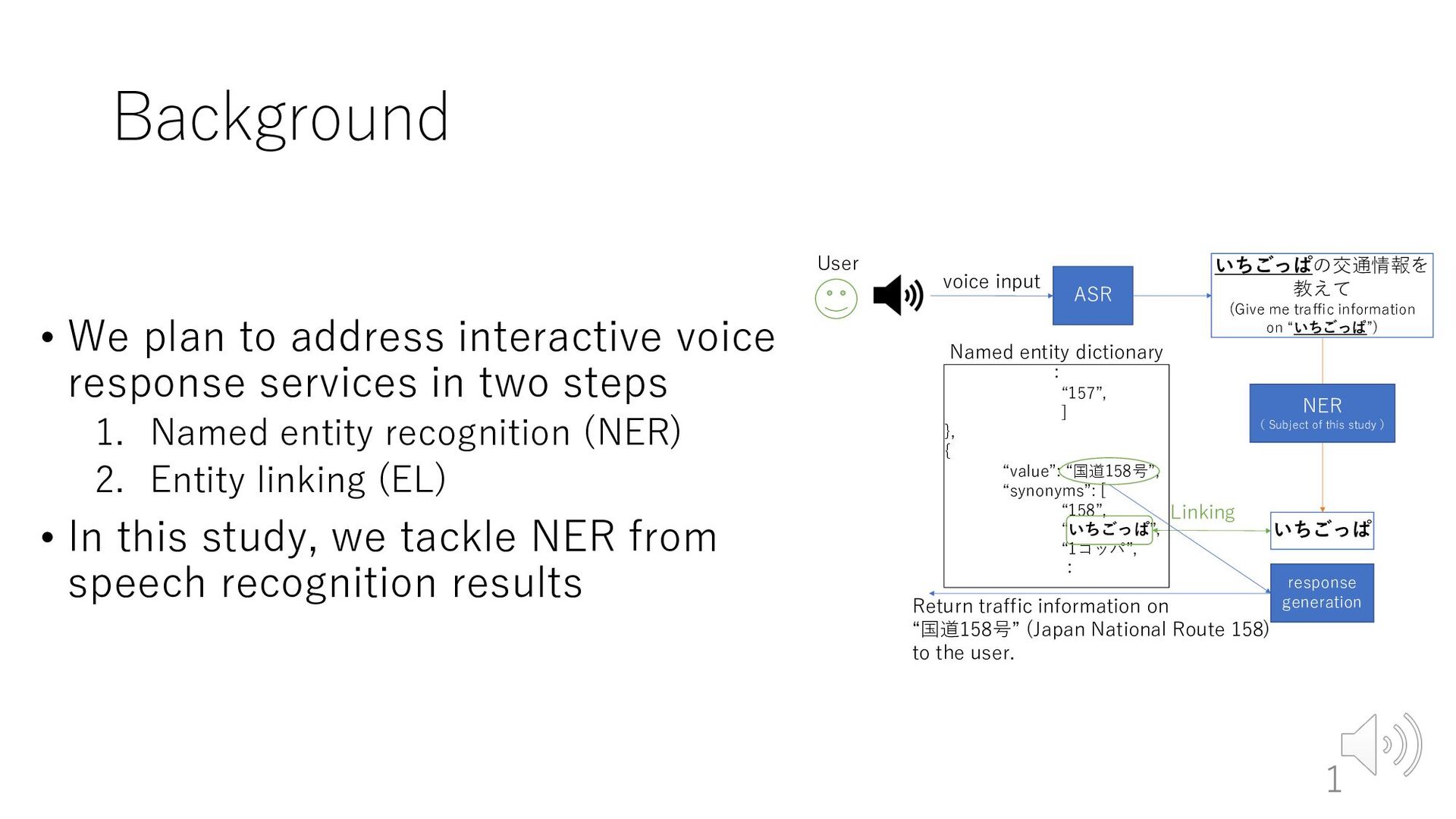
in two steps 1. Named entity recognition (NER) 2. Entity linking (EL) • In this study, we tackle NER from speech recognition results ASR User いちごっぱの交通情報を 教えて (Give me traffic information on “いちごっぱ”) voice input いちごっぱ Linking : “157”, ] }, { “value”: “国道158号”, “synonyms”: [ “158”, “いちごっぱ”, “1コッパ”, : Named entity dictionary response generation Return traffic information on “国道158号” (Japan National Route 158) to the user. NER ( Subject of this study ) 1
errors ØUnknown named entities from abbreviations and aliases ØThe surface forms and meanings can be entirely different in spite of close sounds → NER using conventional methods is difficult 2 国道158号(route 158) (Kokudou-hyaku-goju-hachi-go ) 158 (Hyaku-goju-hachi / ichi-go-hachi ) いちごっぱ (ichi-go-ppa ) 1コッパ(ichikoppa ) イチゴったー(ichigotta ) 15PA(ichigopa ) abbreviation aliase ASR error
additional information not contained in the text ØOmachi et al. (2021) postulated that an end-to-end (E2E) approach might be preferable • Processing ASR texts ØNo information other than text is used ØWe used existing ASR to enable flexible exchange of modules and resources 3
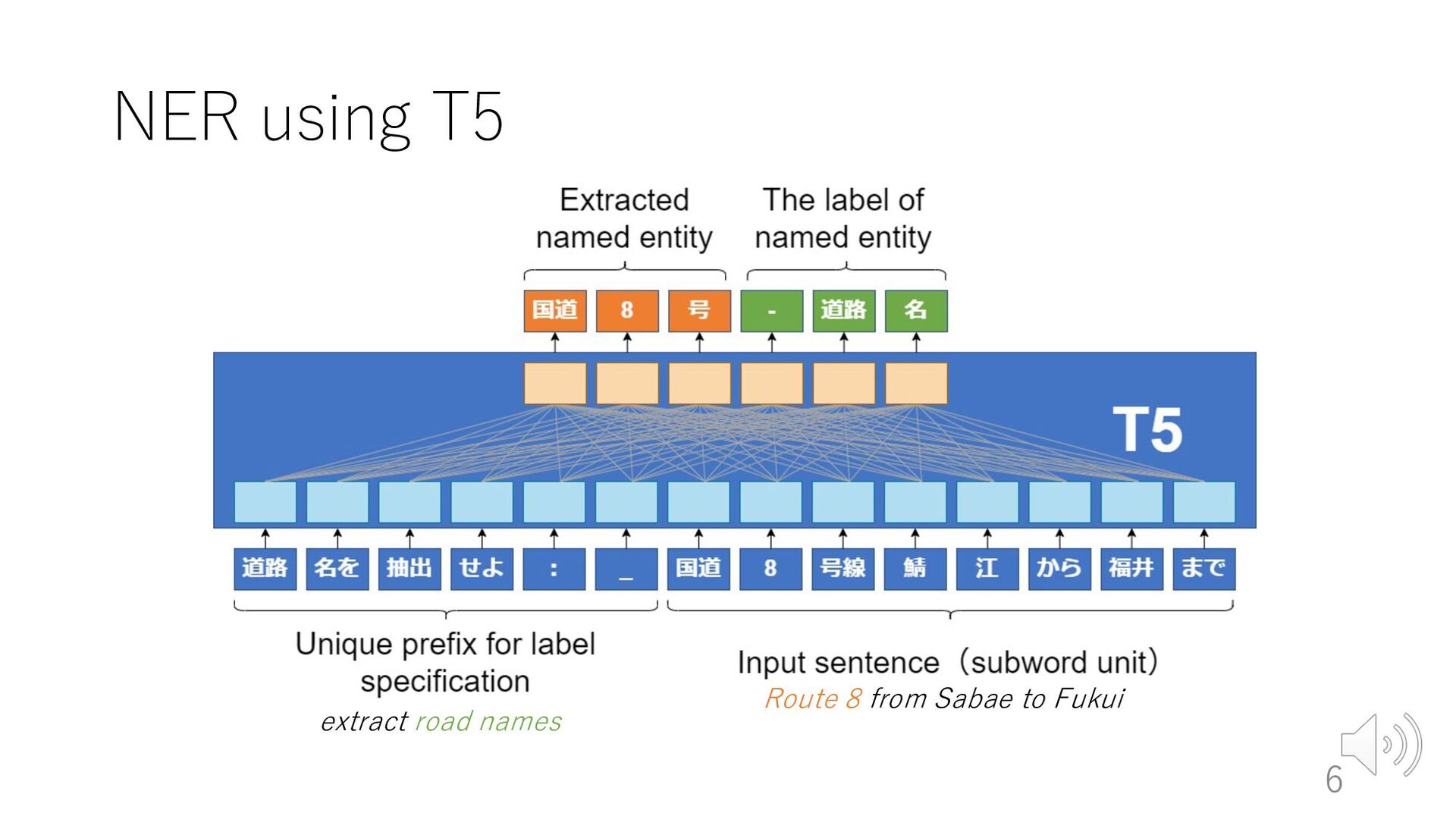
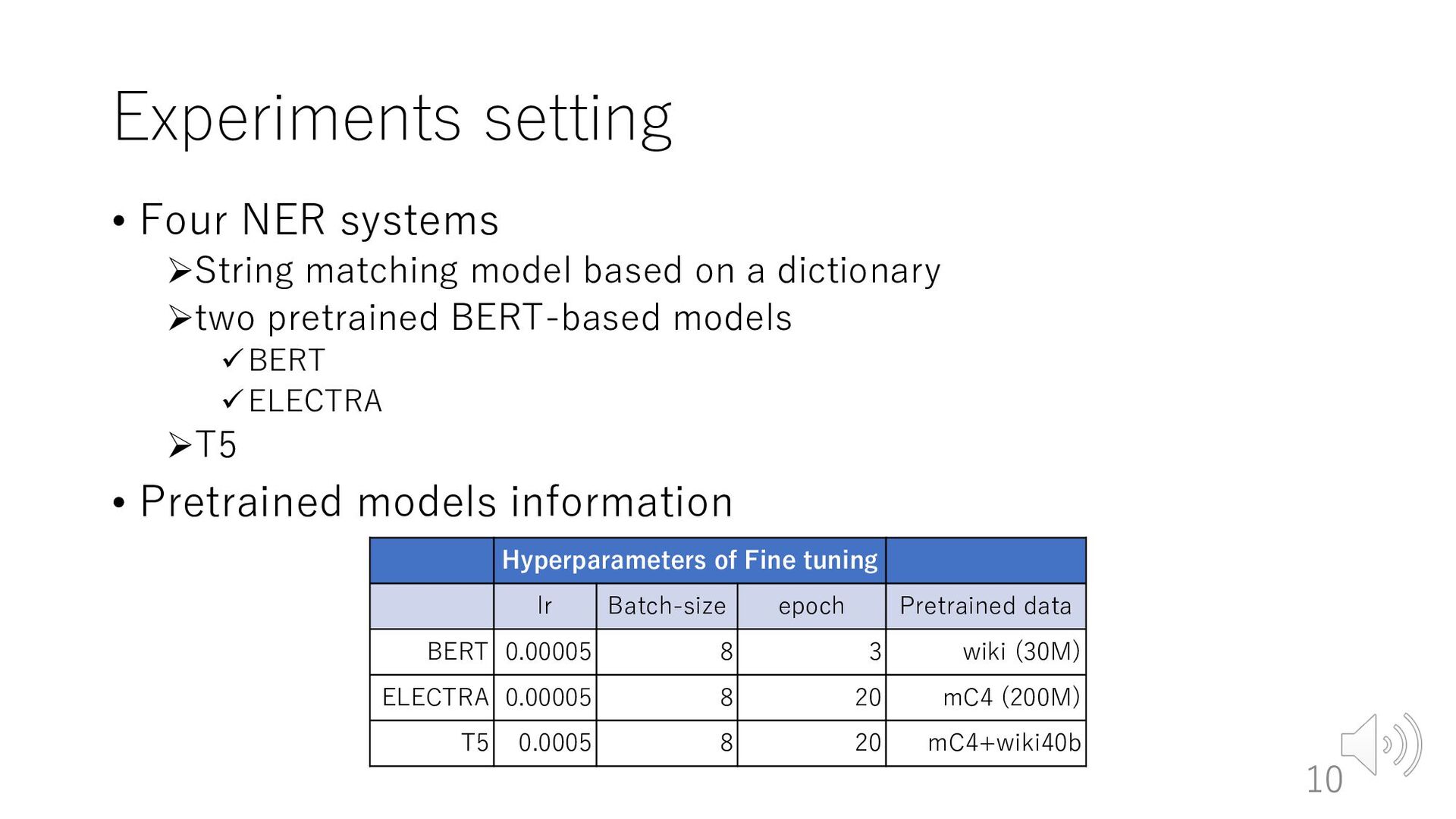
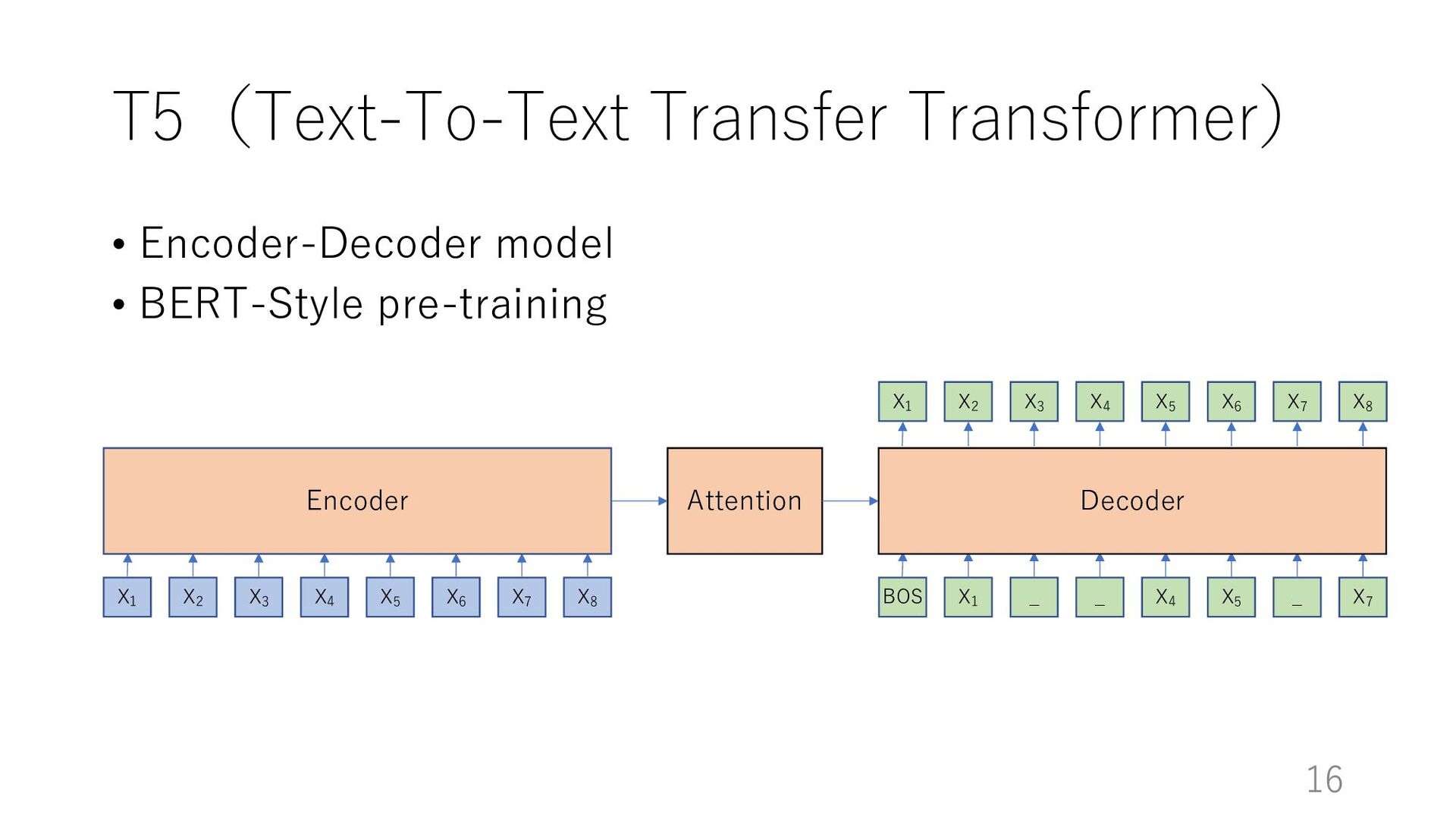
used effectively for ASR error ØAssuming that contextual information can be used effectively by pre-trained models trained on a large number of sentences • Models used in our experiments ØBERT based model (Devlin et al., 2019) üEncoder model ØT5 (Raffel et al., 2020) üEncoder-decoder model 4
鯖 ##江 I-route O I-route B-label B-route O O BERT The token for label specification Input sentence(subword unit) Route 8 from Sabae to Fukui The label of named entity から O まで O 福井 O 5
road traffic information in Fukui, Japan ØData were obtained over a certain period, not arbitrarily sampled • Prepared dictionary ØTwo dictionaries ØAddress in Fukui ØRoute in Fukui ØCertain aliases, abbreviations, and speech recognition errors were registered 7
City) Fallback えーとサザエさん、サザエ市春江町 (Well, Sazae-san, Sazae City, Harue-cho) Example • “Sazae (turban shell)” is a recognition error of “Sabae” • “Harue-cho” was not entered in the dictionary 8 • Two types of data ØMatch üNER succeeded by existing system üLabeled by dictionary matching ØFallback üNER failed by existing system üManually annotated considering ASR errors based on whether the named entities exist in Fukui
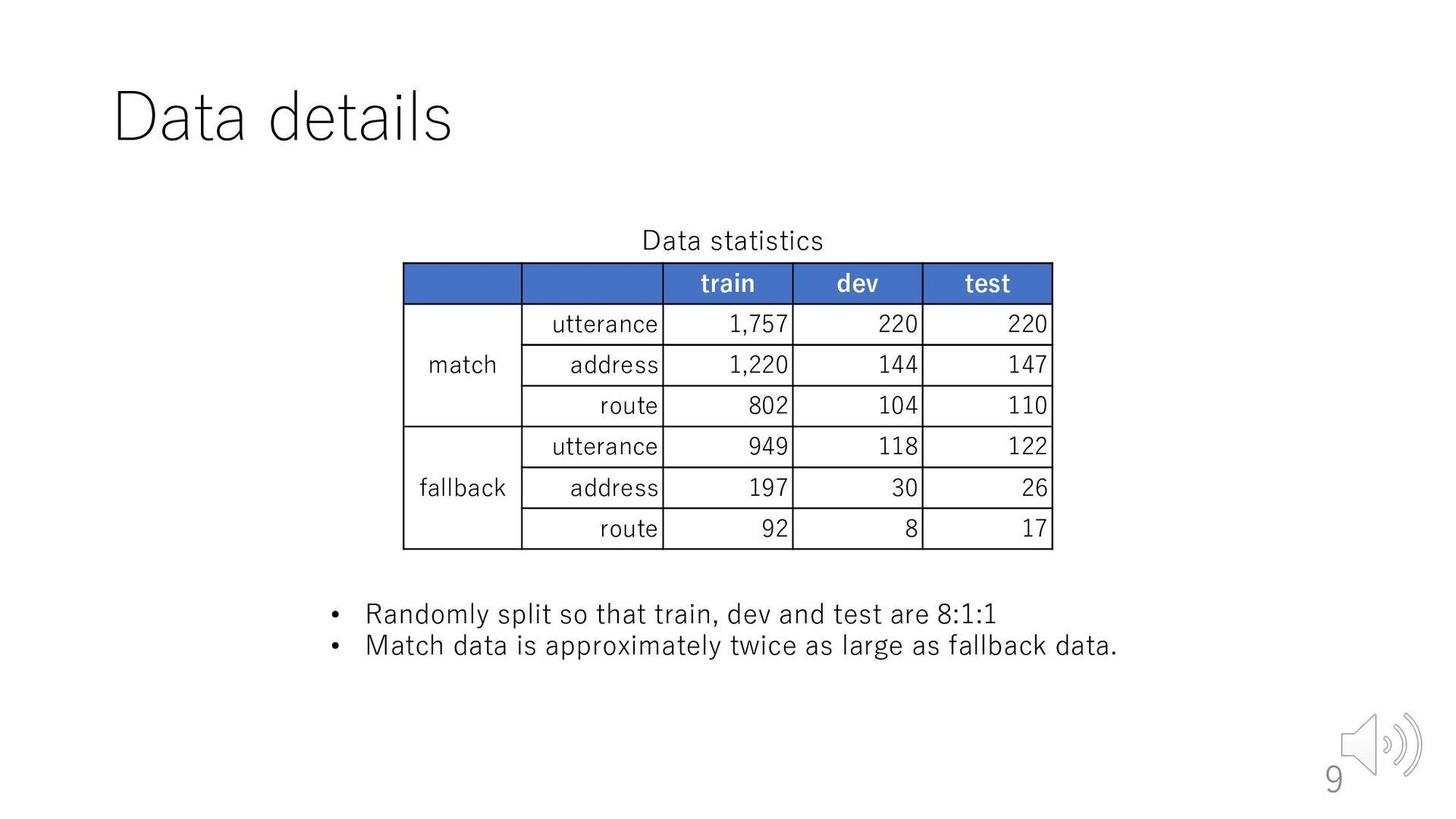
address 1,220 144 147 route 802 104 110 fallback utterance 949 118 122 address 197 30 26 route 92 8 17 Data statistics 9 • Randomly split so that train, dev and test are 8:1:1 • Match data is approximately twice as large as fallback data.
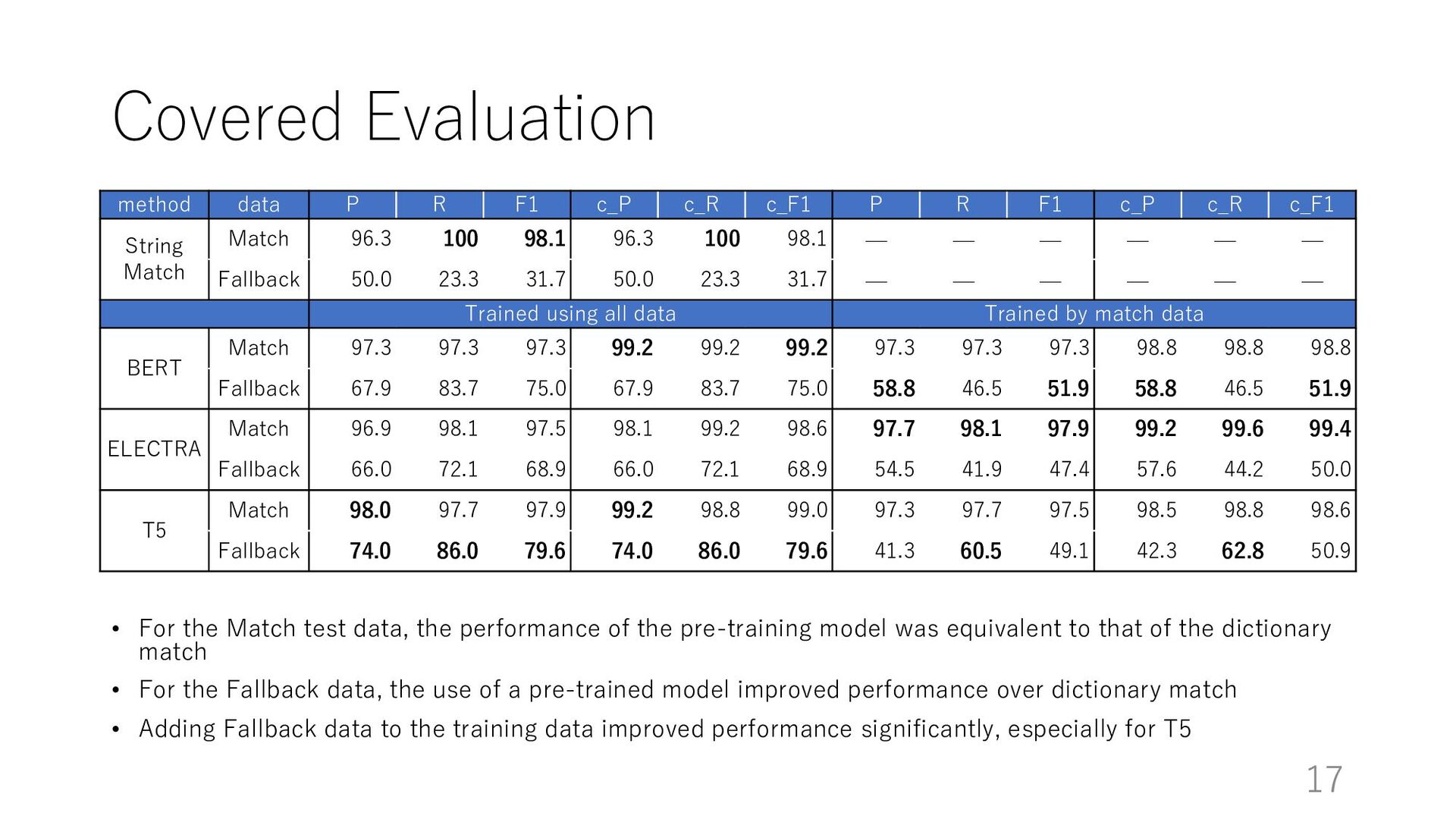
the pre-training model was equivalent to that of the dictionary match • For the Fallback data, the use of a pre-trained model improved performance over dictionary match • Adding Fallback data to the training data improved performance significantly, especially for T5 • Comparison with human recognition suggests still room for improvement based on the performance of the pre-trained models method P R F1 P R F1 String Match 96.3 100 98.1 — — — Trained using all data Trained by match data BERT 97.3 97.3 97.3 97.3 97.3 97.3 ELECTRA 96.9 98.1 97.5 97.7 98.1 97.9 T5 98.0 97.7 97.9 97.3 97.7 97.5 P: precision R: recall method P R F1 P R F1 human 80.0 97.6 87.9 — — — String Match 50.0 23.3 31.7 — — — Trained using all data Trained by match data BERT 67.9 83.7 75.0 58.8 46.5 51.9 ELECTRA 66.0 72.1 68.9 54.5 41.9 47.4 T5 74.0 86.0 79.6 41.3 60.5 49.1 11 Match data Fallback data
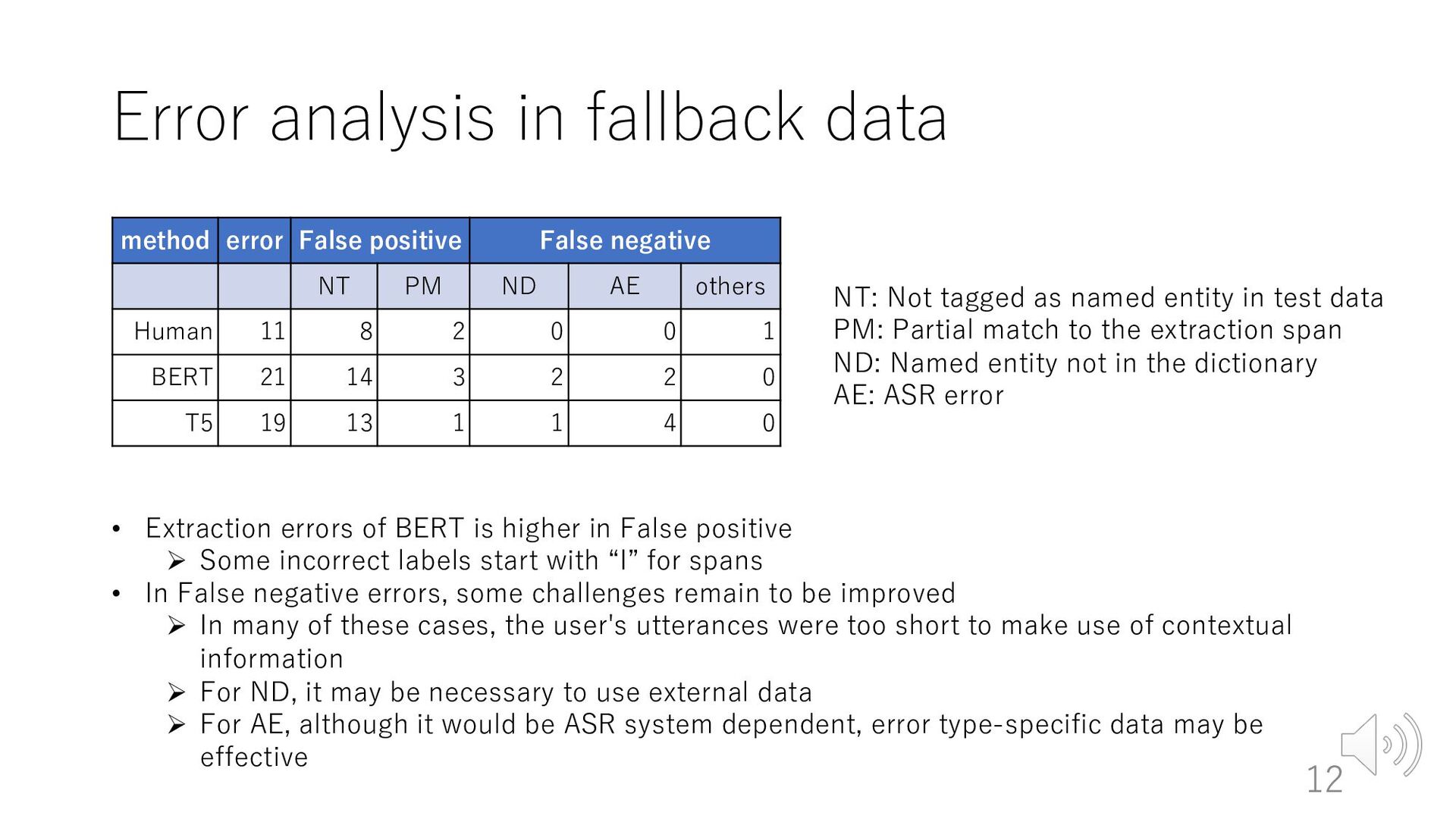
negative NT PM ND AE others Human 11 8 2 0 0 1 BERT 21 14 3 2 2 0 T5 19 13 1 1 4 0 NT: Not tagged as named entity in test data PM: Partial match to the extraction span ND: Named entity not in the dictionary AE: ASR error • Extraction errors of BERT is higher in False positive Ø Some incorrect labels start with “I” for spans • In False negative errors, some challenges remain to be improved Ø In many of these cases, the user's utterances were too short to make use of contextual information Ø For ND, it may be necessary to use external data Ø For AE, although it would be ASR system dependent, error type-specific data may be effective 12
BERT (route) ⻘年の道 Youth Road BERT (address) T5 (address) あの⾼みの⽅のエルパ⾏きのバスは取った後 あの⾼みの⽅のエルパ⾏きのバスは取った後 After taking the bus to Elpa at that height Bold and underlined texts denote the reference and hypothesis. 道: road ⾼みの(⽅の): height ⽅: direction * 13
of the pre-training model was equivalent to that of the dictionary match • For the Fallback data, the use of a pre-trained model improved performance over dictionary match • Adding Fallback data to the training data improved performance significantly, especially for T5 method data P R F1 c_P c_R c_F1 P R F1 c_P c_R c_F1 String Match Match 96.3 100 98.1 96.3 100 98.1 — — — — — — Fallback 50.0 23.3 31.7 50.0 23.3 31.7 — — — — — — Trained using all data Trained by match data BERT Match 97.3 97.3 97.3 99.2 99.2 99.2 97.3 97.3 97.3 98.8 98.8 98.8 Fallback 67.9 83.7 75.0 67.9 83.7 75.0 58.8 46.5 51.9 58.8 46.5 51.9 ELECTRA Match 96.9 98.1 97.5 98.1 99.2 98.6 97.7 98.1 97.9 99.2 99.6 99.4 Fallback 66.0 72.1 68.9 66.0 72.1 68.9 54.5 41.9 47.4 57.6 44.2 50.0 T5 Match 98.0 97.7 97.9 99.2 98.8 99.0 97.3 97.7 97.5 98.5 98.8 98.6 Fallback 74.0 86.0 79.6 74.0 86.0 79.6 41.3 60.5 49.1 42.3 62.8 50.9 17
Eiheiji-cho T5 (address) ⽥尻町から福井市までの福井市内まで From Tajiri-cho to Fukui City to Fukui City BERT/T5 (route) イチゴったー Ichigotta T5 (address) 低い low BERT/T5 (route) アイワかどう Aiwakado Bold and underlined texts denote the reference and hypothesis. • イチゴったー(Ichigotta ): It may be ASR error of “いちごっぱ (ichi-go-ppa, 158)”, which is a colloquial expression for “国道158号 (kokudouhyaku-goju-hachi-gou, Japan National Route 158)”. • 低い(hikui ): It may be ASR error of “福井(Fukui )” • アイワかどう(aiwakado ): It may be ASR error of “舞若道(maiwakado )”, which is abbreviations of “舞 鶴若狭⾃動⾞道(Maizuru-wakasa-jidosyado )”. 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}