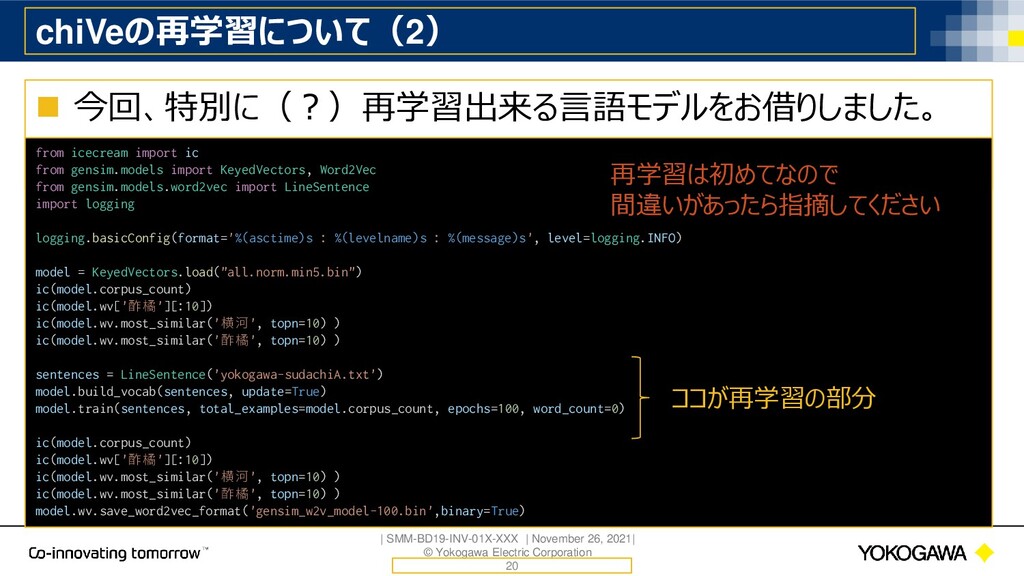
chiVeの再学習について(3) ◼ 先ほどの計算環境でchiVeにYコーパス 約百万行、1,500万語 を追加 ◼ 10Epochで約6分! 21 ('横河', topn=10): [('横河電機', 0.7153161764144897), ('パイオニックス', 0.5750902891159058), ('大同特殊鋼', 0.5683308243751526), ('古河電工', 0.534030020236969), (‘神戸製鋼’, 0.5311375260353088), ('日立製作所', 0.5290708541870117), ('富士電機', 0.5280645489692688), ('神鋼', 0.5144648551940918), ('曙ブレーキ工業', 0.5136256217956543), ('東邦チタニウム', 0.5135630965232849)] ('酢橘', topn=10): [('臭橙', 0.7173675298690796), ('レモン', 0.6835445761680603), ('シークワーサー', 0.6607993245124817), ('青紫蘇', 0.6561844348907471), ('ポン酢', 0.6518506407737732), ('柚子', 0.643626868724823), ('柑橘', 0.6321057677268982), ('日向夏', 0.6260204315185547), ('蜜柑', 0.6254730224609375), ('大根下ろし', 0.6194115281105042)] 学習前 ('横河', topn=10): [('報', 0.8445025682449341), ('技', 0.8400911092758179), ('電機', 0.7764625549316406), ('vol.', 0.7587082386016846), ('Vol.', 0.7563737630844116), (‘1111111111111111111111111111111111111‘, 0.7134548425674438), ('vo', 0.7021391987800598), ('システム', 0.6947261095046997), ('9', 0.6943381428718567), (‘の’, 0.6822482943534851)] ('酢橘', topn=10): [('臭橙', 0.7173675298690796), ('レモン', 0.6835445761680603), ('シークワーサー', 0.6607993245124817), ('青紫蘇', 0.6561844348907471), ('ポン酢', 0.6518506407737732), ('柚子', 0.643626868724823), ('柑橘', 0.6321057677268982), ('日向夏', 0.6260204315185547), ('蜜柑', 0.6254730224609375), ('大根下ろし', 0.6194115281105042)] 学習後(前処理をしていないので酷い結果) 10分程度で特定ドメインの単語ベクトルが追加出来るなら凄い! ただ、全ベクトルを再計算しないといけないという論文があった気も。 (それに、前処理も大事)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
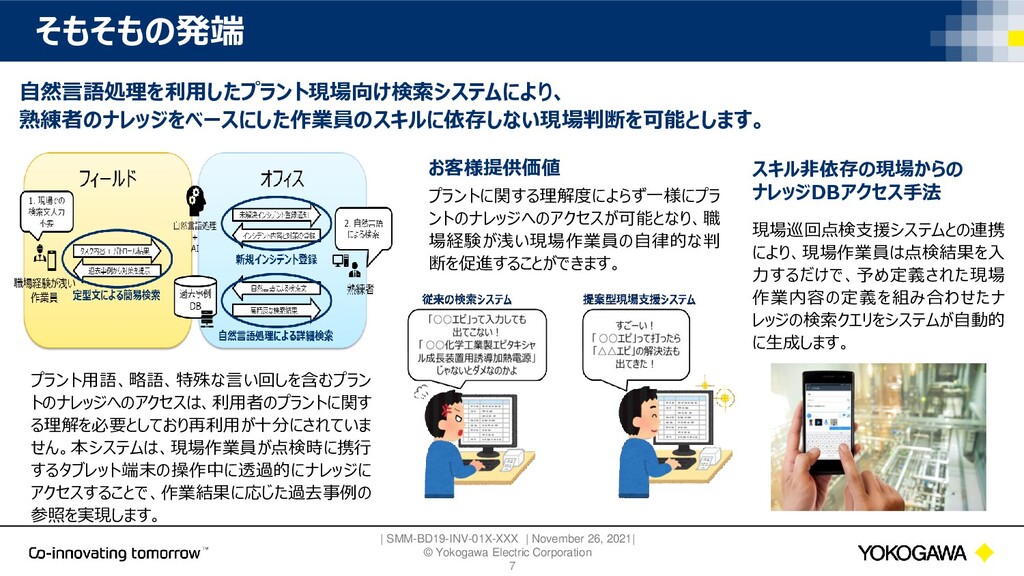{kind=link}
{kind=link}
{kind=link}
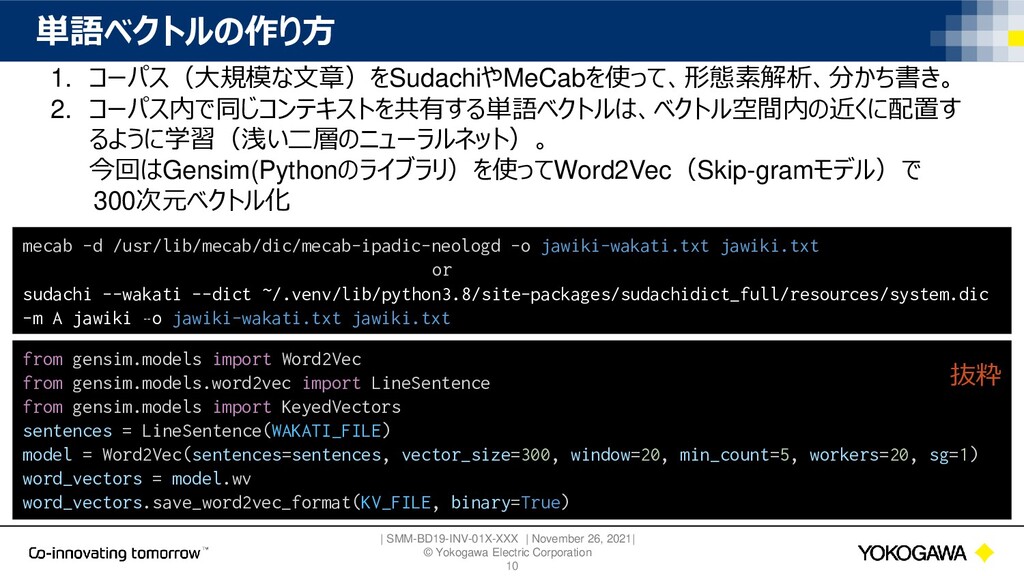{kind=link}
{kind=link}
{kind=link}
{kind=link}
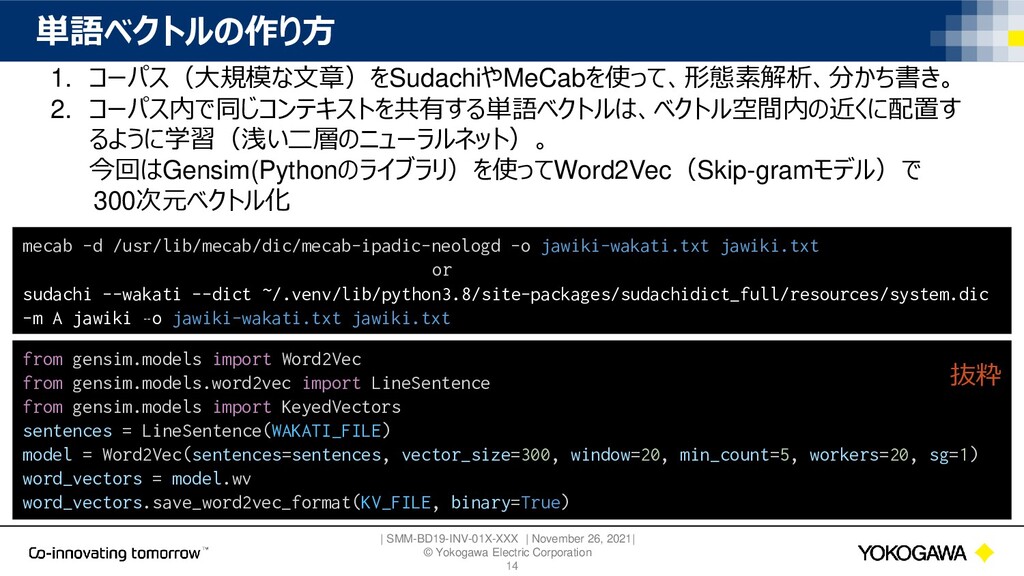{kind=link}
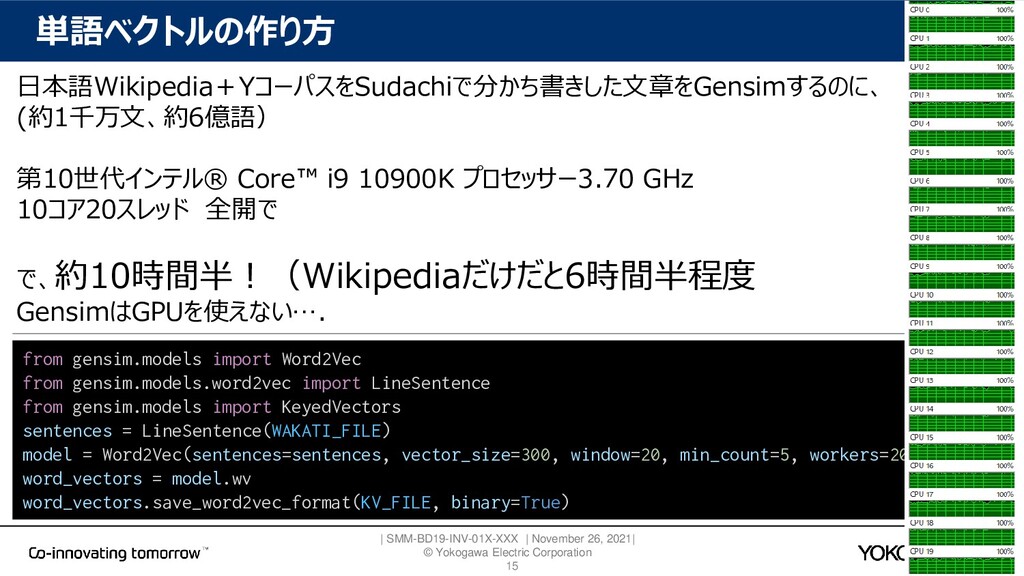{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}