Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介9月30日
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
miyanishi
September 30, 2014
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介9月30日
miyanishi
September 30, 2014
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
Optimising Largest Contentful Paint
csswizardry
37
3.7k
The Pragmatic Product Professional
lauravandoore
37
7.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
150
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Evolving SEO for Evolving Search Engines
ryanjones
0
210
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.5k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
200
Git: the NoSQL Database
bkeepers
PRO
432
67k
Transcript
文献紹介ゼミ 長岡技術科学大学 M1 宮西由貴
著者情報 • SimplerunsupervisedPOStaggingwithbilingual projections • Author: LongDuong et al. •
Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics • Year: 2013 • Pages: 634–639 2
概要 • 品詞付与に必要なリソース – 品詞タグ付きコーパスが大量に必要 – 言語によって貧富の差あり • パラレルコーパスを使った品詞タグ付与 •
8言語に対して実験 • state-of-the-art な手法と同等な結果 – よりシンプルな方法で実現 3
言語リソースの貧富 • 言語リソースの豊富な言語 – 品詞タグ付与も教師あり学習可能 – 英語,フランス語,ドイツ語,イタリア語・・・ • 言語リソースが貧困な言語 –
人手でタグ付けされた少量のコーパスのみ – 教師あり学習では限界 4
増えるパラレルコーパス • グローバル化によりパラレルコーパス増 – 公文書などもパラレルコーパスに! • リソースが豊富な言語⇒貧困な言語 – 品詞タグ付与にも応用できそう –
貧しい言語と富んだ言語の差を埋める 5
提案手法 • 教師なしの品詞タグ付与を提案 – ①Seed model – ②自己学習 • パラレルコーパスを使用
– 豊富な言語(品詞タグ付き) – 貧困な言語 • ターゲットとなる言語 – 貧困な言語 6
タグセット • 品詞タグは12種類 名詞 数詞 動詞 接続詞 形容詞 接頭辞・接尾辞 副詞
句読点 代名詞 その他(外国語・・・) 決定詞・冠詞 前置詞・後置詞 • ユニバーサルに選択した12種類 7
①Seed Model • ソース言語:リソースが豊富な言語 • ターゲット言語:リソースが貧困な言語 1. ソース言語に対して品詞タグを付与(自動) 2. Giza++でアライメントし,1対多のものは削除
3. アライメントスコア上位n件のみ取得 4. emission確率とtransition確率を推定 5. Seedタグ付与プログラムを構築 8
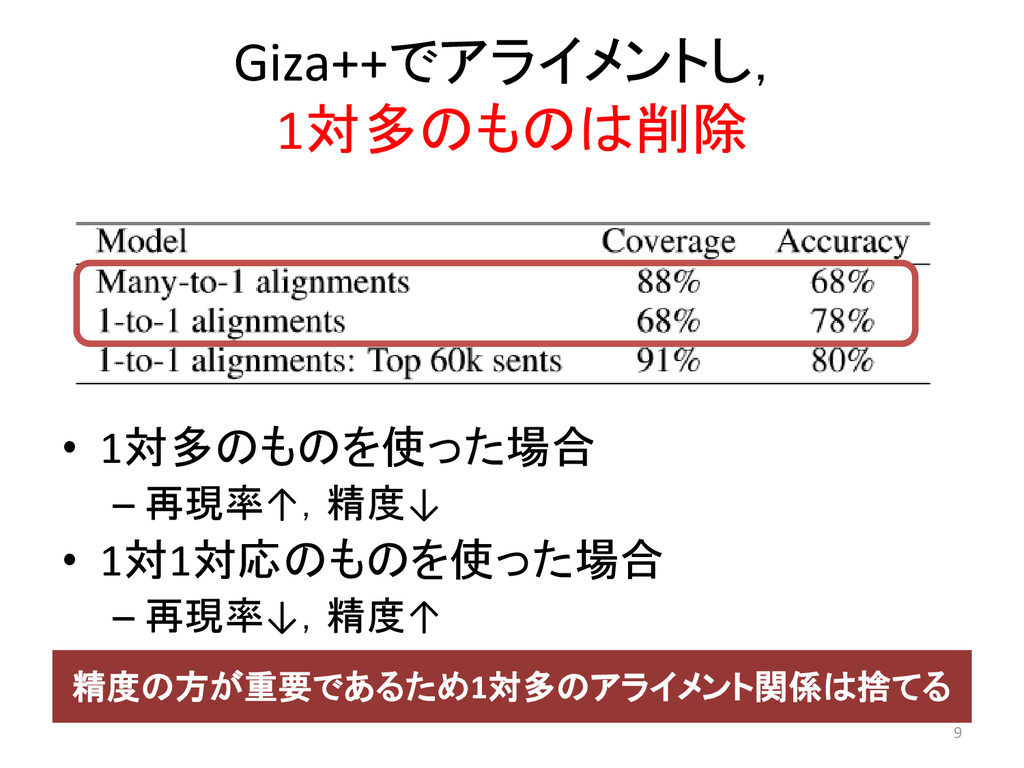
Giza++でアライメントし, 1対多のものは削除 • 1対多のものを使った場合 – 再現率↑,精度↓ • 1対1対応のものを使った場合 – 再現率↓,精度↑
精度の方が重要であるため1対多のアライメント関係は捨てる 9
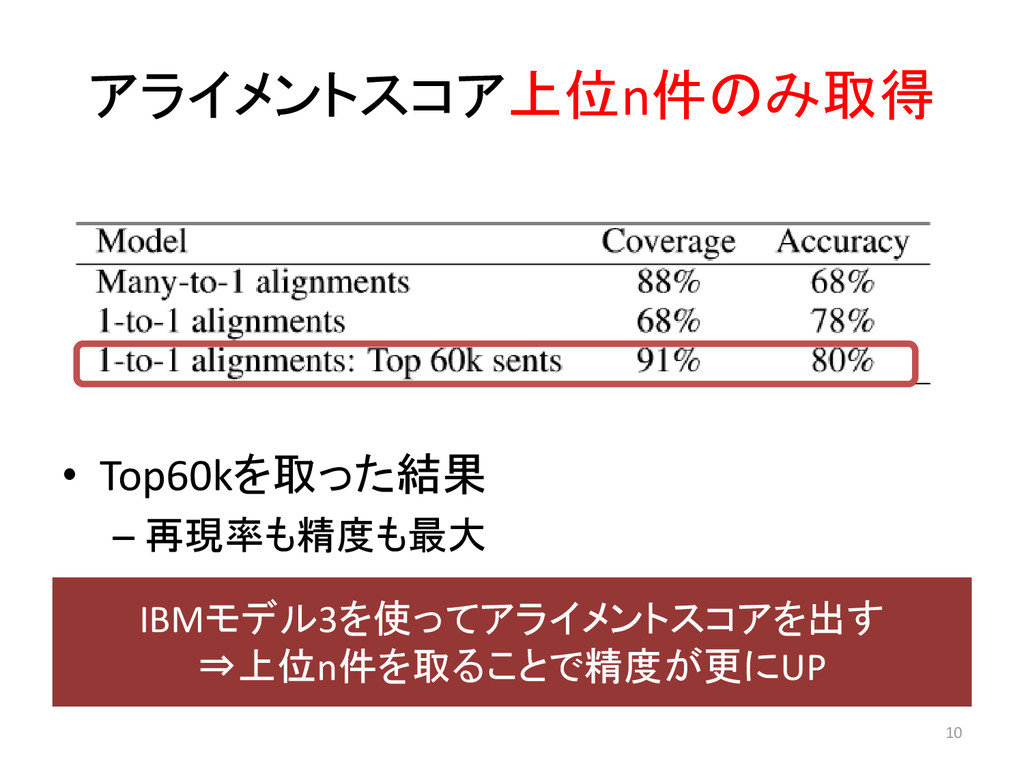
アライメントスコア上位n件のみ取得 • Top60kを取った結果 – 再現率も精度も最大 IBMモデル3を使ってアライメントスコアを出す ⇒上位n件を取ることで精度が更にUP 10
emission確率とtransition確率を推定 • emission確率のパラメータ – |V|×|T| – V:ボキャブラリー T:タグセット • transition確率のパラメータ
– 3 – Tri-gramモデル用 Emission確率とtransition確率を用いた Tri-gramのHMMを作成 11
②自己学習 1. ターゲット言語の文をブロックに分割 2. 最初のブロックにseed modelでタグ付与 3. タグが付いたブロックを修正 4. 修正済タグ付きブロックで新モデルを訓練
5. seed modelの辞書に新モデルを追加 6. 5を使って次のブロックをタグ付与 7. 3に戻る(全ブロックにタグが付くまで) 12
②自己学習 1. ターゲット言語の文をブロックに分割 2. 最初のブロックにseed modelでタグ付与 3. タグが付いたブロックを修正 4. 修正済タグ付きブロックで新モデルを訓練
5. seed modelの辞書に新モデルを追加 6. 5を使って次のブロックをタグ付与 7. 3に戻る(全ブロックにタグが付くまで) 13
タグの修正 • ( | )>0.7 ならば を に置換 – :ターゲット言語の単語
– :ソース言語の単語 – : に付いたタグ(seed model) – : に付いたタグ(リソース) • 0.7は発見的に決定 14
②自己学習 1. ターゲット言語の文をブロックに分割 2. 最初のブロックにseed modelでタグ付与 3. タグが付いたブロックを修正 4. 修正済タグ付きブロックで新モデルを訓練
5. seed modelを新モデルに追加 6. 5を使って次のブロックをタグ付与 7. 3に戻る(全ブロックにタグが付くまで) 15
確率値の更新 • emission & transition 確率を更新 • 新しいモデルに前のモデルを追加 – emission確率:Vが入っている
– 新しいモデルには前のモデルの確率も必要 16
実験について • 使用言語 – ソース言語:英語 – ターゲット言語: デンマーク,オランダ,ドイツ,ギリシア,イタリア, ポルトガル,スペイン,スウェーデン •
ソース言語へのタグ付与 – Stanford POS tagger • 比較手法 – Das and Petrov(2011):state-of-the-artな手法 17
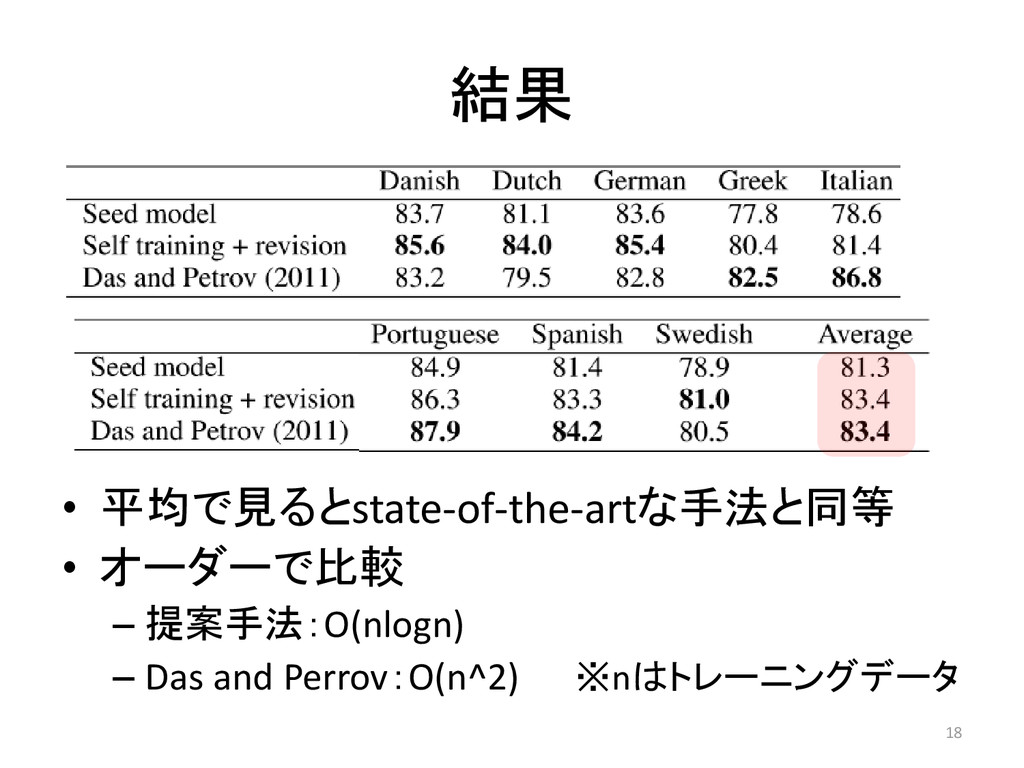
結果 • 平均で見るとstate-of-the-artな手法と同等 • オーダーで比較 – 提案手法:O(nlogn) – Das and
Perrov:O(n^2) ※nはトレーニングデータ 18
まとめ • 品詞付与に必要なリソース – 品詞タグ付きコーパスが大量に必要 – 言語によって貧富の差あり • パラレルコーパスを使った品詞タグ付与 •
8言語に対して実験 • state-of-the-art な手法と同等な結果 – よりオーダーが小さい方法で実現 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}