Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
atmaCup #23でAIコーディングを活用した話
Search
ML_Bear
February 14, 2026
Programming
950
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
atmaCup #23でAIコーディングを活用した話
AIコーディングを駆使してatmaCup #23 (Turing × atmaCup 2nd) を戦った記録です
ML_Bear
February 14, 2026
Other Decks in Programming
See All in Programming
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.1k
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
240
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
900
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
180
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
130
Spring Security 実践 ─ GraphQL APIで実務に役立つ 認証・認可 を学ぶ
wagyu
0
260
AI時代のUIはどこへ行く?その2!
yusukebe
22
7.6k
メソッドのジェネリクスでGoの夢は広がるか? / Kyoto.go #65
utgwkk
3
990
OSもどきOS
arkw
0
600
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
350k
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
250
過去最大のMCPアップデート! 2026-07-28 RC版の謎に迫る
licux
6
420
Featured
See All Featured
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
エンジニアに許された特別な時間の終わり
watany
107
250k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
570
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Building the Perfect Custom Keyboard
takai
2
800
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
540
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
160
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
320
Transcript
atmaCup #23でAIコーディングを活用した話 〜 3rd Place Solution も添えて 〜 ML_Bear /
2026-02-14 1
目次 自己紹介 コンペ概要 解法 (サラッと) 実際のコンペ経過 どうやってAIとコンペを戦ったか AIと協働するコツ まとめ 2
自己紹介 ML_Bear ML Enginner フリーランス(2024.06-) / ex-メルカリ 一応 Kaggle Master
だけどここ数年は引退気味 また再開しようかなと思い始めてはやX年 メルマガ: https://www.ml-bear-times.com/ LLMで自動配信 / 自分が一番気に入ってる 趣味: 海外旅行 / 日本酒 3
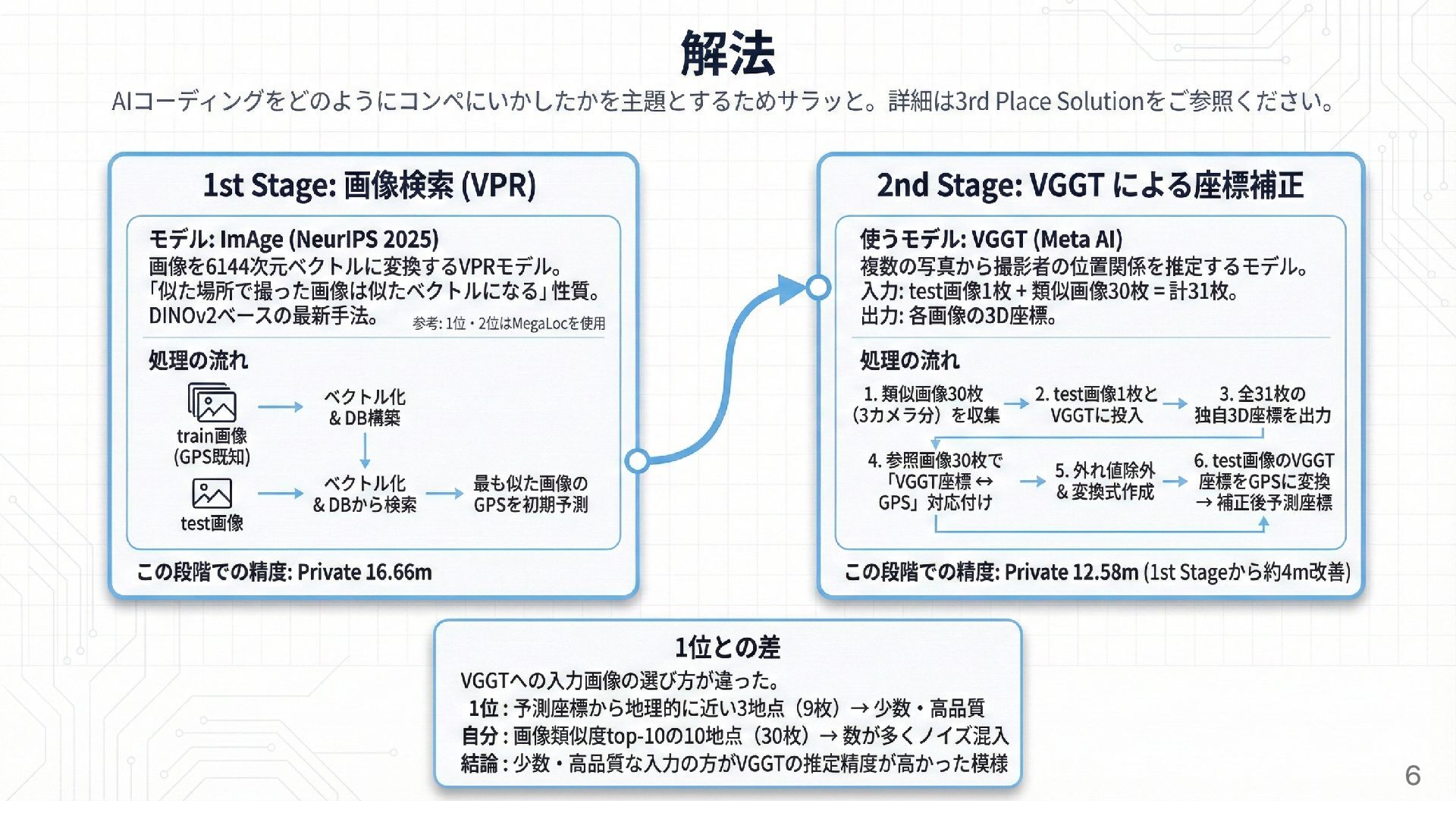
この発表の目的など 発表の目的 「ドメイン知識なし + フルAIコーディング」でコンペに参加した経験の共有 2026年2月時点でのAIコーディングの活用方法の共有 発表の目的ではないこと コンペ解法の詳細共有 (詳細は 3rd
Place Solution をご参照ください) 免責事項 本発表は2026年1月末時点の情報に基づきます atmaCup以降にOpusやCodexがアップデートされて既に少し古いかも 4
コンペ概要 atmaCup #23 (Turing × atmaCup 2nd) https://www.guruguru.science/competitions/31/ 車載カメラ画像から撮影地点の緯度経度を推定 (Visual
Localization) train画像 (GPS既知、2,975地点 x 3カメラ) と test画像 (GPS未知、約1,100枚) が与 えられる 評価指標: Winsorized MAE (上位10%の外れ値を90パーセンタイルでキャップした 平均距離誤差) 大外れを減らすことがスコア改善に直結する設計 5
6
実際のコンペ経過 7
実際のコンペ経過 - 序盤① (1/19-1/20) ChatGPT Pro で計画策定 以下3つをChatGPT Proに投入 コンペの説明、少数のサンプルデータ。
monnu さん Baseline & motono0223 さんの VGGT質問 ChatGPT Pro が出した3段構成の計画: i. 複数の画像検索モデルを組み合わせて、良い候補を漏れなく見つける ii. VGGT で候補画像群から撮影位置を推定して座標を補正する iii. 推定の自信度に応じて複数の予測方法を使い分け、大外れを減らす 1, 2 の方向性はほぼ計画通り。3 は全て失敗 ドメイン知識ゼロの僕が高品質なロードマップを数十分で得られたのは凄い 8
実際のコンペ経過 - 序盤② (1/19-1/20) Claude Codeが半日で9モデルを試す Claude Code が半日で 9
モデル試して ImAge (NeurIPS 2025) を見つけてくれた AI コーディングの恩恵が最も大きかったところ が、MegaLoc の画像サイズを間違えていた (322px、正しくは 518-1024px) Claude Code が別モデルの設定をコピペして使う → CV 57.87m (不採用) AI に任せっぱなしにせず、モデルの公式ドキュメントや推奨設定を人間が確 認する仕組みが必要だった。(この辺りがドメイン知識の有無の差とも言える かも) 9
実際のコンペ経過 - 中盤 (1/20-1/22) VGGT 導入 → スコア爆上がり 当初計画通りに 2nd
Stage (VGGT による座標補正) 導入 CV 約 3m (Private 約 4 m) 改善 この時点のモデルがほぼ最終ベスト (早くも) 検索結果の改善 (複数モデルの統合、候補の並べ替えなど) を 5 パターン試す 全て失敗 LLM が有効なアイディアを出せたのはこのあたりまでだった 10
実際のコンペ経過 - 終盤 (1/23-1/26) LLM のアイディアがサチる Claude Code に「どういう時に予測が外れるか」を分析させ、改善策を発見 →
+0.13m 改善 1st Stage も 2nd Stage も自信がないケースを抽出し、別の判定方法に切り替 えると改善した (詳細は Appendix) Claude Code が実験条件を取り違えてベストの再現に 3 回かかった 些細なパラメータの違いが約 3m の差を生んでいた (AIも人間も気づかず) Codexに聞くとあっさりミスを見つけた。 条件が複雑になってくるとCodexの方が強い印象 追加で 10 以上の改善実験を投入 → 全滅して終了 11
どうやってAIとコンペを戦ったか 12
どうやってAIとコンペを戦ったか - 1 全体像 ChatGPT Pro (Extended Thinking) で調査・計画 それを元にClaude
Codeが実験計画書を作成 Claude Codeが実装 → 実験実行 → 結果を分析 実験計画をこなしたらChatGPT Proにアップデートを依頼 (以下ループ) 13
どうやってAIとコンペを戦ったか - 2 調査・計画 ChatGPT Pro (Extended Thinking) 序盤: Discussionの内容とサンプルデータを投入して計画を立ててもらう
中-終盤: 現状の実験状況を元に実装計画のアップデートを提案してもらう 中盤以降はこいつしかまともな提案を出さなかった 終盤は質が落ちた (DeepResearchのことを完全に忘れてた、使うとなんか差があったかな?) 14
どうやってAIとコンペを戦ったか - 3 実装 コーディングは Claude Code にお任せ Claude Code
は Ghostty で動かしてた (Ghostty速いからおすすめ) 全体計画を Claude Codeに見せて実装計画に落としてからやる Plan modeで一緒にやる / 実験毎に必ず更新させる ディレクトリ構造やログの工夫などは後述 終盤はCodex CLIにレビューを依頼 (Codexの /review 強い) 最近は実験を並行したければ Codex App を使うと便利かも worktree をうまく隠蔽してくれて難なく並列実装ができる Background job などの細かい使い勝手はまだ良くなさそうではある 15
どうやってAIとコンペを戦ったか - 4 実験 / 分析 事前に Vertex AI Custom
Training のジョブ投入コマンドや環境を整備 Claude Code が自動的に Background job で Vertex AI Custom Training に実験投入 Background job は終わると通知を Claude Codeに飛ばす エラーがあればClaude codeが自律的に直して再投入 (GCSに実行ログが置い てあるのを見て勝手にやってくれる) 実験終了したあとはログを見て実験レポートを書かせる (実験計画書内にサマ リーを書き、別途詳細版も作らせる) 環境整備しておけば勝手に実験を並列でやってくれるのがめちゃ楽だった 使い方を教えるのがちょっと面倒 16
AIと協働するコツ 17
AIと協働するコツ - 1 AIの目線を上げる ほっとくと 75 点ぐらいの仕事をさっさと仕上げようとする LLMは超難問解くより、間違ったらいけない問題をちゃんと解くのが好き (そ う学習されてるから?)
計画を立てるときに毎回こう書いていた (効果不明だけど初回は効いた) 「高尾山を早く登る方法は要らない、エベレストを登る方法をくれ。 」 「目標はコンペの上位入賞だ。他の人がやってるような内容ばかり答えなく ていい、差別化要因になる内容を教えて」 18
AIと協働するコツ - 2 コンテキスト制限に負けない仕組みを作る 現在のコンテキスト長では実験を多数行うコンペを戦うのは厳しい Claude (200k): 頻繁にコンテキスト圧縮が必要。そのたびに色々忘れる Codex /
Gemini (1M): コンテキスト増えると性能が劇的に落ちる 計画書と実験レポートの記録ルールを整備 AIも人間も実験経緯を追えるように どうせAIが読むから記録は多いぐらいがちょうどいい (人間はサマリーだけ読 むのでもいい) 19
ディレクトリ構成 . ├── data/ # コンペデータ ├── exp/ # 実験スクリプト(1ファイル=1実験)
│ ├── 01_hoge.py │ └── ... ├── output/ # 実験結果 ├── scripts/ # VertexAI Job投入スクリプトなど ├── spec/ # 計画書・実験レポート (★次頁補足) │ ├── YYYYMMDD_v1.md # 実装計画書 (何度もver.upする) │ ├── ... │ └── exp_reports/ # 個別実験の詳細レポート │ ├── 01_hoge.md │ └── ... ├── src/ # 共有ライブラリ (★次頁補足) ├── Dockerfile # Vertex AI用コンテナ └── CLAUDE.md # Claude Codeメモリ (★次々頁補足) 20
AIと協働するコツ - 3 ディレクトリ構成 - 補足 src/ : 中途半端に実装を共用しようとしたのは失敗だった (終盤にClaude
Codeが ファイルを取り違うなどバグ多発して苦戦) spec/ : 実験結果は実験計画書内にサマリーを書き、別途詳細版を exp_reports/ 内にも作らせる。(サマリーだけだとLLMも人もすぐ忘れる) yag_sysさんのように実験毎にスクリプト切り分けて管理する方がいいかも https://yag.xyz/post/data_competition_setup/ 21
AIと協働するコツ - 4 ディレクトリ構成 - 補足2 (CLAUDE.md ) Claude Codeが繰り返し間違えるポイントを都度
CLAUDE.md に追記 例: GCR使うな / Dockerビルドはプラットフォーム指定しろ / gcloud ai custom- jobs stream-logs 遅いから禁止 など Compaction した後に「お前 CLAUDE.md 読んでる?」 「当たり前だろ読んでるわ (読 んでない)」が多発してストレスだった Compaction後は毎回 @CLAUDE.md で指定して読み込ませた よく使うアクション (VertexAIへのジョブ投入) は skill にして整備した方がよかった のかもなぁ、とか思う。( CLAUDE.md は細部を無視したりする挙動がある) 最近 Claude Codeの自動メモリー機能出たから今後はもっと楽になるかも 22
まとめ 23
まとめ 正しいインプットを与え続ければAI頼みでも80点ぐらいの解は出せる トッププレイヤーに敵わなさそうだが発射台としては良さそう LLMの特性を把握して使い分けるとよい アイディア出しは ChatGPT Pro (Extended Thinking) テンポよく実装するのは
Claude Code 複雑な内容のレビューは Codex AI様が気持ちよく働き続けられる環境づくりに投資するべし 絶え間ない実験計画供給、実験レポートの保存ルール、実験環境提供など 計画以外は「AIが主、人間は副」と割り切ってサポートするのが良さそう たまにコンペ参加してがっつりAIに触る機会作ると良い 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}