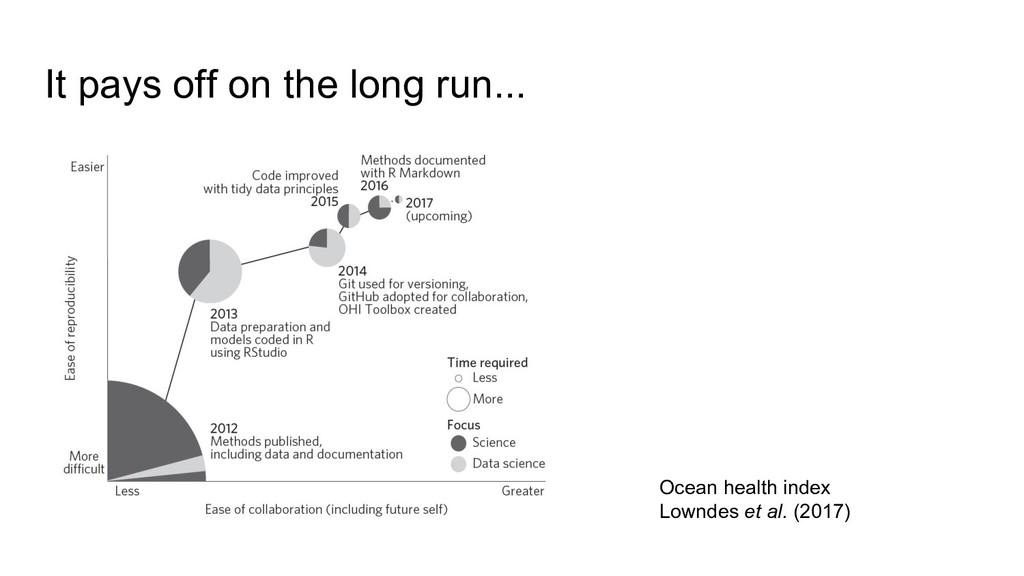
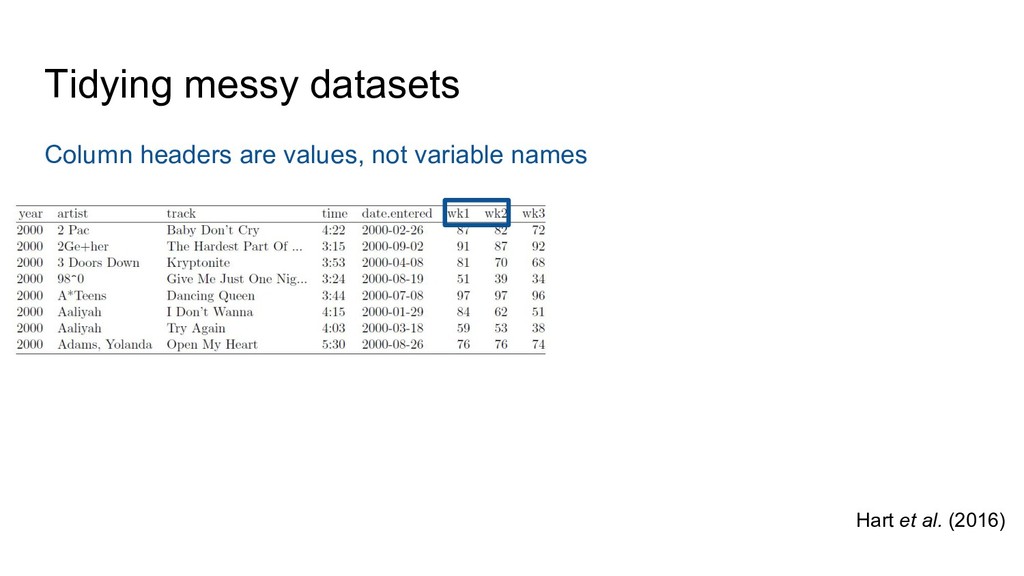
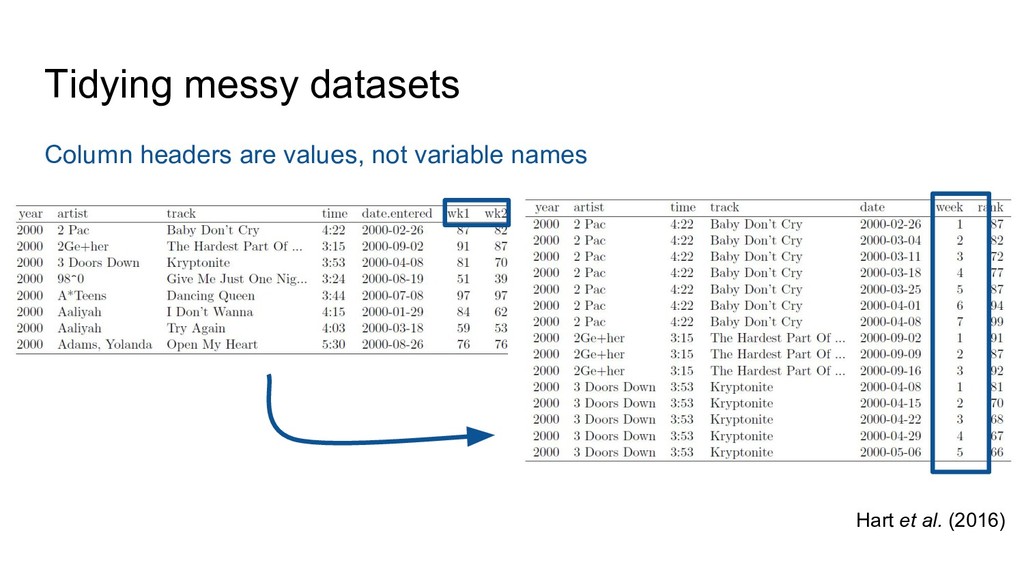
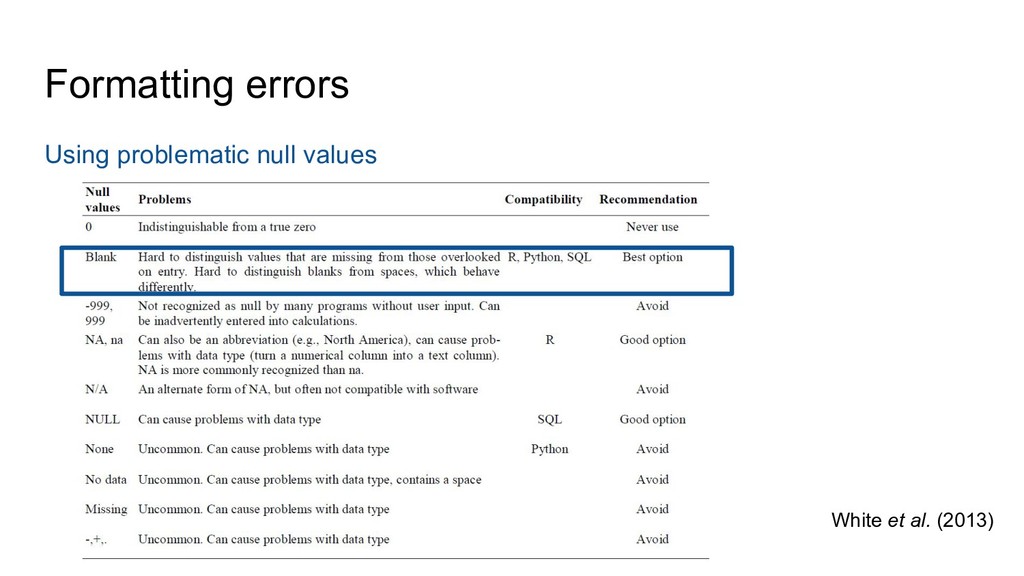
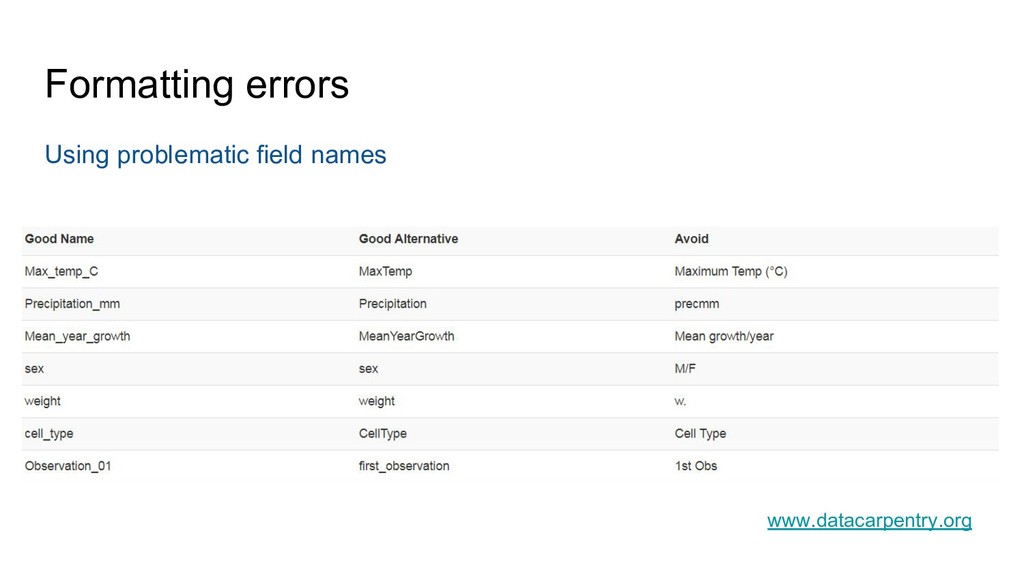
Groth, Hedstrom, Hogg, Kashyap, Mahabal, Siemiginowska, Slavkovic (2014) Ten Simple Rules for the Care and Feeding of Scientific Data. PLoS Comput Biol 10(4): e1003542. doi:10.1371/journal.pcbi.1003542 Hart, Barmby, LeBauer, Michonneau, Mount, Mulrooney, Poisot, Woo, Zimmerman, Hollister (2016) Ten Simple Rules for Digital Data Storage. PLoS Comput Biol 12(10): e1005097. doi:10.1371/journal.pcbi.1005097 Lowndes, Best, Scarborough, Afflerbach, Frazier, O’Hara, Jiang, Halpern (2017) Our path to better science in less time using open data science tools. Nature Ecology & Evolution, 1: 0160 doi:10.1038/s41559-017-0160 White, Baldridge, Brym, Locey, McGlinn, Supp (2013) Nine simple ways to make it easier to (re)use your data. Ideas in Ecology and Evolution 6(2): 1–10. doi:10.4033/iee.2013.6b.6.f
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}