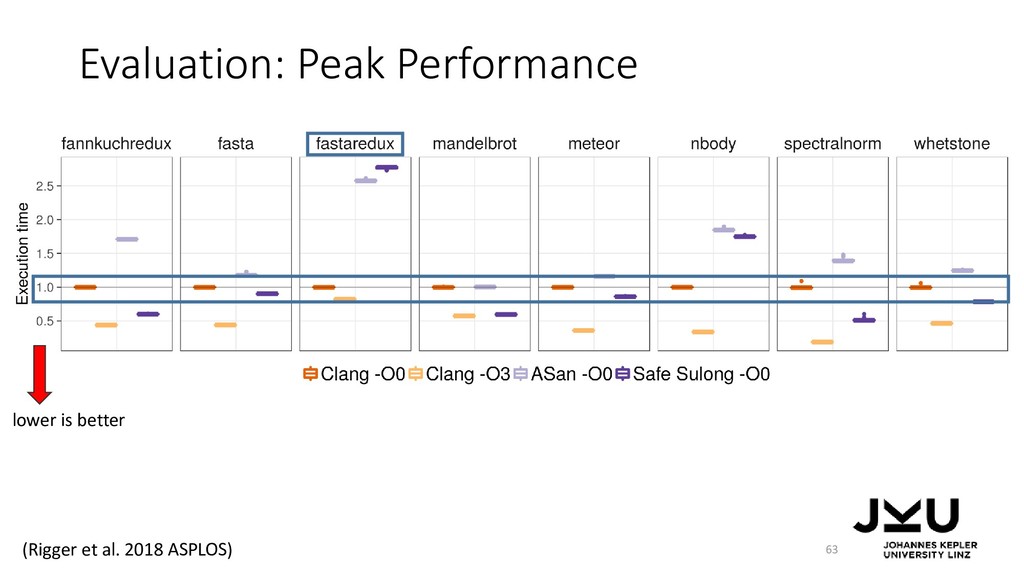
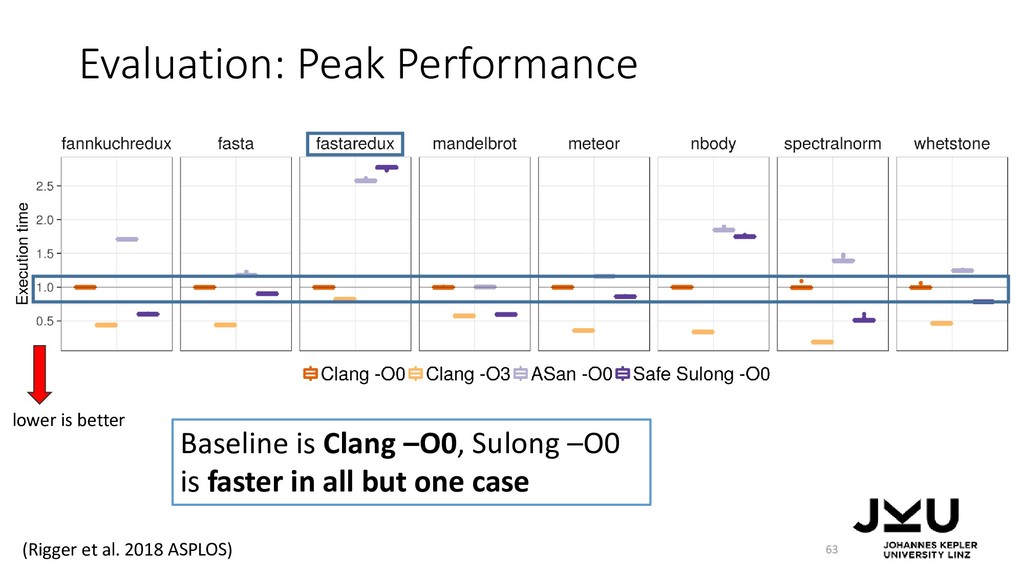
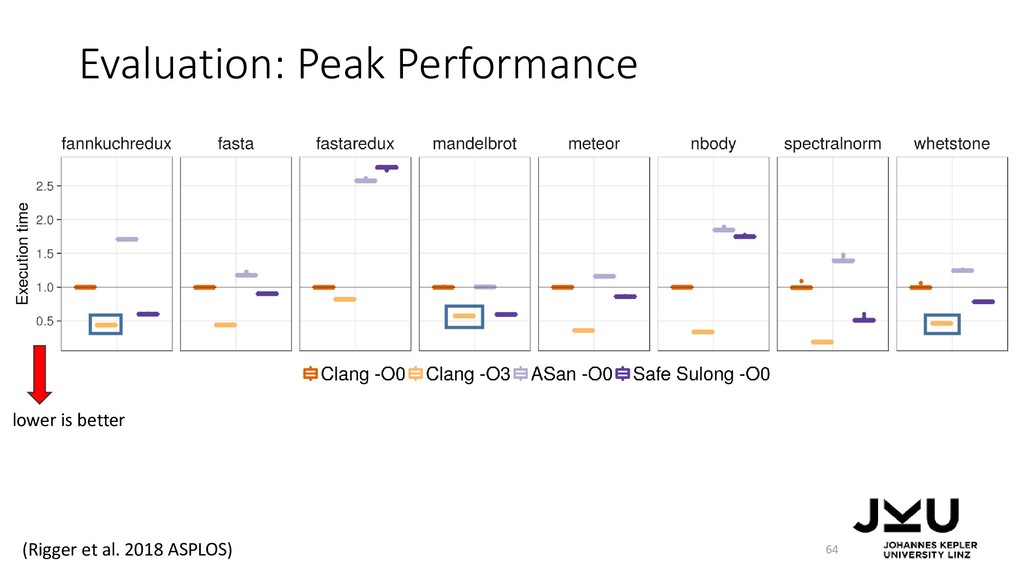
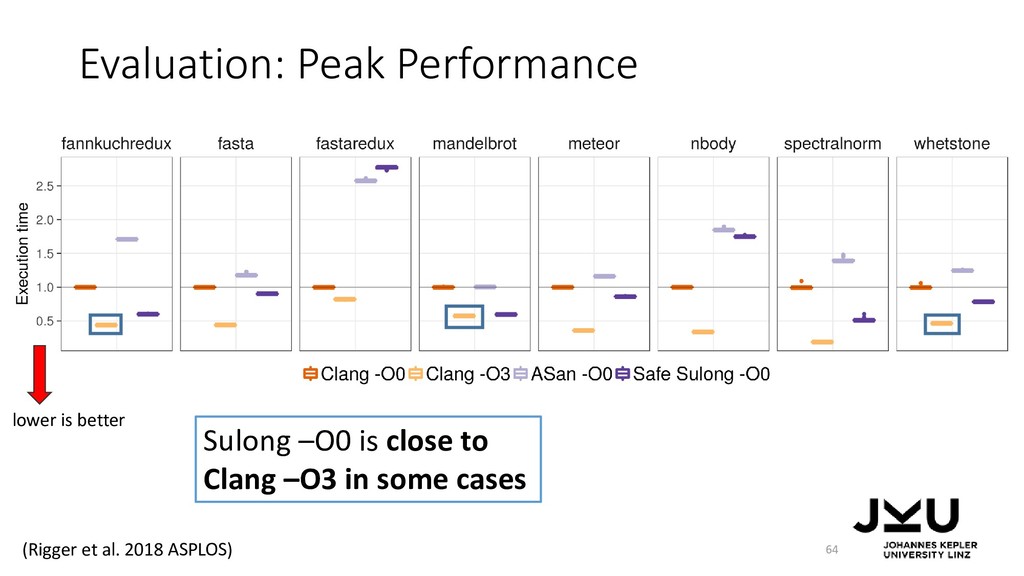
Doug Simon, and Christian Wimmer. 2012. Self-optimizing AST interpreters. In Proceedings of the 8th symposium on Dynamic languages (DLS '12). ACM, New York, NY, USA, 73-82. DOI=http://dx.doi.org/10.1145/2384577.2384587 • Thomas Würthinger, Christian Wimmer, Andreas Wöß, Lukas Stadler, Gilles Duboscq, Christian Humer, Gregor Richards, Doug Simon, and Mario Wolczko. 2013. One VM to rule them all. In Proceedings of the 2013 ACM international symposium on New ideas, new paradigms, and reflections on programming & software (Onward! 2013). ACM, New York, NY, USA, 187-204. DOI=http://dx.doi.org/10.1145/2509578.2509581 • Manuel Rigger, Matthias Grimmer, and Hanspeter Mössenböck. 2016. Sulong - execution of LLVM-based languages on the JVM: position paper. In Proceedings of the 11th Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems (ICOOOLPS '16). ACM, New York, NY, USA, , Article 7 , 4 pages. DOI: https://doi.org/10.1145/3012408.3012416 • Manuel Rigger, Matthias Grimmer, Christian Wimmer, Thomas Würthinger, and Hanspeter Mössenböck. 2016. Bringing low-level languages to the JVM: efficient execution of LLVM IR on Truffle. In Proceedings of the 8th International Workshop on Virtual Machines and Intermediate Languages (VMIL 2016). ACM, New York, NY, USA, 6-15. DOI: https://doi.org/10.1145/2998415.2998416 • Manuel Rigger, Roland Schatz, René Mayrhofer, Matthias Grimmer, and Hanspeter Mössenböck. 2018. Sulong, and Thanks for All the Bugs: Finding Errors in C Programs by Abstracting from the Native Execution Model. In Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '18). ACM, New York, NY, USA, 377-391. DOI: https://doi.org/10.1145/3173162.3173174 85
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
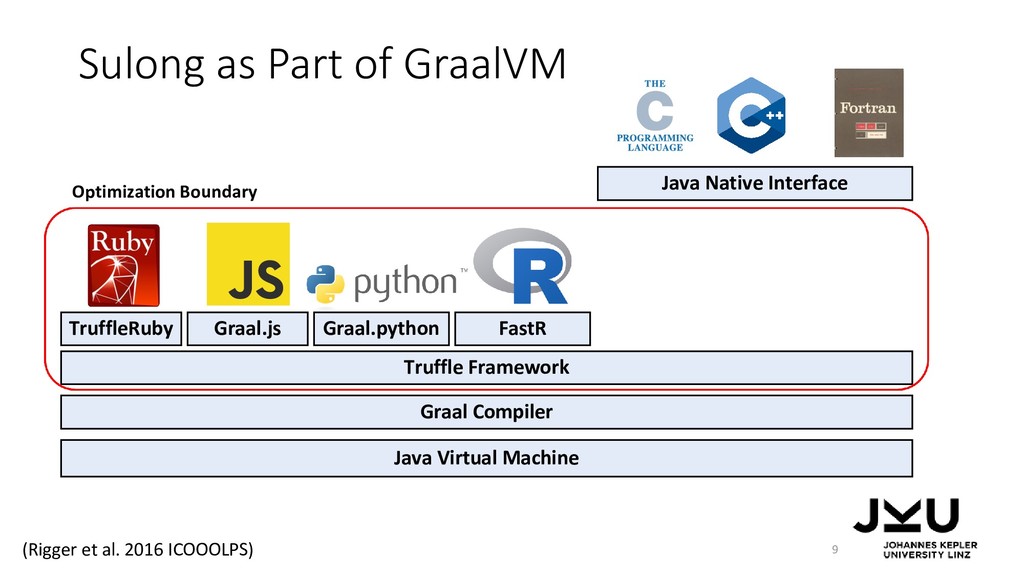{kind=link}
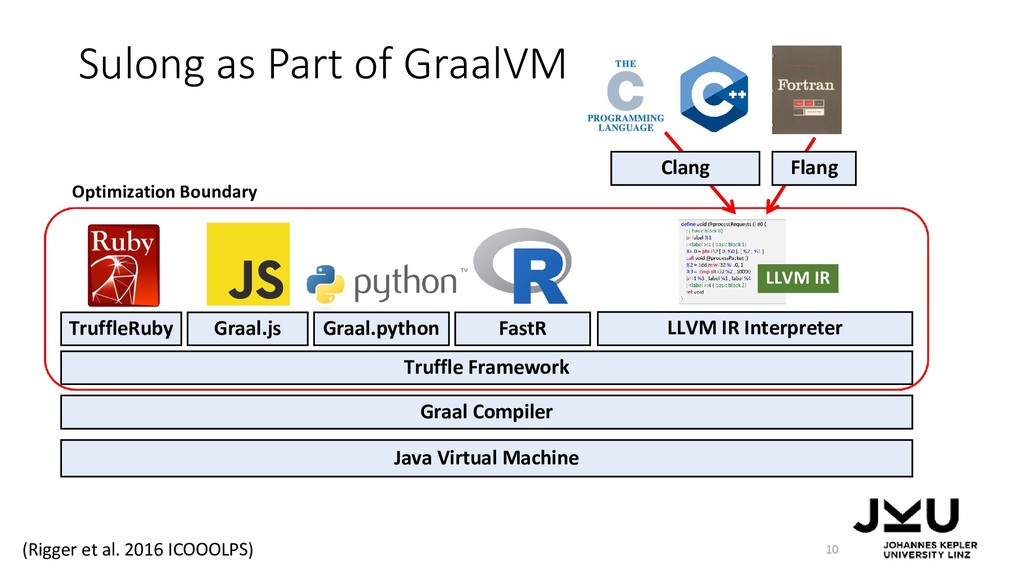{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Buffer Overflows 14 int *arr = malloc(3 * sizeof(int)); arr[5]](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_14.jpg){kind=link}
![Buffer Overflows 14 int *arr = malloc(3 * sizeof(int)); arr[5]](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_15.jpg){kind=link}
![Buffer Overflows 14 int *arr = malloc(3 * sizeof(int)); arr[5]](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_16.jpg){kind=link}
![Use-after-free Errors 15 free(arr); arr[0] = …](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_17.jpg){kind=link}
![Use-after-free Errors 15 free(arr); arr[0] = … C Undefined Behavior](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_18.jpg){kind=link}
![Use-after-free Errors 15 free(arr); arr[0] = … C Undefined Behavior](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
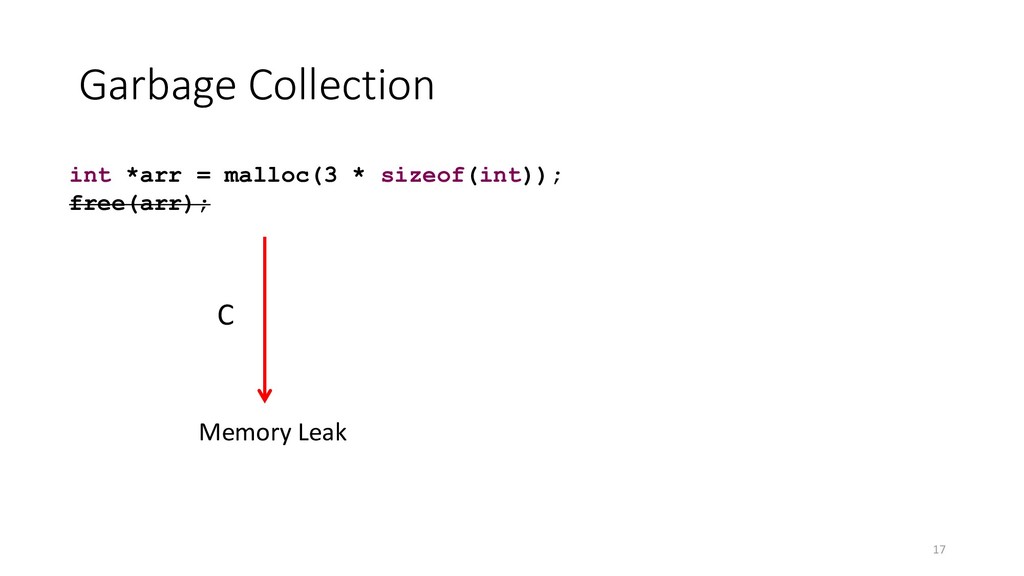{kind=link}
![Garbage Collection 17 Java C int[] arr = new int[3];](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![Compiler Optimizations 19 int test(size_t i) { int arr[2] =](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_26.jpg){kind=link}
![Compiler Optimizations 19 int test(size_t i) { int arr[2] =](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_27.jpg){kind=link}
![Compiler Optimizations 19 int test(size_t i) { int arr[2] =](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_28.jpg){kind=link}
![Compiler Optimizations 20 int test(size_t i) { int arr[2] =](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_29.jpg){kind=link}
![Compiler Optimizations 20 ArrayIndexOutOfBoundsException int test(size_t i) { int arr[2]](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
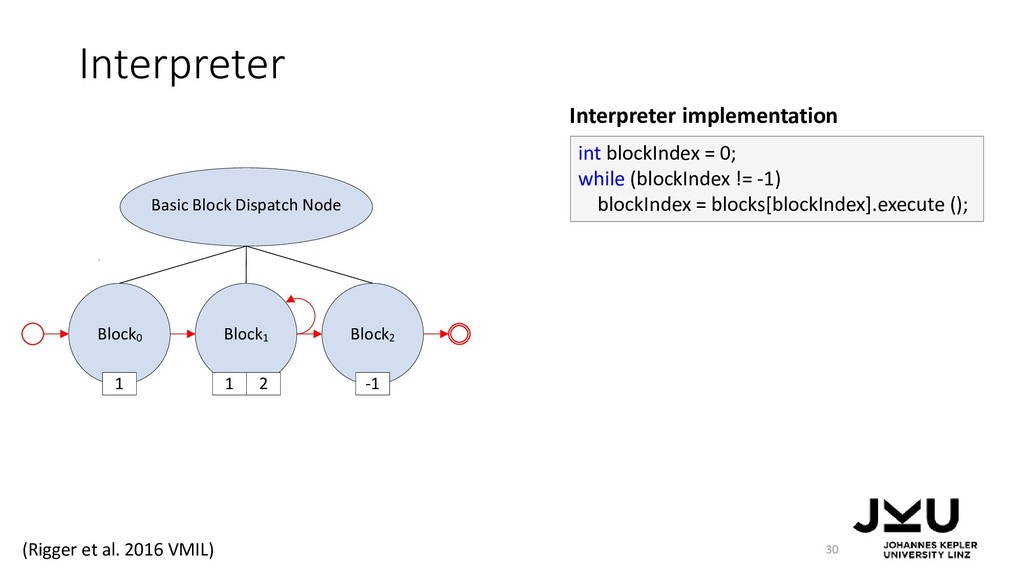{kind=link}
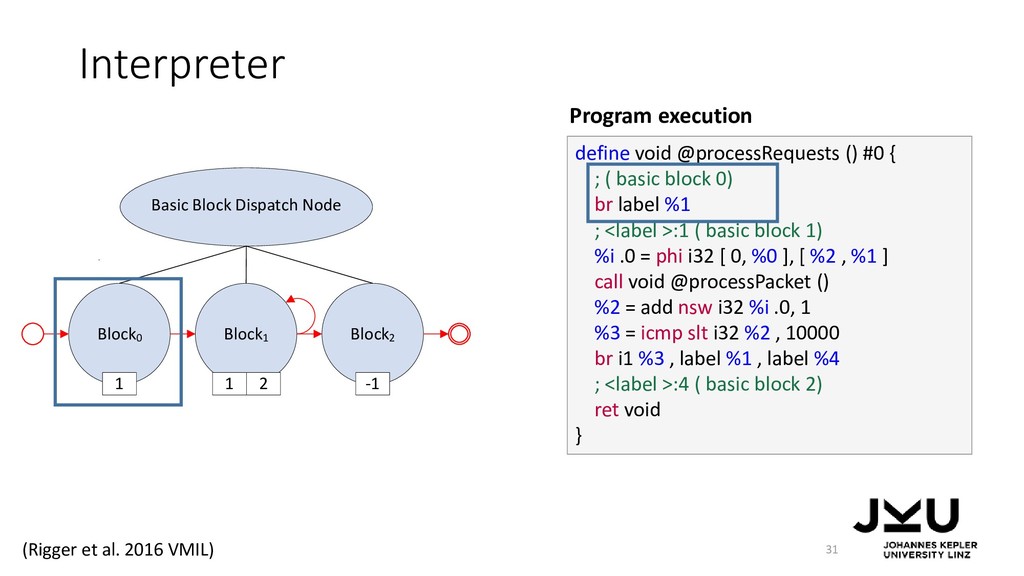{kind=link}
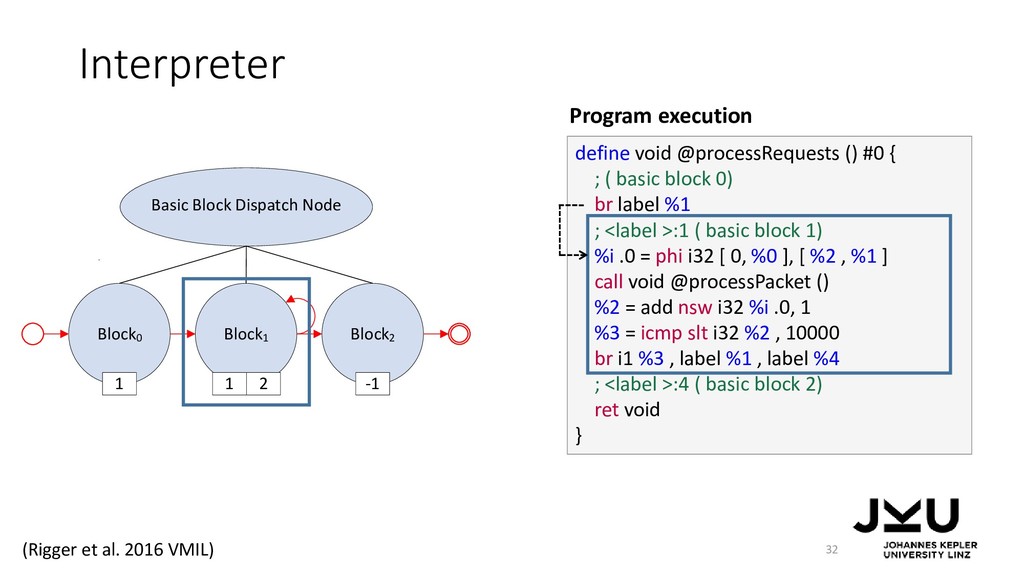{kind=link}
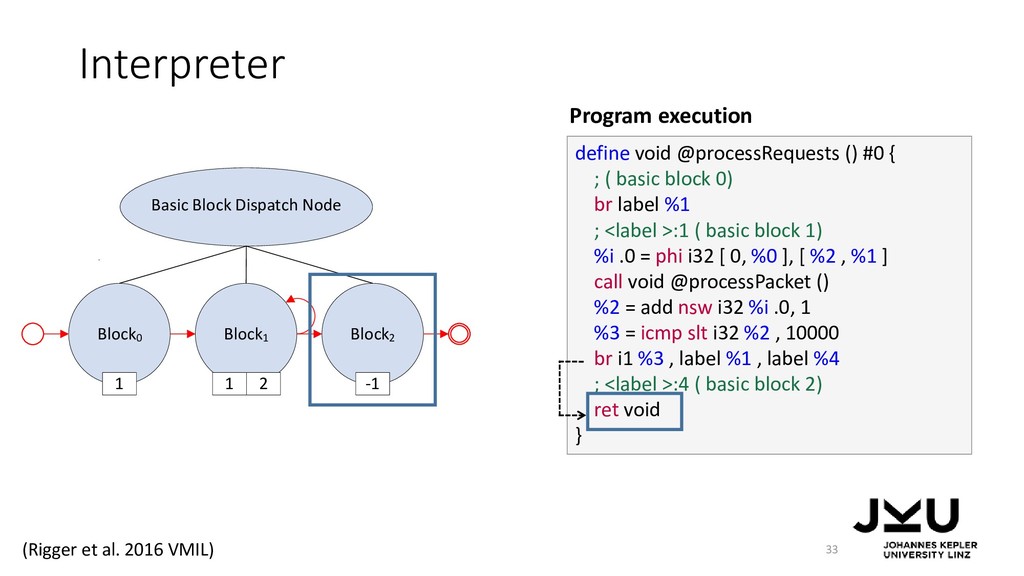{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
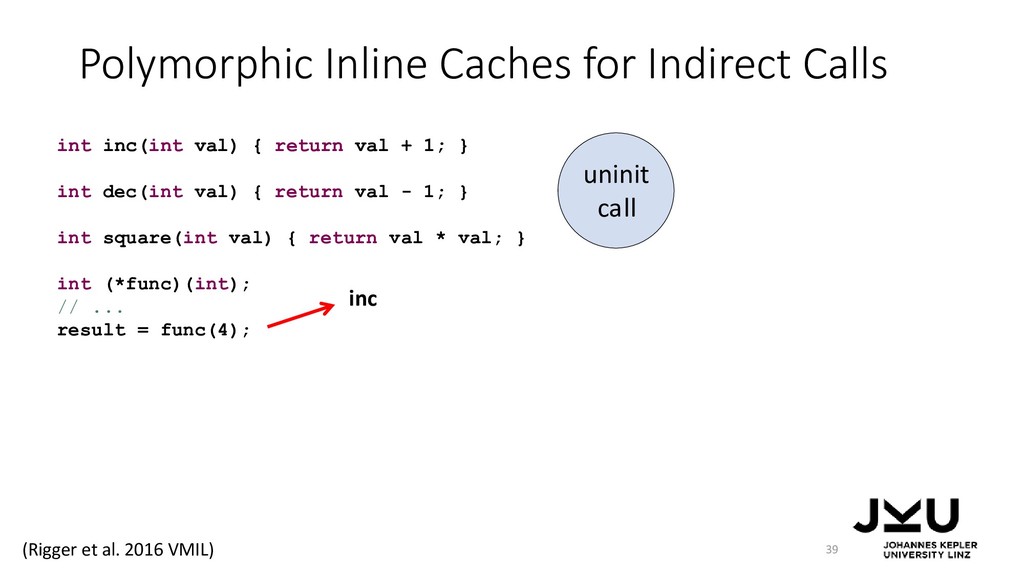{kind=link}
{kind=link}
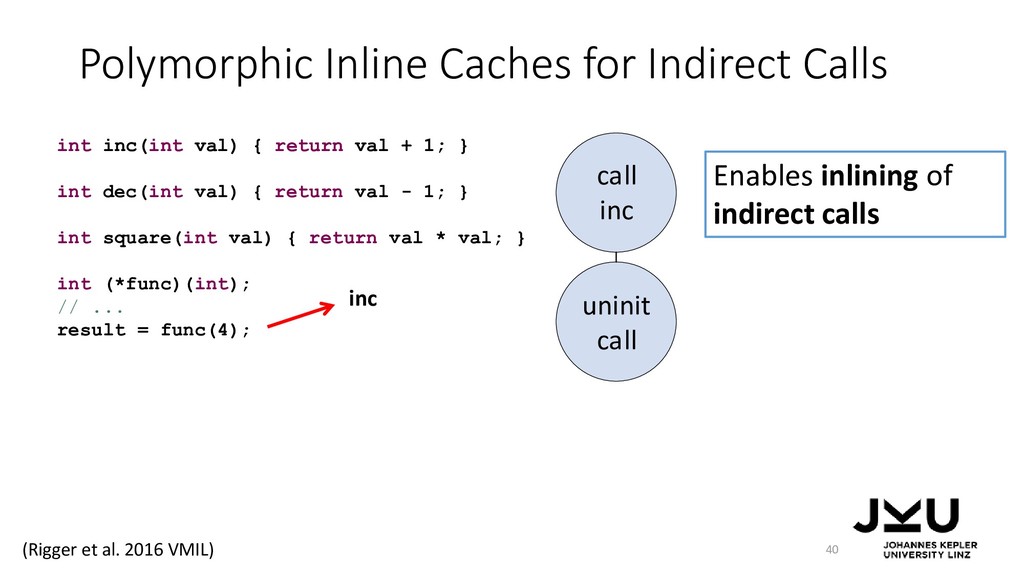{kind=link}
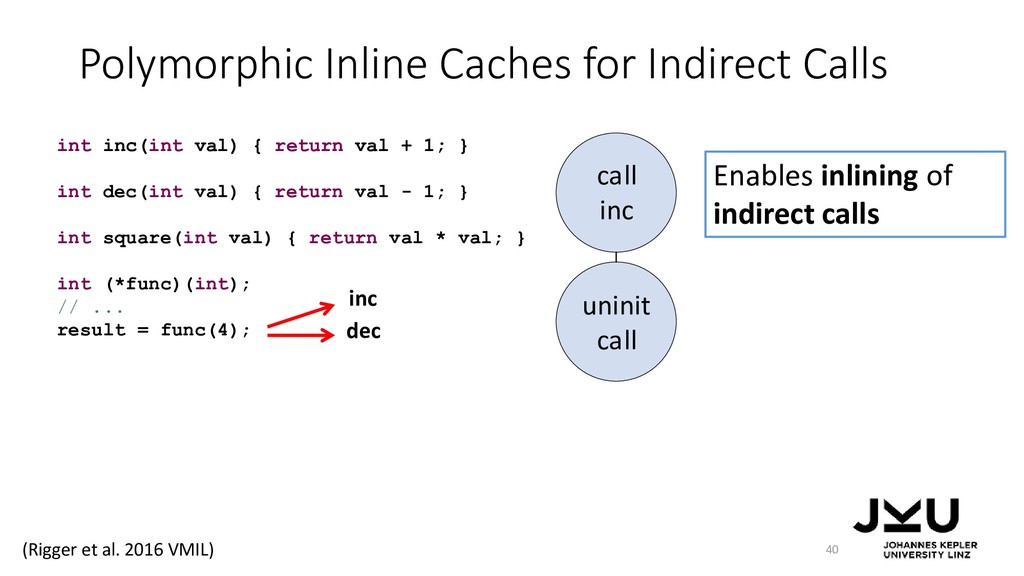{kind=link}
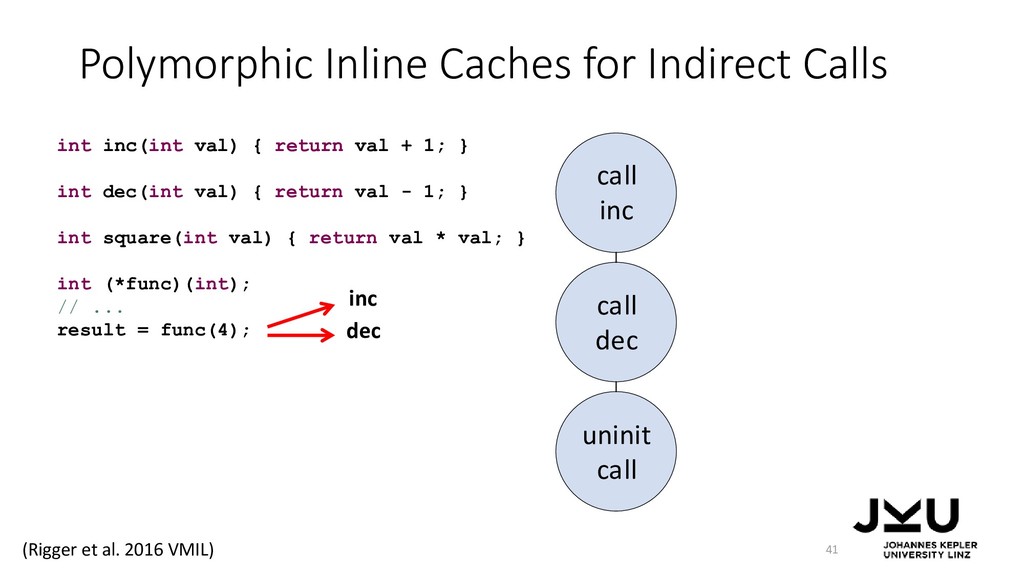{kind=link}
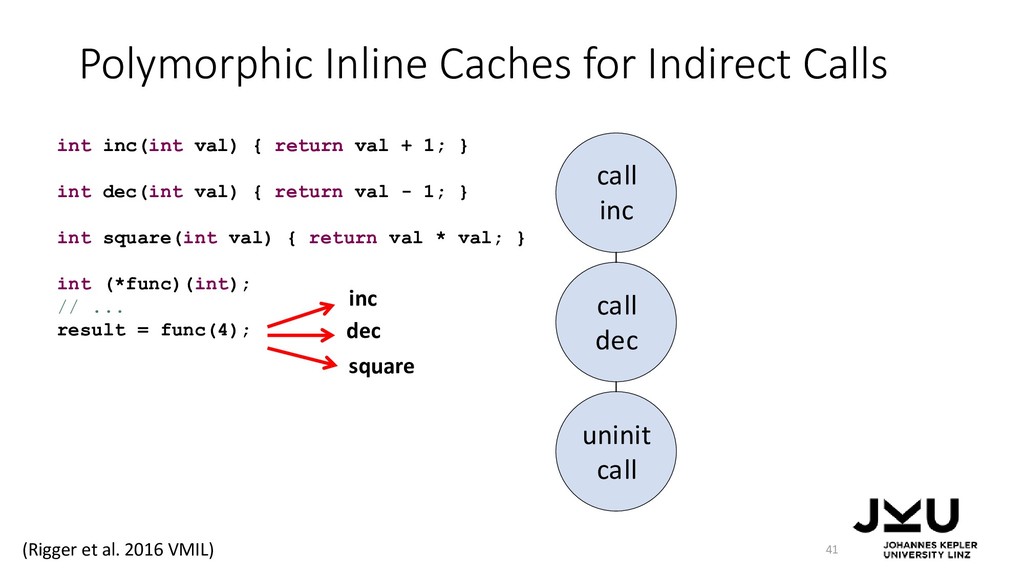{kind=link}
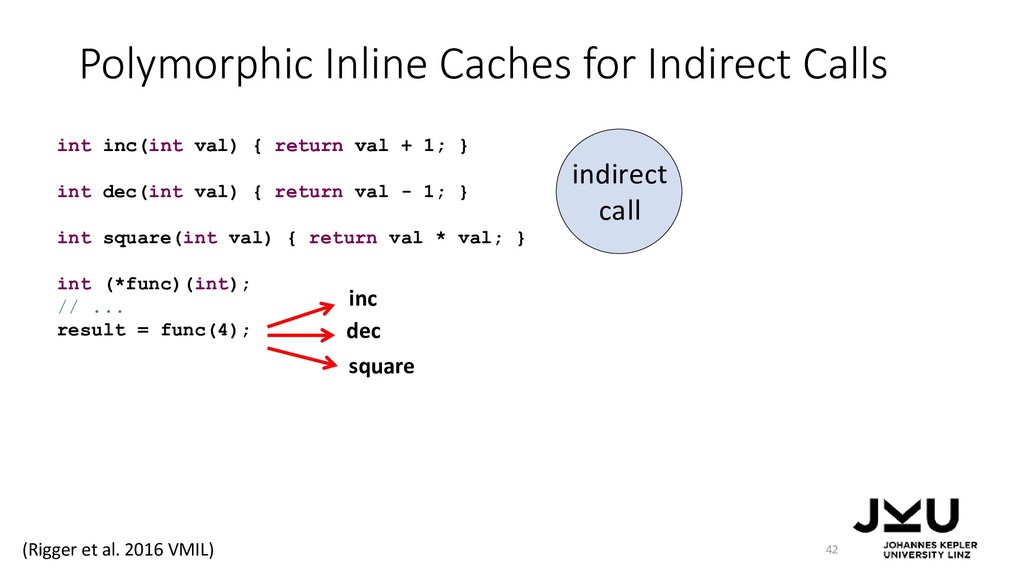{kind=link}
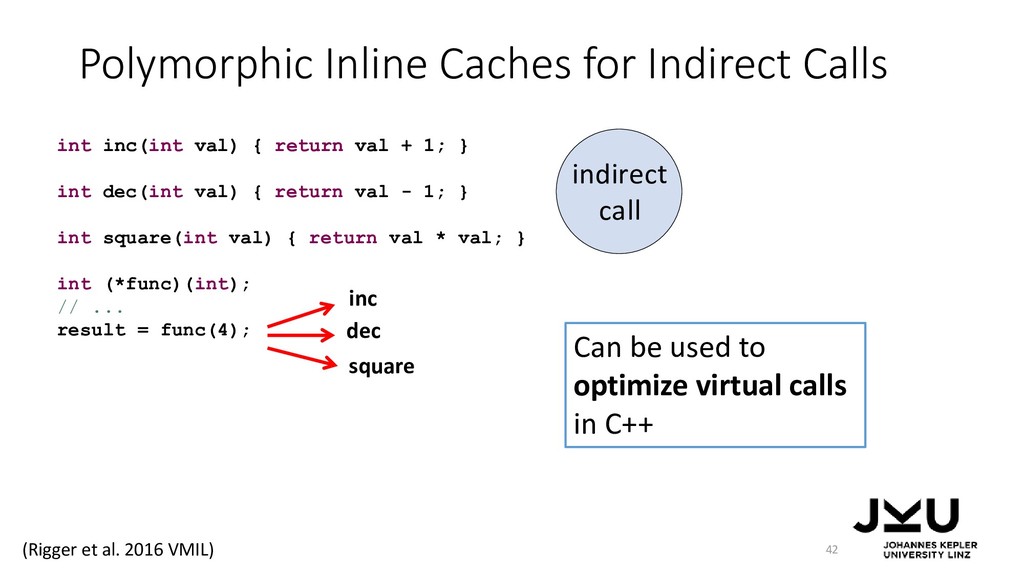{kind=link}
{kind=link}
{kind=link}
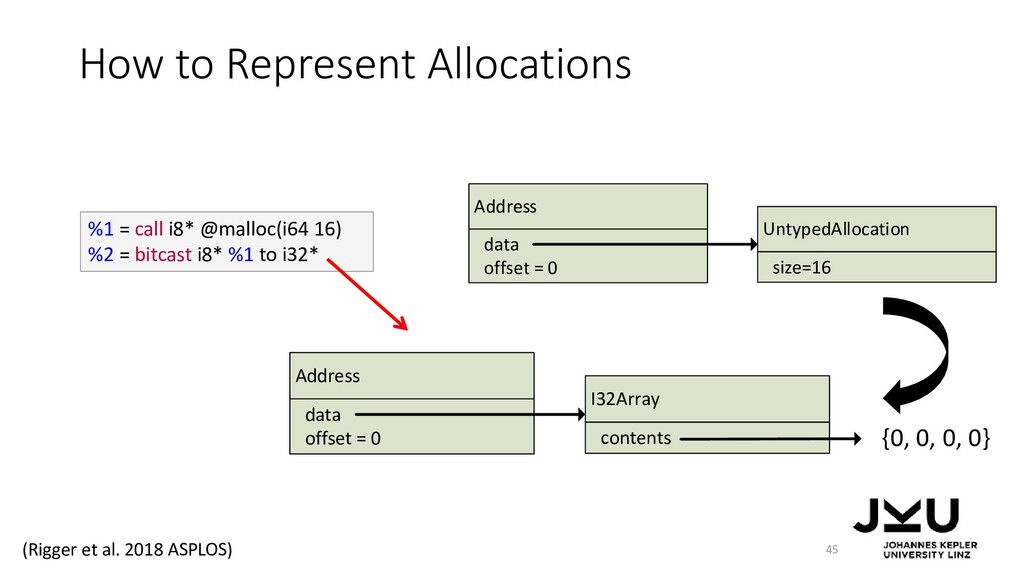{kind=link}
![Prevent Out-Of-Bounds Accesses 46 arr[5] = … Address offset =](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_76.jpg){kind=link}
![Prevent Out-Of-Bounds Accesses contents[5] → ArrayIndexOutOfBoundsException 46 arr[5] = …](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_77.jpg){kind=link}
![Prevent Use-After-Free Errors 47 free(arr); arr[0] = … Address offset=0](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_78.jpg){kind=link}
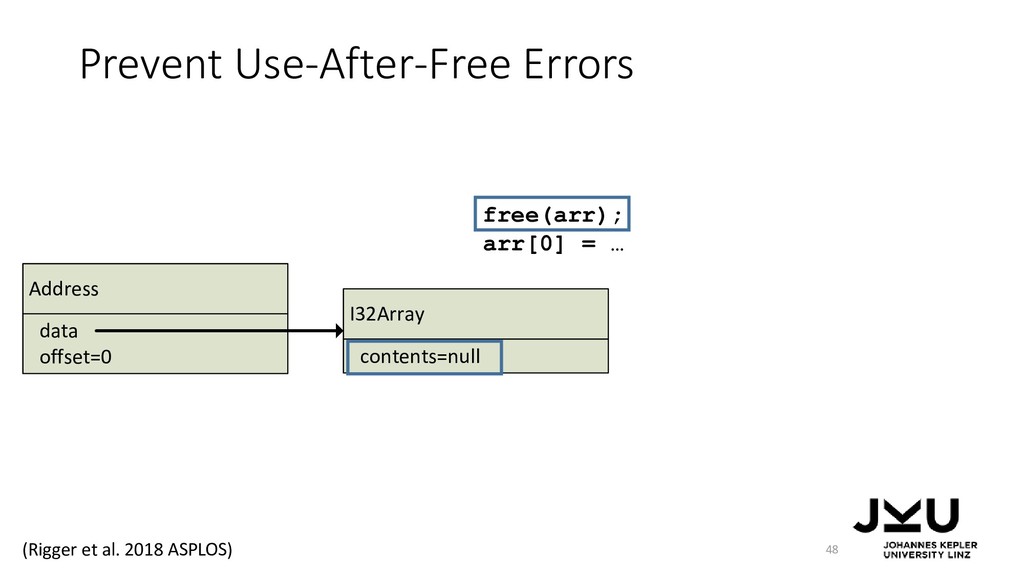{kind=link}
![Address offset=0 data I32Array contents=null Prevent Use-After-Free Errors contents[0]→ NullPointerException](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
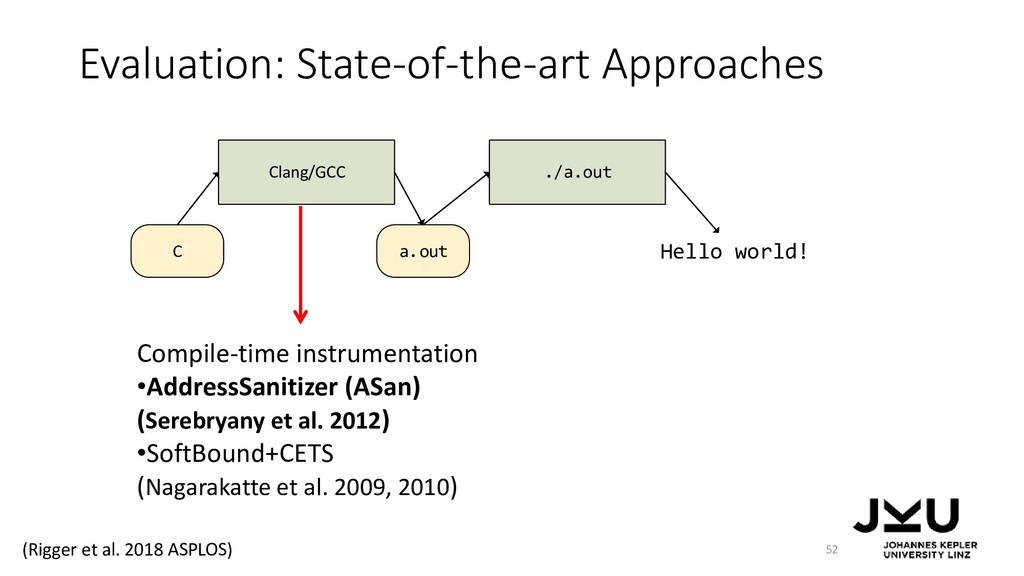{kind=link}
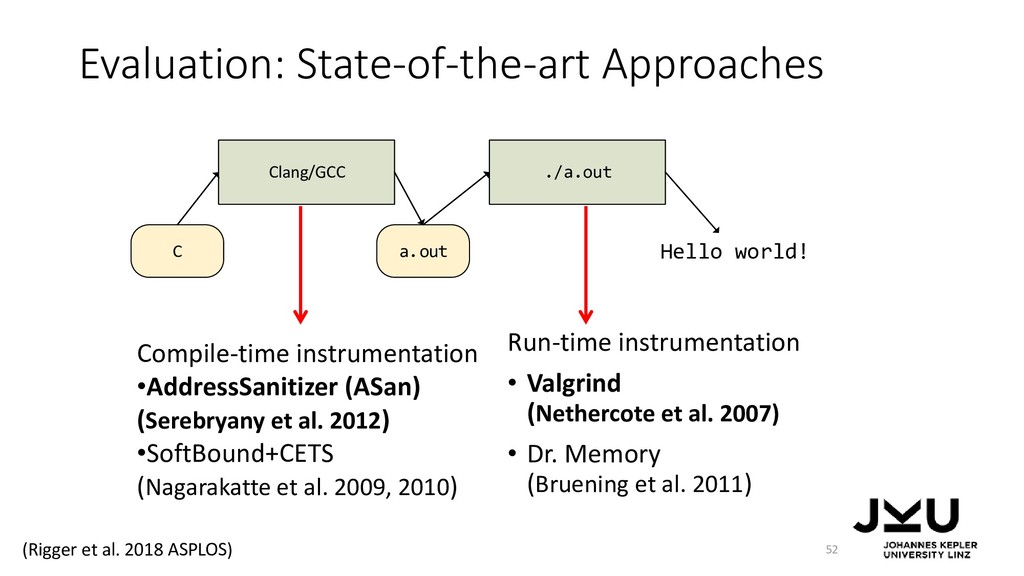{kind=link}
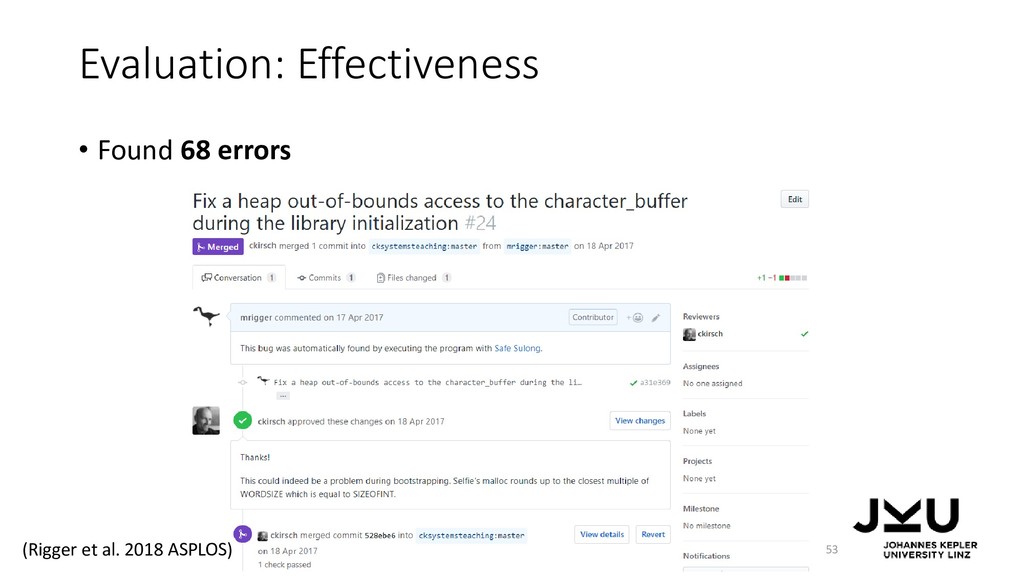{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
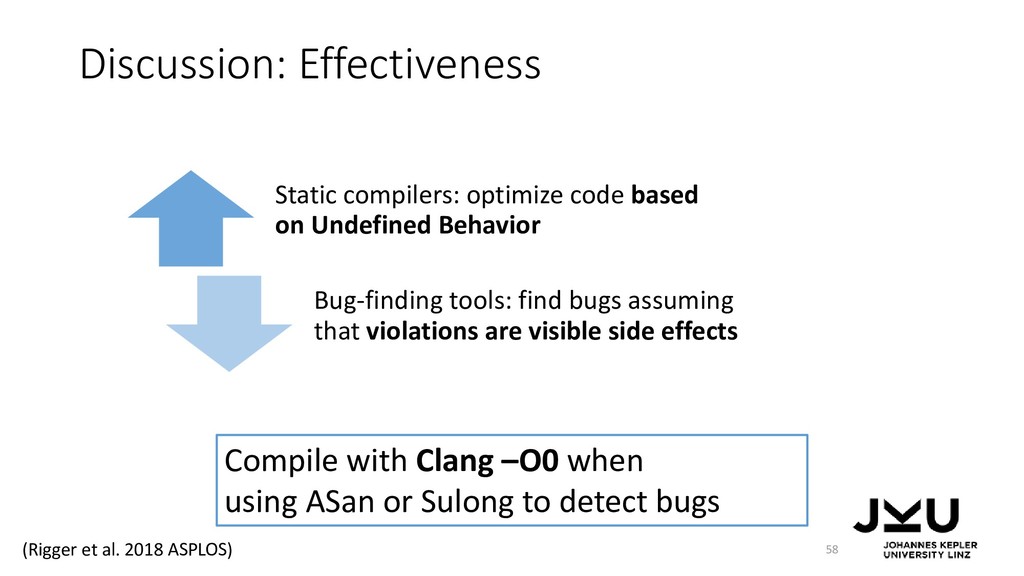{kind=link}
![Discussion: Effectiveness 59 ArrayIndexOutOfBoundsException int test(size_t i) { int arr[2]](https://files.speakerdeck.com/presentations/c29bbcb14b66471f811269e79ba49f46/slide_94.jpg){kind=link}
{kind=link}
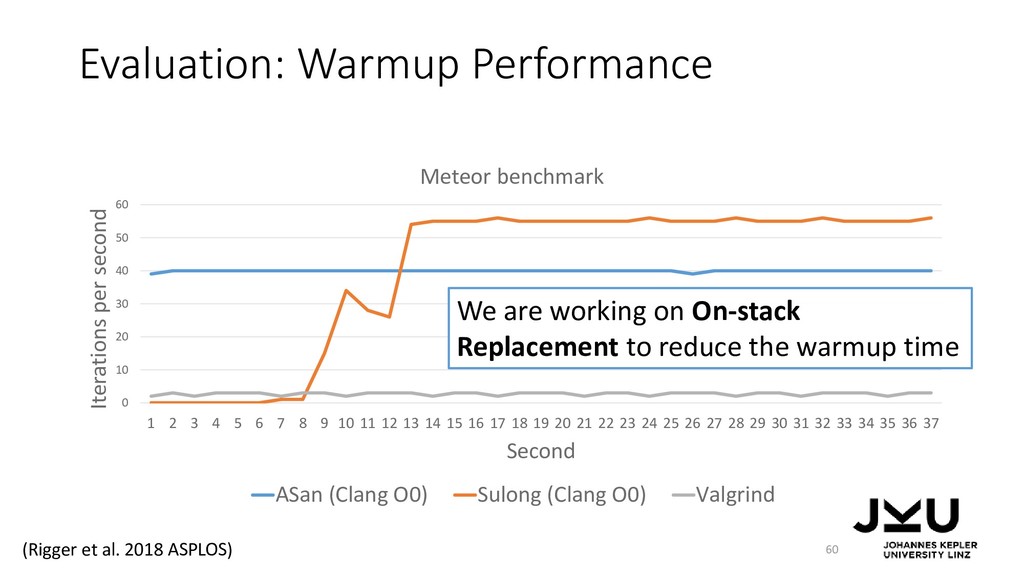{kind=link}
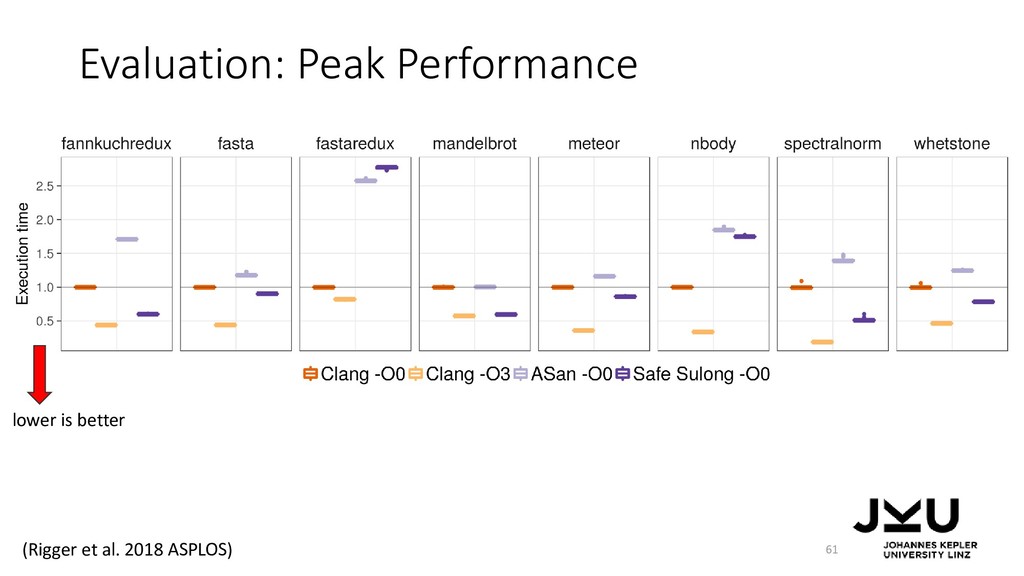{kind=link}
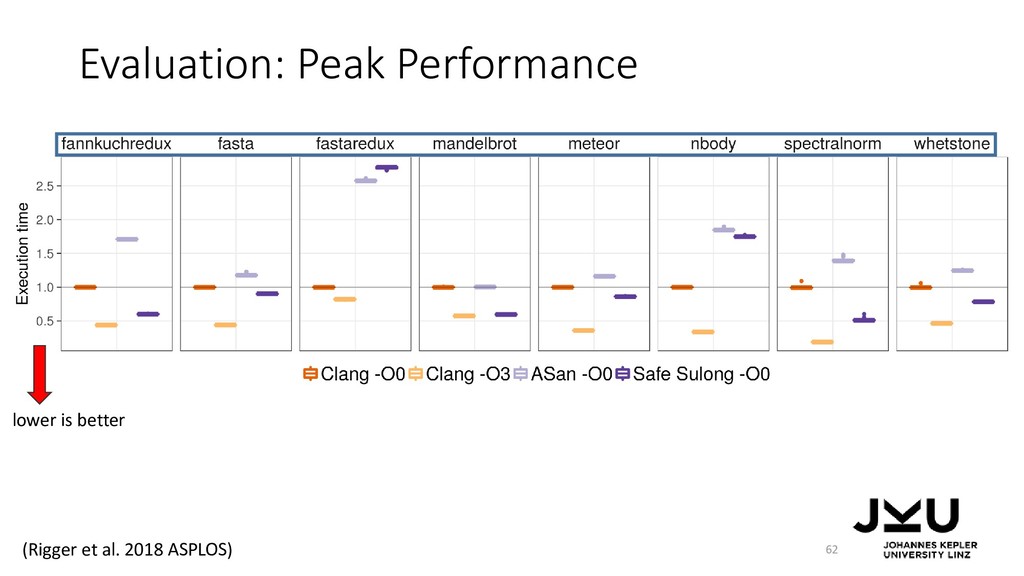{kind=link}
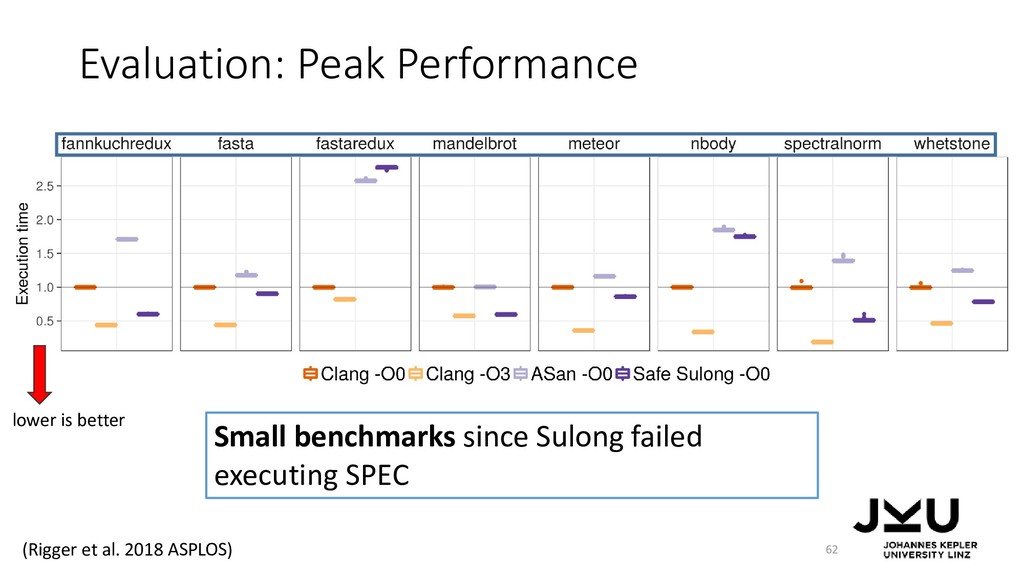{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
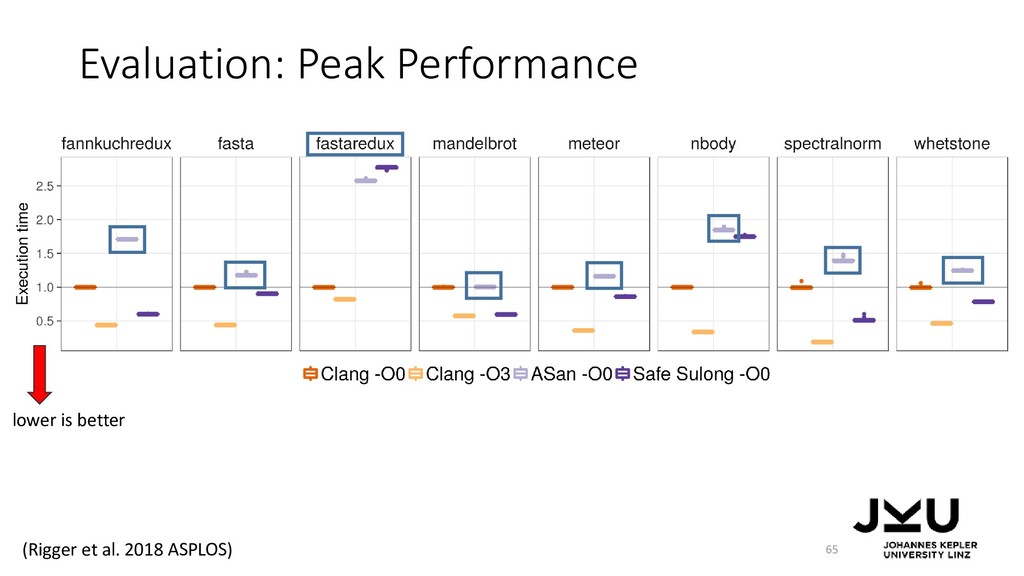{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
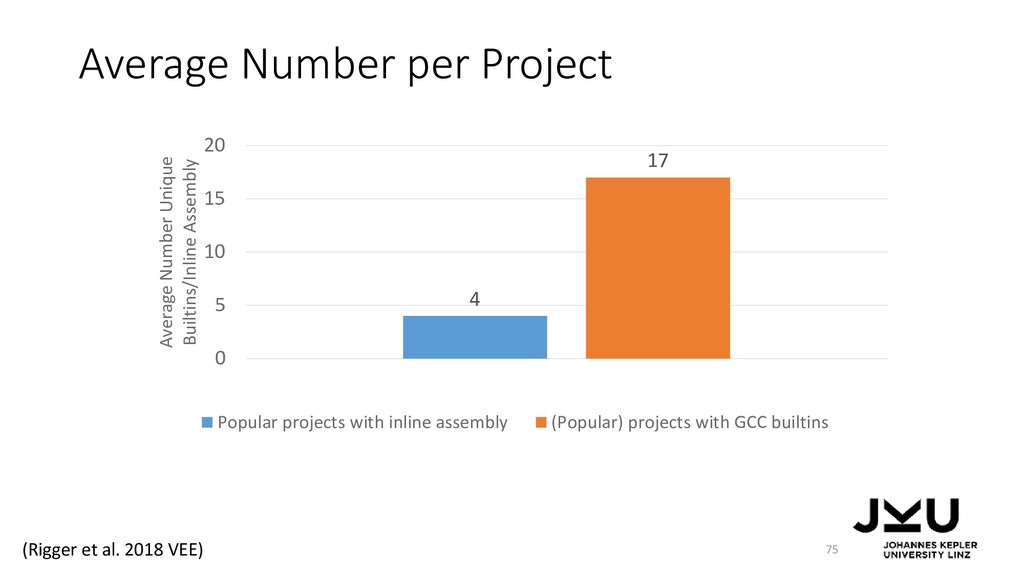{kind=link}
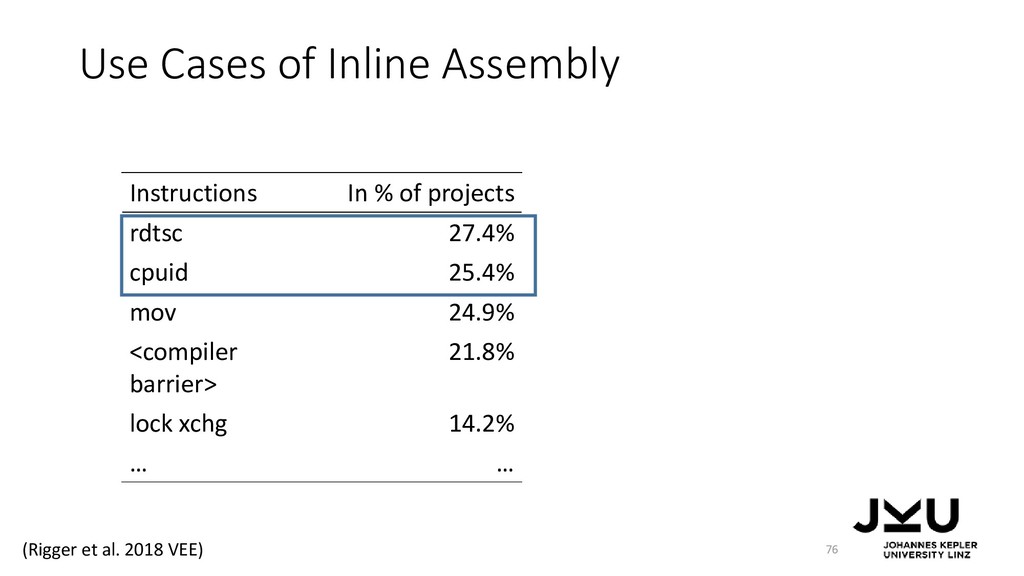{kind=link}
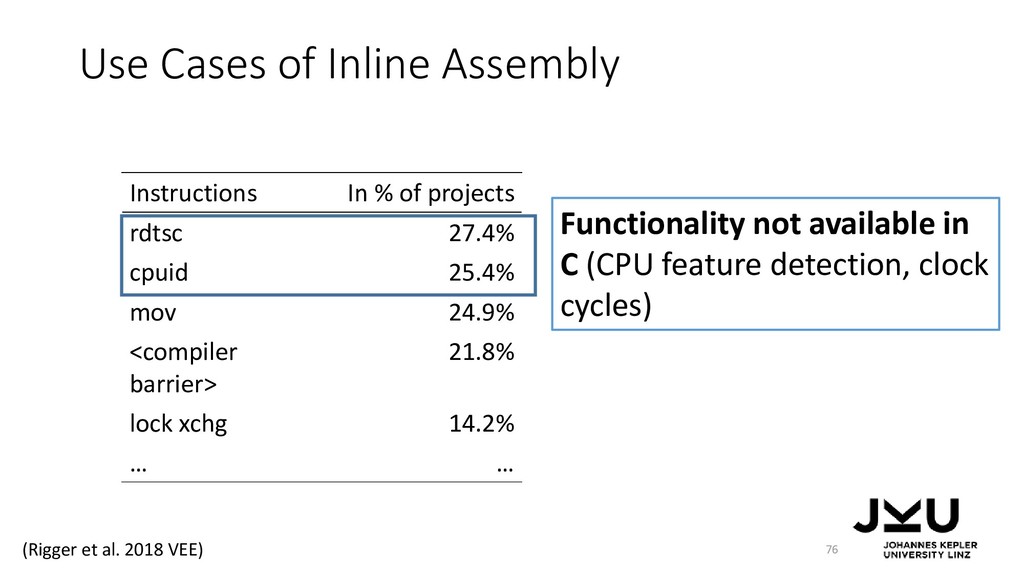{kind=link}
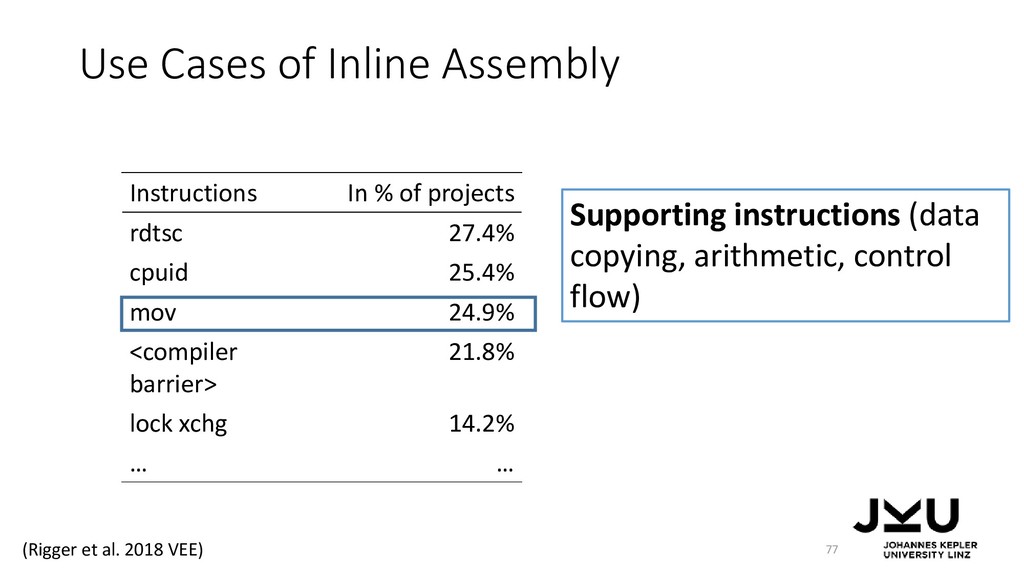{kind=link}
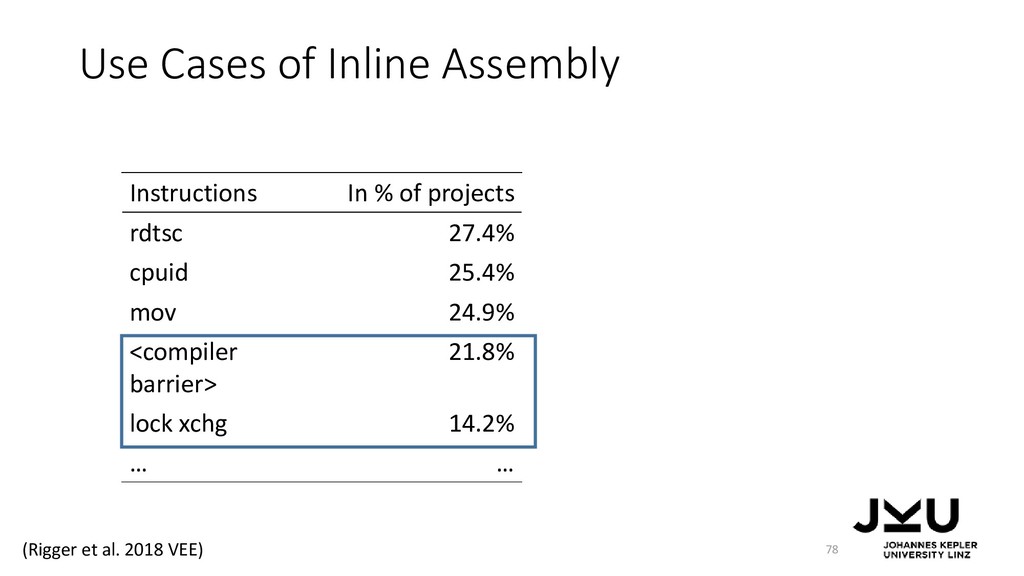{kind=link}
{kind=link}
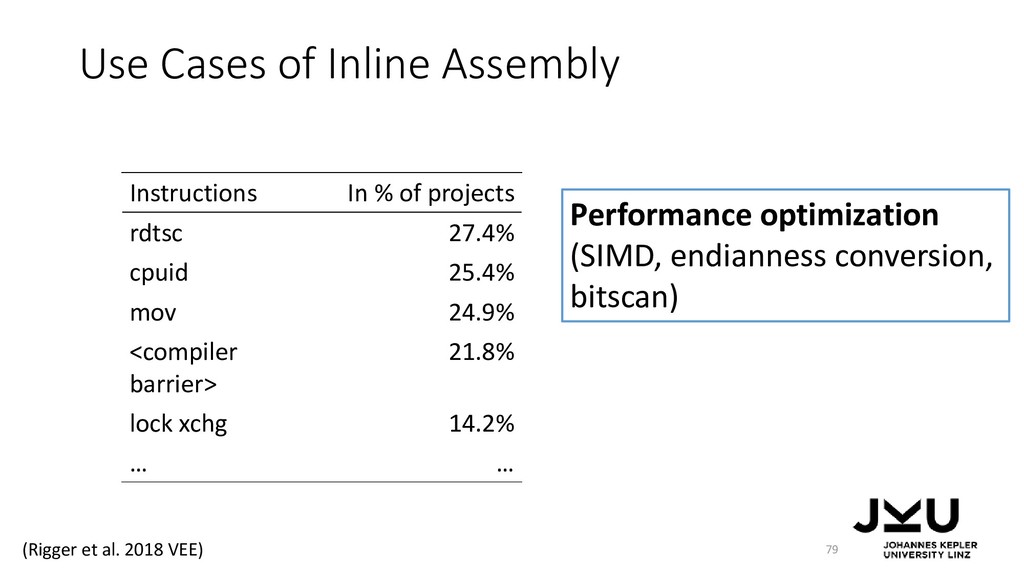{kind=link}
{kind=link}
{kind=link}
{kind=link}
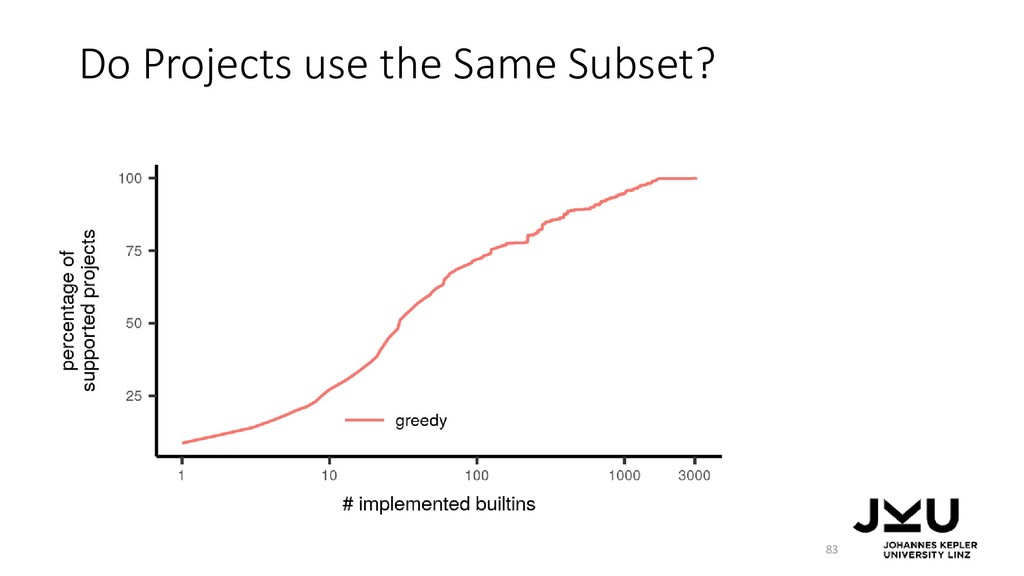{kind=link}
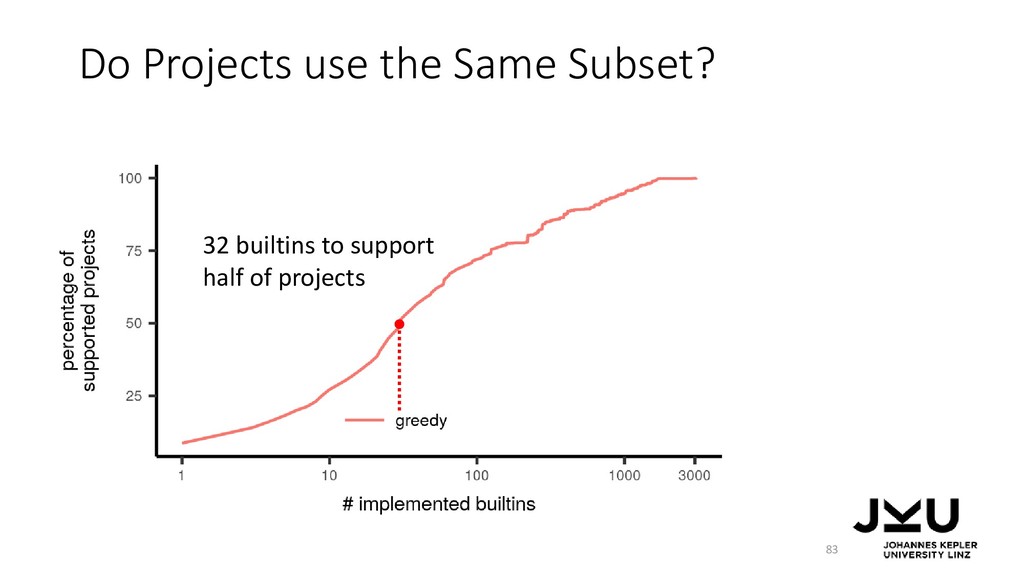{kind=link}
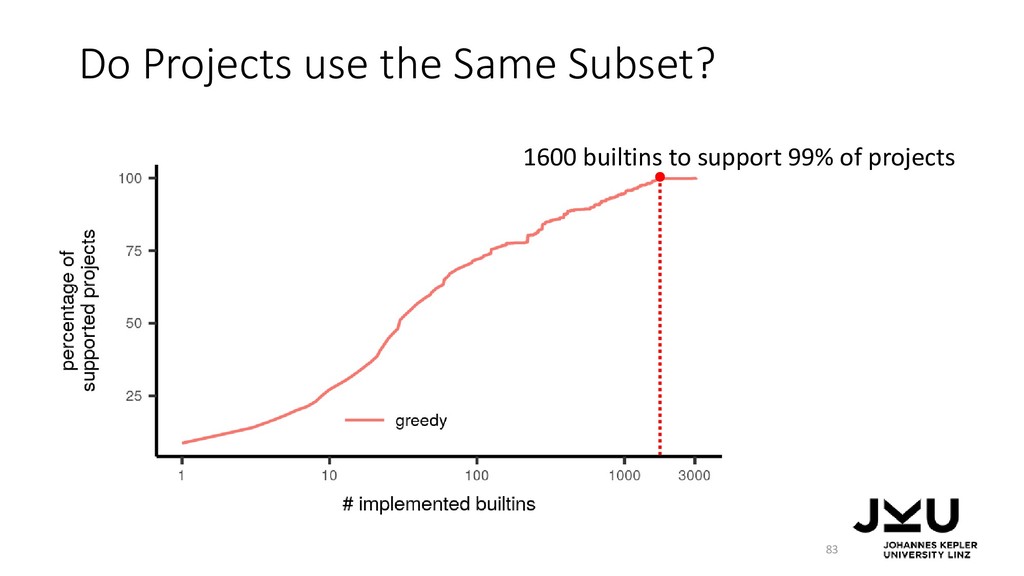{kind=link}
{kind=link}
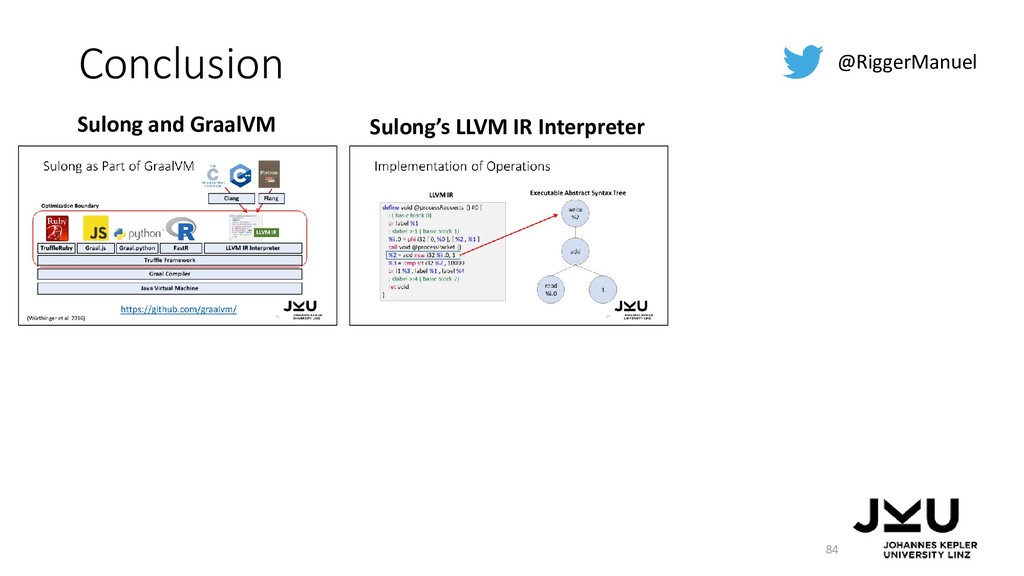{kind=link}
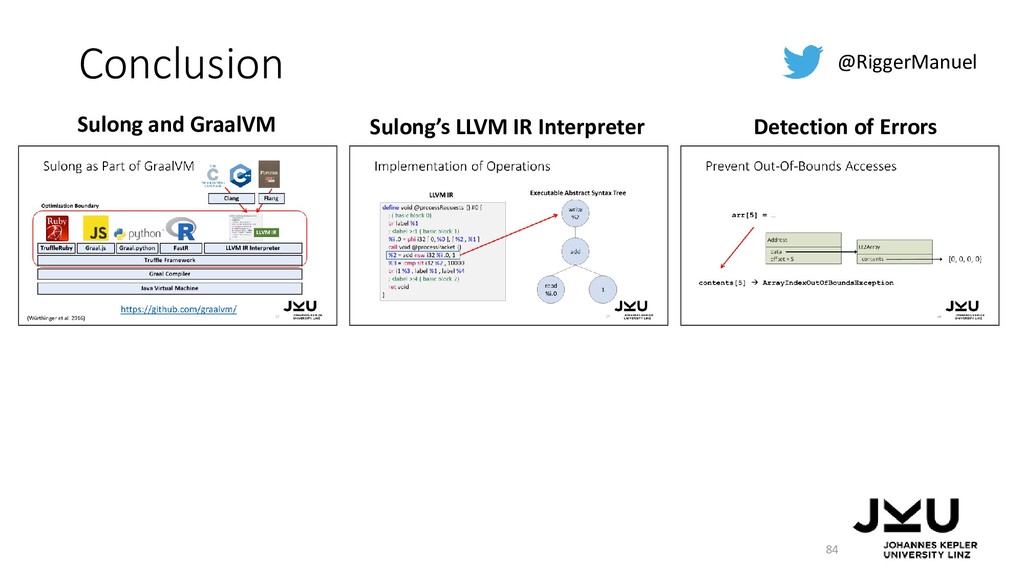{kind=link}
{kind=link}
{kind=link}
{kind=link}