Extended versions from the talk presented at DevOps Porto #30: Lightning Talks with Python Porto https://www.meetup.com/pt-BR/devopsporto/events/263166374/
Full Title:
Fullstack Data Science. From Data Processing Pipeline using Luigi to Serverless Backend Architecture using AWS Lambda Functions
Abstract:
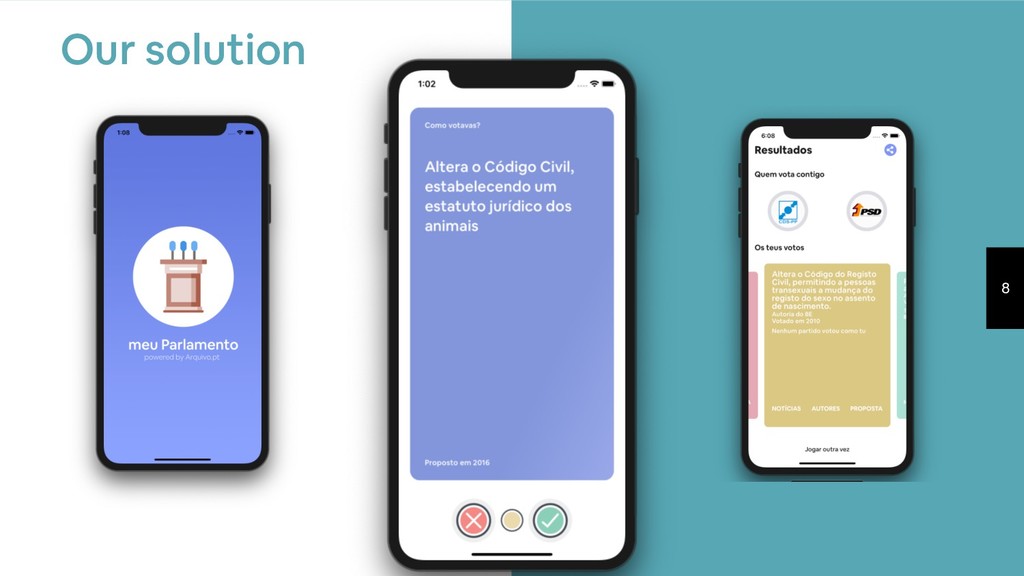
During this talk I will discuss how the project meuParlamento.pt was built. You will learn how we structured the data processing pipeline using Luigi and how we built a Backend API for the mobile App using the serverless architecture using AWS Lambda.
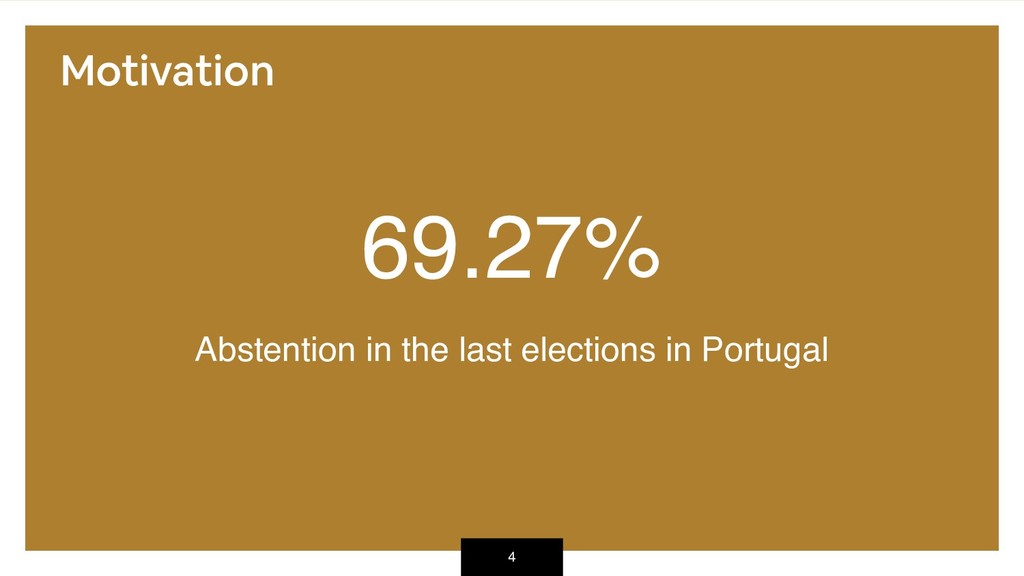
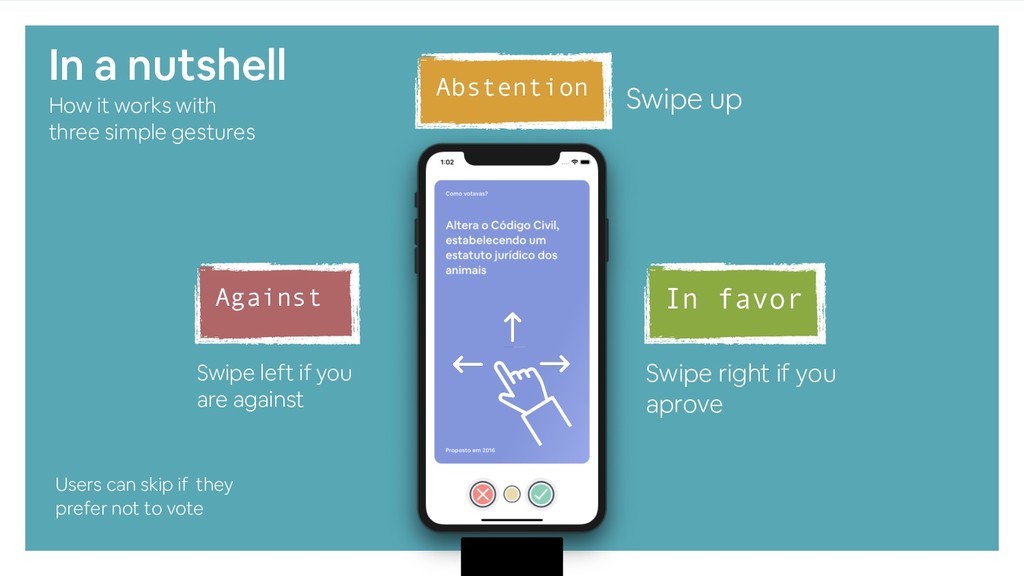
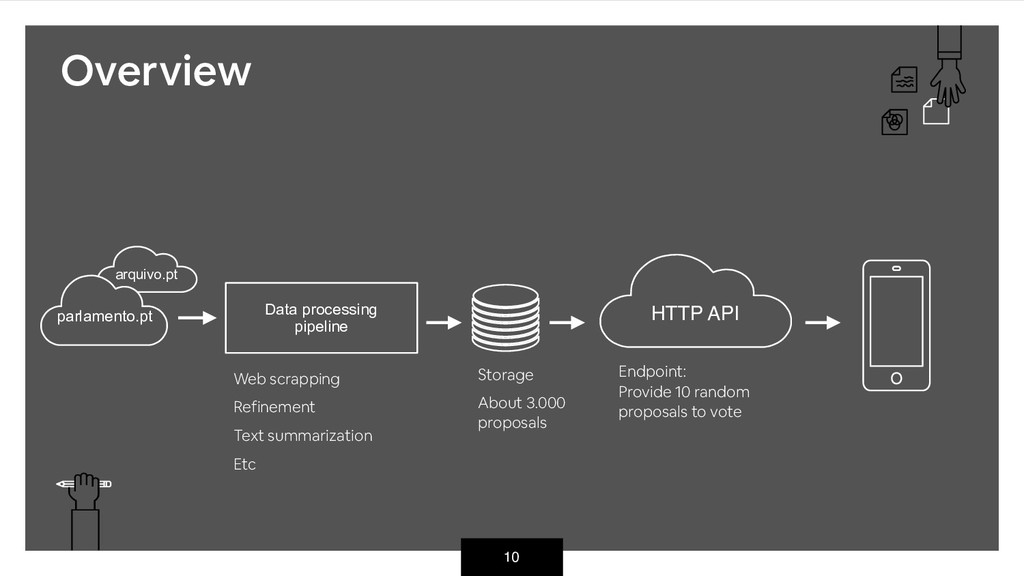
As a side project and non-profit endeavour, meuParlamento.pt was created to bring the Parliament to each users smartphone. The idea is to allow any citizen to become a Member of Parliament, and to vote on the many proposals that have been debated over the years while focusing on privacy and anonymity - no voting data is recorded.
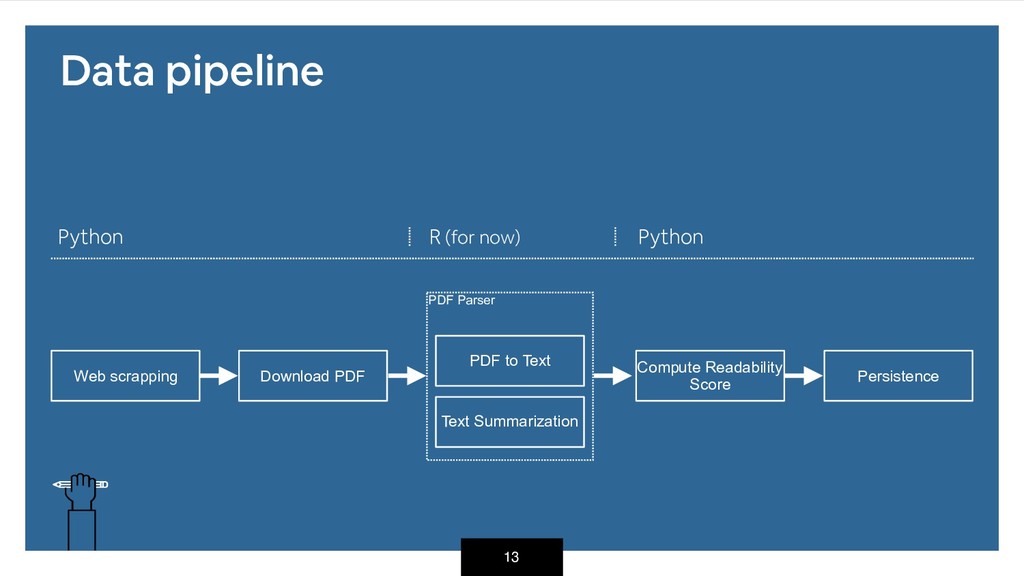
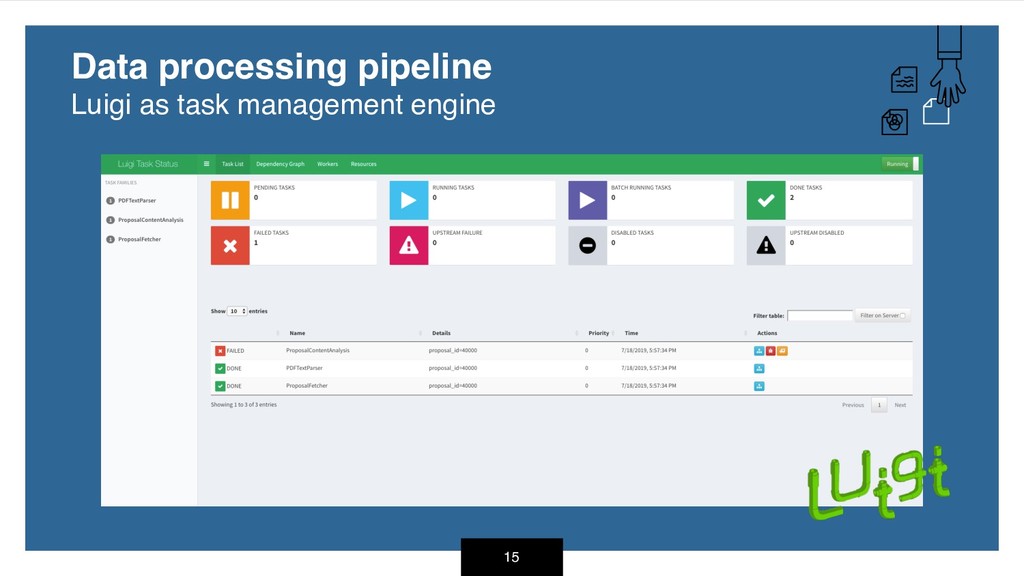
This is an open source project that combines web scrapping, text summarization and data mining to deliver content to users and I hope to present the audience an overview on how it works.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
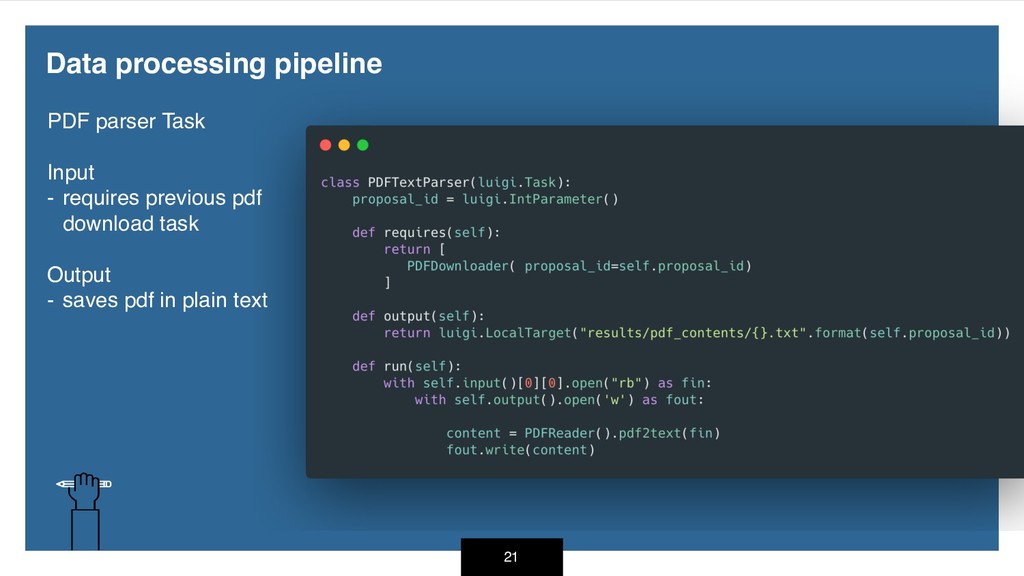{kind=link}
{kind=link}
{kind=link}
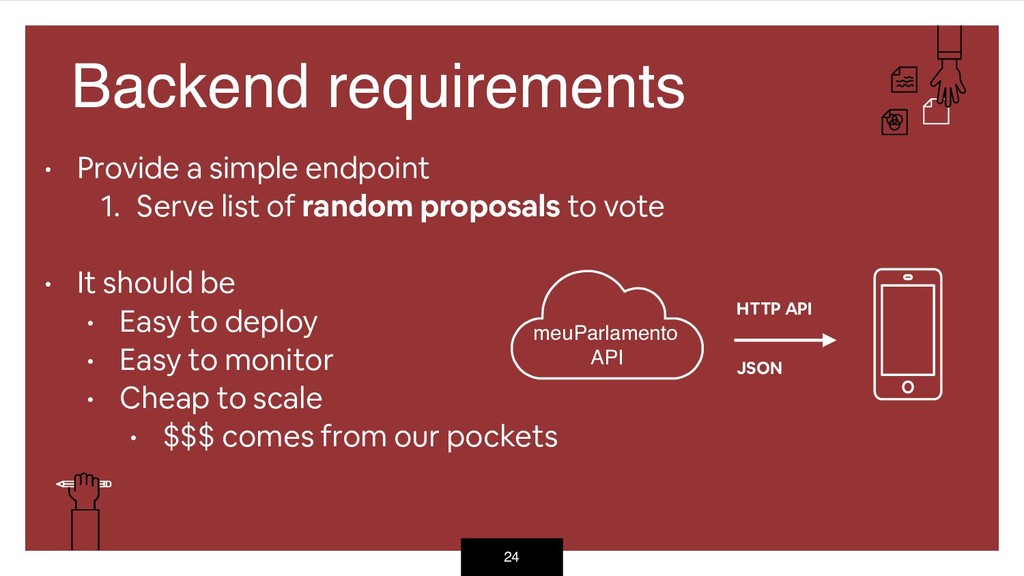{kind=link}
{kind=link}
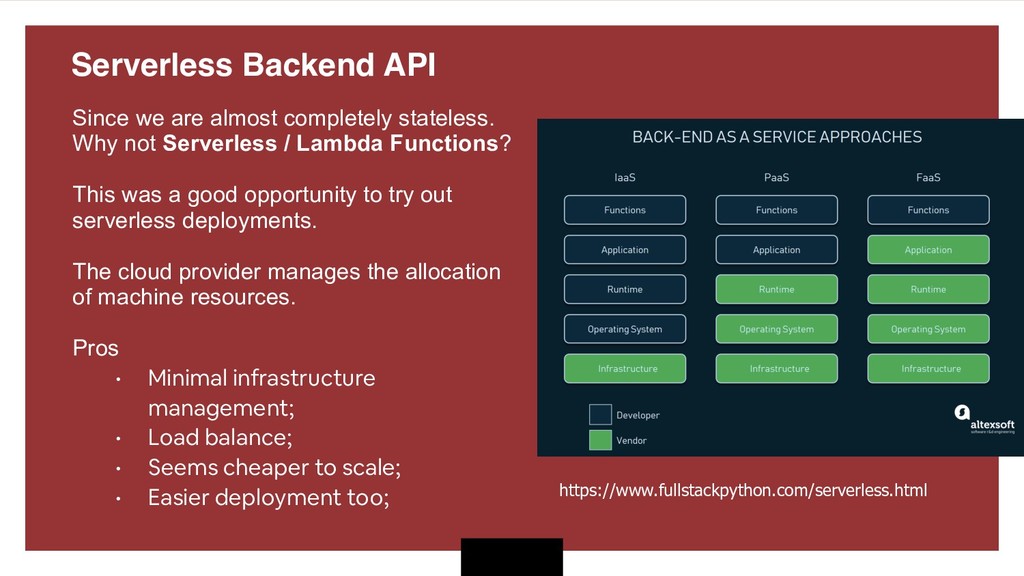{kind=link}
{kind=link}
{kind=link}
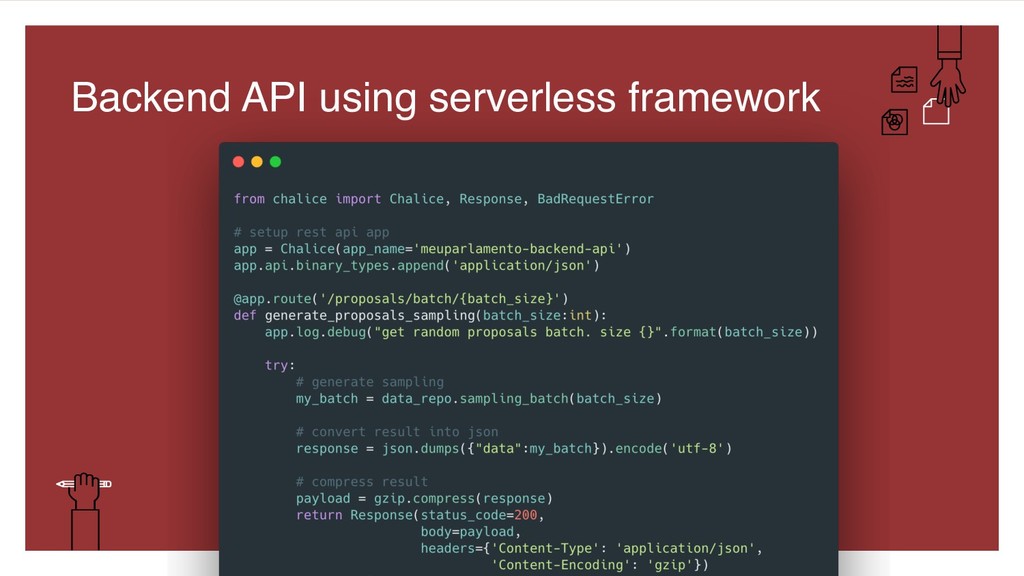{kind=link}
{kind=link}
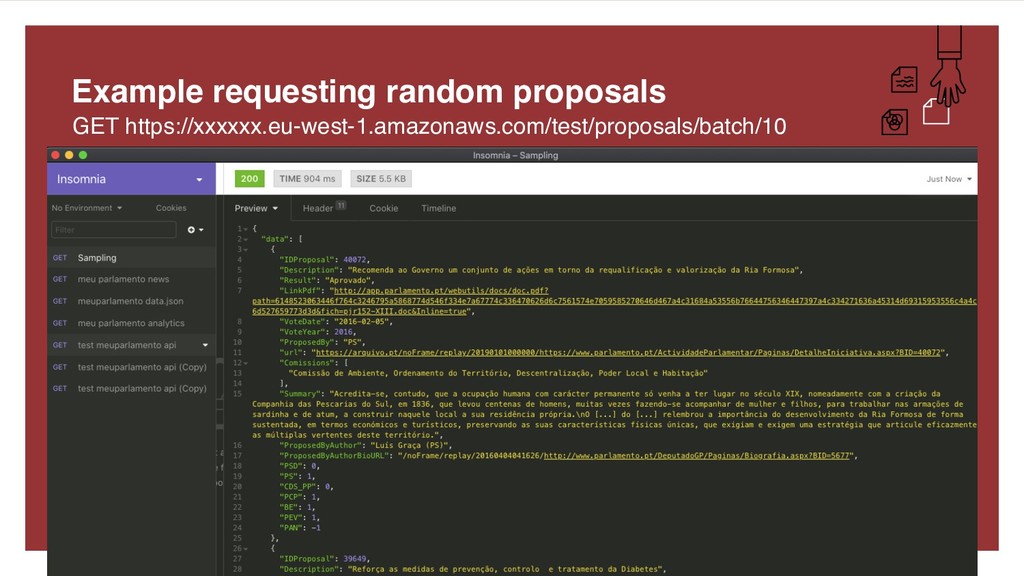{kind=link}
{kind=link}
{kind=link}
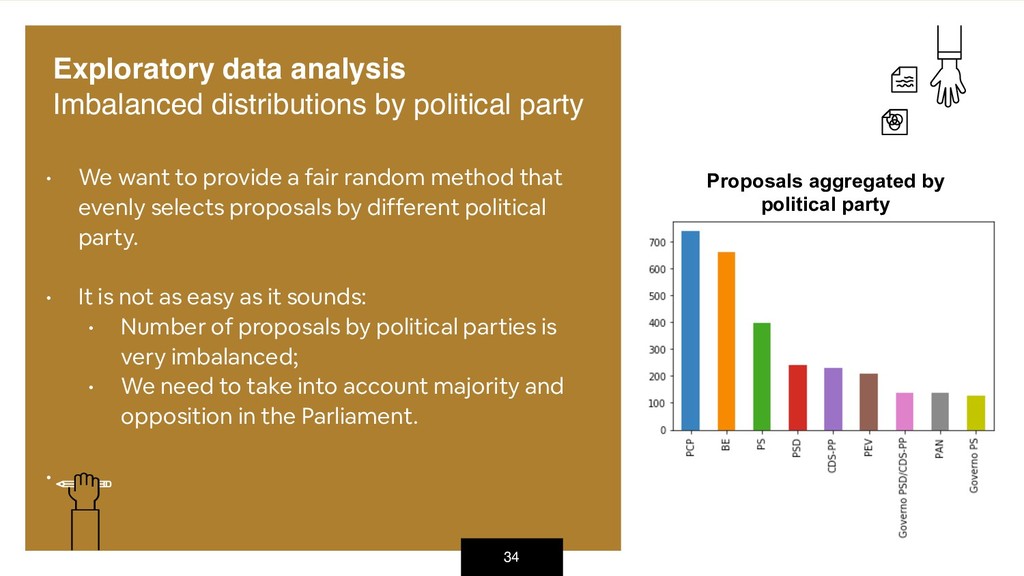{kind=link}
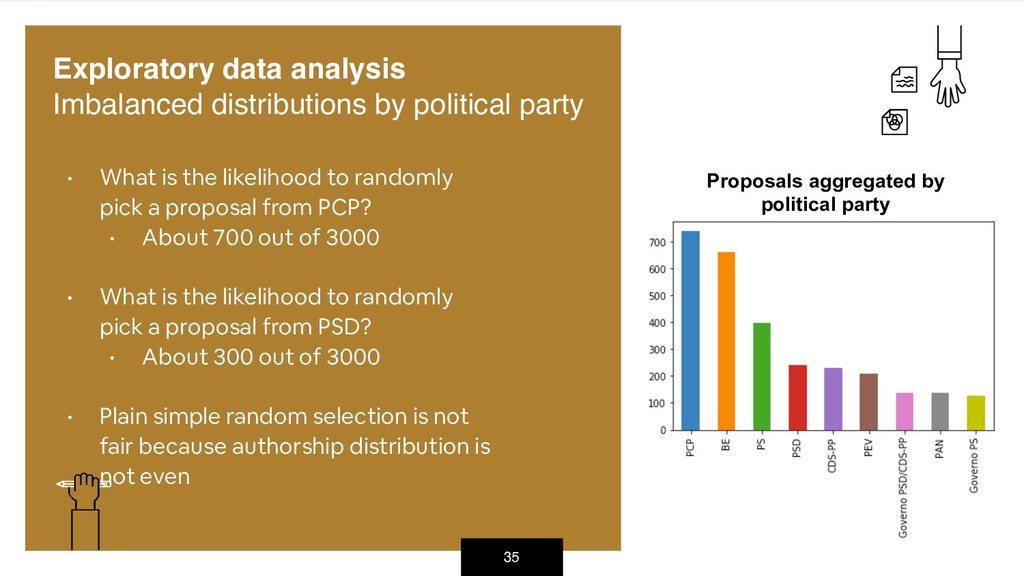{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}