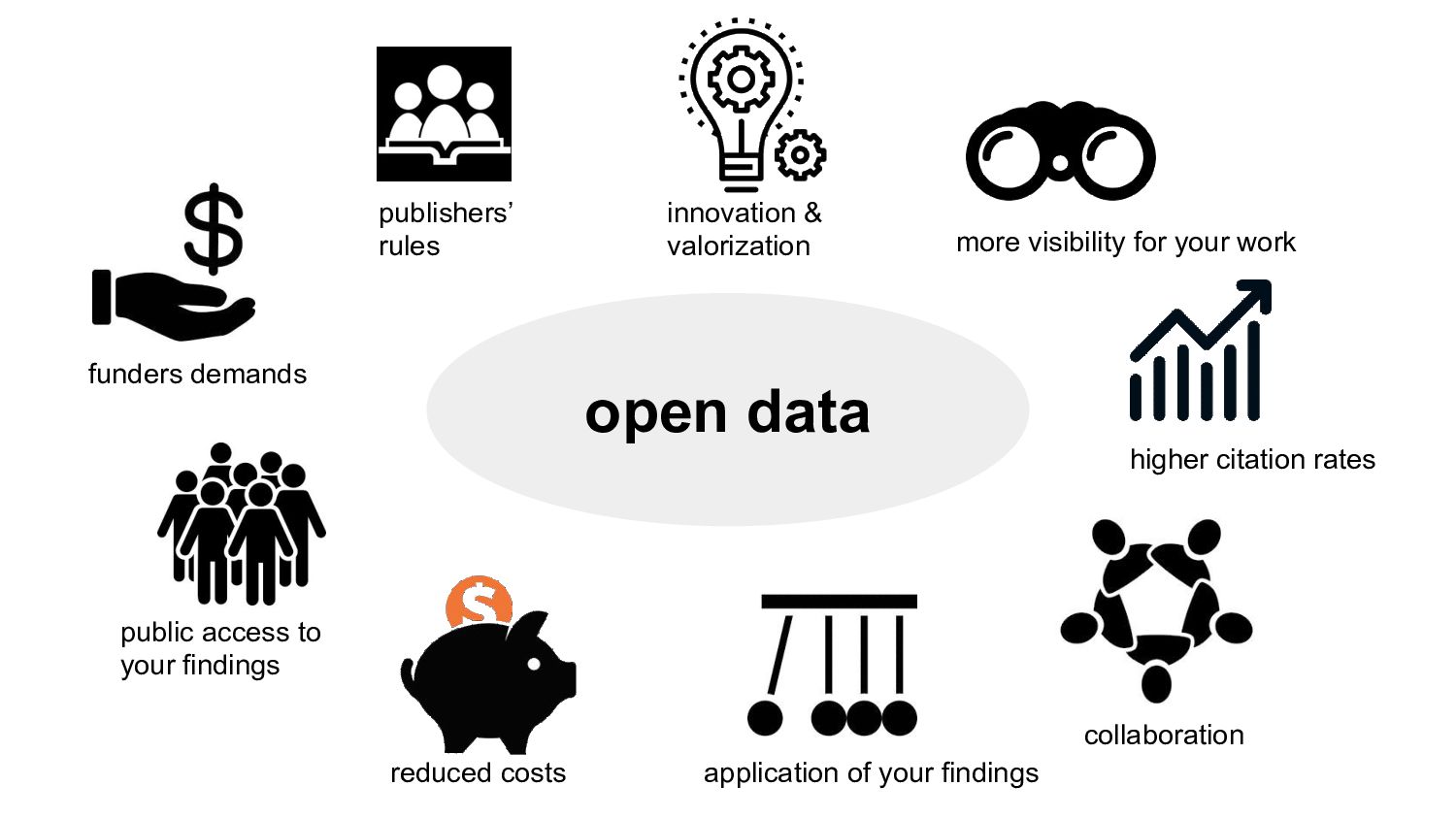
higher data quality, less mistakes • increased research efficiency • minimized risk of data loss, less frustrations • saved time & money • prevent to collect duplicate data
• required by funders & publishers • increase your visibility (citations!) • easy data sharing • new collaboration opportunities “Research data management is part of good research practice”
(RDM) concerns the organization of data, from its entry to the research cycle to the dissemination and archiving of valuable results Data management plan (DMP)
<- The top-level README describing the general layout of the project |- data <- research data | |- raw <- The original, read-only acquired raw data | |- interim <- Intermediate data that has been transformed. | |- processed <- final data products, used in the report/paper/graphs | |_ external <- used additional third party data resources (e.g. vector maps) |- reports <- reported outcome of the analysis as LaTeX, word, markdown,... | |_ figures <- Generated graphics and figures to be used in reporting |- src <- set of analysis scripts used in the analysis “Keep raw data raw!” (Hart et al, 2016)
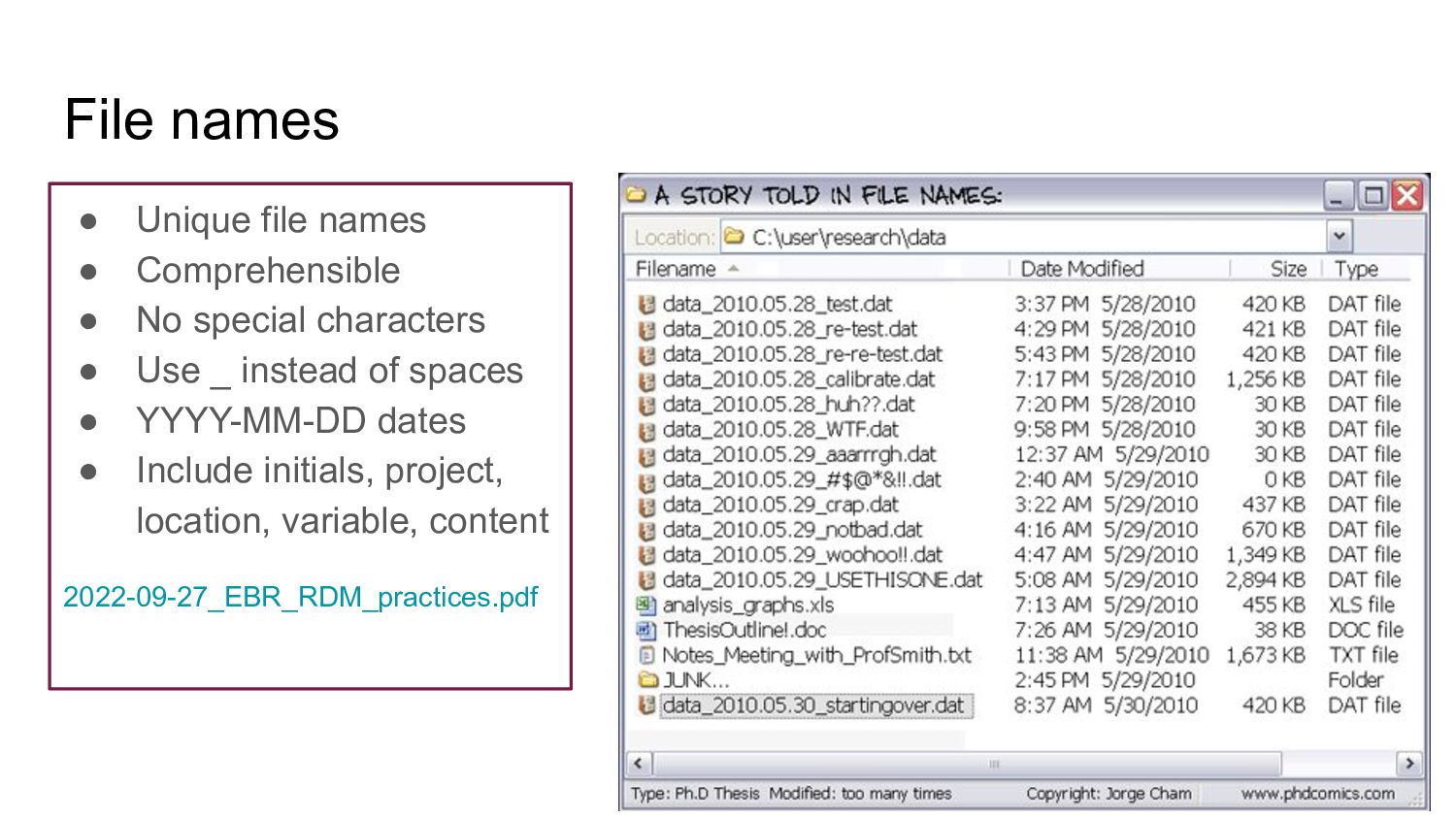
special characters • Use _ instead of spaces • YYYY-MM-DD dates • Include initials, project, location, variable, content 2022-09-27_EBR_RDM_practices.pdf
• Keep changes small • Share changes frequently Manually track changes • Add a CHANGELOG.txt • Copy entire project after large changes Version control system • Git • GitHub, Bitbucket, Gitlab,... File naming conventions: file_v1, file_v2 Use a version control system (recommended)
Easily reusable • Commonly used Some preferred file formats Tabular data .csv (comma separated values), HDF5, netcdf, rdf Text .txt, html, xml, odt, rtf Still images .tif, jpeg2000, png, pdf, gif, bmp, svg “Love your data, and help other love it, too” (Goodman et al, 2014)
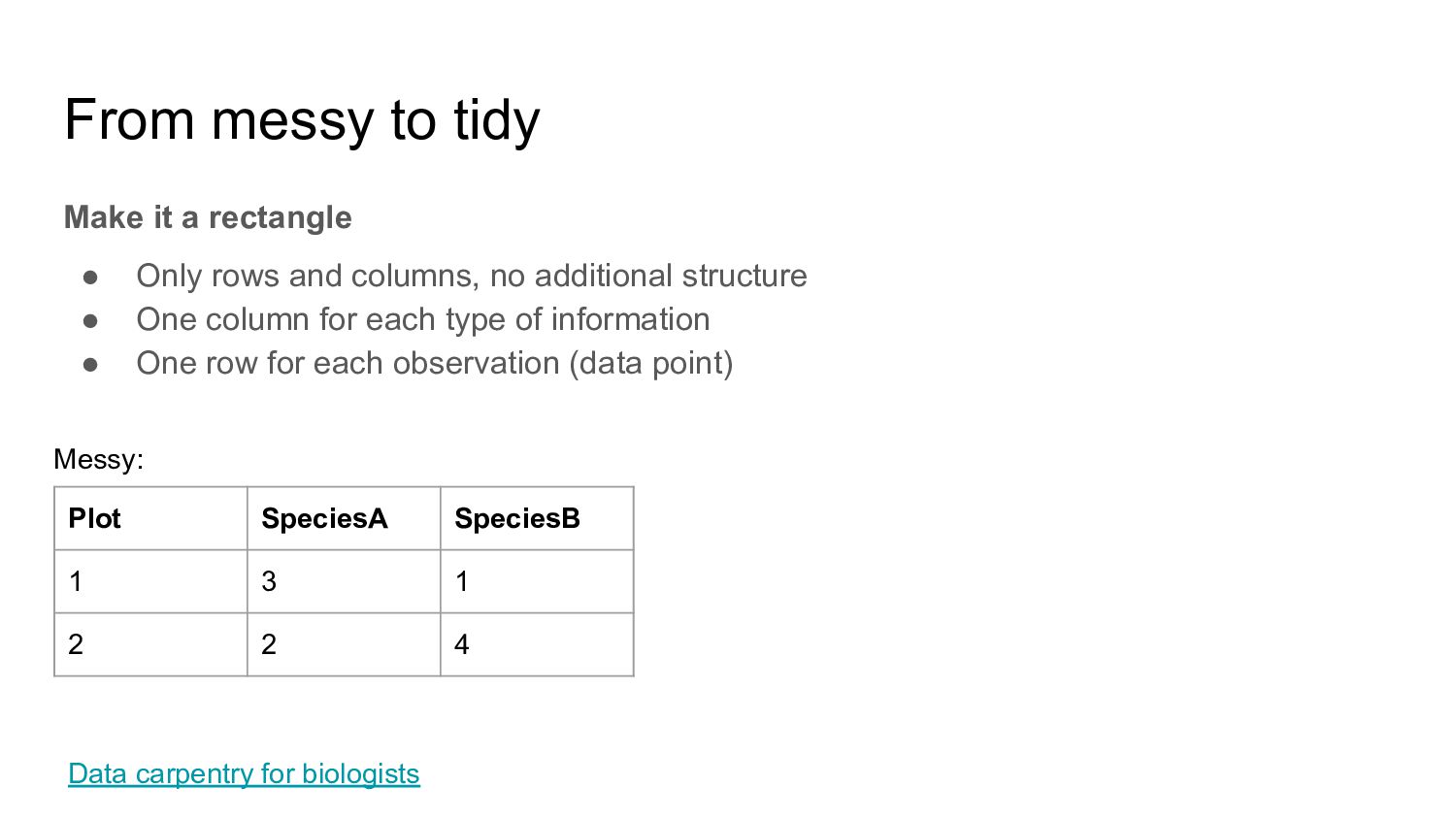
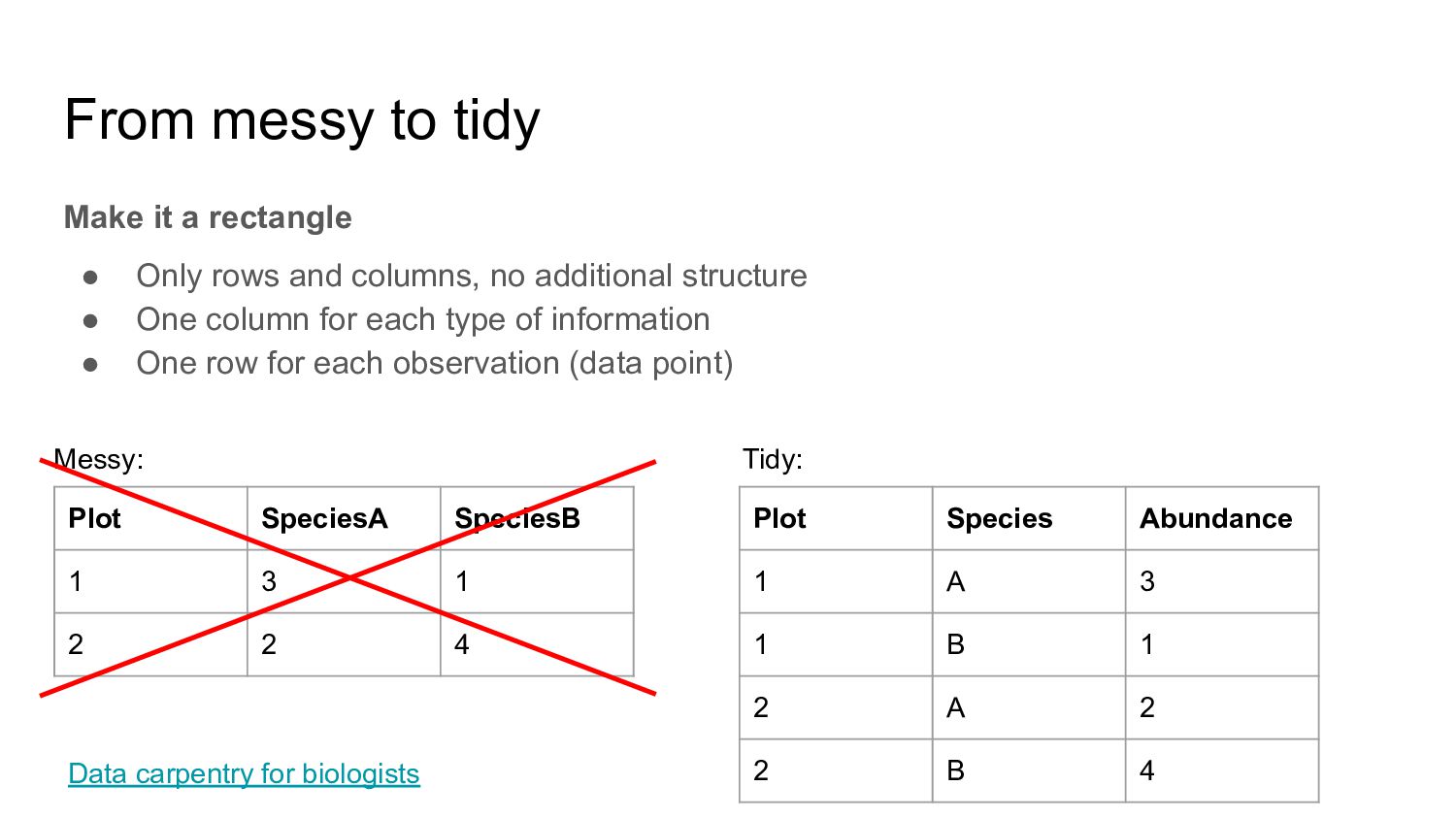
rows and columns, no additional structure • One column for each type of information • One row for each observation (data point) Data carpentry for biologists Plot SpeciesA SpeciesB 1 3 1 2 2 4 Messy:
rows and columns, no additional structure • One column for each type of information • One row for each observation (data point) Data carpentry for biologists Plot SpeciesA SpeciesB 1 3 1 2 2 4 Messy: Plot Species Abundance 1 A 3 1 B 1 2 A 2 2 B 4 Tidy:
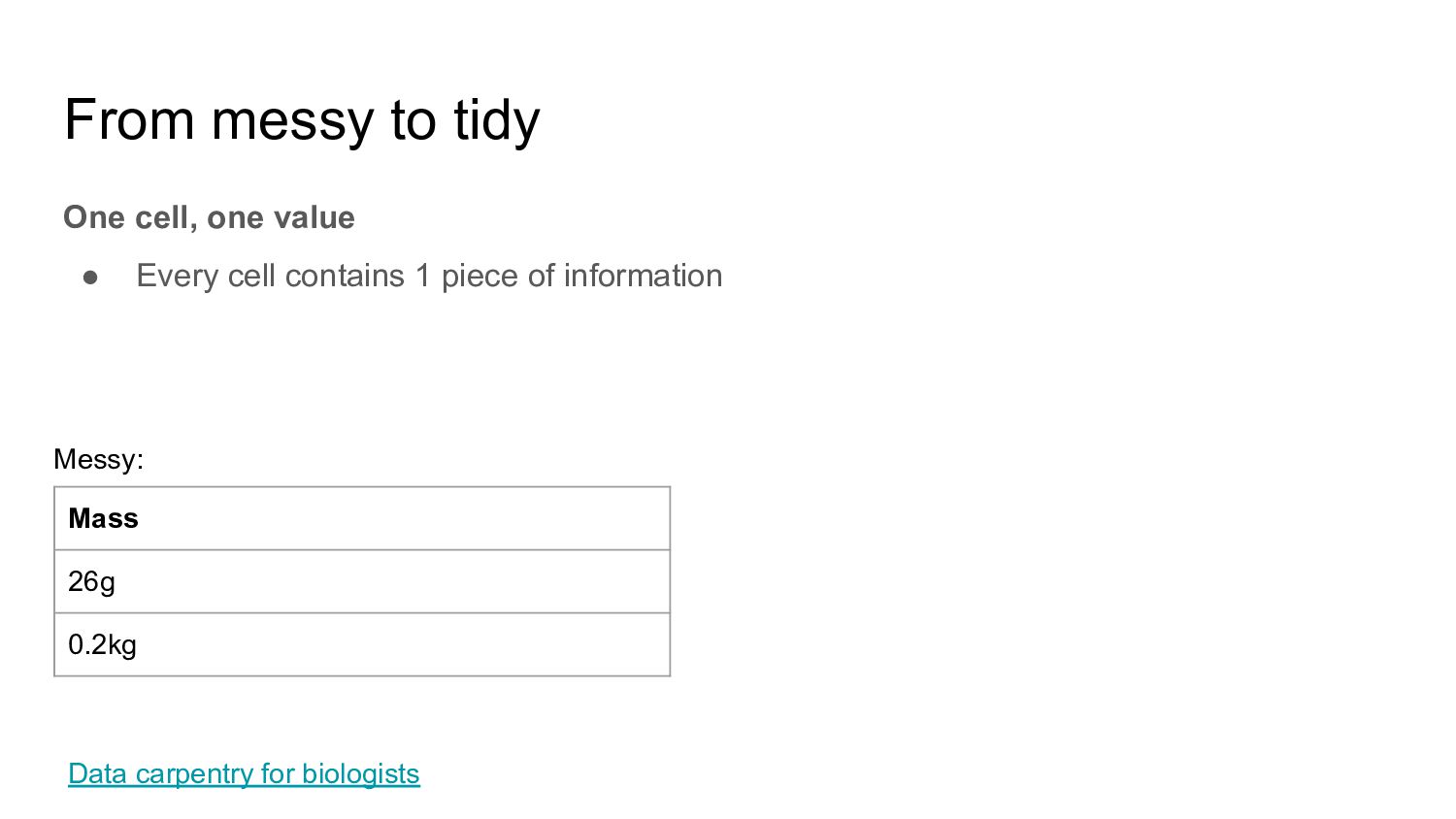
Don’t use visual markings (colors, italics, fonts,...) • Avoid spaces in names, use ‘_’ or CamelCase for multiple words • Avoid special characters (*, @, ^,...) Data carpentry for biologists Min temp 5 4.5 3.1* Messy:
Don’t use visual markings (colors, italics, fonts,...) • Avoid spaces in names, use ‘_’ or CamelCase for multiple words • Avoid special characters (*, @, ^,...) Data carpentry for biologists Min temp 5 4.5 3.1* Messy: min_temp calibration_error 5 0 4.5 0 3.1 1 Tidy:
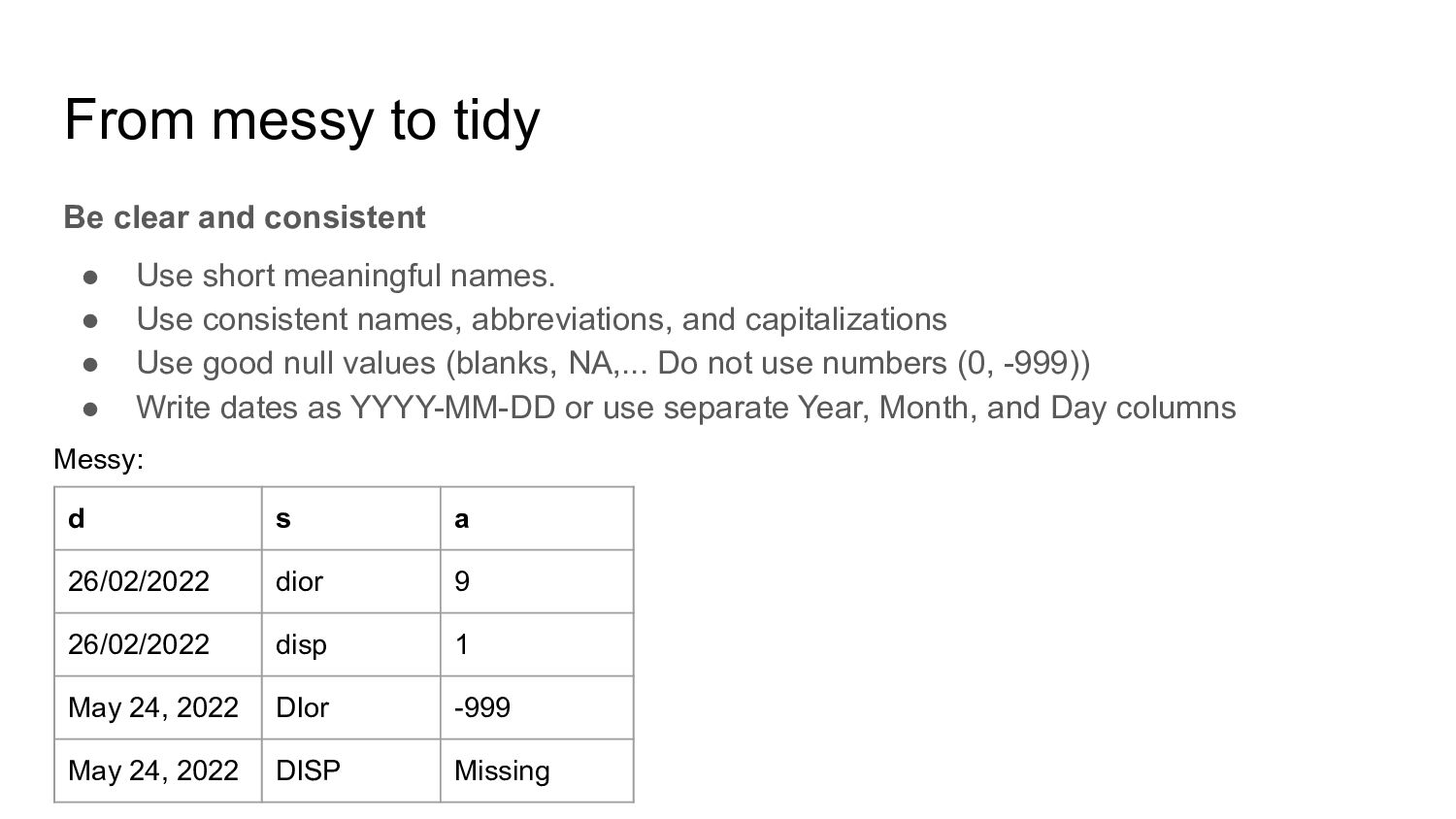
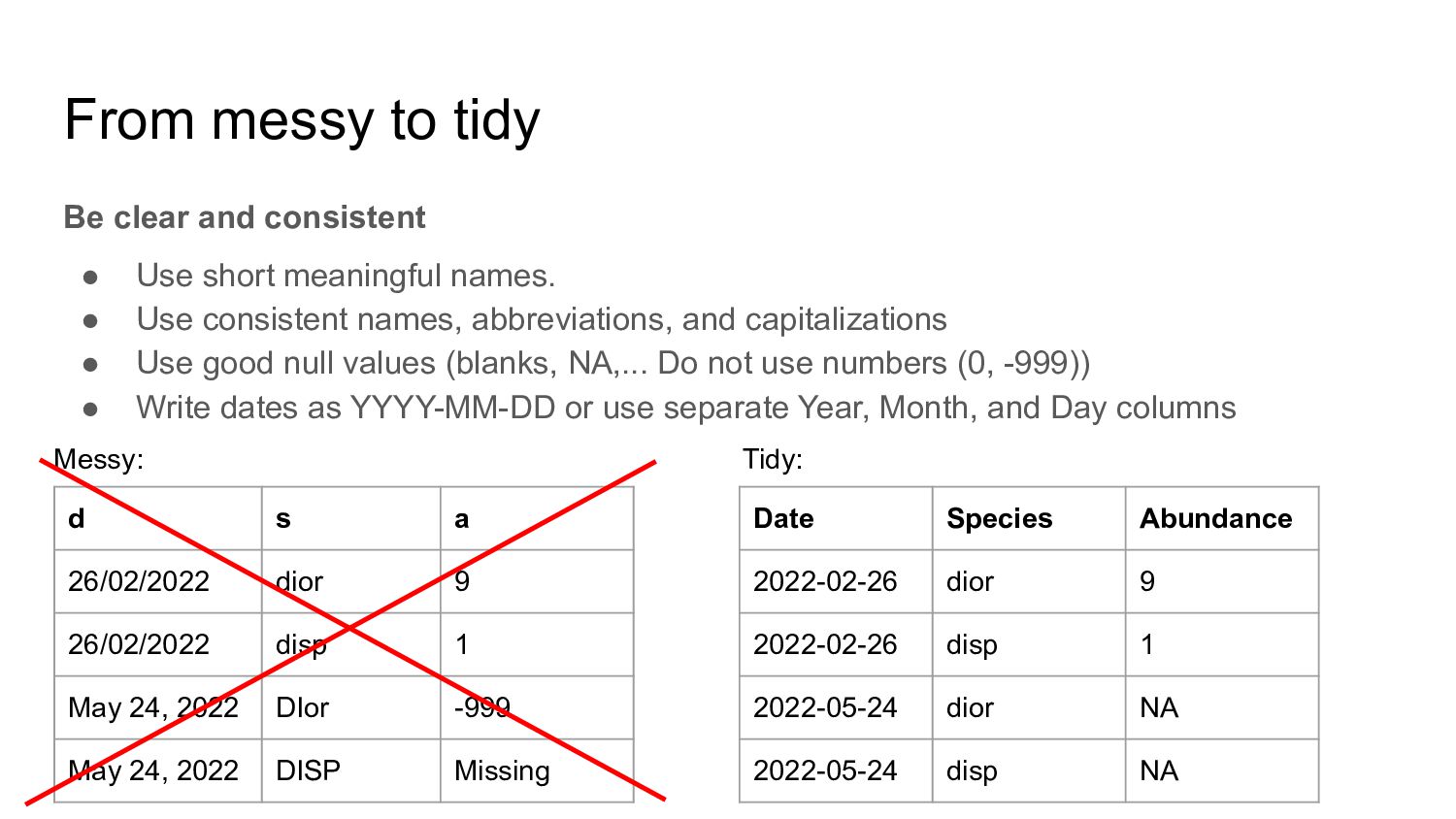
short meaningful names. • Use consistent names, abbreviations, and capitalizations • Use good null values (blanks, NA,... Do not use numbers (0, -999)) • Write dates as YYYY-MM-DD or use separate Year, Month, and Day columns d s a 26/02/2022 dior 9 26/02/2022 disp 1 May 24, 2022 DIor -999 May 24, 2022 DISP Missing Messy:
short meaningful names. • Use consistent names, abbreviations, and capitalizations • Use good null values (blanks, NA,... Do not use numbers (0, -999)) • Write dates as YYYY-MM-DD or use separate Year, Month, and Day columns d s a 26/02/2022 dior 9 26/02/2022 disp 1 May 24, 2022 DIor -999 May 24, 2022 DISP Missing Messy: Date Species Abundance 2022-02-26 dior 9 2022-02-26 disp 1 2022-05-24 dior NA 2022-05-24 disp NA Tidy:
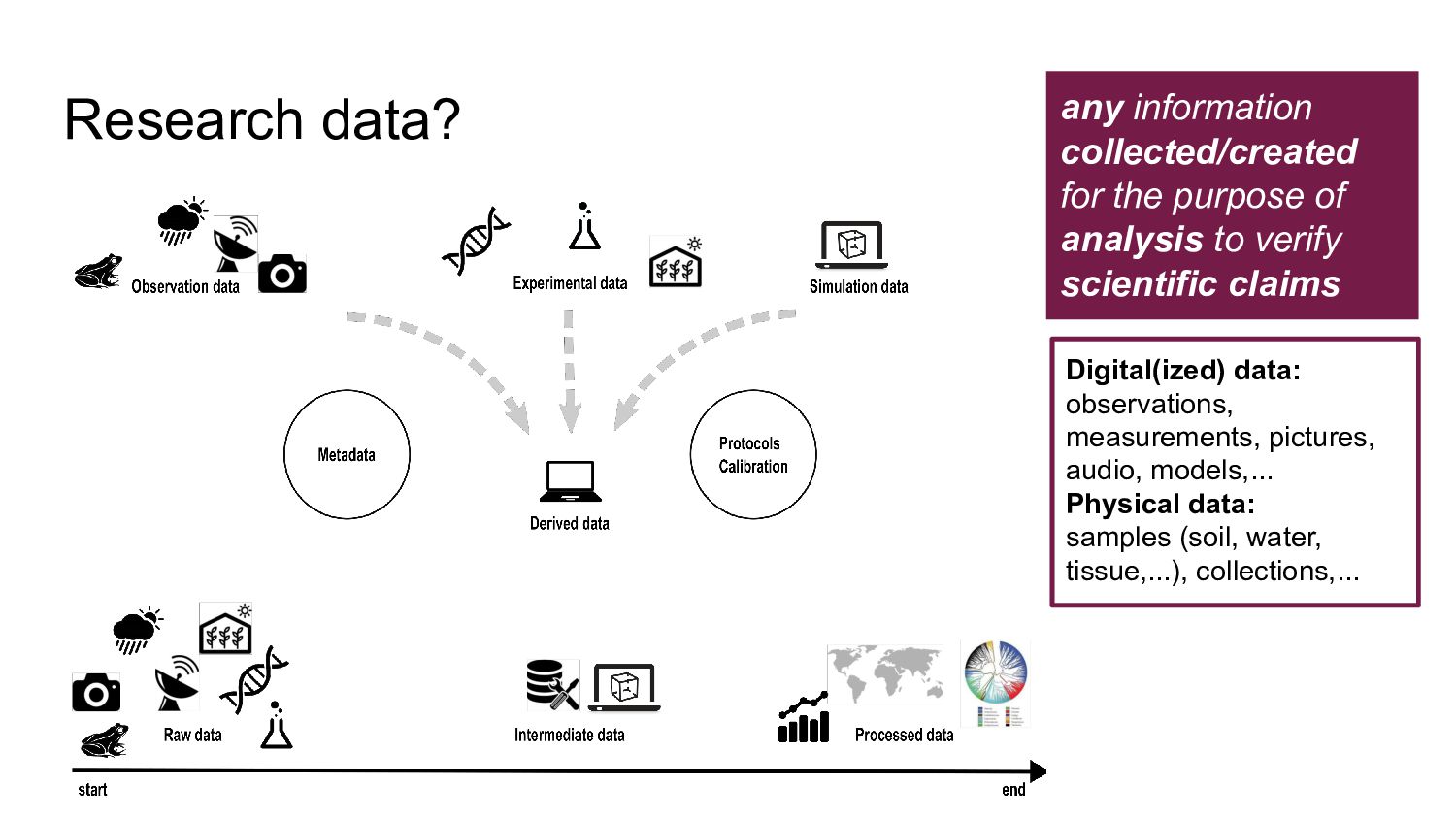
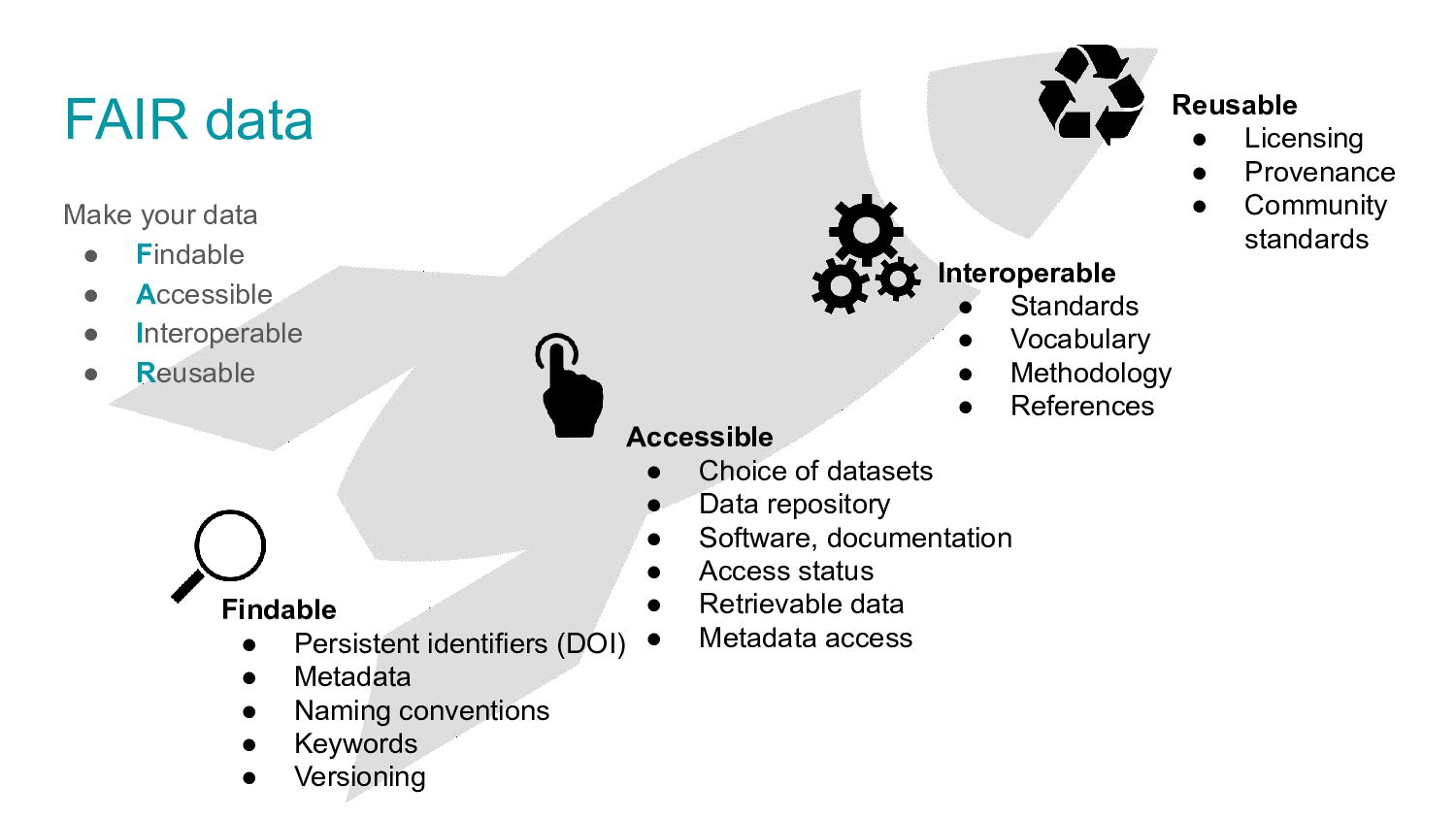
data type, description • Explain codes & abbreviations • Code & reason for missing values • Code used for derived data • File format • Software • Data standards
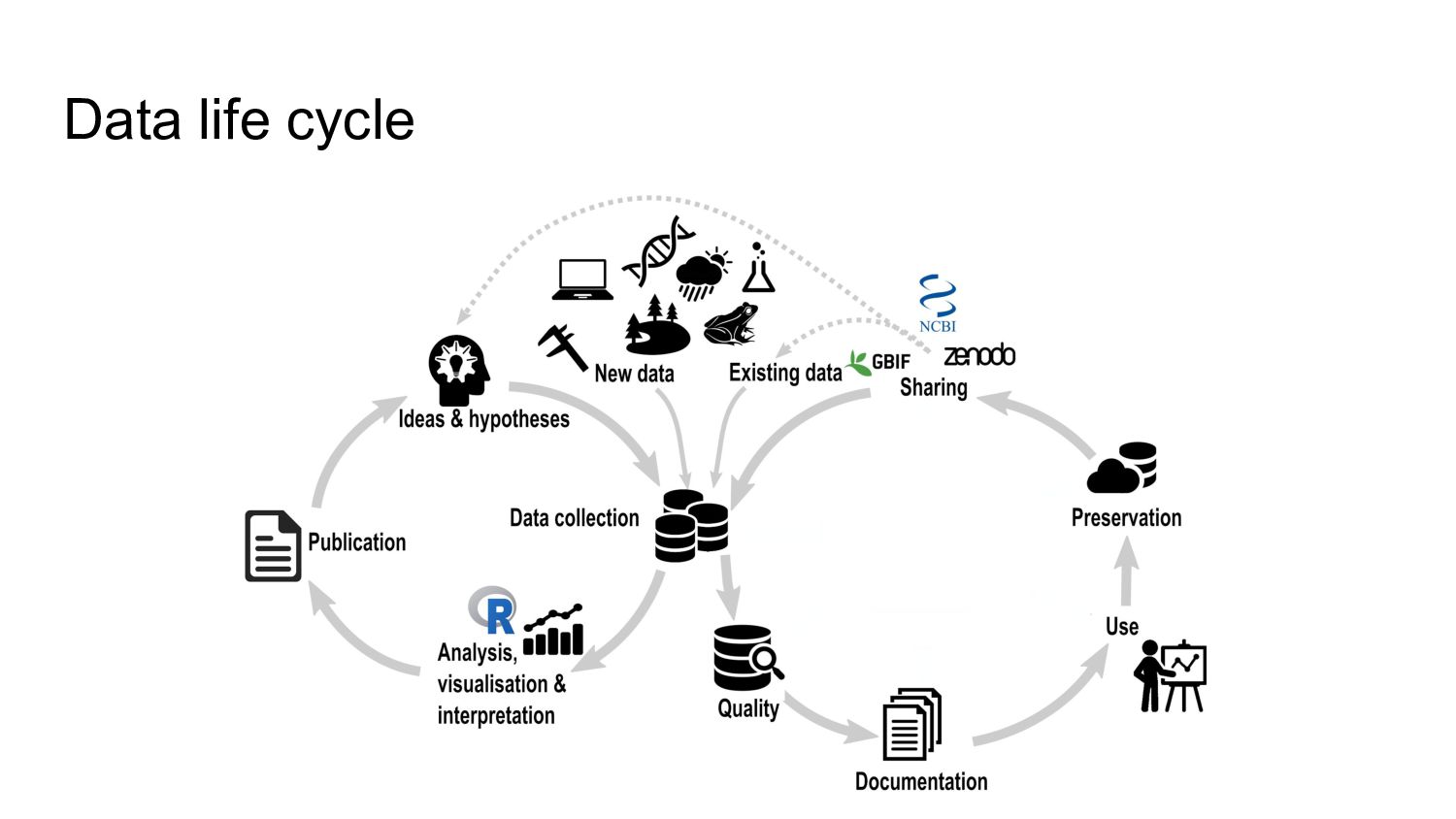
Domain specific repositories ◦ GBIF for species occurrences ◦ Movebank for movement data ◦ Genbank for genomic data ◦ ... • General repositories (Zenodo, dataDryad,...) • ORCID integration • DOI for citing datasets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}