Confiabilidade • Ben Treynor Sloos, Vice Presidente de Engenharia do Google • Incorporar aspectos de Engenharia em Operações • Garantir a Confiabilidade de Software e Produtos O QUE É SRE?
em contrato. A obrigação. Nunca pode ser 100%. SLA Service Level Indicator O indicador de performance do SLO e SLA. O dedo duro. SLI Service Level Objective O objetivo de melhora da métrica. Mais rigoroso que o SLA. A estrela guia. Nunca pode ser 100%. SLO O quanto falta pro SLO e SLA serem quebrados? A margem de erro. Error Budget
time técnico • É simples, objetivo, todos entendem • Sem glamour • "Se alguém demora mais que 30 segundos pra entender, está ruim" Métricas de Confiabilidade
tempo Rate Duração média, maxima, p99, p90, p50 dos requests dentro de um determinado range de tempo Duration Porcentagem de erros em um determinado range de tempo Error • Métricas voltadas para serviços e microsserviços • Modelo baseado em uso de serviço
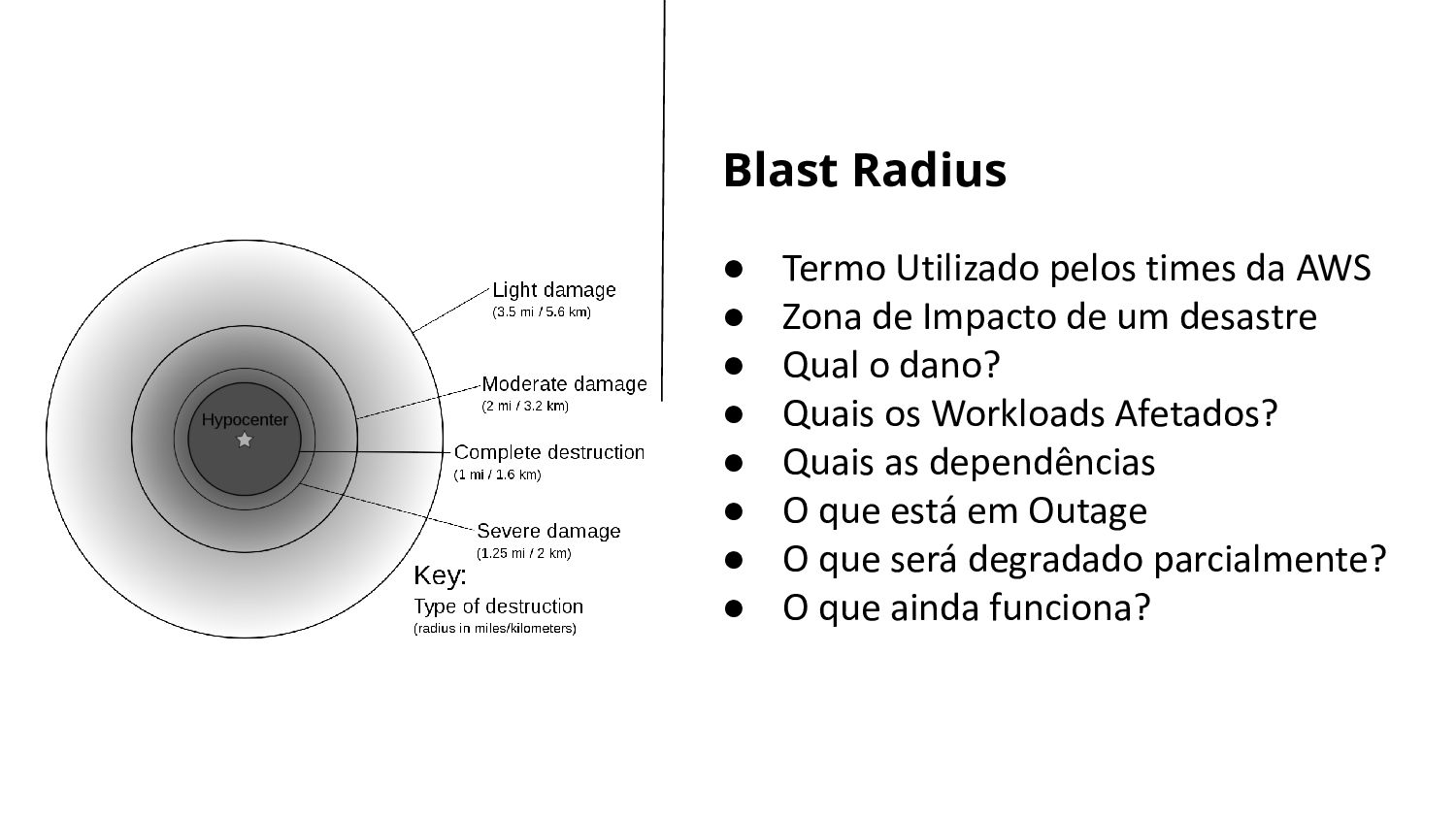
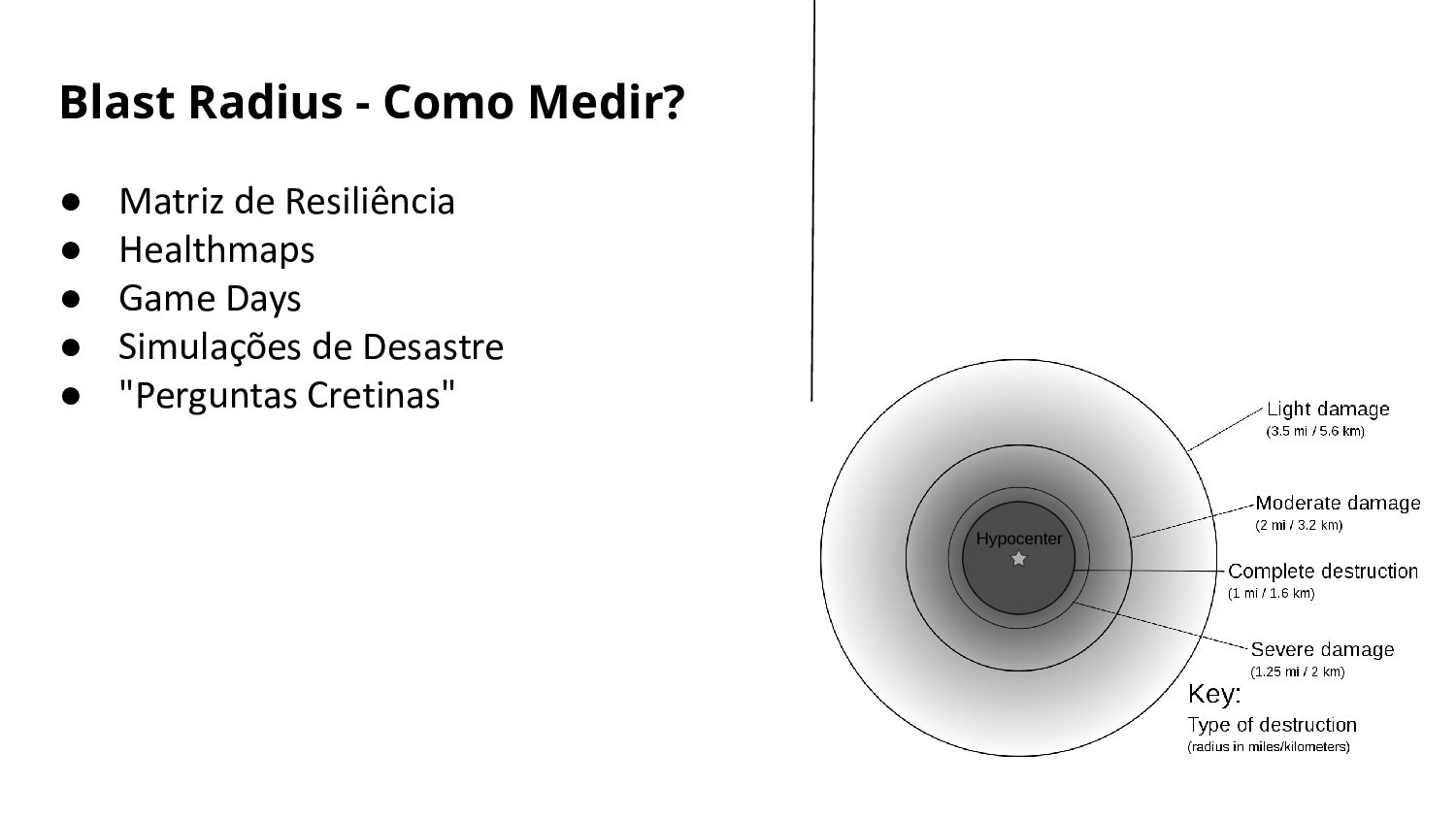
• Zona de Impacto de um desastre • Qual o dano? • Quais os Workloads Afetados? • Quais as dependências • O que está em Outage • O que será degradado parcialmente? • O que ainda funciona? Blast Radius
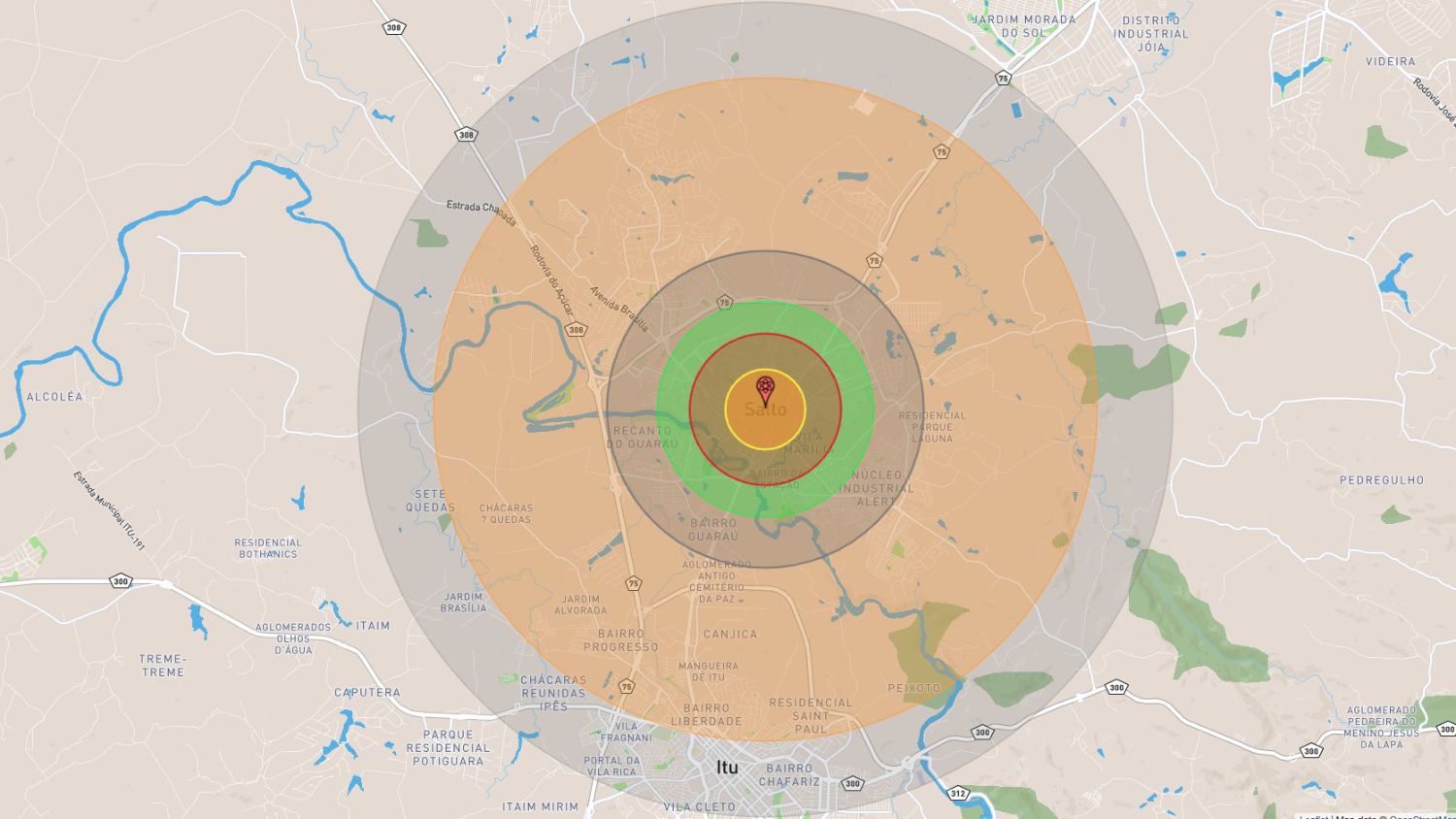
definição • Quem define o que é um desastre? • Capacidade de escolher entre ◦ Tomar uma voadora ◦ Tomar um soco ◦ Tomar um tapa • Minimizar e contornar os impactos • Simular é melhor que o acaso • Medir o Blast Radius • Gerar Backlog Disaster Recovery
o impacto real delas • Diminuir as Dependências • Criar fluxos alternativos • TradeOffs • Testar ativamente os fluxos alternativos • Desligar dependências, simular falhas e manter os SLO's Disaster Recovery & Game Days Objetivos
Multi Region • Backups, Snapshots, Restore • Recursos Redundantes • Camadas de Dados • Região e Plano de DR? • Capacity Planning • Plataforma • SLA dos fornecedores
de Comunicação Sync • Priorizar comunicação Async • Sempre pensar num fallback • Mensageria e Filas Async • Plataforma Inbound & Outbound • Timeout nas Integrações
duas ou mais soluções? ◦ Use várias • Duvida entre dois ou mais parceiros? ◦ Tenha vários • Fluxo reserva • Mensageria, Reservas, Fluxo • Represagem • Processamento tardio
dos Fallbacks • Trabalhar com as falhas de forma prevista • Thresholds 5xx, conn, business • Fallback acionado de forma inteligente • Quebra tornar o fallback prioritário • Checagem inteligente • Monitoramento
• Garantir de verdade • MVP não é desculpa • Deu certo, e agora??? • Revisitar periodicamente • Score de confiança interno • Até quando é do controle do SRE?
inovação? • Quais as melhores ferramentas? • Quais as melhores práticas? • Quais as melhores recomendações? • Tudo isso já vem por default? • Como garantir isso rápido? • Como evoluir isso? Templates & Golden Path
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}