This Looks Like That: Deep Learning for Interpretable Image Recognitionをまとめてみた
This Looks Like That: Deep Learning for Interpretable Image Recognition
Chaofan, C. Oscar, L. Daniel, T. Alina, B. Cynthia, R. Jonathan, K. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019)
Chaofan, C. Oscar, L. Daniel, T. Alina, B. Cynthia, R. Jonathan, K. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019) 筑波⼤学院 宗政 友洋 作成者 :
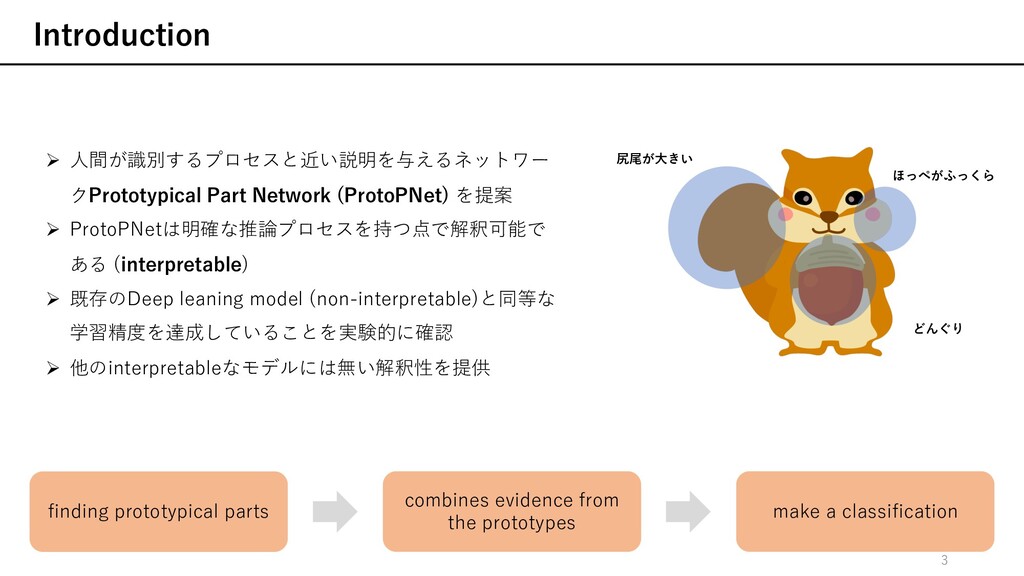
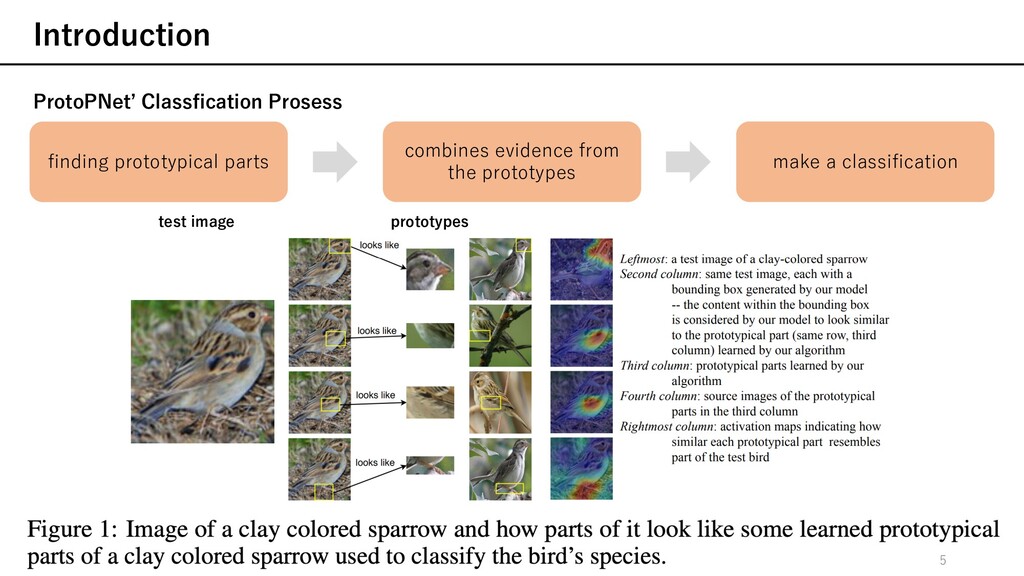
(interpretable) Ø 既存のDeep leaning model (non-interpretable)と同等な 学習精度を達成していることを実験的に確認 Ø 他のinterpretableなモデルには無い解釈性を提供 尻尾が⼤きい どんぐり ほっぺがふっくら Introduction finding prototypical parts combines evidence from the prototypes make a classification 3
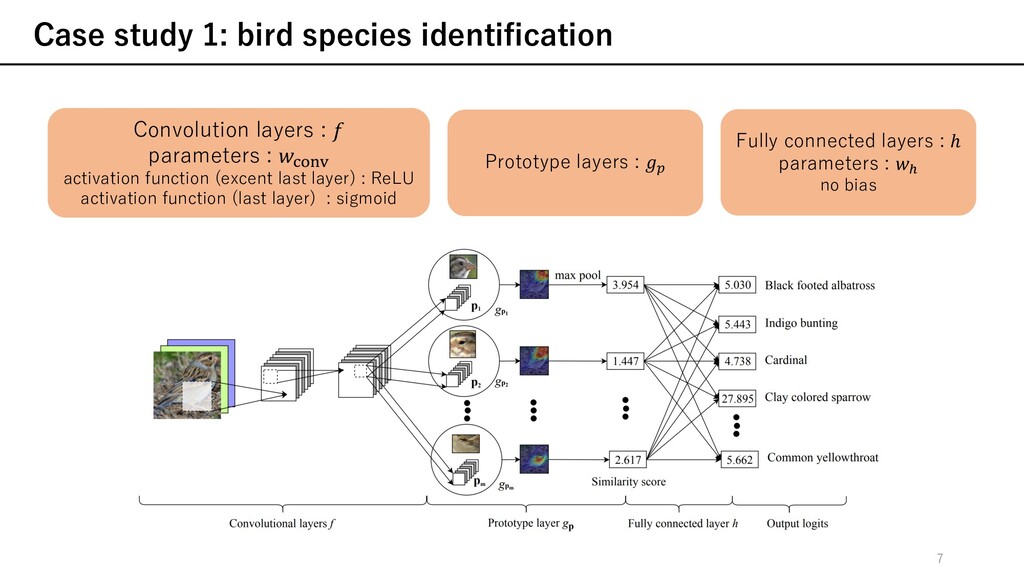
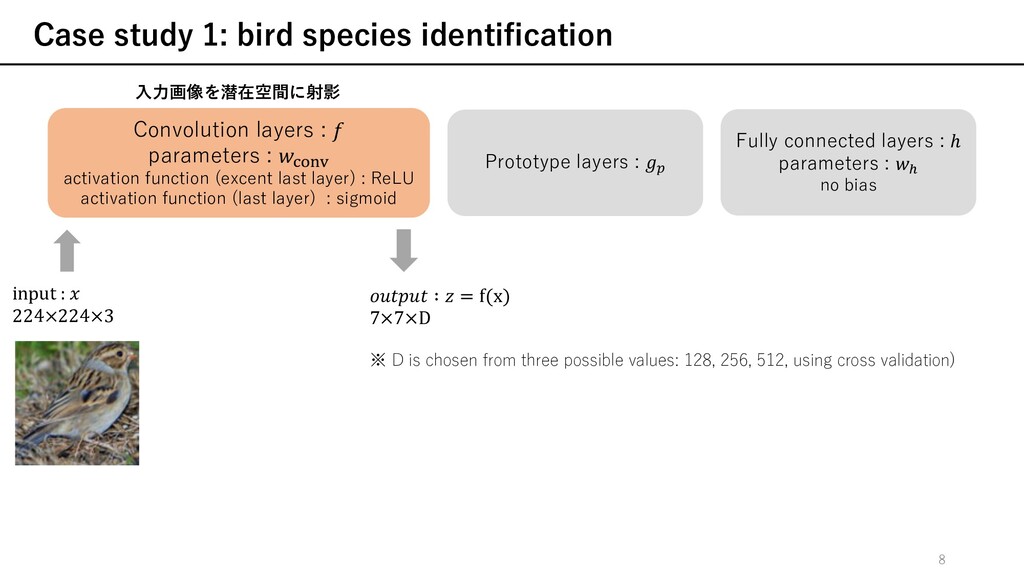
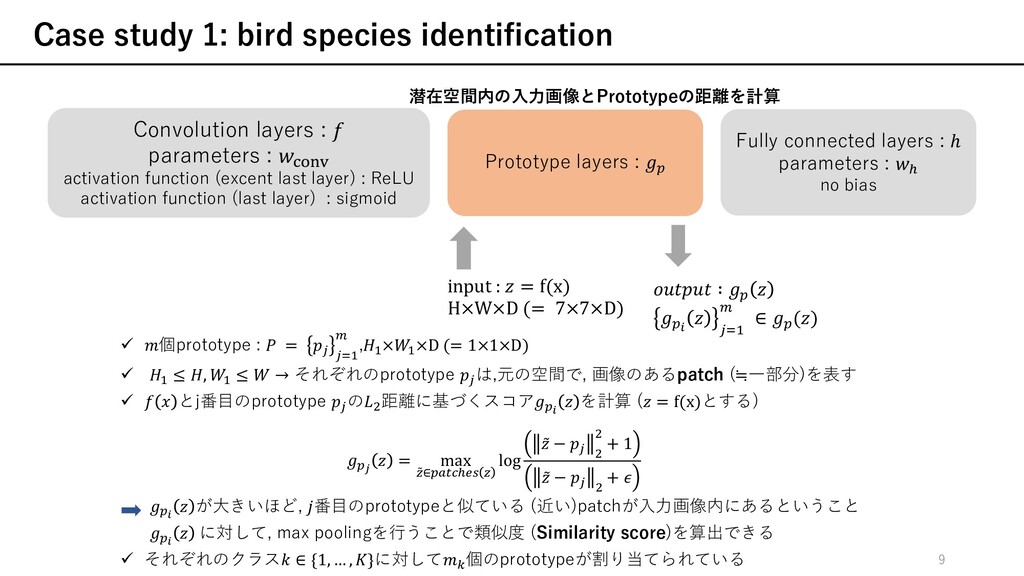
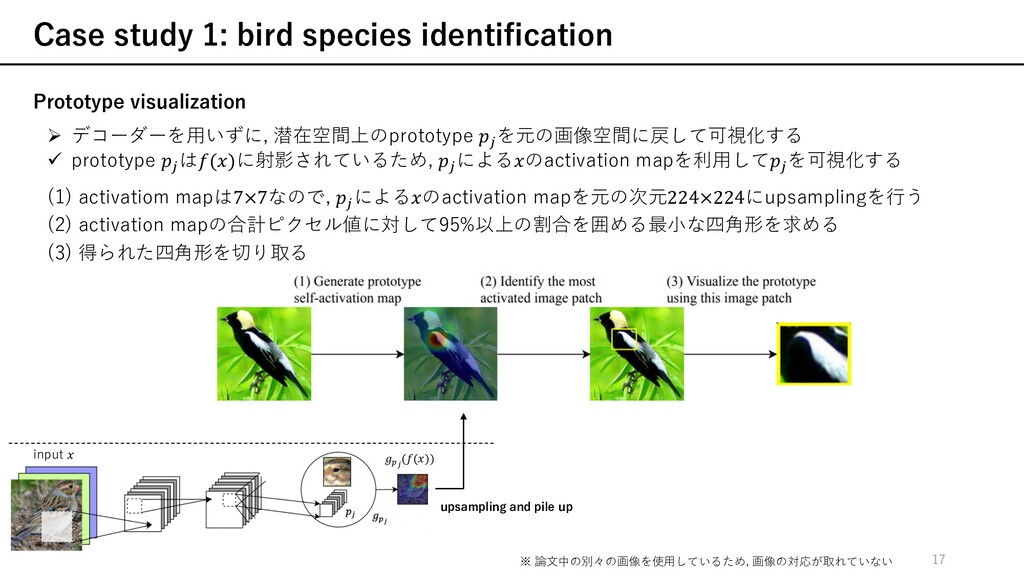
) ü 訓練されたモデルに対して, 説明性を与える⼿法 ü ネットワークが実際にどのように決定をするかの推論プロセスを説明するものではない attention-based interpretability (Ex. Part R-CNN, PS-CNN, 2-level attn, Neural const, RA-CNN, ...) ü 決定するときに注⽬している箇所を強調する⼿法 ü ⼊⼒のどの部分を注⽬しているのかを⽰すのみ other prototype classification techniques prototype (≒訓練データの⼀部を代表する表現)を⽤いた学習 ü 本論⽂は[24]と最も近い ü prototypeを可視化するためにdecoderを必要 ü ⾃然画像の場合, 可視化の際に現実的なprototypeの作成に失敗 ü decoder不要 ü 全てのprototypeはある訓練データの潜在表現のため, 忠実に可視化可能 本論⽂では, 推論プロセスを含めた説明性を与える 注⽬しているのかを⽰すことに加えて, それらの部分に類似した典型的なケースを⽰している f x [24] O. Li, H. Liu, C. Chen, and C. Rudin. Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI), 2018. 6
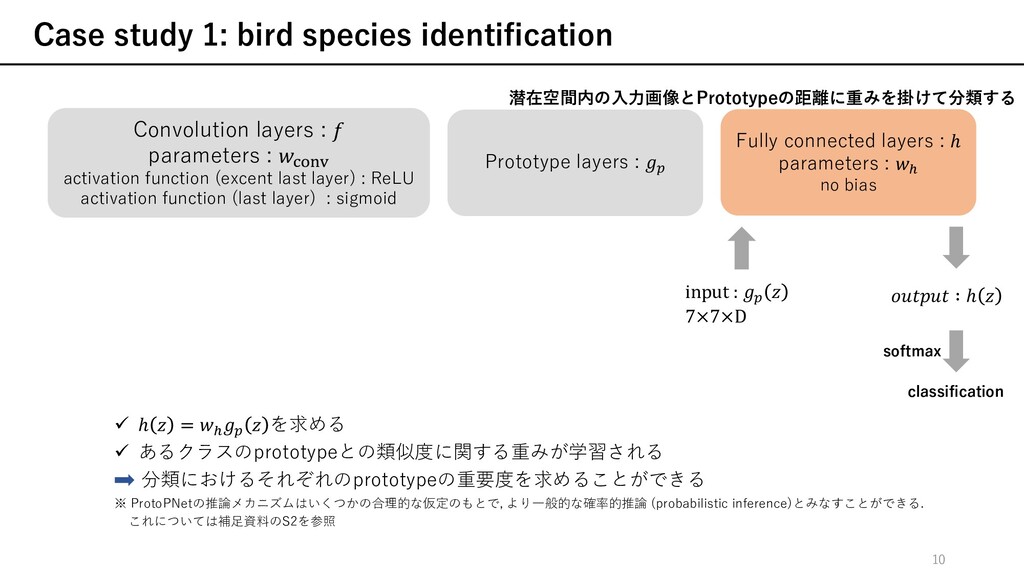
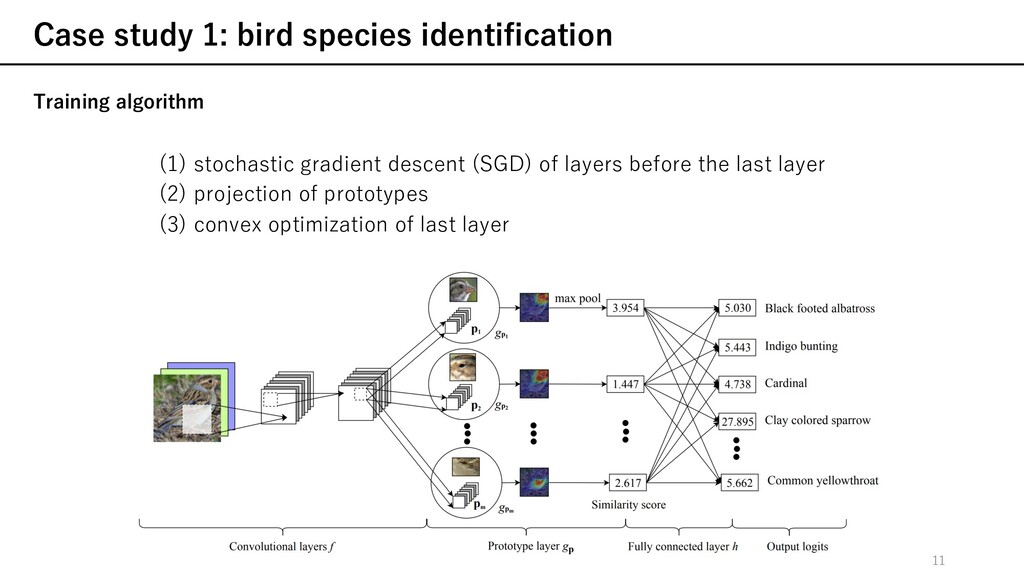
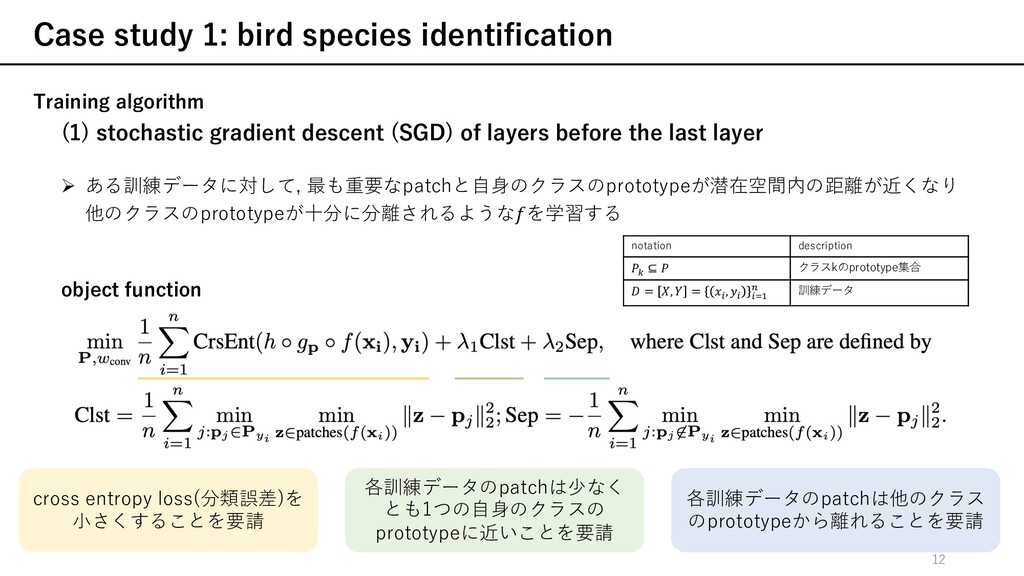
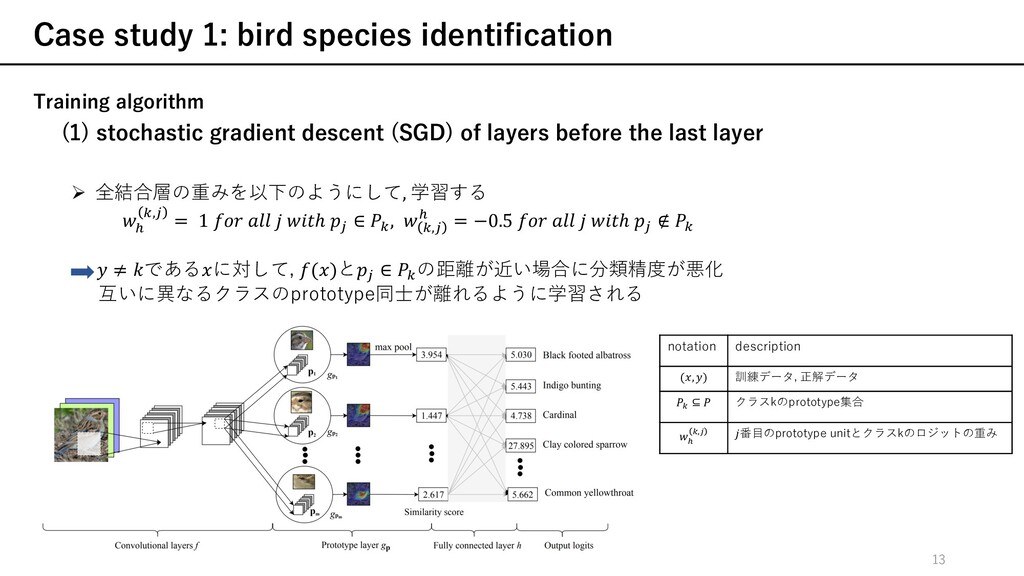
gradient descent (SGD) of layers before the last layer Ø ある訓練データに対して, 最も重要なpatchと⾃⾝のクラスのprototypeが潜在空間内の距離が近くなり 他のクラスのprototypeが⼗分に分離されるようなを学習する notation description m ⊆ クラスkのprototype集合 = , = r , r rRS t 訓練データ cross entropy loss(分類誤差)を ⼩さくすることを要請 各訓練データのpatchは他のクラス のprototypeから離れることを要請 各訓練データのpatchは少なく とも1つの⾃⾝のクラスの prototypeに近いことを要請 object function 12
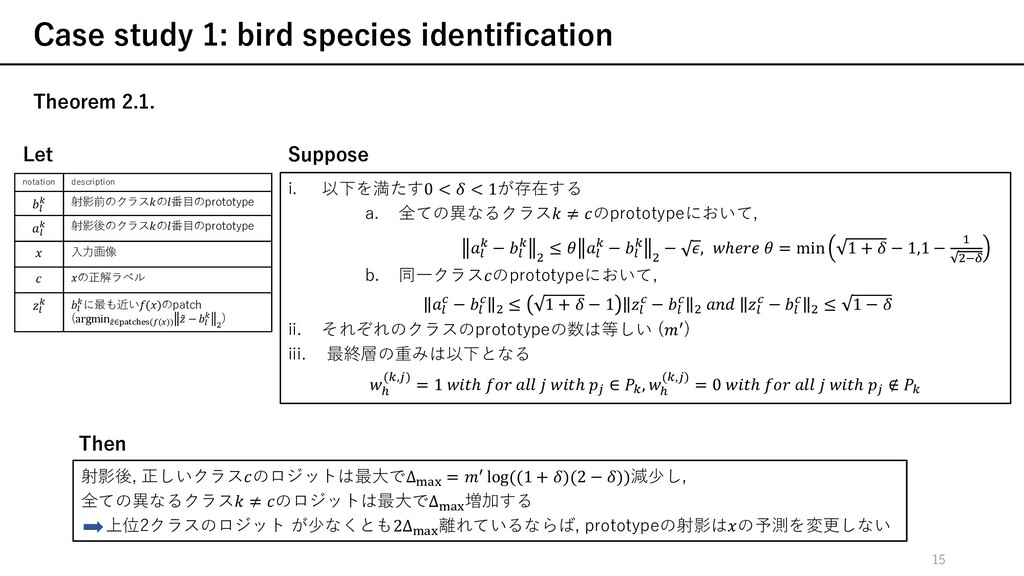
射影後, 正しいクラスのロジットは最⼤でΔ€•‚ = ƒ log((1 + )(2 − ))減少し, 全ての異なるクラス ≠ のロジットは最⼤でΔ€•‚ 増加する 上位2クラスのロジット が少なくとも2Δ€•‚ 離れているならば, prototypeの射影はの予測を変更しない notation description † m 射影前のクラスの番⽬のprototype † m 射影後のクラスの番⽬のprototype ⼊⼒画像 の正解ラベル † m † mに最も近い()のpatch (argmin ̃ `∈ˆ•‰,Š‹Œ(•(Ž)) ̃ − † m Z ) i. 以下を満たす0 < < 1が存在する a. 全ての異なるクラス ≠ のprototypeにおいて, † m − † m Z ≤ † m − † m Z − , ℎ = min 1 + − 1,1 − S Z’“ b. 同⼀クラスのprototypeにおいて, † c − † c Z ≤ 1 + − 1 † c − † c Z † c − † c Z ≤ 1 − ii. それぞれのクラスのprototypeの数は等しい (ƒ) iii. 最終層の重みは以下となる 3 (m,Q) = 1 ℎ ℎ Q ∈ m, 3 (m,Q) = 0 ℎ ℎ Q ∉ m Then 15
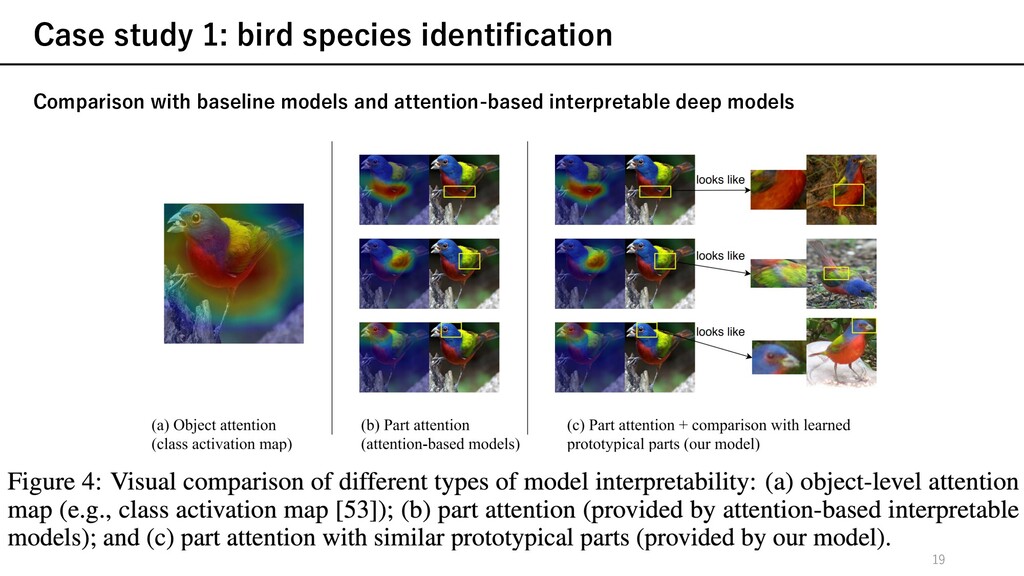
and attention-based interpretable deep models Ø ProtoPNetとBaseline (without the prototype layer)との精度⽐較 Ø ProtoPNetと既存⼿法との精度⽐較 full : model was trained on full images bb : model was trained on images cropped usinng bounding boxes (or the model used bounding boxes in other ways) anno : model was trained with keypoint annotations of bird parts 20
and prototype pruning test image three nearest prototype Ø ある検証データのpatchに対して近傍にあるprototypeの上位3件 Ø あるprototypeに対して近傍にあるpatchの上位3件 ü 検証データの近傍にあるprototypeは同⼀のクラスからなる ü あるprototypeのpatchは同質の意味概念を持つ prototype three nearest training patches three nearest test patches 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}