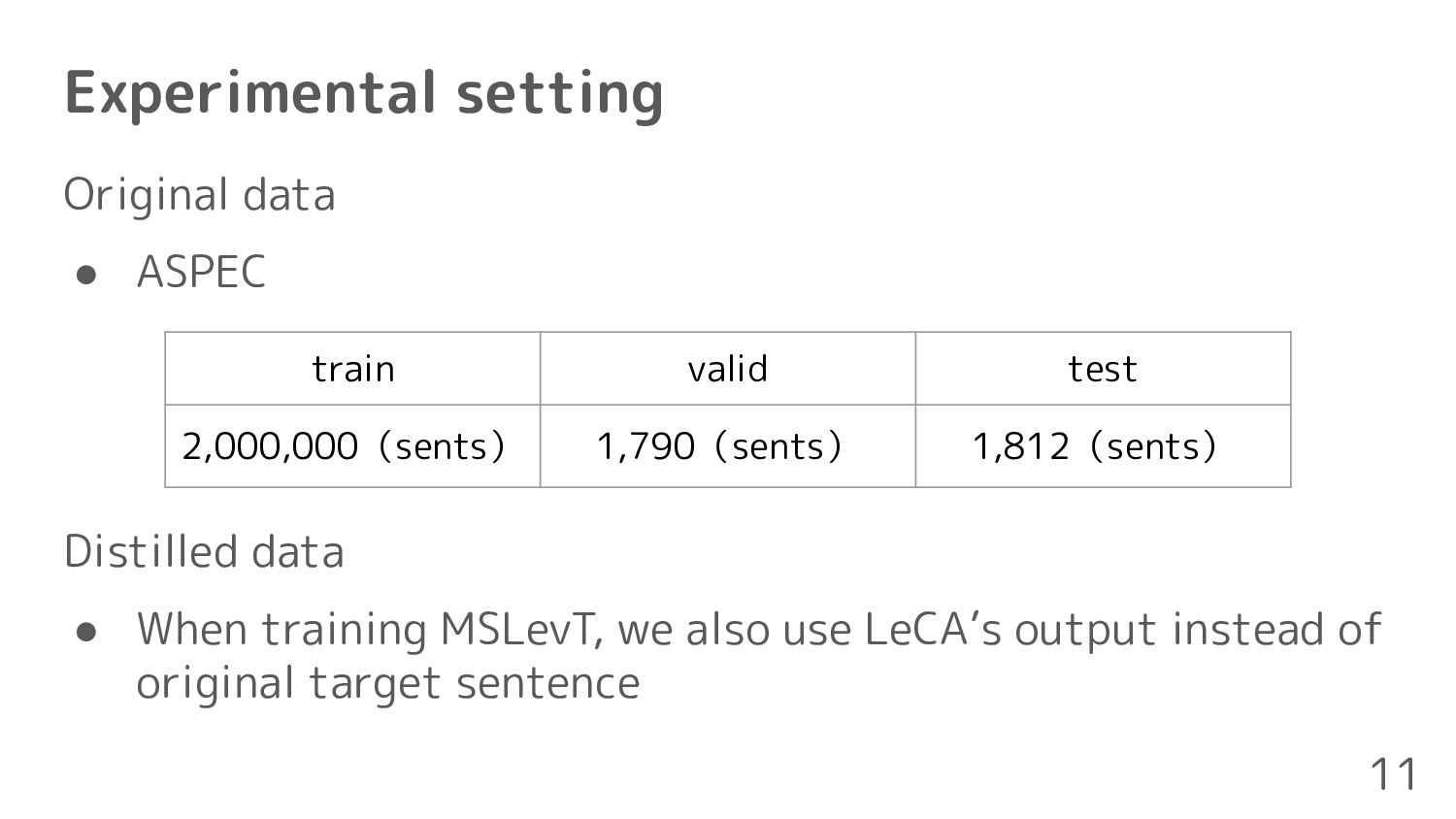
target vocabularies (RTVs) are given ◦ Each RTV consists of more than one word ◦ Given RTVs are random order Input この回路は ,入力信号位相の変化により共振周波数がシフトする帰還回路であり,2基のコイルの中央にある物体 の磁気特性の変化を,高い感度と分解能で検出することができる。 RTVs magnetic features, resonance frequency, feedback circuit, resolution, input signal phase Output This is a feedback circuit shifting resonance frequency by change of input signal phase, which can detect change of magnetic features of an object present at a center of two coils on high sensitivity and resolution. 2 Purpose: Generating a sentence that contains all RTVs
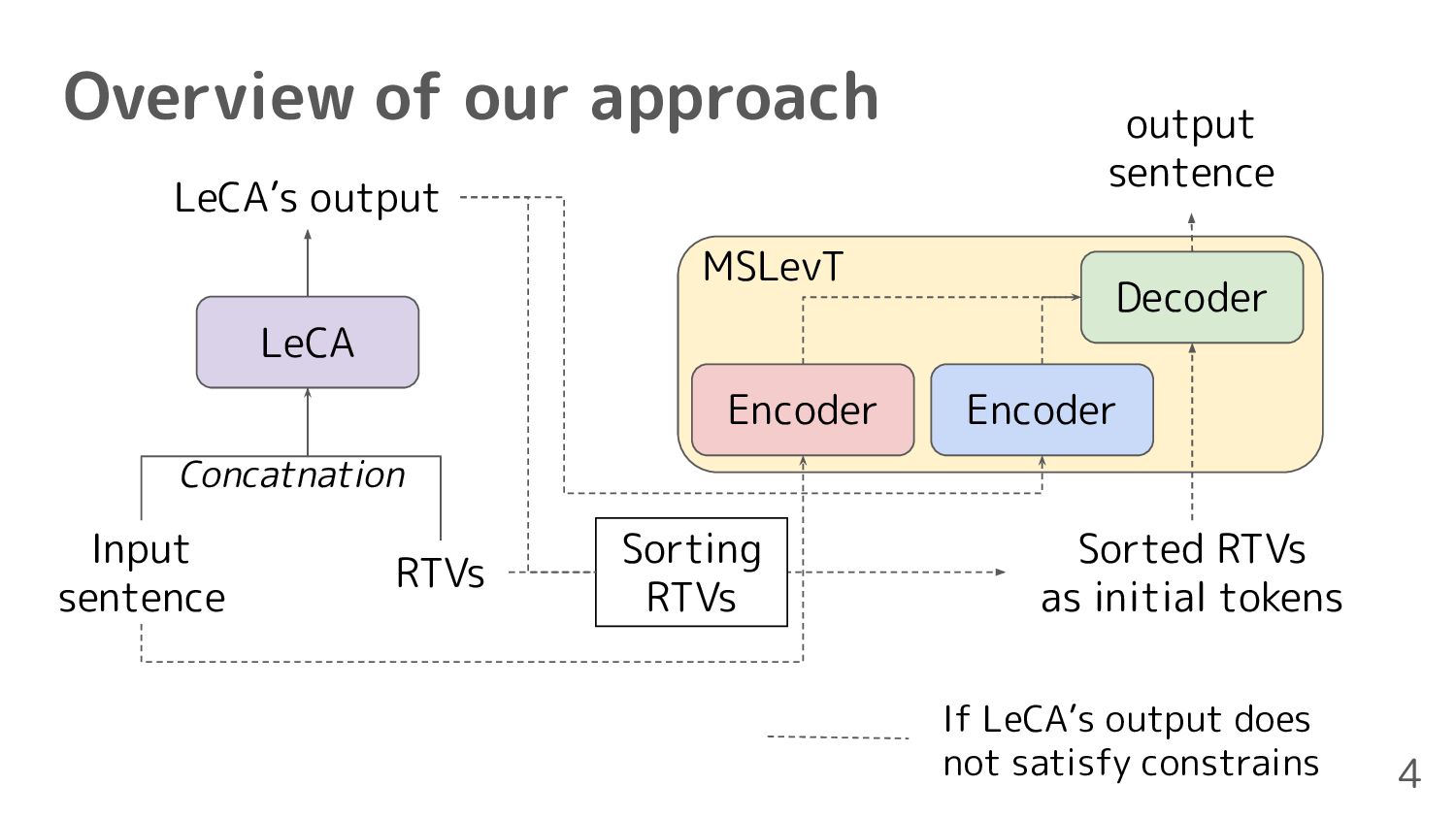
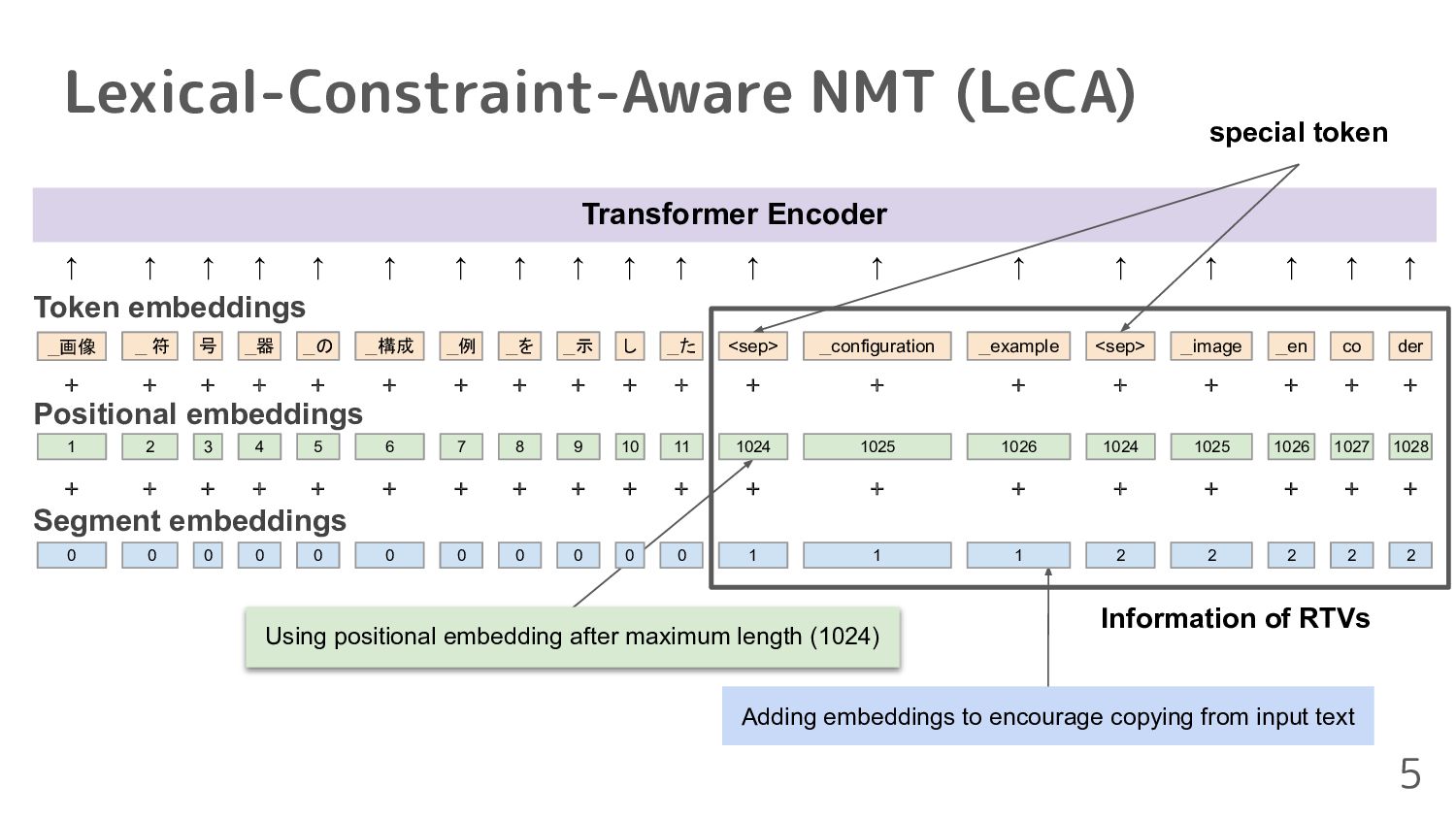
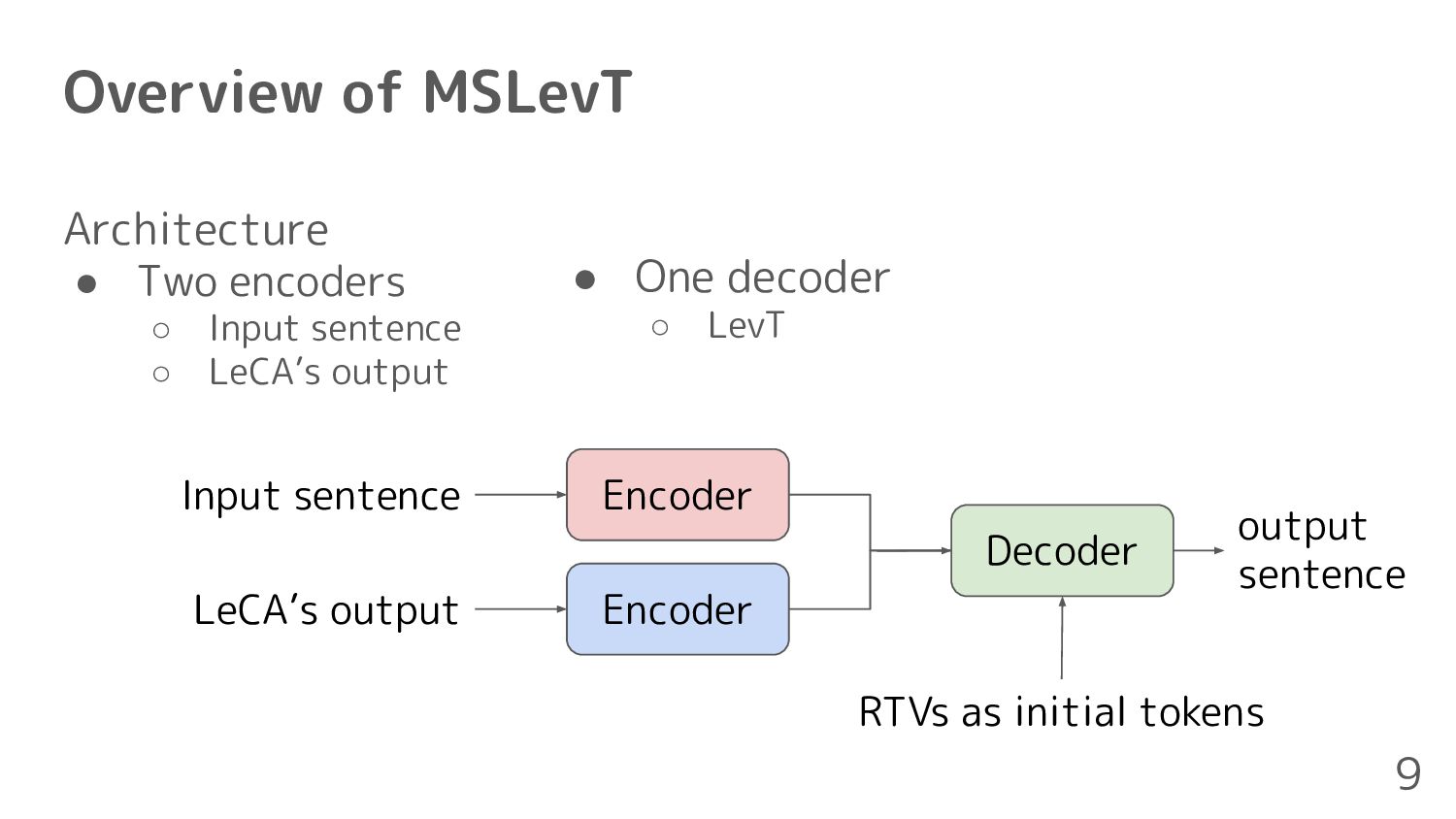
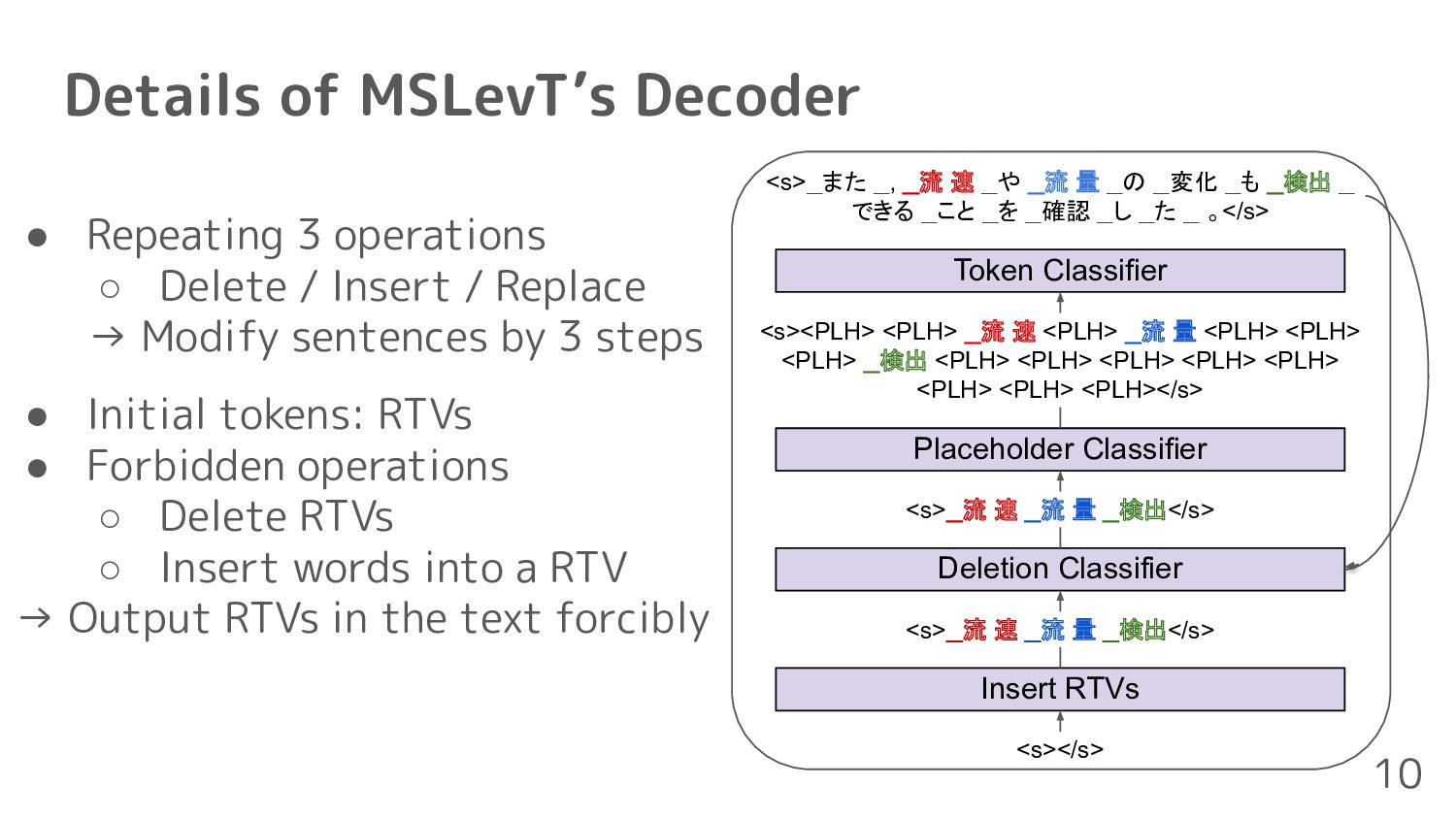
consideration of RTVs • Lexical-Constraint-Aware NMT(LeCA)[Chen+, 2020] ◦ Constraints can be satisfied using with grid beam search, but it is computationally time-consuming 3 Post-processing for the translation not including RTVs 1. Sorting RTVs using fasttext [Bojanowski+, 2017] 2. Automatic post-editing for translation using multi-source Levenshtein transformer(MSLevT)[Wan+, 2020]
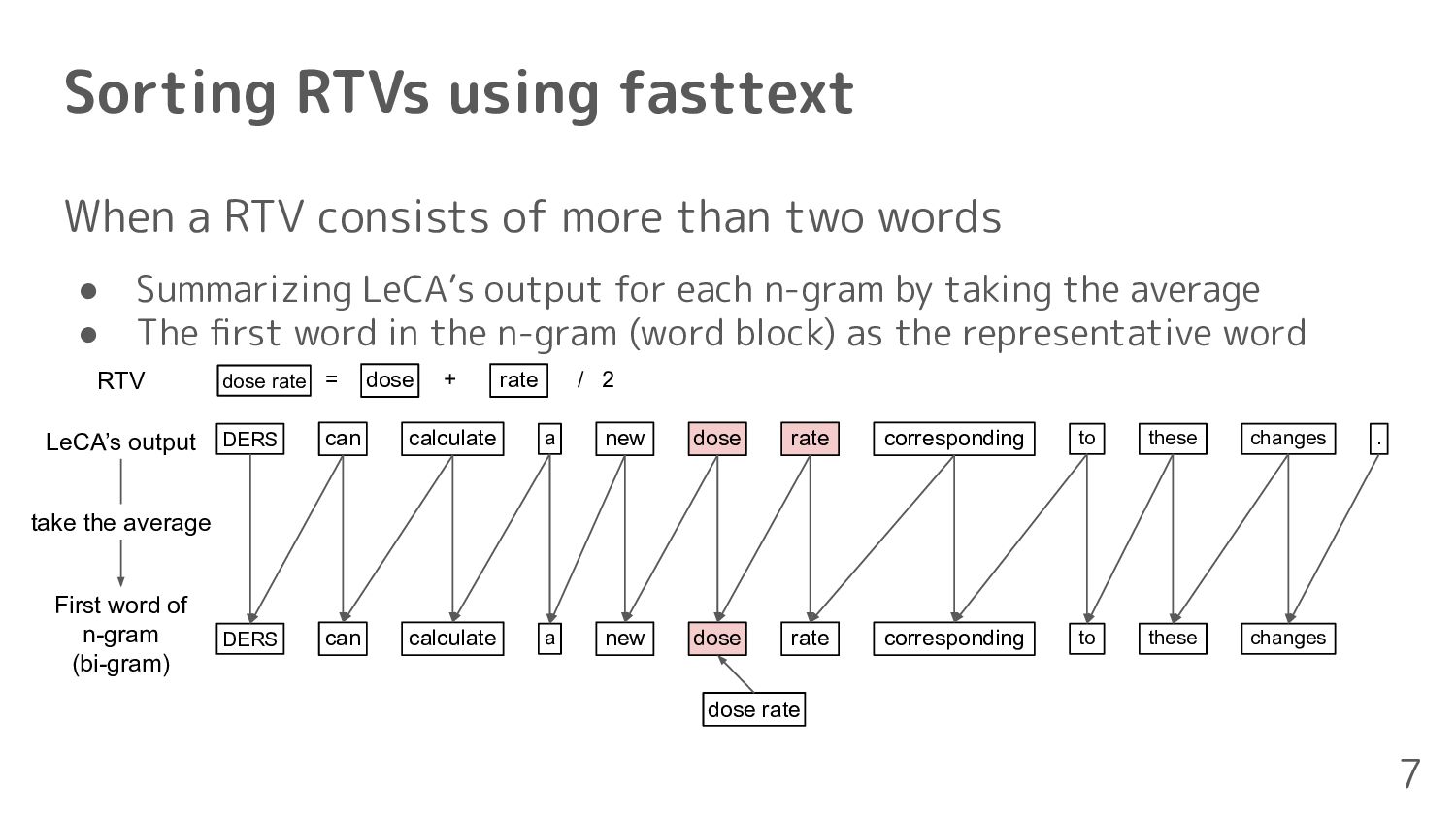
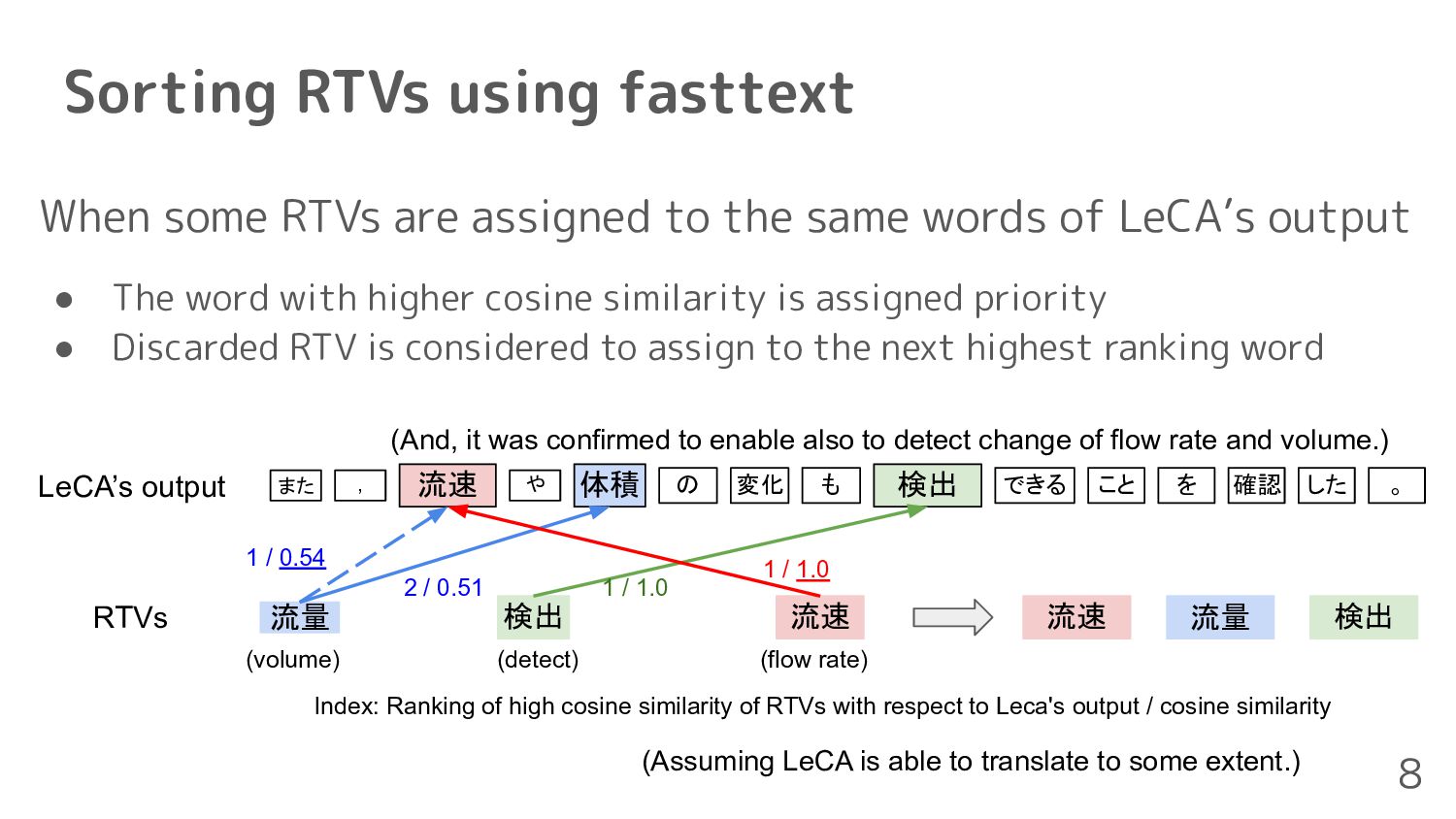
each word of LeCA’s output and RTVs 2. Calculate cosine similarity between each RTV and LeCA’s output 3. Assign the RTV to the LeCA's output with the highest similarity 4. Define the order of RTVs based on assigned position 6 Two irregular cases • A RTV consists of more than two words • Some RTVs are assigned to the same words of LeCA’s output
than two words • Summarizing LeCA’s output for each n-gram by taking the average • The first word in the n-gram (word block) as the representative word 7 DERS can calculate new a dose rate corresponding to these changes . LeCA’s output First word of n-gram (bi-gram) DERS can calculate new a dose rate corresponding to these changes dose rate dose rate = + / 2 take the average dose rate RTV
LeCA’s output • The word with higher cosine similarity is assigned priority • Discarded RTV is considered to assign to the next highest ranking word (detect) 2 / 0.51 また , 流速 体積 や の 変化 も 検出 できる こと を 確認 した 。 LeCA’s output 流量 検出 流速 RTVs 1 / 1.0 1 / 1.0 1 / 0.54 Index: Ranking of high cosine similarity of RTVs with respect to Leca's output / cosine similarity 流量 検出 流速 (volume) (flow rate) Sorting RTVs using fasttext 8 (And, it was confirmed to enable also to detect change of flow rate and volume.) (Assuming LeCA is able to translate to some extent.)
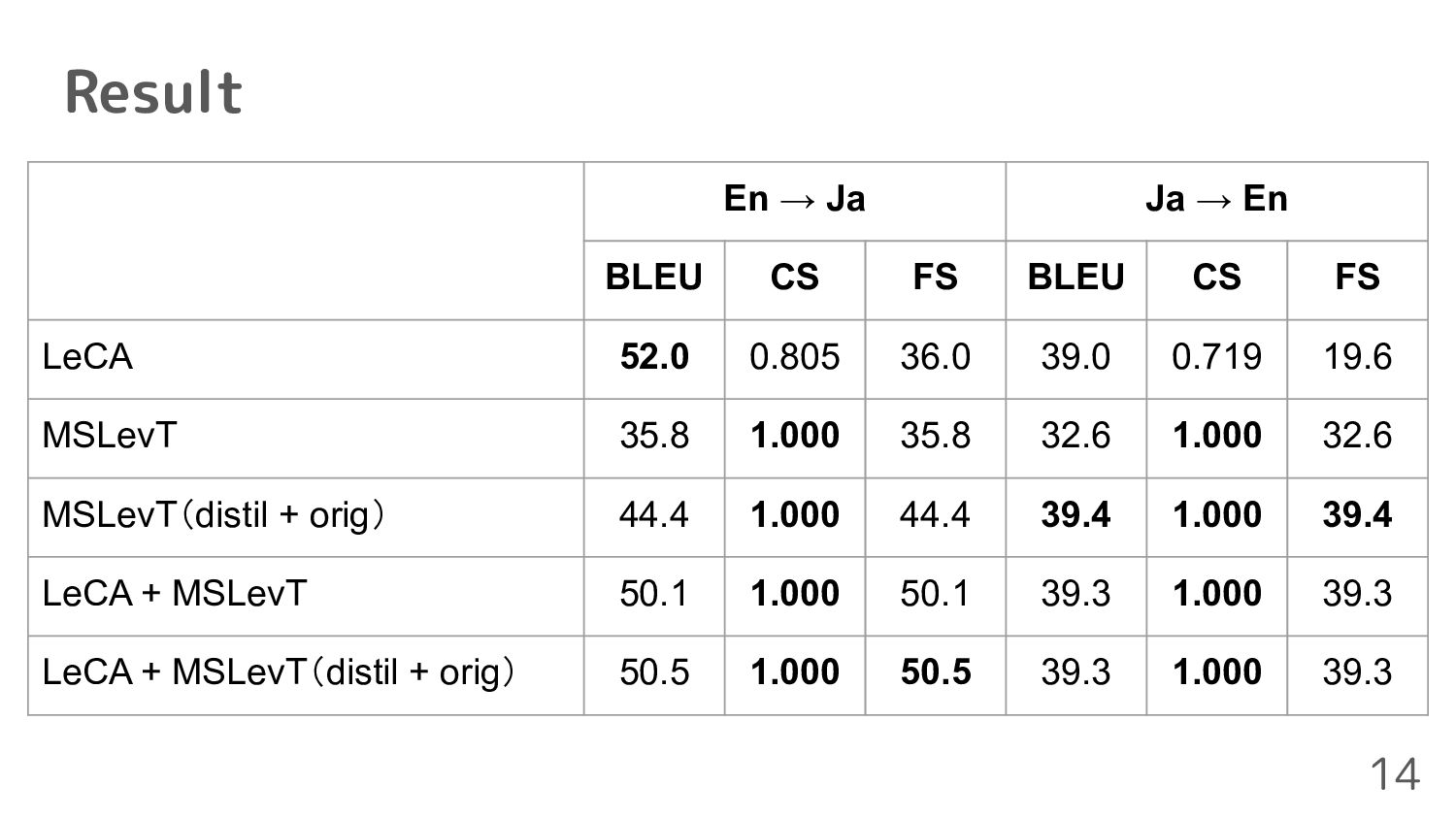
translations that contain all RTVs in the test data • Final score(FS) ◦ Combining the BLEU and consistency scores ◦ Translations not satisfying constraints are replaced to an empty string before calculating BLEU score 13
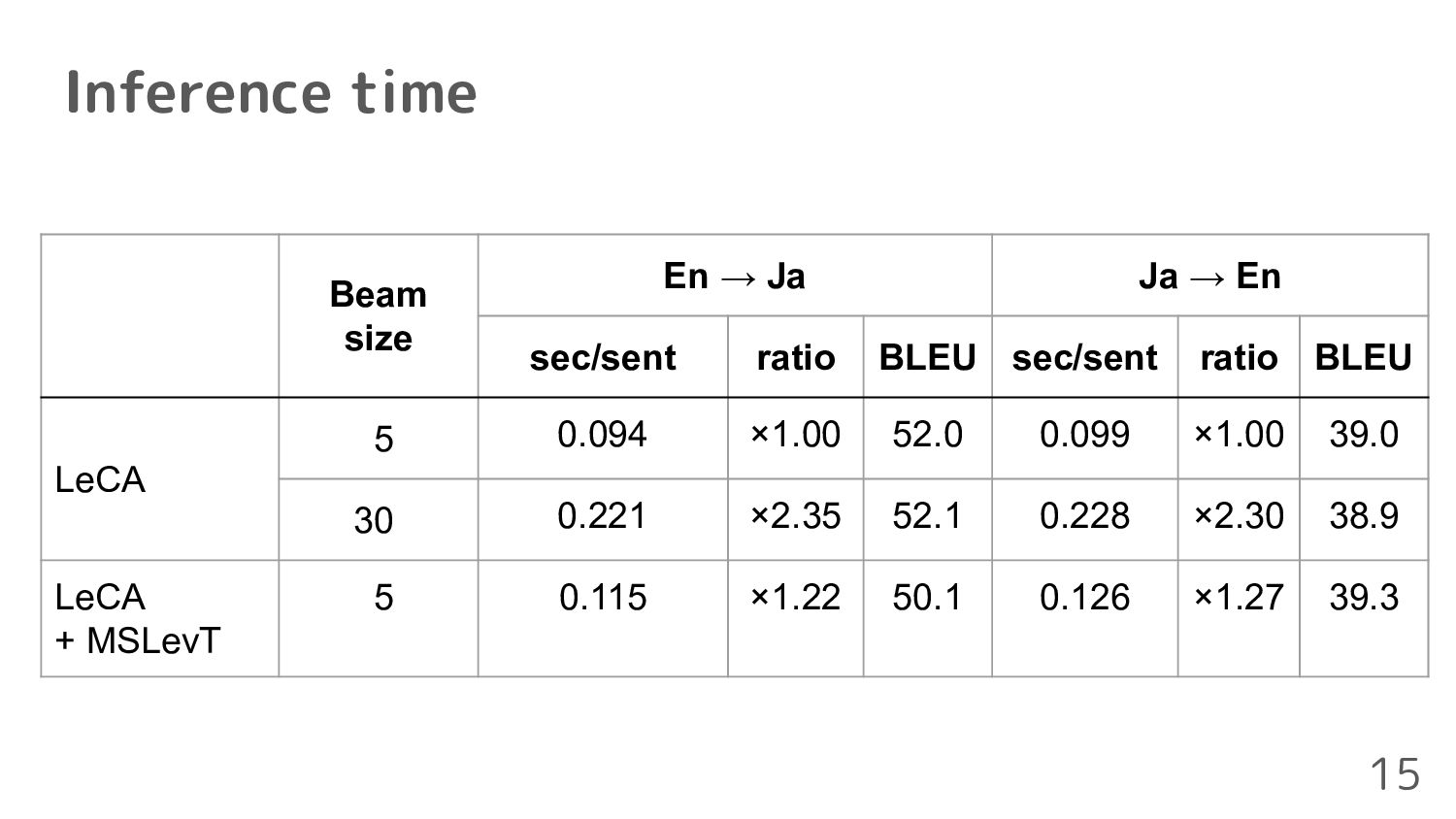
translation task of WAT 2022 • We succeeded in generating sentences including all RTVs keeping the LeCA’s BLEU score • Our proposed method can generate translations faster 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}