2013 Wellington Thanks to Prof Manuel Ujaldon of University of Malaga and Dr Michael Dinneen of University of Auckland for providing illustrations to and reviewing the paper
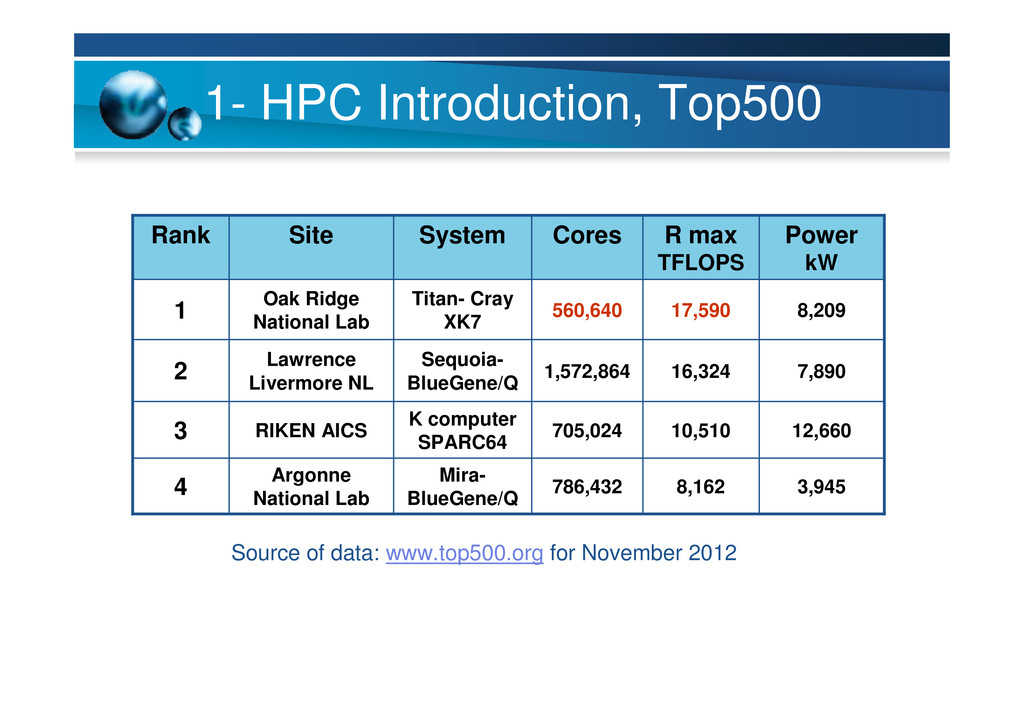
2012 3,945 8,162 786,432 Mira- BlueGene/Q Argonne National Lab 4 12,660 10,510 705,024 K computer SPARC64 RIKEN AICS 3 7,890 16,324 1,572,864 Sequoia- BlueGene/Q Lawrence Livermore NL 2 8,209 17,590 560,640 Titan- Cray XK7 Oak Ridge National Lab 1 Power kW R max TFLOPS Cores System Site Rank
– noted for its parallel efficiency – often used to simulate large systems (100 millions of atoms) – developed by University of Illinois in 1995 – since matured and scalable to thousands of processors. Latest stable version is 2.9 Viruses are very small intra-cellular parasites that invade the cells of virtually all known organisms. They reproduce by utilizing the cell's machinery to replicate viral proteins and genomic material, generally damaging or killing the host cell in the process Source: University of Illinois NAMD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
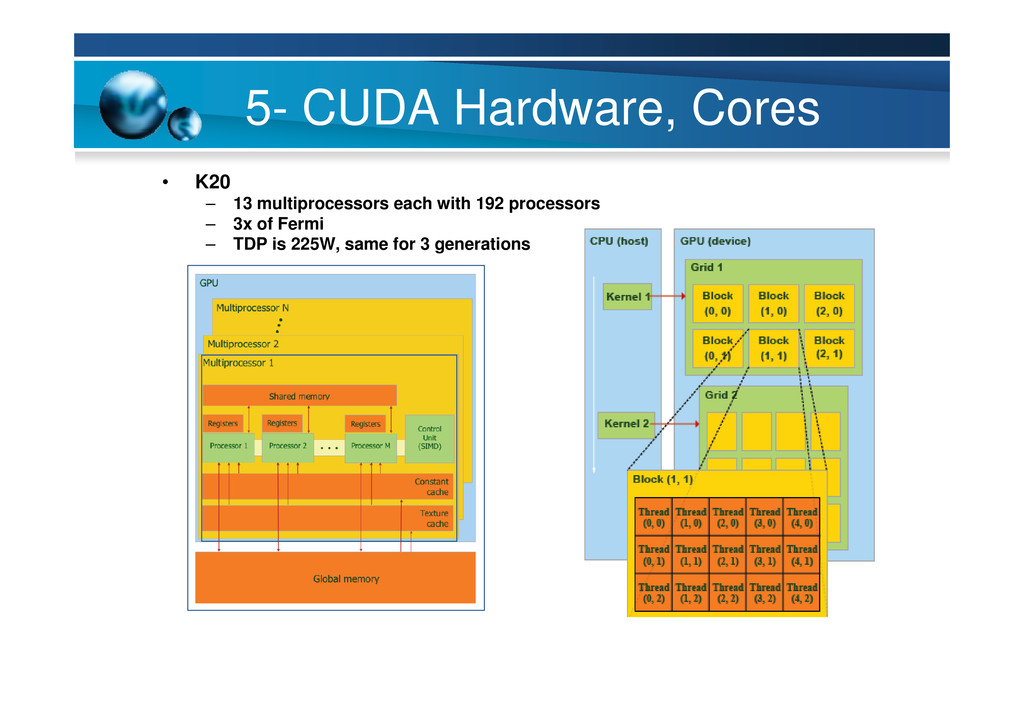{kind=link}
{kind=link}
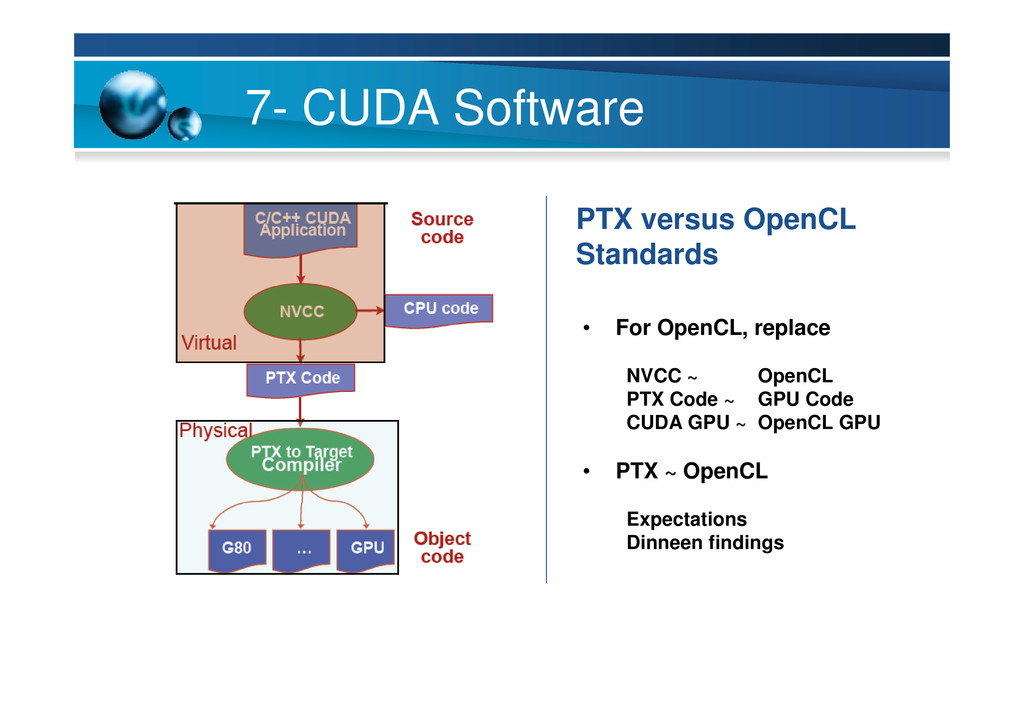{kind=link}
{kind=link}
{kind=link}
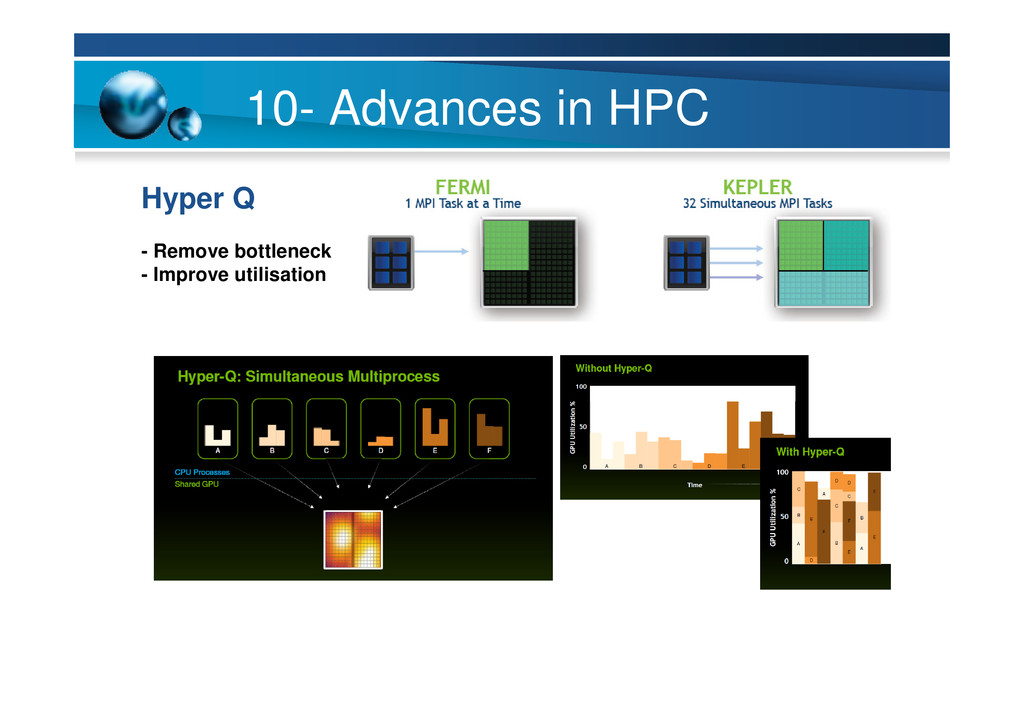{kind=link}
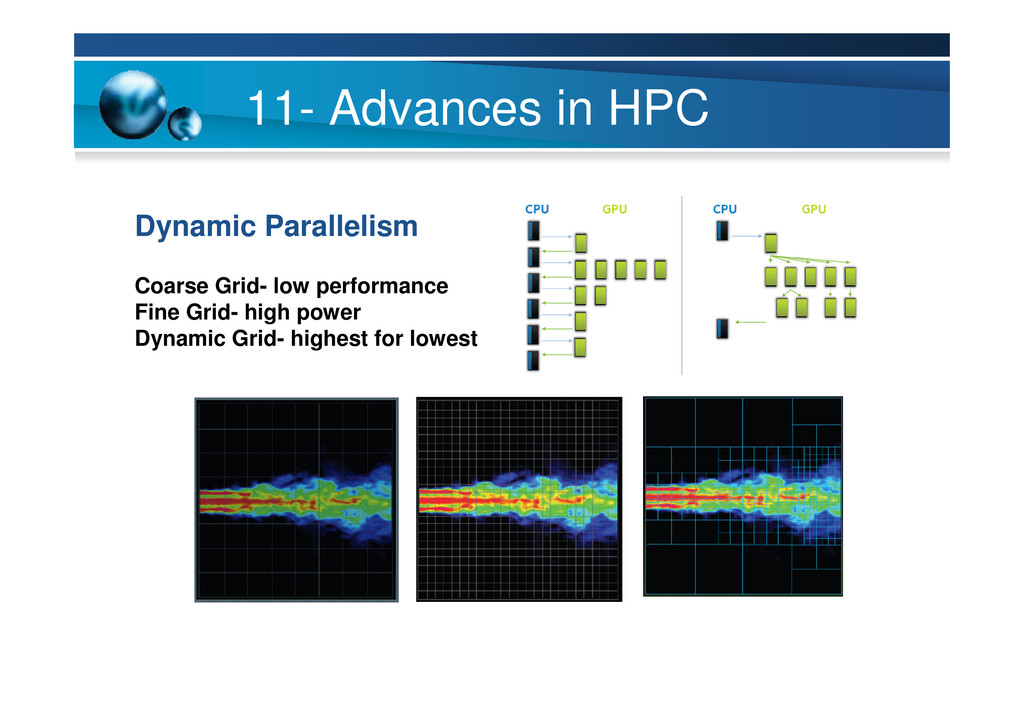{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}