Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OpenTelemetryのバックエンドを作ってparquetと戯れている話
Search
mrasu
September 28, 2023
Programming
920
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OpenTelemetryのバックエンドを作ってparquetと戯れている話
mrasu
September 28, 2023
Other Decks in Programming
See All in Programming
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
3
660
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
870
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3.1k
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
180
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1k
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
230
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
240
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
2.6k
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
210
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
730
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
560
Featured
See All Featured
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Raft: Consensus for Rubyists
vanstee
141
7.6k
What's in a price? How to price your products and services
michaelherold
247
13k
Utilizing Notion as your number one productivity tool
mfonobong
4
460
Faster Mobile Websites
deanohume
310
32k
Building Adaptive Systems
keathley
44
3.1k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Deep Space Network (abreviated)
tonyrice
0
230
A Tale of Four Properties
chriscoyier
163
24k
The browser strikes back
jonoalderson
0
1.4k
Transcript
OpenTelemetryのバックエンド を作ってparquetと戯れている話 株式会社Vaxila Labs 杉中宏亮
⾃⼰紹介 • 杉中 宏亮 (@m_rasu) • 株式会社 Vaxila Labs •
趣味では昔からGo、仕事では 1年ぐらい
SRE NEXTに 落ちたので来ました
SRE NEXTに落ちたので来ました SRE NEXTは明⽇。 SRE NEXTではOpenTelemetry関連のOSSの話をしようと 思ってましたが、 Goの⼈たちの前なので僕が書いている実装の話をします。
OpenTelemetryネィティブの監視SaaSで 会社を作りました
話したいこと Parquetのためにしてる⼯夫 -> Parquet 楽しい
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
Parquetとは • 列指向のファイルフォーマット ◦ CSVやJSONは⾏指向 • ⼤規模なデータを保存するときによく使われる • カラム単位でエンコーディング⽅法を変えられる •
Readに強い代わりに、Writeはダメ
Parquetのエンコーディング⽅法 代表例 • Run length Encoding ◦ 「a,a,a,b,b,b,a,a」 -> 「a3b3a2」みたいな
• Delta Encoding ◦ 差分を書くことで容量圧縮 ◦ 時間の列で⾼威⼒ ◦ 「7,5,3,1」 -> 「7,-2, 3 (最初が7で、-2を連続3回)」みたいな • zstd,snappy,lz4 なども
Goで使う Goなら • xitongsys/parquet-go • parquet-go/parquet-go Vaxilaでは「parquet-go/parquet-go」を使⽤
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
OpenTelemetry とは OpenTelemetry is a vendor-neutral open-source Observability framework -
公式 https://opentelemetry.io/docs/
OpenTelemetry とは 簡単に⾔うと、 • 分散トレーシング • メトリクス • ログ を作ったり、送信したりするのに必要なSDK、プロトコルな
ど⼀式 ベンダー⾮依存が特徴
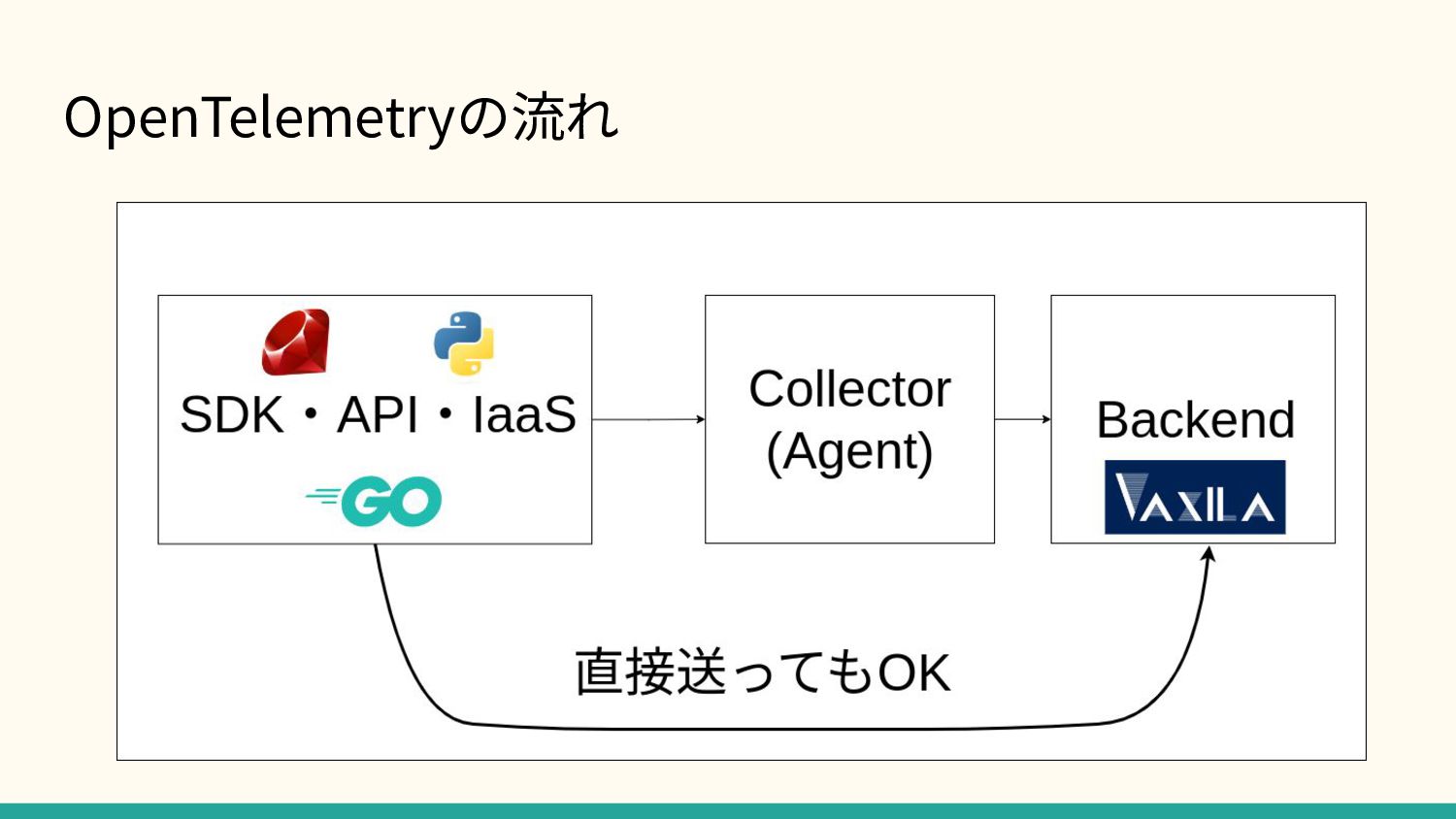
OpenTelemetryの流れ
OpenTelemetry で分散トレーシング 分散トレーシングという名前だが、分散環境じゃなくても便利 下図の1本1本がSpan SpanにはHTTPのパスやSQLなど⾊々記録している
OpenTelemetry は Protocol Buffers • データを送信する時は基本的にProtocol Buffers • json もできる
• Apache Arrow の実装もそのうちできそう
Protocol Buffers例 message TracesData { repeated ResourceSpans resource_spans; } message
ResourceSpans { repeated ScopeSpans scope_spans; } message ScopeSpans { repeated Span spans; } message Span { bytes trace_id; bytes span_id; repeated KeyValue attributes; } 例えば、トレーシングのProtocol Buffersはこんな感じ attributes の中に、 URLや実⾏したSQLが⼊ってい る
OpenTelemetry は Protocol Buffers VaxilaではParquetのフォーマットで保存している
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
Vaxilaとは • 問題を解決するための監視ツール • OpenTelemetryを使ってエラーや速度低下の原因を探し て教える 「SLOを良くするために」
なんで作った? • 原因を⾒つけるために⾊々な特徴を探してた 「これ、⼈間がやる必要ある?」 -> 機械がやれよ • 「それ、前からエラー鳴ってたみたいですが、 全員無視してますね‧‧‧」を無くしたい • 安く
SLOに問題が! 原因特定の流れ
エラーのトレースと、それ以外を⽐べて原因を推測する 原因特定の流れ
attributes の分布からエラー原因を探すことも 原因特定の流れ
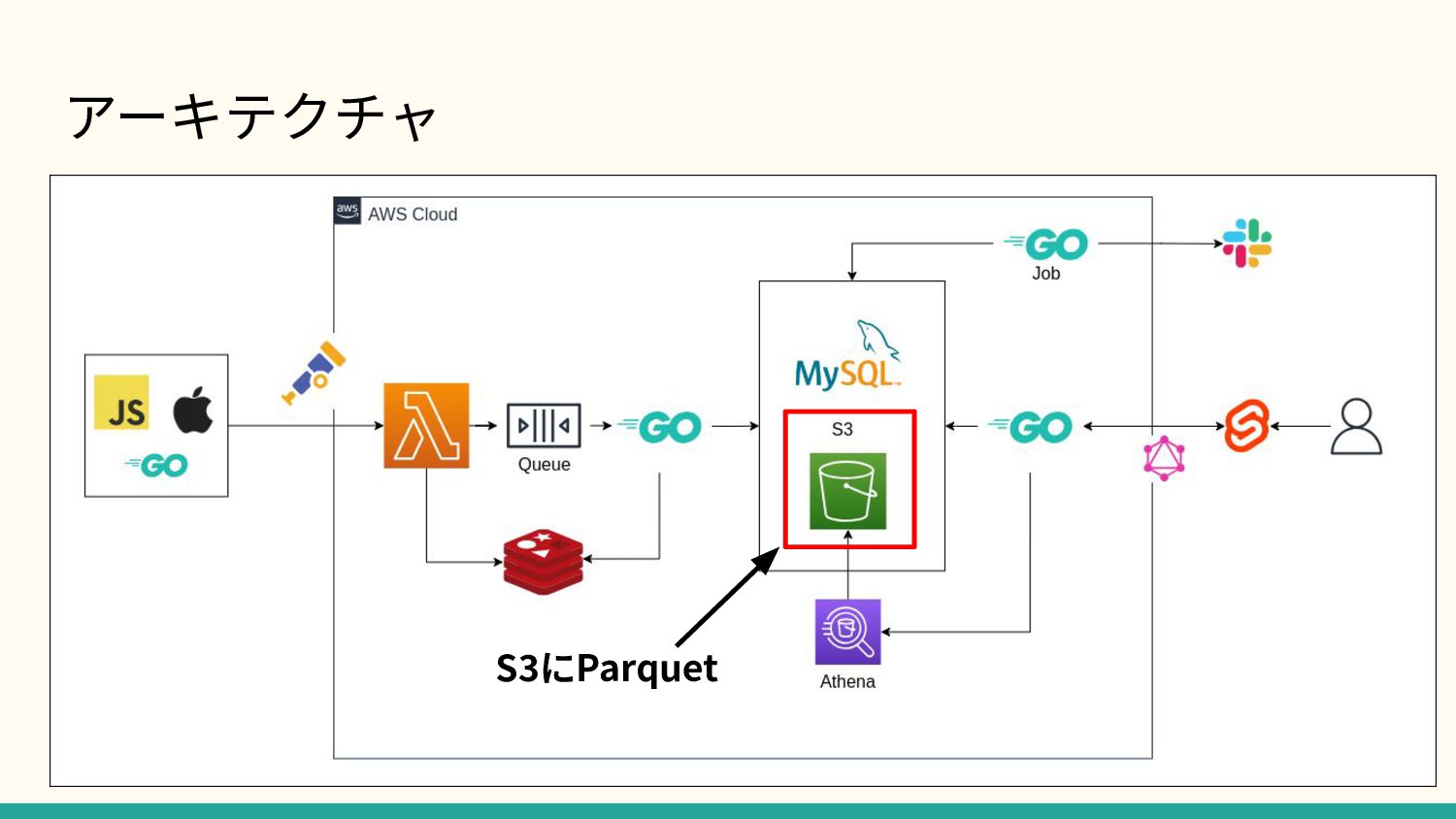
アーキテクチャ S3にParquet
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
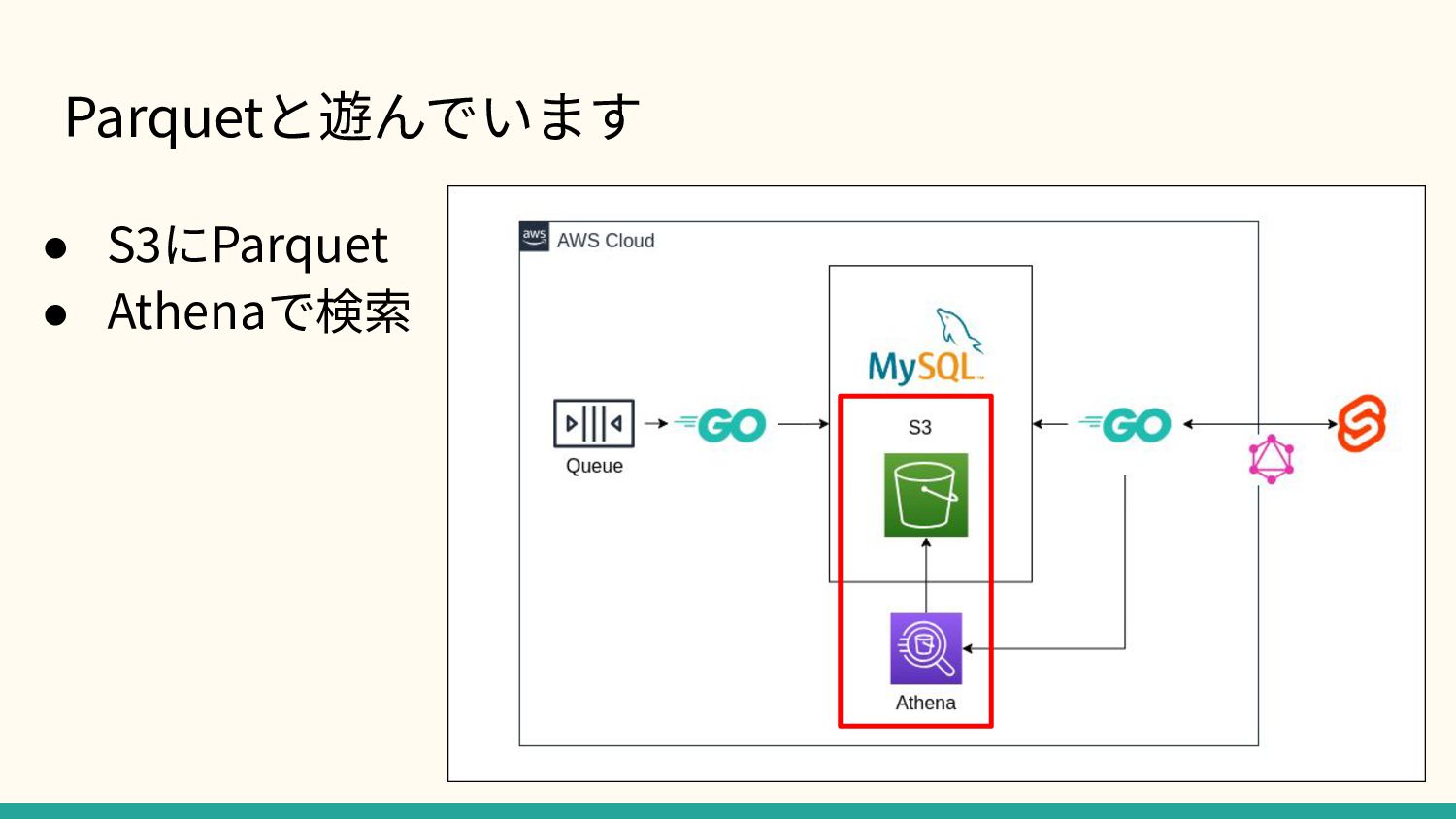
Parquetと遊んでいます • S3にParquet • Athenaで検索
Parquet (OpenTelemetry) ファイルから原因を探す • 例外が起きたか? • 実⾏時間が⻑すぎないか? • エラーではないSpanと⽐較すれば ◦
「user_idが99のときだけエラー起きてるな」 ◦ 「このインスタンスだけ遅いから捨てよう」 というのがわかる
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
OpenTelemetryのフォーマットは使わない Athena (trino) は配列内に触れるとスキャン量がかなり増える -> GoではSpanをトップレベルに type TraceSpan struct {
TraceID []byte `parquet:"trace_id"` SpanID []byte `parquet:"span_id"` Attributes []Attribute `parquet:"attributes,list"` Scope InstrumentationScope `parquet:"scope"` } message ScopeSpans { InstrumentationScope scope; repeated Span spans; } message Span { bytes trace_id; bytes span_id; repeated KeyValue attributes; } go pb
エンコーディングを選ぶ 今は無難なところを指定している • stringの列はzstd • 時間を表す列はdelta encoding type TraceSpan struct
{ SpanID []byte `parquet:"span_id"` Name string `parquet:"name,zstd"` StartTimeUnixNano uint64 `parquet:"start_time_unix_nano,delta"` EndTimeUnixNano uint64 `parquet:"end_time_unix_nano,delta"` }
頻出フィールドを冗⻑化する Spanの属性には “service.name” というキーがよく検索条件になる -> トップレベルにフィールドを作る 他にも、 「例外が起きたか」 などを事前に計算 type
TraceSpan struct { TraceID []byte `parquet:"trace_id"` ServiceName string `parquet:"service_name,zstd,dict"` HasExceptionEvent bool `parquet:"has_exception_event"` } トレース検索の絞り込み
⽬次 1. Parquetとは 2. OpenTelemetryとは 3. Vaxilaとは 4. Parquetと遊ぶ a.
ファイルの内容を考える b. Athenaと遊ぶ
Athenaを使う = SQL を書く SQLは頑張る • Athenaは途中の結果を再使⽤しない ◦ 2回参照したら2回読み込まれる ->
遅い‧お⾦かかる • つまり、UNIONと相性が悪い -> concat, case, filter などで1回しか読まなくてもい いように頑張る
ファイル数を減らして⾼速化 Athenaはファイルを参照するのは時間がかかる 「⼩さいファイルが⼀杯」よりも、「巨⼤なファイルが 少々」の⽅が速い (Parquetの効率も良くなる)
×「データが来るたびにファイルを作る」 ◦「数秒待って1ファイルにまとめる」 キューで⼀括保存
別DBにある項⽬で絞り込み 検索項⽬がRDB(Aurora)にあることがある 「この問題が起きたTraceの中から検索したい」 -> 100万Traceあったら100万個のORがついたSQLが必要ってこと ‧‧‧? -> TraceIdを全部⼊れたファイルを⼀時的にアップロードしてAthena 上でTraceIdを取得できるようにする トレース検索の絞り込み
と、⾊々している
結論 Parquet 楽しい
以上 X(@vaxila_labs)もよろしくお願いします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}