Java API to locally access data from Wiktionary, a collaboratively-edited, free dictionary. Specific target is the French Wiktionary.
End of studies project at Polytech'Nice-Sophia engineering school.
https://github.com/MattiSG/SemWiktionary
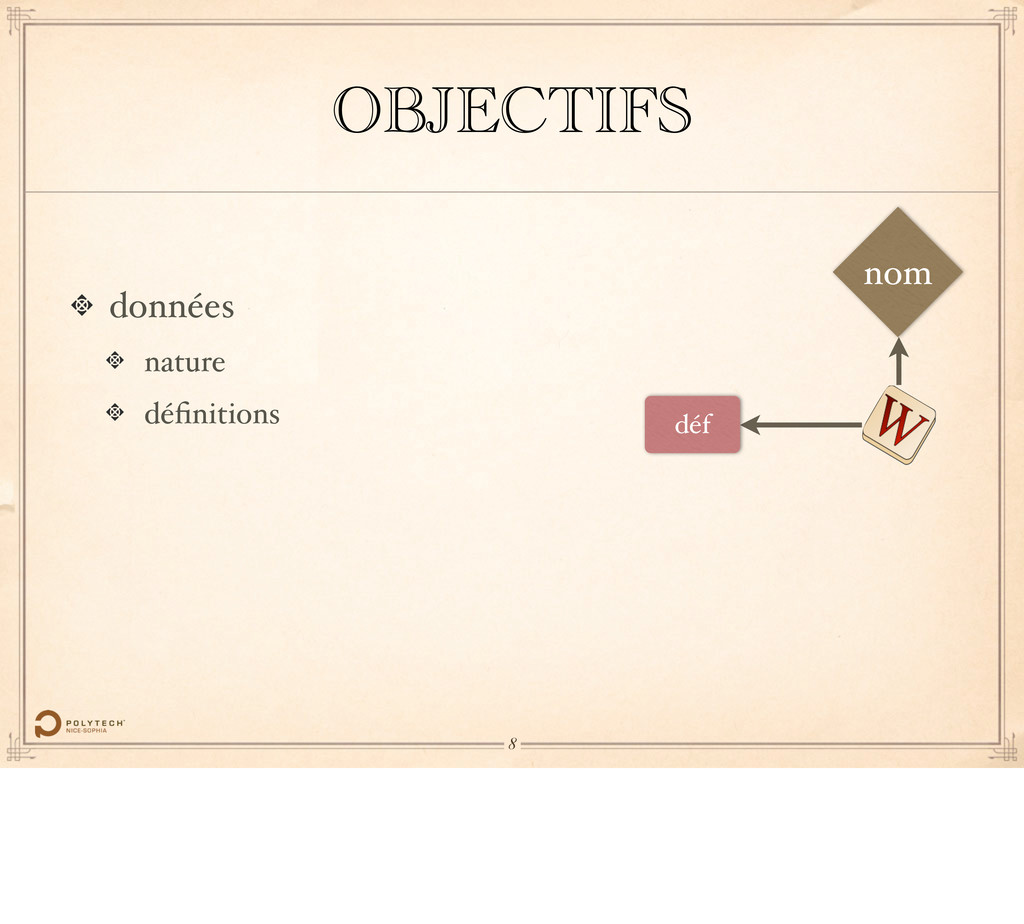
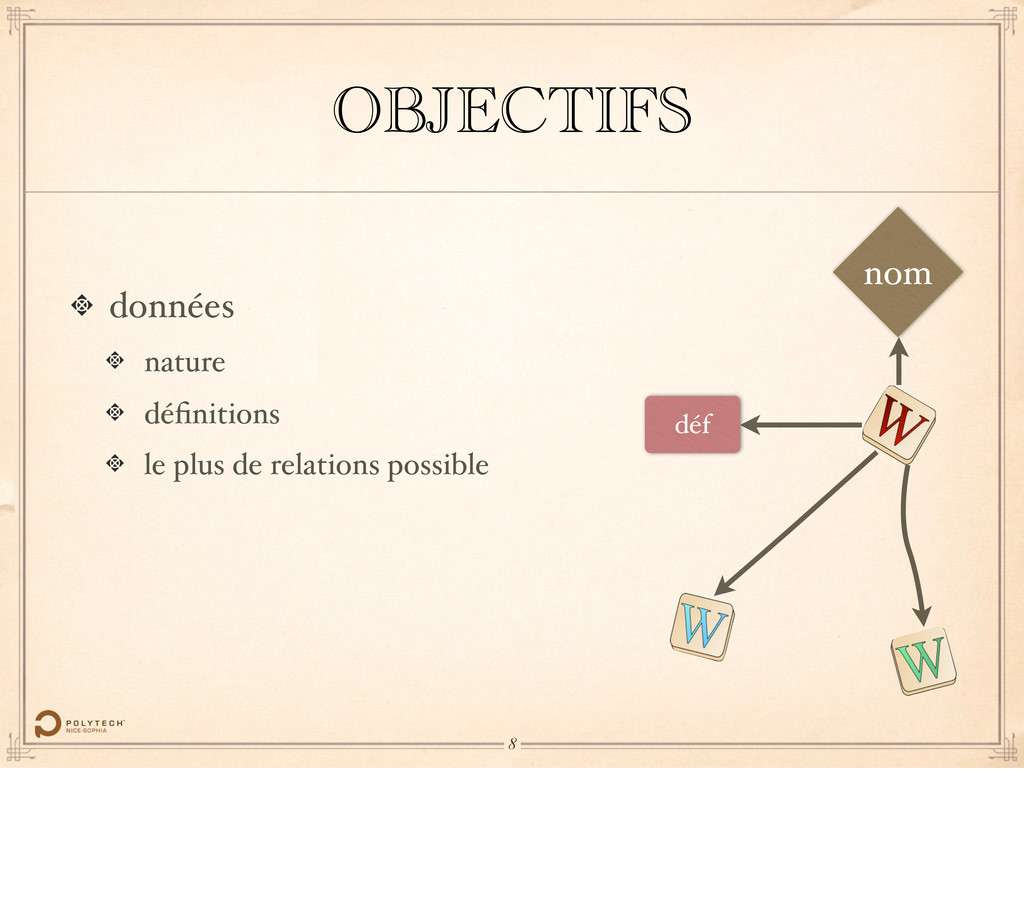
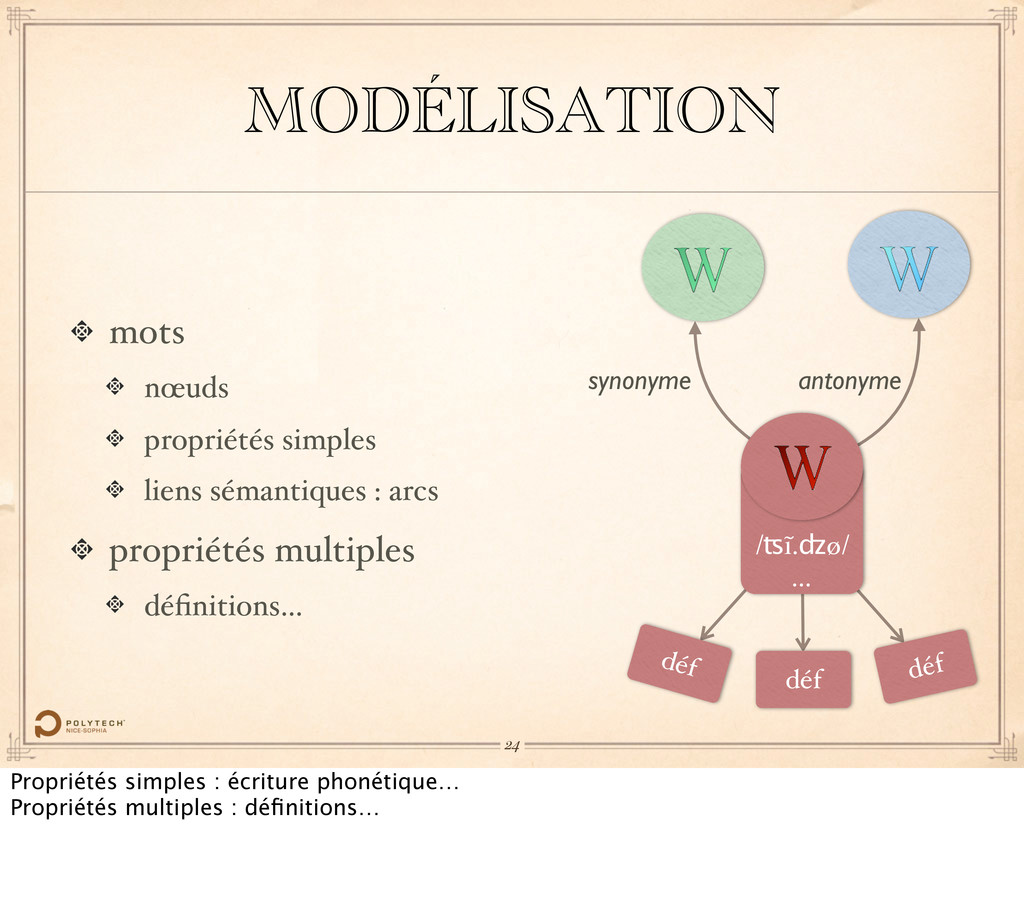
Le Wiktionary est un dictionnaire opéré par la Wikimedia Foundation, l’association responsable de Wikipédia. Chaque mot fait l’objet d’un article, d’une page sur le site.
prononciation ou langue… …mais également des relations sémantiques entre les mots, classiques comme la synonymie et l’antonimie, mais également plus avancées, telles que la méronymie, l’holonymie…
telles que prononciation ou langue… …mais également des relations sémantiques entre les mots, classiques comme la synonymie et l’antonimie, mais également plus avancées, telles que la méronymie, l’holonymie…
contient des données linéaires, telles que prononciation ou langue… …mais également des relations sémantiques entre les mots, classiques comme la synonymie et l’antonimie, mais également plus avancées, telles que la méronymie, l’holonymie…
données NoSQL plutôt que les technologies du web sémantique. NoSQL : Not Only SQL. Neo4j nous a été suggéré par notre encadrant et, après analyse des différentes possibilités, il s’agissait effectivement de la solution la plus pertinente (NoSQL + Java + format de données adapté aux graphes).
de données NoSQL plutôt que les technologies du web sémantique. NoSQL : Not Only SQL. Neo4j nous a été suggéré par notre encadrant et, après analyse des différentes possibilités, il s’agissait effectivement de la solution la plus pertinente (NoSQL + Java + format de données adapté aux graphes).
demandé d’utiliser une base de données NoSQL plutôt que les technologies du web sémantique. NoSQL : Not Only SQL. Neo4j nous a été suggéré par notre encadrant et, après analyse des différentes possibilités, il s’agissait effectivement de la solution la plus pertinente (NoSQL + Java + format de données adapté aux graphes).
nous a demandé d’utiliser une base de données NoSQL plutôt que les technologies du web sémantique. NoSQL : Not Only SQL. Neo4j nous a été suggéré par notre encadrant et, après analyse des différentes possibilités, il s’agissait effectivement de la solution la plus pertinente (NoSQL + Java + format de données adapté aux graphes).
On nous a demandé d’utiliser une base de données NoSQL plutôt que les technologies du web sémantique. NoSQL : Not Only SQL. Neo4j nous a été suggéré par notre encadrant et, après analyse des différentes possibilités, il s’agissait effectivement de la solution la plus pertinente (NoSQL + Java + format de données adapté aux graphes).
généré tous les mois 1,8 Go ; 58+ millions de lignes 2 000 000+ mots < m e d i a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> 7 Wiktionnaire français => descriptions françaises, mais de mots internationaux Fichier de novembre 2011 : - 58 324 698 lignes - 2 124 047 mots
partir d’une idée intégré à OpenOffice …dictionnaire des synonymes objectif : faciliter la recherche 10 Prenons pour commencer un des sens qu’offre le Wiktionnaire à ce terme. Il est dit qu’il s’agit d’un vocabulaire normalisé sur la base de termes génériques et de termes spécifiques à un domaine. On peut également le définir de la manière suivante : un thésaurus est d'abord un ouvrage pratique. C'est un dictionnaire d’analogies généralisé qui permet de trouver un mot juste à partir d'une idée.
des programmes politiques 13 SemPol : permettre la recherche de thèmes dans les programmes des candidats à l’élection présidentielle en utilisant le vocabulaire apparenté à la requête de l’utilisateur.
dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> La source analysée par le parser était le dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
d i a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> La source analysée par le parser était le dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
textuel seul 17 < m e d i a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> La source analysée par le parser était le dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
textuel seul JFlex 17 < m e d i a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> La source analysée par le parser était le dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
textuel seul JFlex lexer pour Java syntaxe Lex / Bison 17 < m e d i a w i k i x m l n s = " h t t p : / / www.mediawiki.org/xml/export-0.5/" xmlns:xsi="http://www.w3.org/2001/ X M L S c h e m a - i n s t a n c e " xsi:sc hemaLocation="http:// www.mediawiki.org/xml/export-0.5/ http://www.mediawiki.org/xml/ export-0.5.xsd" version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</sitename> <base>http://fr.wiktionary.org/wiki/ Wiktionnaire:Page_d%E2%80%99accueil</base> <generator>MediaWiki 1.18wmf1</generator> <case>case-sensitive</case> <namespaces> <namespace key="-2" case="case- sensitive">Média</namespace> <namespace key="-1" case="first- letter">Spécial</namespace> <namespace key="0" case="case-sensitive" /> <namespace key="1" case="case- sensitive">Discussion</namespace> <namespace key="2" case="first- letter">Utilisateur</namespace> <namespace key="3" case="first-/namespace> La source analysée par le parser était le dumpfile Wiktionary. Nous avons recherché des analyseurs existant. Malheureusement, ils étaient soit spécialisés pour Wikipédia, comme par exemple Xwiki ou WikiModel, soit ils ne faisaient que transformer le formatage Mediawiki en HTML, ce qui n’était pas utile pour nous.
phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
’’’ ’’’ ’’’ ? Normalement, le processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
des internautes 18 Lexical ’’’ ’’’ ’’’ ? # Normalement, le processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
des internautes 18 Lexical ’’’ ’’’ ’’’ ? * : # - Normalement, le processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
des internautes parser officiel multi-passes performance ? 18 Lexical ’’’ ’’’ ’’’ ? * : # - Normalement, le processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
des internautes parser officiel multi-passes performance ? une seule passe ! 18 Lexical ’’’ ’’’ ’’’ ? * : # - Normalement, le processus de compilation s’effectue en trois phases : Phase lexicale : transformation de groupes de caractères en jetons. Phase syntaxique : vérification de la validité des groupes de jetons. Phase sémantique : actions en fonction des groupes de jetons valides. Mais ici, la grammaire est ambigu. Par exemple, on ne peut pas distinguer le gras de
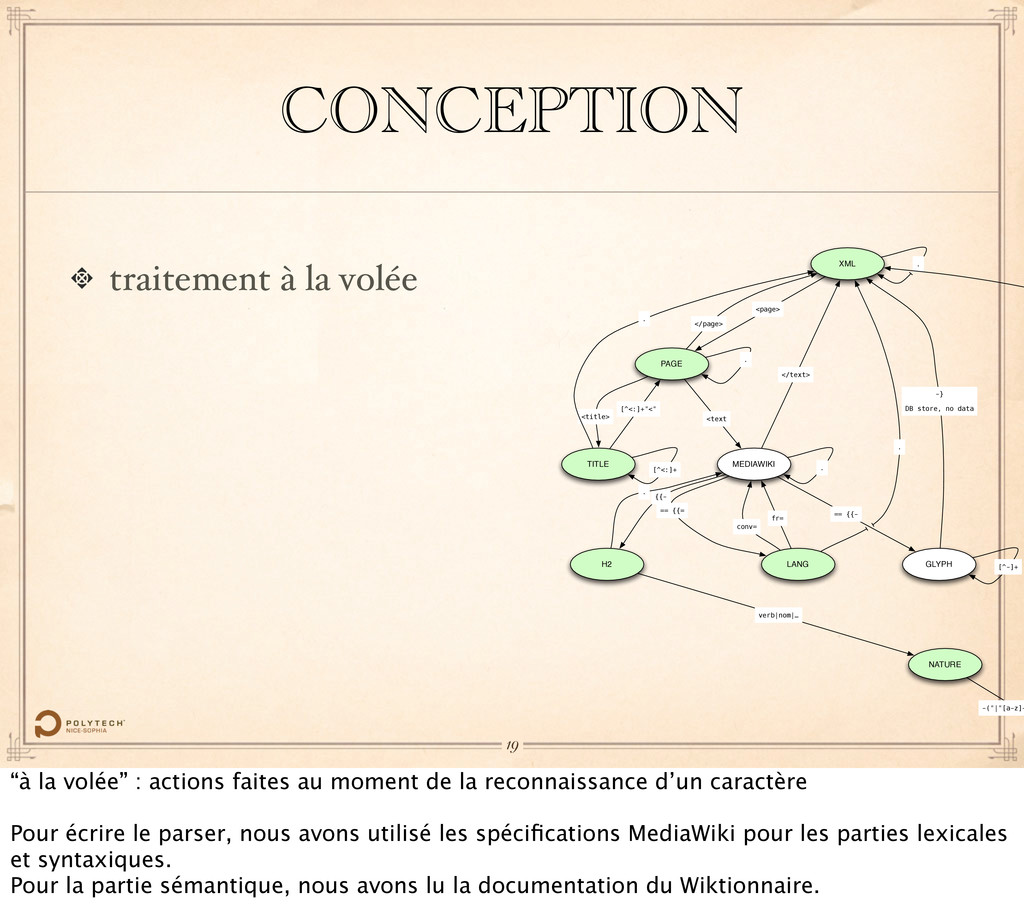
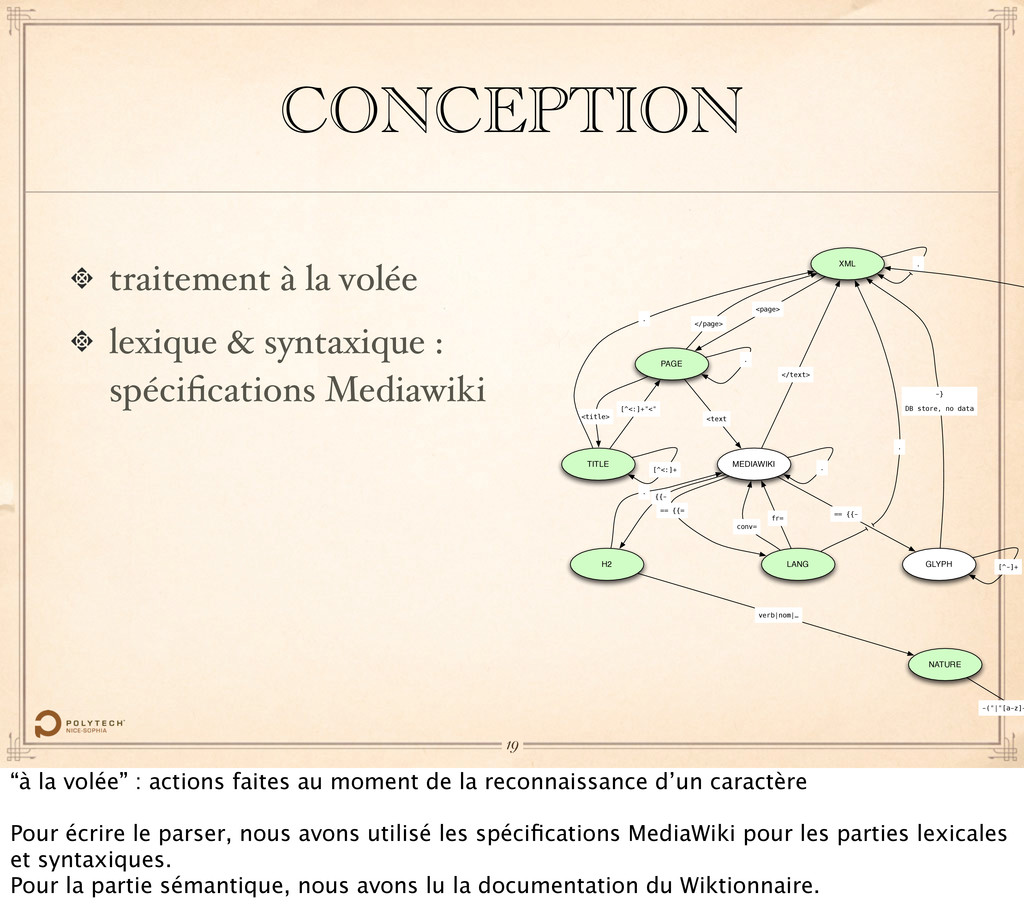
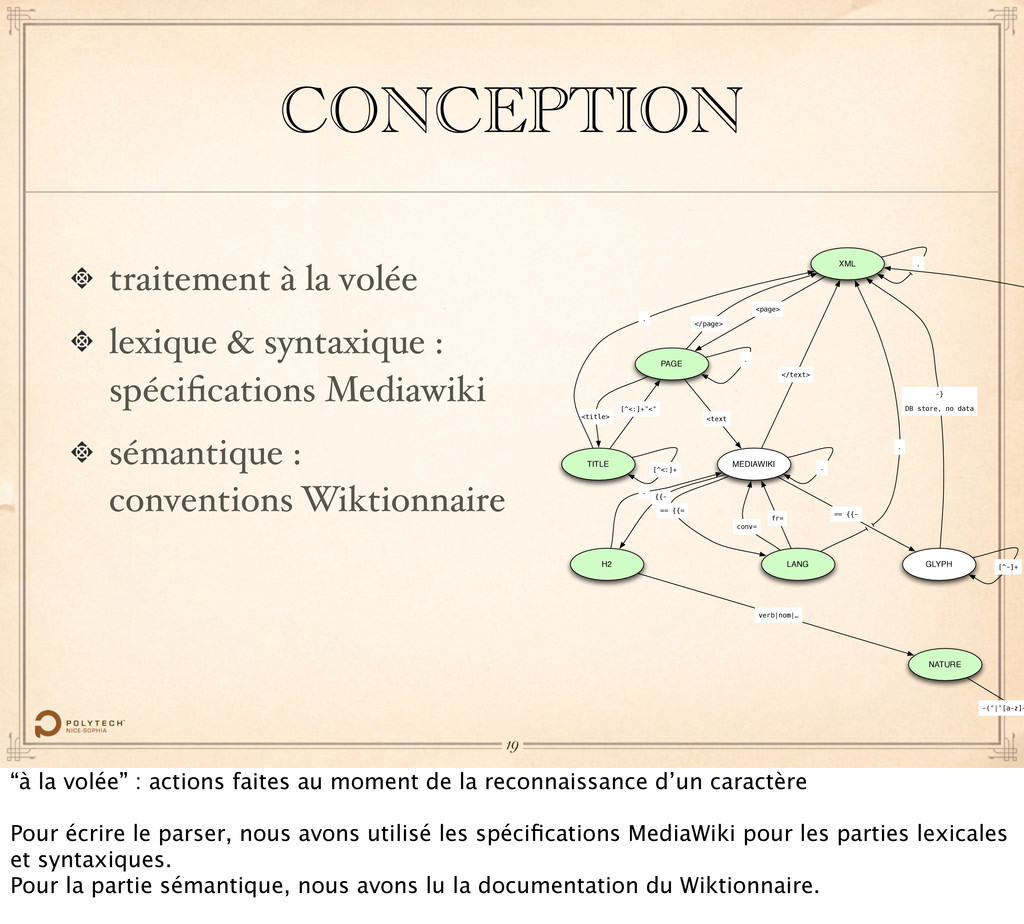
de la reconnaissance d’un caractère Pour écrire le parser, nous avons utilisé les spécifications MediaWiki pour les parties lexicales et syntaxiques. Pour la partie sémantique, nous avons lu la documentation du Wiktionnaire.
H2 NATURE <page> </page> <title> [^<:]+"<" <text [^<:]+ . == {{= fr= {{- verb|nom|… -("|"[a-z]+ . GLYPH [^-]+ == {{- -} DB store, no data . . conv= . . </text> 19 “à la volée” : actions faites au moment de la reconnaissance d’un caractère Pour écrire le parser, nous avons utilisé les spécifications MediaWiki pour les parties lexicales et syntaxiques. Pour la partie sémantique, nous avons lu la documentation du Wiktionnaire.
Mediawiki XML PAGE TITLE MEDIAWIKI LANG H2 NATURE <page> </page> <title> [^<:]+"<" <text [^<:]+ . == {{= fr= {{- verb|nom|… -("|"[a-z]+ . GLYPH [^-]+ == {{- -} DB store, no data . . conv= . . </text> 19 “à la volée” : actions faites au moment de la reconnaissance d’un caractère Pour écrire le parser, nous avons utilisé les spécifications MediaWiki pour les parties lexicales et syntaxiques. Pour la partie sémantique, nous avons lu la documentation du Wiktionnaire.
Mediawiki sémantique : conventions Wiktionnaire XML PAGE TITLE MEDIAWIKI LANG H2 NATURE <page> </page> <title> [^<:]+"<" <text [^<:]+ . == {{= fr= {{- verb|nom|… -("|"[a-z]+ . GLYPH [^-]+ == {{- -} DB store, no data . . conv= . . </text> 19 “à la volée” : actions faites au moment de la reconnaissance d’un caractère Pour écrire le parser, nous avons utilisé les spécifications MediaWiki pour les parties lexicales et syntaxiques. Pour la partie sémantique, nous avons lu la documentation du Wiktionnaire.
Mediawiki sémantique : conventions Wiktionnaire heuristiques de résilience listes mal formées, délimiteurs mal placés… XML PAGE TITLE MEDIAWIKI LANG H2 NATURE <page> </page> <title> [^<:]+"<" <text [^<:]+ . == {{= fr= {{- verb|nom|… -("|"[a-z]+ . GLYPH [^-]+ == {{- -} DB store, no data . . conv= . . </text> 19 “à la volée” : actions faites au moment de la reconnaissance d’un caractère Pour écrire le parser, nous avons utilisé les spécifications MediaWiki pour les parties lexicales et syntaxiques. Pour la partie sémantique, nous avons lu la documentation du Wiktionnaire.
24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
prenait plus que la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
dur 20 Notre parser prenait plus que la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
dur profiler base de données 20 Notre parser prenait plus que la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
dur profiler base de données revue de code optimisation des transactions 20 Notre parser prenait plus que la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
prenait plus que la limite de 24h. Nous avons donc cherché le point limitant pour améliorer les performances. Statistiques système : analyse des ressources utilisées par le parser. Le processeur n’était utilisé qu’à 40%, RAM stable, mais disque dur très sollicité.
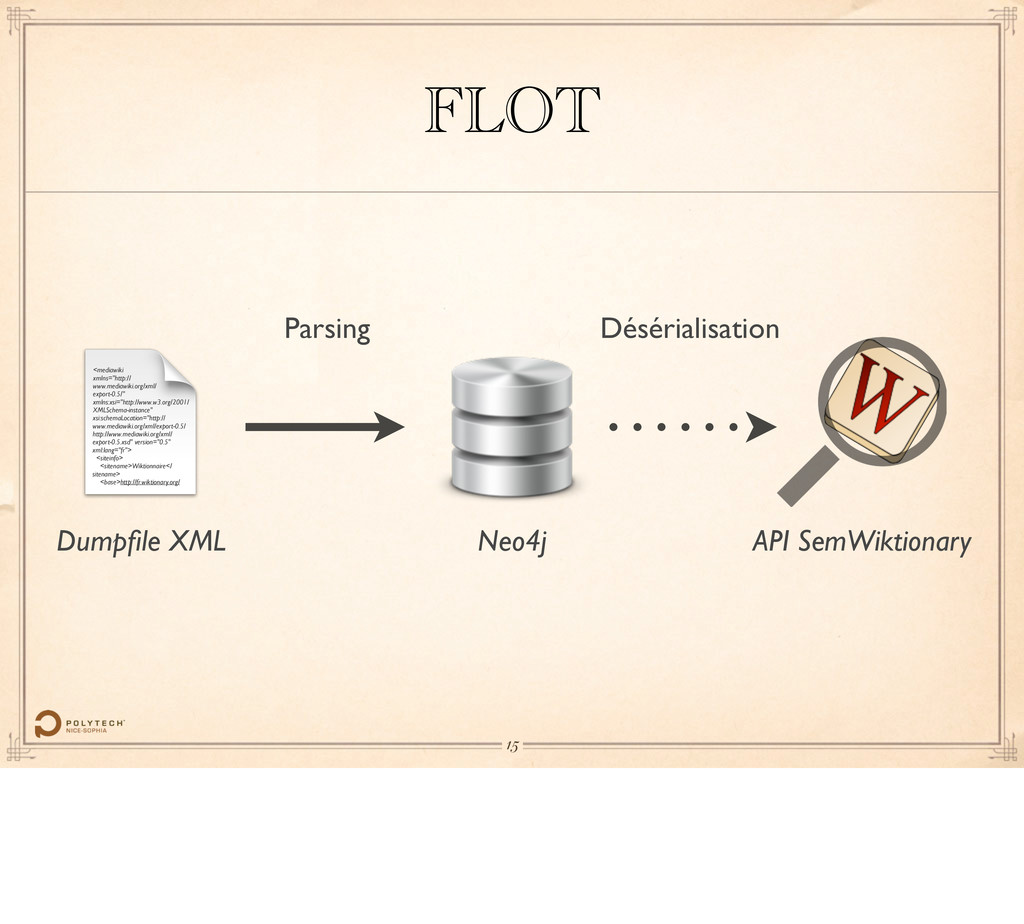
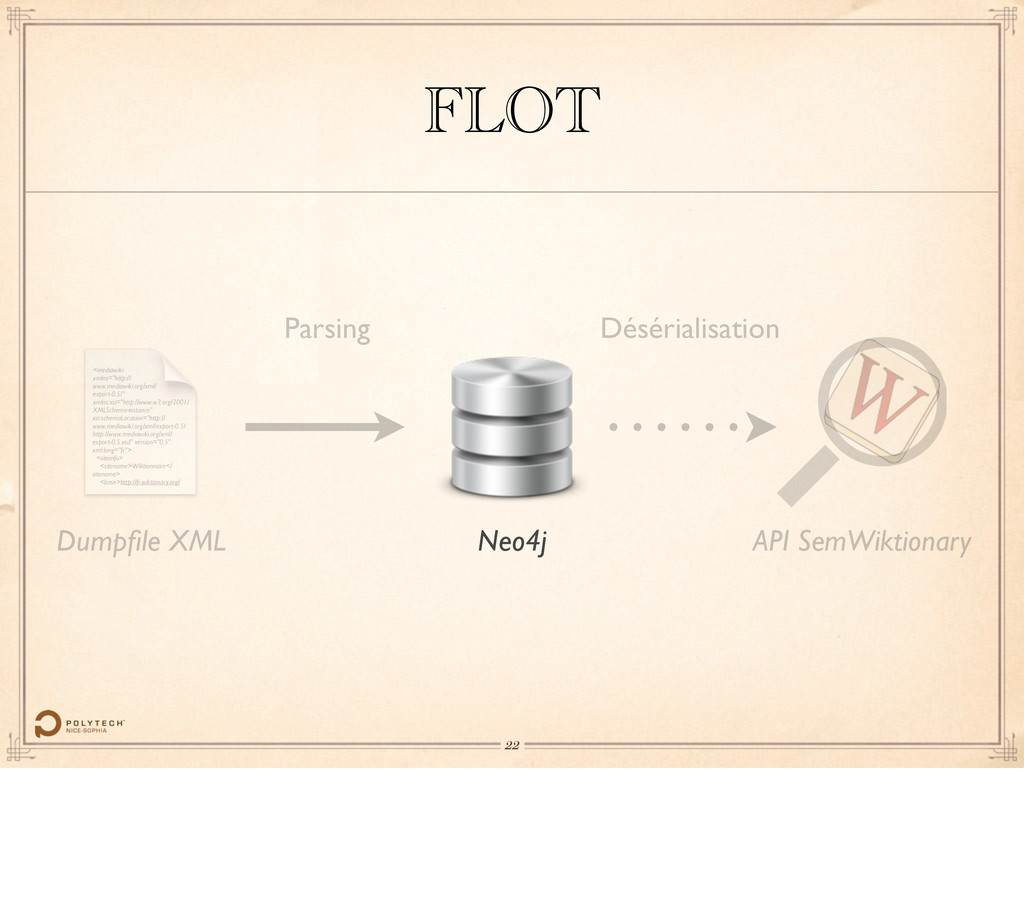
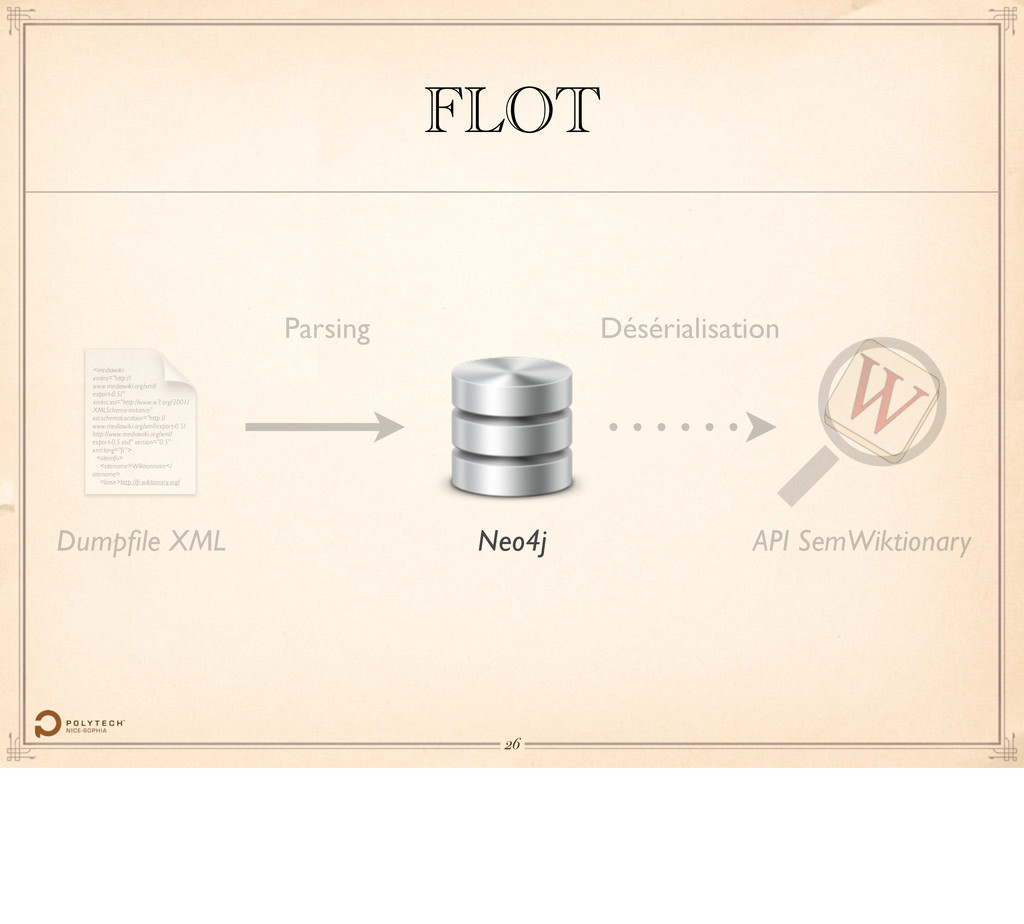
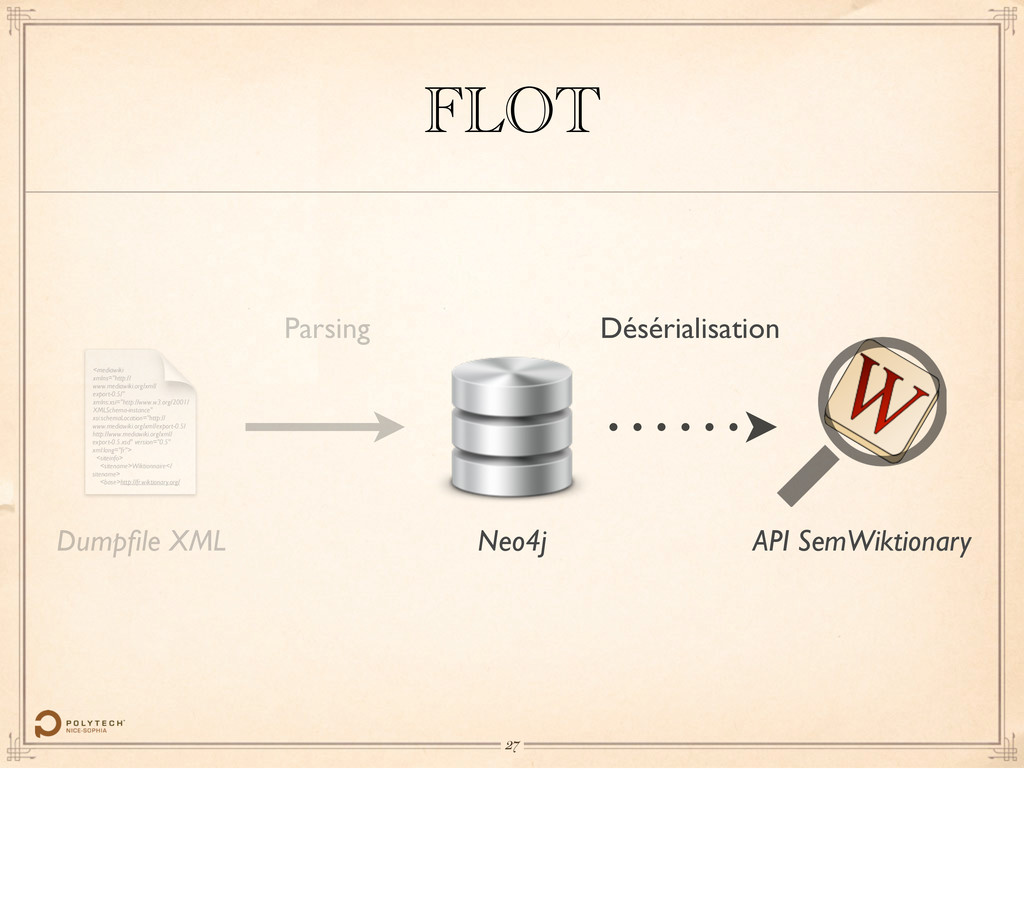
version="0.5" xml:lang="fr"> <siteinfo> <sitename>Wiktionnaire</ sitename> <base>http://fr.wiktionary.org/ Dumpfile XML Neo4j FLOT API SemWiktionary Parsing Désérialisation 21 Passer la parole à Fabien.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}