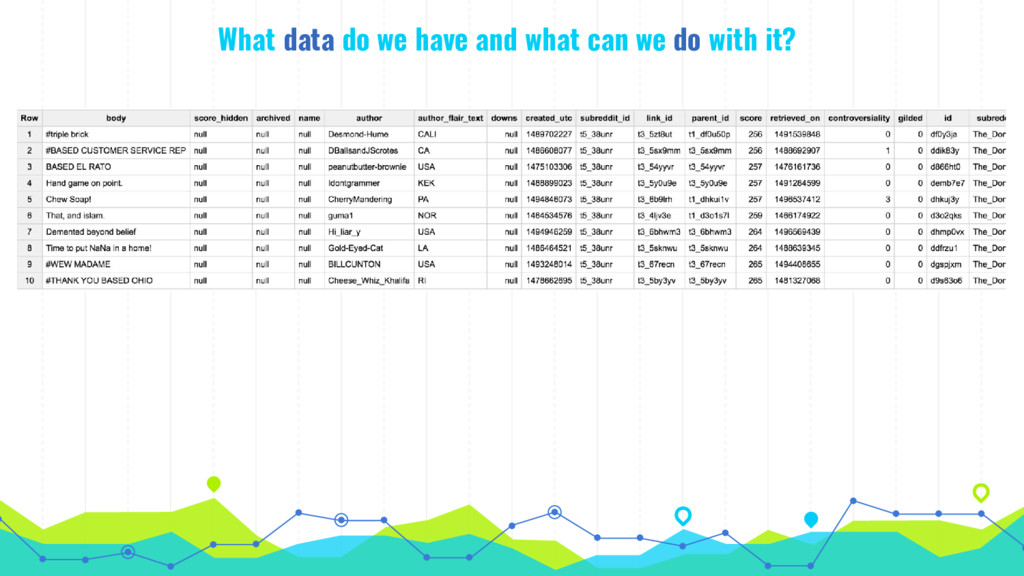
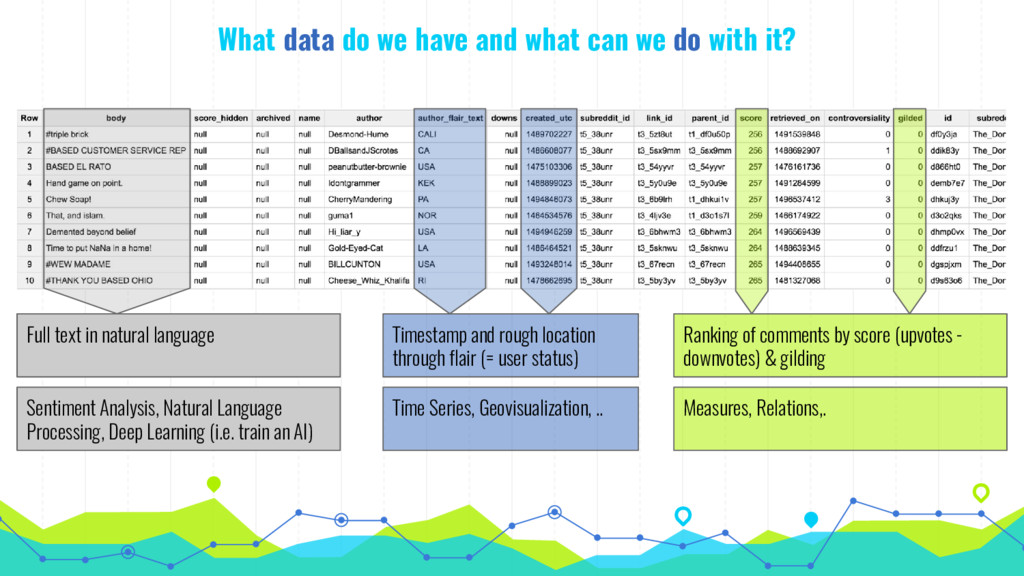
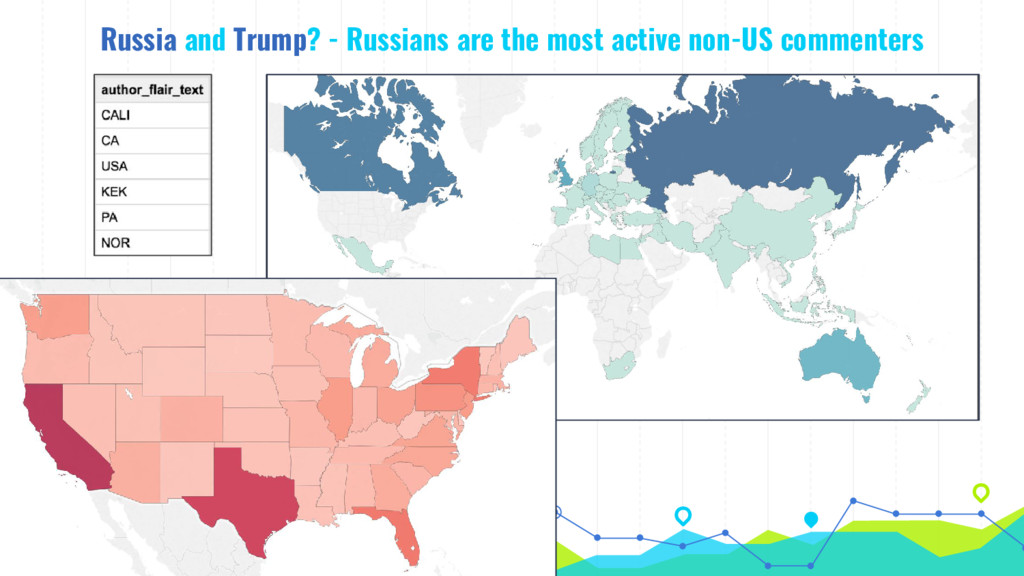
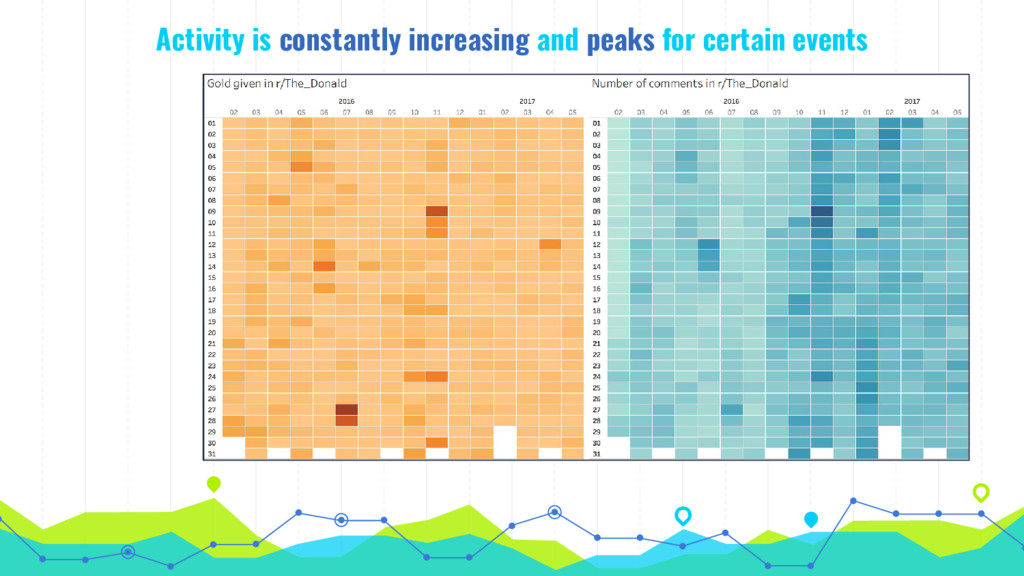
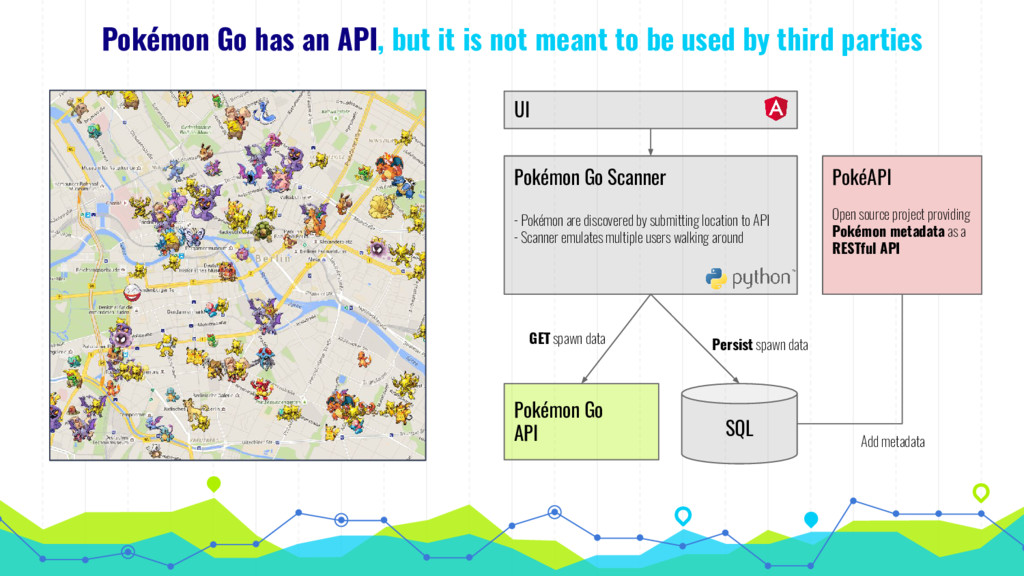
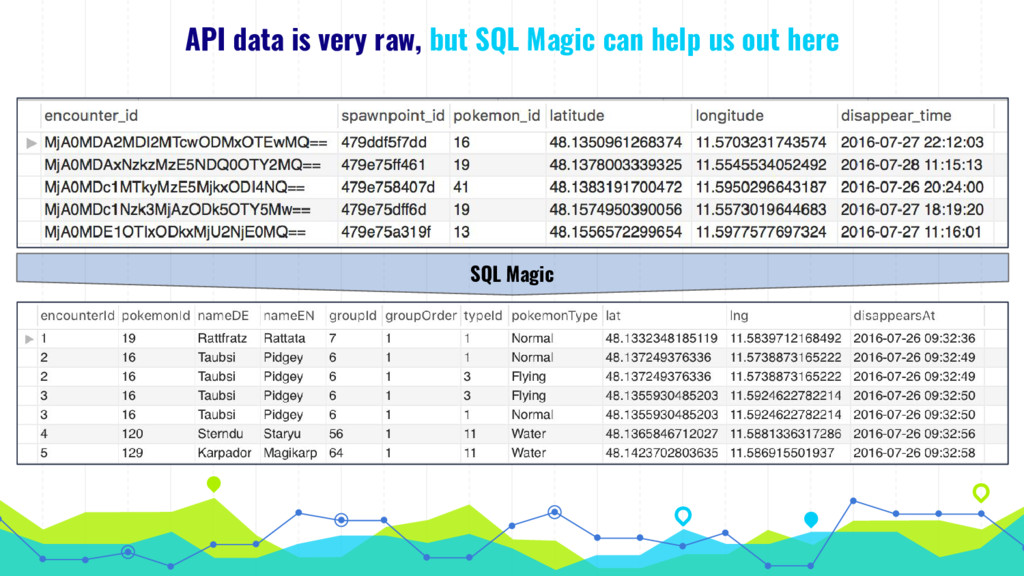
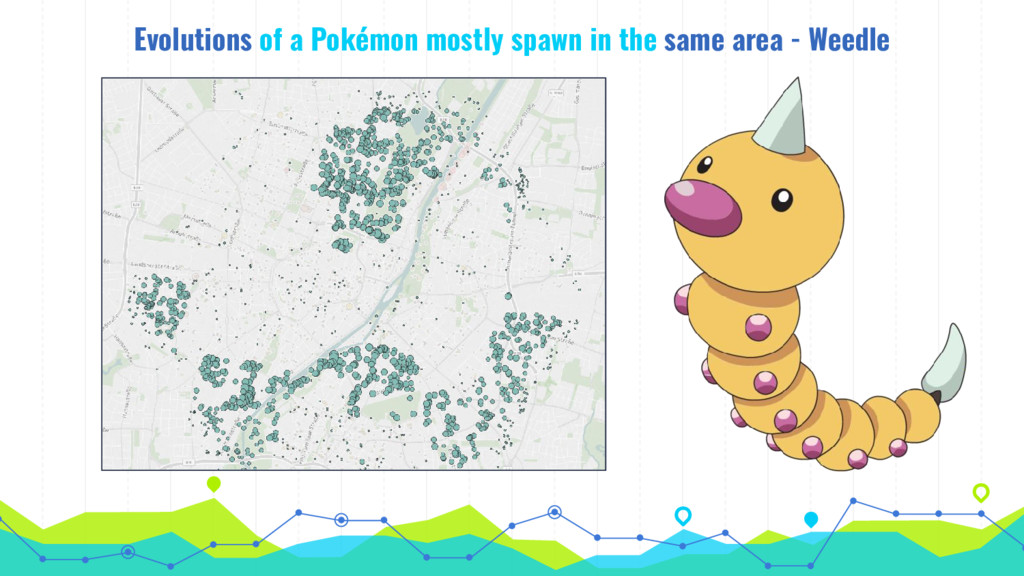
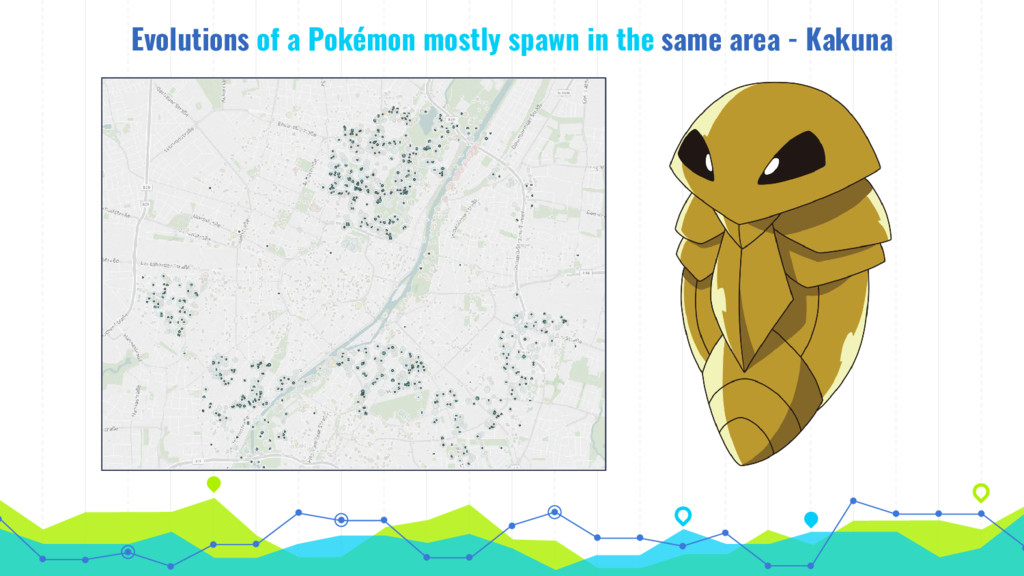
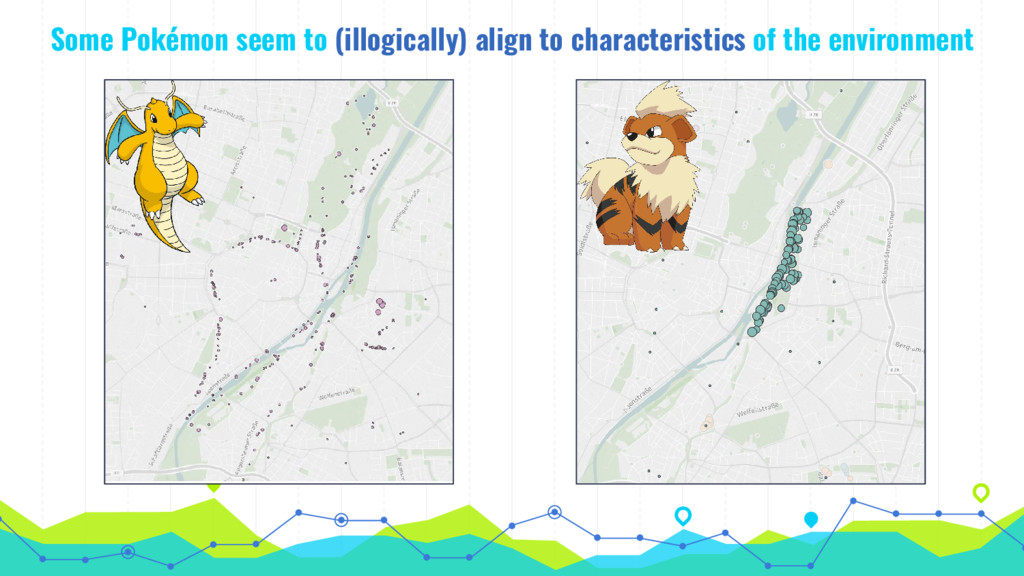
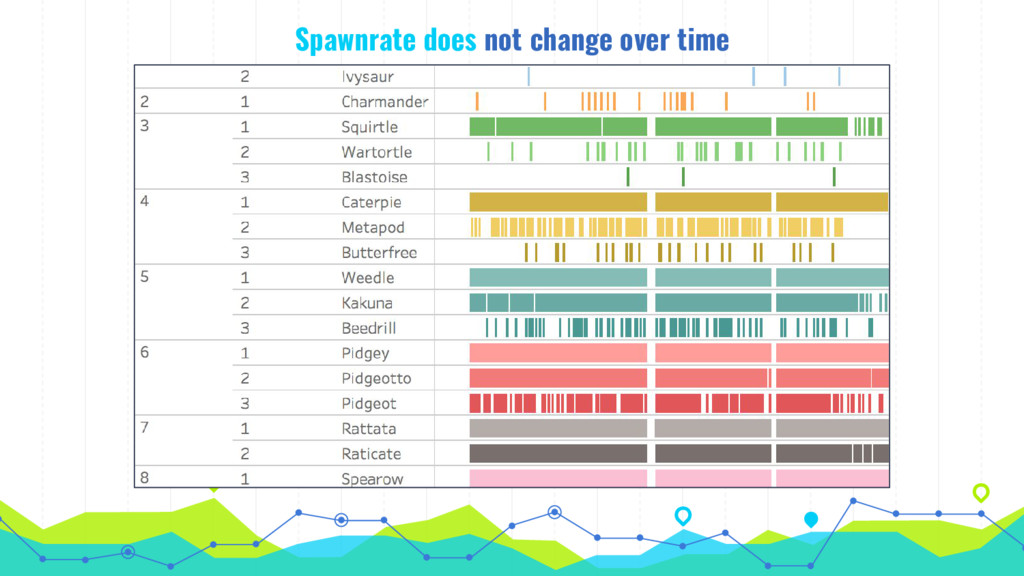
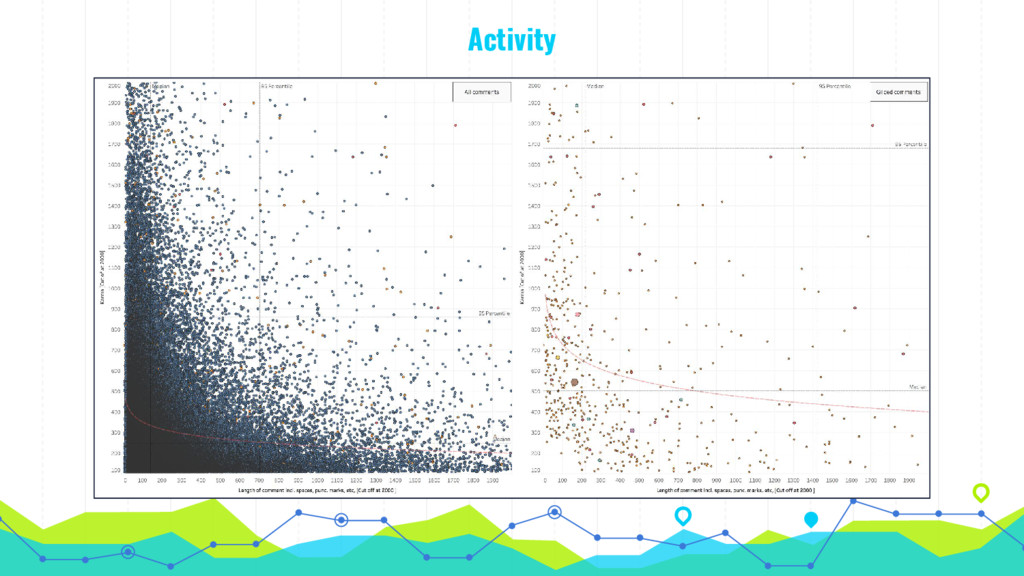
In his talk, Markus talks about extracting, analyzing and visualizing data from unusual sources. He will talk about two of his projects: First he'll talk about using a Pokémon Go bot to gather and processing data on 250k spawns of Pokémon in Munich during the peak of the Pokémon Go hype in 2016 and the insights about the logic behind the game that he gained by visualizing this data. Second he will talk about his analysis of 16 mio. comments in r/The_Donald, a community on Reddit that is devoted to Donald Trump, analyzing (among others) the community's language compared to natural english, activity levels over time and geographical distribution of users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}