In today‘s dynamic world turnover of customers is high, and companies spend more and more money to win new clients. However, it is usually much more sustainable and rewarding to keep the hard-won customers, rather than chase the new ones. B2C industries, lead by telco and retail, are already implementing data-driven solutions for customer retention. However, in the B2B context, customer retention still remains out of the focus of data science. In this talk, we will present a newly developed and implemented data-driven solution to track customer churn and address potential threats within Siemens client base worldwide. We will go through the different aspects of a real world data initiative from the setup, data acquisition and management, to modeling and delivering the analytical results to the end user.
{kind=link}
{kind=link}
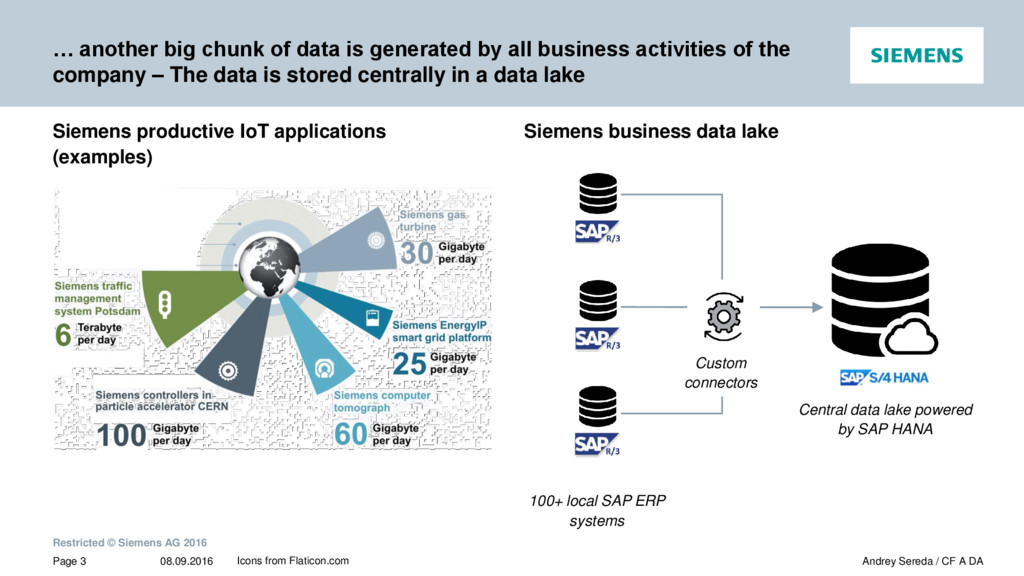{kind=link}
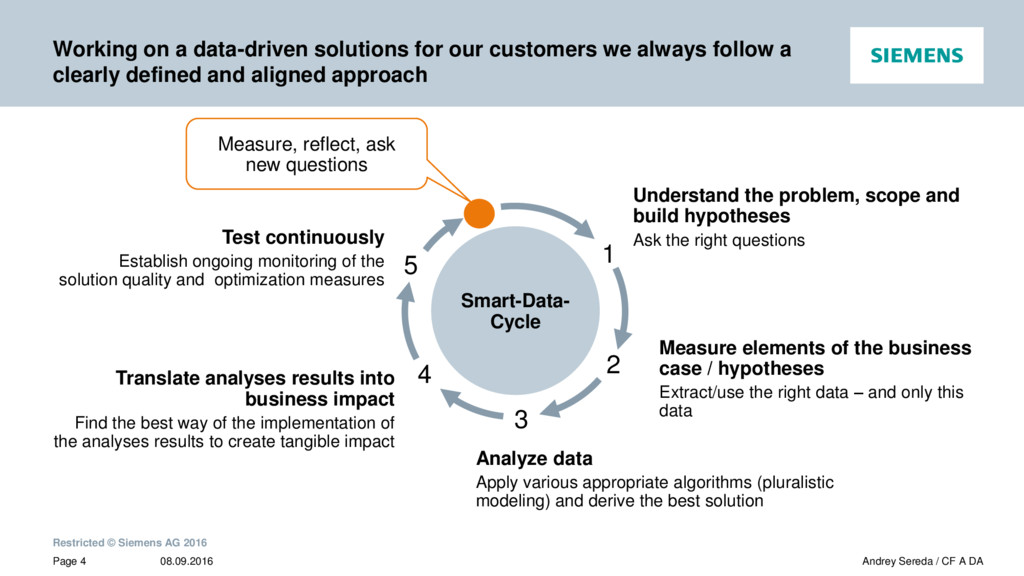{kind=link}
{kind=link}
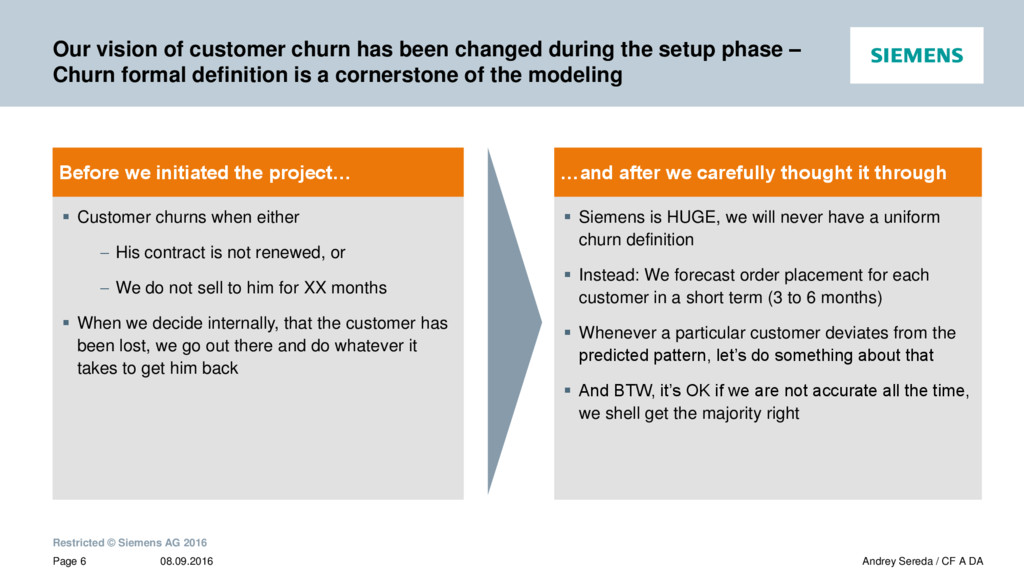{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
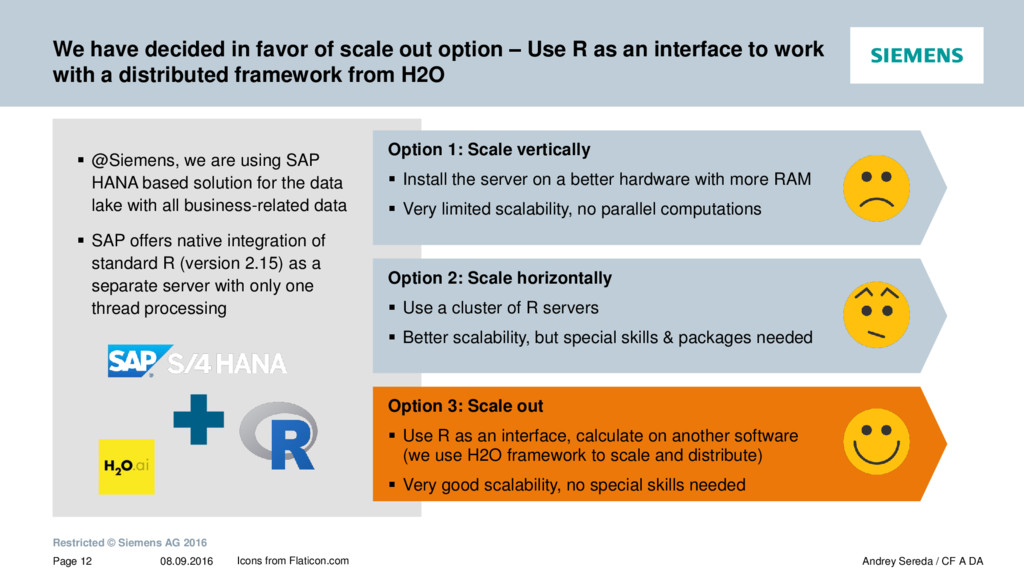{kind=link}
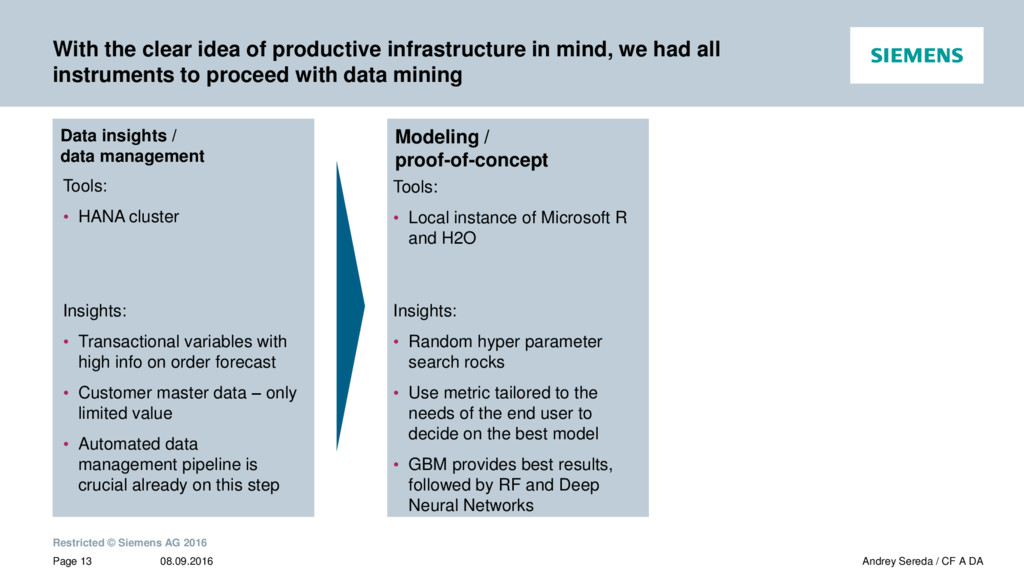{kind=link}
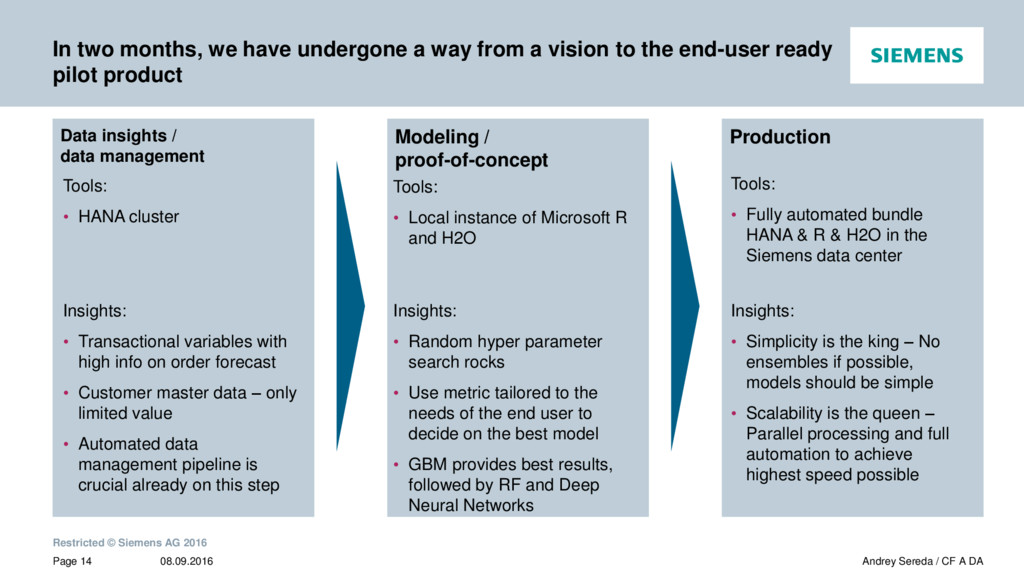{kind=link}
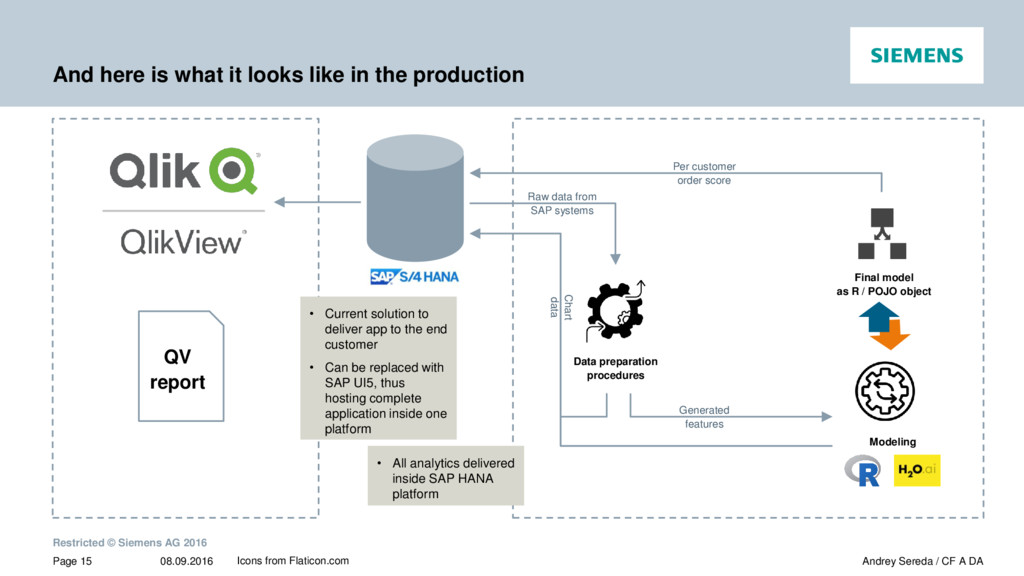{kind=link}
{kind=link}
{kind=link}
{kind=link}
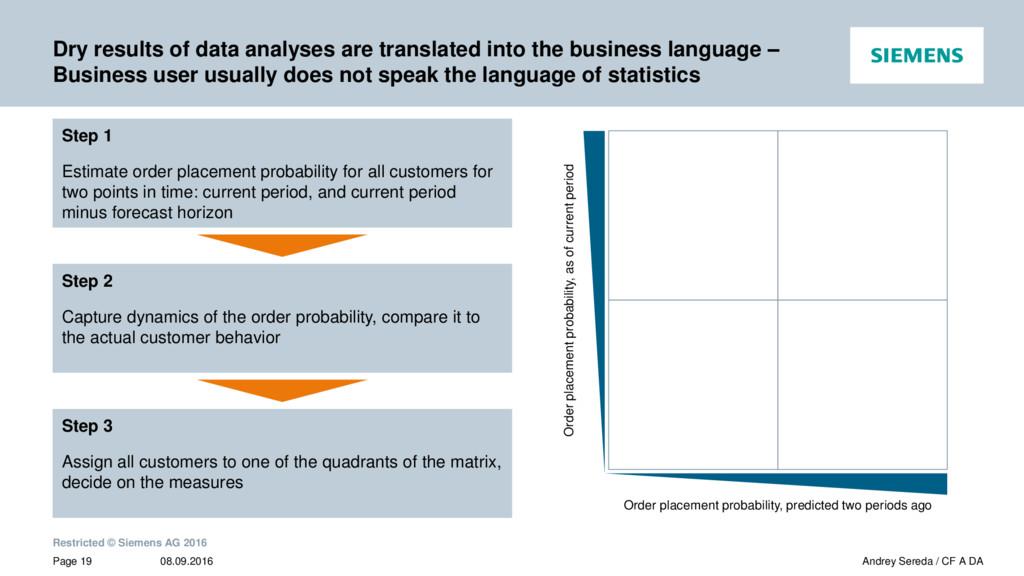
{kind=link}