Group(PG)で構成される クライアントは Primary の disk (OSD) に対して読み書きする Pool node 4 node 1 node 2 node 3 Ceph cluster disk0 disk1 disk2 disk3 disk4 disk5 17 PG Primary Replica Replica ホスト分布 0 disk 5 disk 1 disk 2 node4, node1, node2 1 disk 2 disk 1 disk 5 node2, node1, node4 2 disk 4 disk 0 disk 3 node3, node1, node2 3 disk 1 disk 3 disk 5 node1, node2, node4 4 disk 3 disk 0 disk 4 node2, node1, node3 5 disk 0 disk 2 disk 4 node1, node2, node3 6 disk 0 disk 3 disk 5 node1, node2, node4 7 disk 2 disk 1 disk 4 node2, node1, node3 FailureDomain = host にすることで、 PG 内に同じサーバの disk が無いようにする
pg_id を取得: hash(pool_id, object_id) mod pg_num = pg_id 3. CRUSH アルゴリズムで OSD を算出: CRUSH(clush_map, pg_id) = osd_primary 18 … 0003 0004 0005 … 12 16 20 24 /dev/rbd0 書込むデータ: 7MB (位置: 15MB ~ 22MB) ・hash(pool_id=2, object_id=0003) mod 8 → pg_id=5 CRUSH(clush_map, pg_id=5) → osd_primary=0 ・hash(pool_id=2, object_id=0004) mod 8 → pg_id=0 CRUSH(clush_map, pg_id=0) → osd_primary=5 ・hash(pool_id=2, object_id=0005) mod 8 → pg_id=2 CRUSH(clush_map, pg_id=2) → osd_primary=4 PG Primary Replica Replica 0 disk 5 disk 1 disk 2 1 disk 2 disk 1 disk 5 2 disk 4 disk 0 disk 3 3 disk 1 disk 3 disk 5 4 disk 3 disk 0 disk 4 5 disk 0 disk 2 disk 4 6 disk 0 disk 3 disk 5 7 disk 2 disk 1 disk 4 Pool 位置
pg_id を取得: hash(pool_id, object_id) mod pg_num = pg_id 3. CRUSH アルゴリズムで OSD を算出: CRUSH(clush_map, pg_id) = osd_primary 4. osd_primary に書込む → osd_primary が Replica の OSD に書込む node 4 node 1 node 2 node 3 Ceph cluster Ceph Client /dev/rbd0 disk0 disk1 disk2 disk3 disk4 disk5 ストレージ専用の NW があると、クライアン トからの Write 帯域を圧迫しない PG 5 PG 0 PG 2 19 Pool PG Primary Replica Replica 0 disk 5 disk 1 disk 2 1 disk 2 disk 1 disk 5 2 disk 4 disk 0 disk 3 3 disk 1 disk 3 disk 5 4 disk 3 disk 0 disk 4 5 disk 0 disk 2 disk 4 6 disk 0 disk 3 disk 5 7 disk 2 disk 1 disk 4
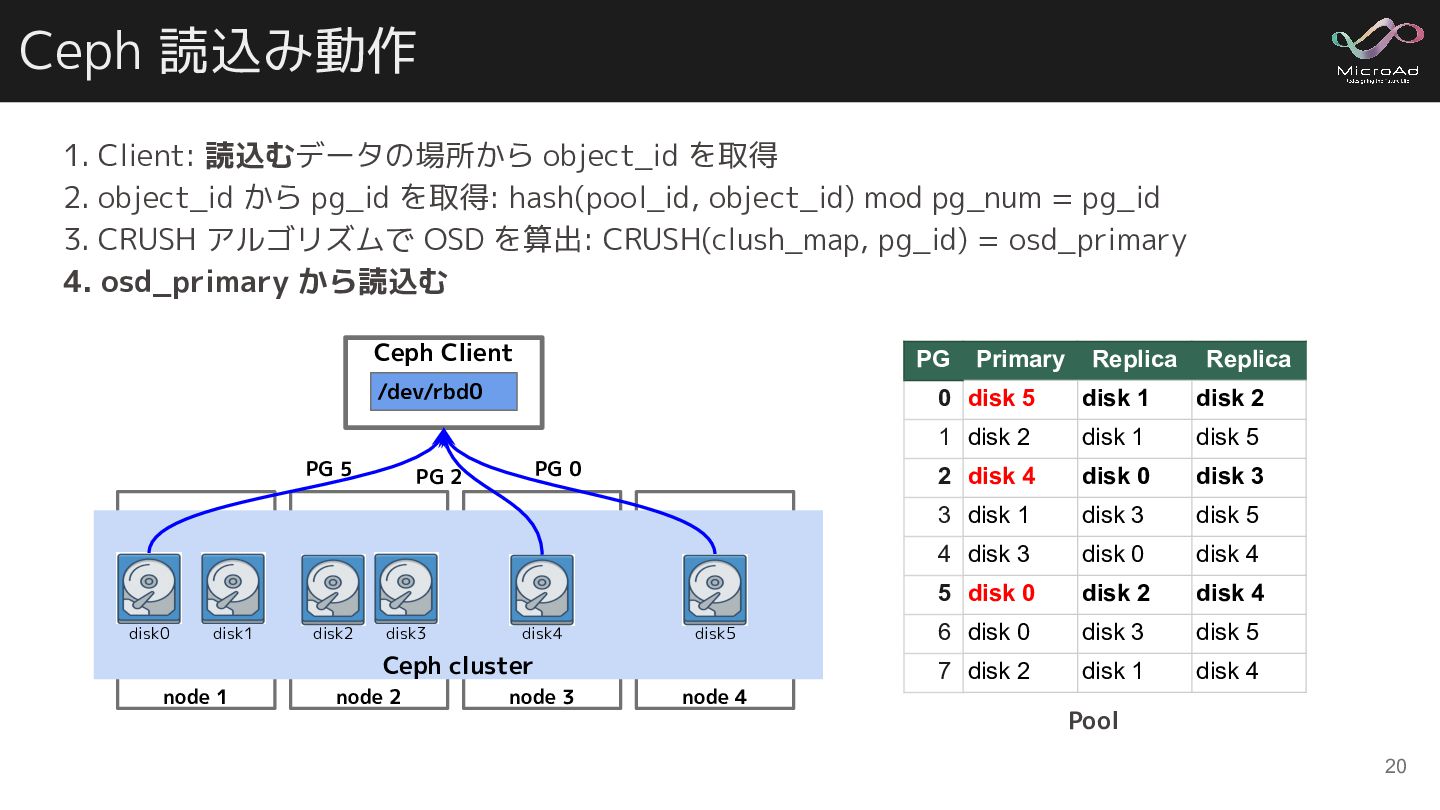
pg_id を取得: hash(pool_id, object_id) mod pg_num = pg_id 3. CRUSH アルゴリズムで OSD を算出: CRUSH(clush_map, pg_id) = osd_primary 4. osd_primary から読込む 20 Pool PG Primary Replica Replica 0 disk 5 disk 1 disk 2 1 disk 2 disk 1 disk 5 2 disk 4 disk 0 disk 3 3 disk 1 disk 3 disk 5 4 disk 3 disk 0 disk 4 5 disk 0 disk 2 disk 4 6 disk 0 disk 3 disk 5 7 disk 2 disk 1 disk 4 node 4 node 1 node 2 node 3 Ceph cluster Ceph Client /dev/rbd0 disk0 disk1 disk2 disk3 disk4 disk5 PG 5 PG 0 PG 2
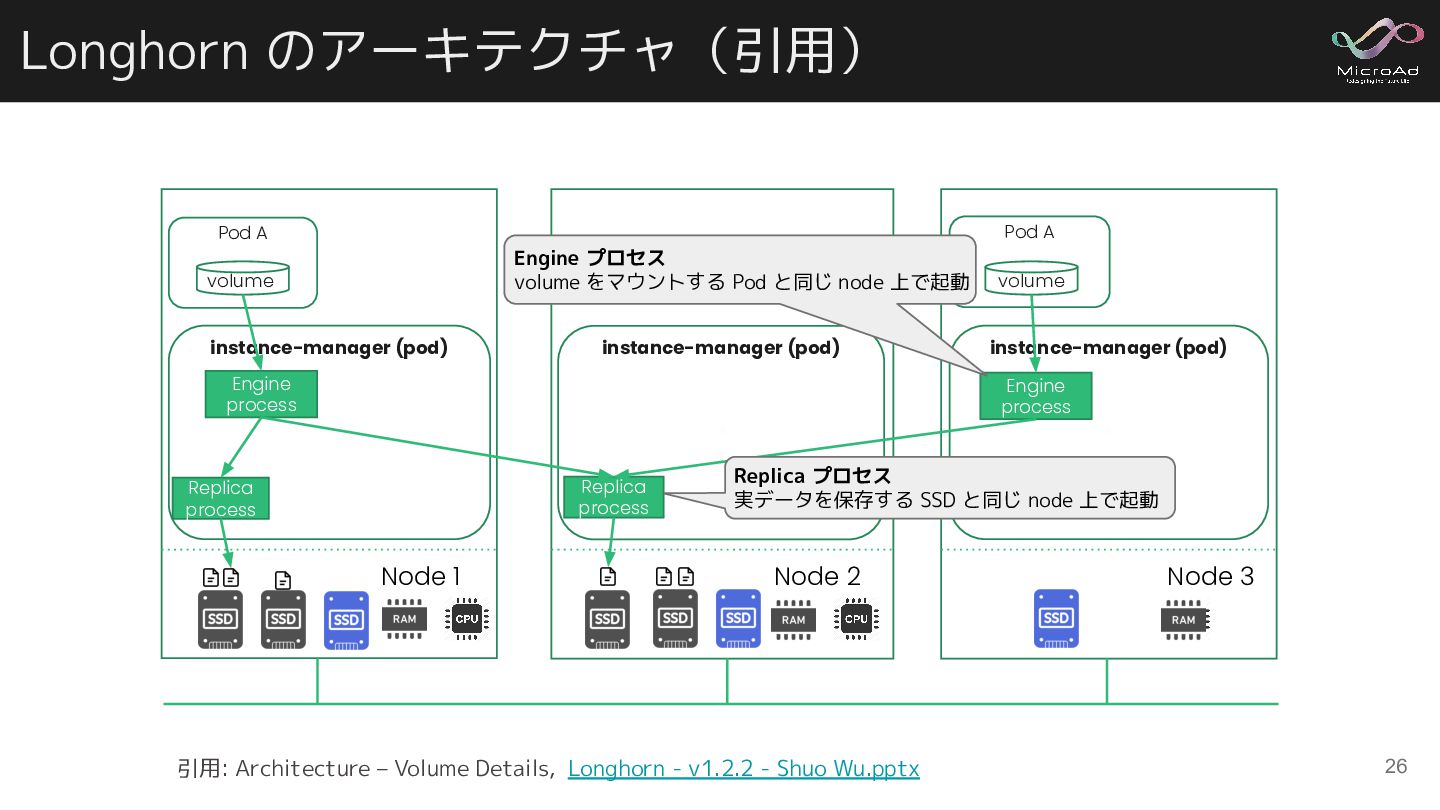
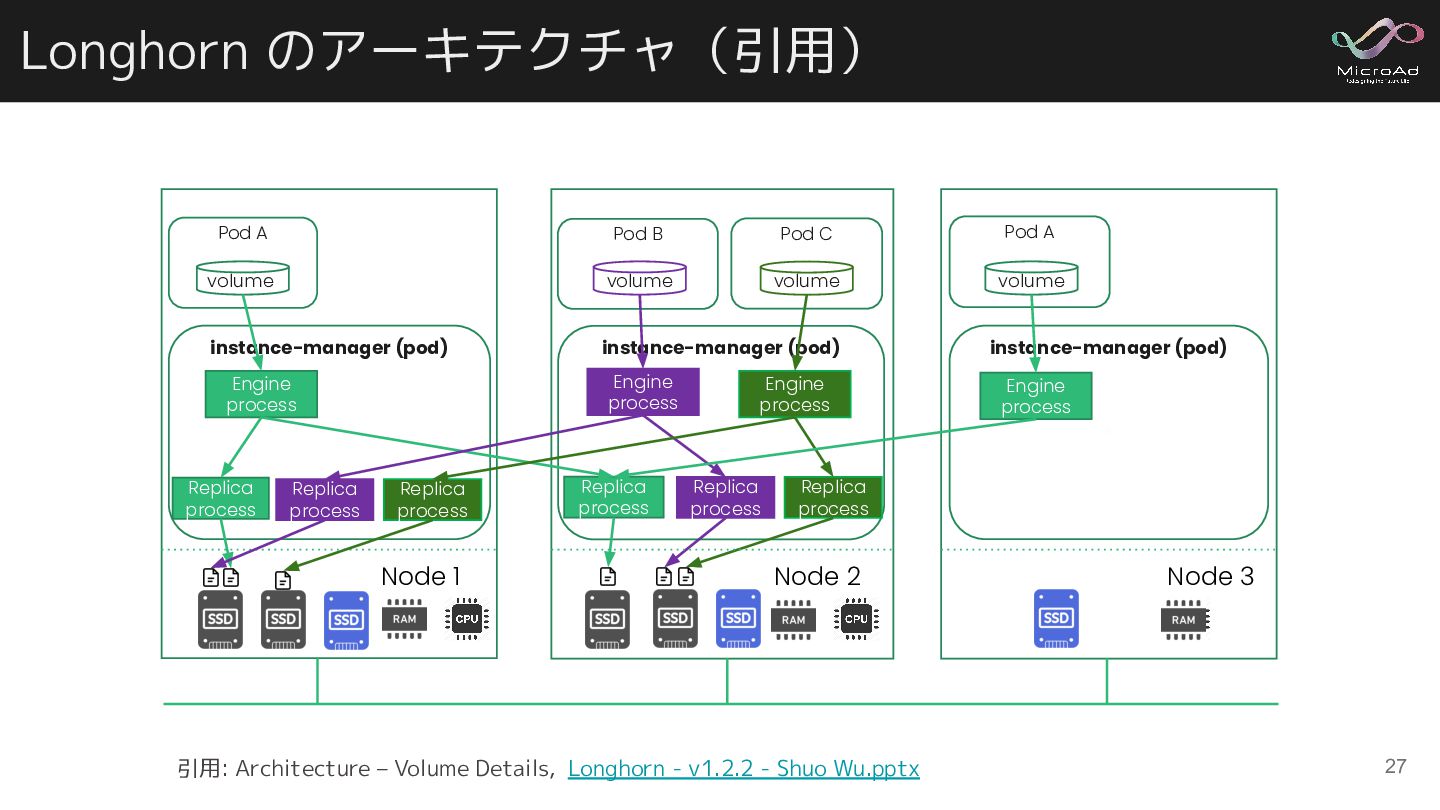
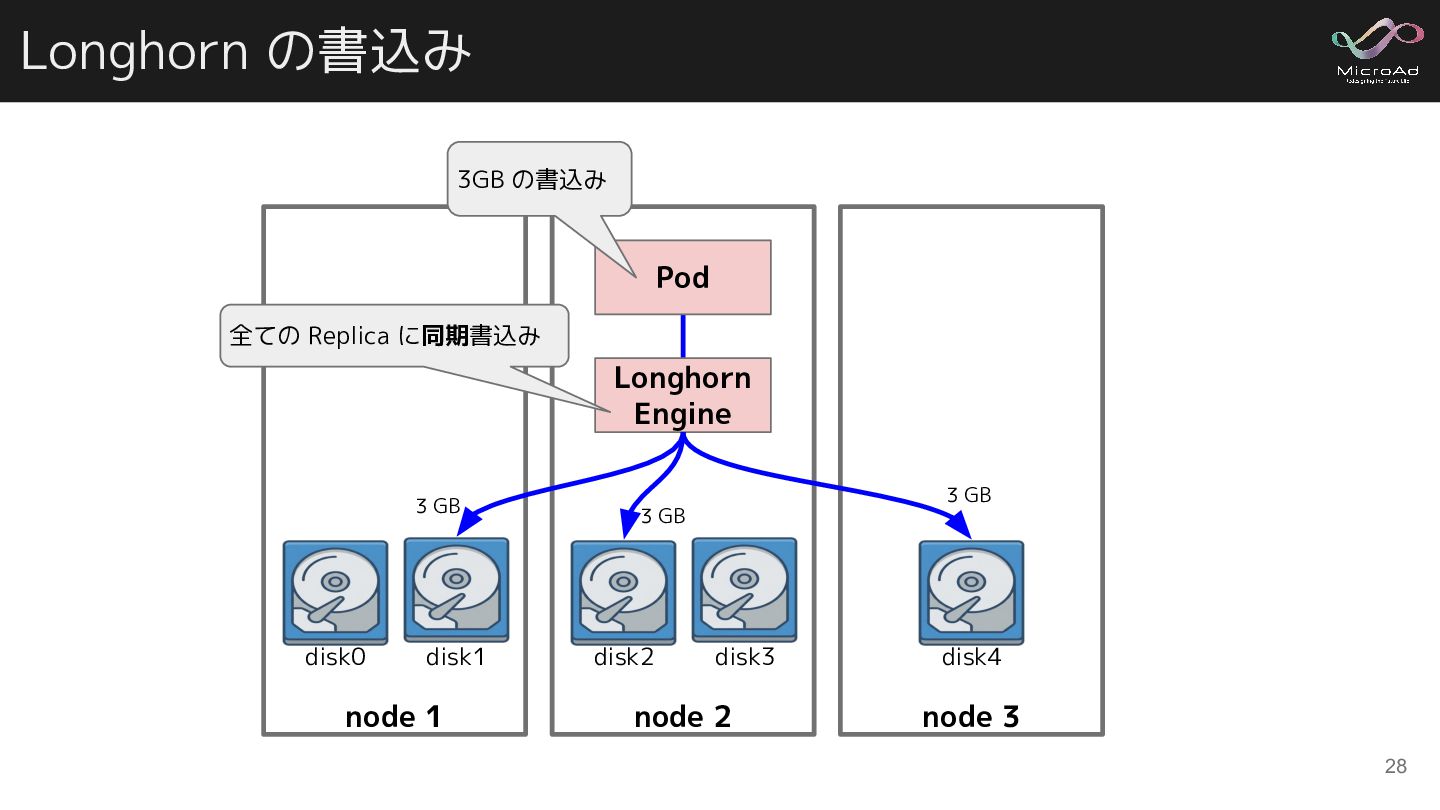
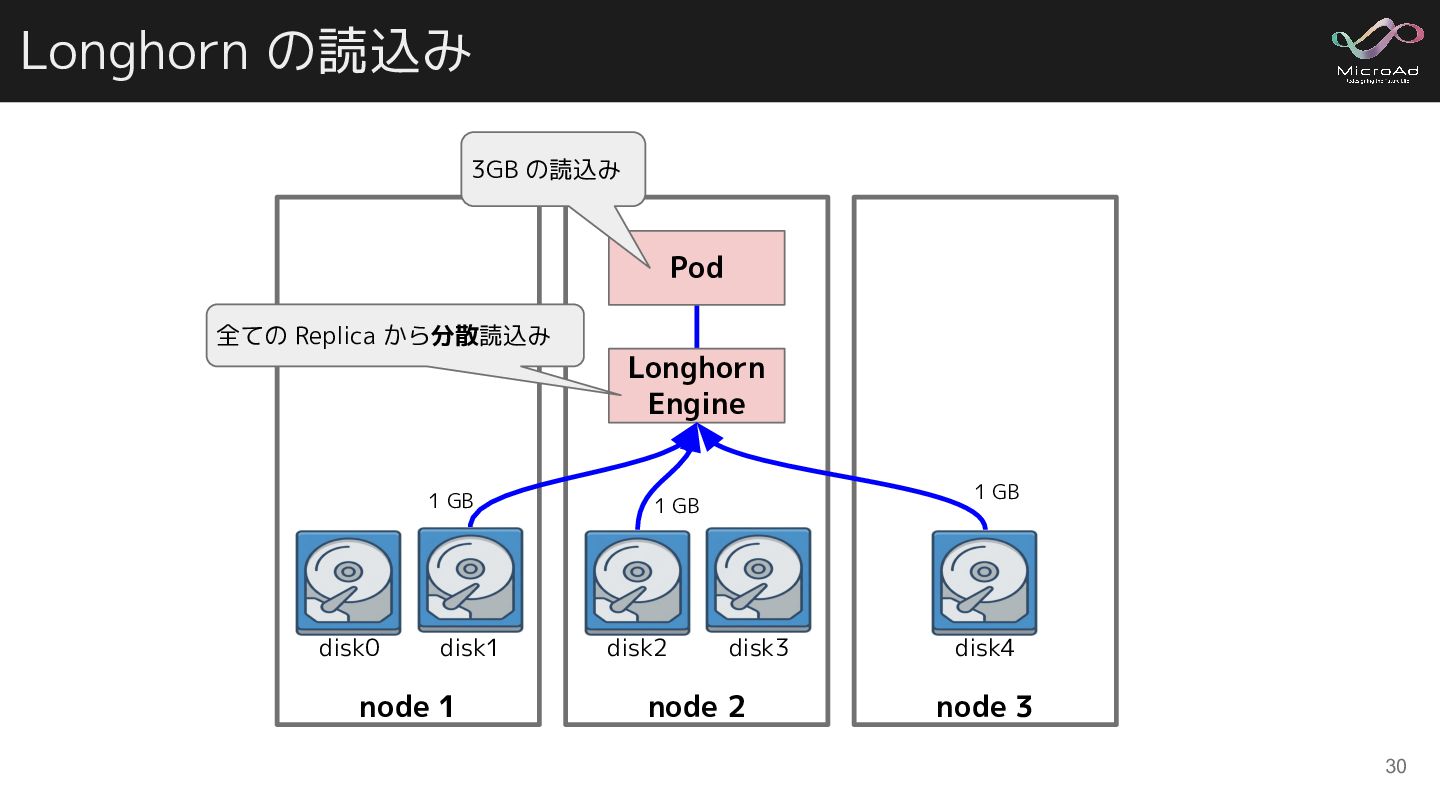
A volume Engine process Replica process Replica process Pod B volume Engine process Replica process Engine process Replica process Replica process Node 2 Node 3 Pod C volume Pod A volume Engine process Node 1 Replica process 引用: Architecture – Volume Details, Longhorn - v1.2.2 - Shuo Wu.pptx
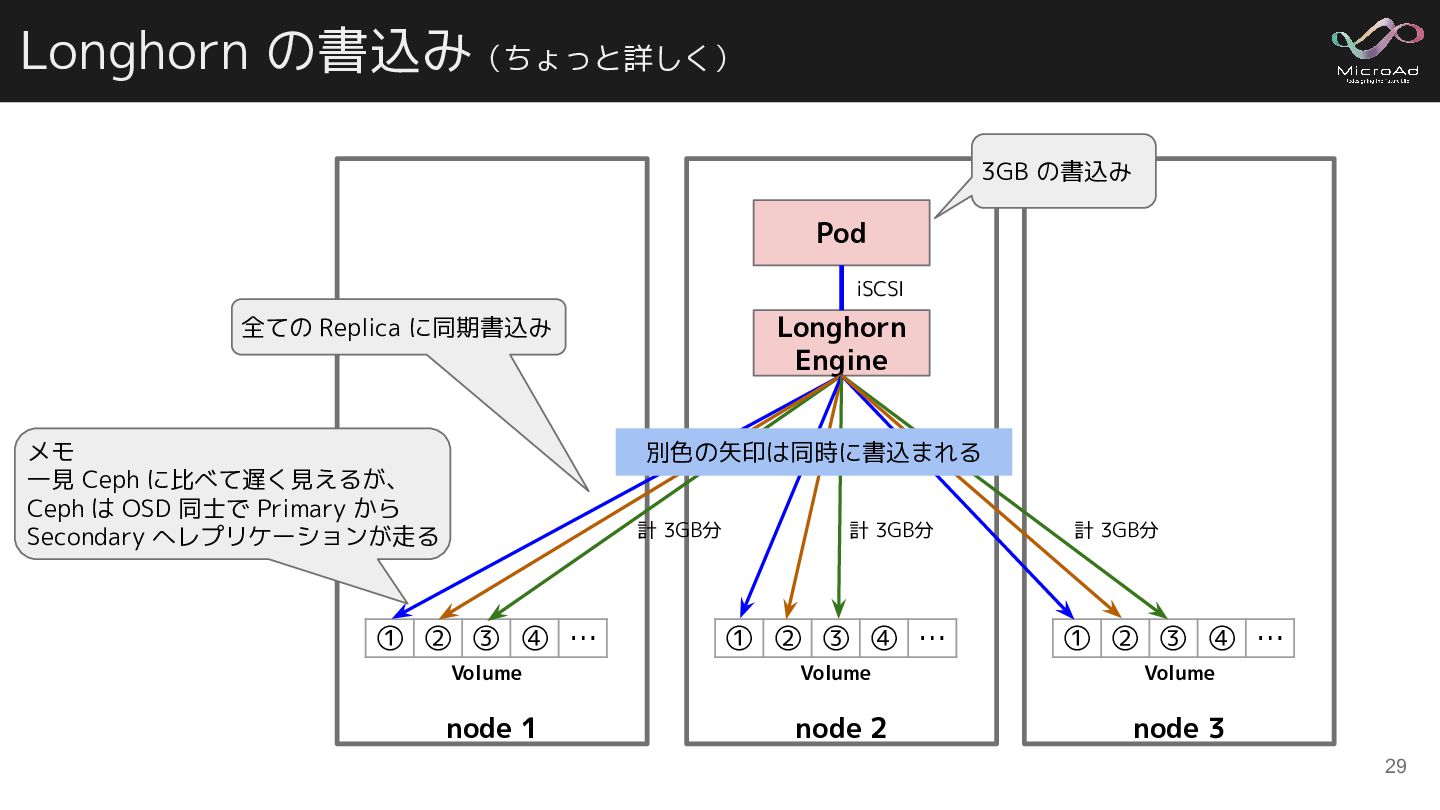
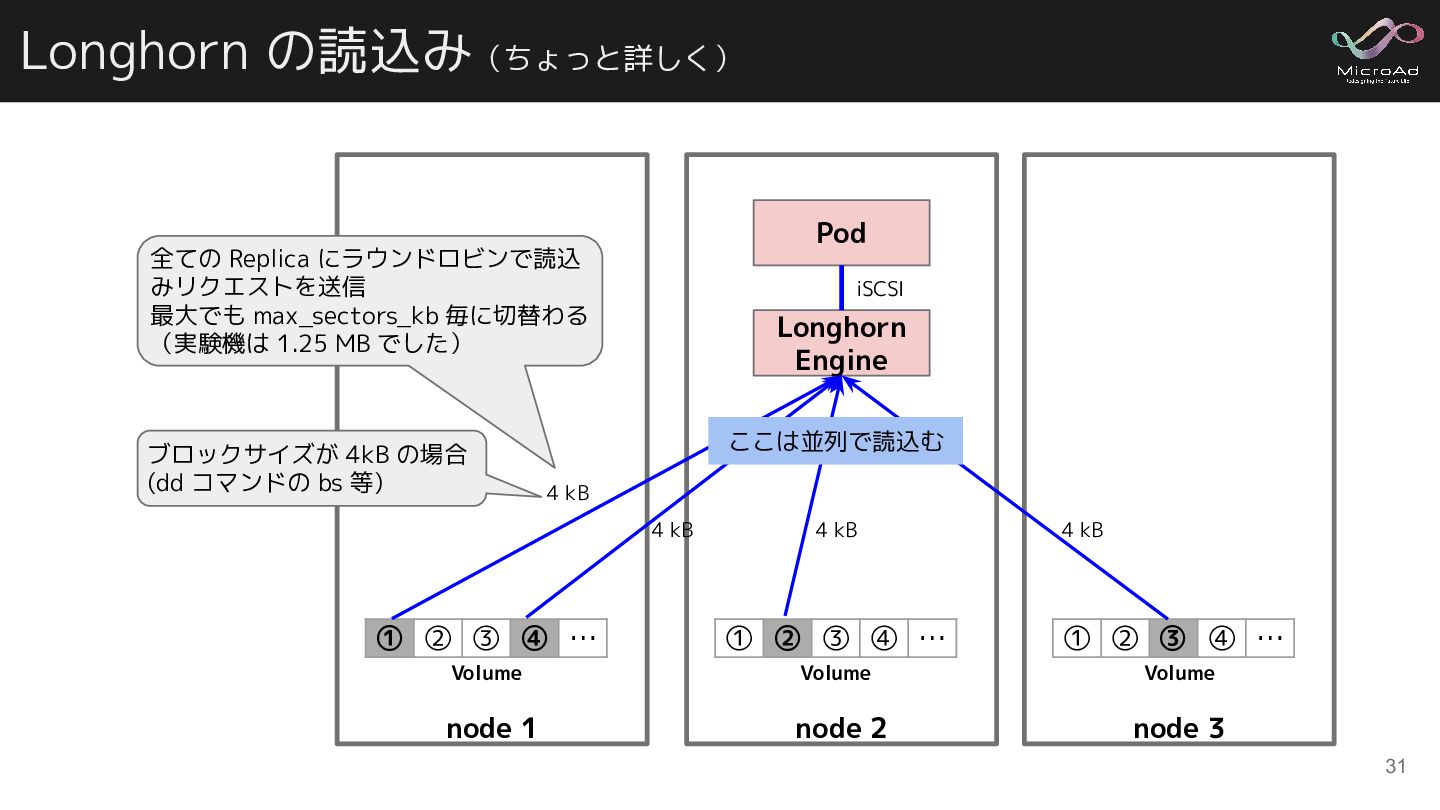
ensure reading data from local replica at first priority if there is any to lower the read latency · Issue #3143 32 node 1 ① ② ③ ④ … node 2 ① ② ③ ④ … node 3 ① ② ③ ④ … Longhorn Engine Volume Volume Volume Pod Q. Pod が動いている node からのみ read すればよくない?? A. ラウンドロビンこそ至高 こんな感じで、同じ node 上からの み read すればよくない?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pod が動いている node から Read すれば良くない? ここで議論されており「ラウンドロビンこそ至高」という結論に至っている [FEATURE] Longhorn should](https://files.speakerdeck.com/presentations/fed8d1c336cc4d1c925f53cfe08e968e/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
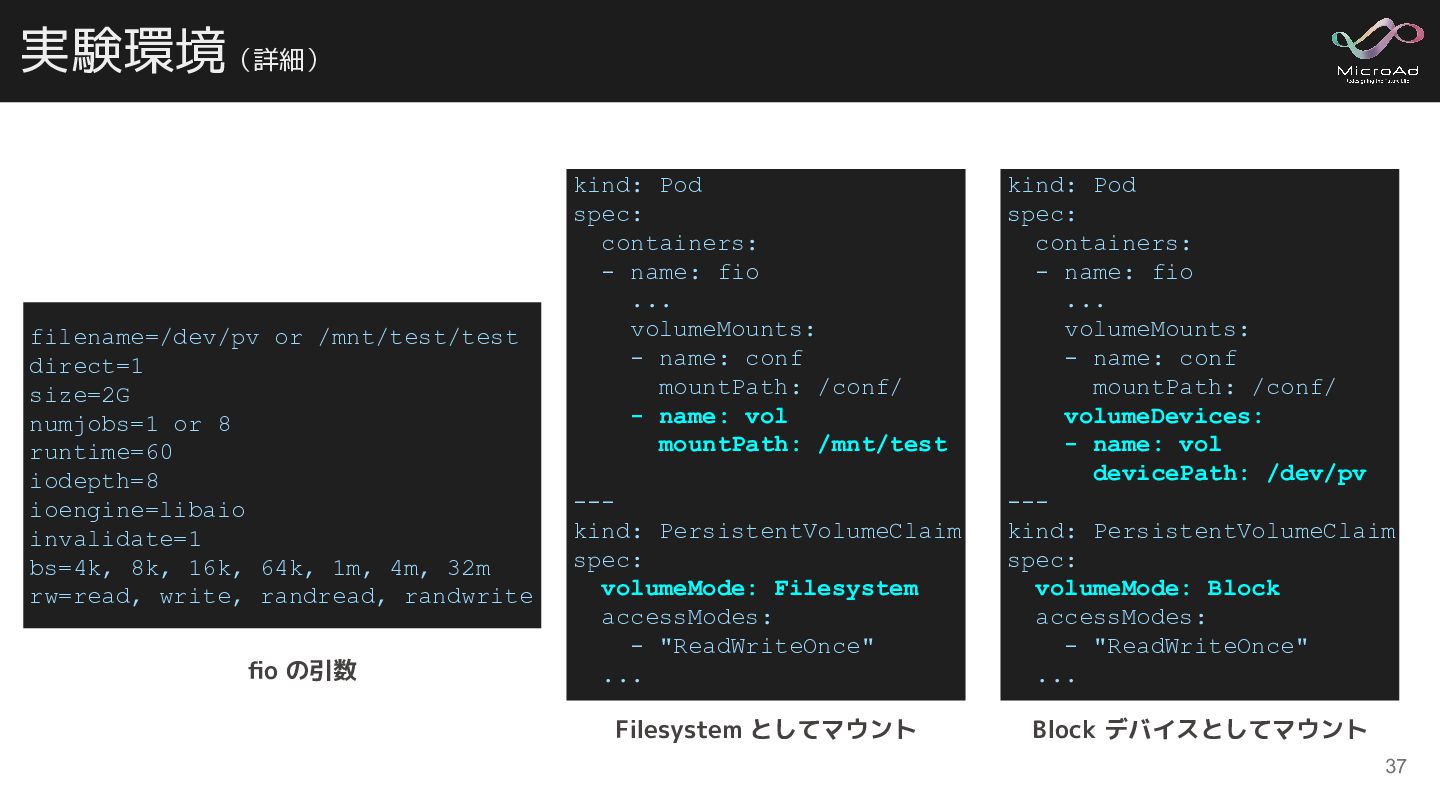{kind=link}
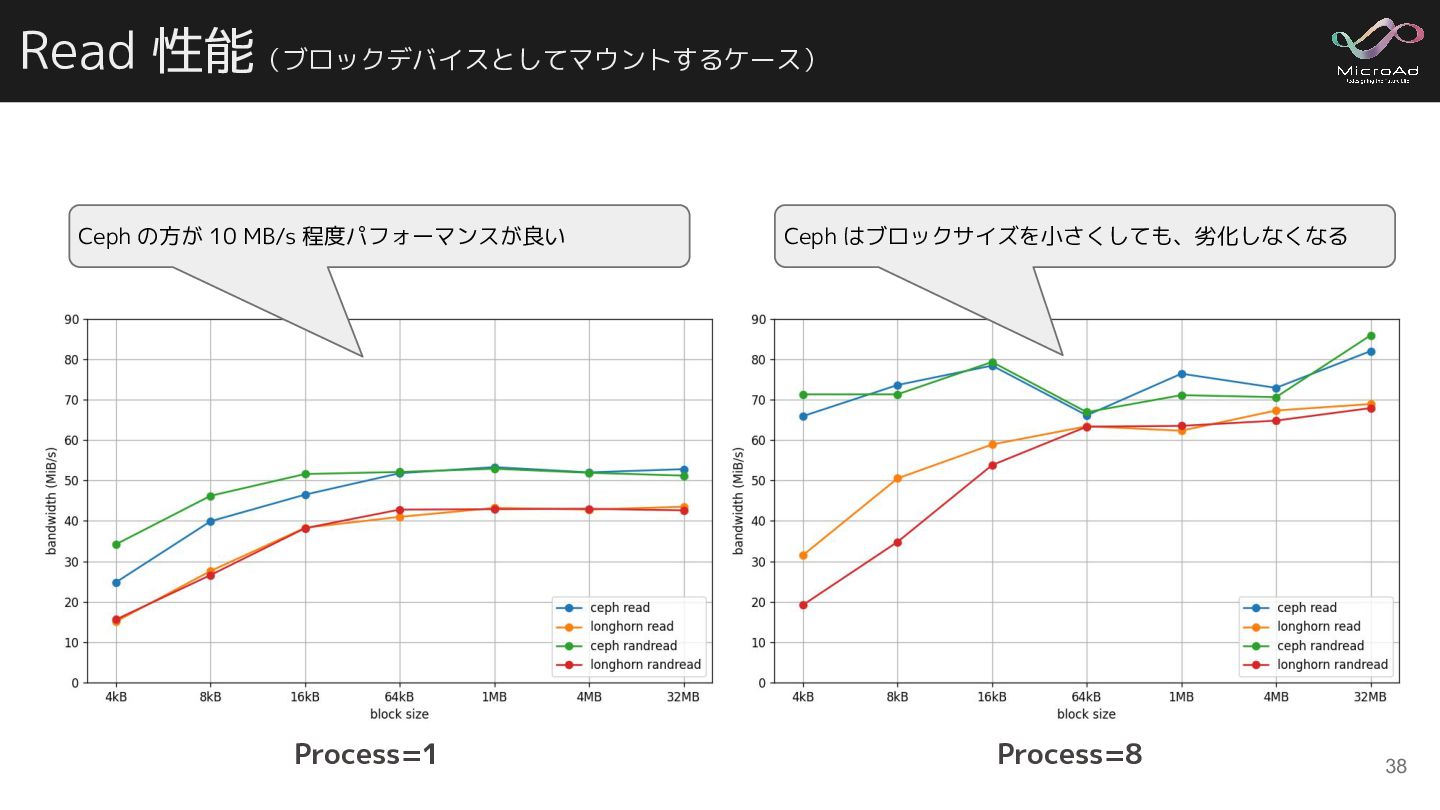{kind=link}
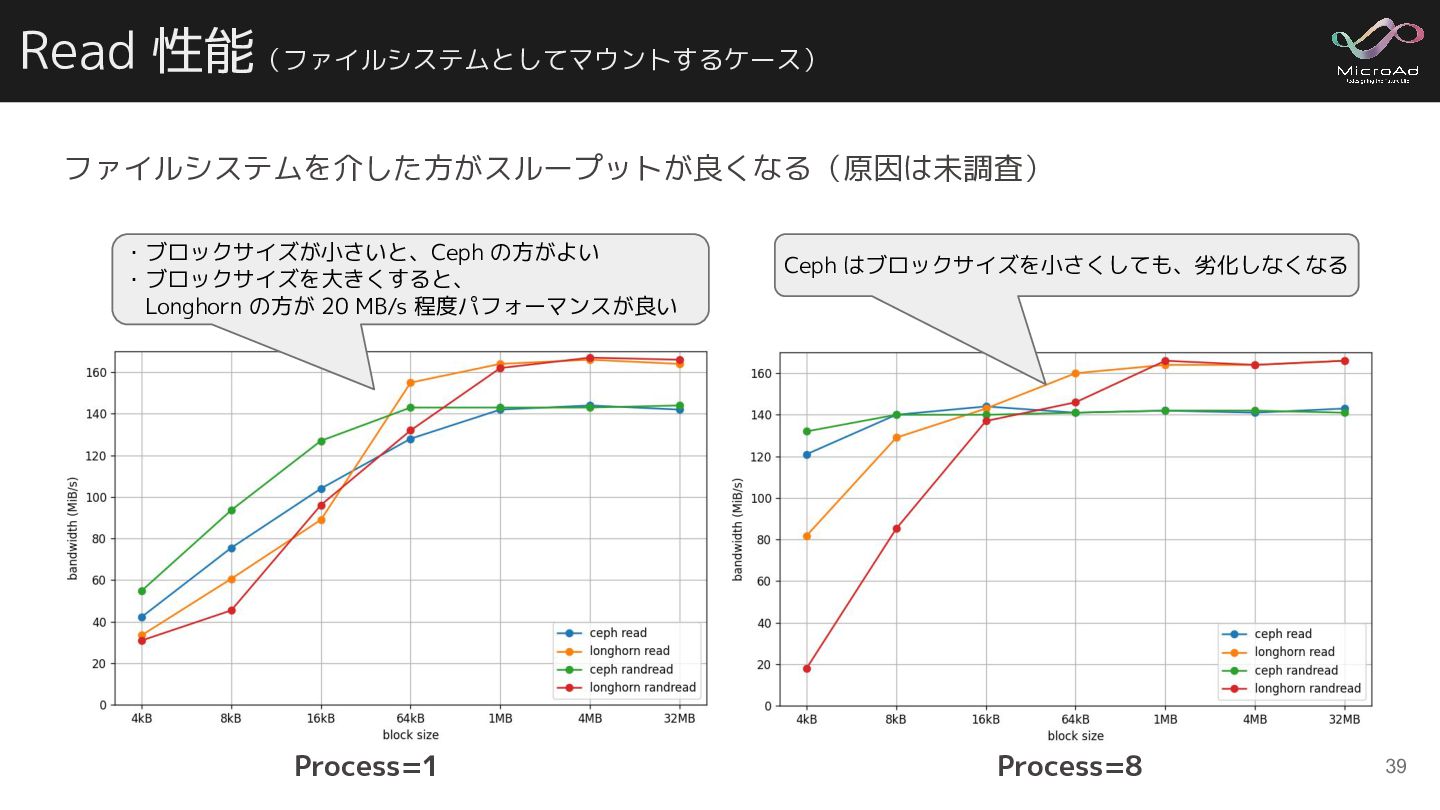{kind=link}
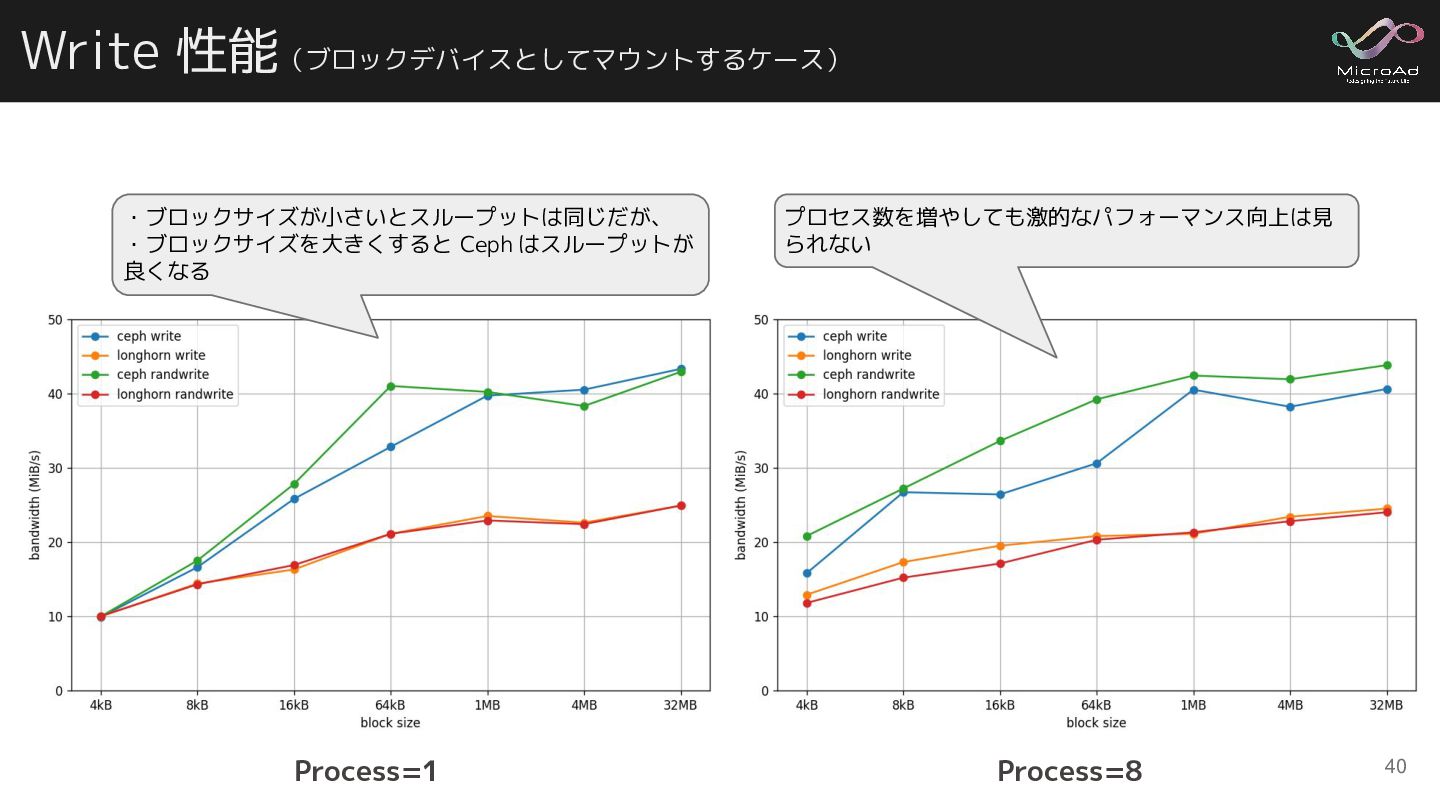{kind=link}
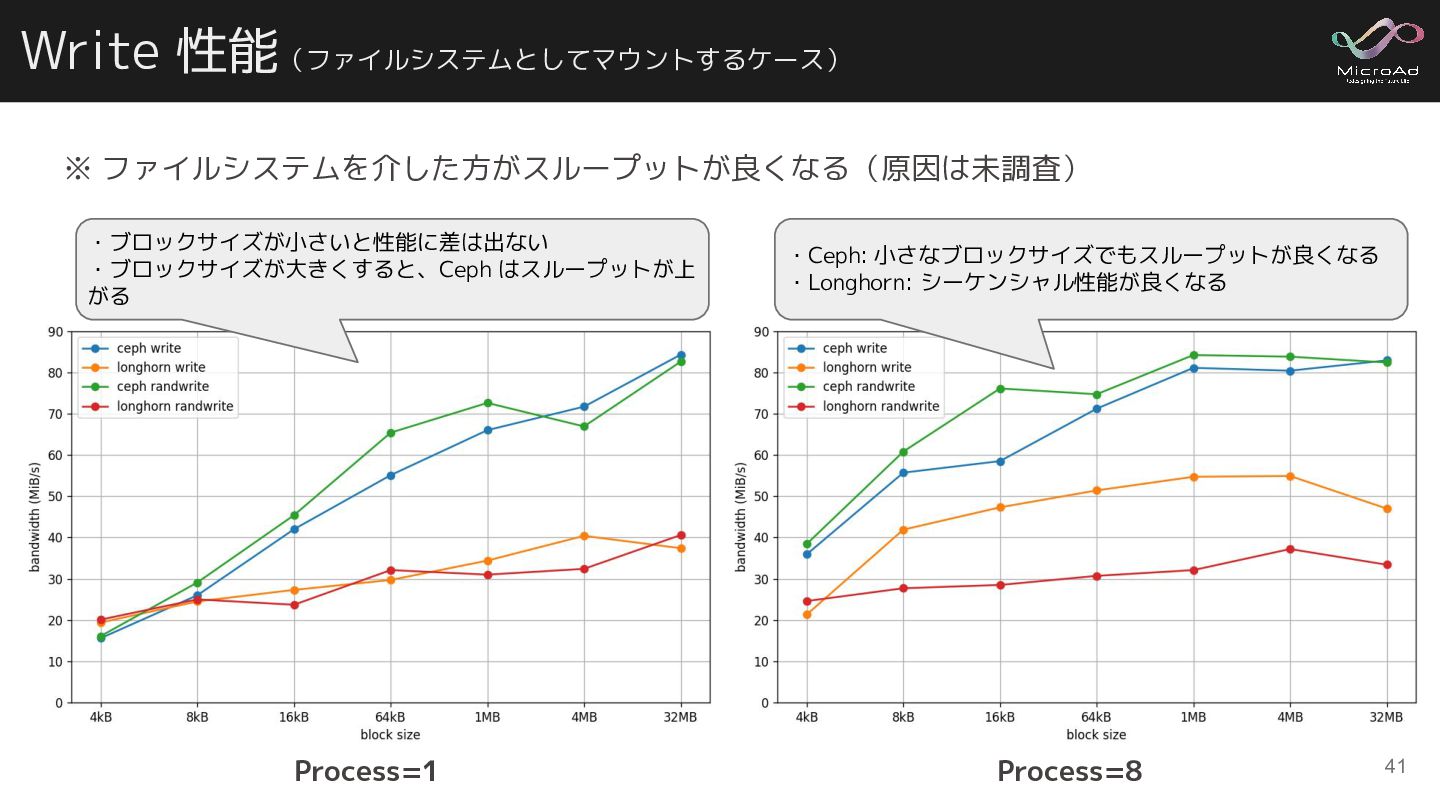{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}