com um salário. Fanático por computador desde os 7 anos de idade. Desenvolvedor desde os 13 anos de idade. Eu sempre estou buscando melhorar minhas habilidades, me tornei um programador poliglota que trabalha em várias linguagens de programação e múltiplos paradigmas de desenvolvimento.
com um salário. Fanático por computador desde os 7 anos de idade. Desenvolvedor desde os 13 anos de idade. Eu sempre estou buscando melhorar minhas habilidades, me tornei um programador poliglota que trabalha em várias linguagens de programação e múltiplos paradigmas de desenvolvimento.
• Valor de mercado: ~US$ 392 bilhões • +4 milhões de servidores • 120 bilhões buscas por mês • Adsense, Gmail, google maps, street view, youtube, android, chrome, etc ¿Google?
WHERE `field` LIKE “%text%"; • SELECT * FROM `table` MATCH (`field`,`desc`) AGAINST ("Text") • Muito facil de implementar • Desempenho é ruim (fácil de DoS) • Sharding manual • corrupção MyISAM • Sintaxe de consulta limitada • No é un motor de busca! ¿SQL?
CPU) • Alta velocidade de pesquisa (500+ queries/sec) • Alta escalabilidade: Craigslist.org • 300 milhões de consultas/dia • 15 clusters • BoardReader.com: +16 bilhões de documentos indexados em 37 máquinas. • Fala protocolo MySQL
(2008) • Configuração da velha escola (.conf files) • Configuração de cluster complexo • Velha escola • difícil de instalar, configurar e escalabilidade • Protocolo proprietário • Não de esquema livre
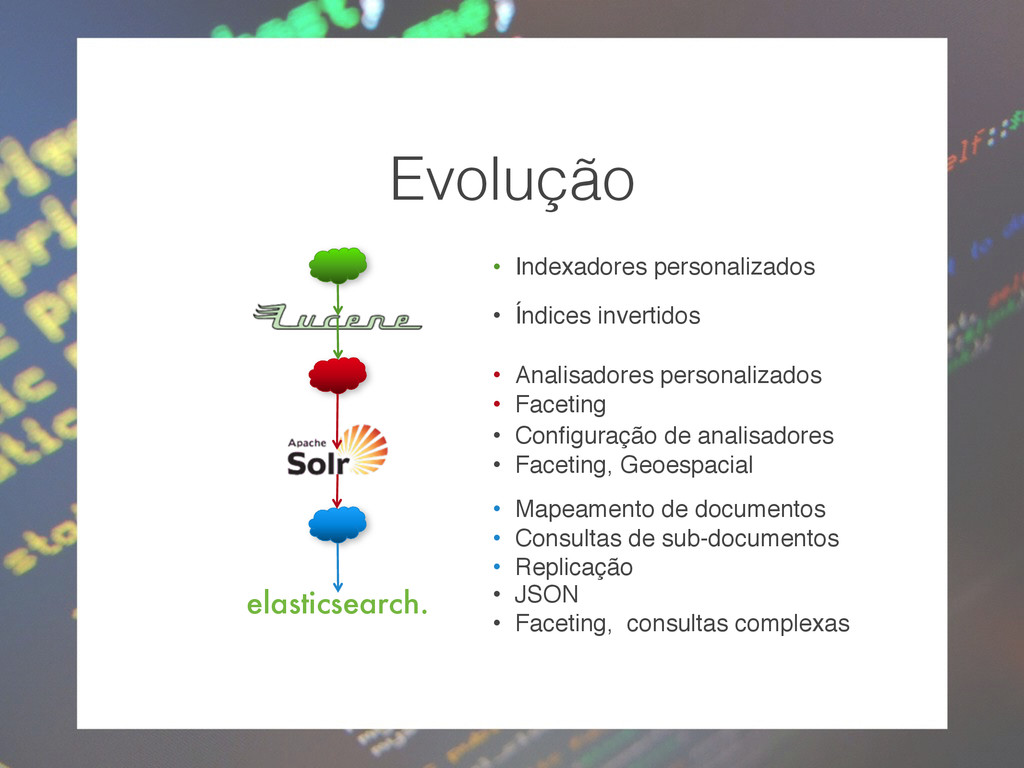
projeto Apache Lucene. Suas principais características incluem pesquisa de texto completo, bateu destacando, pesquisa facetada, clustering dinâmica, integração de banco de dados e de documentos ricos (por exemplo, Word, PDF). Pesquisa distribuída e replicação do índice, Solr é altamente escalável.” Solr/Lucene
poderoso, distribuido, em tempo real e código aberto. • Master nodes & data nodes; • Réplicas e fragmentos automáticas • Transporte assíncrona entre nodos
isso usando ElasticSearch Pesquisa 20TB de dados usando ElasticSearch, incluindo 1,3 bilhões de arquivos e 130 bilhões de linhas de código Usa ElasticSearch para fornecer resultados imediatos e relevantes para a sua plataforma de distribuição de áudio em linha atingindo 180 milhões de pessoas Usa ElasticSearch para fornecer resultados de mais de 20 milhões de produtos, um segundo depois de um artigo foi publicado já está disponível nos resultados Usa ElasticSearch para fornecer resultados de 25 milhões de usuários por dia. 70 milhões de documentos indexados. 215 GB de Dados
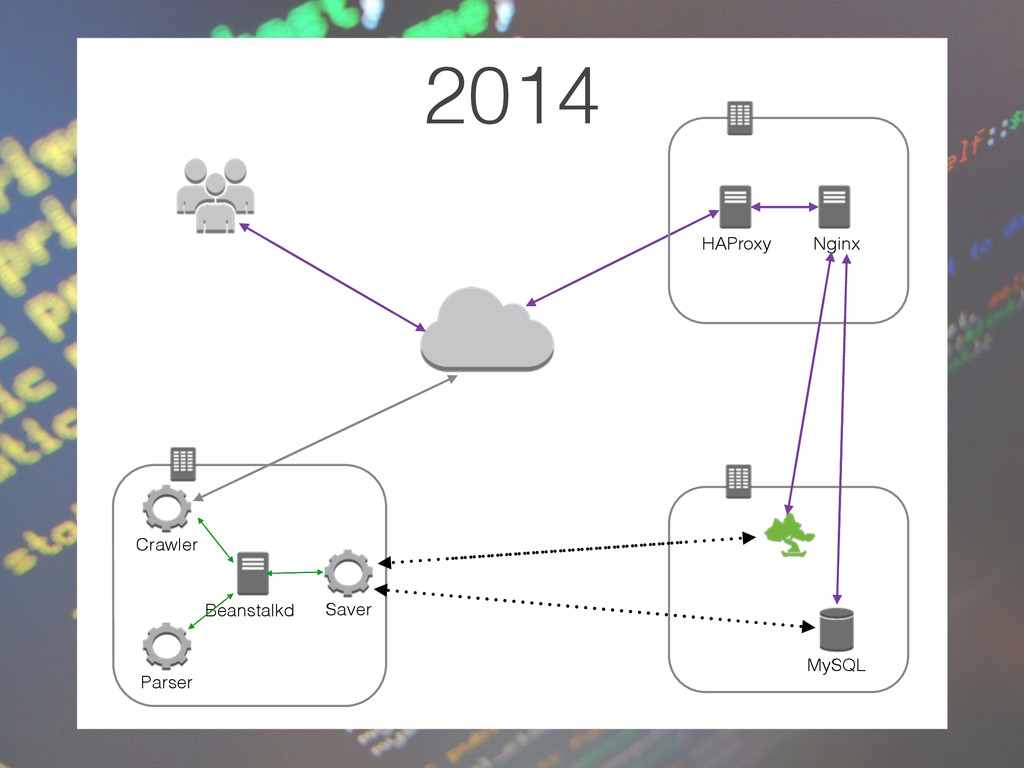
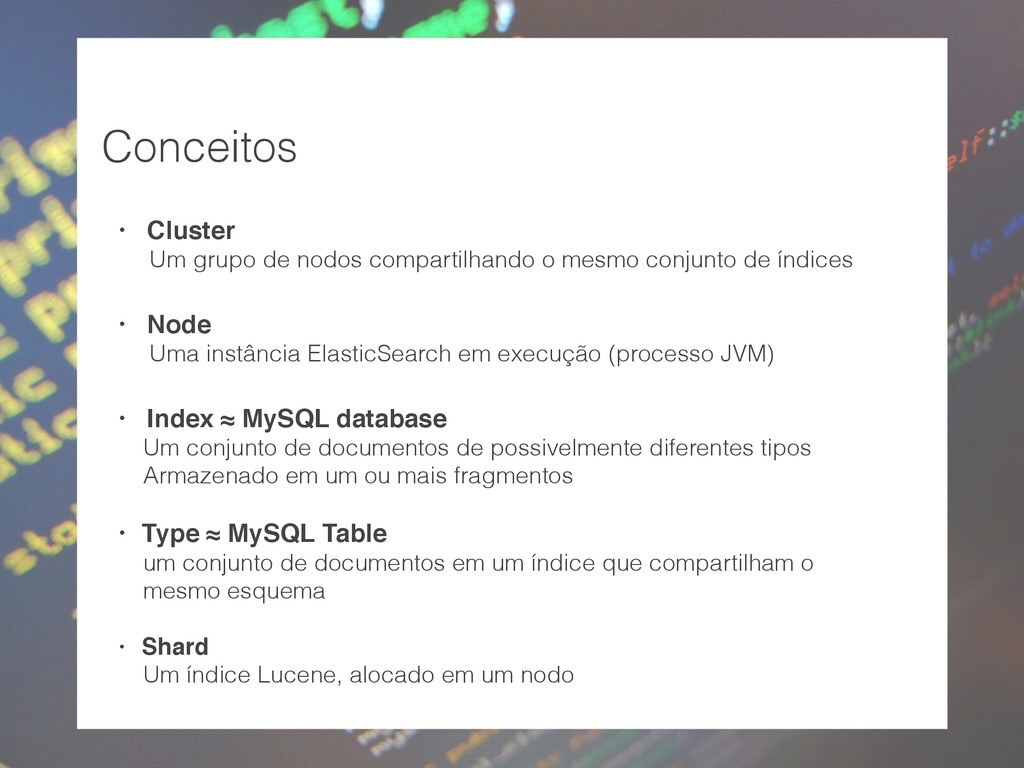
conjunto de índices • Node Uma instância ElasticSearch em execução (processo JVM) • Index ≈ MySQL database Um conjunto de documentos de possivelmente diferentes tipos Armazenado em um ou mais fragmentos • Type ≈ MySQL Table um conjunto de documentos em um índice que compartilham o mesmo esquema • Shard Um índice Lucene, alocado em um nodo
conjunto puxando dados (ou sendo empurrado com os dados) que é, então, indexada no cluster. • CouchDB • rabbitmq • twitter • wikipedia • MongoDB • JDBC
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Miguel Gallardo @mg3dem [email protected]](https://files.speakerdeck.com/presentations/1fdae7a012f40132c2fa1a02e52fa712/slide_52.jpg){kind=link}
![Miguel Gallardo @mg3dem [email protected] Obrigado!](https://files.speakerdeck.com/presentations/1fdae7a012f40132c2fa1a02e52fa712/slide_53.jpg){kind=link}