Need to parallelize processing across multitude of CPUs • Achieves above while KeepIng Software Simple • Gives scalability with low-cost commodity hardware Why Hadoop ? BarCamp Chennai - 5 Mohit Soni
Log Analysis • Image manipulation • Sorting large-scale data • Data Mining When to use and not-use Hadoop ? BarCamp Chennai - 5 Mohit Soni Hadoop is not a good choice: • For real-time processing • For processing intensive tasks with little data • If you have Jaguar or RoadRunner in your stock
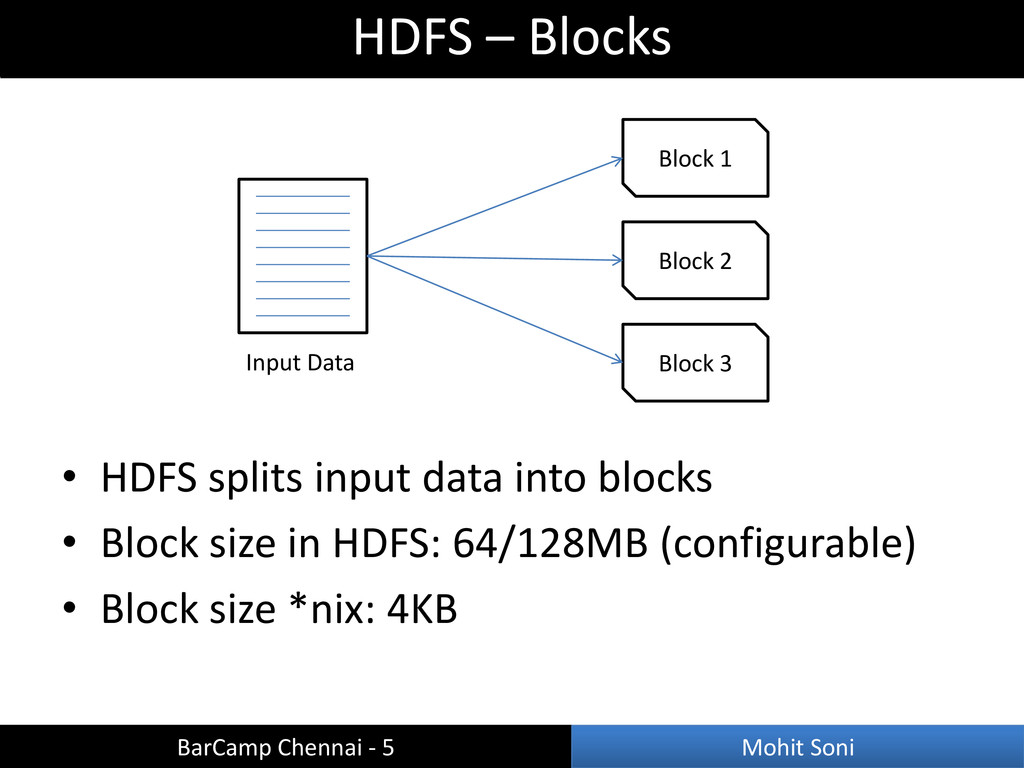
(Google File System) • Write once read many access model • Fault tolerant • Efficient for batch-processing HDFS – Overview BarCamp Chennai - 5 Mohit Soni
• Node failure is handled gracefully, without loss of data HDFS – Replication BarCamp Chennai - 5 Mohit Soni Block 1 Block 2 Block 1 Block 3 Block 2 Block 3
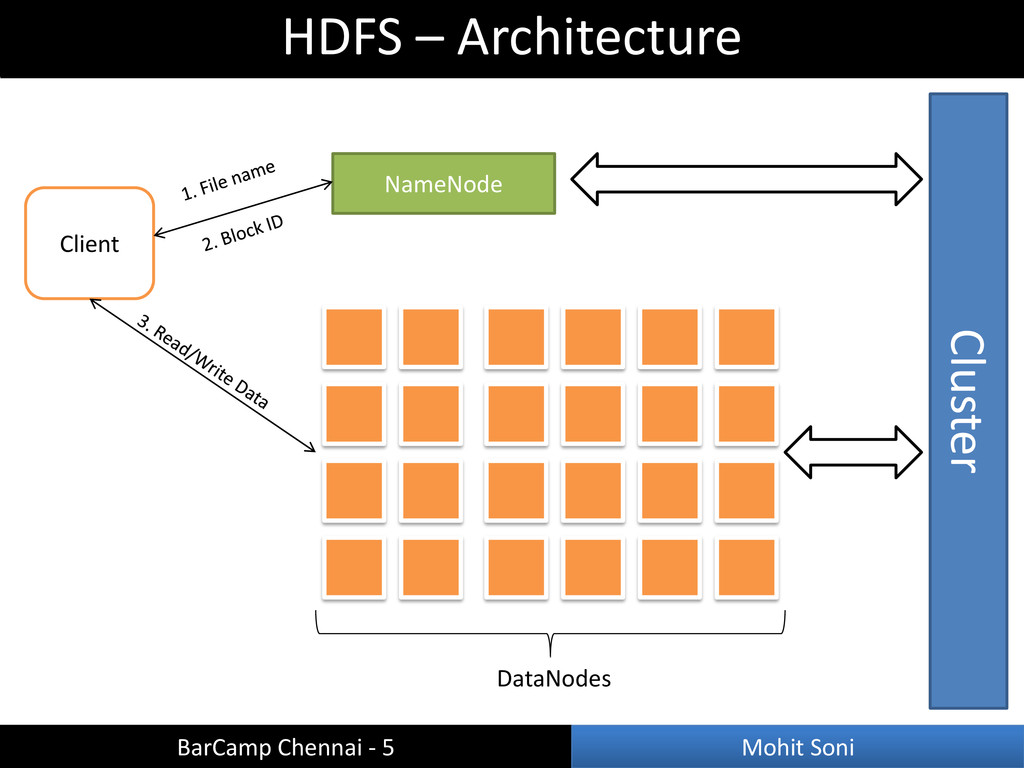
of blocks – Manages read/write access to files • Metadata – List of files – List of blocks that constitutes a file – List of DataNodes on which blocks reside, etc • Single Point of Failure (candidate for spending $$) HDFS – NameNode BarCamp Chennai - 5 Mohit Soni
blocks – Informs NameNode about block IDs stored – Client read/write data blocks from DataNode – Performs block replication as instructed by NameNode • Block Replication – Supports various pluggable replication strategies – Clients read blocks from nearest DataNode • Data Pipelining – Client write block to first DataNode – First DataNode forwards data to next DataNode in pipeline – When block is replicated across all replicas, next block is chosen HDFS – DataNode BarCamp Chennai - 5 Mohit Soni
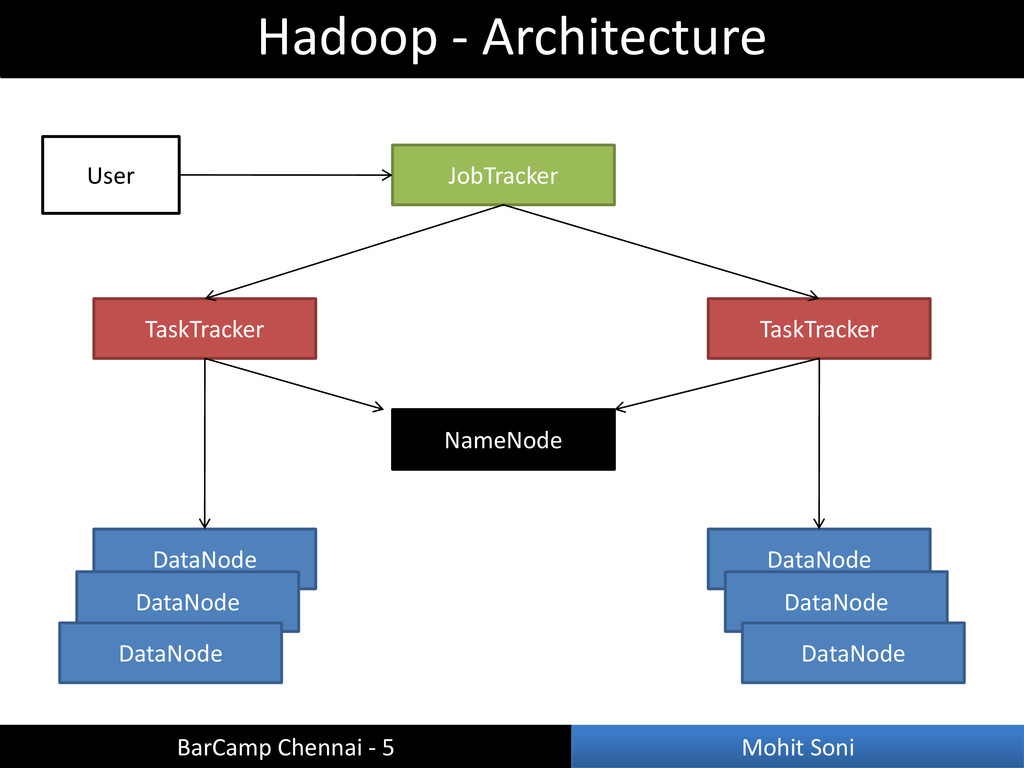
Accepts job requests from users – Schedule Map and Reduce tasks for TaskTrackers – Monitors tasks and TaskTrackers status – Re-execute task on failure • TaskTracker (Slave) – Multiple TaskTrackers in a cluster – Run Map and Reduce tasks Hadoop - Terminology BarCamp Chennai - 5 Mohit Soni
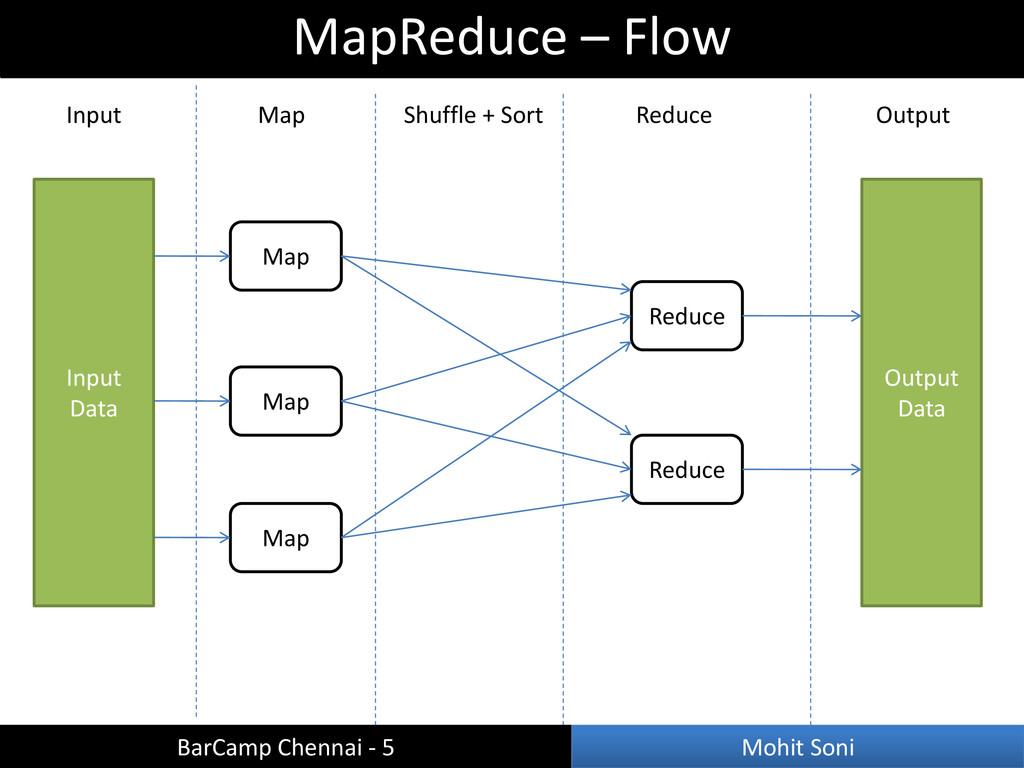
{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> out, Reporter reporter) throws Exception { String l = value.toString(); StringTokenizer t = new StringTokenizer(l); while(t.hasMoreTokens()) { word.set(t.nextToken()); out.collect(word, one); } } } BarCamp Chennai - 5 Mohit Soni Word Count – Mapper
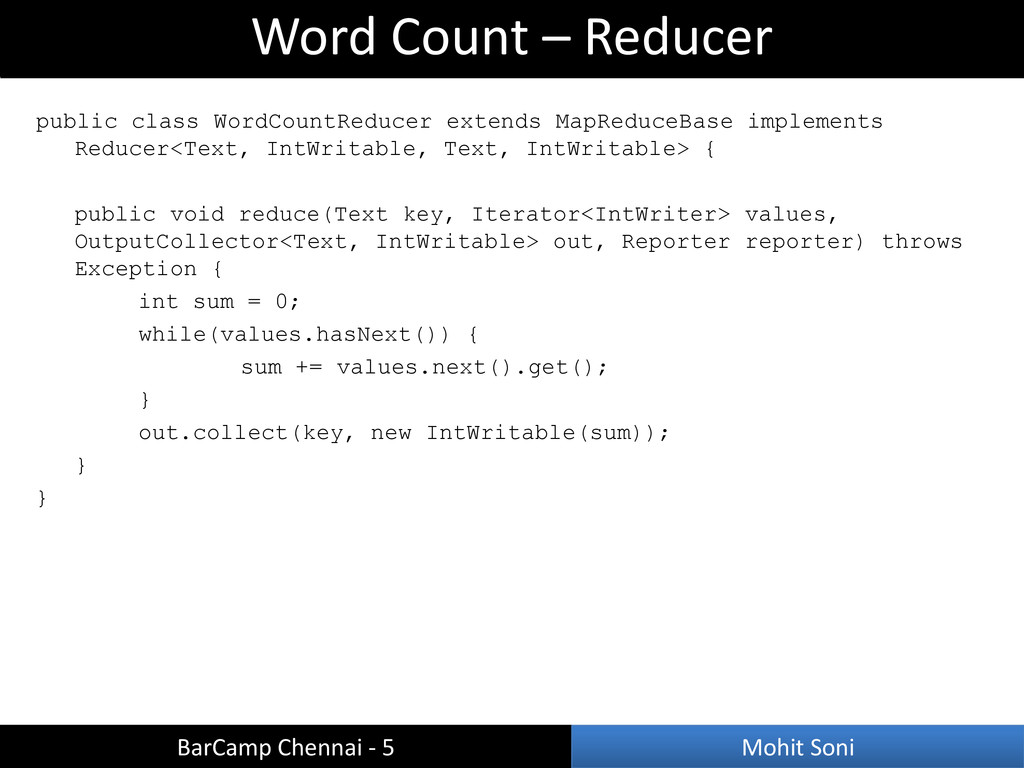
{ public void reduce(Text key, Iterator<IntWriter> values, OutputCollector<Text, IntWritable> out, Reporter reporter) throws Exception { int sum = 0; while(values.hasNext()) { sum += values.next().get(); } out.collect(key, new IntWritable(sum)); } } BarCamp Chennai - 5 Mohit Soni Word Count – Reducer
Data Processing on Large Clusters • Tom White, Hadoop: The Definitive Guide, O’Reilly • Setting up a Single-Node Cluster: http://bit.ly/glNzs4 • Setting up a Multi-Node Cluster: http://bit.ly/f5KqCP Diving Deeper BarCamp Chennai - 5 Mohit Soni
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![public class WordCountConfig { public static void main(String[] args) throws](https://files.speakerdeck.com/presentations/aa05b7d0e2e40130c4be42093019a534/slide_23.jpg){kind=link}
{kind=link}
{kind=link}