Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介2022前期_Redistributing Low Frequency Words: ...
Search
maskcott
June 15, 2022
Research
66
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
June 15, 2022
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
poster.NAACL-SRW_Two Sentence Concatenation Approach to Data Augmentation for Neural Machine Translation
maskcott
0
120
Other Decks in Research
See All in Research
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
130
「AIとWhyを深堀る」をAIと深堀る
iflection
0
500
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
130
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
210
Data Visualization Tools in the Age of AI
flekschas
0
160
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
220
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
310
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
520
Ankylosing Spondylitis
ankh2054
0
180
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
130
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
640
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
420
Featured
See All Featured
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
210
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
330
Google's AI Overviews - The New Search
badams
0
1k
Building Adaptive Systems
keathley
44
3.1k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
280
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Producing Creativity
orderedlist
PRO
348
40k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
160
How to Ace a Technical Interview
jacobian
281
24k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
580
Transcript
発表者: 小町研 M2 今藤誠一郎 2022/6/15 @論文紹介2022 前期 1
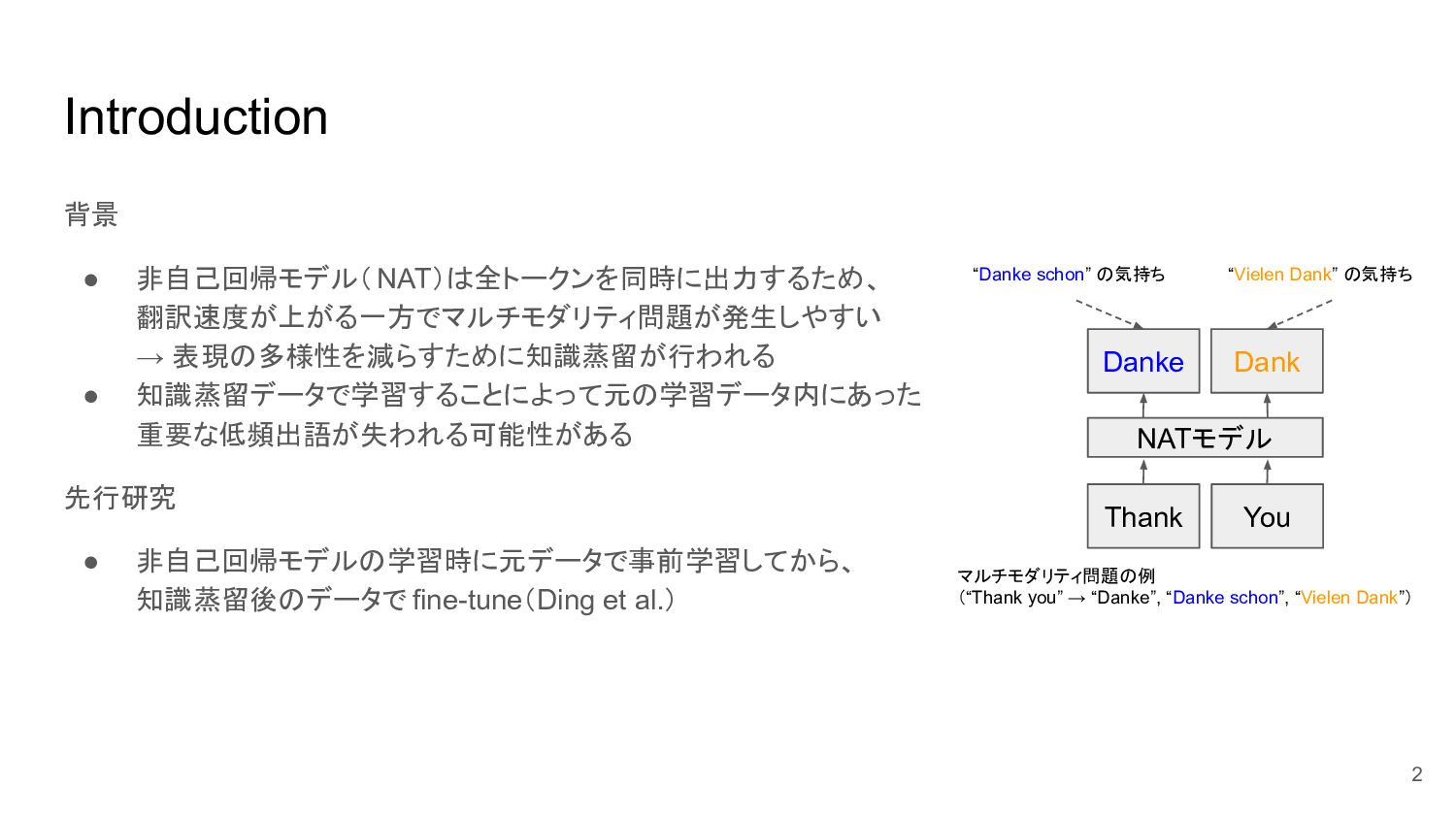
Introduction 背景 • 非自己回帰モデル( NAT)は全トークンを同時に出力するため、 翻訳速度が上がる一方でマルチモダリティ問題が発生しやすい → 表現の多様性を減らすために知識蒸留が行われる • 知識蒸留データで学習することによって元の学習データ内にあった
重要な低頻出語が失われる可能性がある 先行研究 • 非自己回帰モデルの学習時に元データで事前学習してから、 知識蒸留後のデータで fine-tune(Ding et al.) 2 マルチモダリティ問題の例 (“Thank you” → “Danke”, “Danke schon”, “Vielen Dank”) NATモデル Danke Dank “Danke schon” の気持ち “Vielen Dank” の気持ち Thank You
本研究 • 知識蒸留の際に単言語コーパスから蒸留データを作成することを提案 貢献 • 提案手法は全てのケースで通常の KDよりも高いBLEUスコアを達成 • 提案手法は単言語コーパスは比較的容易に手に入るという点でデータの規模を拡大させることが 難しくなくモデルの限界まで性能を向上させることができうる
• 提案手法は通常の知識蒸留を補完するものであり、両者を組み合わせることで、 マルチモダリティ問題と低頻度単語翻訳問題を軽減し、さらなる改善を得ることができる 3 概要
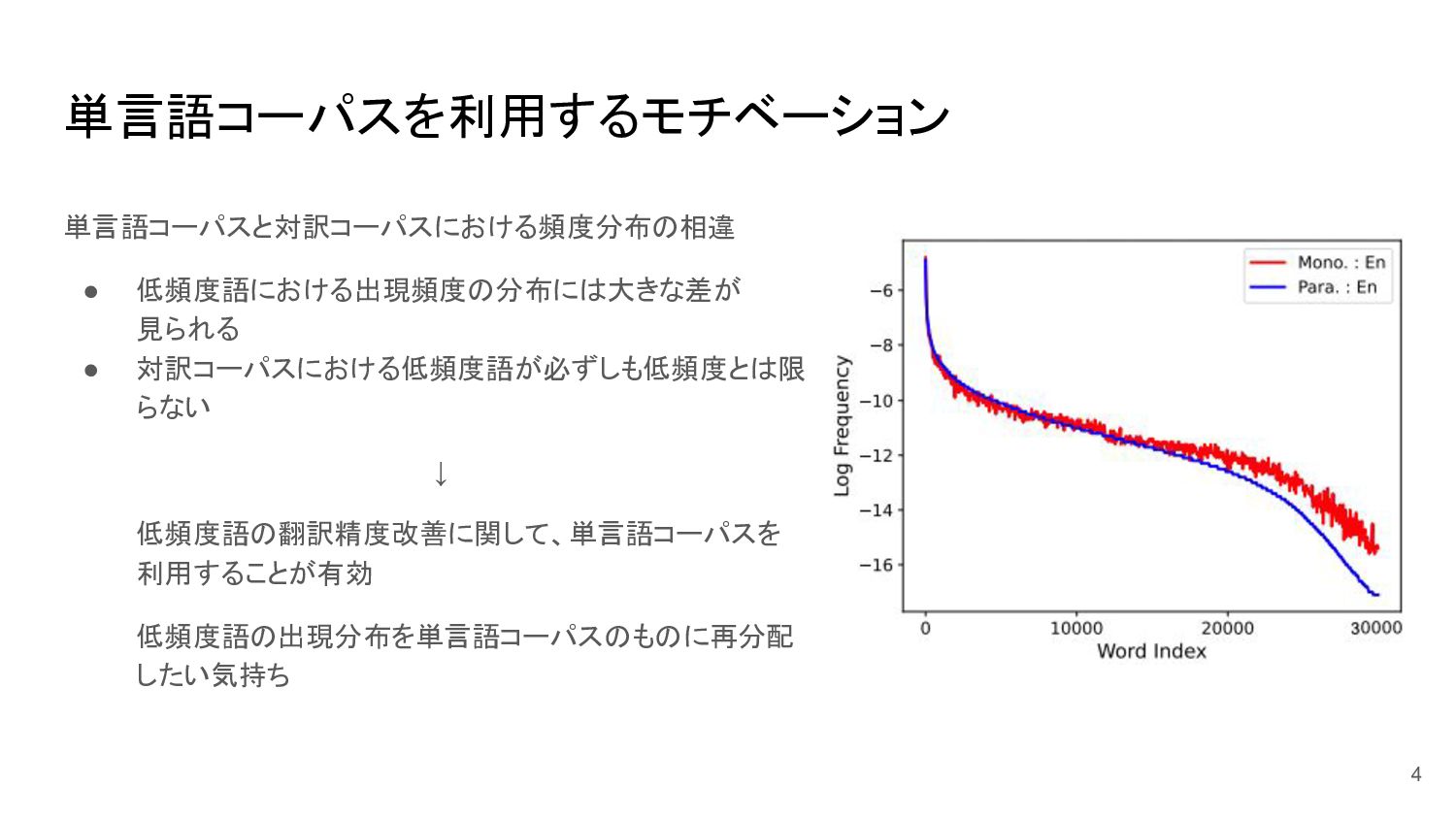
単言語コーパスと対訳コーパスにおける頻度分布の相違 • 低頻度語における出現頻度の分布には大きな差が 見られる • 対訳コーパスにおける低頻度語が必ずしも低頻度とは限 らない ↓ 低頻度語の翻訳精度改善に関して、単言語コーパスを 利用することが有効
低頻度語の出現分布を単言語コーパスのものに再分配 したい気持ち 4 単言語コーパスを利用するモチベーション
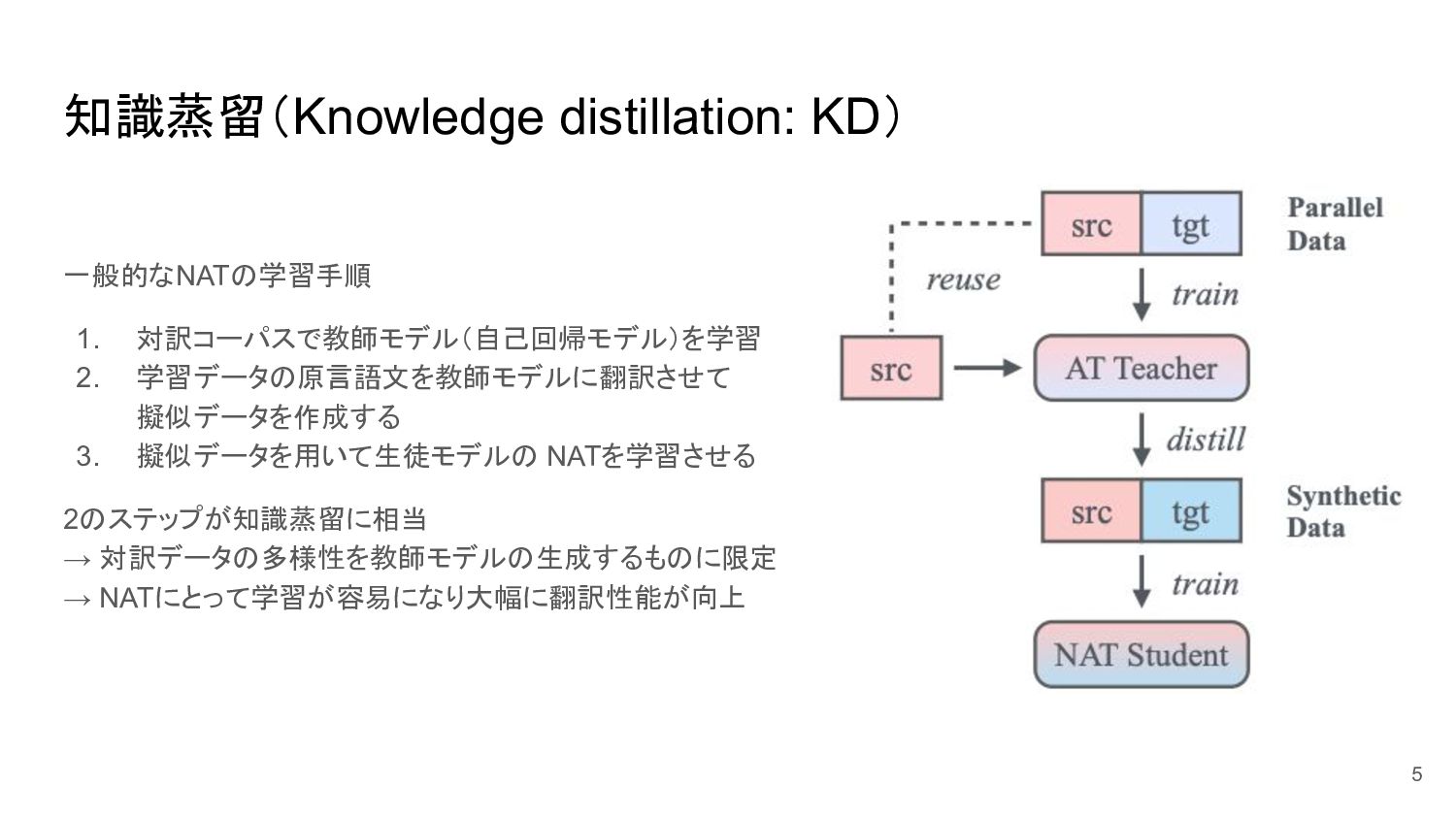
知識蒸留(Knowledge distillation: KD) 一般的なNATの学習手順 1. 対訳コーパスで教師モデル(自己回帰モデル)を学習 2. 学習データの原言語文を教師モデルに翻訳させて 擬似データを作成する 3.
擬似データを用いて生徒モデルの NATを学習させる 2のステップが知識蒸留に相当 → 対訳データの多様性を教師モデルの生成するものに限定 → NATにとって学習が容易になり大幅に翻訳性能が向上 5
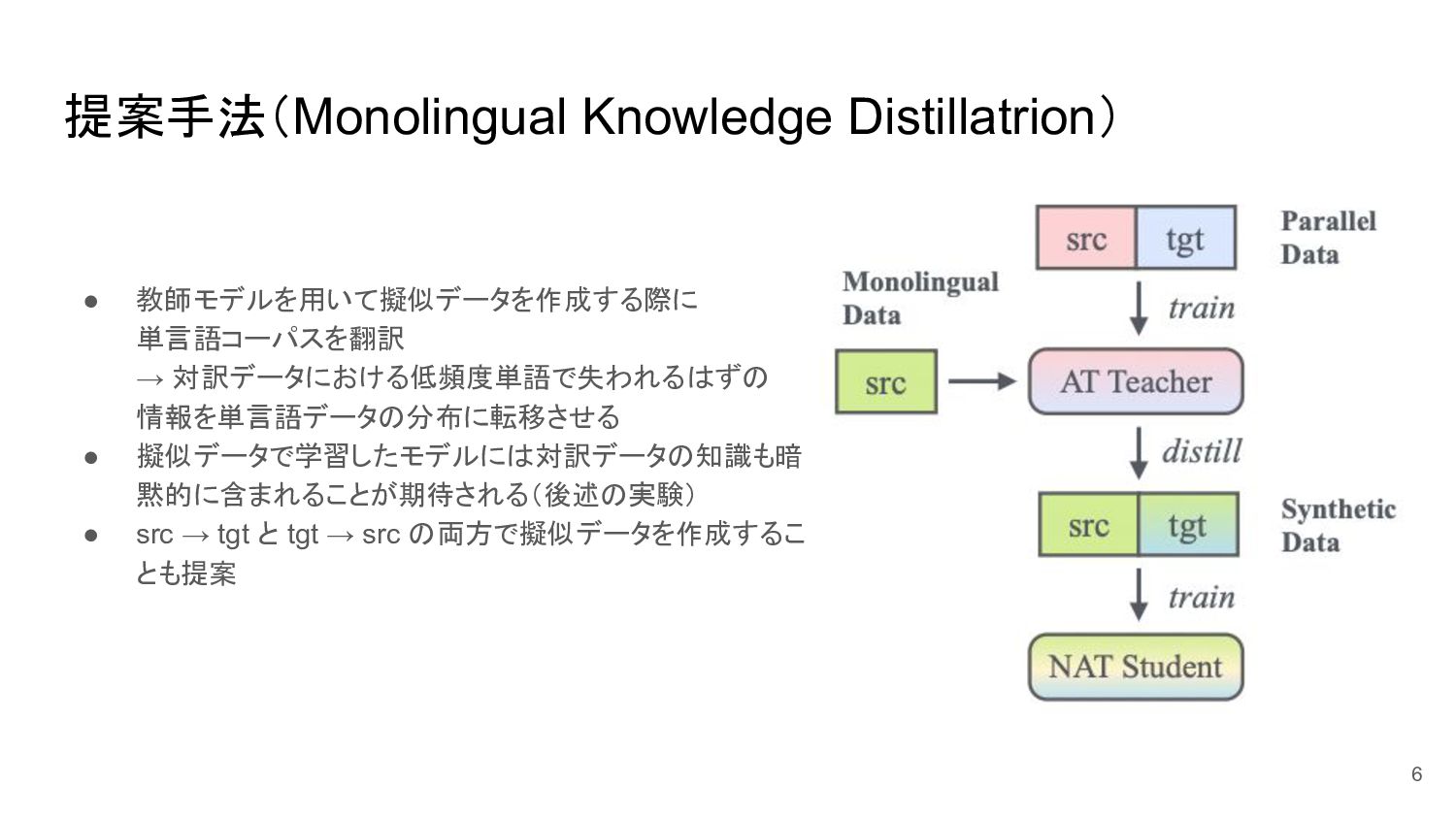
提案手法(Monolingual Knowledge Distillatrion) • 教師モデルを用いて擬似データを作成する際に 単言語コーパスを翻訳 → 対訳データにおける低頻度単語で失われるはずの 情報を単言語データの分布に転移させる •
擬似データで学習したモデルには対訳データの知識も暗 黙的に含まれることが期待される(後述の実験) • src → tgt と tgt → src の両方で擬似データを作成するこ とも提案 6
KDと低頻度語に関する分析 • Ding et al., 2021 に基づいて low-frequency word (LFW)
linkの分析 → src → tgt のアライメントは一意に近づく一方で tgt → src のアライメントが少なくなることを実証 → アライメントの質を測る指標 • 手法(学習データを分割している?) 1. fastalignで単語アライメントを作成し、 src側が低頻出語なものを抽出(辞書) 2. (元データから対訳文をサンプリングしてサブセットを作成(辞書の作成に利用しない?)) 3. 辞書の単語アライメントに関して 2のデータを用いて次の指標で評価 ▪ Recall : 低頻度語のうちどれだけ辞書に基づいたアライメントが張られているか ▪ Precision : 辞書の中のアライメントがどれだけ正しいか(人手評価) ▪ F1 : PrecisionとRecallの調和平均 7
KDと低頻度語に関する分析 8 • Monolingual KD の方が KD よりもアライメントの質が良い( F1) •
低頻度語における src → tgt のアライメントと tgt → src のアライメントに関して、 forward と backward で補完的である → 両方向で蒸留データを作成することで、低頻度語におけるアライメントが双方向で改善される → 単語アライメント的な観点からも両方の単言語コーパスを使うのが良さそう
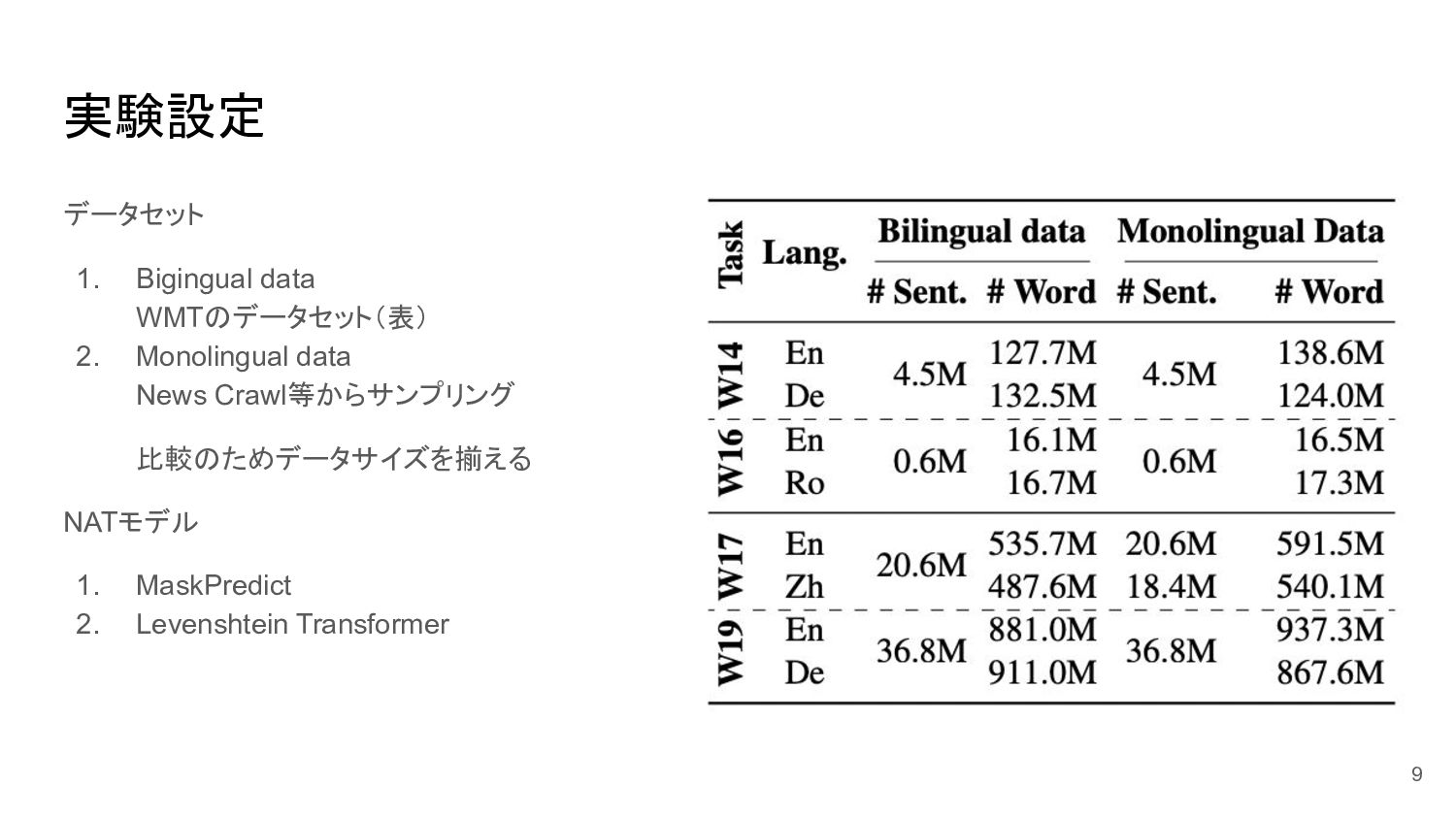
実験設定 データセット 1. Bigingual data WMTのデータセット(表) 2. Monolingual data News
Crawl等からサンプリング 比較のためデータサイズを揃える NATモデル 1. MaskPredict 2. Levenshtein Transformer 9
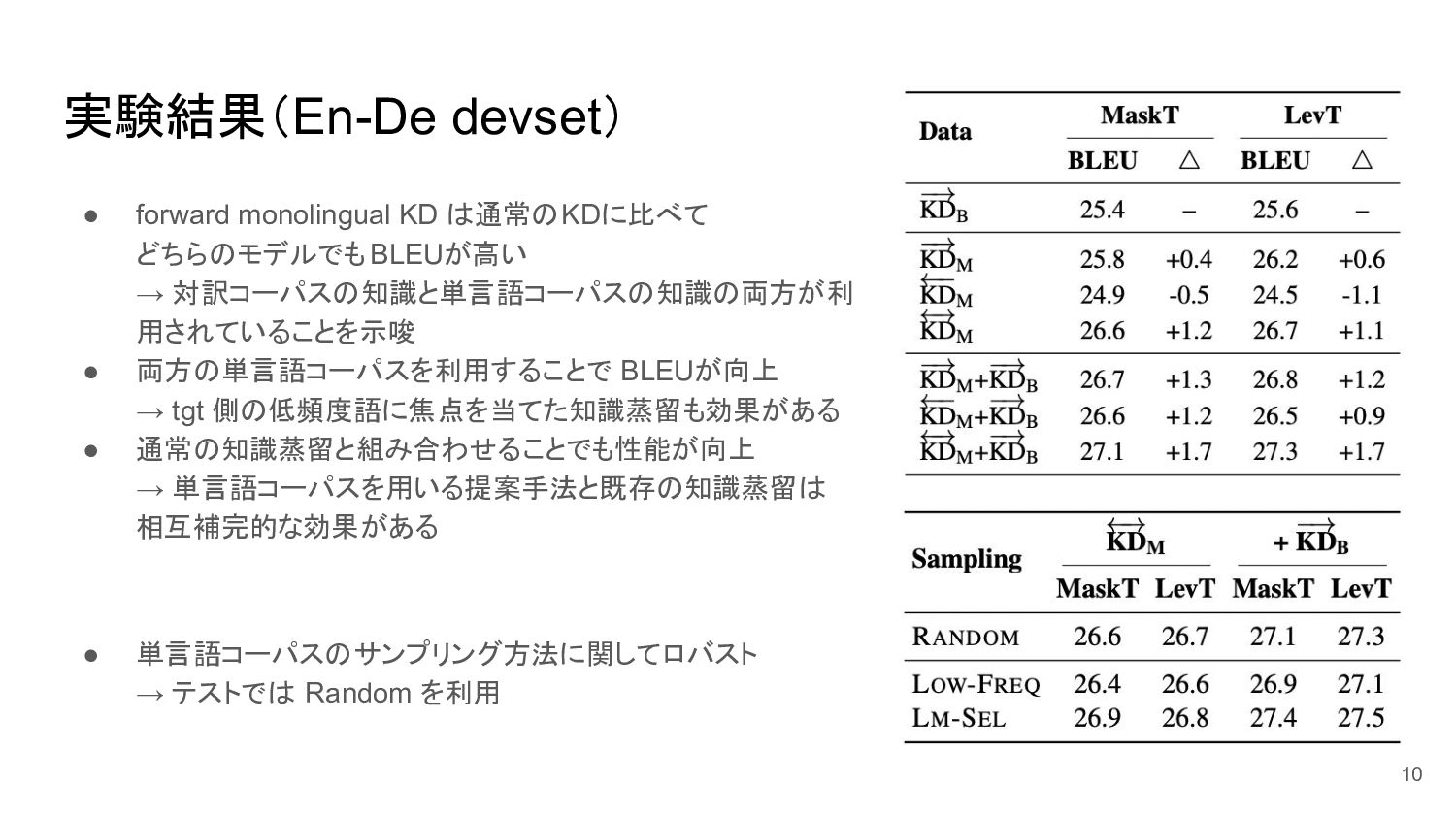
実験結果(En-De devset) • forward monolingual KD は通常のKDに比べて どちらのモデルでもBLEUが高い → 対訳コーパスの知識と単言語コーパスの知識の両方が利
用されていることを示唆 • 両方の単言語コーパスを利用することで BLEUが向上 → tgt 側の低頻度語に焦点を当てた知識蒸留も効果がある • 通常の知識蒸留と組み合わせることでも性能が向上 → 単言語コーパスを用いる提案手法と既存の知識蒸留は 相互補完的な効果がある • 単言語コーパスのサンプリング方法に関してロバスト → テストでは Random を利用 10
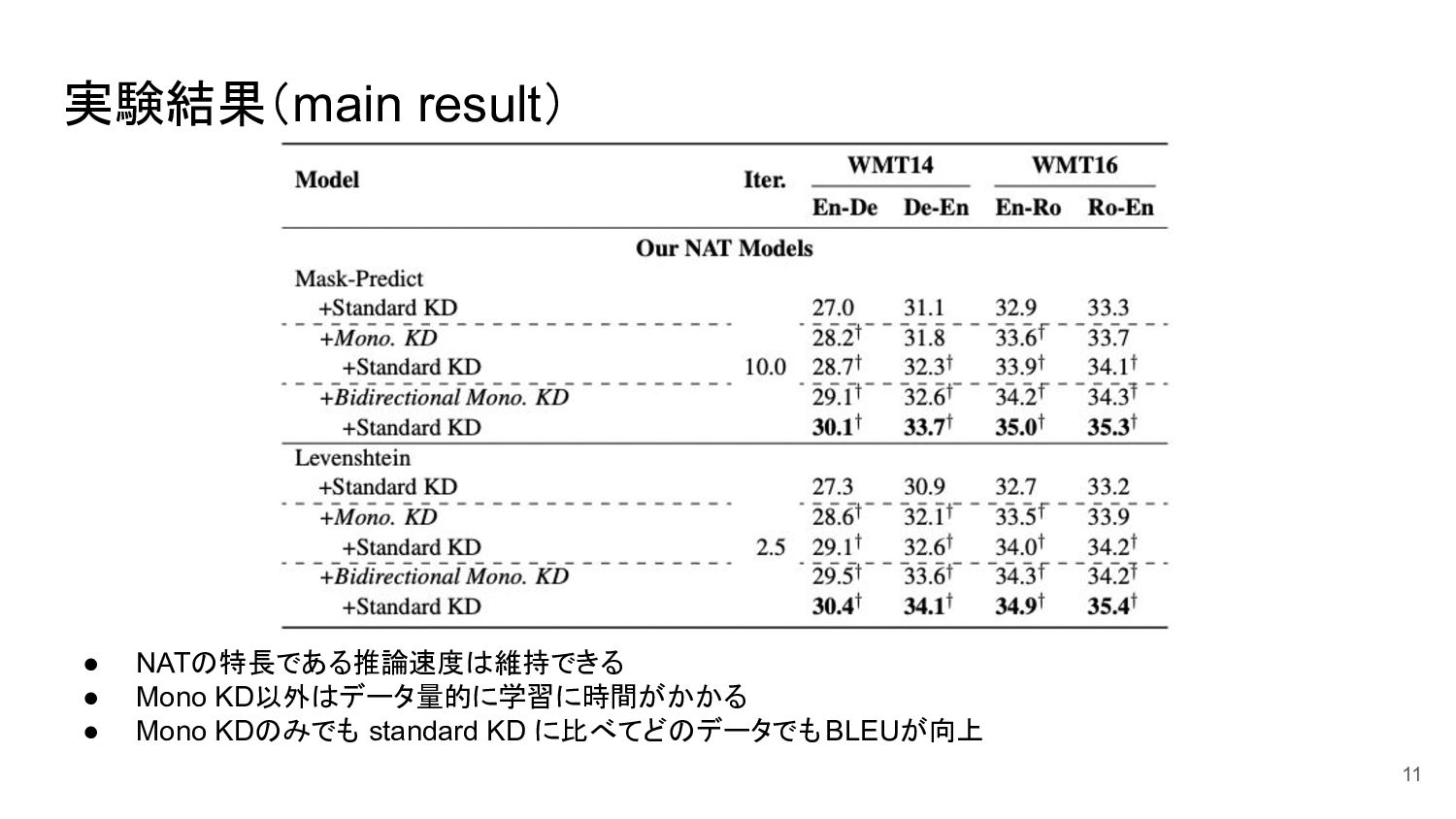
実験結果(main result) 11 • NATの特長である推論速度は維持できる • Mono KD以外はデータ量的に学習に時間がかかる • Mono
KDのみでも standard KD に比べてどのデータでも BLEUが向上
実験結果(main result) 12 • データサイズを大きくした時( WMT17, WMT19) • データ拡張に近い手法ではあるが、 低資源の設定ではなくても提案手法の効果が見られた
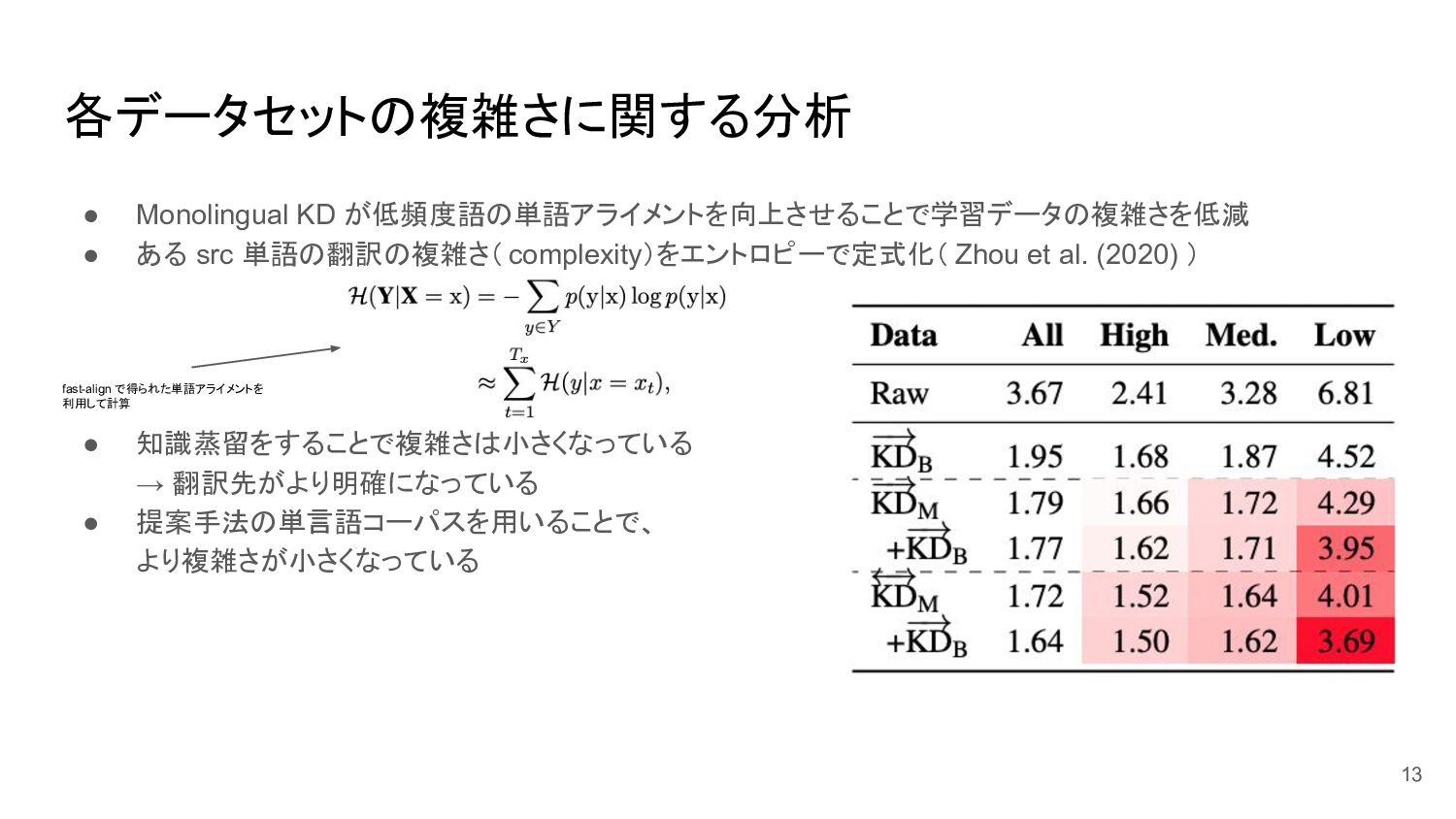
各データセットの複雑さに関する分析 • Monolingual KD が低頻度語の単語アライメントを向上させることで学習データの複雑さを低減 • ある src 単語の翻訳の複雑さ( complexity)をエントロピーで定式化(
Zhou et al. (2020) ) • 知識蒸留をすることで複雑さは小さくなっている → 翻訳先がより明確になっている • 提案手法の単言語コーパスを用いることで、 より複雑さが小さくなっている 13 fast-align で得られた単語アライメントを 利用して計算
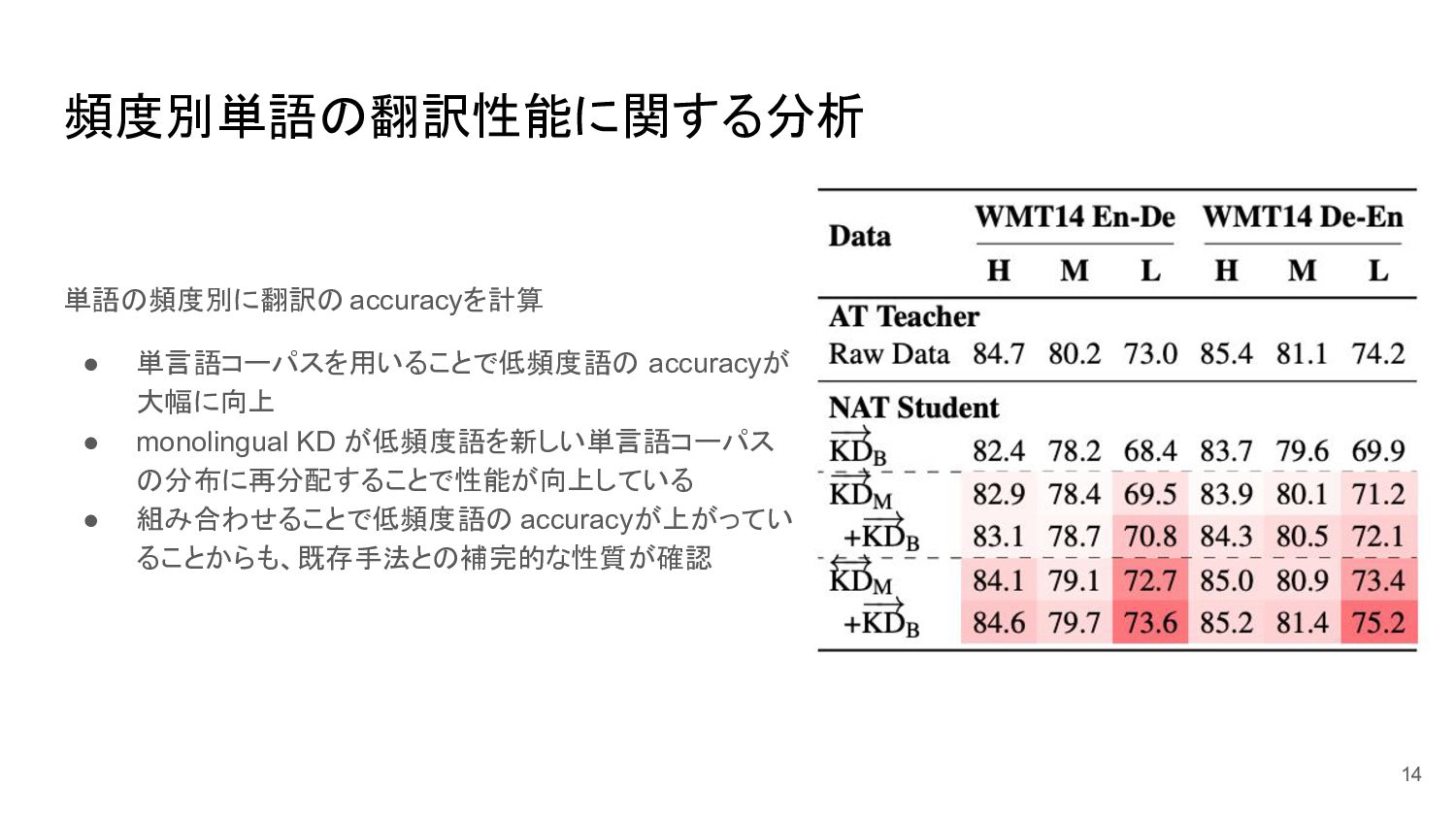
頻度別単語の翻訳性能に関する分析 単語の頻度別に翻訳の accuracyを計算 • 単言語コーパスを用いることで低頻度語の accuracyが 大幅に向上 • monolingual KD
が低頻度語を新しい単言語コーパス の分布に再分配することで性能が向上している • 組み合わせることで低頻度語の accuracyが上がってい ることからも、既存手法との補完的な性質が確認 14
単言語コーパスの活用 • データの規模 15 • 教師モデルの学習 • 5× まではスコアが向上 •
10× で減少に転じたのはモデルの容量が原因? • 単言語コーパスによる教師モデルの強化は効果なし • KDによるATからNATへの情報伝達のロスに起因
結論 • 対訳データに含まれる低頻度語の分布を外部の単言語データを用いて再分配する、シンプルで効果的 かつスケーラブルなアプローチである monolingual KD を提案 • monolingual KD
の活用方法 1. 逆方向の monolingual KD と組み合わせることで低頻度のターゲット単語をより多く生成可能 2. 既存の KD と組み合わせることで両コーパスの知識を明示的に補完する 3. 低コストで入手できる単言語データを拡大する 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}