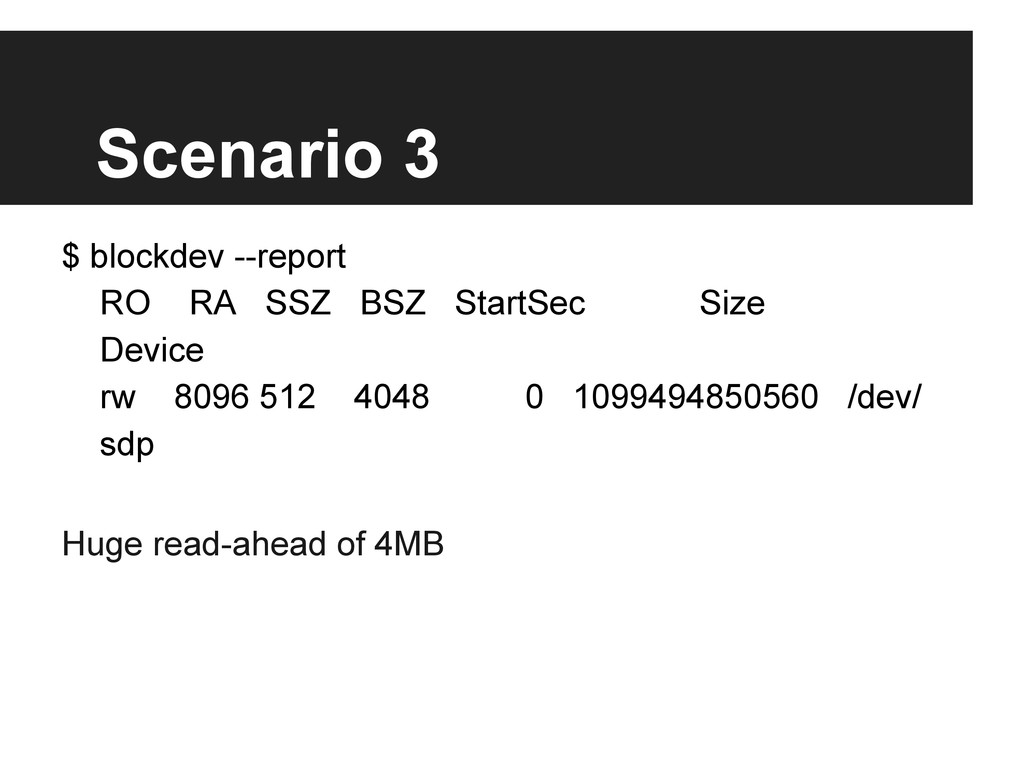
MongoNYC 2012: Operational Best Practices, Scott Hernandez, 10gen. In this session we’ll talk through a series of examples to distill some of our best operational practices. The format of this talk is an interactive and fun adventure through some real-world cases that come from real systems and large deployments. This session will touch on backups, network availability, performance pitfalls, indexing/schema-design, log management, monitoring and alerting along with some good examples of diagnostic techniques with a goal of finding good solutions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
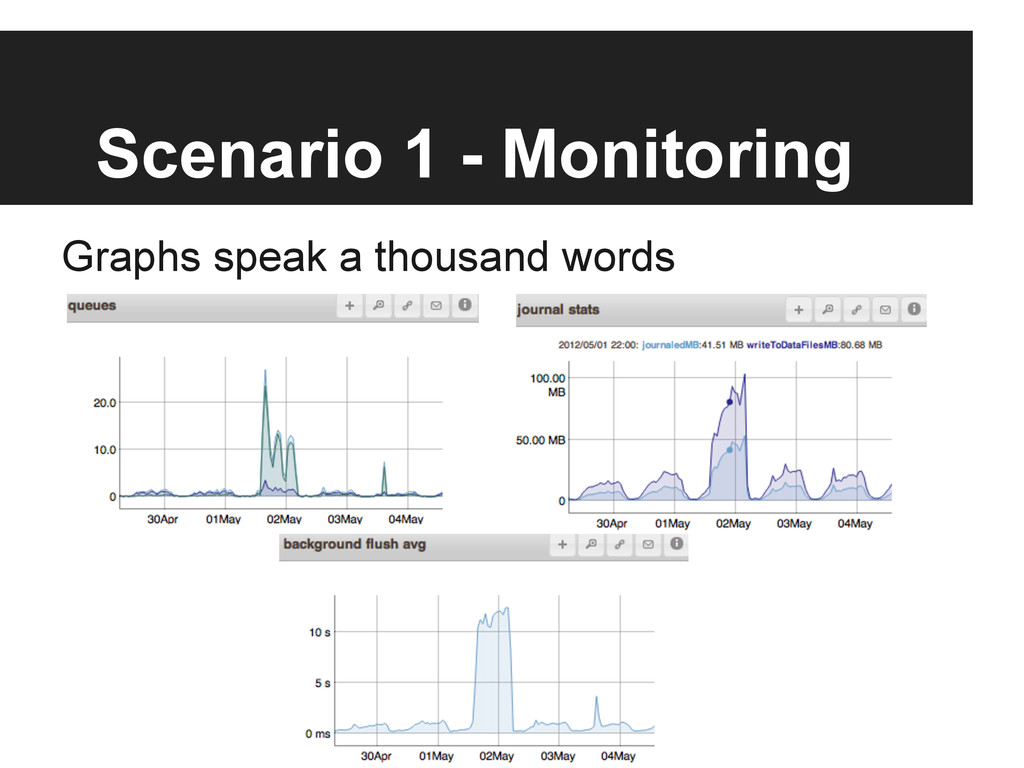{kind=link}
{kind=link}
{kind=link}
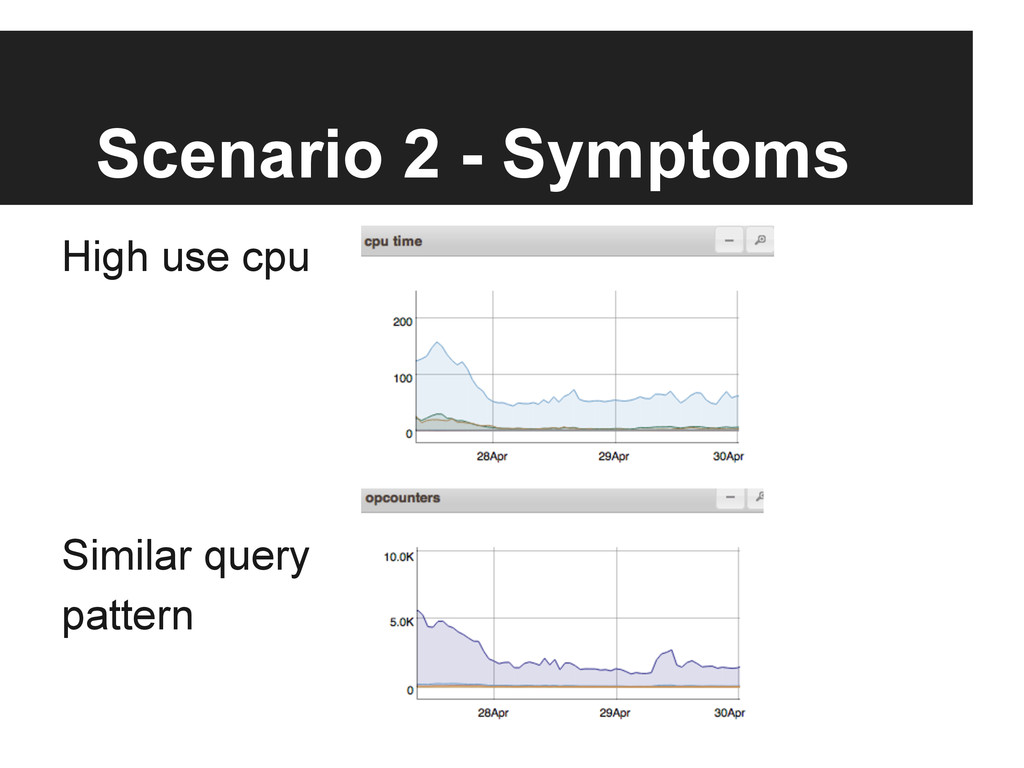{kind=link}
{kind=link}
{kind=link}
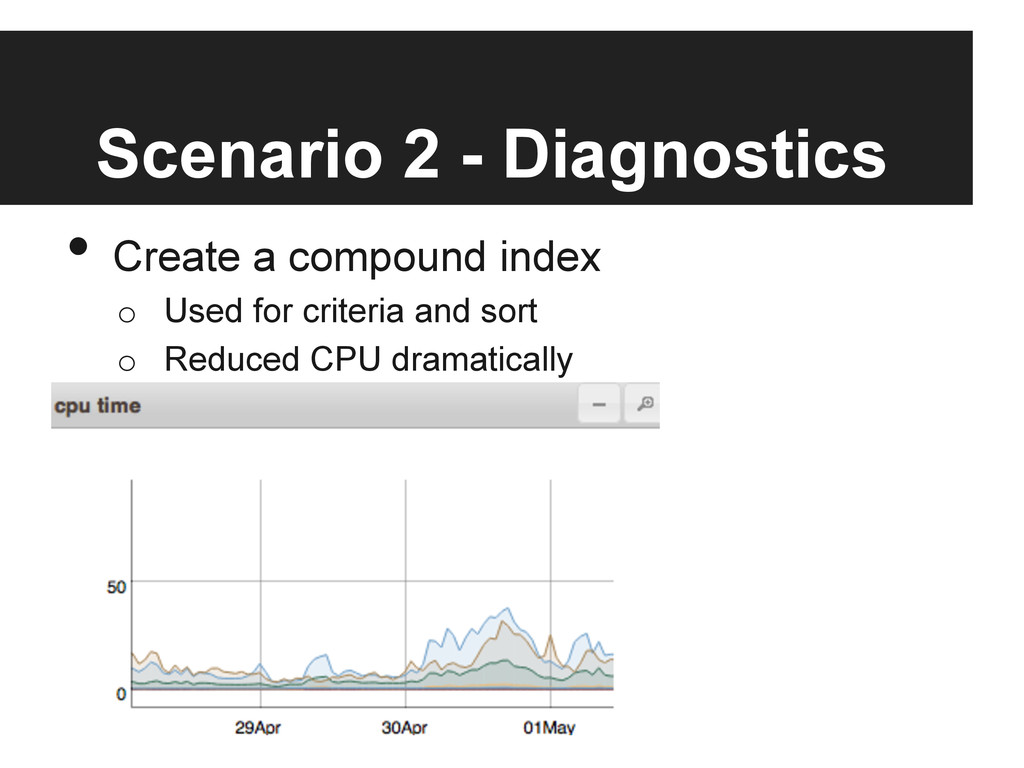{kind=link}
{kind=link}
{kind=link}
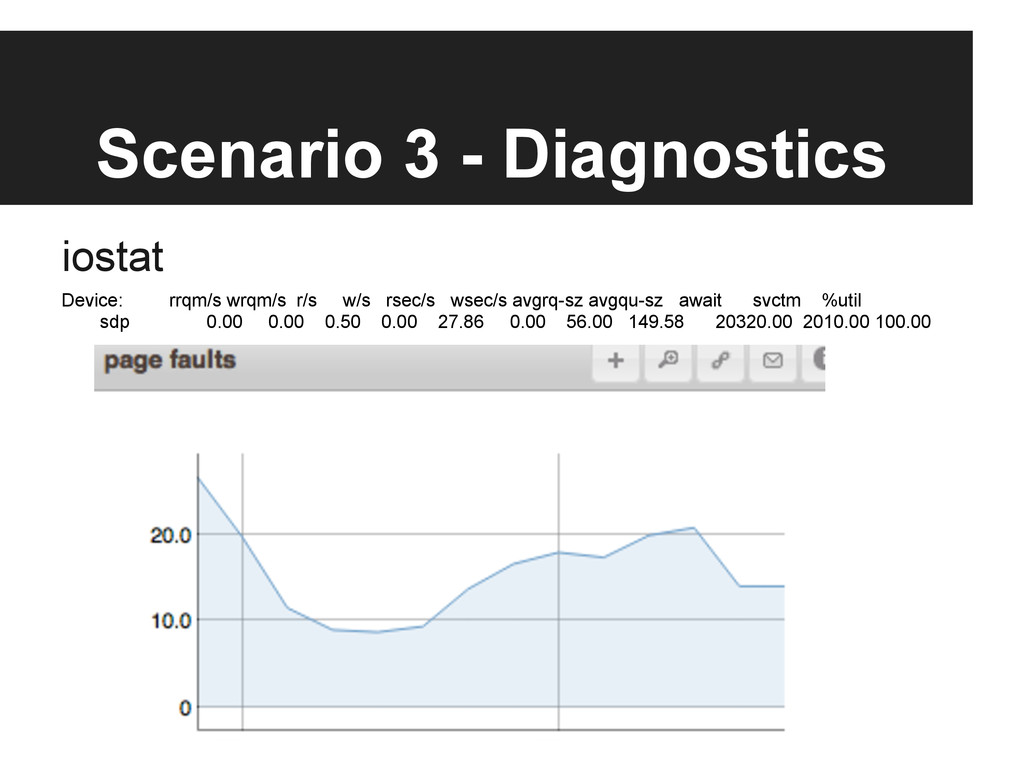{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}