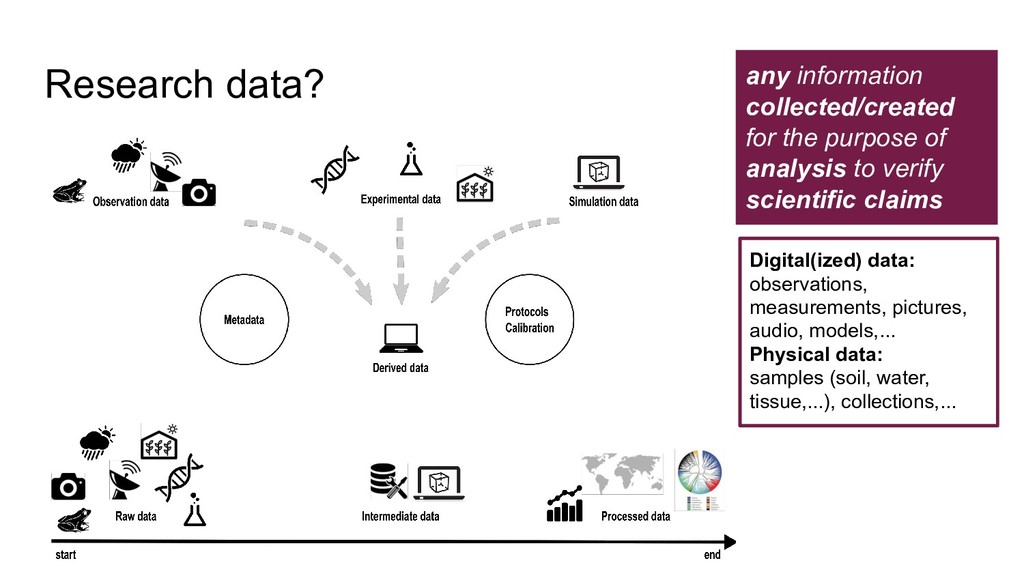
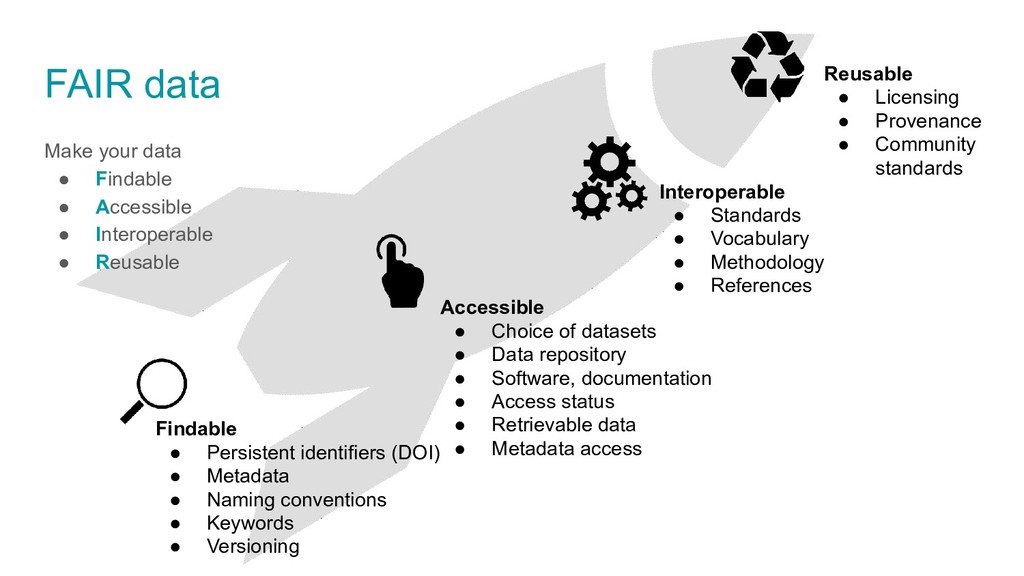
Research data management in biodiversity research. Data organization, data quality, documentation, preservation and publication using the FAIR principles.
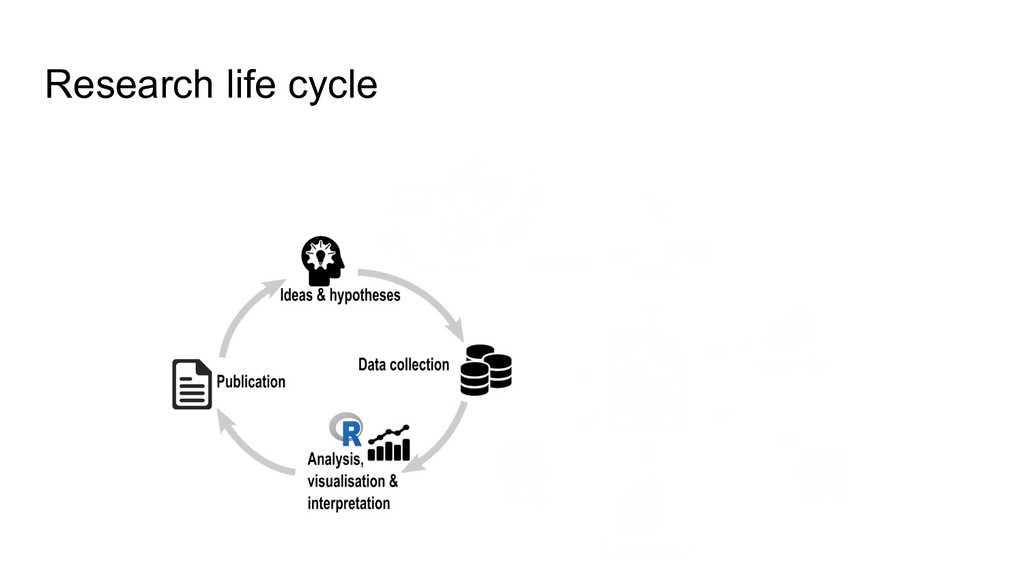
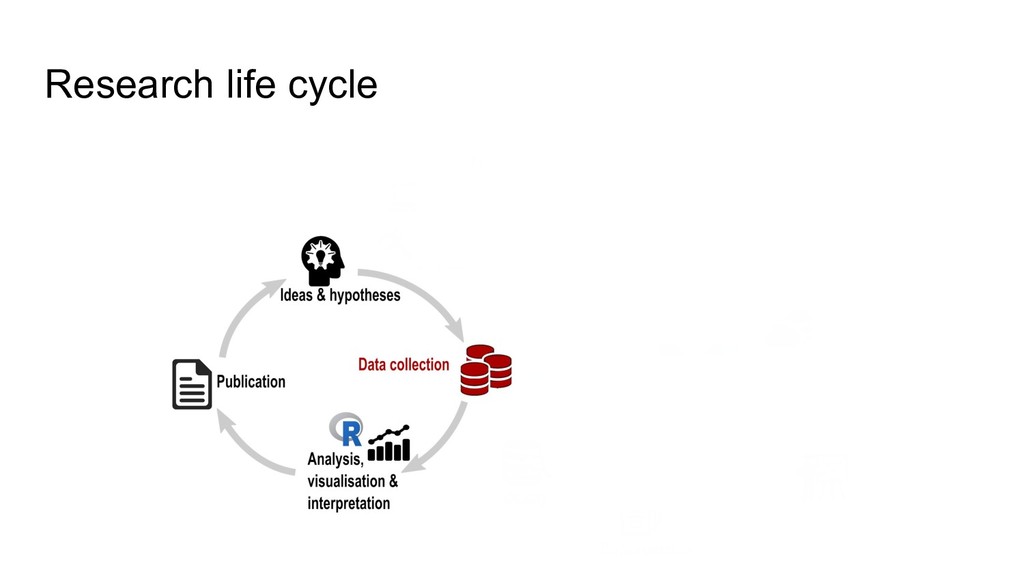
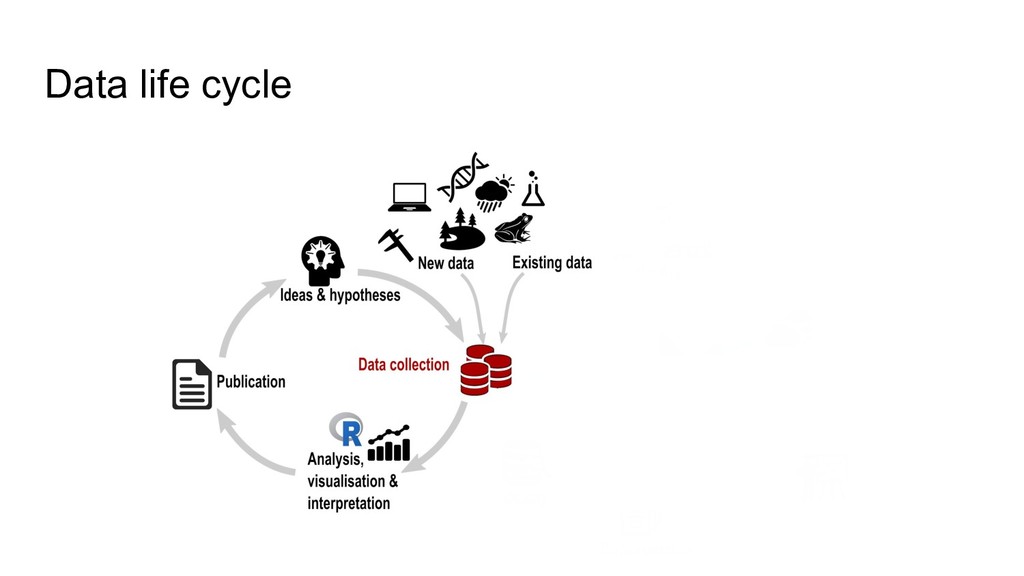
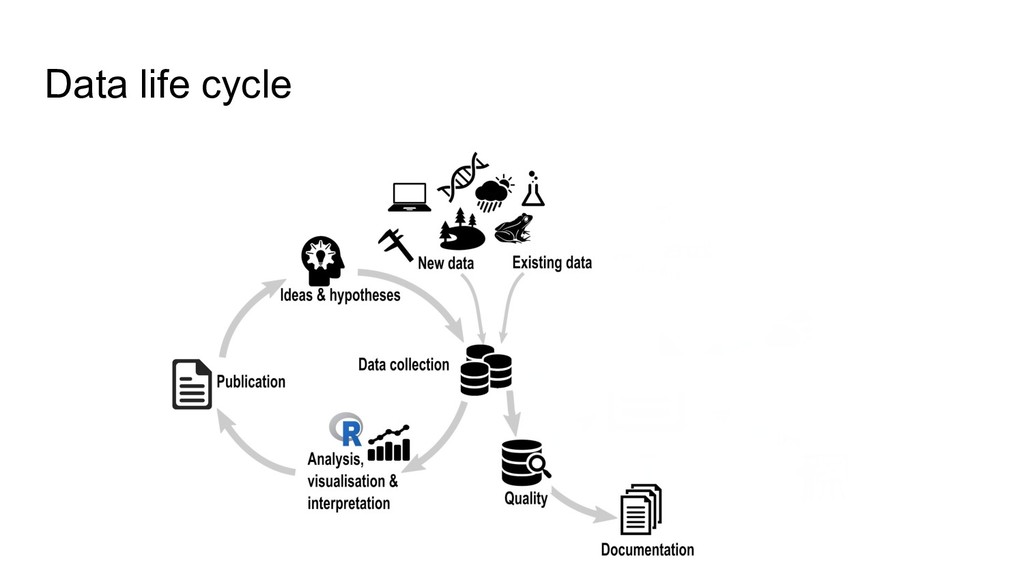
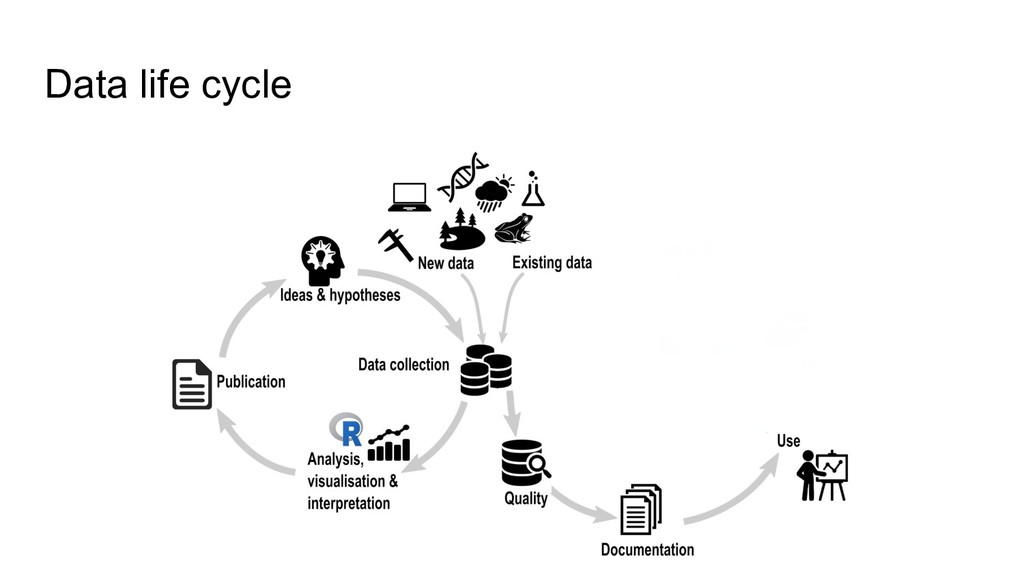
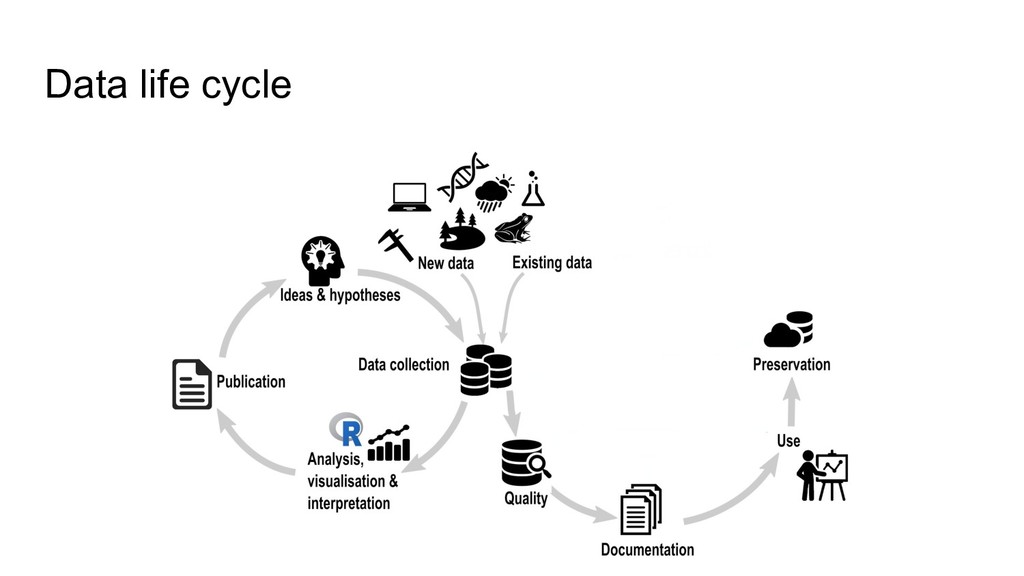
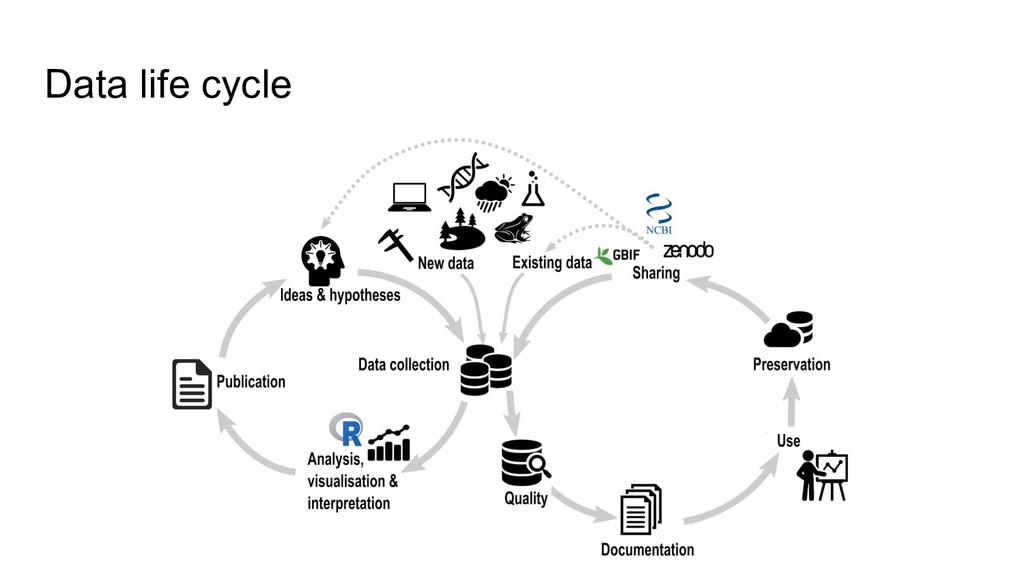
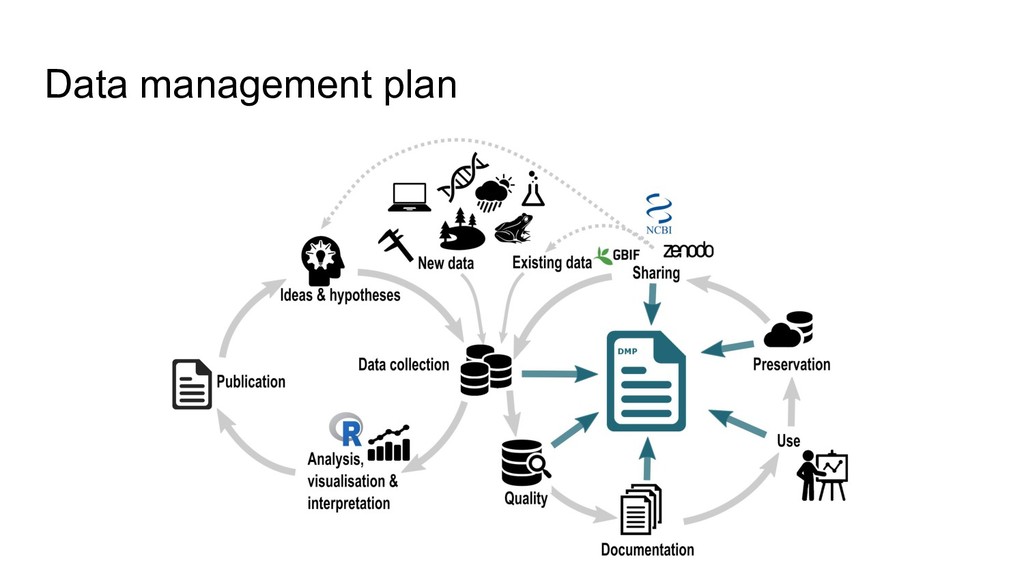
higher data quality, less mistakes • increased research efficiency • minimized risk of data loss, less frustrations • saved time & money • prevent to collect duplicate data RDM concerns the organization of data, from its entry to the research cycle to the dissemination and archiving of valuable results
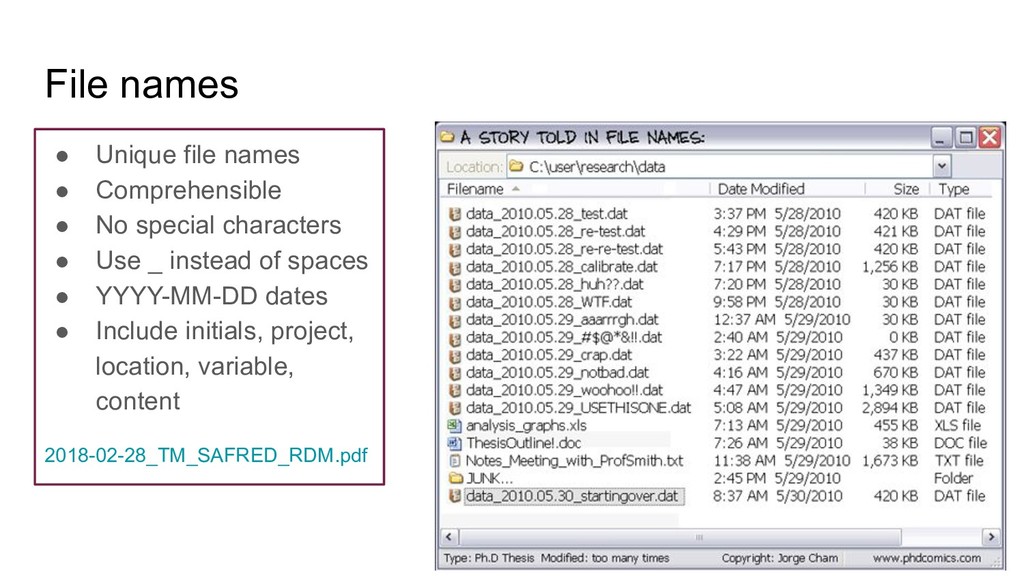
Easily reusable • Commonly used • Structured folder system • Naming conventions Some preferred file formats Tabular data .csv (comma separated values), HDF5, netcdf, rdf Text .txt, html, xml, odt, rtf Still images .tif, jpeg2000, png, pdf, gif, bmp, svg “Love your data, and help other love it, too” (Goodman et al, 2014)
<- The top-level README describing the general layout of the project |- data | |- raw <- The original, read-only acquired raw data | |- interim <- Intermediate data that has been transformed. | |- processed <- final data products, used in the report/paper/graphs | |_ external <- used additional third party data resources (e.g. vector maps) |- reports <- reported outcome of the analysis as LaTeX, word, markdown,... | |_ figures <- Generated graphics and figures to be used in reporting |- src <- set of analysis scripts used in the analysis “Keep raw data raw!” (Hart et al, 2016)
• Keep changes small • Share changes frequently Manually track changes • Add a CHANGELOG.txt • Copy entire project after large changes Version control system • Git • GitHub, Bitbucket, Gitlab,... File naming conventions: file_v1, file_v2 Use a version control system (recommended)
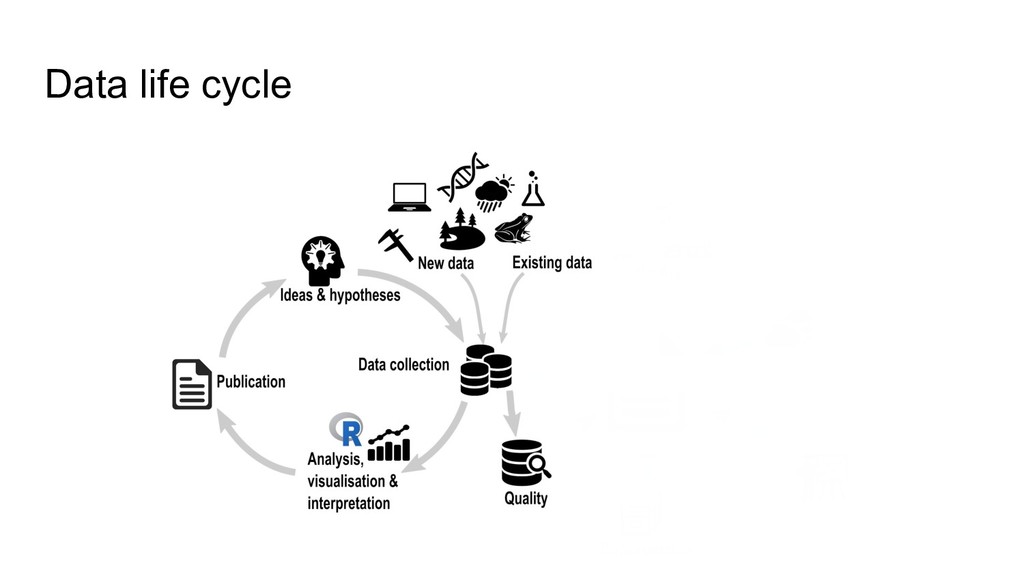
data type, description • Explain codes & abbreviations • Code & reason for missing values • Code used for derived data • File format • Software • Data standards
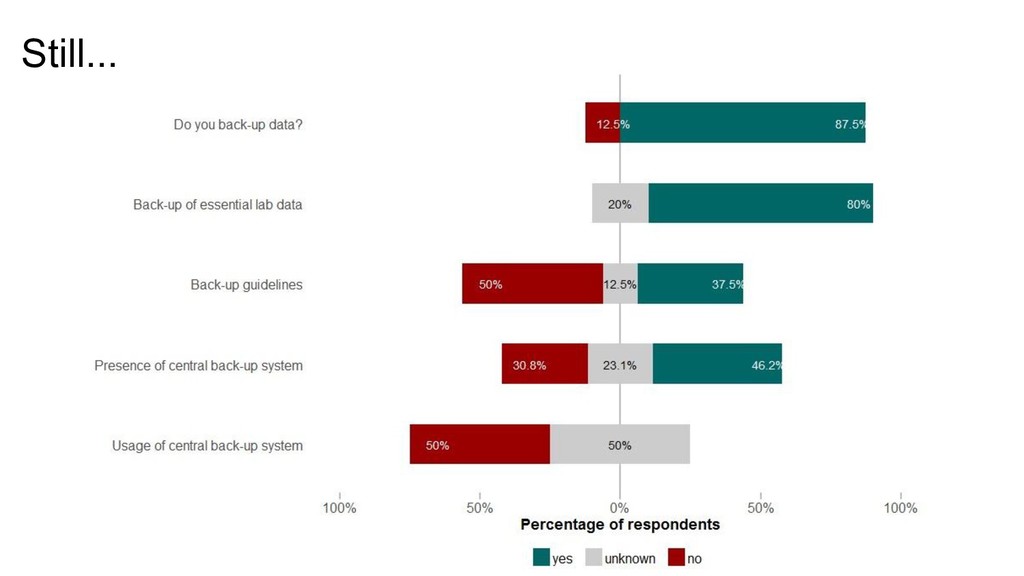
has lost data… • Hardware theft or misplacement • Hardware failure • Hardware damage • Software faults • Power failure • Viruses or hacking • Human errors • Backups
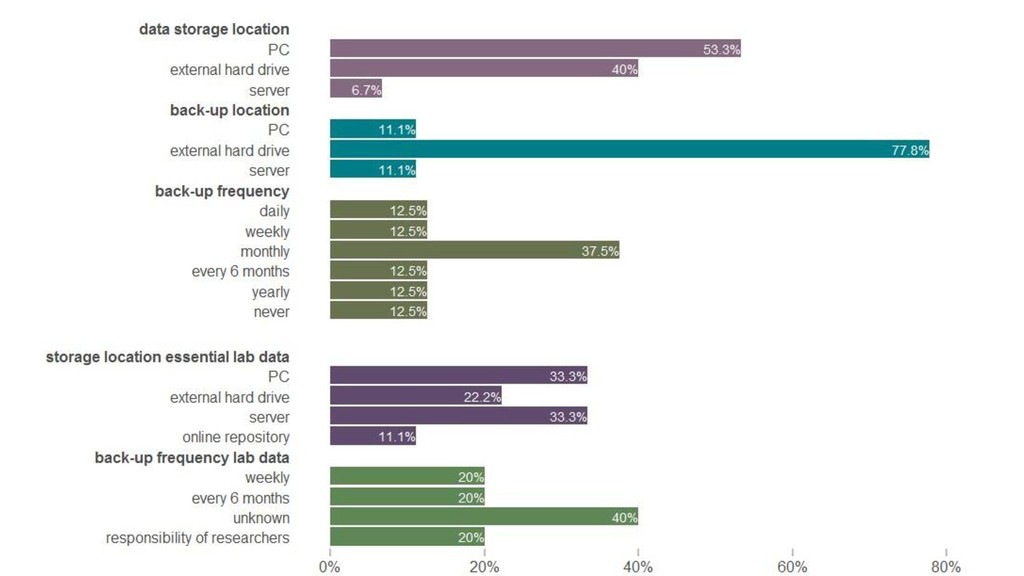
Size? • Responsible • Frequency of full backups • Frequency of partial backups • Organization of backup files “Have a systematic backup scheme” (Hart et al, 2016)
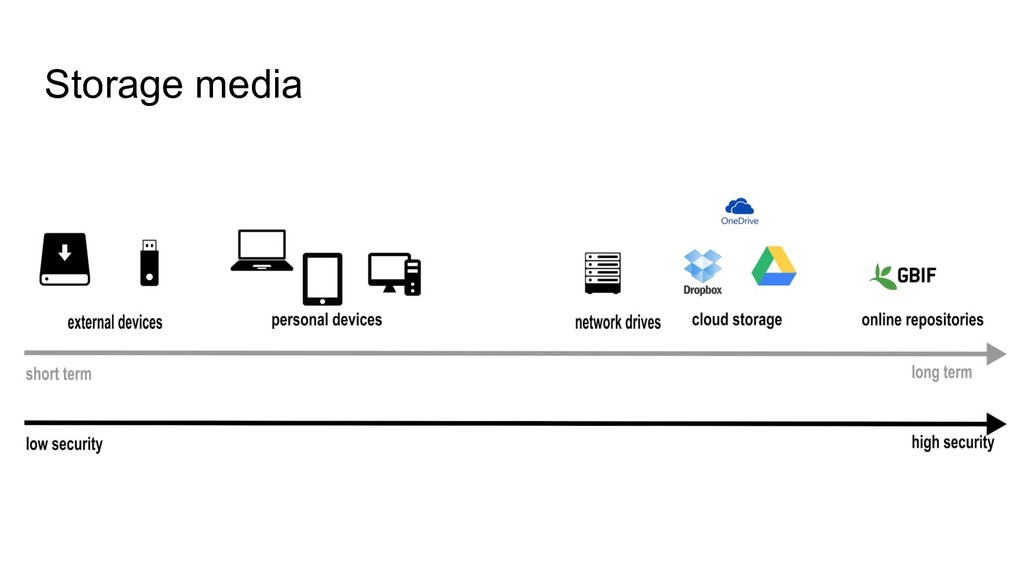
• While still active • >1 location: hard drives, servers, laptops,... • Easy to modify files, but also to delete or lose them Archiving & publishing • Long-term monitoring projects • After finishing short-term projects • Deposited in a digital repository • Safeguarded & preserved both!
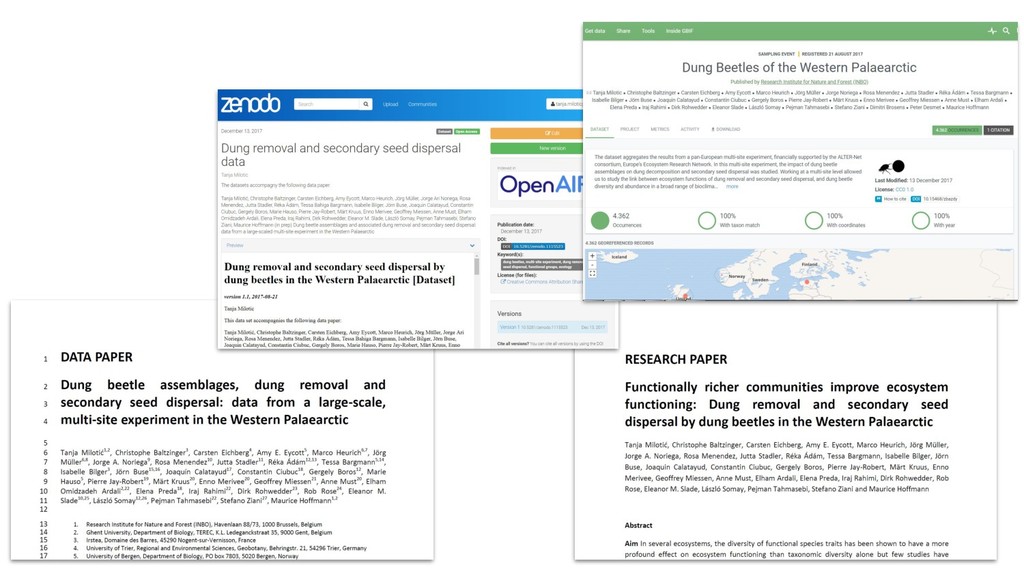
Domain specific repositories ◦ GBIF for species occurrences ◦ Genbank for genomic data ◦ ... • General repositories (Zenodo, dataDryad,...) • ORCID integration • DOI for citing datasets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}