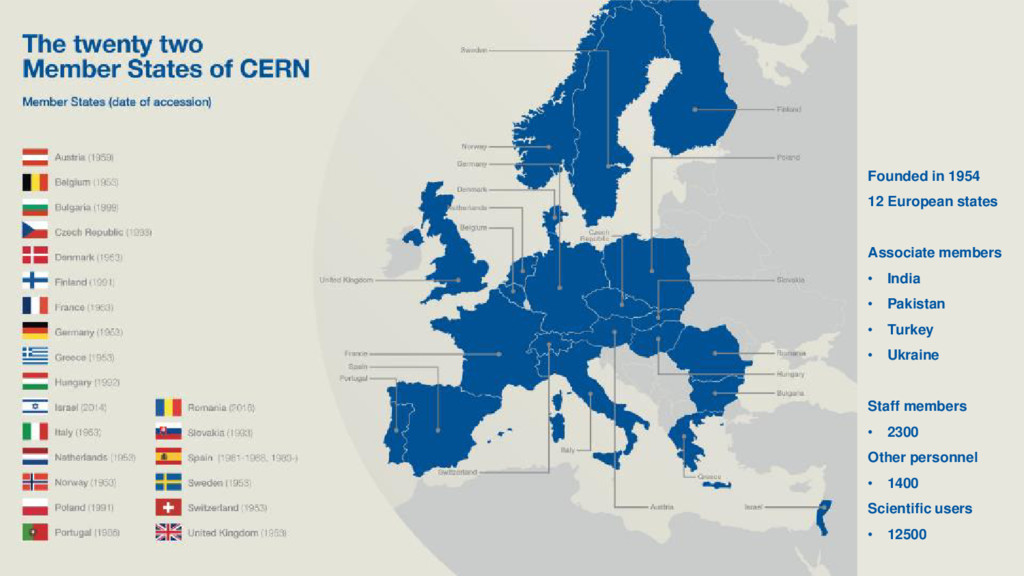
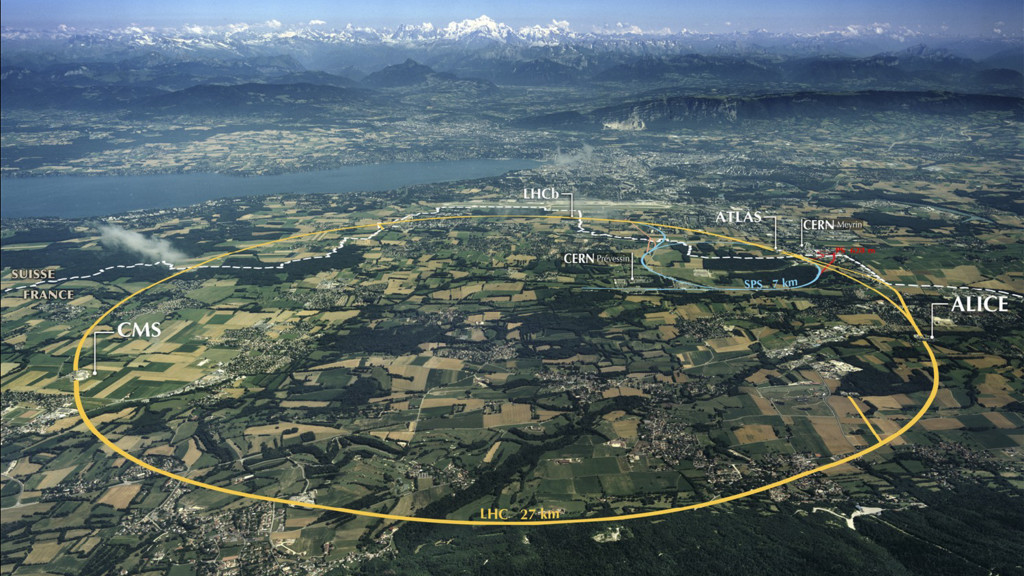
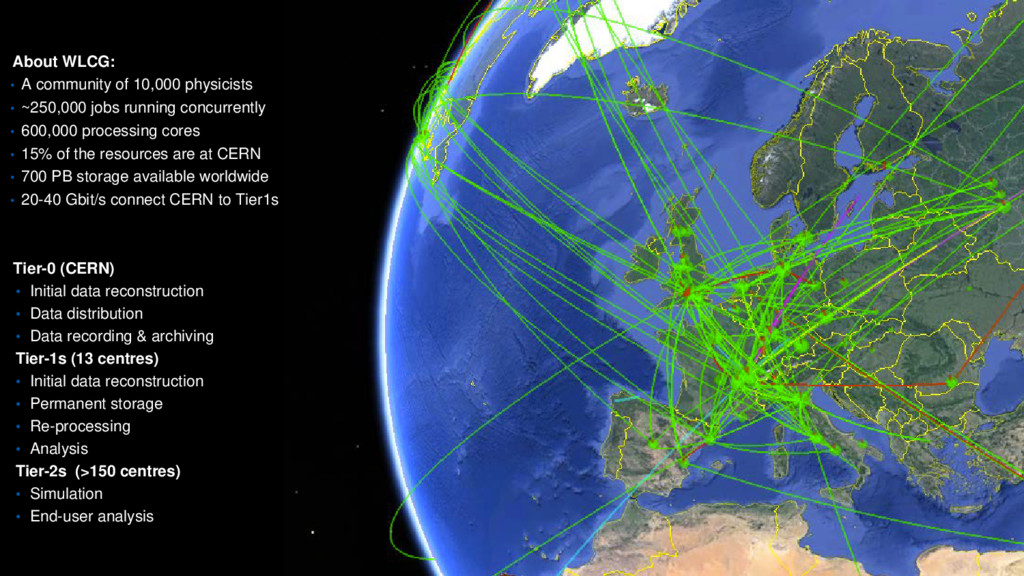
to store, distribute and analyse the LHC data • The CERN data centre (Tier-0) distributes LHC data to other WLCG sites (Tier-1, Tier-2, Tier-3) • Global collaboration of more than 170 data centres around the world from 42 countries Monitoring @ CERN 10 23 May 2017
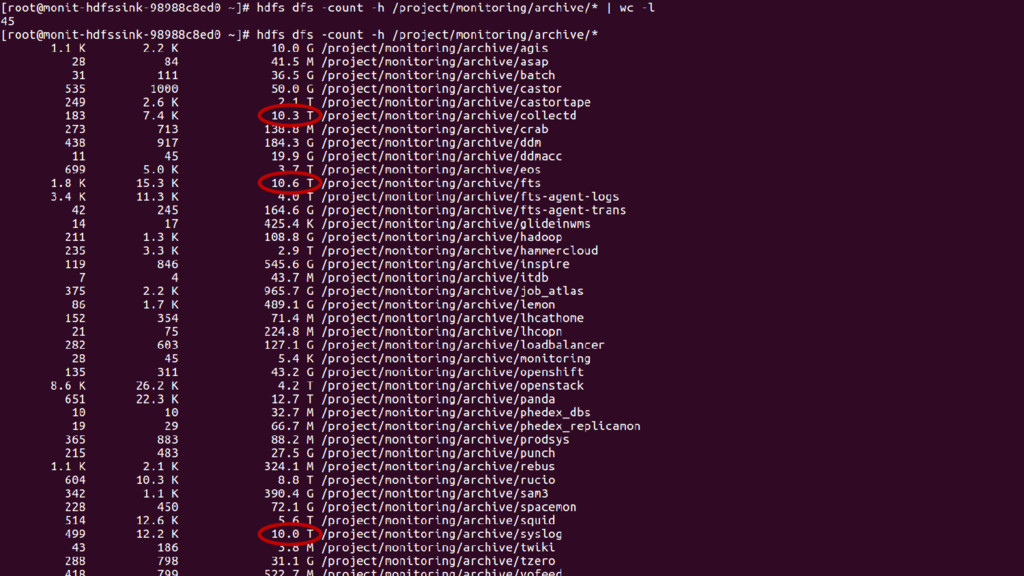
logs • Data centre HW and OS • Data centre services • WLCG site/services monitoring • WLCG job monitoring and data management • Spikey workload with an average of 500GB/day • When things go bad we have more data/users 23 May 2017 Monitoring @ CERN 13
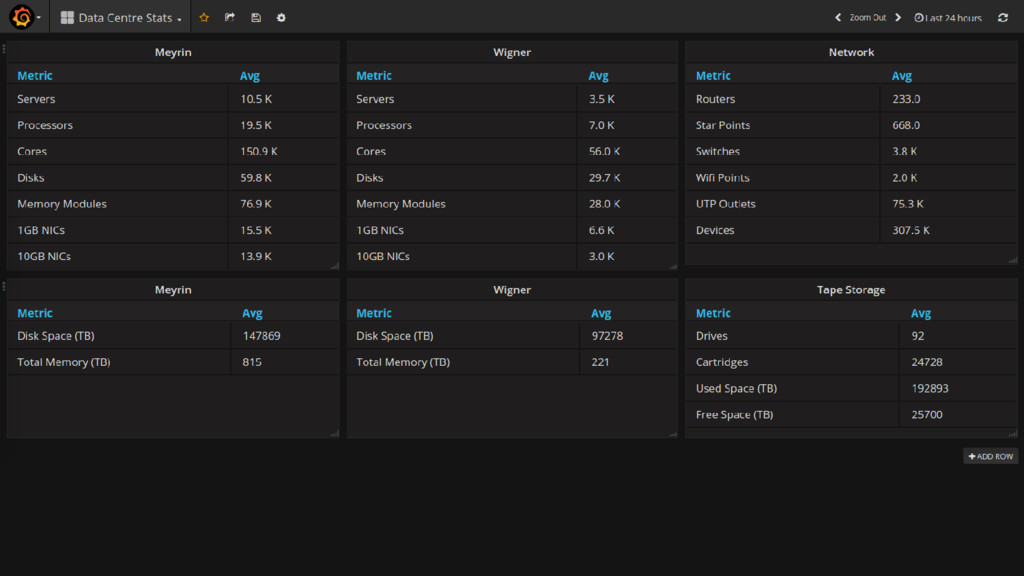
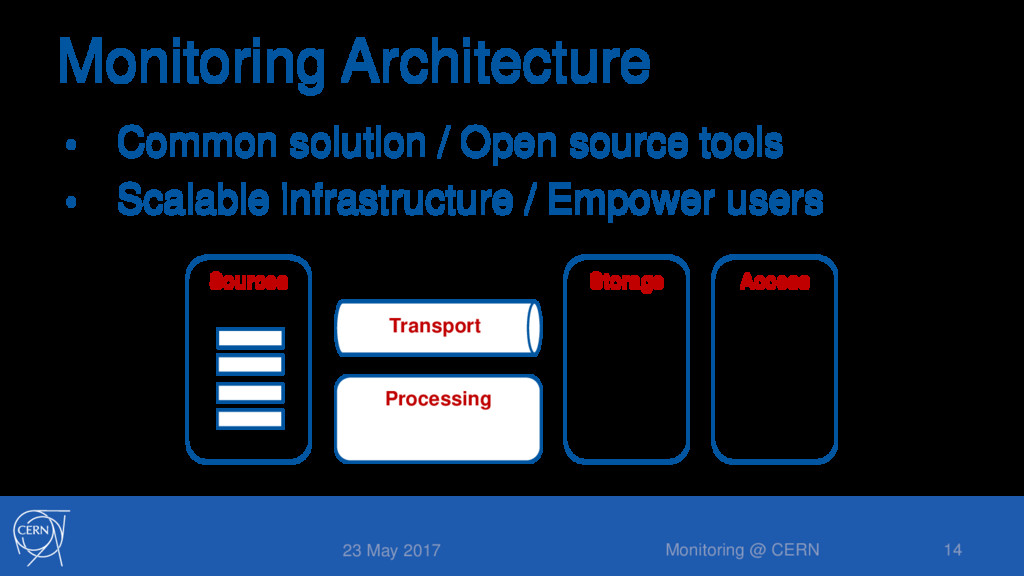
HW • Based on Collectd: 30k nodes, 1 min samples • External data sources • Data centre services and WLCG • A mix between push and pull models • Different technologies and protocols 23 May 2017 Monitoring @ CERN 15
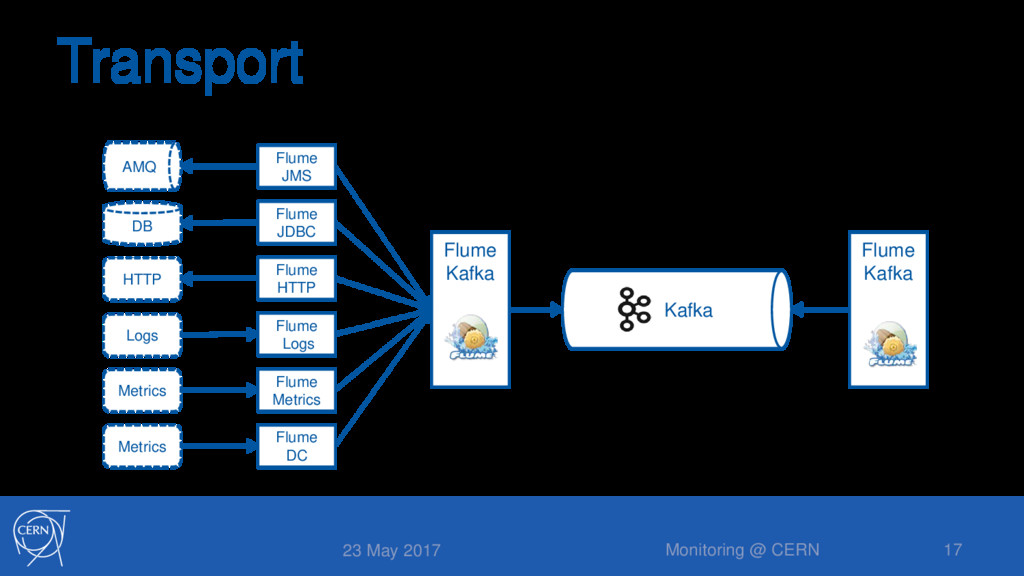
JMS/AVRO, AVRO/KAFKA, KAFKA/ESSINK • File based channels (small capacity) • Several interceptors and morhphlines • For validation and transformation • Check mandatory fields, apply common schema 23 May 2017 Monitoring @ CERN 18
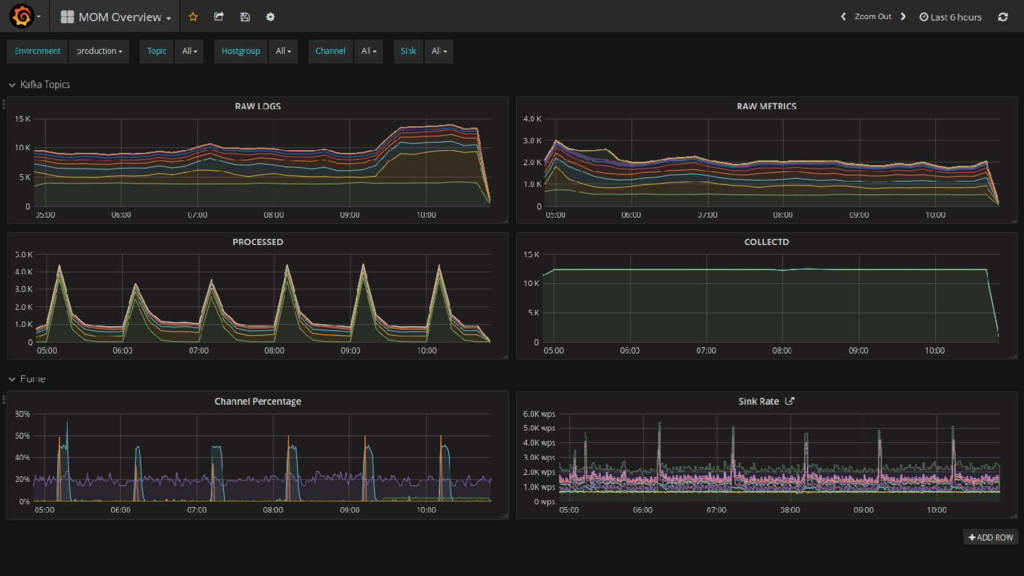
• Data buffered for 12h (target is 72h) • Each data source in a separate topic • Each topic divided in 20 partitions • Two replicas per partition 23 May 2017 Monitoring @ CERN 19
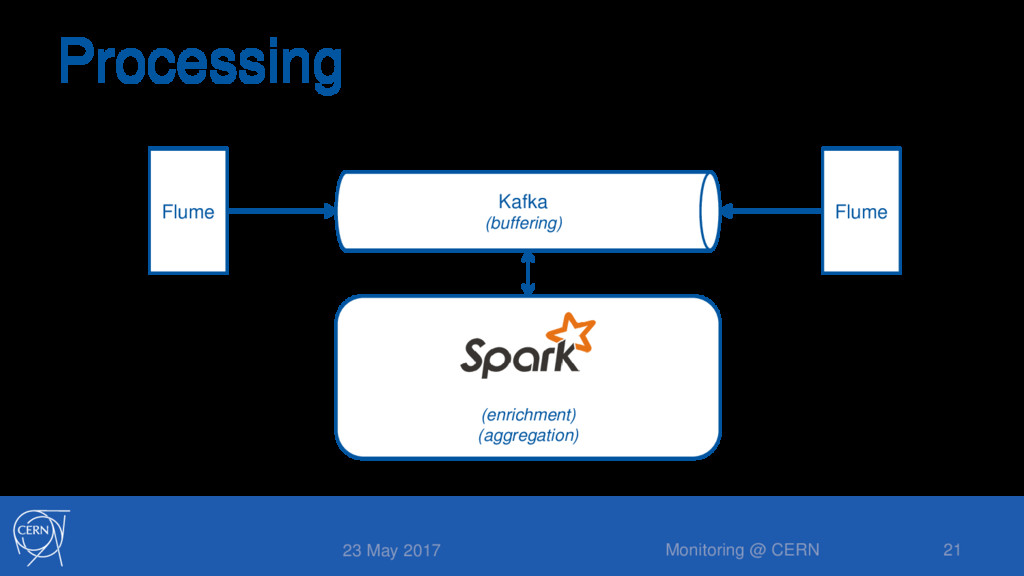
topology metadata • Aggregation jobs: mostly over time • Correlation jobs: cpu load vs service activity • Batch processing jobs (scala) • Compaction and reprocessing jobs • Monthly or yearly reports for management 23 May 2017 Monitoring @ CERN 22
Automatic process at every push with Gitlab CI • Jobs orchestrated as processes on Mesos • Marathon for long-living processes (e.g. streaming) • Chronos for recurrent execution (e.g. batch) • Jobs executed in Mesos or Yarn clusters 23 May 2017 Monitoring @ CERN 23
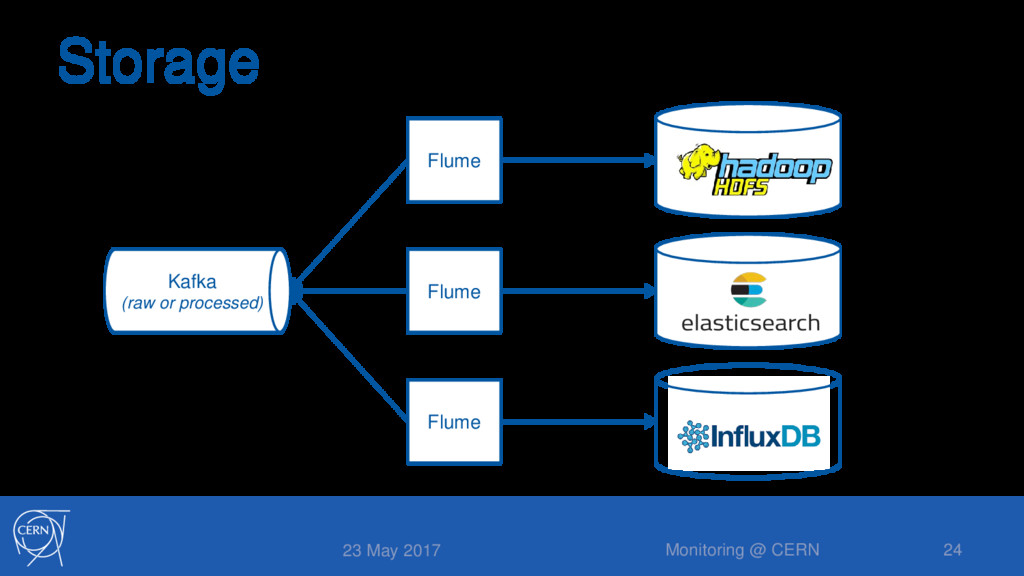
Data kept forever (limited to resources) • ES for searches and data discovery • Data kept for 1 month • InfluxDB for plots and dashboards • Data kept for 7 days • 5m bins kept for 1M, 1h bins kept for 5Y 23 May 2017 Monitoring @ CERN 25
/project/monitoring/archive/fts/metrics/2017/05/22/ • Data aggregated once per day into ~1Gb files • Selected data sets stored in ES and/or InfluxDB • ES: two generic instances (metrics and logs) • ES: each data producer in a separate index • InfluxDB: one instance per data producer 23 May 2017 Monitoring @ CERN 26
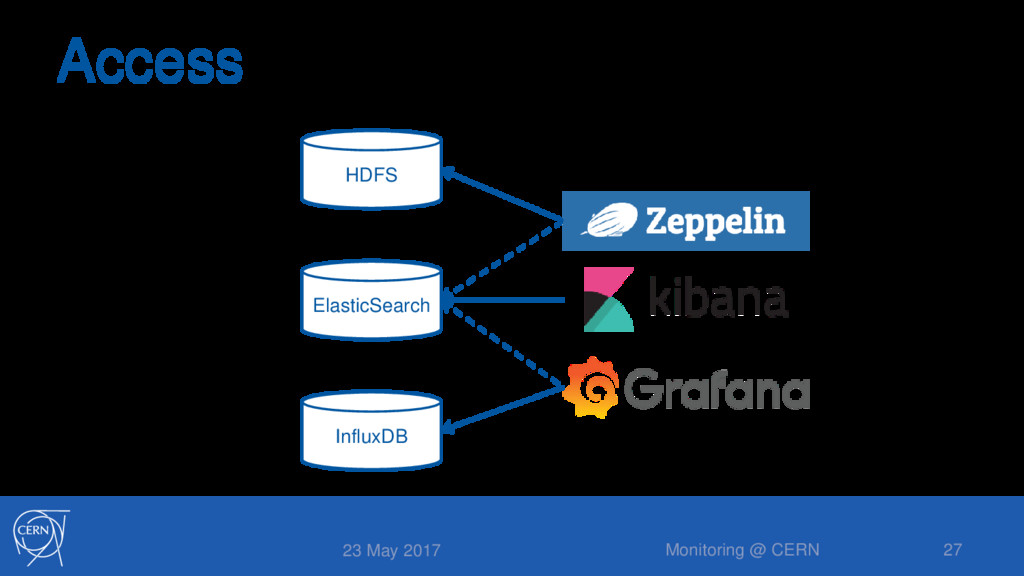
with >5 years • Local alarms from metrics thresholds • Moving towards a multiple scope strategy • Local alarms from Collectd, to enable local actuators • Base alarms from Grafana, easy integration • Advanced alarms from Spark Jobs (user specific) 23 May 2017 Monitoring @ CERN 31
10 Spark, 50 Elasticsearch • Some nodes with Ceph volumes attached • Physical nodes • Only used for InfluxDB and HDFS • All configuration done via Puppet 23 May 2017 Monitoring @ CERN 32
very easy to add new sources • Kafka is the core of the “business” • Careful resources planning (topic/partition split) • Control consumer group and offsets is key • Securing the infrastructure takes time 23 May 2017 Monitoring @ CERN 33
• Keep batch and streaming code as close as possible • DataFrame to decouple from JSON (un)marshalling • Store checkpoints on HDFS • Very positive experience with Marathon • InfluxDB and Elasticsearch • Tried to make them as complementary as possible 23 May 2017 Monitoring @ CERN 34
{kind=link}
![Monitoring @ CERN [email protected]](https://files.speakerdeck.com/presentations/af11c064decf4ed5ab7405e72a33cbad/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}