Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2021後期_Analyzing the Source and Target Cont...
Search
maskcott
October 22, 2021
Research
83
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
October 22, 2021
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
poster.NAACL-SRW_Two Sentence Concatenation Approach to Data Augmentation for Neural Machine Translation
maskcott
0
120
Other Decks in Research
See All in Research
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
0
100
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
260
IA for theory
gpeyre
0
180
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
650
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
640
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
140
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
200
論文紹介:HalluCitation Matters
wasyro
0
110
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
180
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
250
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
370
Leo the Paperboy
mayatellez
7
1.9k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
140
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
How to build a perfect <img>
jonoalderson
1
5.7k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
950
Everyday Curiosity
cassininazir
0
240
Transcript
発表者: 小町研 M1 今藤誠一郎 2021/10/22 @論文紹介2021 後期 1
概要 • NMTにおいて単語生成時には src と prefix (過去のタイムステップで出力された部 分) の2つの文脈に影響を受ける •
生成決定に対するソースとターゲットの相対的な貢献度を明示的に評価するため の手法は存在しない • Layerwise Relevance Propagation (LRP) を用いてこの評価を試みた 2
貢献 • NMT予測に src, tgt が貢献しているのかを評価する際の LRP の使い方を示した • 異なる
prefix(リファレンス、モデルの出力、ランダム生成)における src と tgt の貢 献の変化 • プレフィックスがランダムのときにモデルが以前の出力に依存する傾向があること を確認した • データが多いほどモデルはsrcの情報に頼るようになり、よりシャープにトークンを 注意することがわかった • 学習プロセスはモノトニックではなくいくつかのステージに分かれることが確認でき た 3
Layer-wise Relevance Propagation (LRP) • 画像処理分野にてBach et al. が2015年に提案した手法 •
DNNの予測を単一の入力次元(画像: サブピクセル, トークン: エンべディング)に 対する “関連性スコア” に分解するフレームワーク • attention層のあるTransformerモデルにそのまま適用することができない 4
LRPの設定 • 関連スコア を各層の各次元に定義 • 保存則 • 分配則 この条件を満たすために様々な手法があるが、 ここではLRP-αβを利用する
5 l + 1 層 l 層 最終層 R i (l) R j (l+1) R j+3 (l+1 ) R j+1 (l+1 ) R j+2 (l+1 ) R k (l+2 ) ••• ••• f ••• ••• v ij ※ここのfはtop-1 logit
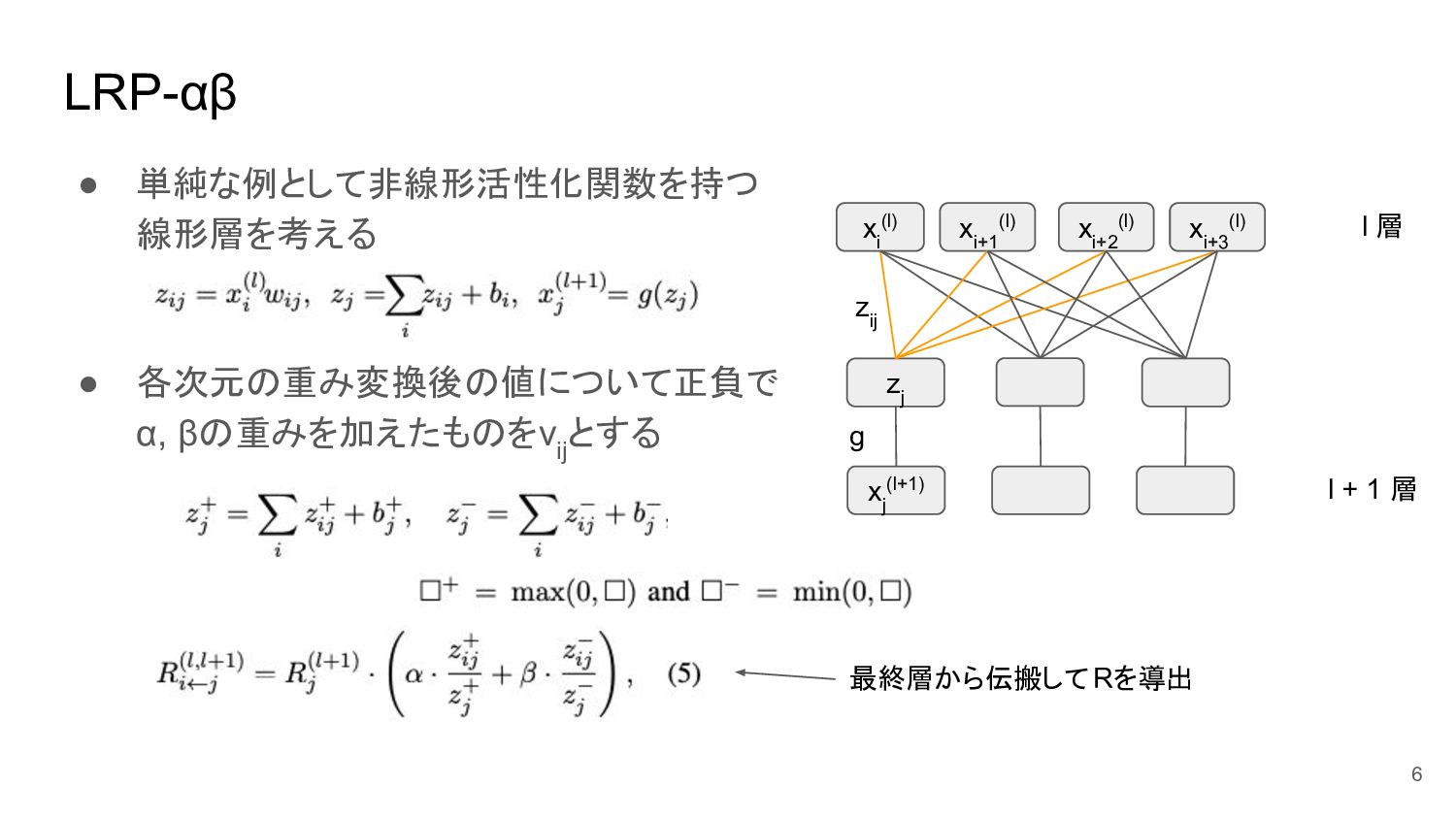
LRP-αβ • 単純な例として非線形活性化関数を持つ 線形層を考える • 各次元の重み変換後の値について正負で α, βの重みを加えたものをv ij とする
6 最終層から伝搬して Rを導出 z ij l 層 l + 1 層 x i (l) x i+3 (l) x i+1 (l) x i+2 (l) z j x j (l+1) g
Attention層への対処 • これまでの話は下のように表現できる構造をしているモデルに適用可能 各層は線形演算畳み込み演算を含んでおり、ReLUのような単調な活性化関数をLRPでは無視している (Bach et al., 2015) ⇨ attention層は線形演算ではないので適用不可
(z ij に相当するものがない) ⇨ としてテイラー展開を用いて拡張する 7 任意のベクトルに対する変換をテイラー展開 元の式に代入 入力ニューロンごとに分割 このz ij を用いることで複雑な非線形層においても先の関連スコアの伝搬が可能になる TransformerにおいてAttention層で式(7)を適用する(任意のベクトルはゼロベクトルとする)
条件付き言語モデルへの適用 • 標準的な機械翻訳モデルは入力と既に生成されたトークンに基づいて出力トークン を決定 → 出力に関わる全てのトークンの貢献度を知りたい • エンコーダーデコーダー間にも伝搬を次の2ステップで適用 ◦ デコーダーを関連スコアが逆伝播するが一部がエンコーダーへ流れる
(デコーダーはエンコーダー最終層の表現を用いるため) ◦ エンコーダーへ流れた関連スコアが伝播される ※ デコーダーの各層の関連スコアの合計は保存されない、全トークンの関連スコアの合計が予測値となる モデルの予測する単語候補の中で最も高い確率のものに対する貢献度で評価している 8 タイムステップtにおける関連スコアの制 約(top1 logitを1として正規化)
実験設定 • Transformer base model (Vaswani et al., 2017) •
WMT14 En-Fr dataset (1m, 2.5m, 5m, 10m, 20m, 30m) • αβ-LRP (α = ½, β = ½), (α=1, β = 0)を試したが同様の傾向が見られたため、 論文では後者を利用 • 1000文からなる評価データを用いた平均で評価 各文の src, tgt のトークン数が揃ったデータセットになっている 9
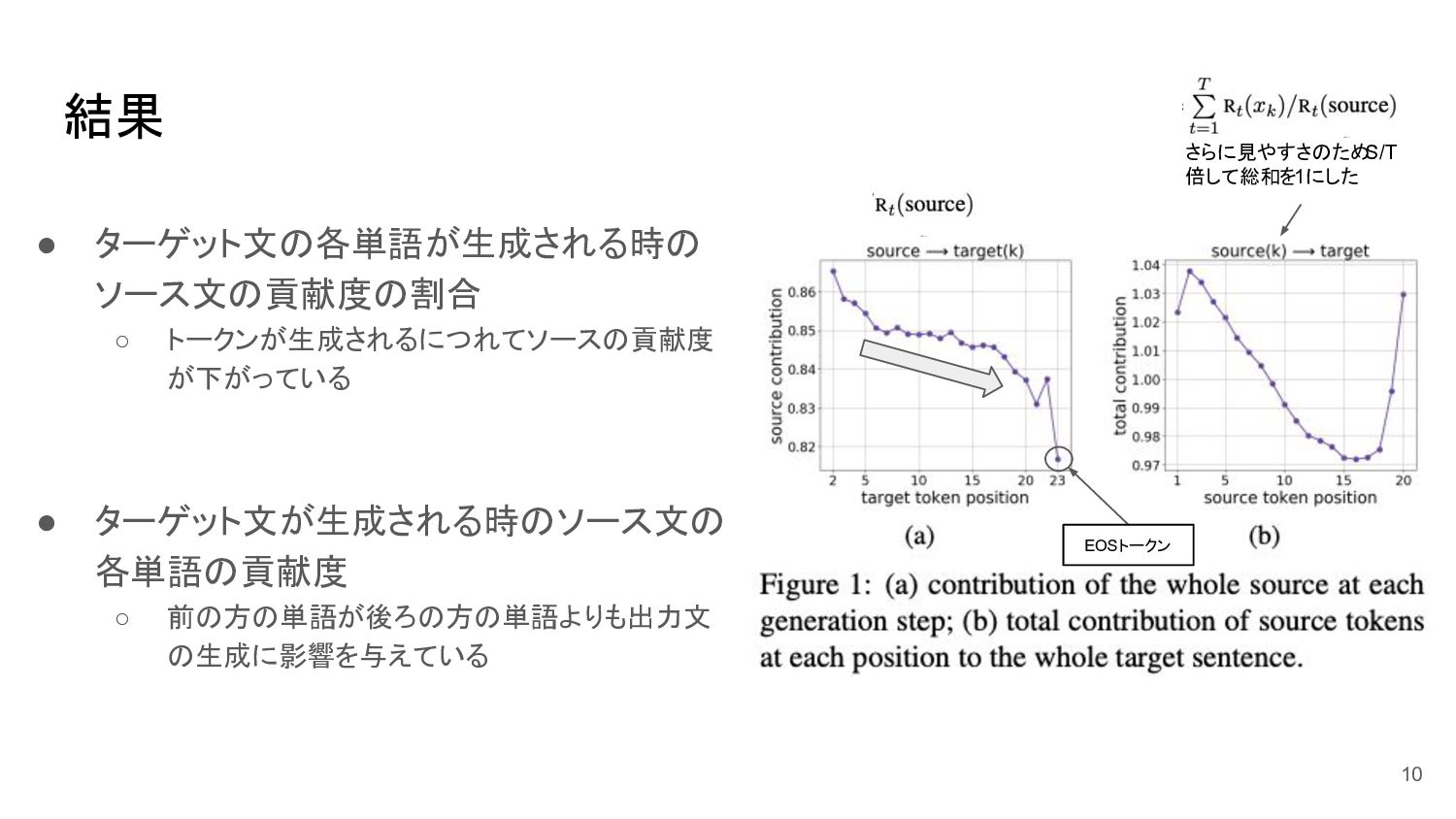
結果 • ターゲット文の各単語が生成される時の ソース文の貢献度の割合 ◦ トークンが生成されるにつれてソースの貢献度 が下がっている • ターゲット文が生成される時のソース文の 各単語の貢献度
◦ 前の方の単語が後ろの方の単語よりも出力文 の生成に影響を与えている 10 さらに見やすさのため S/T 倍して総和を1にした EOSトークン
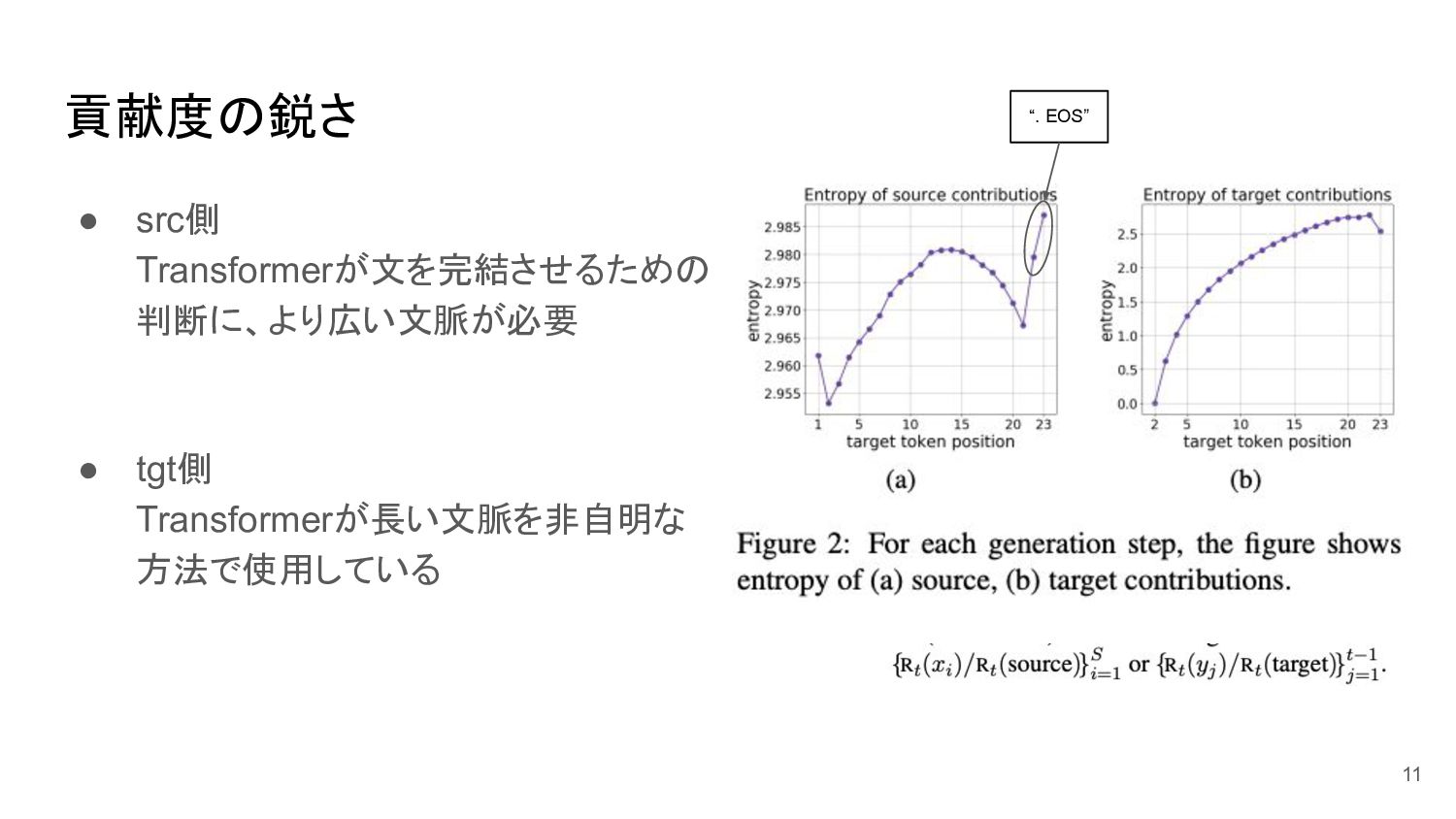
貢献度の鋭さ • src側 Transformerが文を完結させるための 判断に、より広い文脈が必要 • tgt側 Transformerが長い文脈を非自明な 方法で使用している 11
“. EOS”
prefixの影響 • Reference vs model prefixes (a, b) ◦ モデルの生成したprefixを与えた方がsrcの
情報を多く利用し、より見るトークンを特定 できている → モデルの出力がより簡単なため • Reference vs random prefixes (c, d) ◦ 先行研究で述べられている NMTにおける 自己回復能力の影響が顕著に現れている 12
Exposure Bias に関する分析 • Exposure bias (Ranzato et al.,2016) :
学習時はリファレンスを与えられるのにテ スト時には出力結果に基づいた出力をするという問題 • Wang and Sennrich (2020) はNMTで問題になる幻覚現象(ソース文に全く関係 のない語を流暢に出力する)が、exposure biasに起因すると考え、Minimum Risk Training (MRT) を提案 • 実際にMRTは幻覚現象を低減したが、tgtへの過度の依存を直接測れなかった → 今回の提案手法で分析を行う • Exposure biasへのアプローチとしてword dropoutも比較対象として行う 13 文単位での目的関数
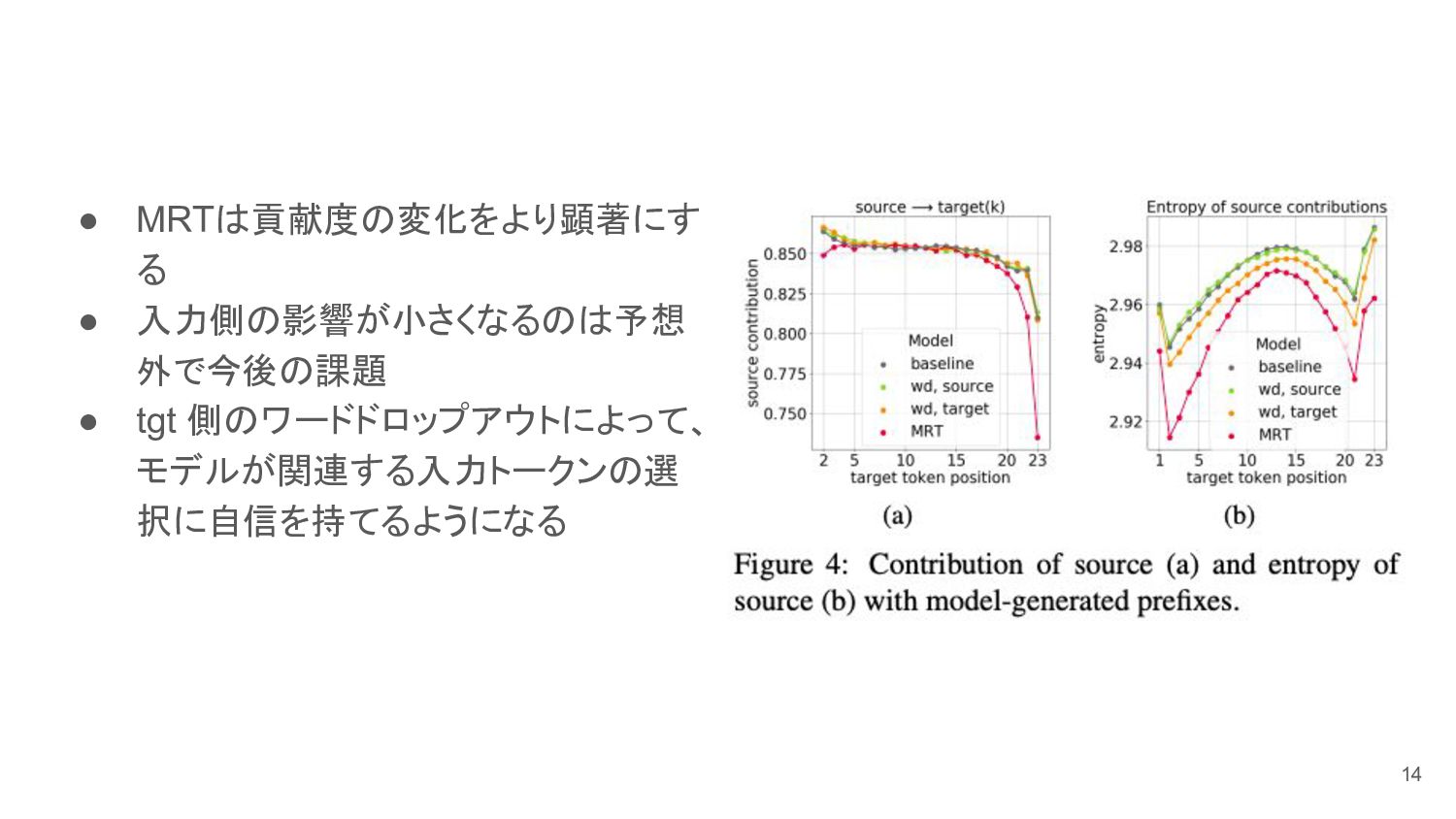
• MRTは貢献度の変化をより顕著にす る • 入力側の影響が小さくなるのは予想 外で今後の課題 • tgt 側のワードドロップアウトによって、 モデルが関連する入力トークンの選
択に自信を持てるようになる 14
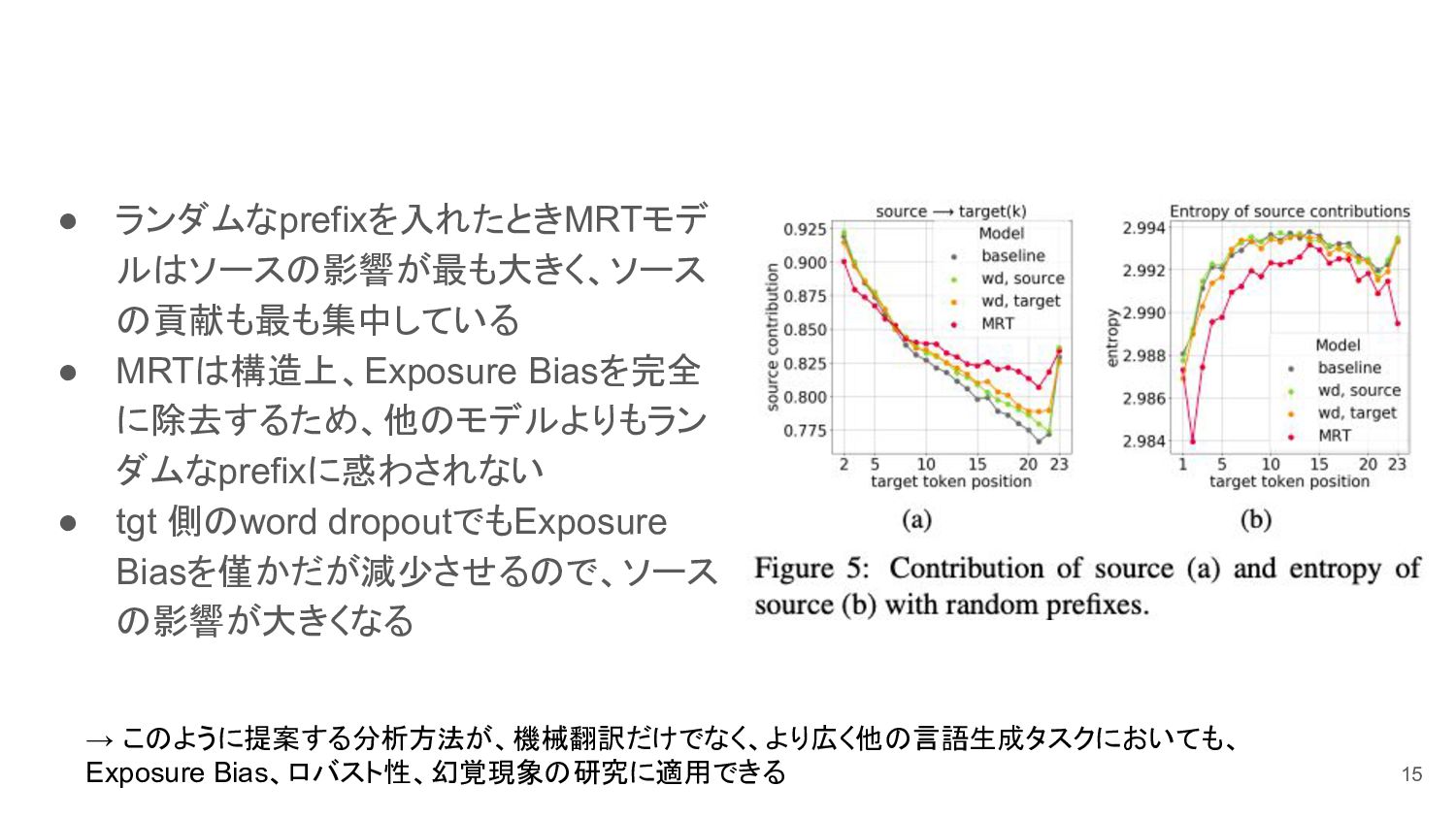
• ランダムなprefixを入れたときMRTモデ ルはソースの影響が最も大きく、ソース の貢献も最も集中している • MRTは構造上、Exposure Biasを完全 に除去するため、他のモデルよりもラン ダムなprefixに惑わされない •
tgt 側のword dropoutでもExposure Biasを僅かだが減少させるので、ソース の影響が大きくなる 15 → このように提案する分析方法が、機械翻訳だけでなく、より広く他の言語生成タスクにおいても、 Exposure Bias、ロバスト性、幻覚現象の研究に適用できる
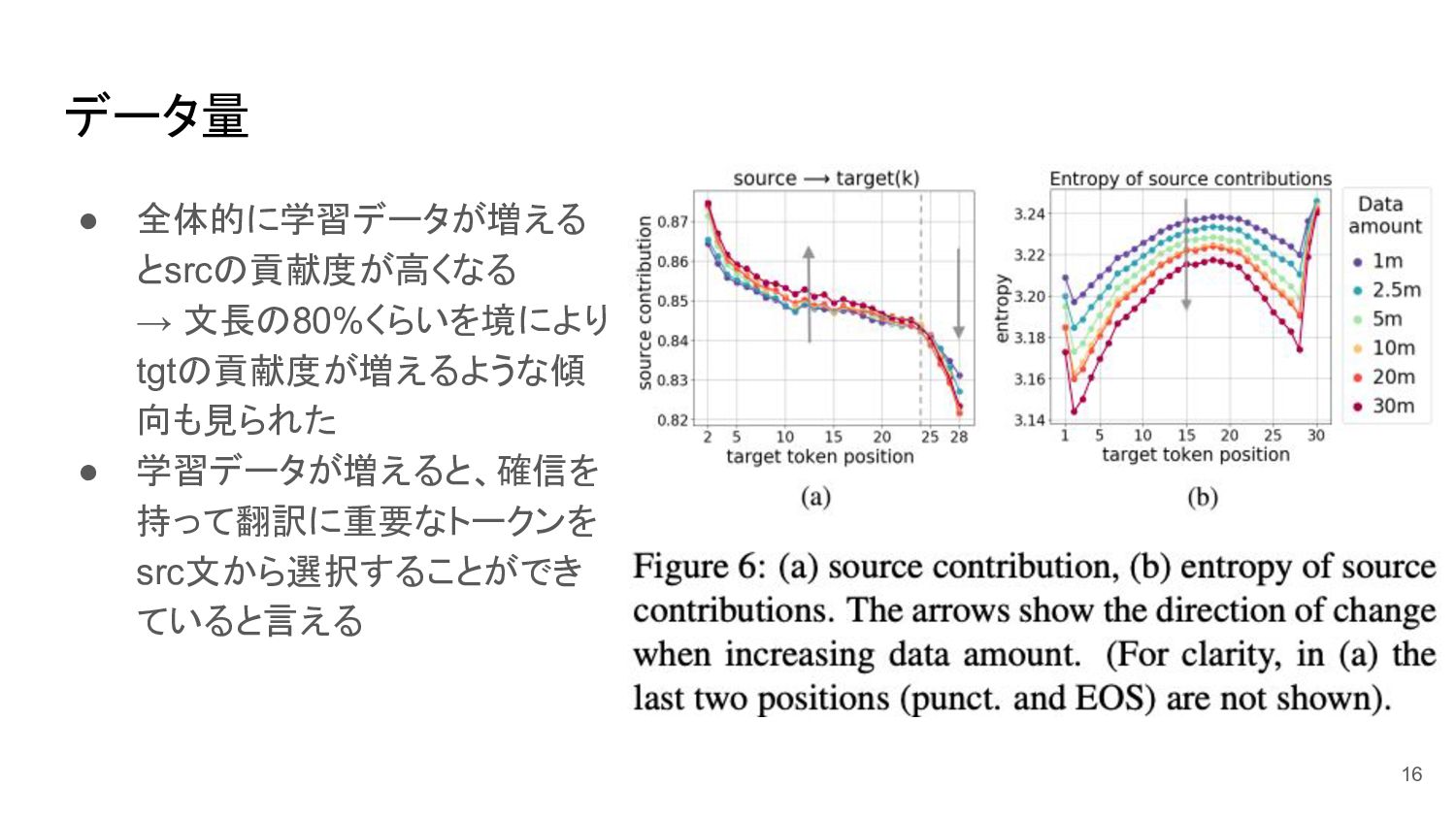
データ量 • 全体的に学習データが増える とsrcの貢献度が高くなる → 文長の80%くらいを境により tgtの貢献度が増えるような傾 向も見られた • 学習データが増えると、確信を
持って翻訳に重要なトークンを src文から選択することができ ていると言える 16
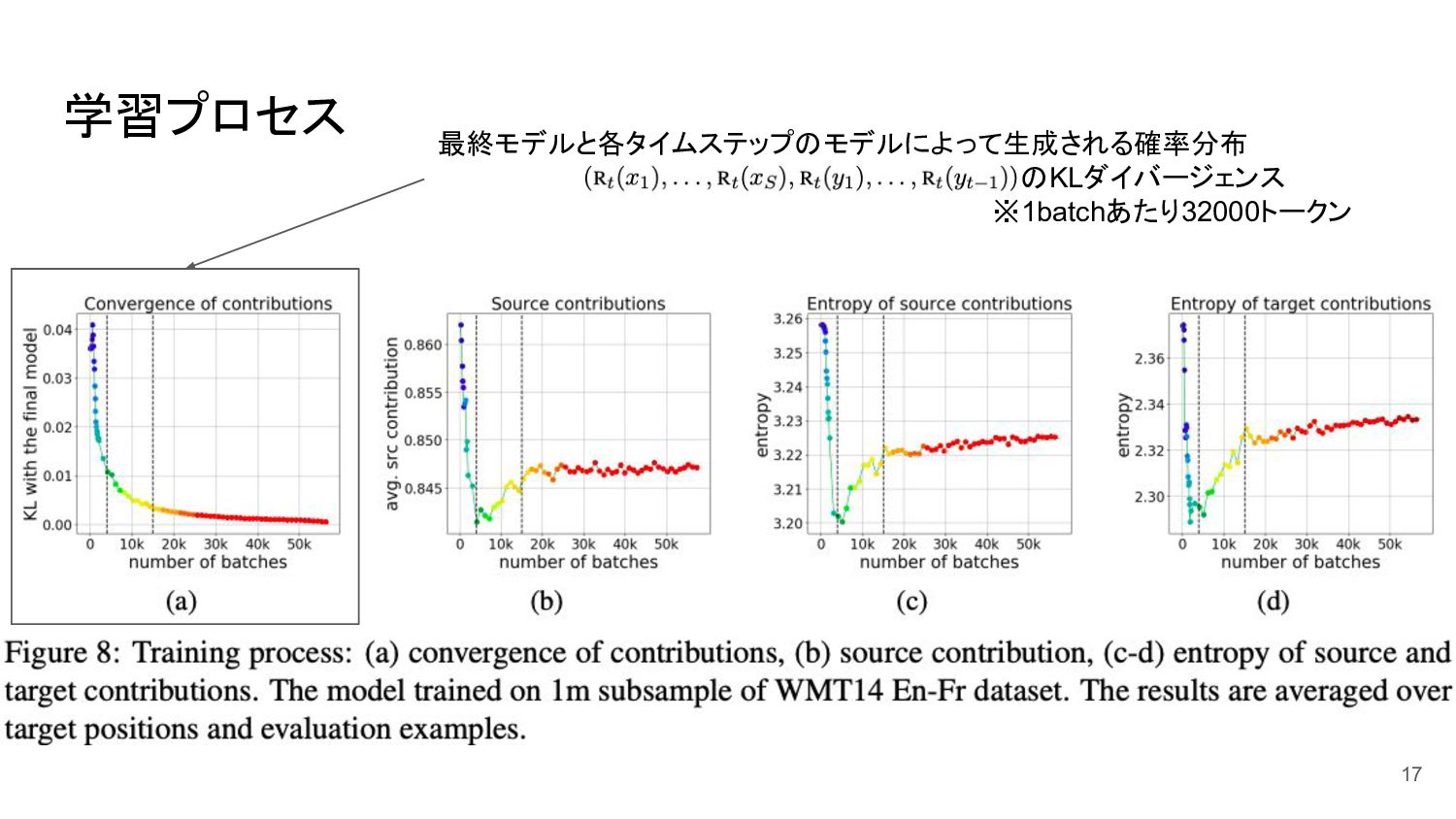
学習プロセス 17 最終モデルと各タイムステップのモデルによって生成される確率分布 のKLダイバージェンス ※1batchあたり32000トークン
18
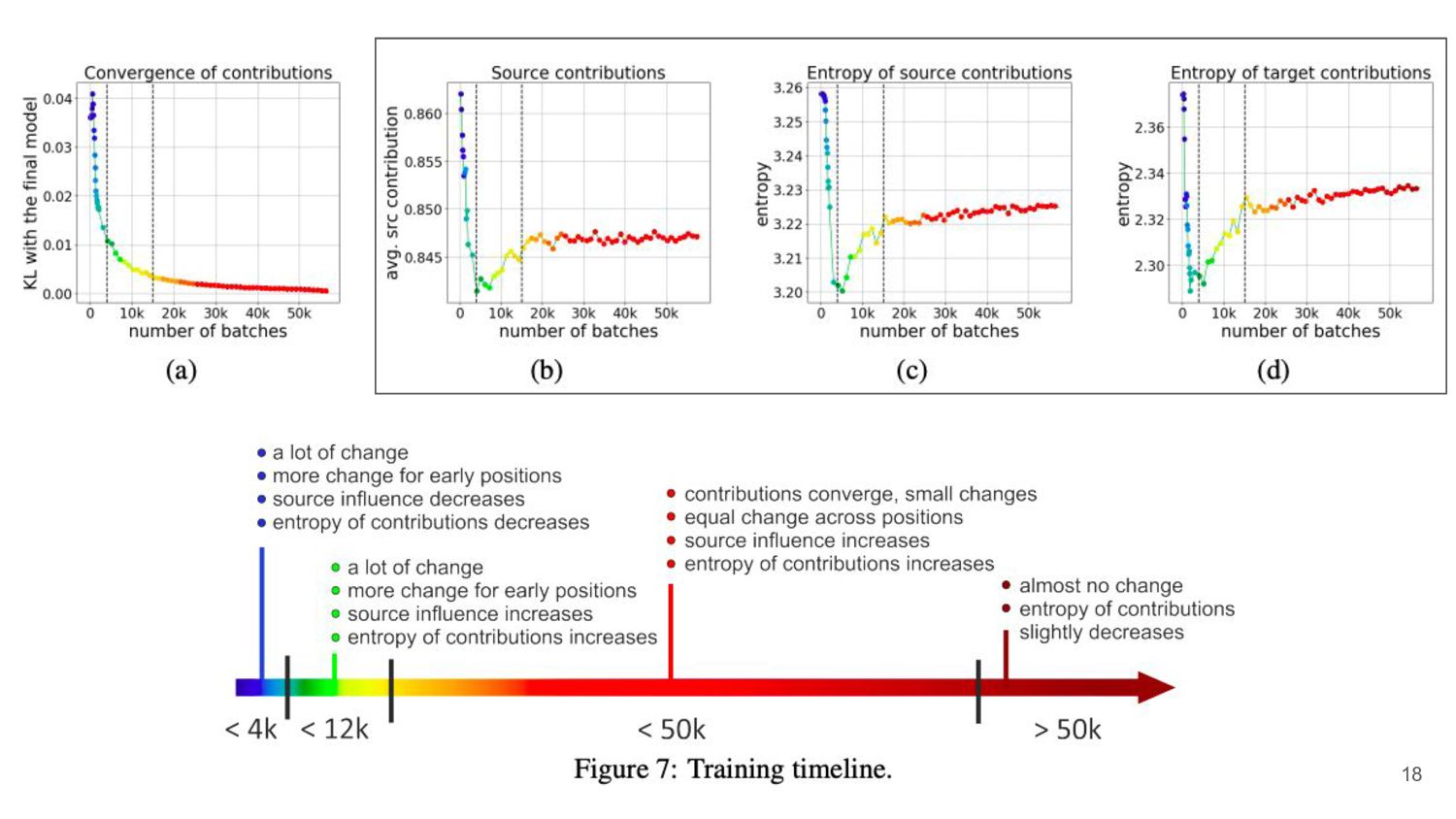
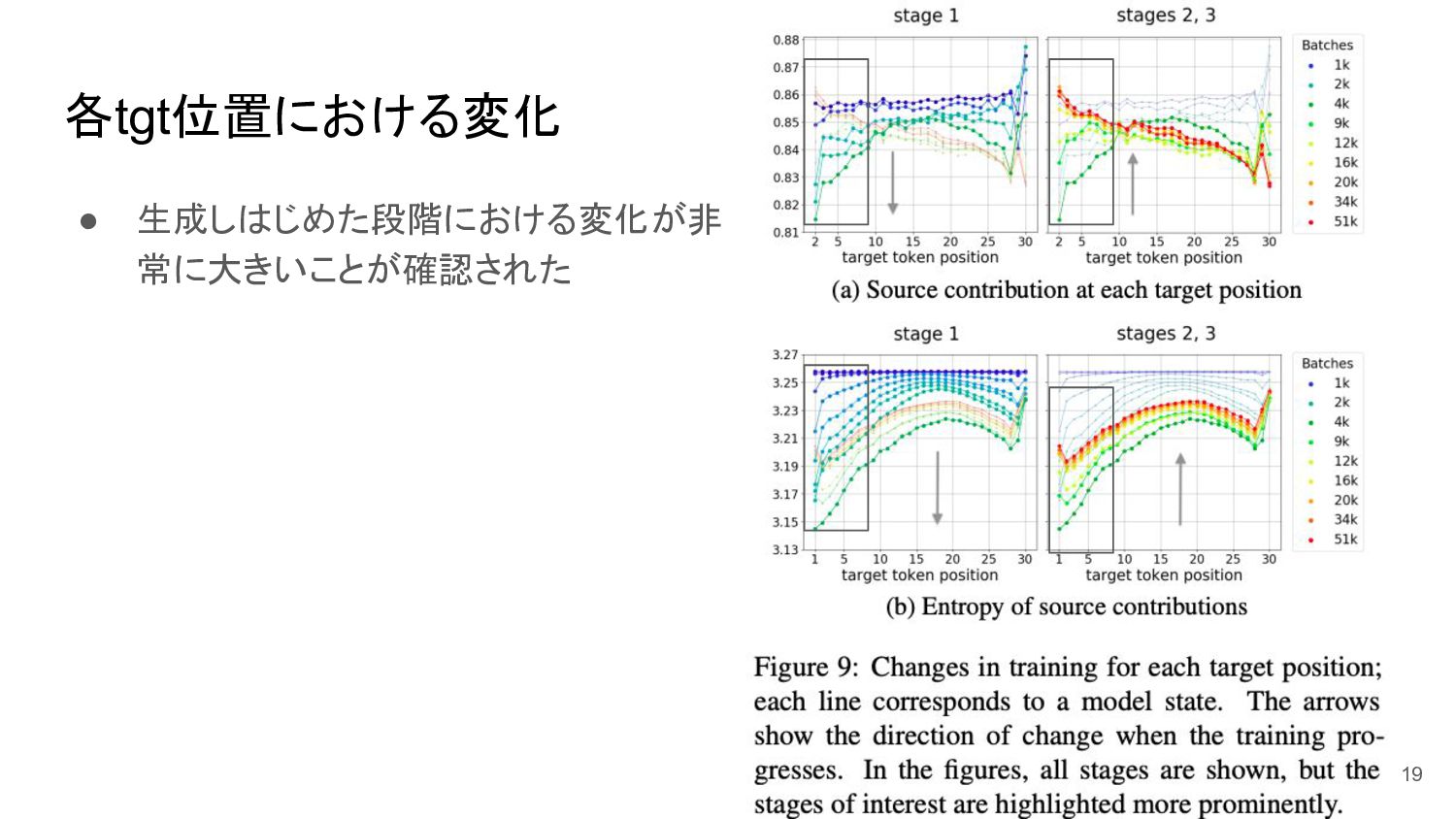
各tgt位置における変化 • 生成しはじめた段階における変化が非 常に大きいことが確認された 19
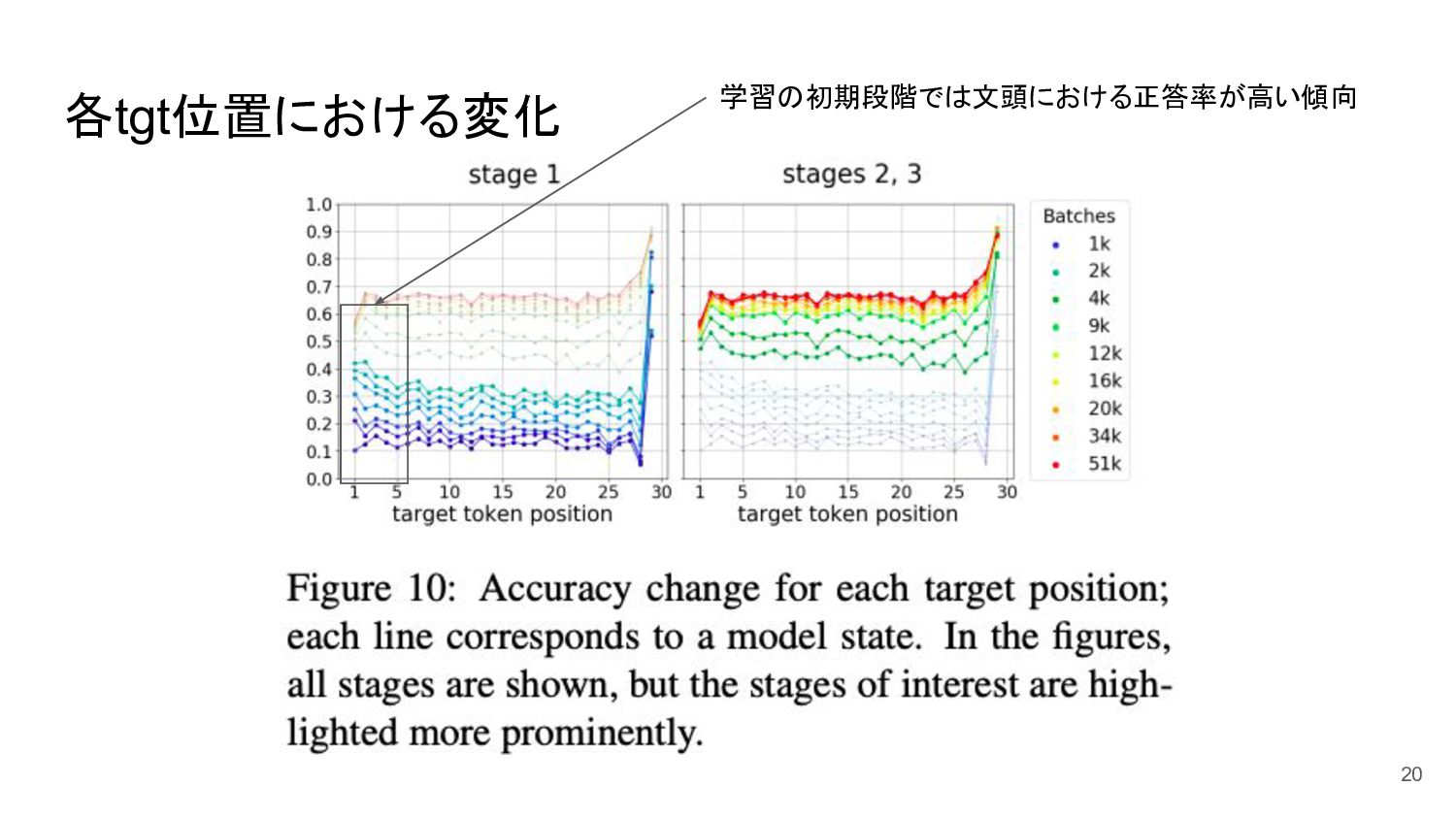
各tgt位置における変化 20 学習の初期段階では文頭における正答率が高い傾向
まとめ • LRPを用いてNMT予測に対するsrcとtgtの相対的な貢献度を評価する方法を示し た • 異なる種類のprefixを条件とした時、学習データ量を変化させた時、学習プロセス 中、における貢献度の変化などを分析することでこの分析手法の有効性を示した • より多くのデータを用いて学習すると予測の際によりsrcの情報に依存し、より単語 の貢献度は鋭くなる
• 学習プロセスは単調ではなくいくつかのステージに分類することができる code: https://github.com/lena-voita/the-story-of-heads blog: https://lena-voita.github.io/posts/source_target_contributions_to_nmt.html 21
まとめ • LRPを用いてNMT予測に対するsrcとtgtの相対的な貢献度を評価する方法を示し た • 異なる種類のprefixを条件とした時、学習データ量を変化させた時、学習プロセス 中、における貢献度の変化などを分析することでこの分析手法の有効性を示した • より多くのデータを用いて学習すると予測の際によりsrcの情報に依存し、より単語 の貢献度は鋭くなる
• 学習プロセスは単調ではなくいくつかのステージに分類することができる • 今後は、この分析方法を用いてソースとターゲットの貢献度のバランスに関する、 他の学習方法の効果を測定する 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}