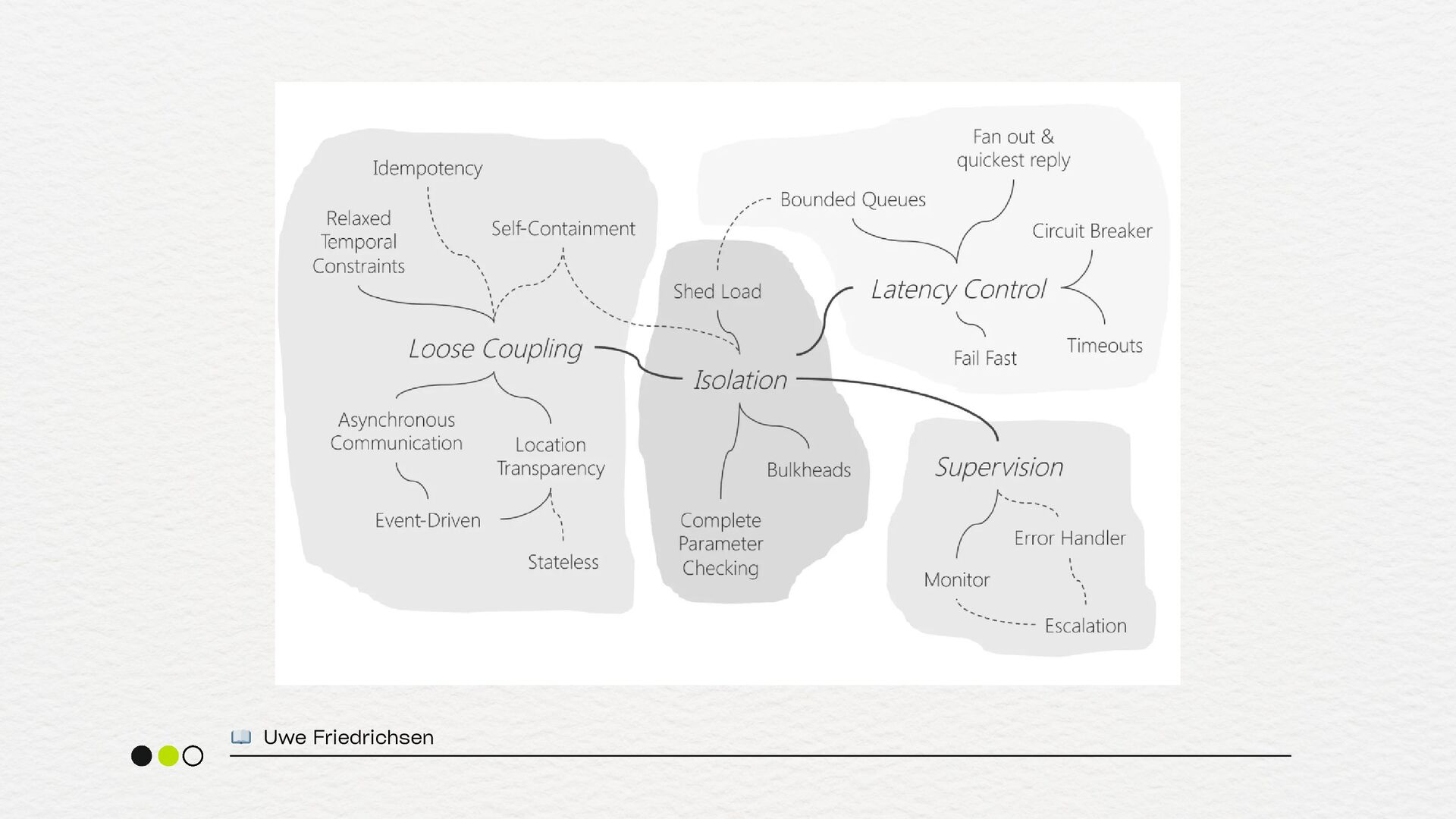
mesmo se parte do sistema falhar recupera-se rapidamente e mantém serviço útil sob falha 📖 Netflix Tech Blog: Making the Netflix API More Resilient (2012). alguns conceitos próximos
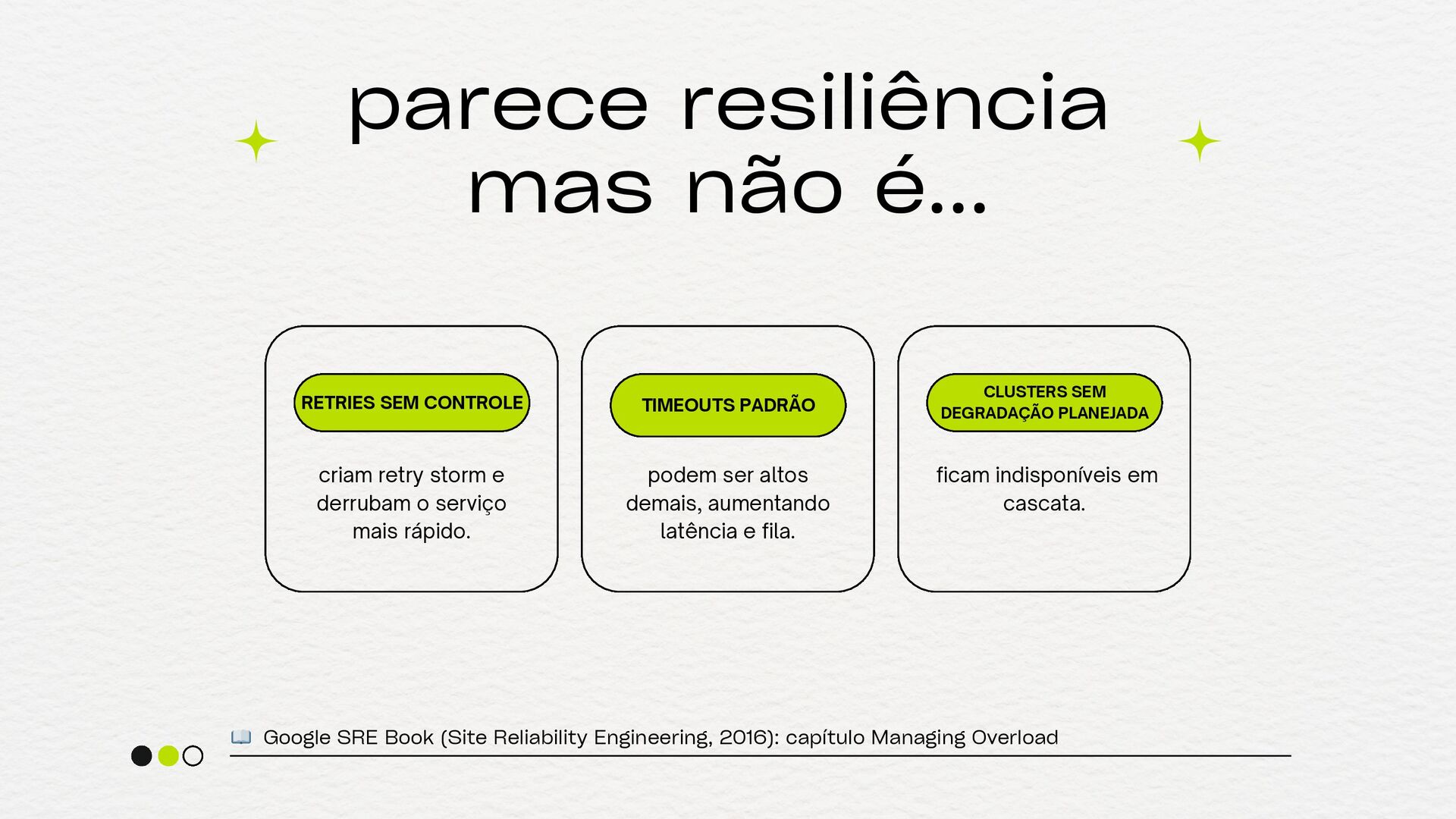
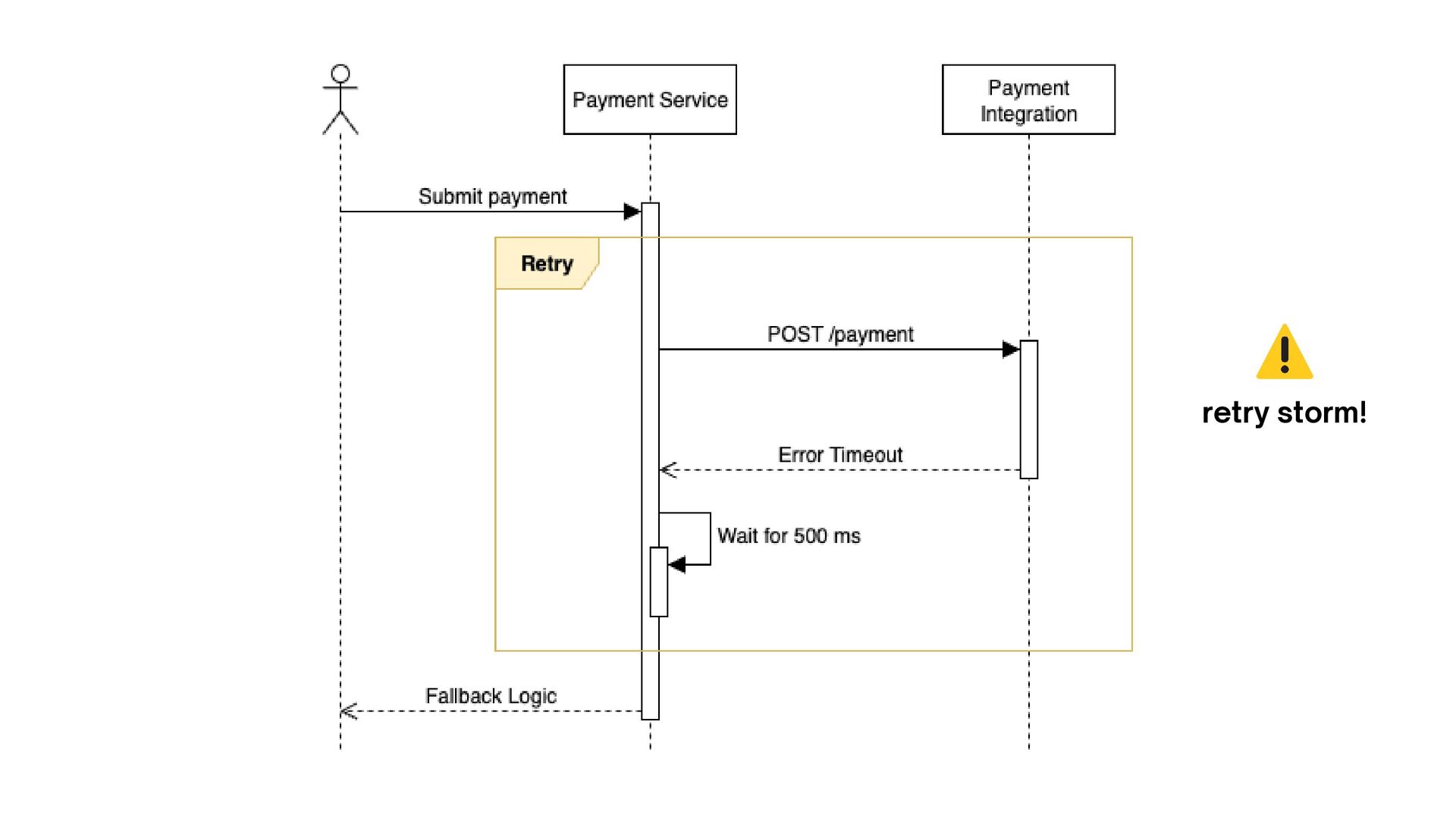
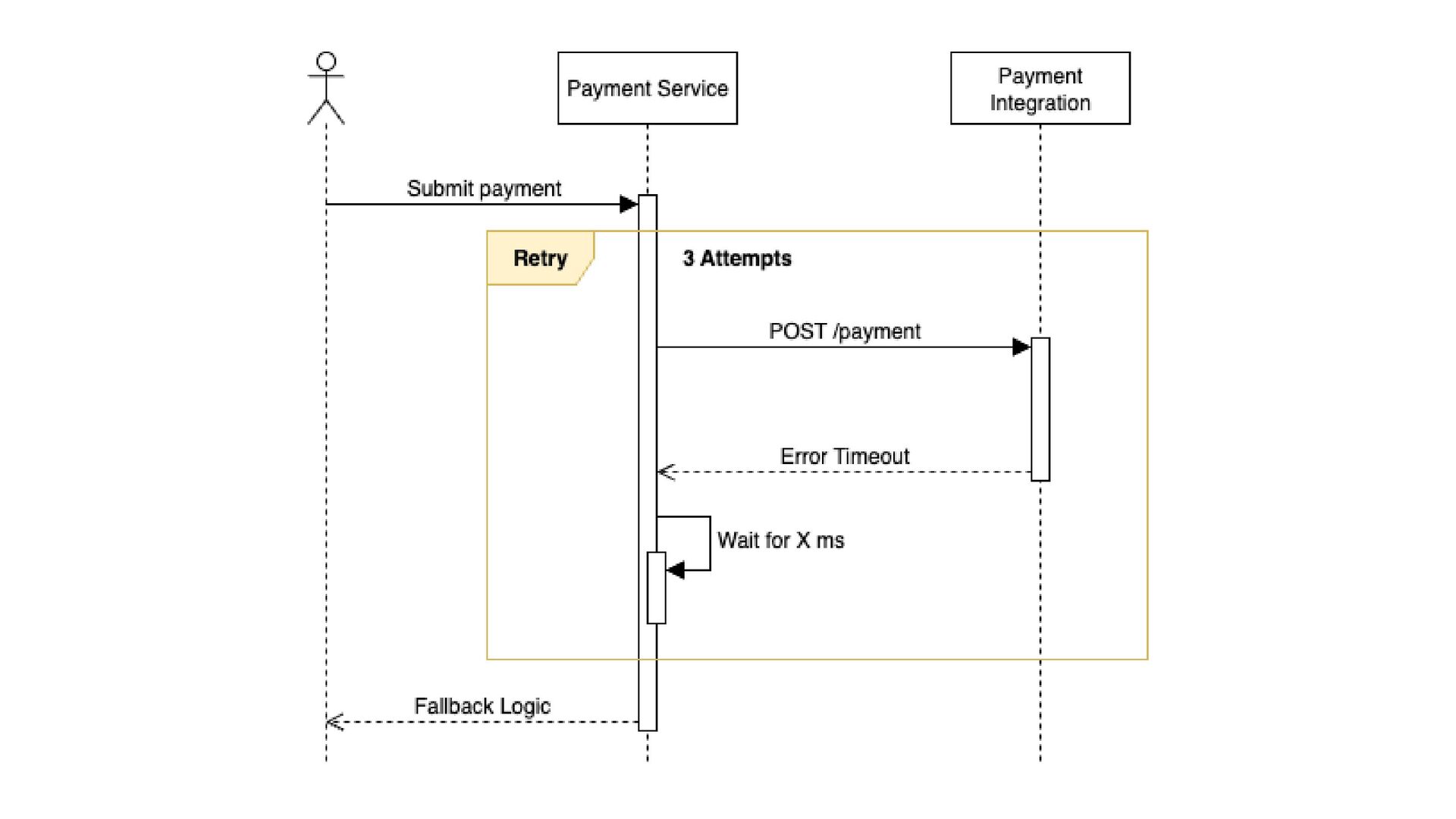
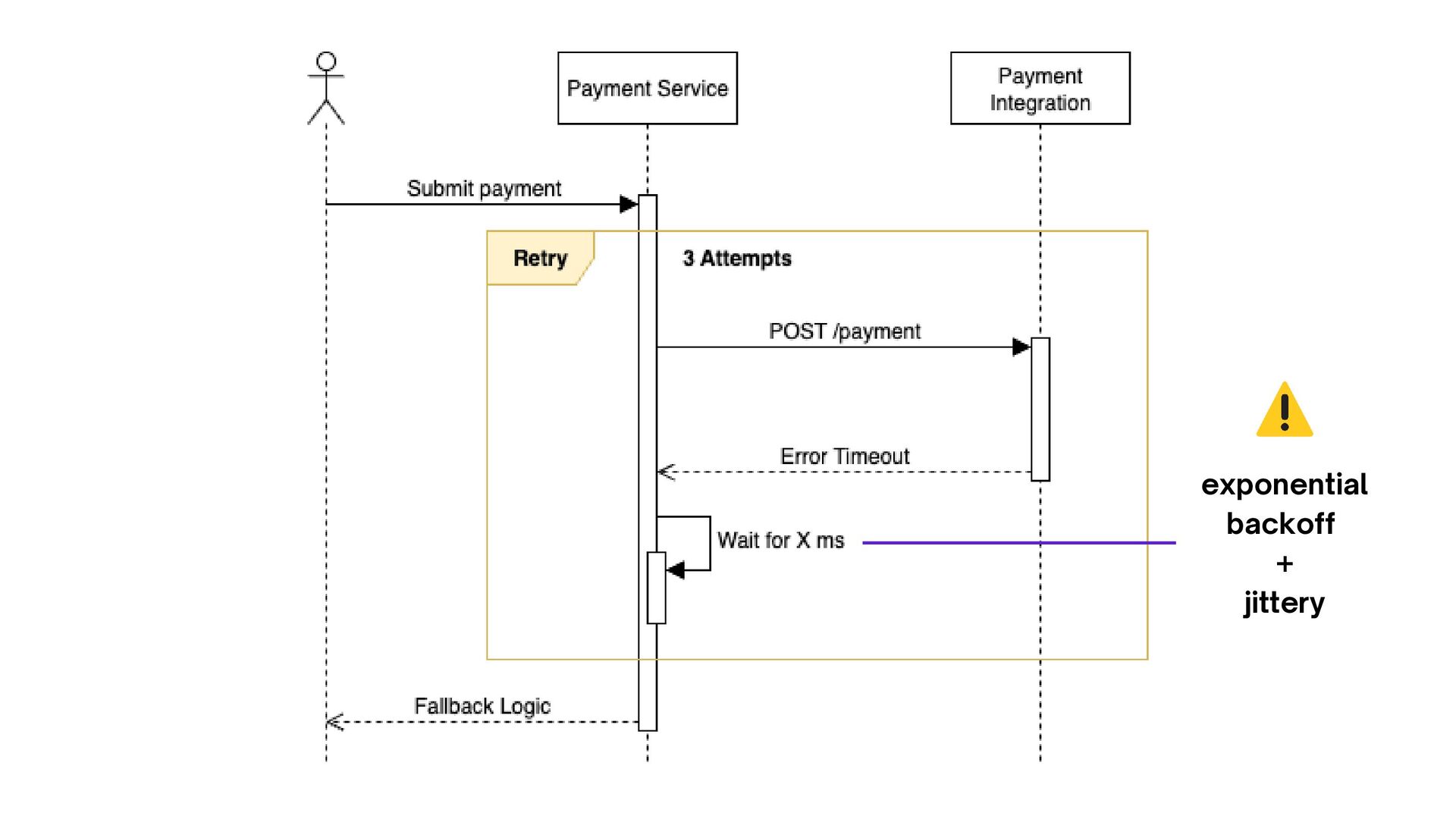
Reliability Engineering, 2016): capítulo Managing Overload RETRIES SEM CONTROLE TIMEOUTS PADRÃO CLUSTERS SEM DEGRADAÇÃO PLANEJADA criam retry storm e derrubam o serviço mais rápido. podem ser altos demais, aumentando latência e fila. ficam indisponíveis em cascata.
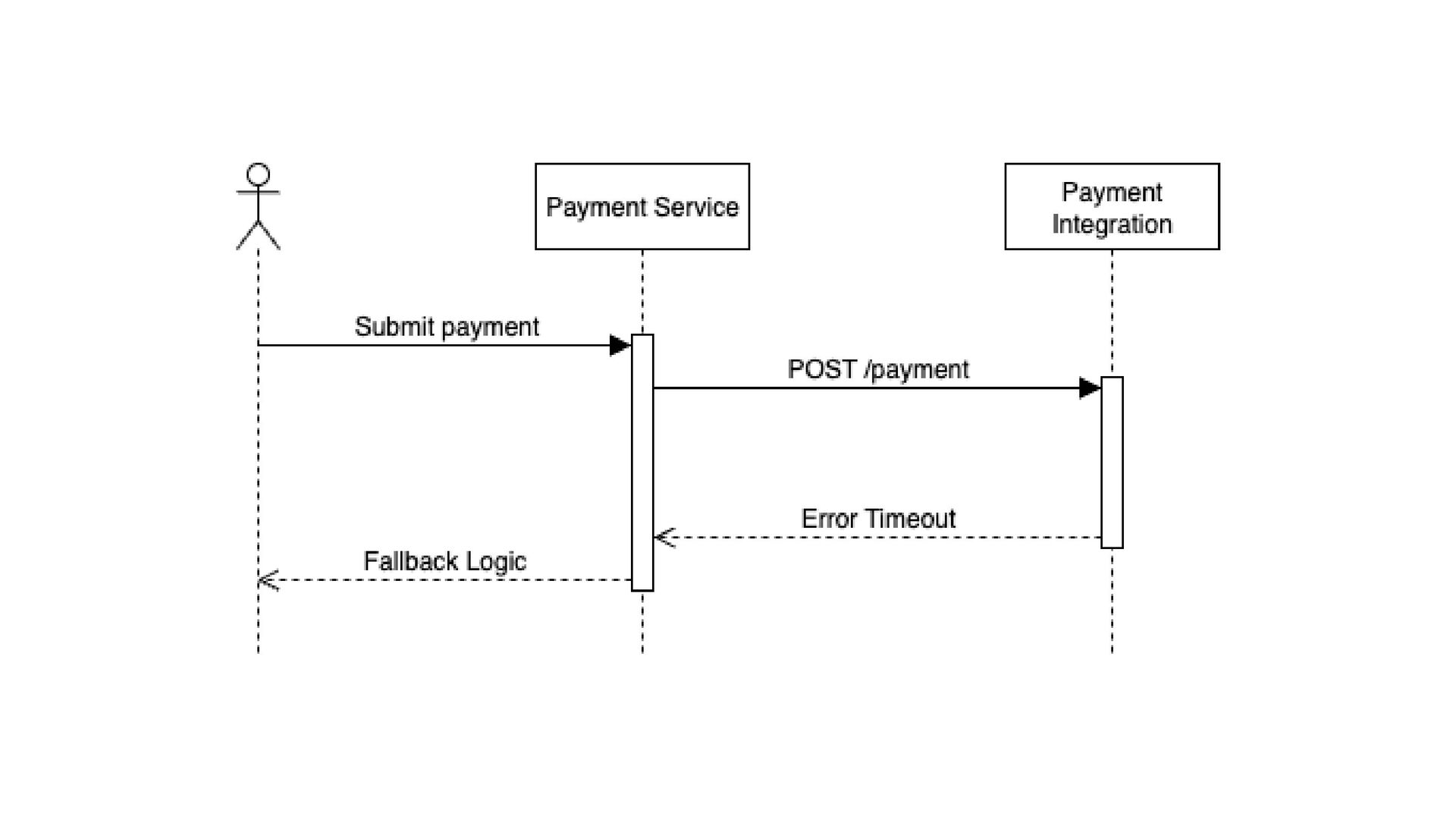
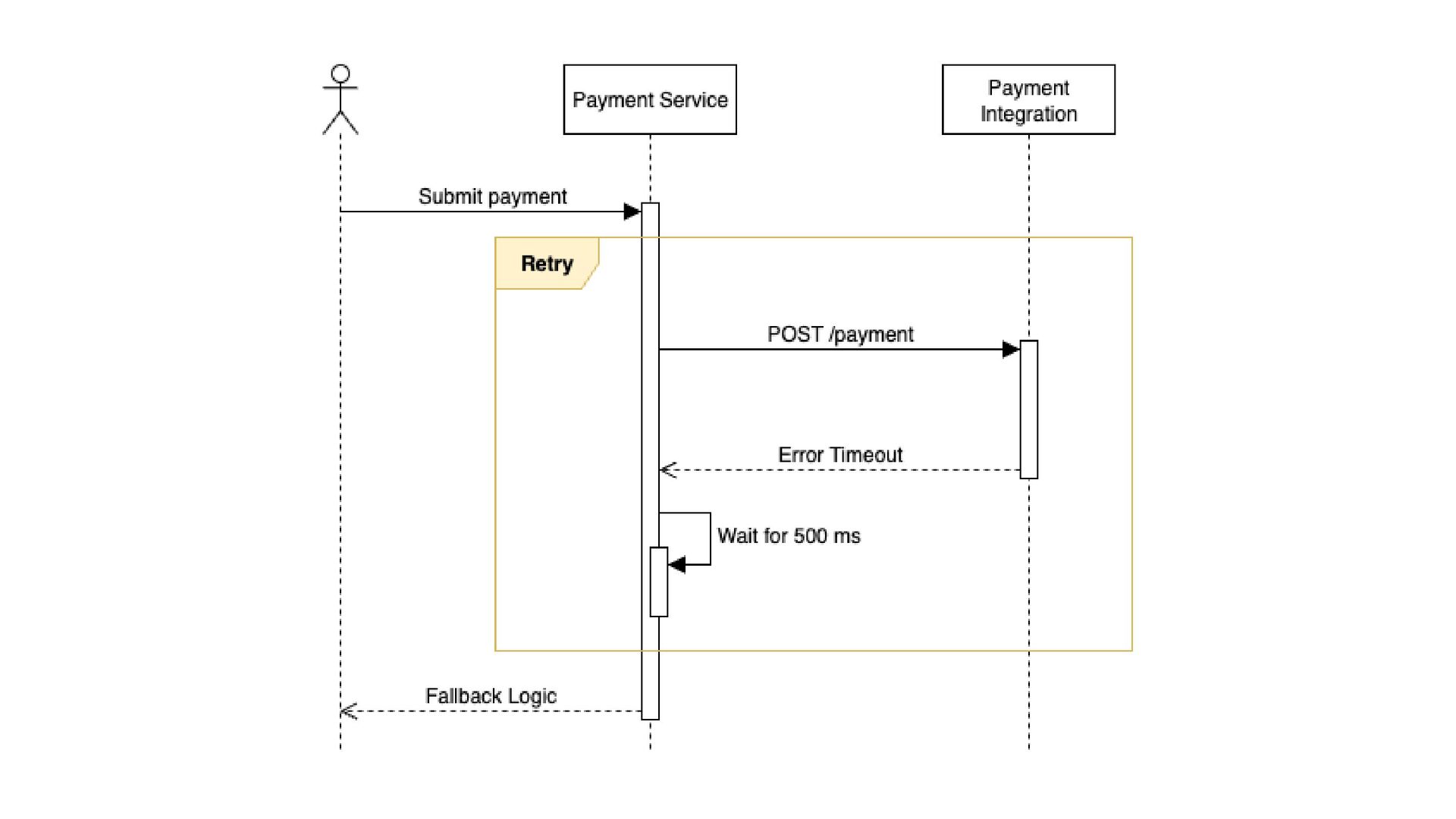
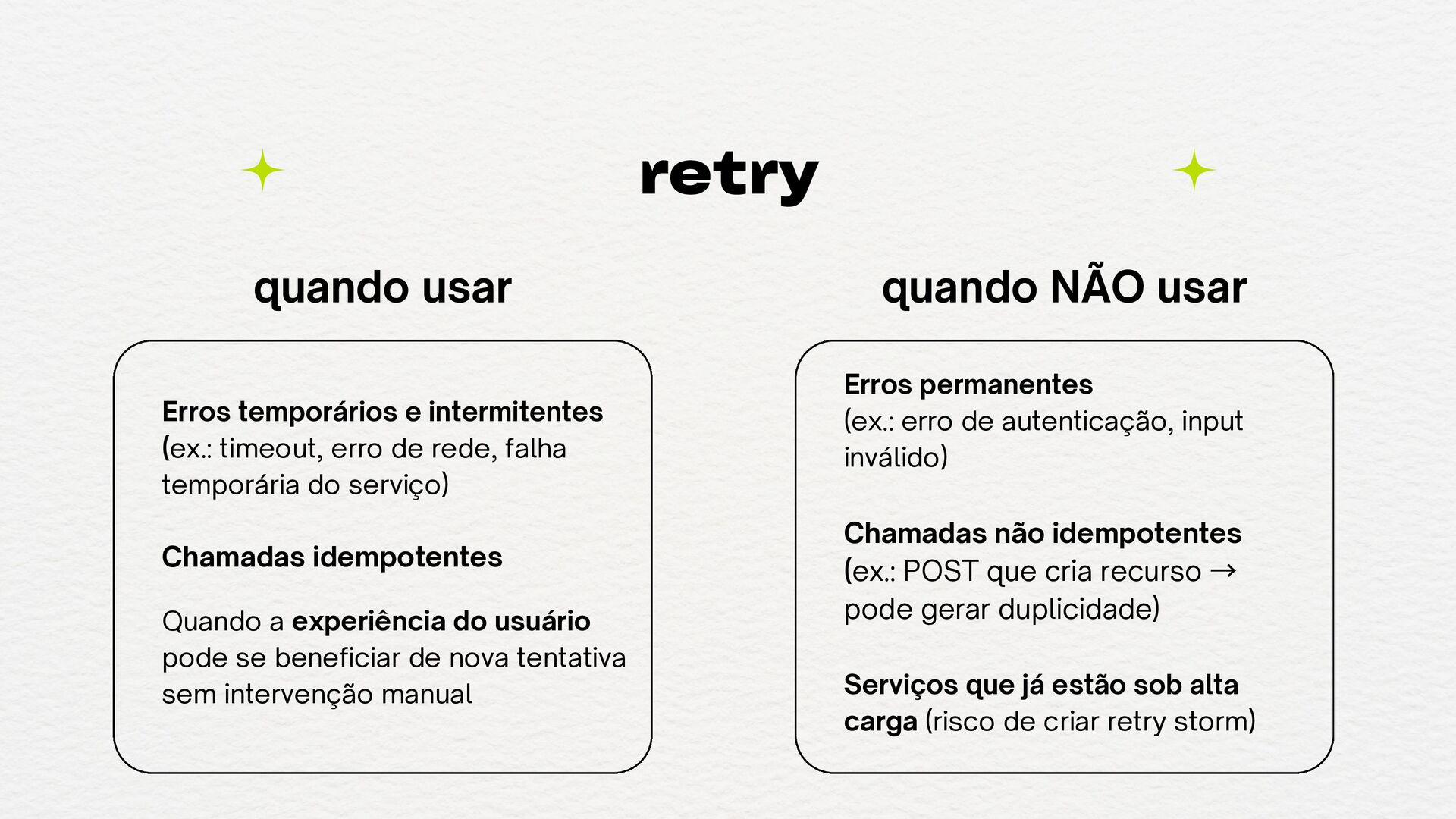
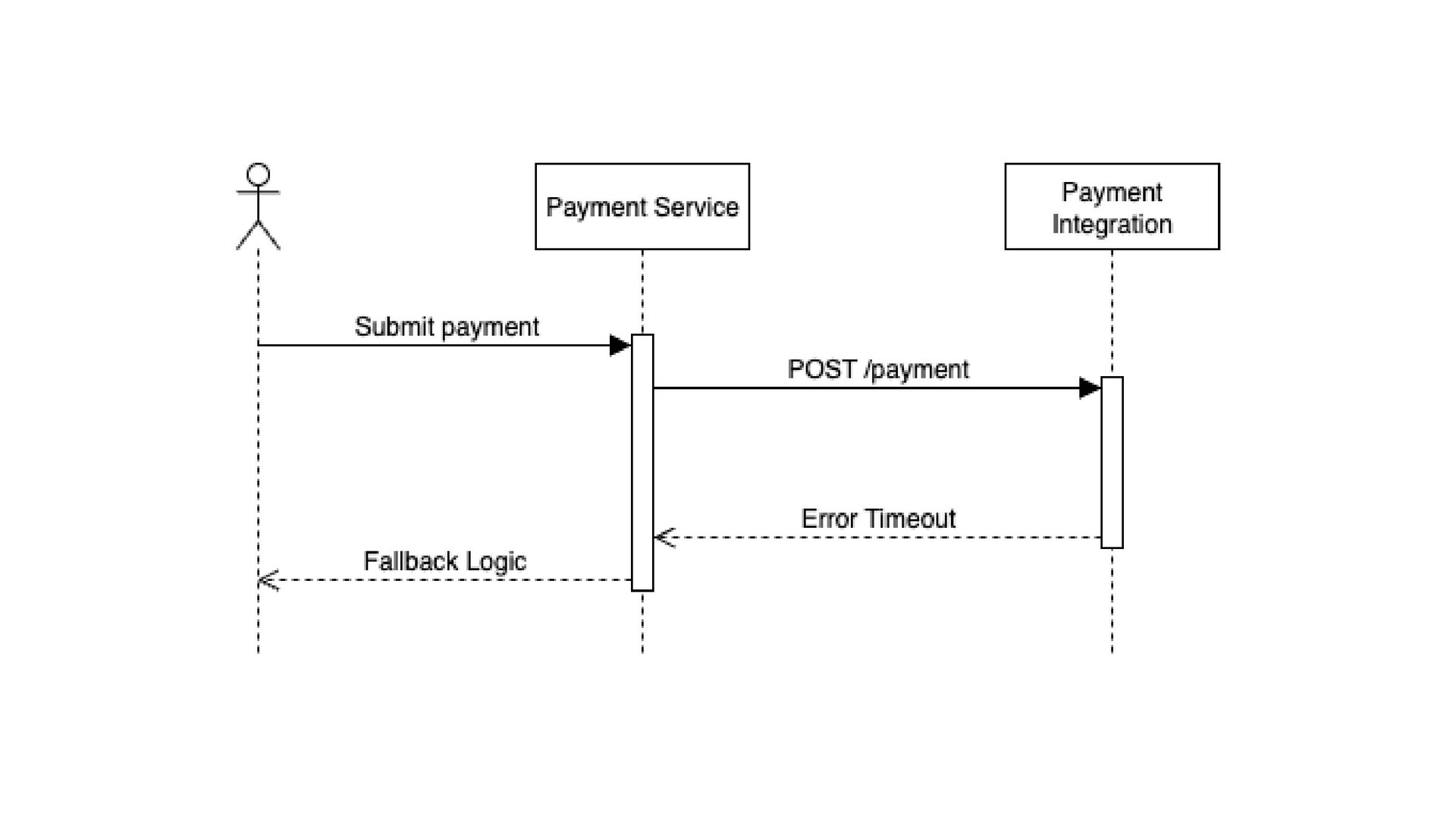
beneficiar de nova tentativa sem intervenção manual Erros temporários e intermitentes (ex.: timeout, erro de rede, falha temporária do serviço) quando usar Chamadas não idempotentes (ex.: POST que cria recurso → pode gerar duplicidade) Serviços que já estão sob alta carga (risco de criar retry storm) Erros permanentes (ex.: erro de autenticação, input inválido) quando NÃO usar
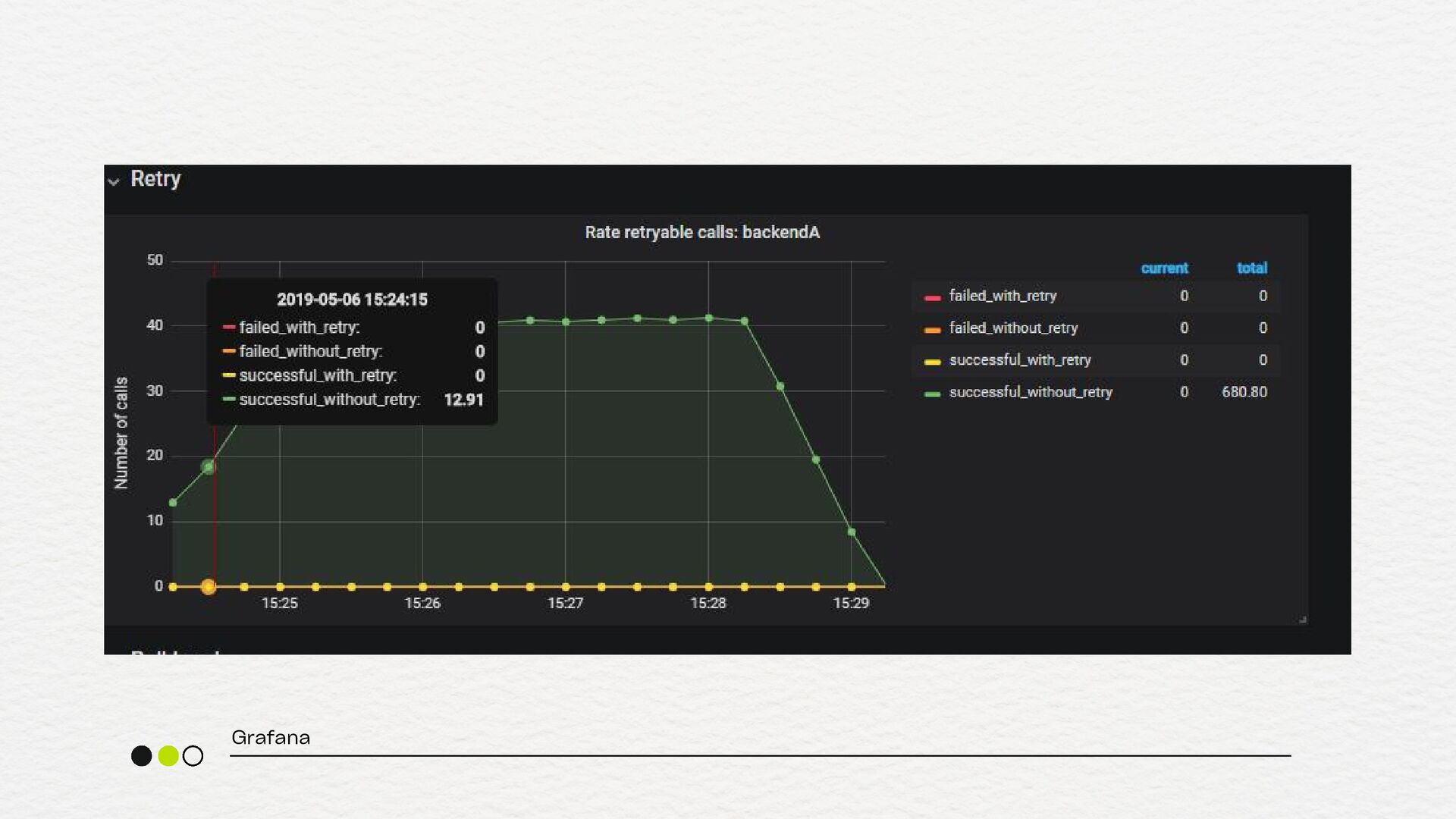
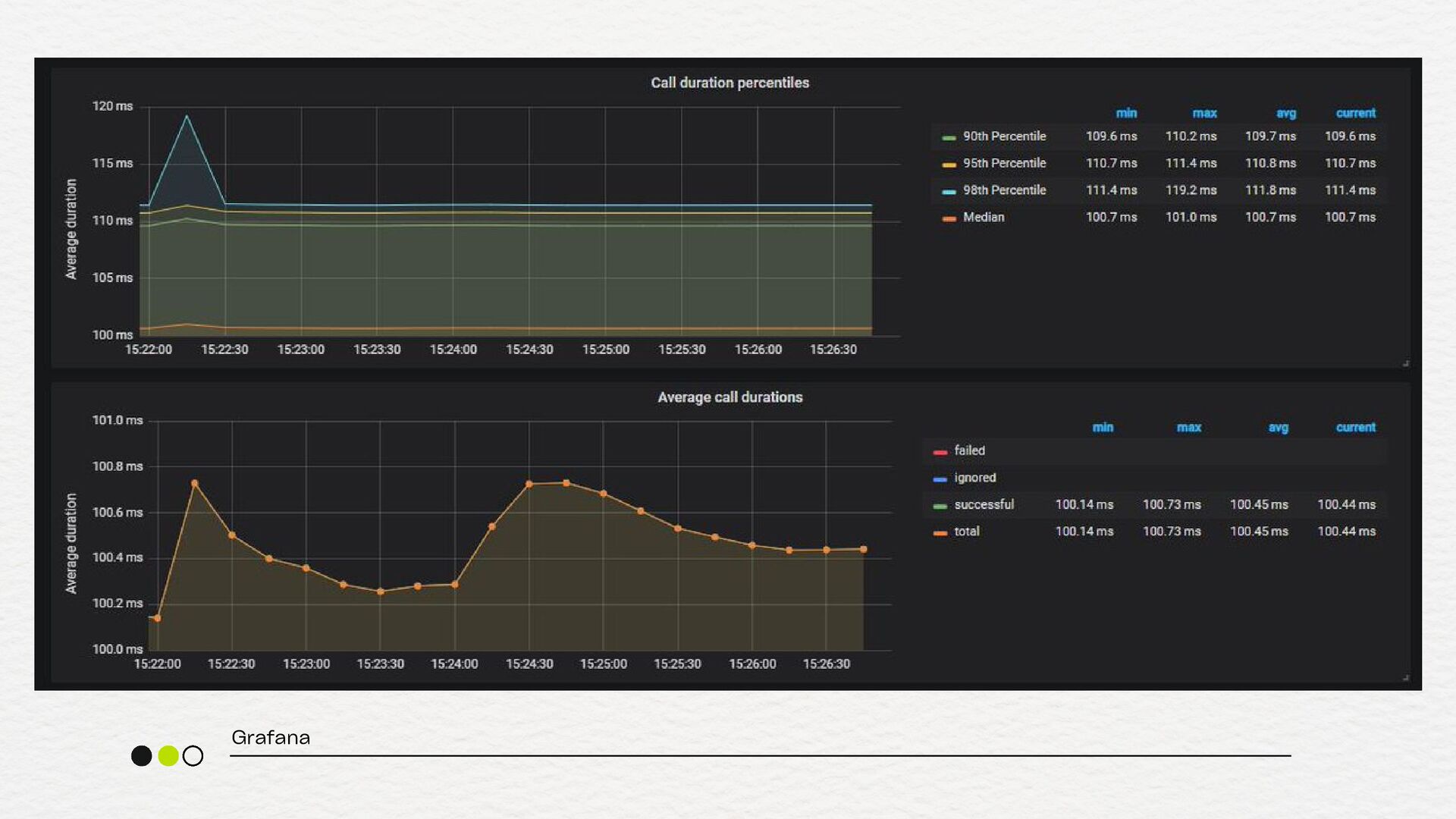
depois do retry) retry.failed.count (quantos falharam mesmo após retry) latency.p95 (para garantir que o retry não está aumentando demais a latência) metrificando
falhas se manifestem rapidamente e que o sistema se recupere de forma segura." 📖 Release It! Design and Deploy Production-Ready Software (Michael Nygard, 2018)
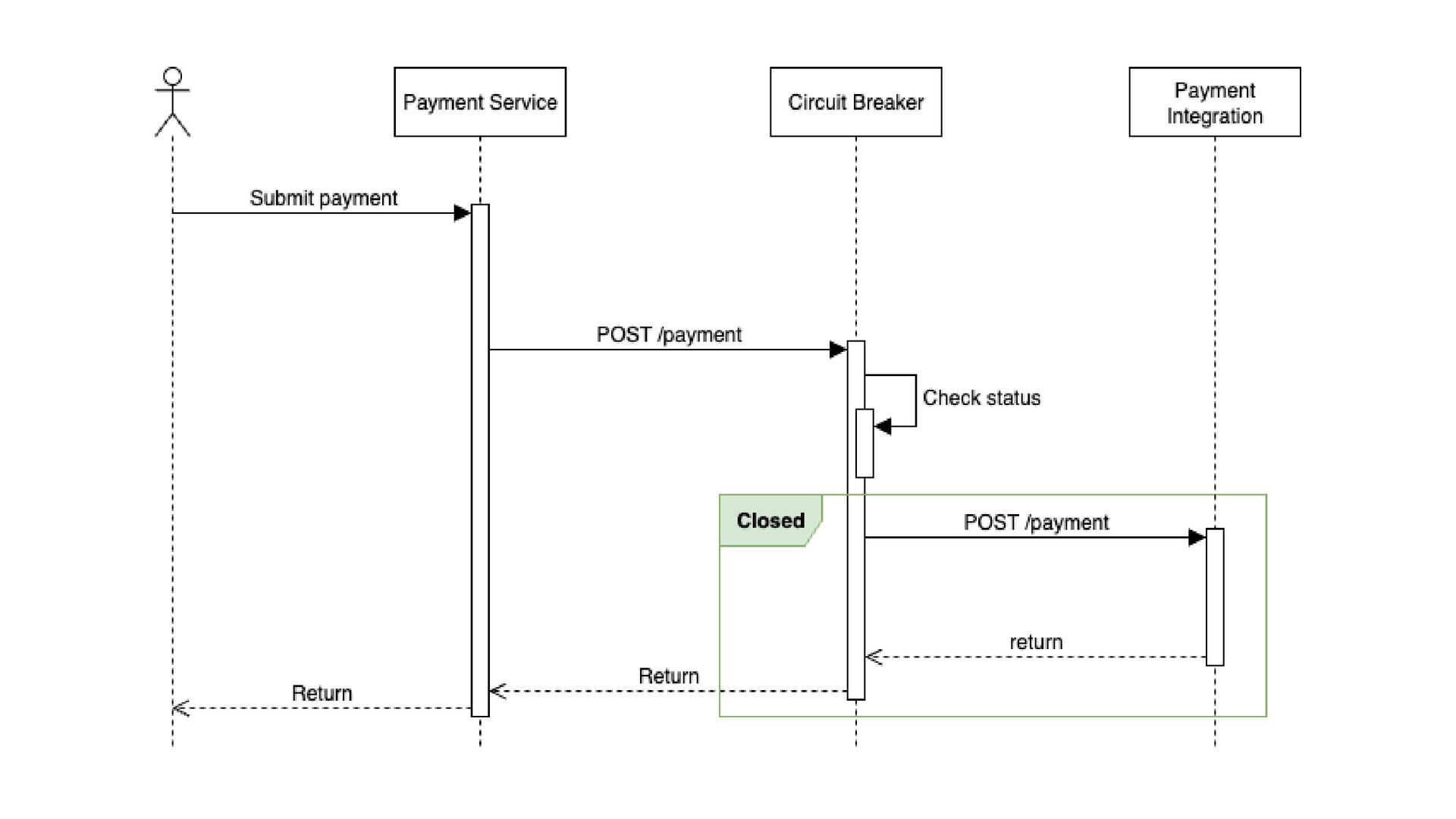
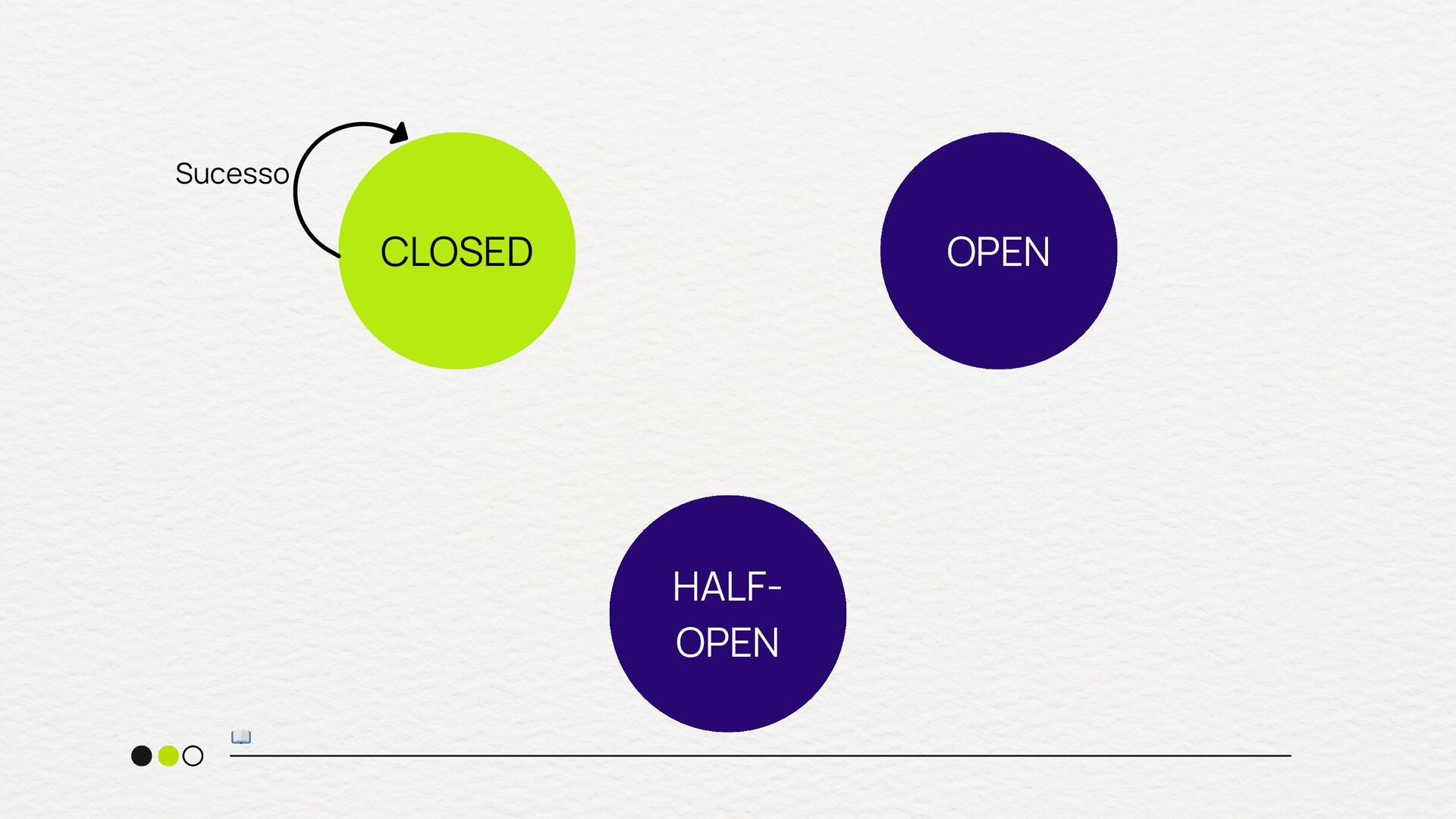
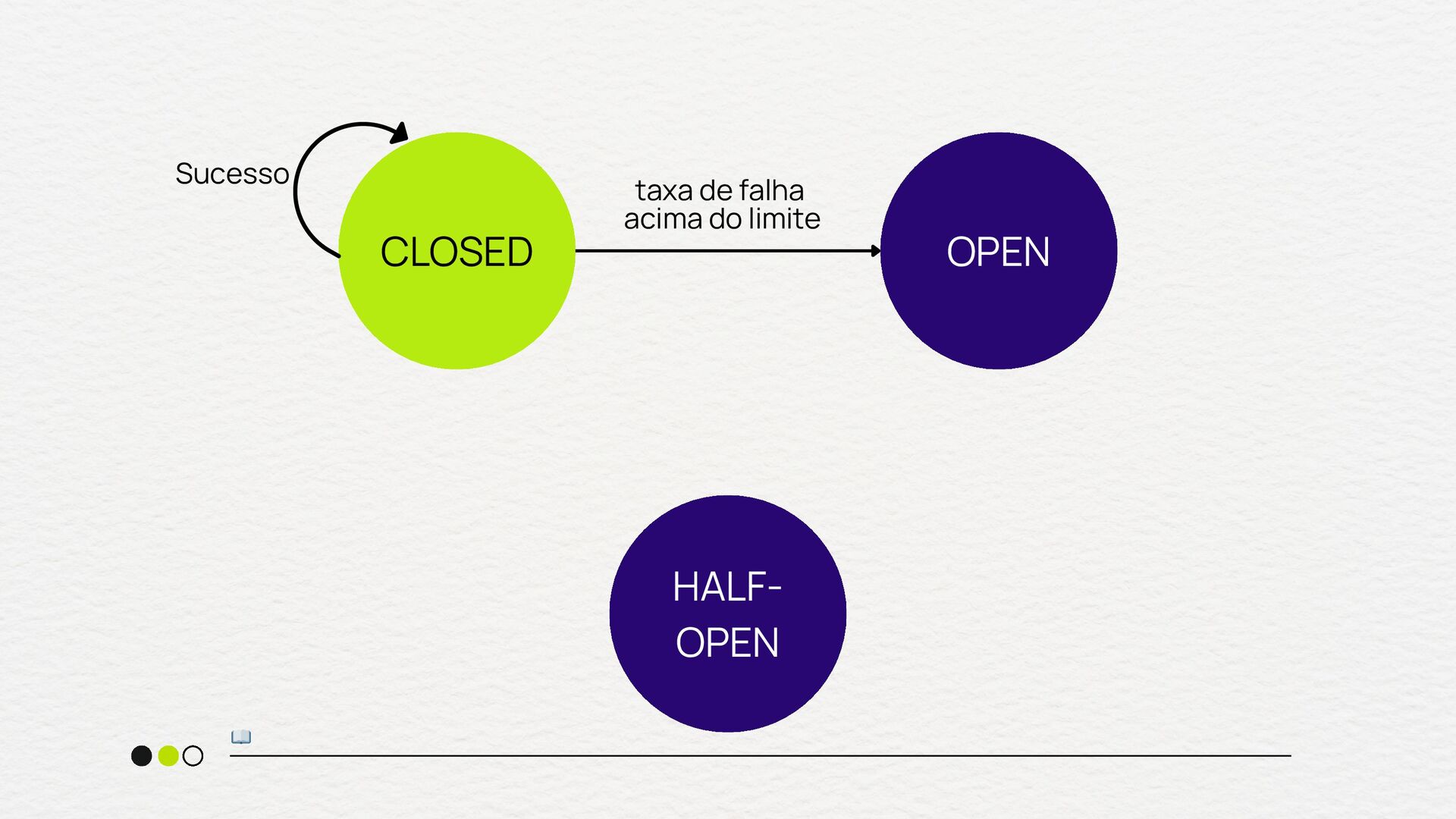
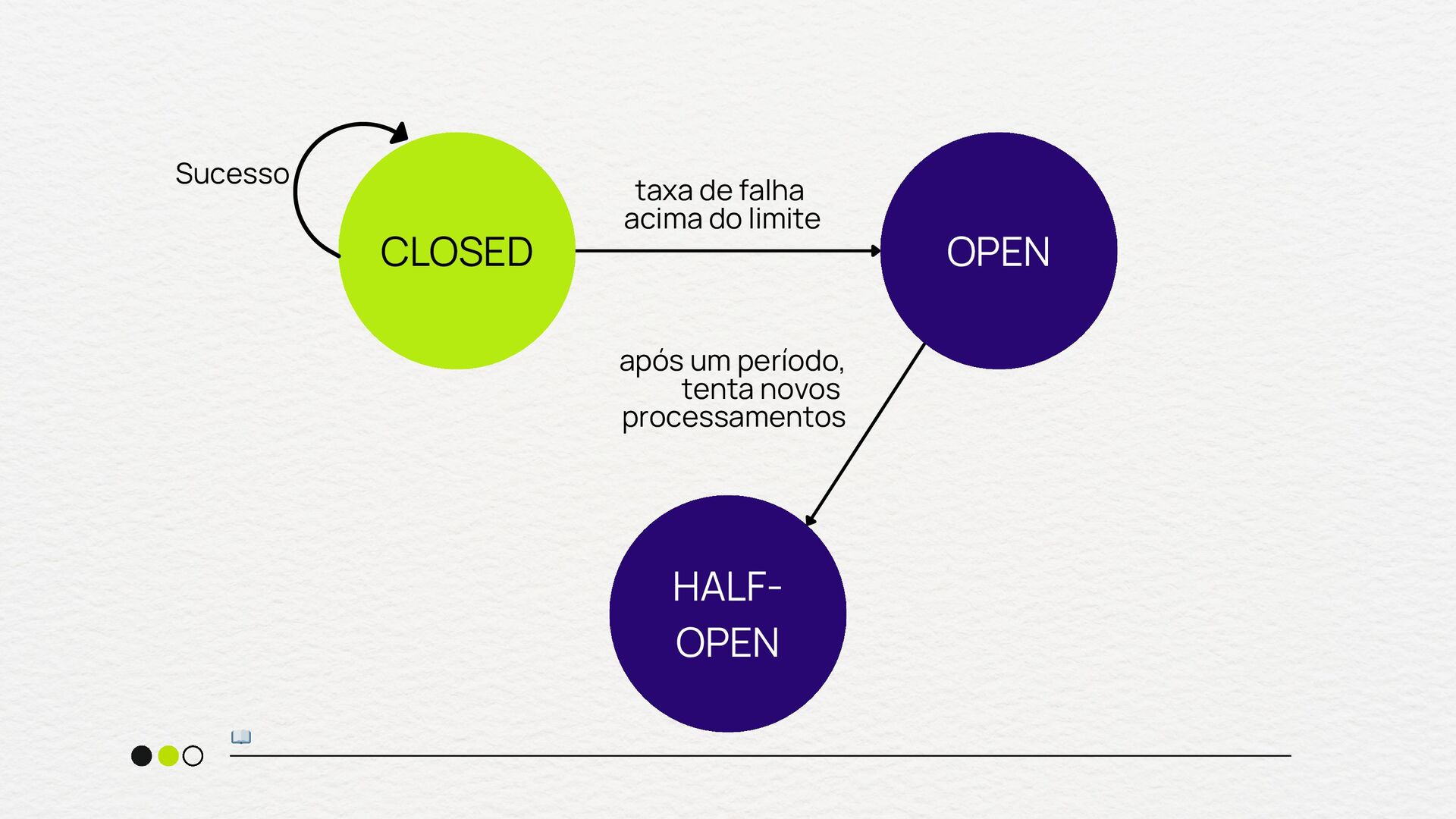
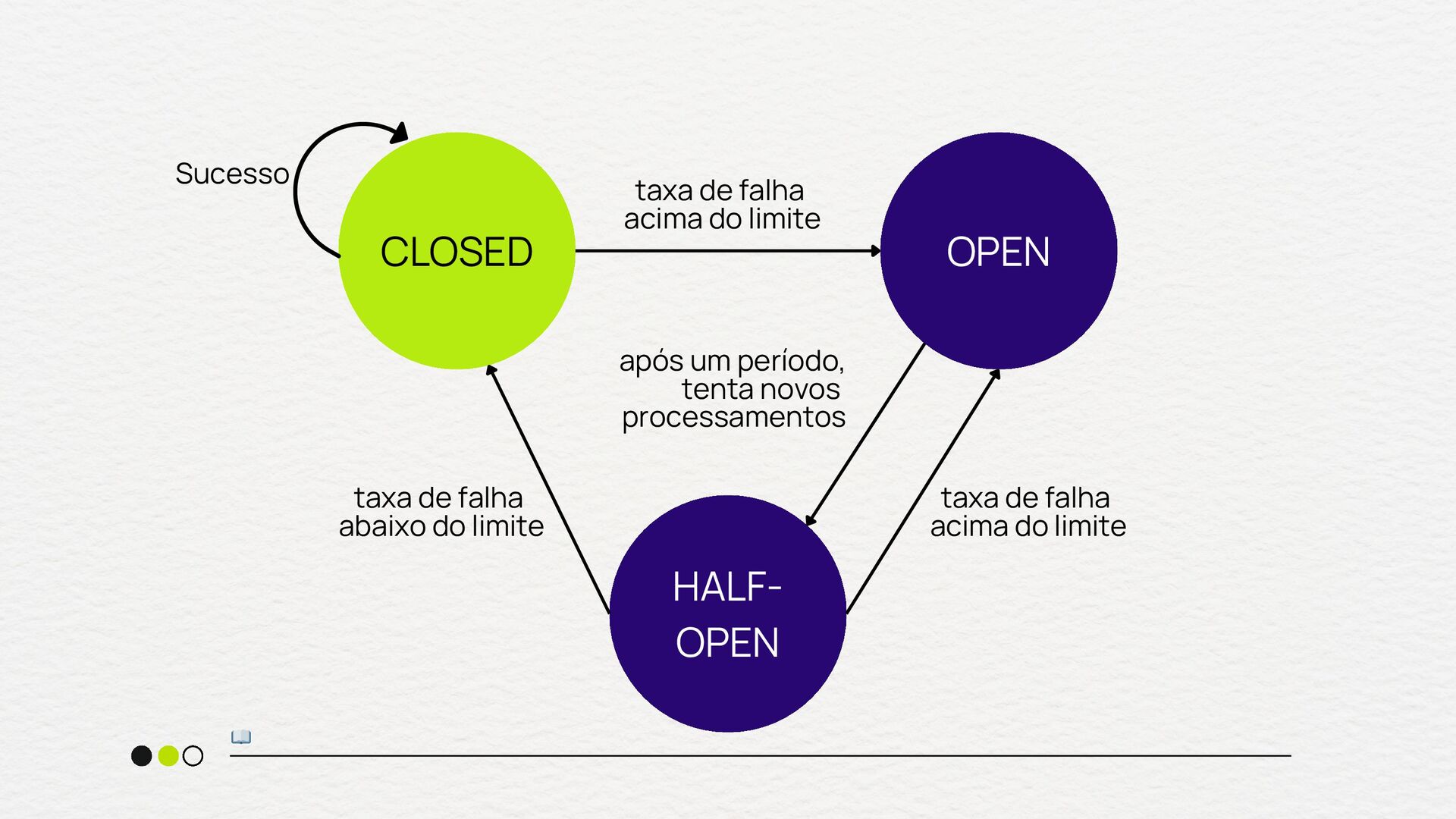
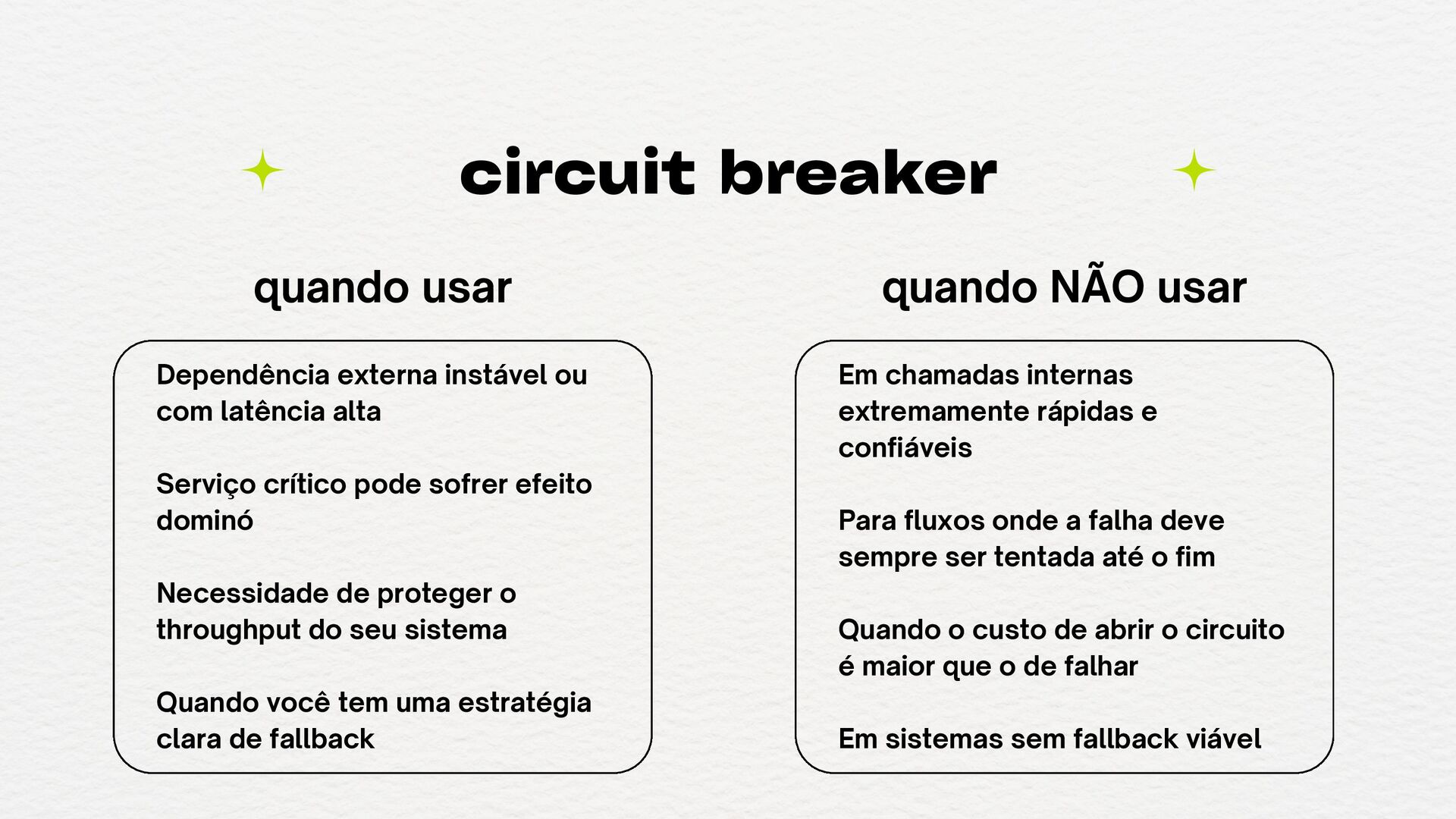
crítico pode sofrer efeito dominó Necessidade de proteger o throughput do seu sistema Quando você tem uma estratégia clara de fallback quando usar Em chamadas internas extremamente rápidas e confiáveis Para fluxos onde a falha deve sempre ser tentada até o fim Quando o custo de abrir o circuito é maior que o de falhar Em sistemas sem fallback viável quando NÃO usar
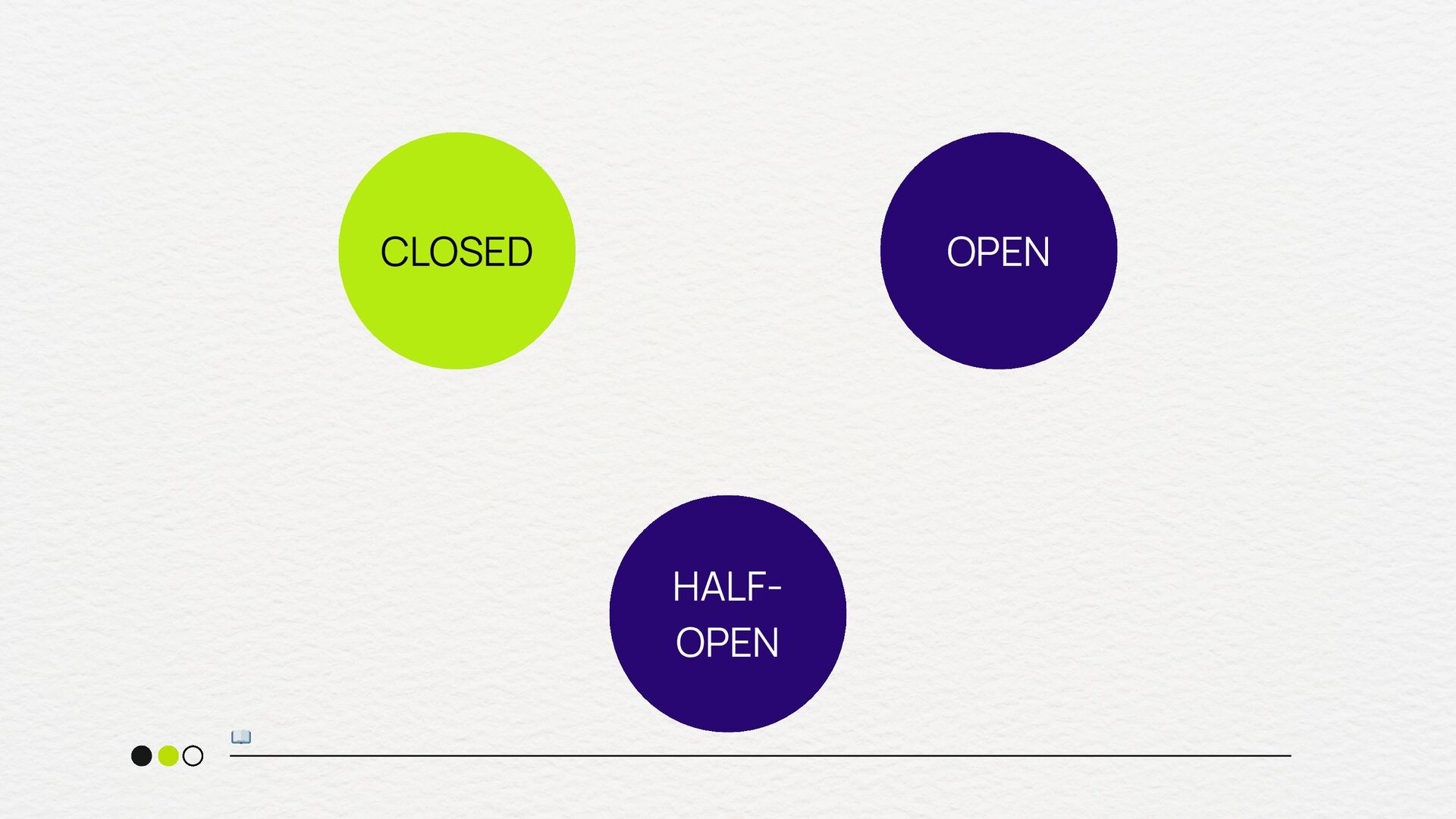
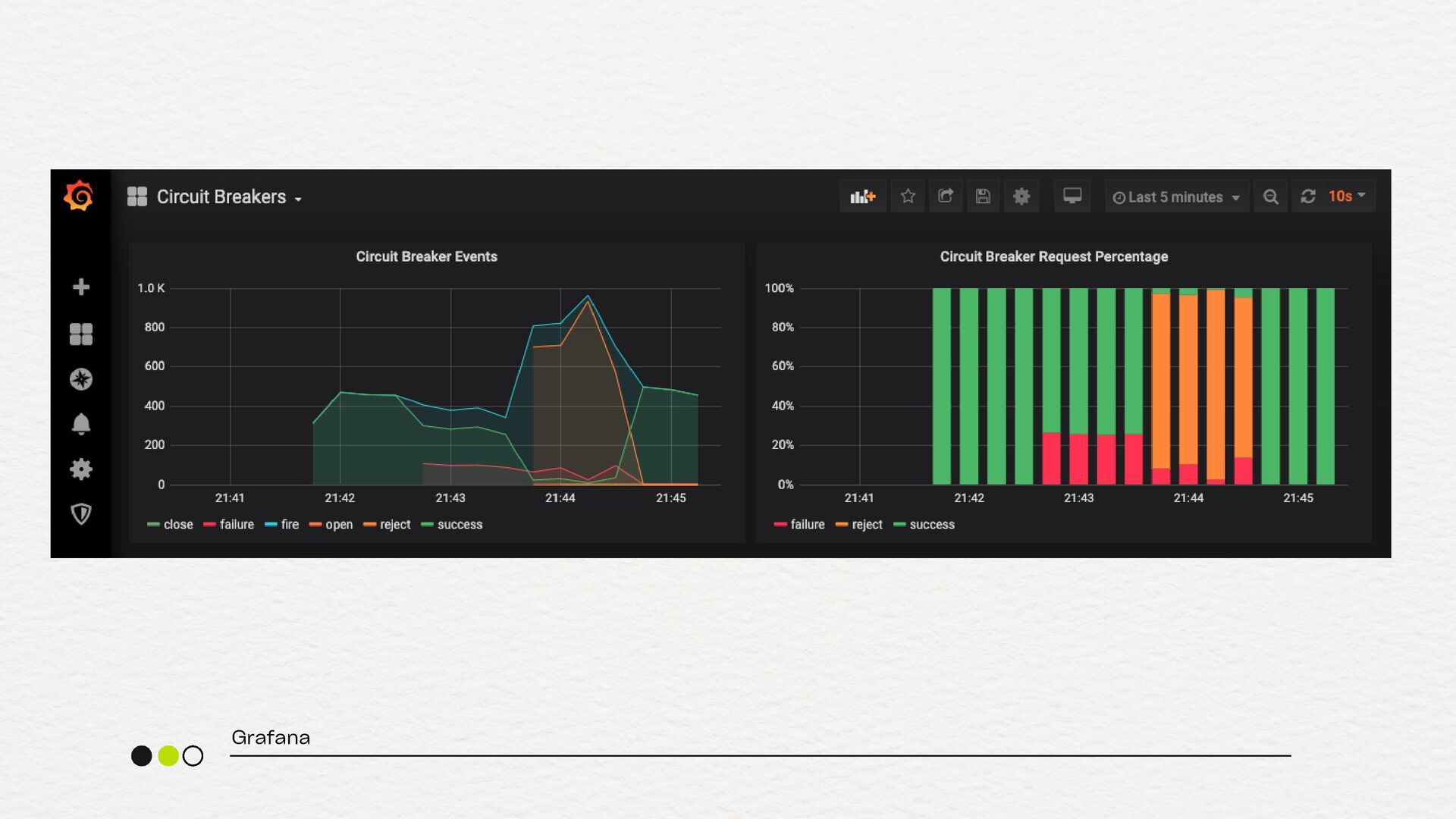
vezes que o circuito foi aberto) circuit.breaker.half_open.success.count (sucessos durante o estado half-open) circuit.breaker.half_open.failure.count (Falhas durante o estado half- open) metrificando
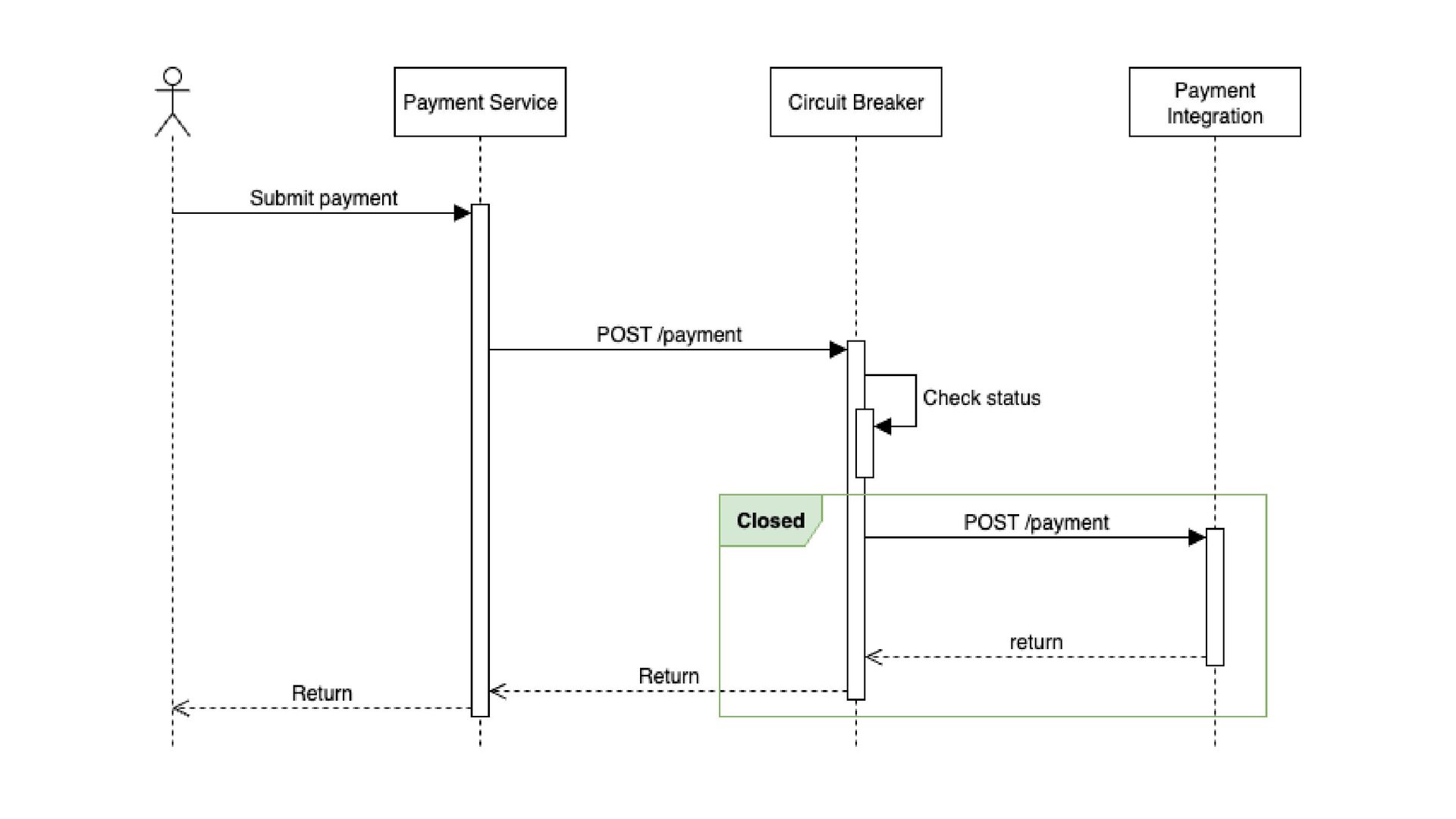
tempo de execução das requisições quando o circuito está fechado) circuit.breaker.fallback.count (número de vezes que o fallback foi acionado) error.rate (por dependência - % de falhas que disparam o Circuit Breaker) metrificando
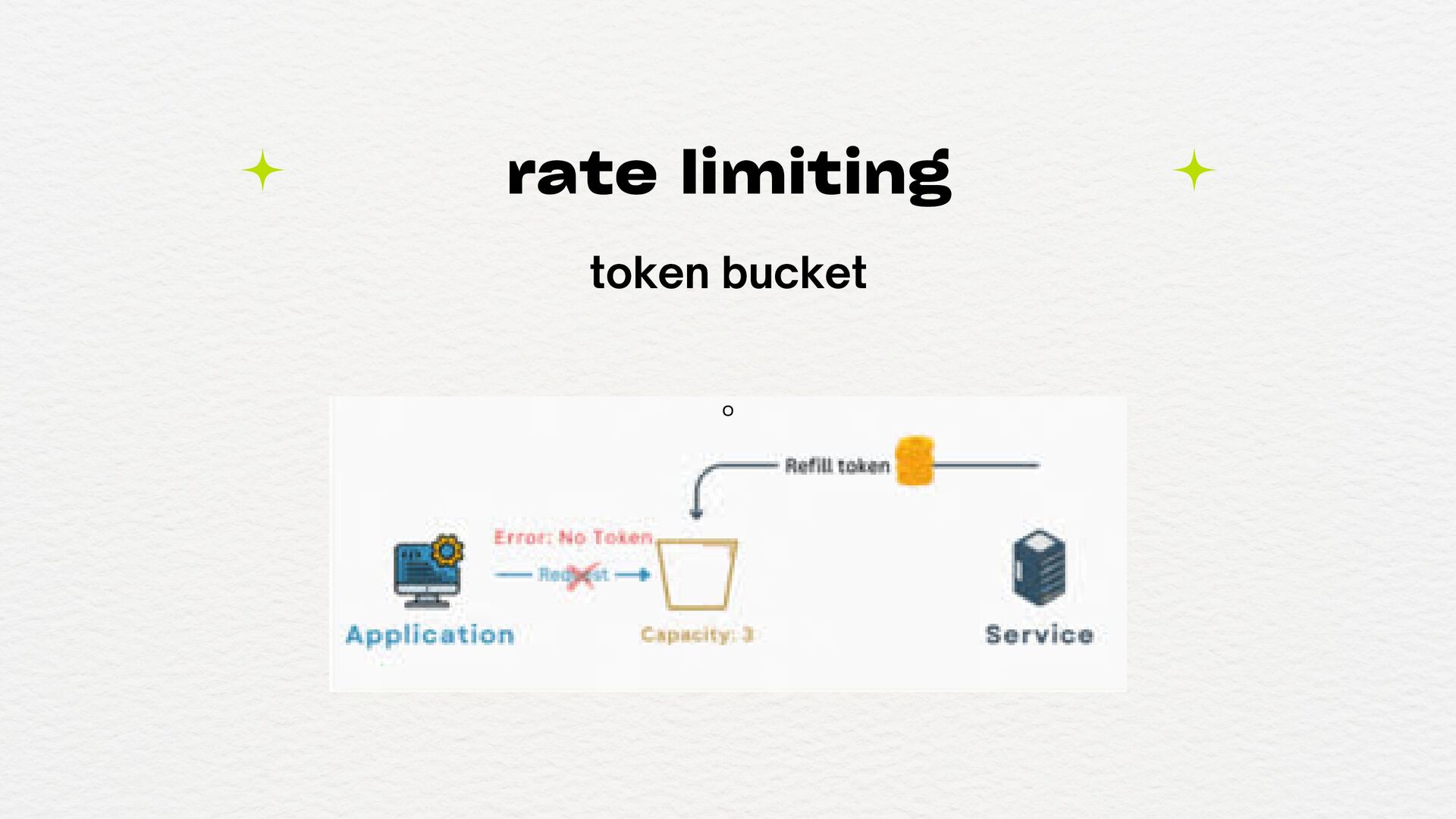
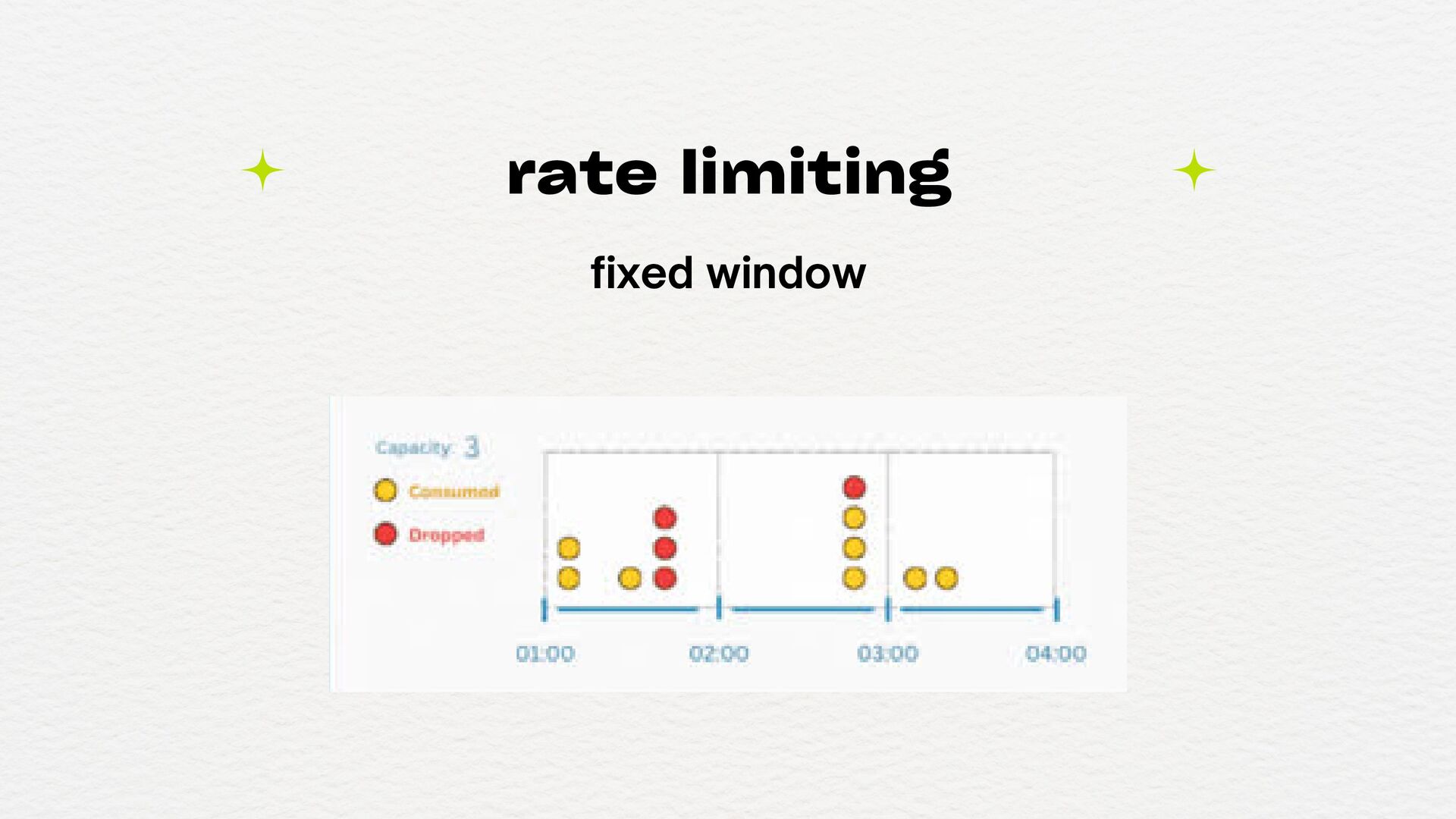
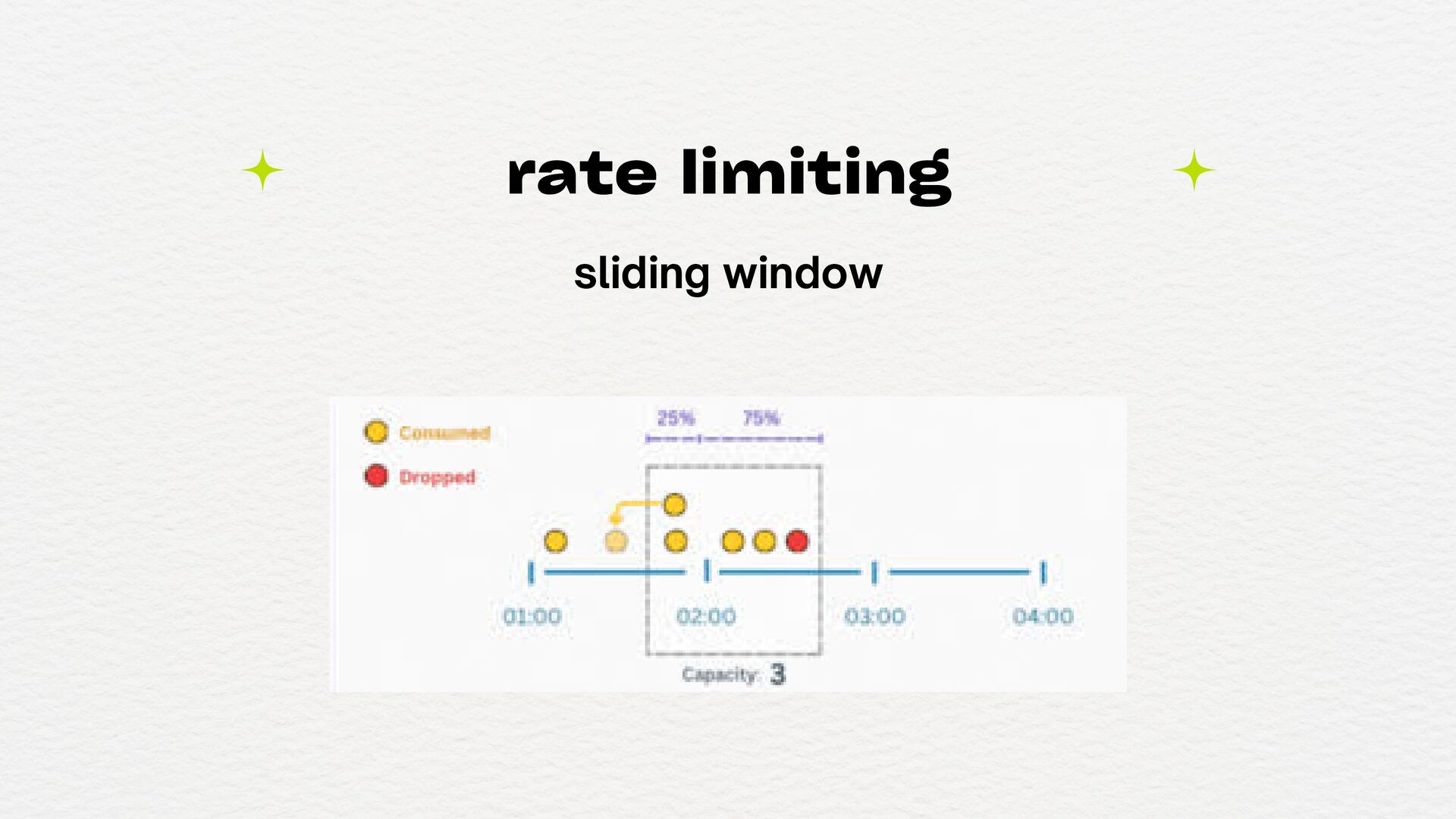
(DoS, loops, etc) Para proteger recursos sensíveis (como serviços de terceiros pagos por volume) Para aplicar fairness (por exemplo, não deixar um único cliente monopolizar sua API) Para proteger backend ou serviços internos que não foram feitos para aguentar tráfego massivo Para garantir limites de planos em APIs públicas (ex: usuários free vs. premium) quando usar
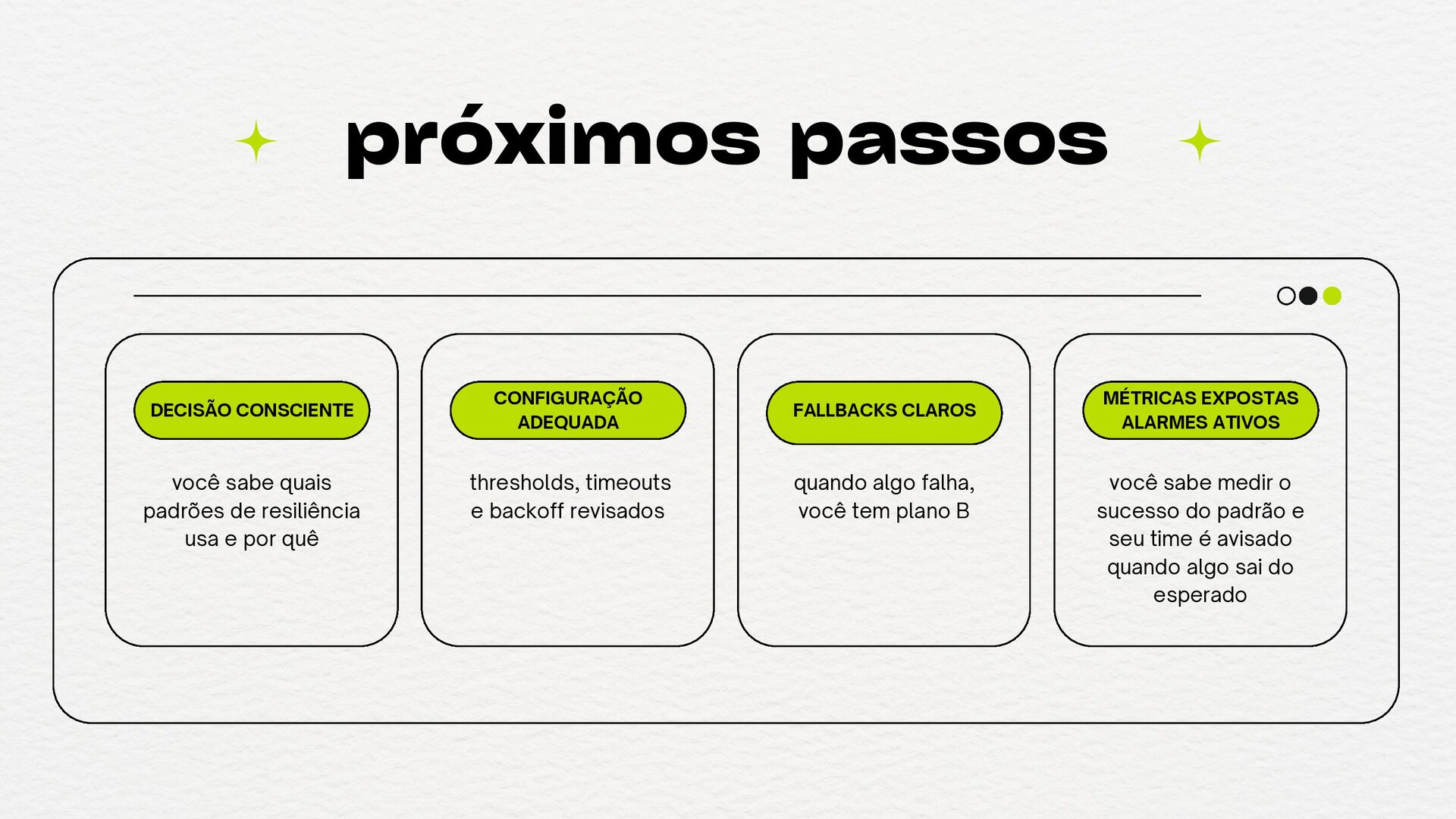
ALARMES ATIVOS você sabe quais padrões de resiliência usa e por quê thresholds, timeouts e backoff revisados quando algo falha, você tem plano B você sabe medir o sucesso do padrão e seu time é avisado quando algo sai do esperado
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}