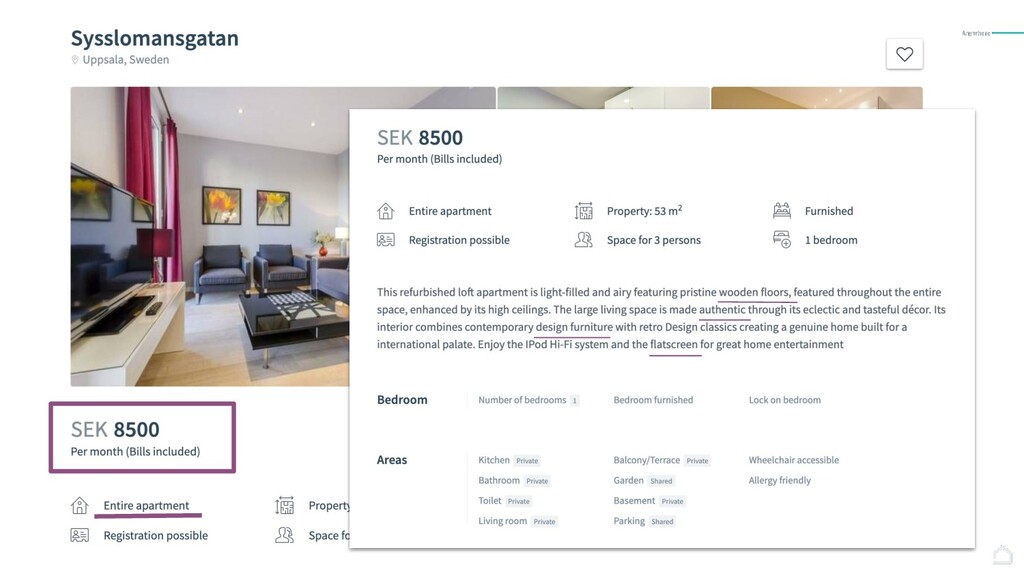
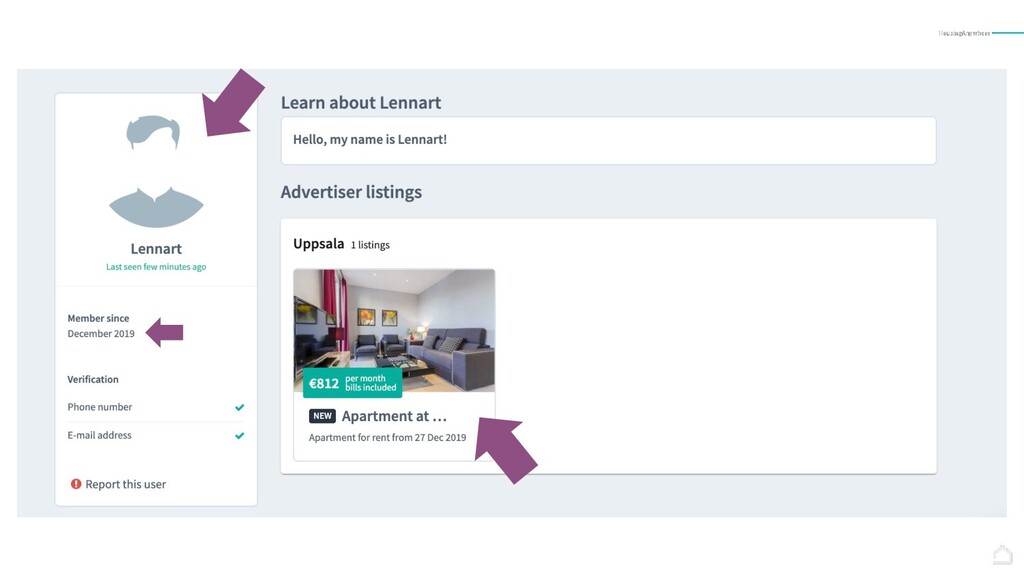
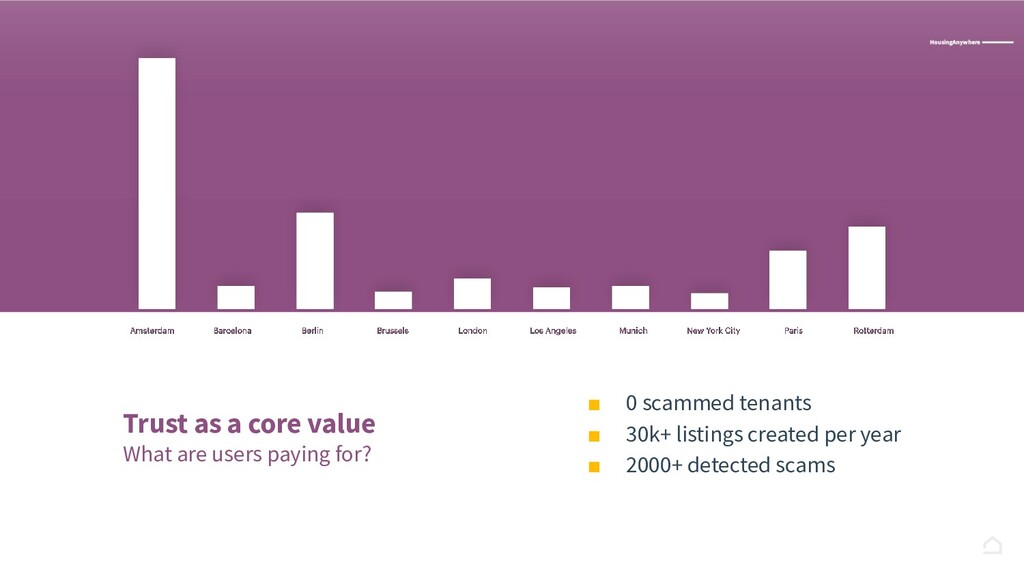
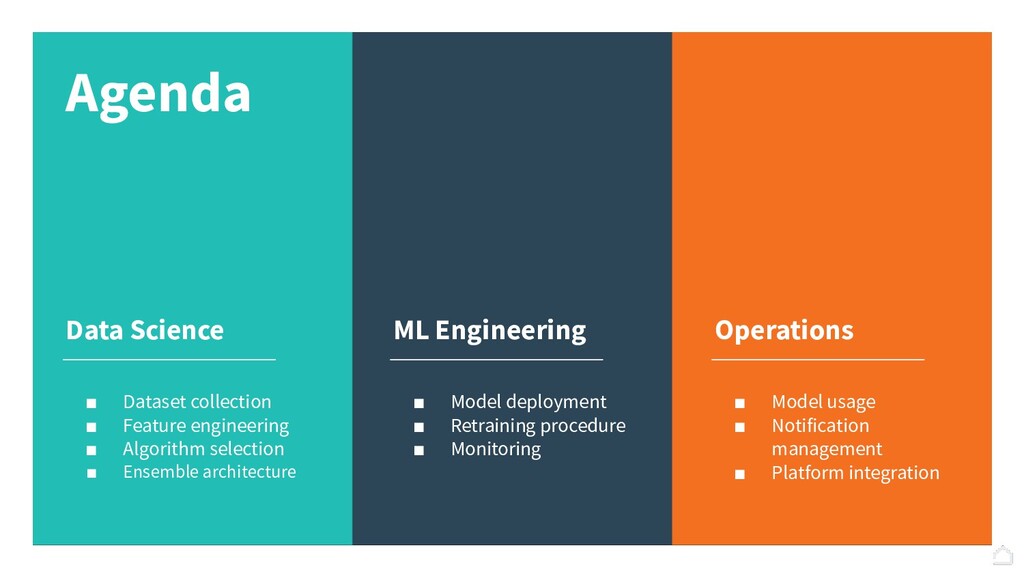
A one year journey to develop Penelope, a Machine Learning product able to keep HousingAnywhere scammers-free: challenges, intuitions and discoveries. HousingAnywhere is an accommodation marketplace with listings in 400+ cities around the world where advertisers publish hundreds of listings everyday. How we moved from a rule-based engine to a semi-automated process powered by Machine Learning.
![Detecting Scams Using AI [for real] How we built one](https://files.speakerdeck.com/presentations/281f4f453be845be94257bb808bbafa1/slide_0.jpg){kind=link}
![Massimo Belloni Data Scientist / Machine Learning Engineer [email protected] @massibelloni](https://files.speakerdeck.com/presentations/281f4f453be845be94257bb808bbafa1/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
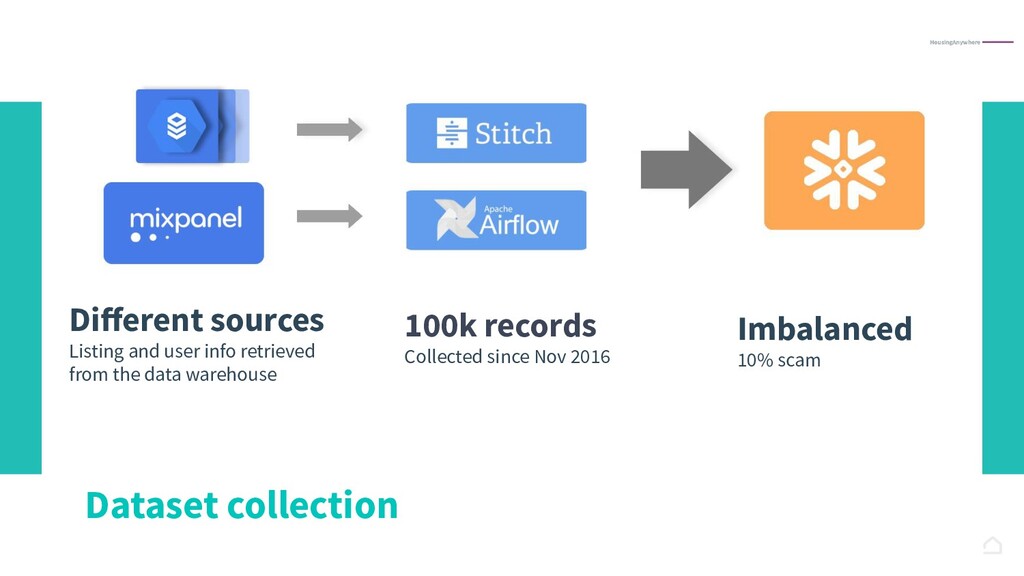{kind=link}
{kind=link}
{kind=link}
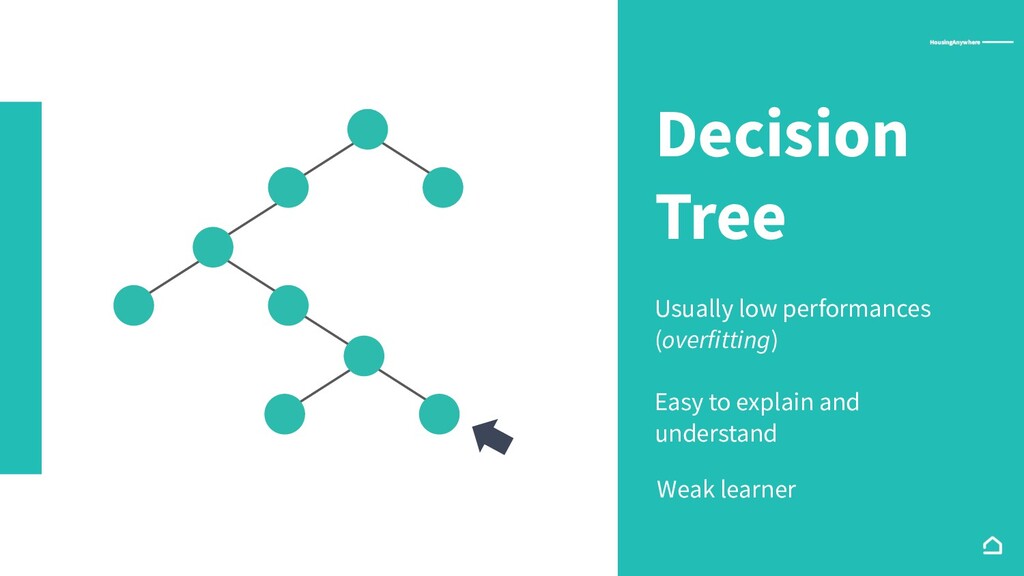{kind=link}
{kind=link}
{kind=link}
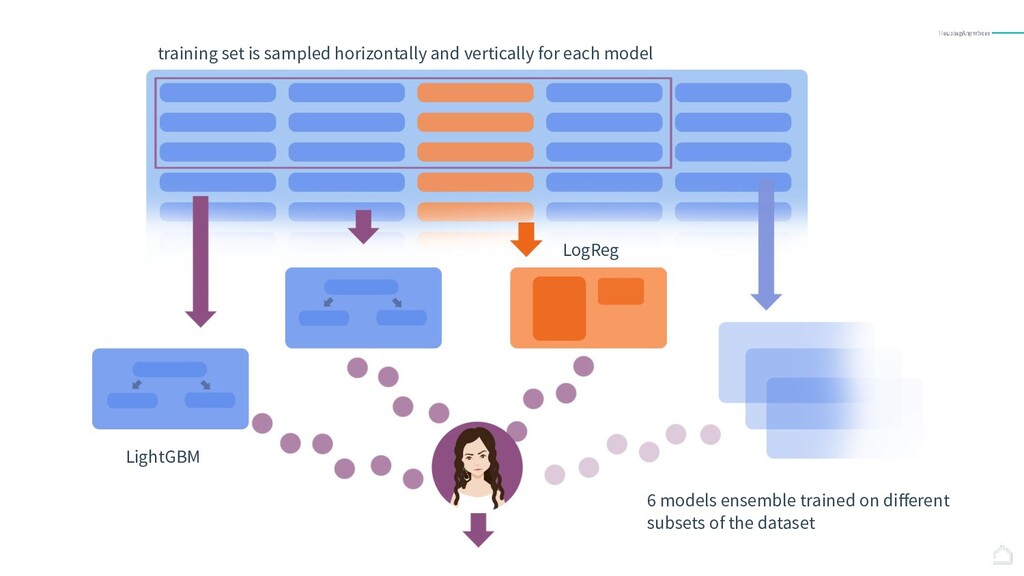{kind=link}
{kind=link}
{kind=link}
{kind=link}
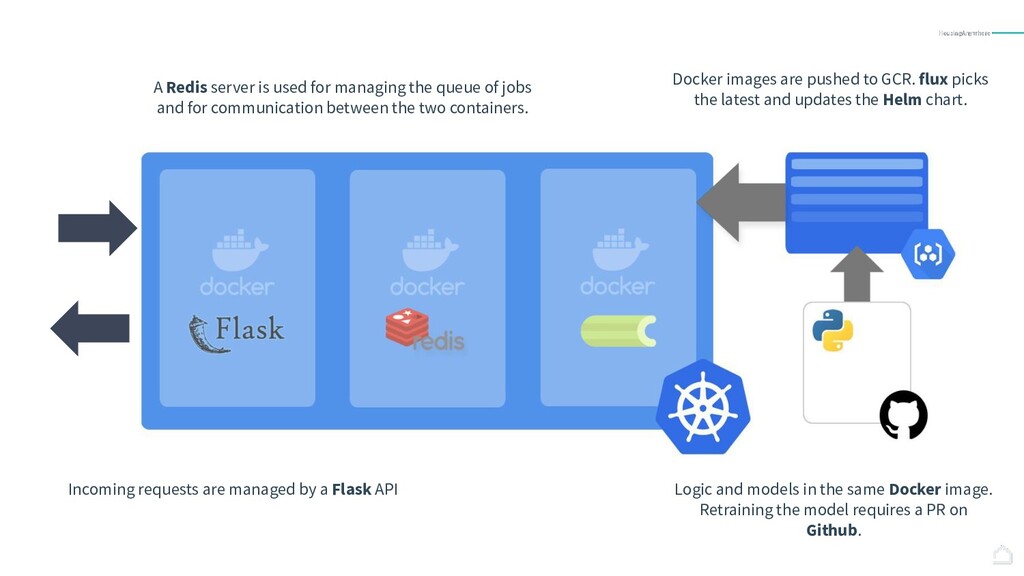{kind=link}
{kind=link}
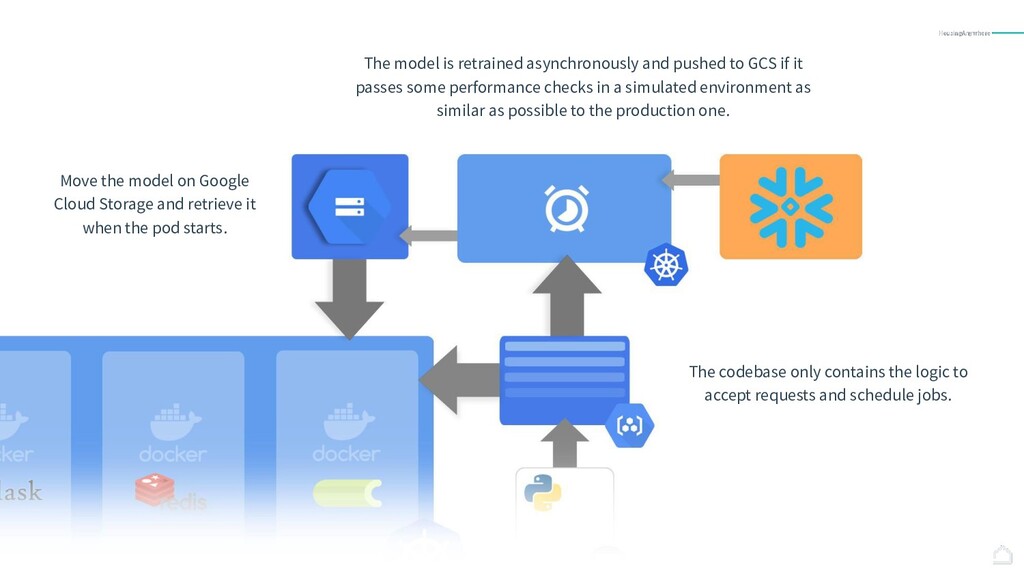{kind=link}
{kind=link}
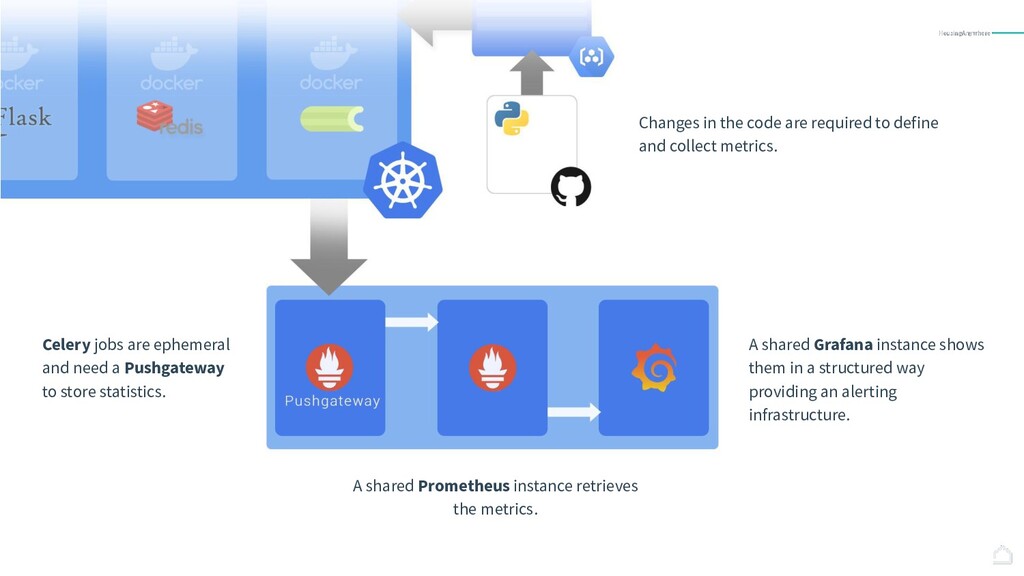{kind=link}
{kind=link}
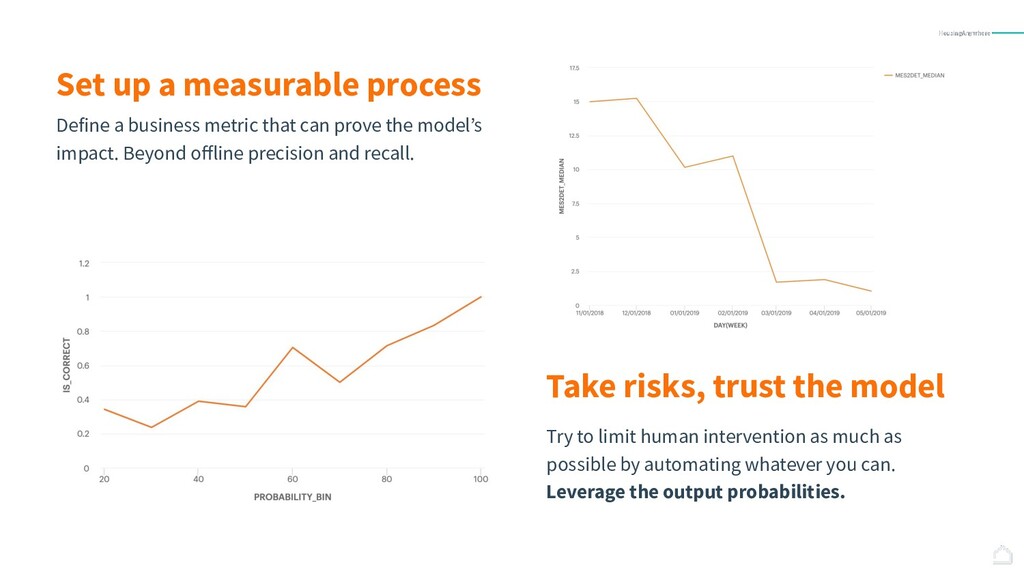{kind=link}
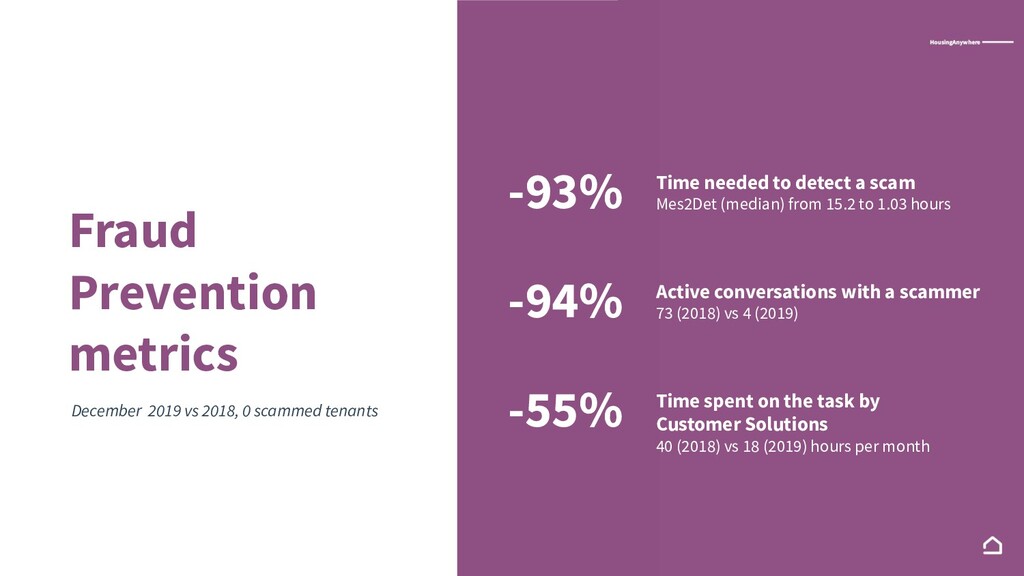{kind=link}
{kind=link}
{kind=link}