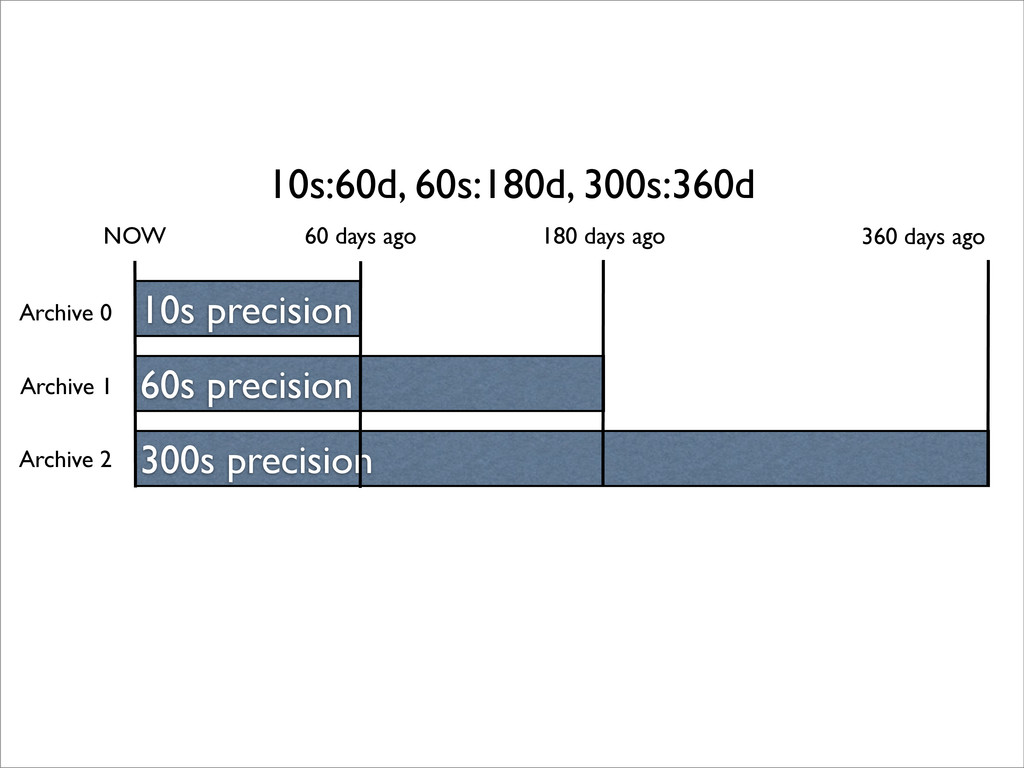
Round-robin • Fixed size • Newer points overwrite older ones • No concept of type: Everything’s a float (or None) • Can contain multiple “Archives” with different precisions
precision at display time for per-bucket rate • e.g. for minutely stats, use scale(<metric>, 60) Some tools store counts as per-second rates statsd, collectd (StoreRates true)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}