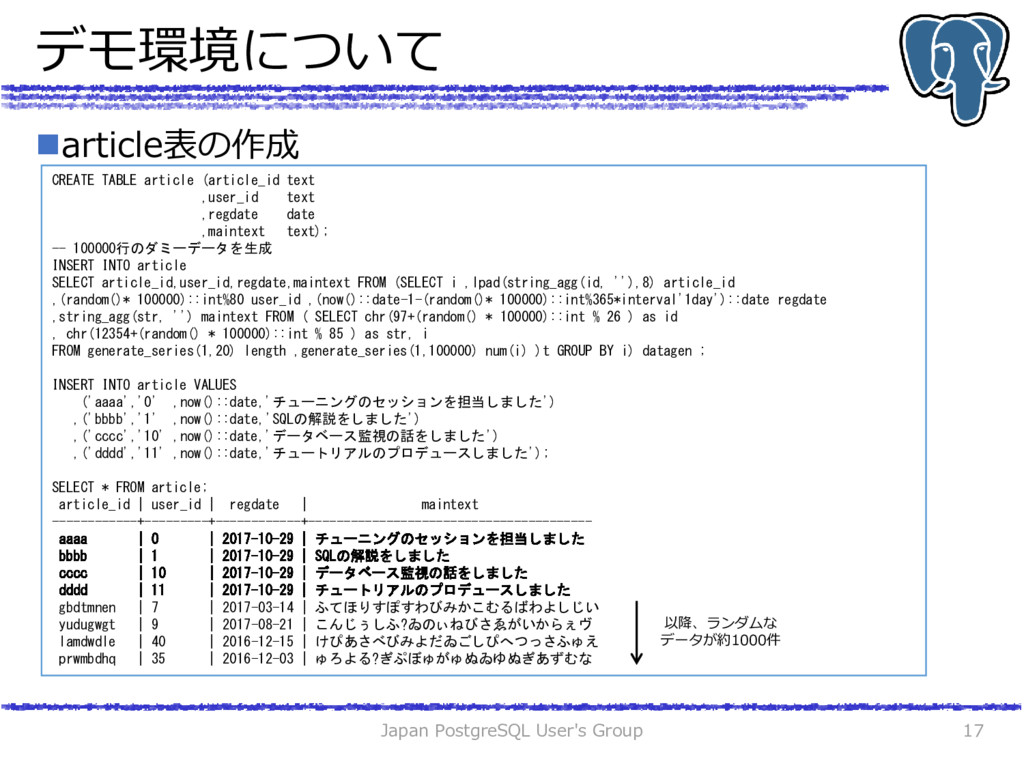
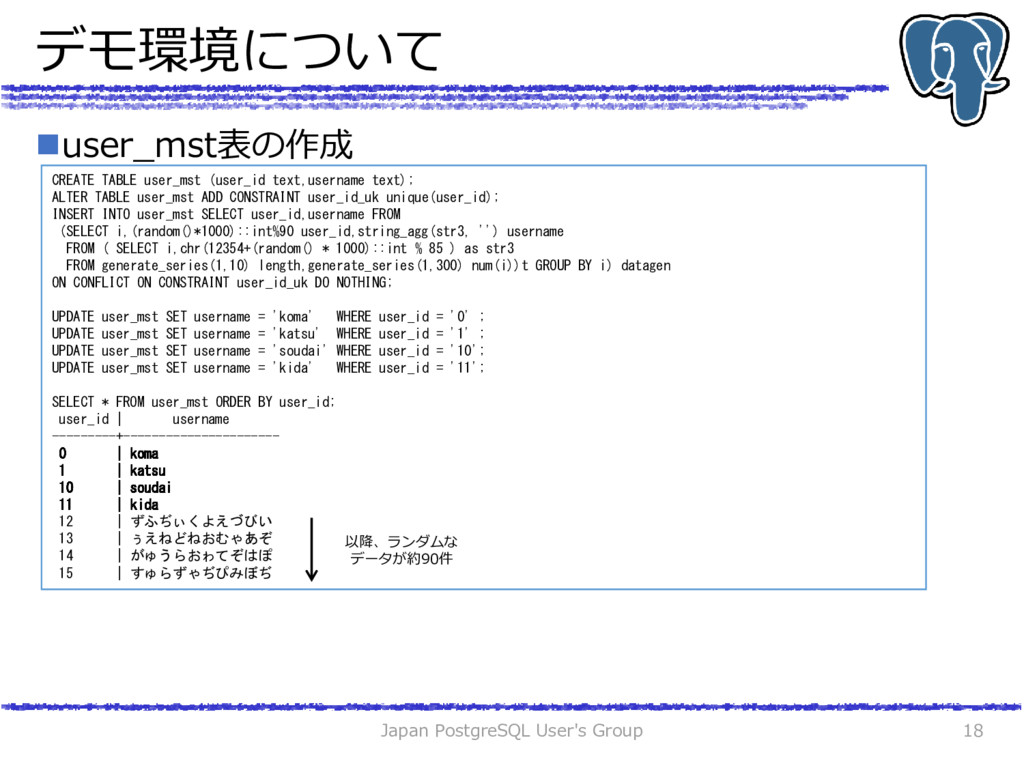
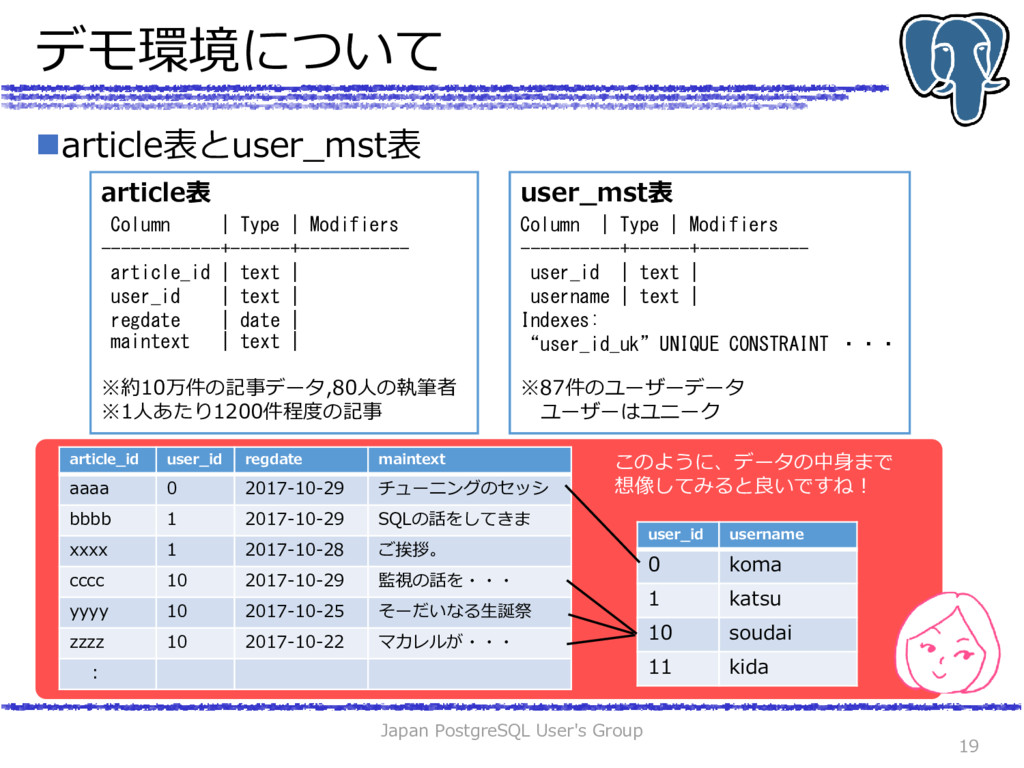
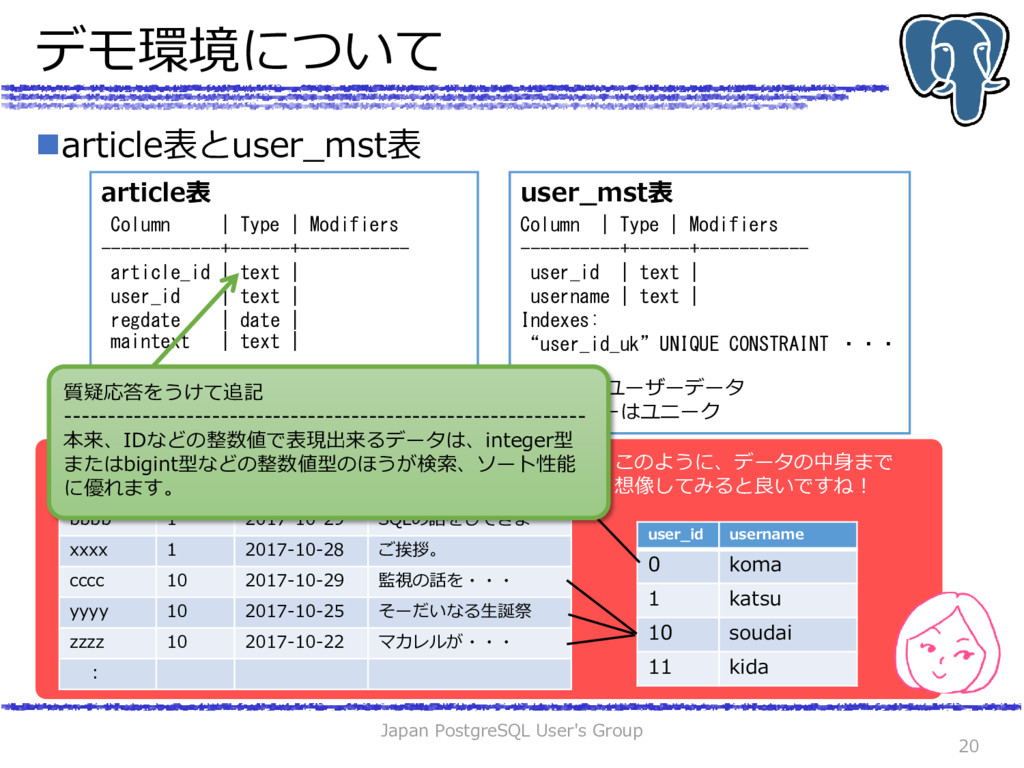
(article_id text ,user_id text ,regdate date ,maintext text); -- 100000行のダミーデータを生成 INSERT INTO article SELECT article_id,user_id,regdate,maintext FROM (SELECT i ,lpad(string_agg(id, ''),8) article_id ,(random()* 100000)::int%80 user_id ,(now()::date-1-(random()* 100000)::int%365*interval'1day')::date regdate ,string_agg(str, '') maintext FROM ( SELECT chr(97+(random() * 100000)::int % 26 ) as id , chr(12354+(random() * 100000)::int % 85 ) as str, i FROM generate_series(1,20) length ,generate_series(1,100000) num(i) )t GROUP BY i) datagen ; INSERT INTO article VALUES ('aaaa','0' ,now()::date,'チューニングのセッションを担当しました') ,('bbbb','1' ,now()::date,'SQLの解説をしました') ,('cccc','10' ,now()::date,'データベース監視の話をしました') ,('dddd','11' ,now()::date,'チュートリアルのプロデュースしました'); SELECT * FROM article; article_id | user_id | regdate | maintext ------------+---------+------------+---------------------------------------- aaaa | 0 | 2017-10-29 | チューニングのセッションを担当しました bbbb | 1 | 2017-10-29 | SQLの解説をしました cccc | 10 | 2017-10-29 | データベース監視の話をしました dddd | 11 | 2017-10-29 | チュートリアルのプロデュースしました gbdtmnen | 7 | 2017-03-14 | ふてほりすぽすわびみかこむるばわよしじい yudugwgt | 9 | 2017-08-21 | こんじぅしふ?ゐのぃねびさゑがいからぇヴ lamdwdle | 40 | 2016-12-15 | けぴあさべびみよだゐごしぴへつっさふゅえ prwmbdhq | 35 | 2016-12-03 | ゅろよる?ぎぷぼゅがゅぬゐゆぬぎあずむな 以降、ランダムな データが約1000件
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
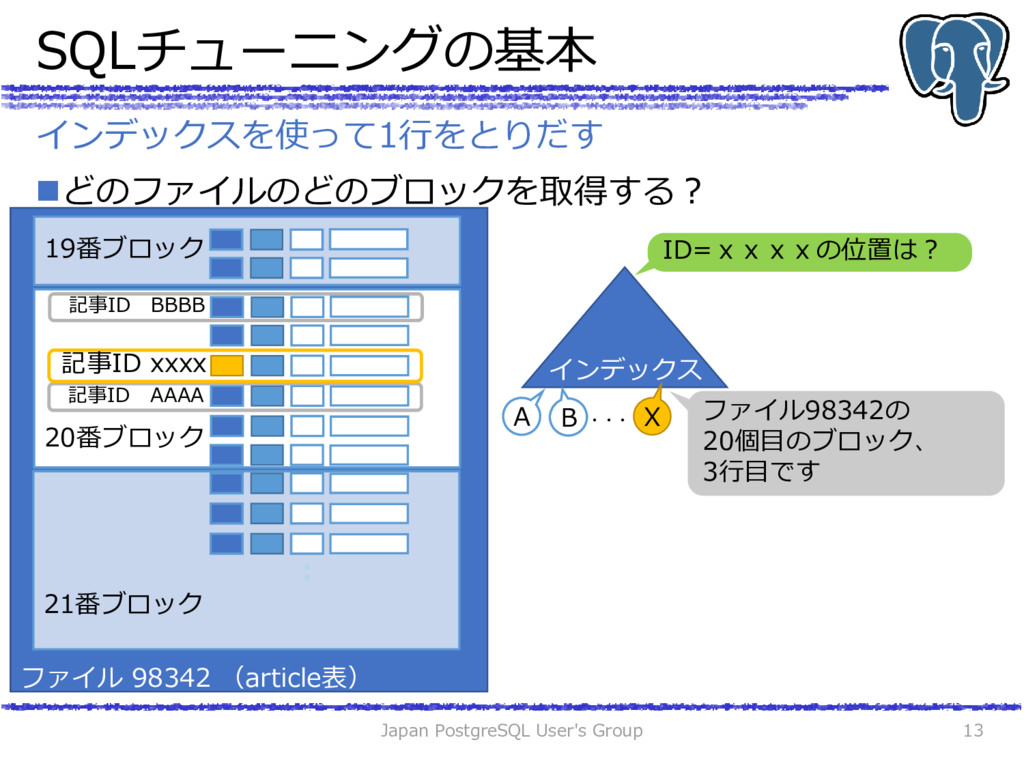{kind=link}
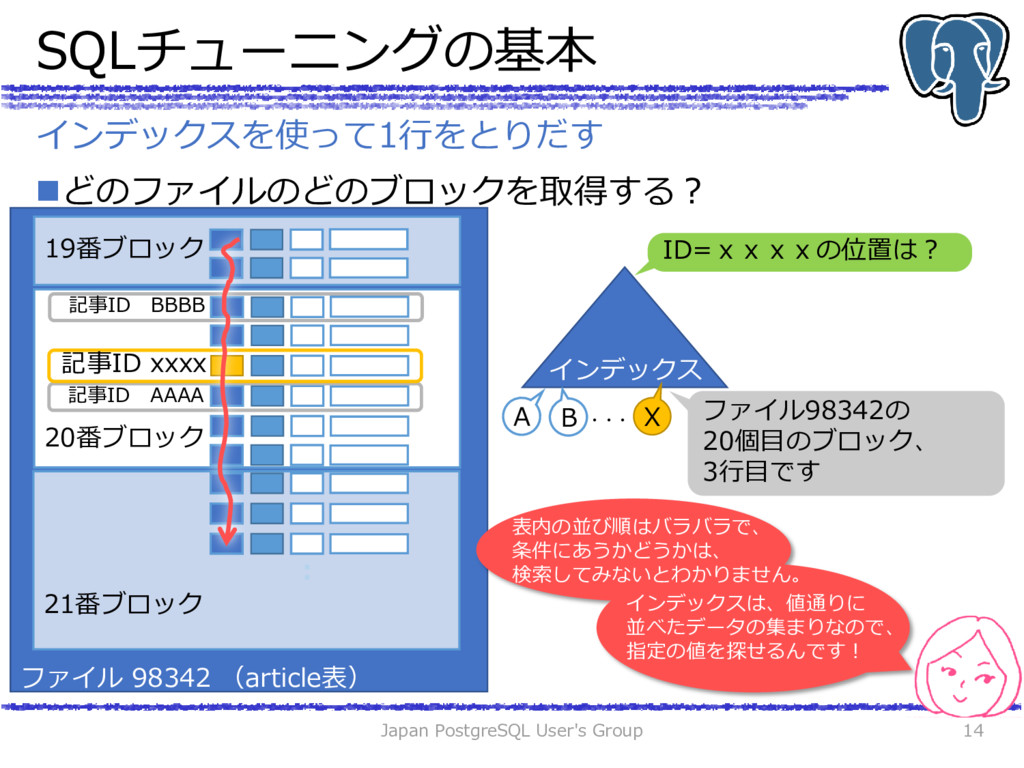{kind=link}
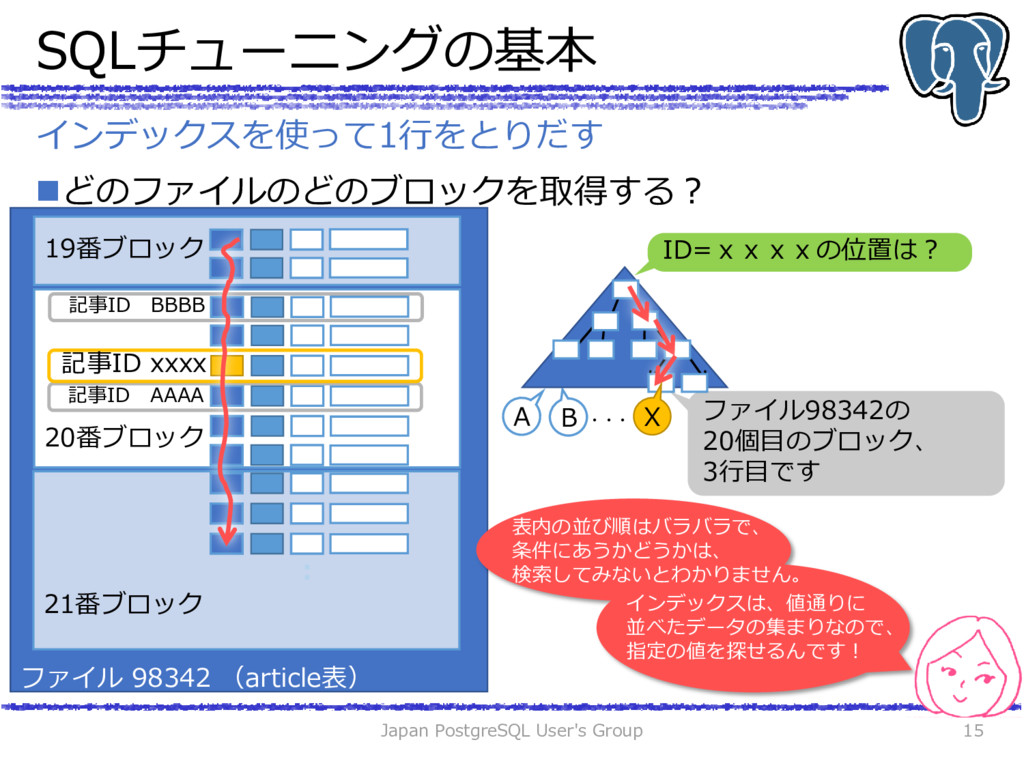{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}