rax, rdi movabs rcx, -8446744073709551616 div rcx pop rcx ret DIV 命令を使った実装 294,881 ns/iter 測定は AMD Ryzen 5 7600X 6-Core Processor にて。 の範囲で被除数を ランダムにサンプリングした 131072 個の入力の処理時間を評価。 divrem_1e19_u128(unsigned __int128): movabs rax, 8507059173023461586 movabs r9, -7667109045778114189 mov rdx, rdi mulx r8, rcx, rax mulx r10, r10, r9 mov rdx, rsi mulx rax, r11, rax mulx rsi, rdx, r9 add r10, rcx movabs rcx, -8446744073709551616 adc r8, 0 add rdx, r10 adc rsi, r8 adc rax, 0 add rsi, r11 adc rax, 0 shld rax, rsi, 2 imul rcx, rax sub rdi, rcx mov rdx, rdi ret clang trunk による最適化実装 226,113 ns/iter example::divrem_1e19_rep2::h8c930d3d88b36963: mov rax, rsi shr rax, 63 mov rdx, rsi shld rdx, rdi, 1 movabs rcx, -1432625727662628443 mulx rdx, rdx, rcx imul rax, rcx add rdx, rax movabs rcx, 8446744073709551616 mulx r8, rax, rcx sub r8, rdx add rax, rdi adc r8, rsi setne sil movabs rdi, -8446744073709551617 cmp rax, rdi seta r8b or r8b, sil movzx esi, r8b test sil, sil lea r8, [rax + rcx] cmove r8, rax add rcx, r8 xor eax, eax cmp r8, rdi seta al cmovbe rcx, r8 add rdx, rsi add rax, rdx mov rdx, rcx ret 近似商+最大2回補正の実装 211,356 ns/iter 定数除数整数除算の高速実装 / 近似商と補正による除算アルゴリズム Mizar/みざー, 競プロキャンプ2026関東LT, 2026-06-06 54 / 56
{kind=link}
![0. 自己紹介代わりの問題紹介 Accuracy of Integer Division Approximate Functions (2023年8月出題) [1]](https://files.speakerdeck.com/presentations/ff868ccba28d4d059f6a8c902d5e2db4/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
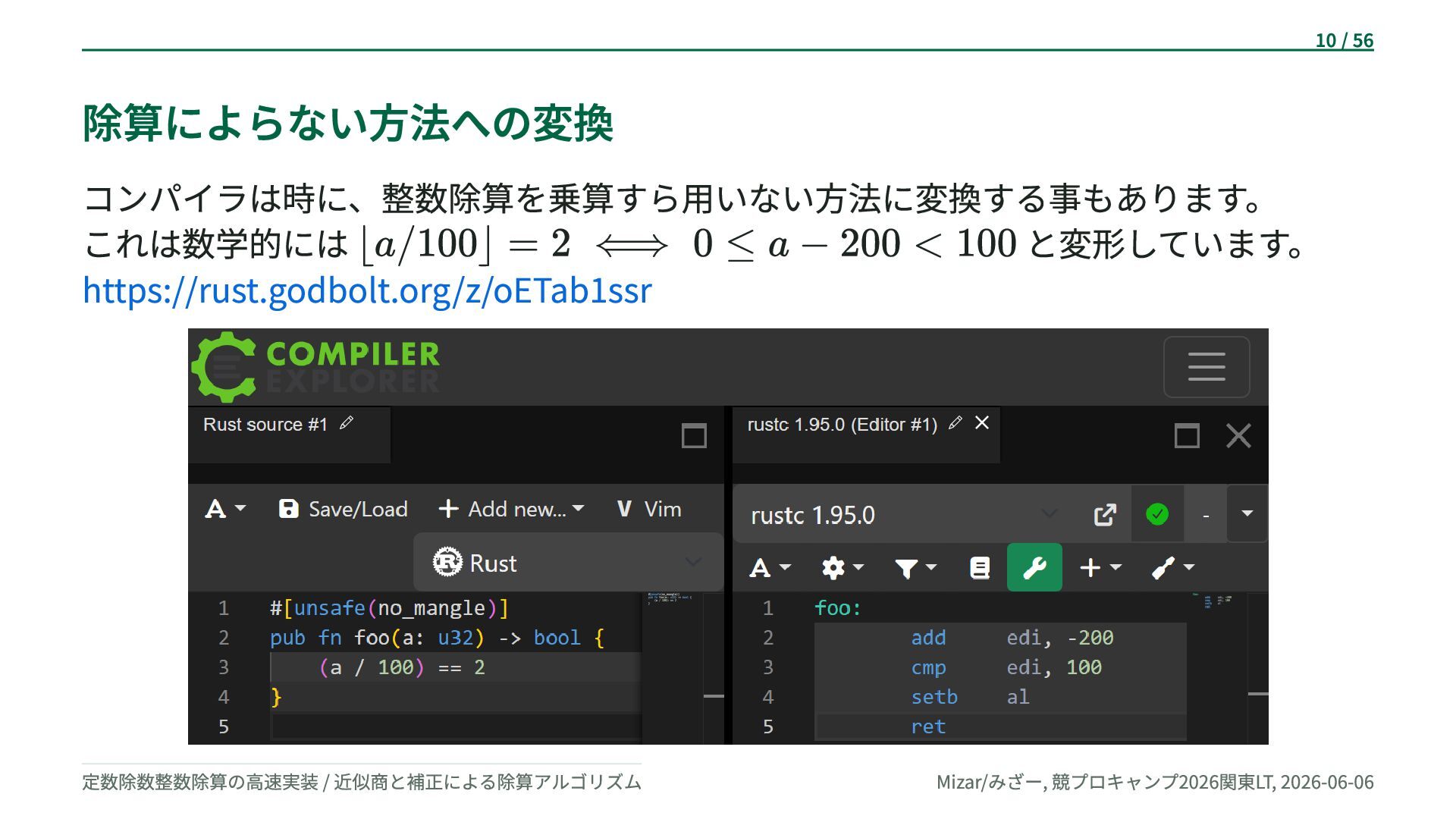{kind=link}
{kind=link}
{kind=link}
{kind=link}
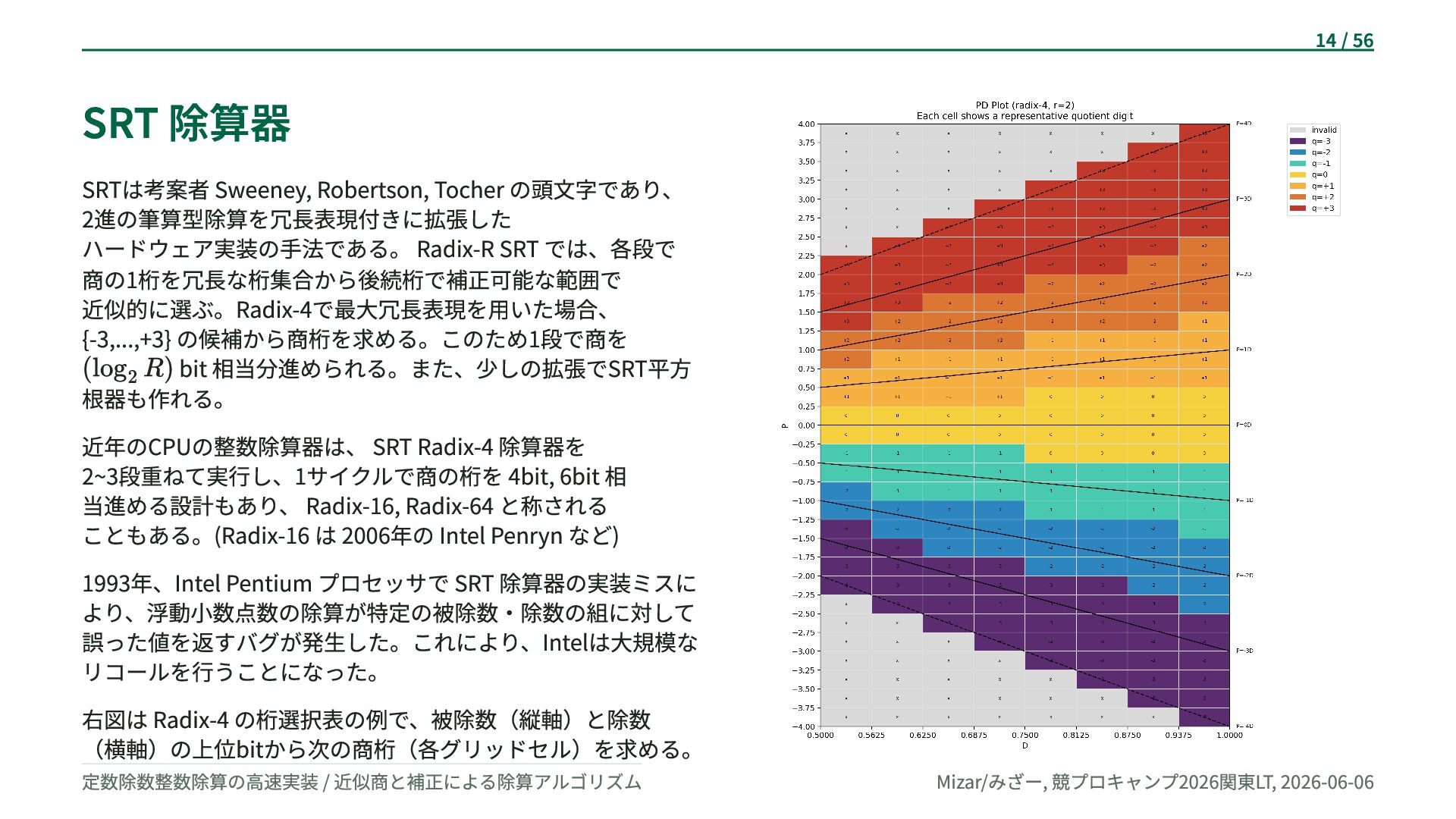{kind=link}
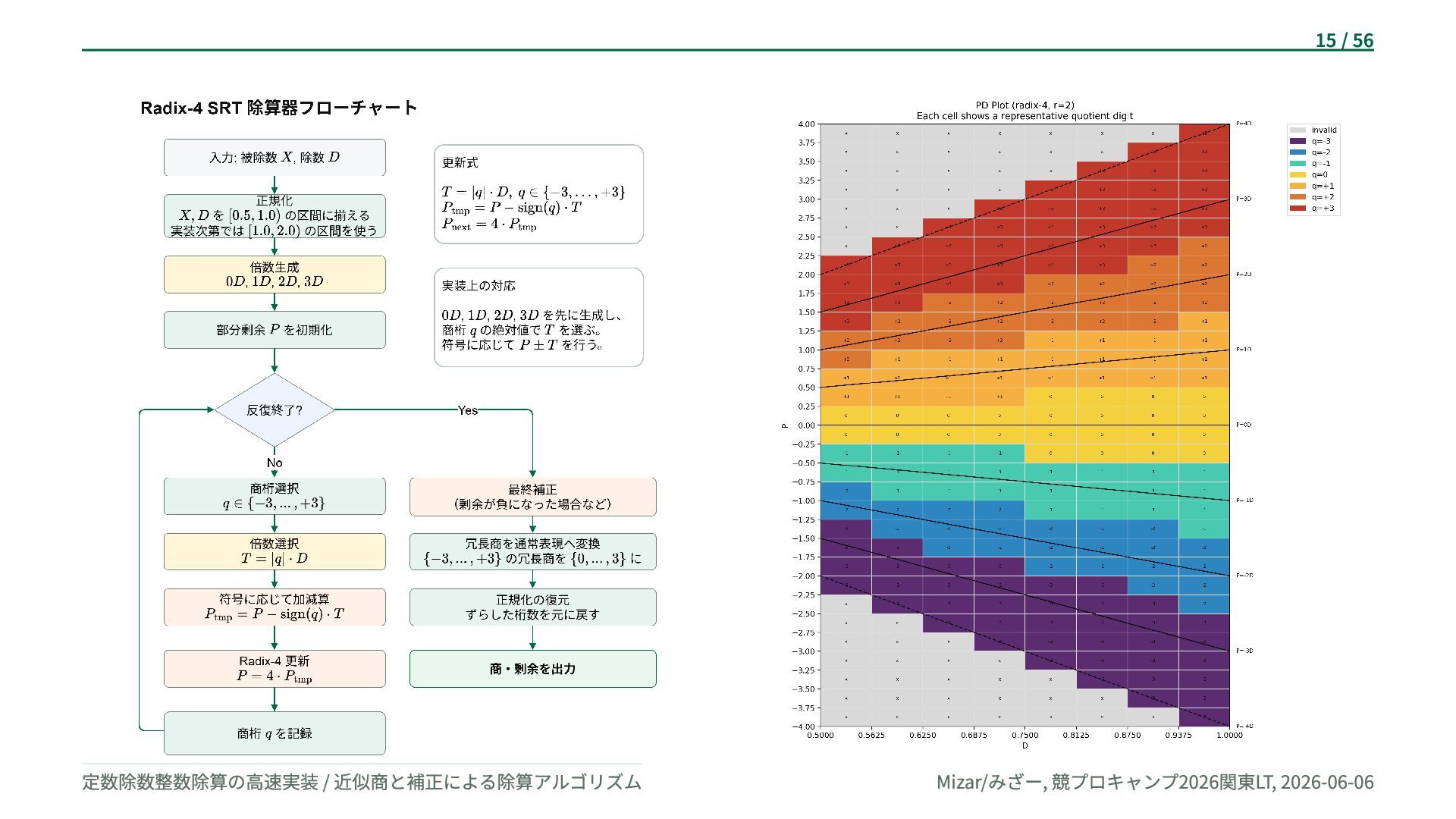{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
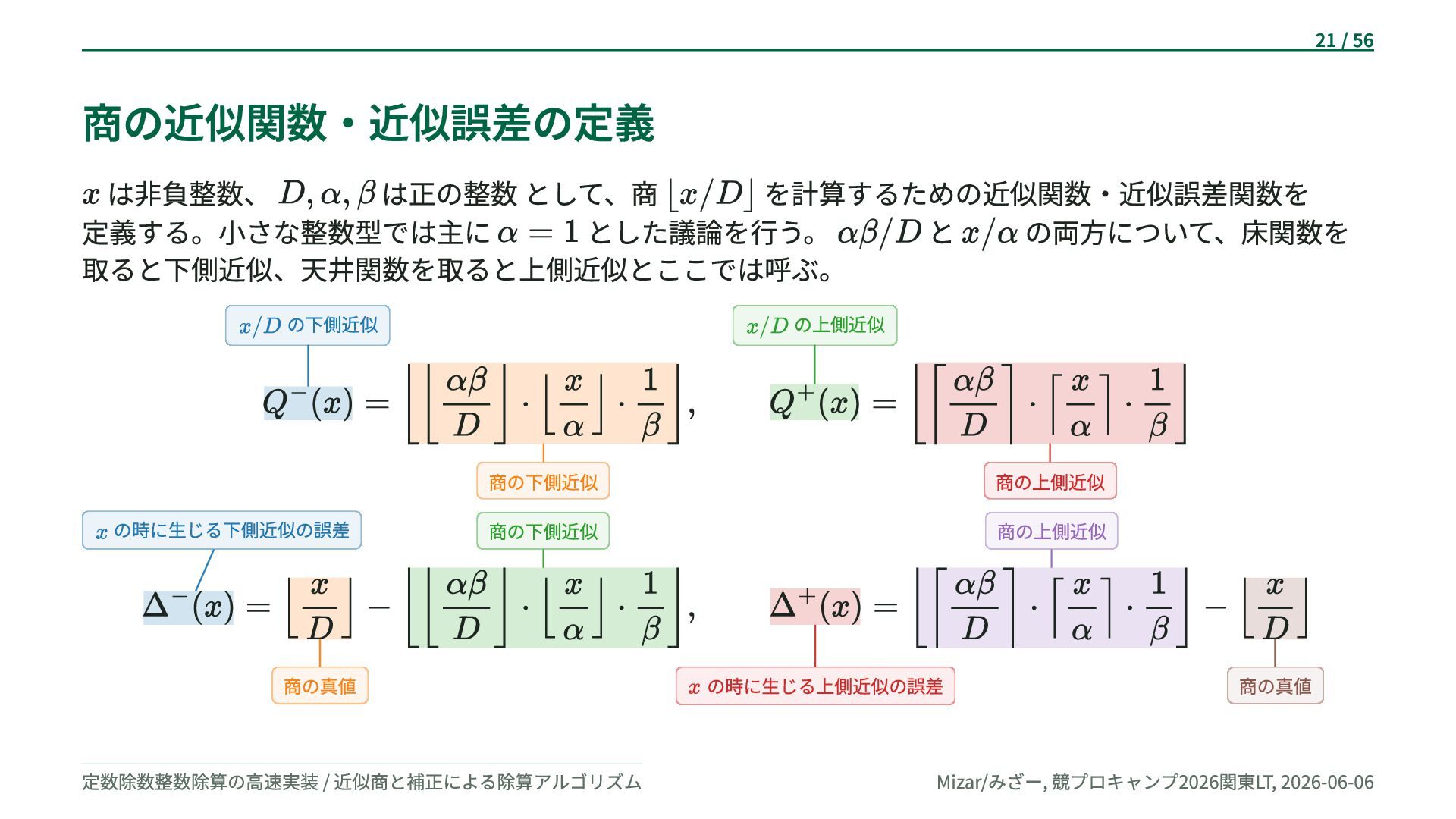{kind=link}
{kind=link}
{kind=link}
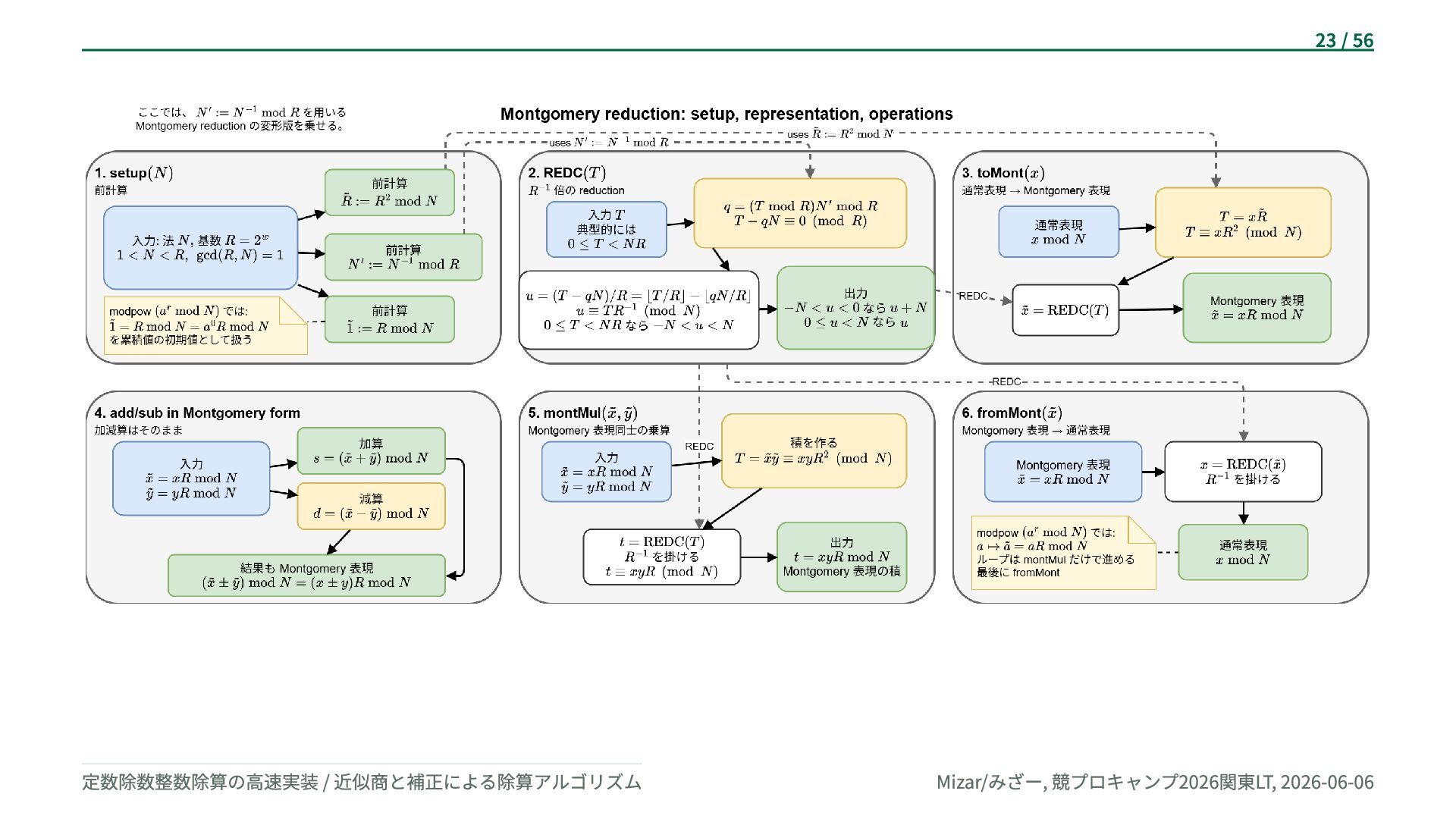
![Barrett Reduction Paul Barrett の CRYPTO’86 論文 [7] は、RSA を標準的な](https://files.speakerdeck.com/presentations/ff868ccba28d4d059f6a8c902d5e2db4/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![32bit整数の除算器 #[derive(Debug, Clone, Copy)] enum DivisorU32Kind { Up, Shift }](https://files.speakerdeck.com/presentations/ff868ccba28d4d059f6a8c902d5e2db4/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ac_library に見る実装の住み分け ac_library [13] の modint 実装は、法がいつ決まるかで方針が分かれる。 static_modint : 法がコンパイル時定数](https://files.speakerdeck.com/presentations/ff868ccba28d4d059f6a8c902d5e2db4/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
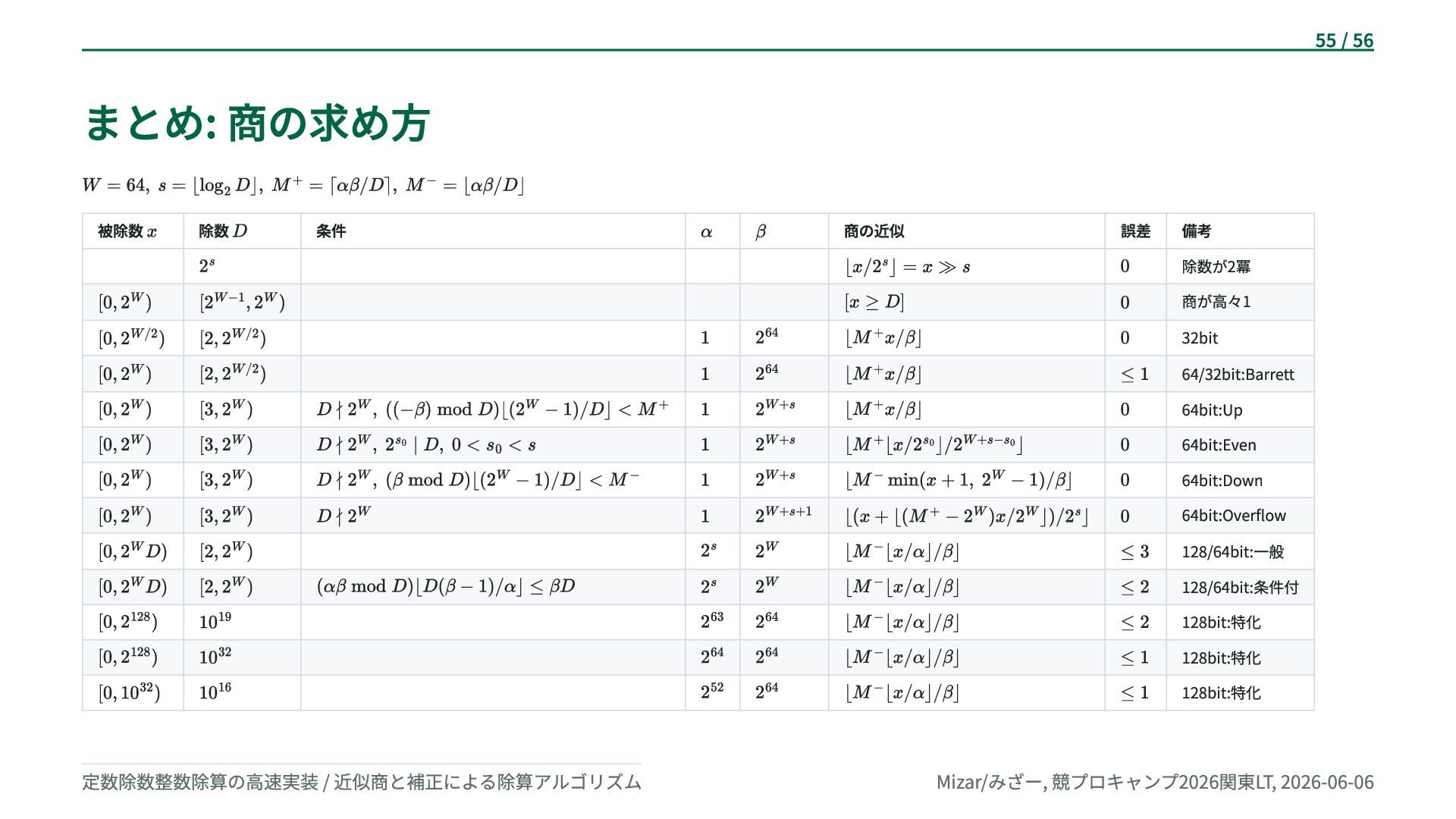{kind=link}
{kind=link}