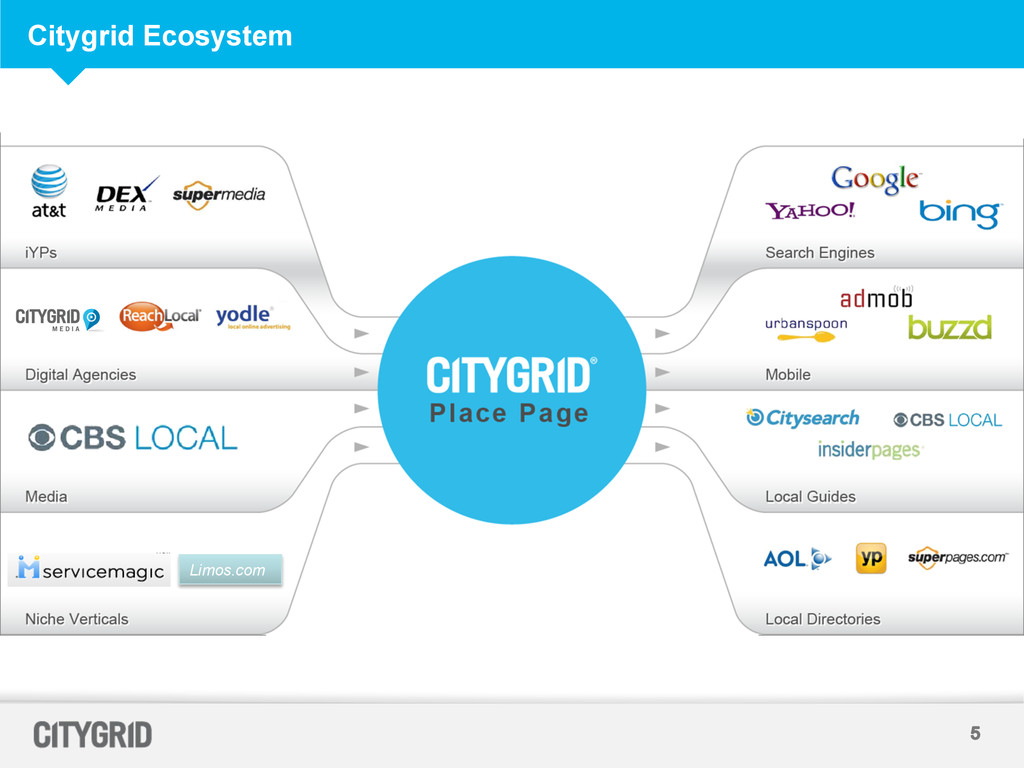
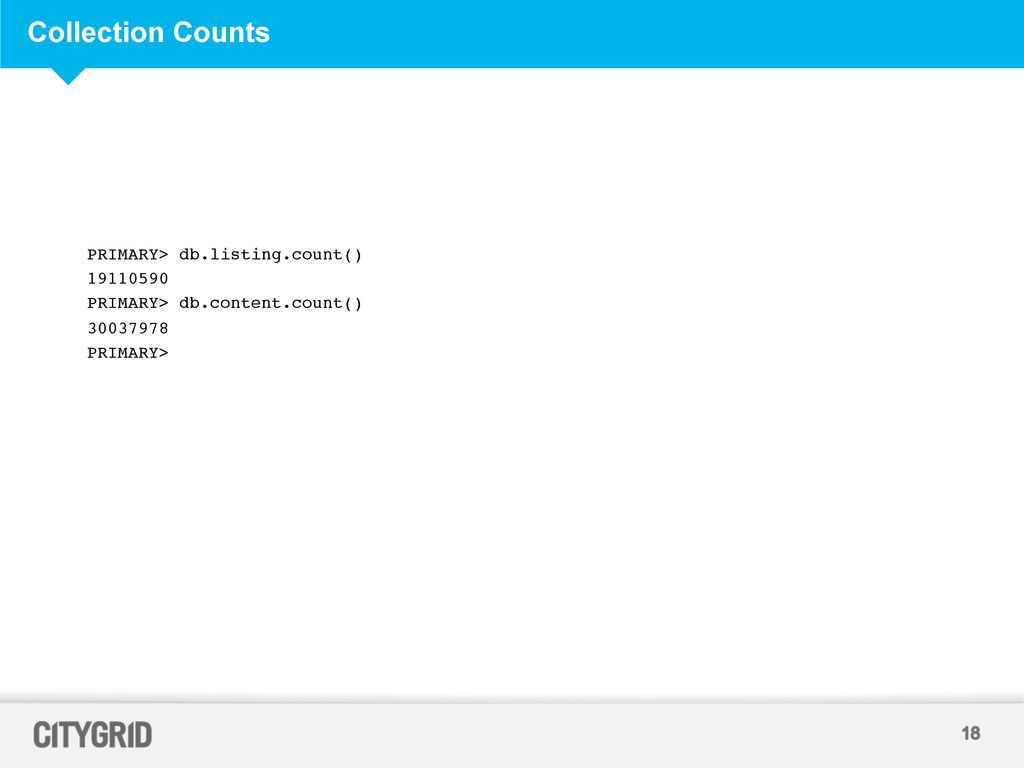
aggregate advertising and content from local businesses, and distribute this data across our network of websites and mobile applications • Citygrid Places Store has 19+ MM places and 1+ MM advertisers • O&O sites and applications are Citysearch.com, Urbanspoon.com and InsiderPages.com
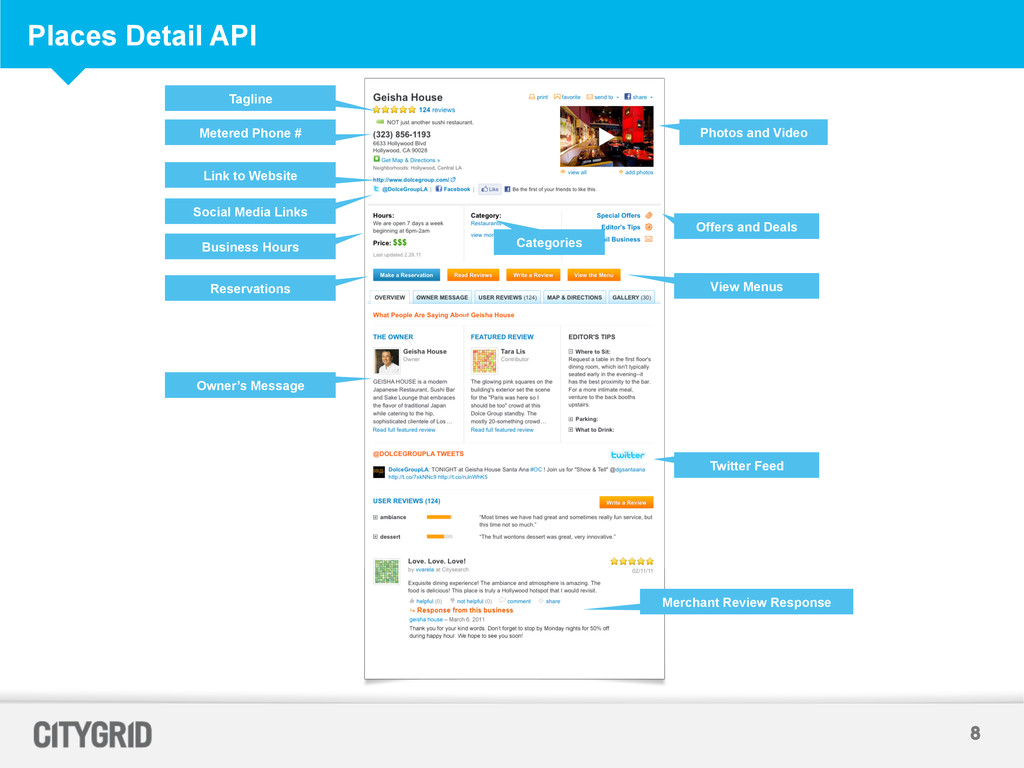
What, Where, Latitude / Longitude, Radius – XML, JSON, Protocol Buffer Responses – SOLR Index • Places Reviews / Offers API – Request Parameters - What, Where, Latitude / Longitude, Listing ID – XML, JSON, Protocol Buffer Responses – SOLR Index • Places Detail – Request Parameters - Listing ID, Info USA ID, Public ID – XML, JSON, Protocol Buffer Responses – Mongo DB • AD API’s • Additional Information is at http://developer.citygridmedia.com
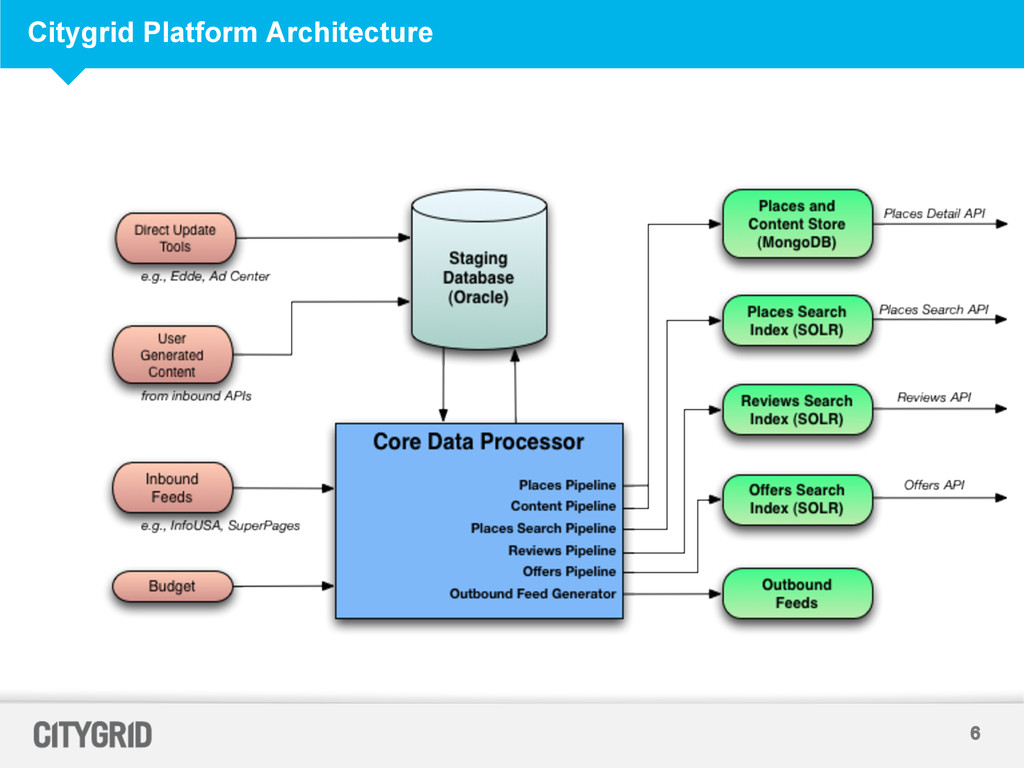
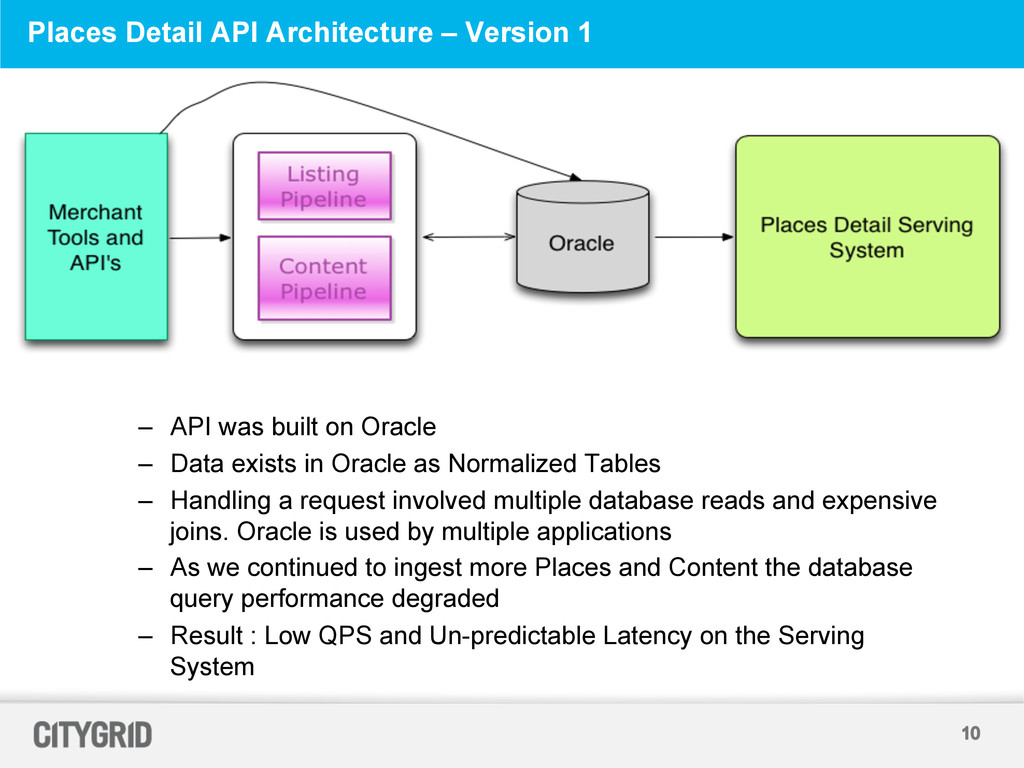
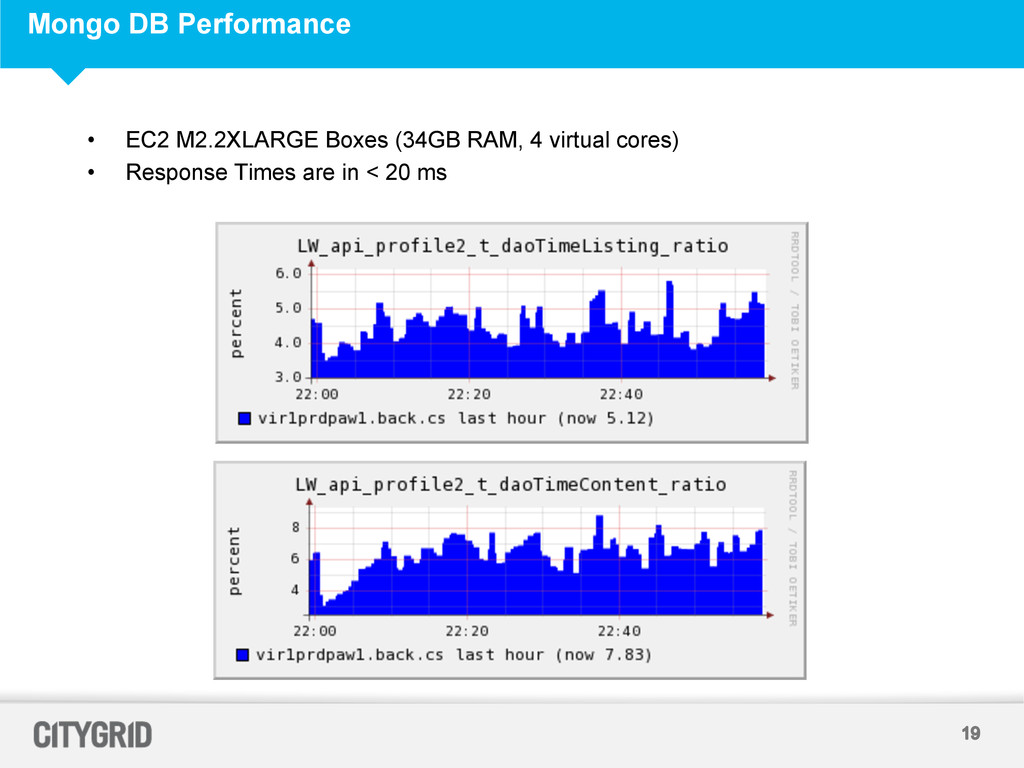
built on Oracle – Data exists in Oracle as Normalized Tables – Handling a request involved multiple database reads and expensive joins. Oracle is used by multiple applications – As we continued to ingest more Places and Content the database query performance degraded – Result : Low QPS and Un-predictable Latency on the Serving System
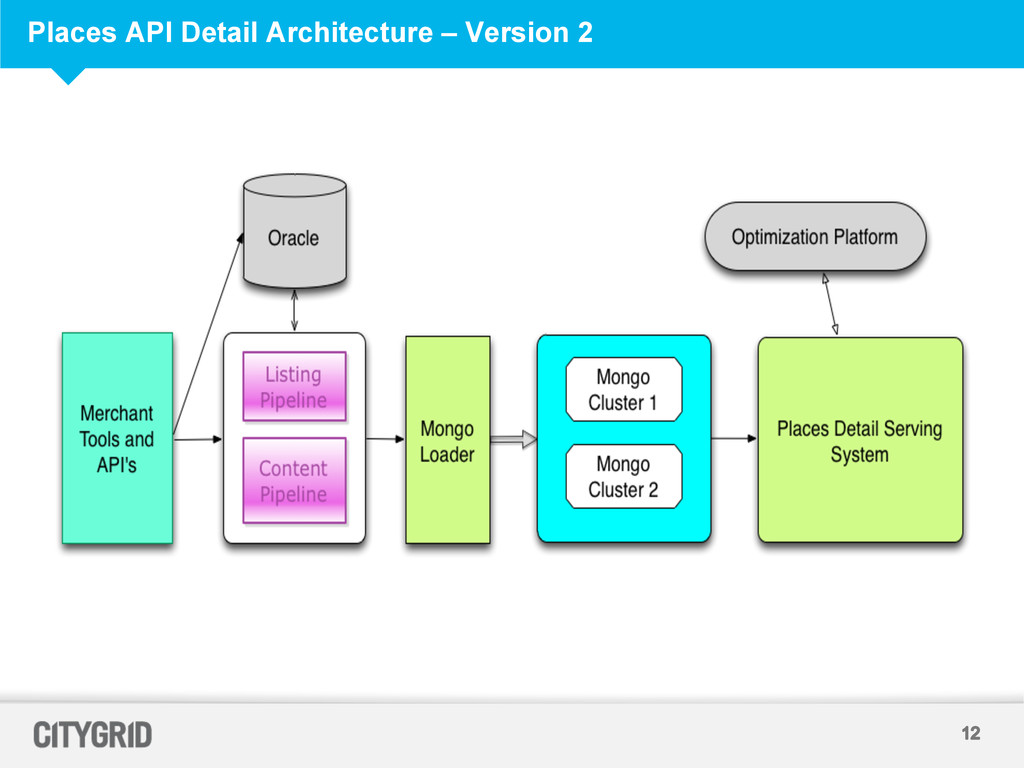
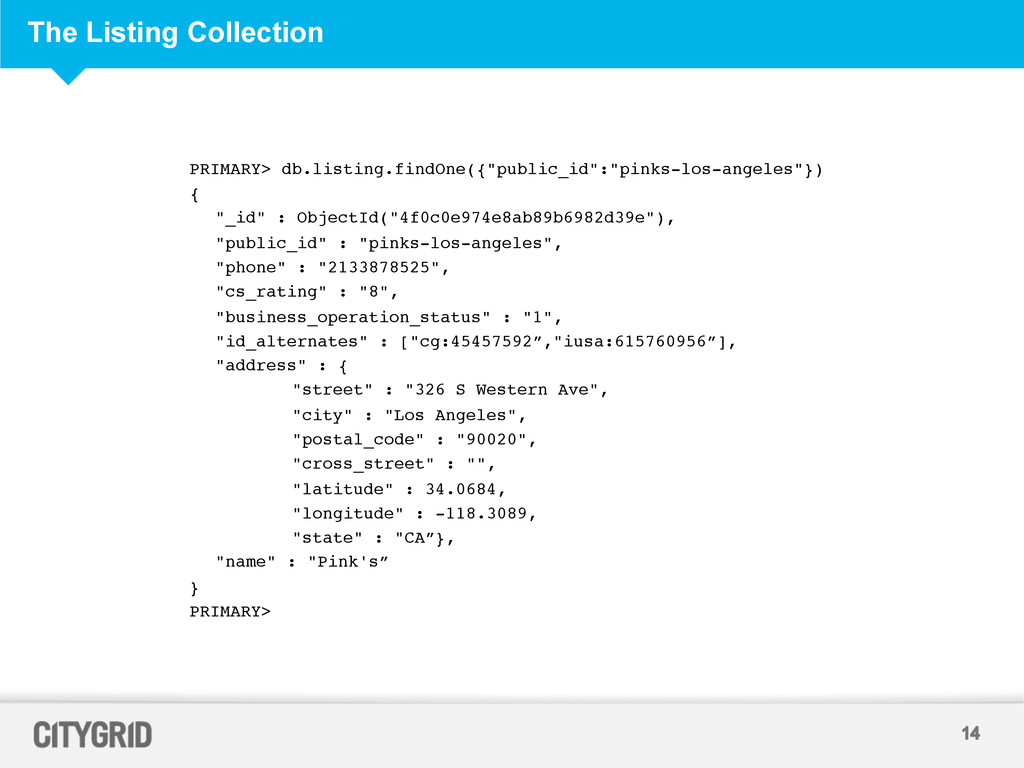
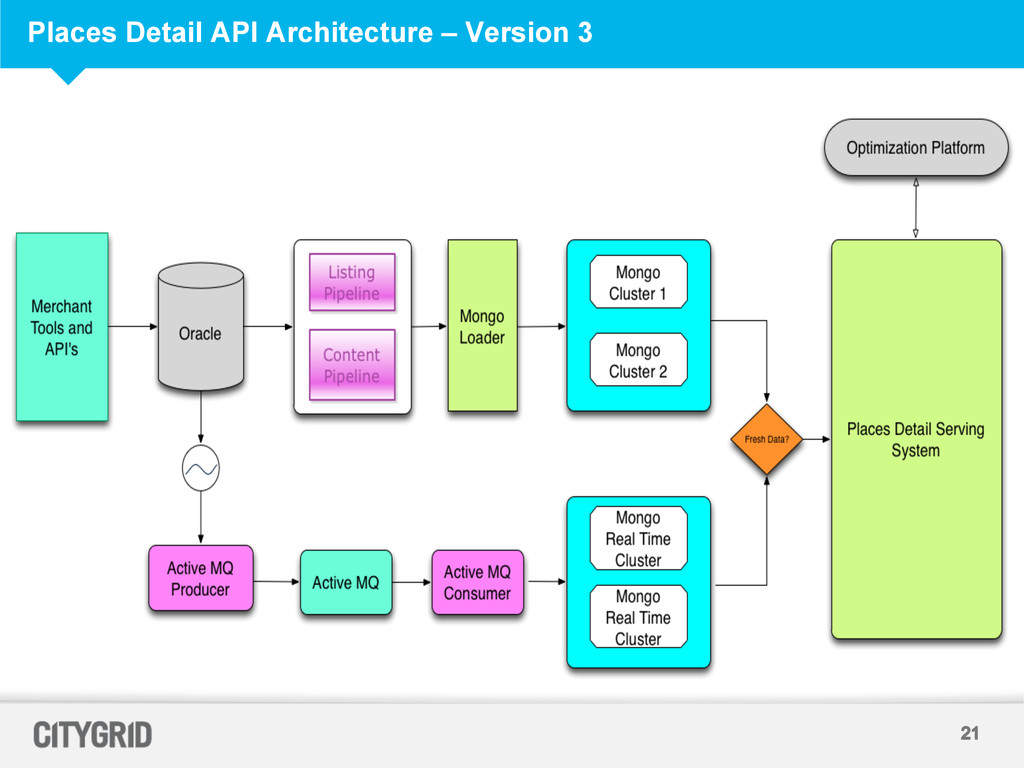
Each Mongo Cluster is a two node replica set for redundancy • Each Mongo Instance has two collections – Listing Collection and Content Collections – Listing Collection has basic data about a Place – Content Collection stores content received from multiple providers which gets matched against the listing • Two Mongo Clusters – Load a Cluster Cold and swap it into serving – Data Pipelines do not produce deltas hence we have full data loads – Updating / Inserting during serving results in data syncs between replicas which resulted in degraded performance for the serving API
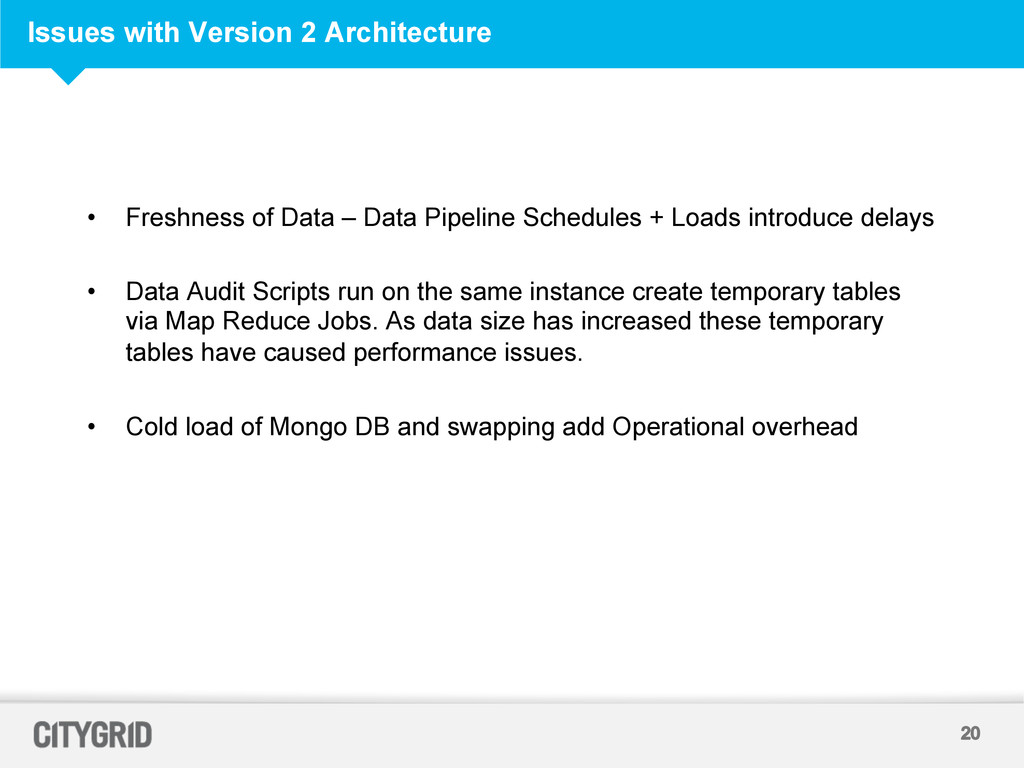
Data Pipeline Schedules + Loads introduce delays • Data Audit Scripts run on the same instance create temporary tables via Map Reduce Jobs. As data size has increased these temporary tables have caused performance issues. • Cold load of Mongo DB and swapping add Operational overhead
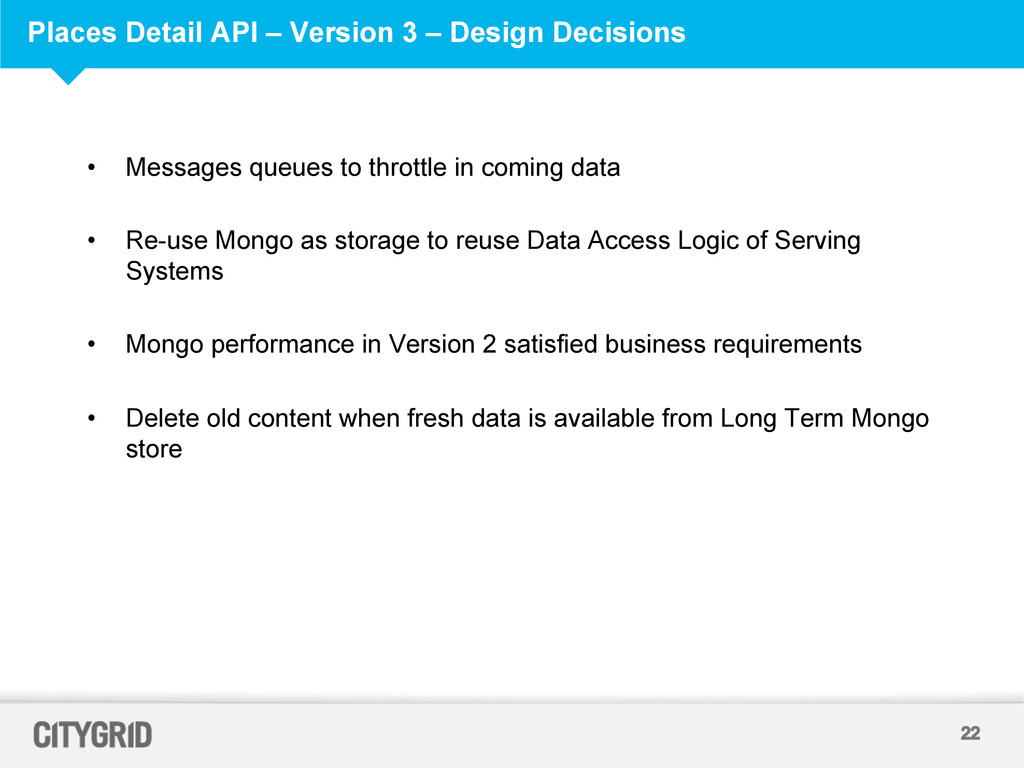
Messages queues to throttle in coming data • Re-use Mongo as storage to reuse Data Access Logic of Serving Systems • Mongo performance in Version 2 satisfied business requirements • Delete old content when fresh data is available from Long Term Mongo store
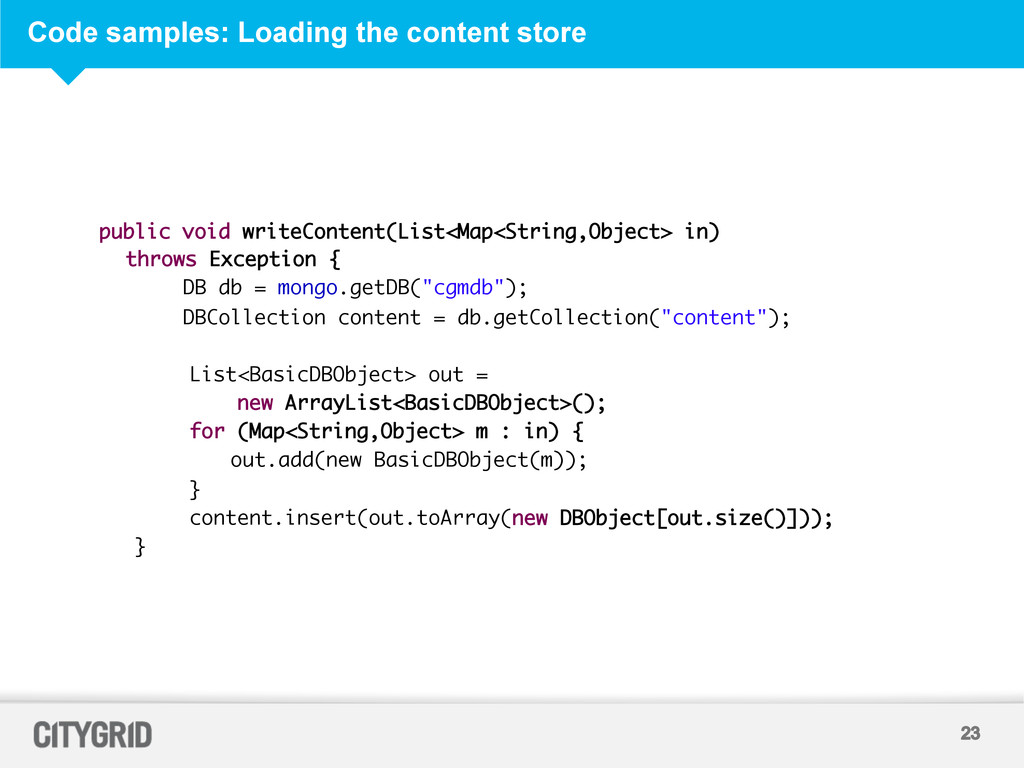
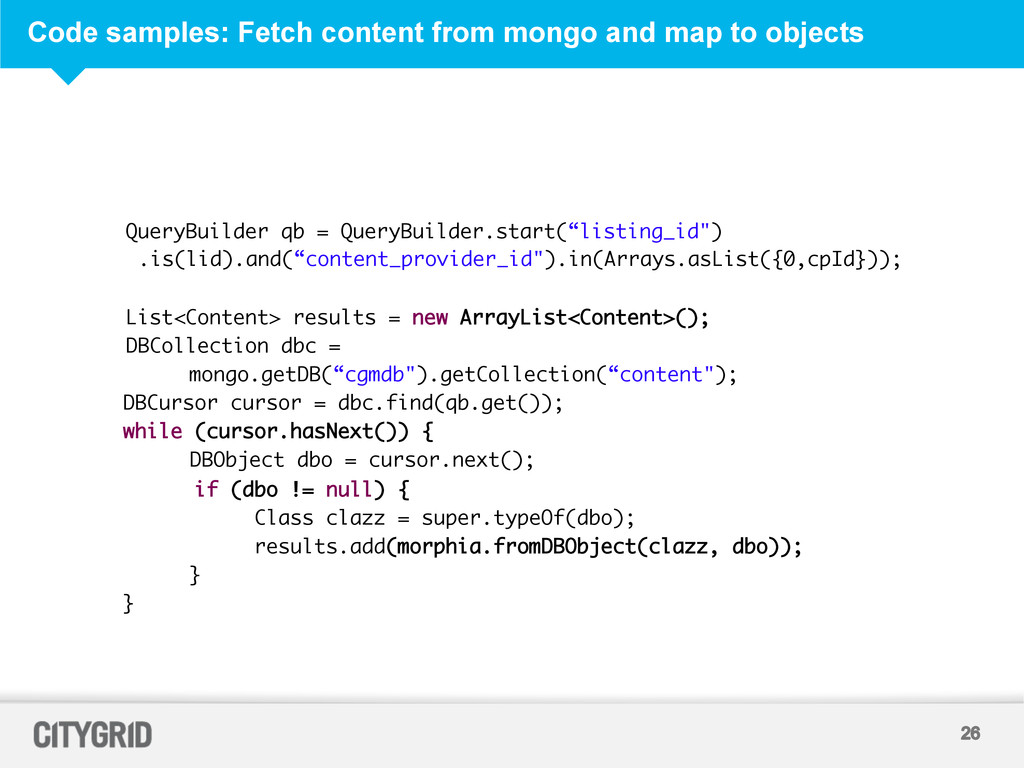
throws Exception { DB db = mongo.getDB("cgmdb"); DBCollection content = db.getCollection("content"); List<BasicDBObject> out = new ArrayList<BasicDBObject>(); for (Map<String,Object> m : in) { out.add(new BasicDBObject(m)); } content.insert(out.toArray(new DBObject[out.size()])); }
good for data lookups but to generate statistics and aggregations across large data sets map reduce is the suggested approach. • Mongo DB supports Map Reduce commands for aggregations – Creates a collection to hold the output – This collection is subject to replication – caused production degradation last week when our content and listing sizes increased. – The output collection was replicated between replicas – Solution: Local DB not subject to replication – Currently broken for map reduce on secondary: https://jira.mongodb.org/browse/SERVER-4264
Data Loads • Shard Listing and Content Data • Integrate Search, Ads and other end points with Mongo DB – Prefix and fuzzy match performs better with less stored fields in SOLR – Reduce SOLR memory footprint by putting stored fields in Mongo • Spring Data Integration
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The Content Collection ! PRIMARY> db.content.findOne({public_id:” pi-on-sunset-los-angeles",cap_provider_id: {$in:[”0”,”1”]}})! { !](https://files.speakerdeck.com/presentations/4f21a662a0a84d0022004936/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}