Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Boston 2013 - Session - Laura Thomson
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Monitorama
March 28, 2013
400
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Boston 2013 - Session - Laura Thomson
Monitorama
March 28, 2013
More Decks by Monitorama
See All by Monitorama
Monitorama PDX 2017 - Ian Bennett
monitorama
1
630
PDX 2017 - Pedro Andrade
monitorama
0
830
PDX 2017 - Roy Rapoport
monitorama
4
990
PDX 2017 - Julia Evans
monitorama
0
520
Berlin 2013 - Session - Brad Lhotsky
monitorama
5
770
Berlin 2013 - Session - Alex Petrov
monitorama
6
730
Berlin 2013 - Session - Jeff Weinstein
monitorama
2
670
Berlin 2013 - Session - Oliver Hankeln
monitorama
1
590
Berlin 2013 - Session - David Goodlad
monitorama
0
510
Featured
See All Featured
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
300
Faster Mobile Websites
deanohume
310
31k
Unsuck your backbone
ammeep
672
58k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
180
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
Rails Girls Zürich Keynote
gr2m
96
14k
エンジニアに許された特別な時間の終わり
watany
107
250k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.6k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Optimizing for Happiness
mojombo
378
71k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
170
Navigating Weather and Climate Data
rabernat
0
220
Transcript
Many Moving Parts Monitoring Complex Systems
[email protected]
1 Wednesday, May
29, 13
Many Moving Parts Monitoring Complex Systems (at roflscale) 2 Wednesday,
May 29, 13
Confession: I’m not a sysadmin. 3 Wednesday, May 29, 13
(Why does devops == ops, anyway?) 4 Wednesday, May 29,
13
5 Wednesday, May 29, 13
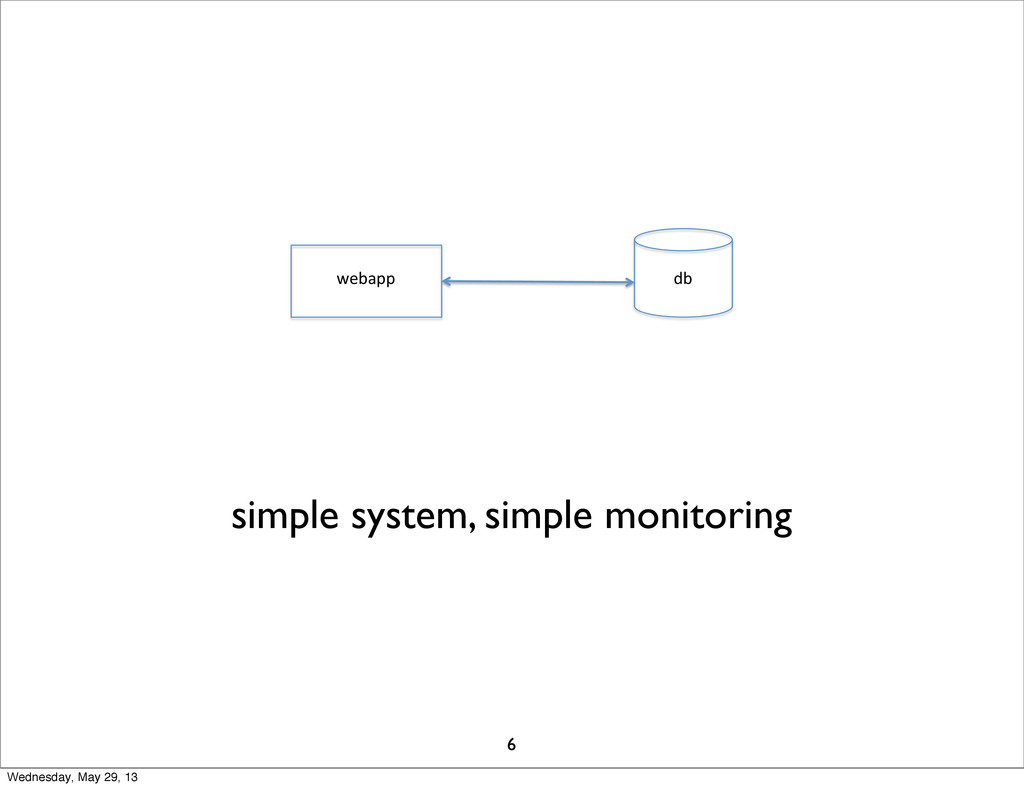
webapp& db& simple system, simple monitoring 6 Wednesday, May 29,
13
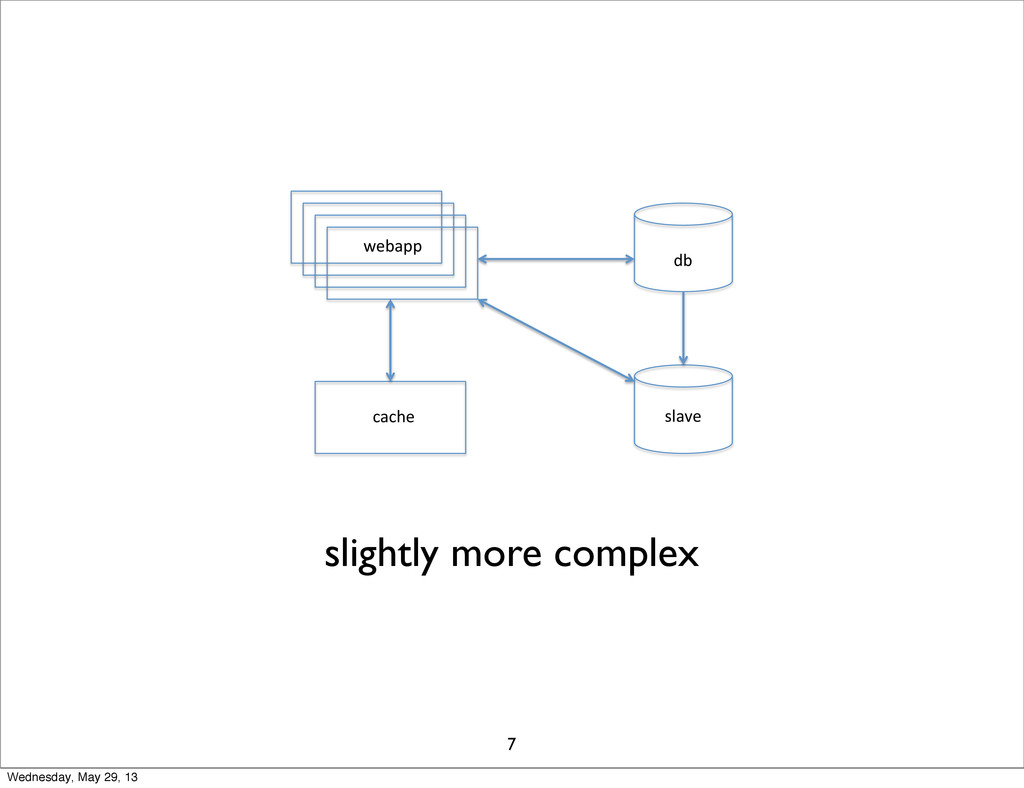
webapp& db& cache& slave& slightly more complex 7 Wednesday, May
29, 13
Most of us don’t work on simple stuff 8 Wednesday,
May 29, 13
Most of us don’t work on simple stuff ...and if
you do I hate you. 9 Wednesday, May 29, 13
Most of us don’t work on simple stuff ...and if
you do I hate you. (just kidding) 10 Wednesday, May 29, 13
Some of our stuff looks like this 11 Wednesday, May
29, 13
Some of our stuff looks like this (avert your eyes
now if you are easily scared) 12 Wednesday, May 29, 13
13 Wednesday, May 29, 13
It’s actually more complicated than that 14 Wednesday, May 29,
13
Socorro Very Large Array at Socorro, New Mexico, USA. Photo
taken by Hajor, 08.Aug.2004. Released under cc.by.sa and/or GFDL. Source: http://en.wikipedia.org/wiki/File:USA.NM.VeryLargeArray.02.jpg 15 Wednesday, May 29, 13
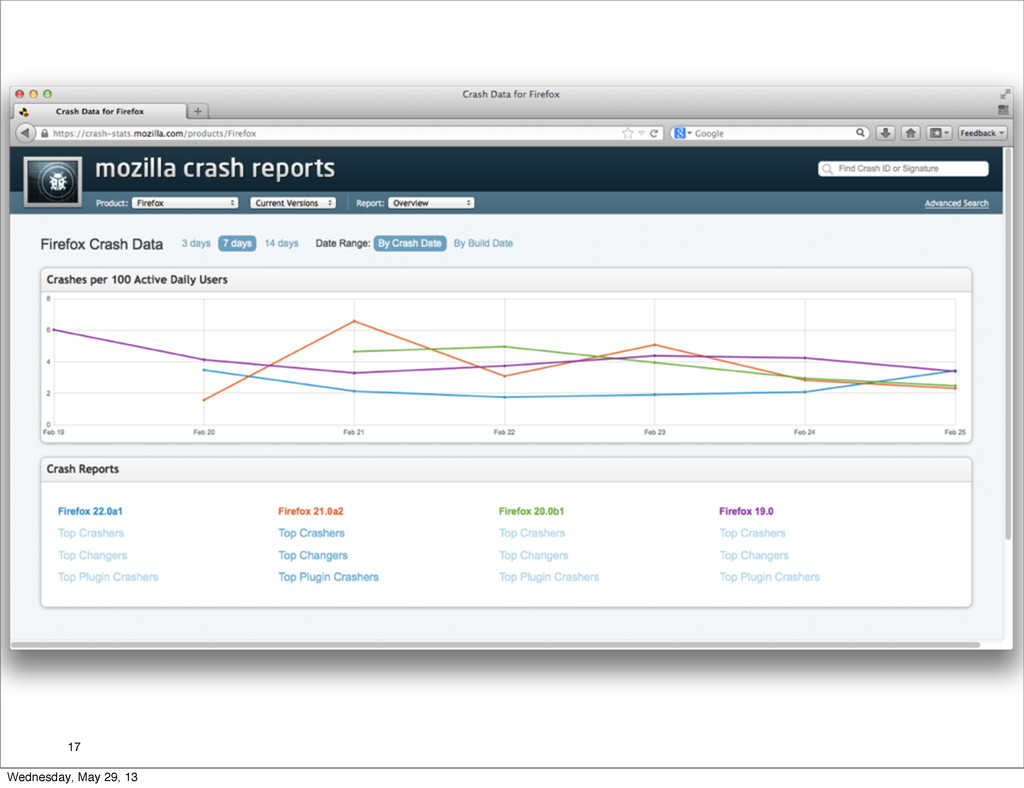
16 Wednesday, May 29, 13
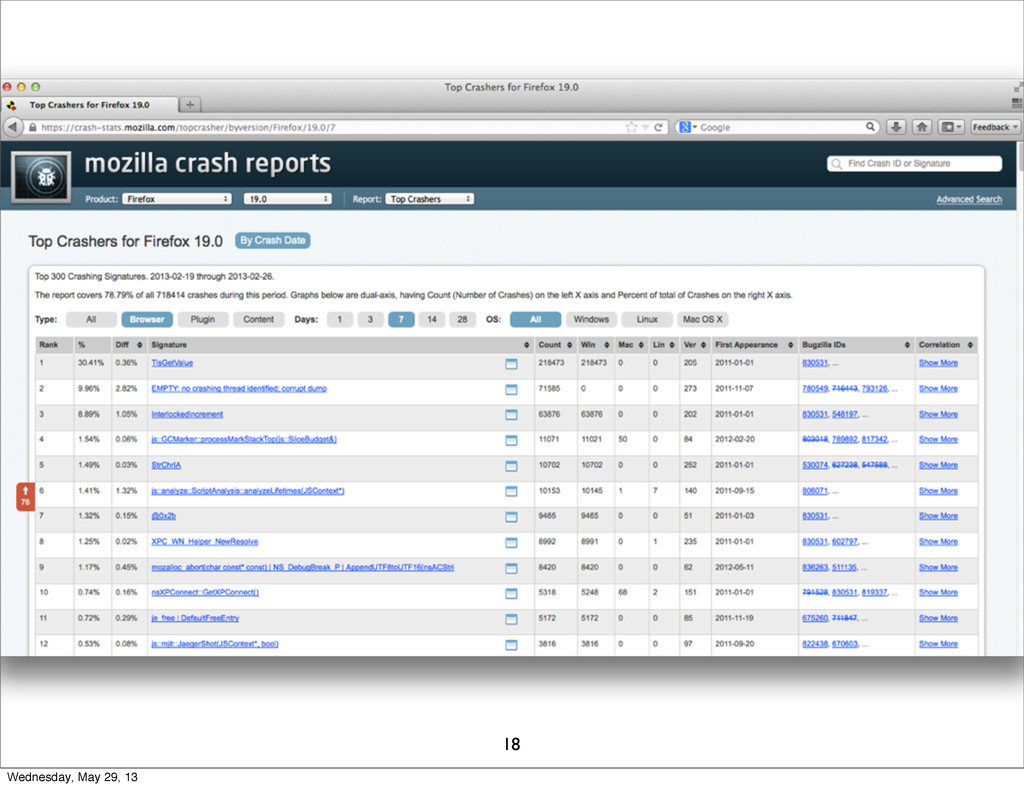
17 Wednesday, May 29, 13
18 Wednesday, May 29, 13
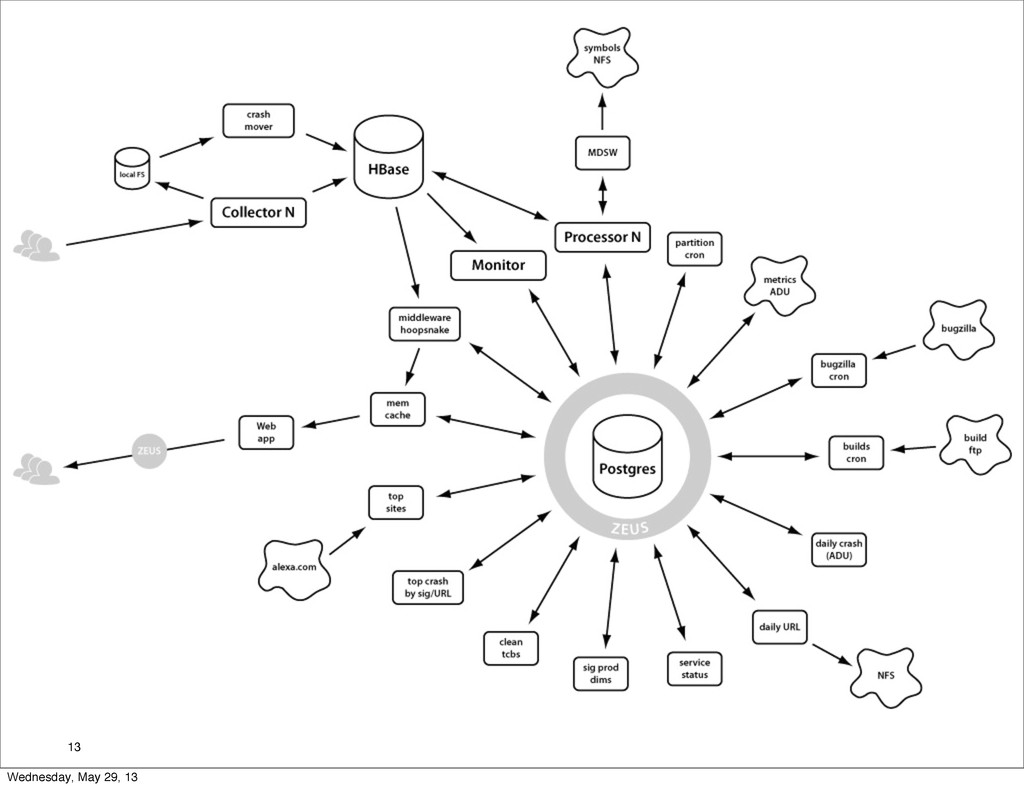
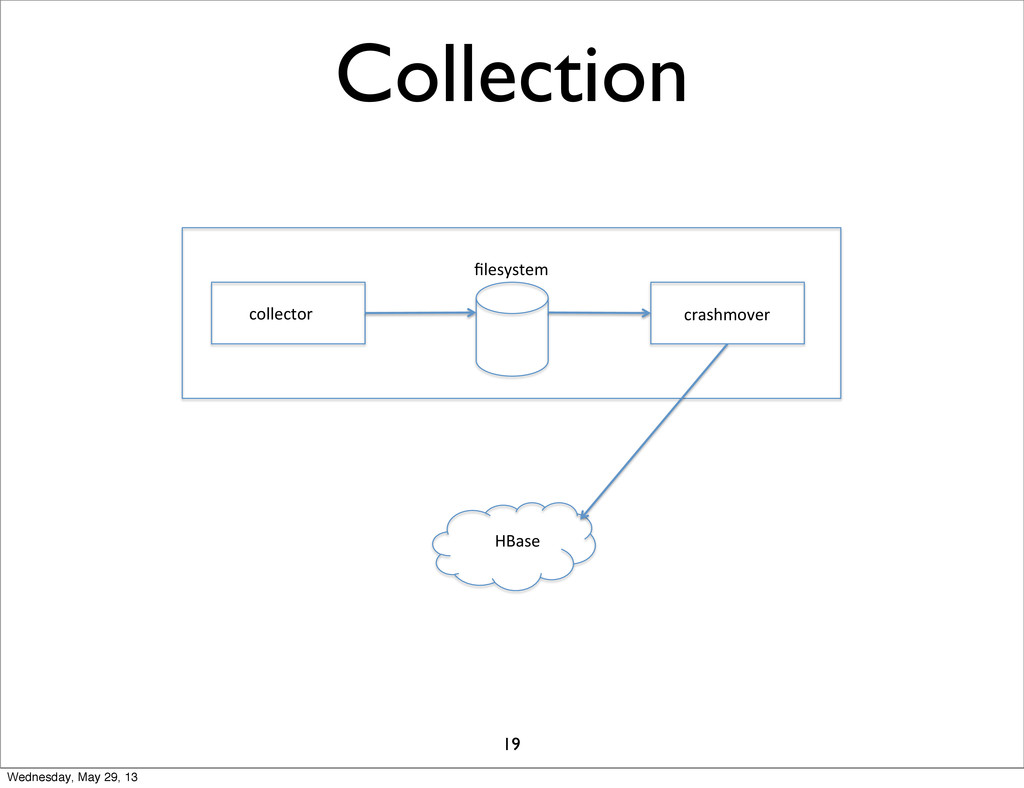
Collection collector' crashmover' filesystem' HBase' 19 Wednesday, May 29, 13
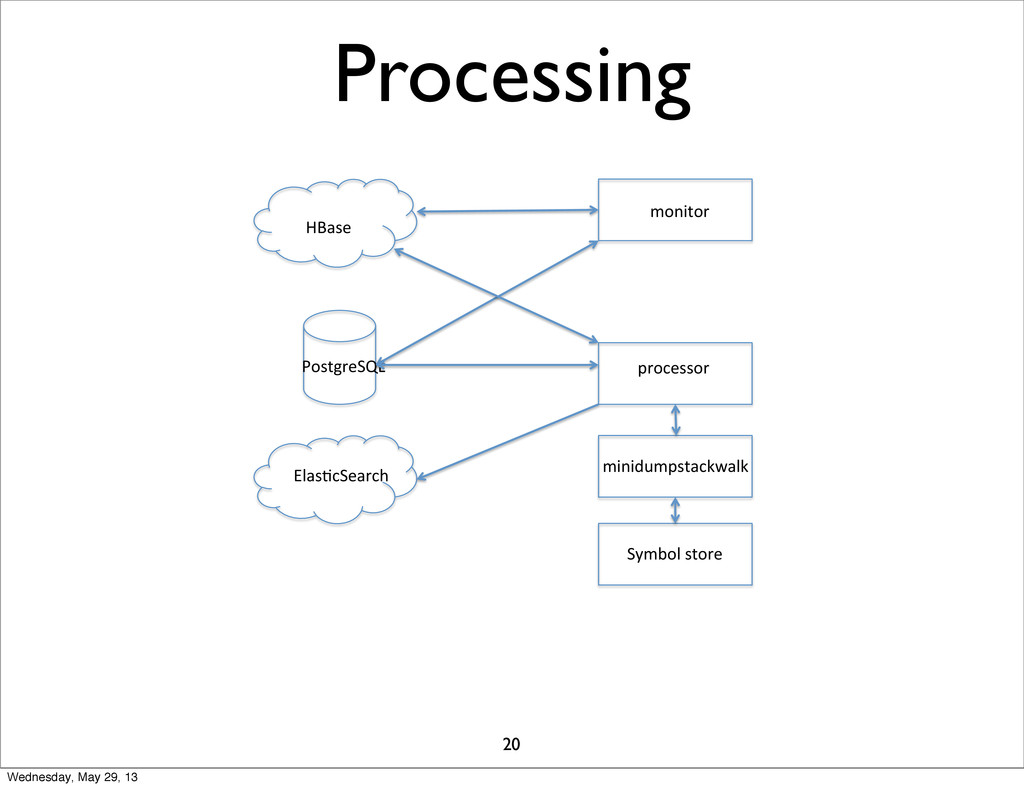
Processing HBase& PostgreSQL& Elas1cSearch& monitor& processor& Symbol&store& minidumpstackwalk& 20 Wednesday,
May 29, 13
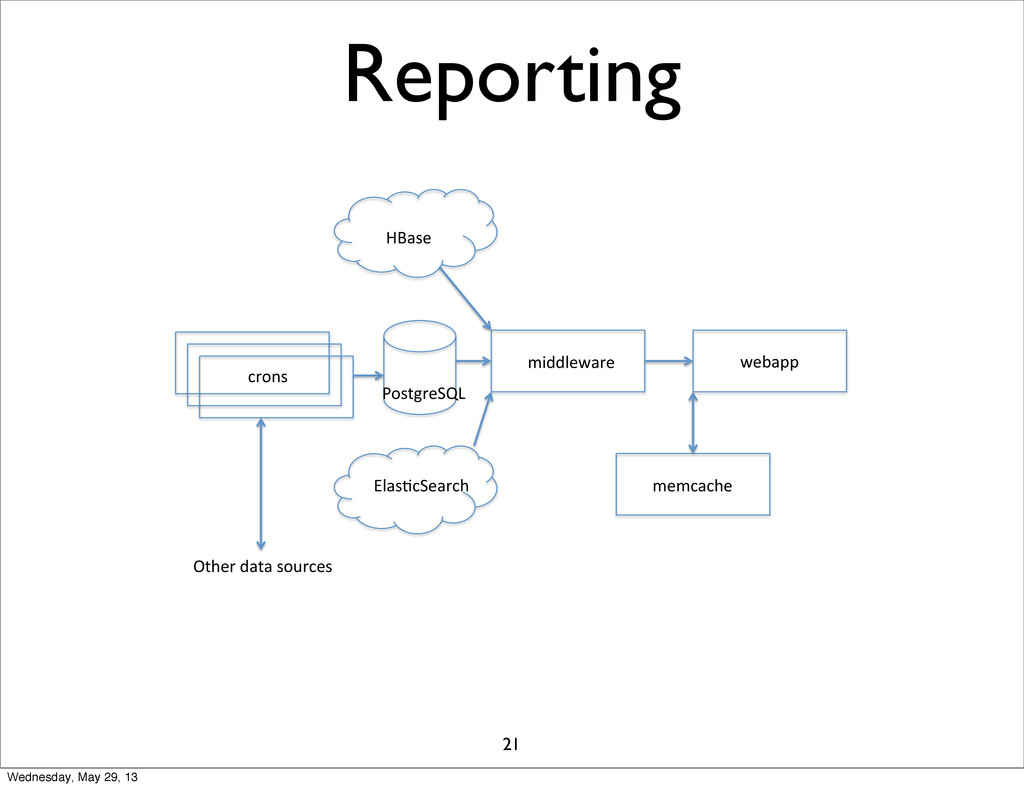
Reporting HBase& PostgreSQL& Elas1cSearch& middleware& webapp& memcache& crons& Other&data&sources& 21
Wednesday, May 29, 13
> 120 physical boxes (not cloud) ~10 developers + DBAs
+ sysadmin team + QA + Hadoop ops 22 Wednesday, May 29, 13
3000 crashes per minute 3 million per day Crash size
150k - 20MB ~800GB stored in PostgreSQL ~110TB stored in HDFS 23 Wednesday, May 29, 13
like many complex systems it’s a data pipeline or firehose,
if you prefer 24 Wednesday, May 29, 13
25 Wednesday, May 29, 13
26 Wednesday, May 29, 13
Diagnostic Indirect Threshold Trend Performance Business 27 Wednesday, May 29,
13
Diagnostic 28 Wednesday, May 29, 13
Host DOWN 500 ISE Replication lag 29 Wednesday, May 29,
13
You know where to look You have a good idea
about what to fix Not always simple, but often well-defined 30 Wednesday, May 29, 13
Indirect 31 Wednesday, May 29, 13
FILE_AGE CRITICAL: blah.log is M seconds old Last record in
database N seconds ago 32 Wednesday, May 29, 13
Something is wrong Maybe with the monitored component Maybe somewhere
upstream 33 Wednesday, May 29, 13
Why is this useful? 34 Wednesday, May 29, 13
High level exception handlers The thing you don’t know to
monitor yet The thing you don’t know how to monitor 35 Wednesday, May 29, 13
You know where to start looking You might have to
look deeper too 36 Wednesday, May 29, 13
Threshold 37 Wednesday, May 29, 13
DISK WARNING - free space: (% used) More files on
disk than there ought to be 38 Wednesday, May 29, 13
Sometimes simple (disk space) Sometimes complex root cause (files) Sometimes
hard to measure 39 Wednesday, May 29, 13
1% errors = normal, expected 5% errors = something bad
is happening 40 Wednesday, May 29, 13
Error rates Count errors (statsd, etc) per window Monitor on
counts (rate) 41 Wednesday, May 29, 13
Trend 42 Wednesday, May 29, 13
Disk is 85% full Did it get that way over
months? Did it get that way in one night? 43 Wednesday, May 29, 13
Trends are important Rates of change are important 44 Wednesday,
May 29, 13
Top crashes (count) Explosive crashes (trend) 45 Wednesday, May 29,
13
Performance 46 Wednesday, May 29, 13
Page load times Other component response times X items processed/minute
47 Wednesday, May 29, 13
Tooling is improving Traditionally more for dev than ops Needs
threshold/trend alerting for ops 48 Wednesday, May 29, 13
Business 49 Wednesday, May 29, 13
Transactions/hour Conversion rate Volumes 50 Wednesday, May 29, 13
Just another performance monitor Thresholds Trends Alerts 51 Wednesday, May
29, 13
Often these exist in human form AUTOMATE Better a page
than an angry boss/customer 52 Wednesday, May 29, 13
53 Wednesday, May 29, 13
You’ve probably heard: Monitoring and testing converge 54 Wednesday, May
29, 13
Running tests on prod can be awesome except when it
isn’t (Knight) (be careful) 55 Wednesday, May 29, 13
two kinds: safe for prod not safe for prod (write,
load, etc) 56 Wednesday, May 29, 13
Monitor as unit test: When you have a failure, add
a monitor (coverage is hard to measure) 57 Wednesday, May 29, 13
Questions?
[email protected]
@lxt 58 Wednesday, May 29, 13
![Many Moving Parts Monitoring Complex Systems [email protected] 1 Wednesday, May](https://files.speakerdeck.com/presentations/25526820aadc01301b635a51928d31b2/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected] @lxt 58 Wednesday, May 29, 13](https://files.speakerdeck.com/presentations/25526820aadc01301b635a51928d31b2/slide_57.jpg){kind=link}